



你好,AI艺术家朋友! 👋 欢迎来到我们面向初学者的ComfyUI教程,这是一个令人难以置信的强大和灵活的工具,用于创作令人惊叹的AI生成艺术。 🎨 在本指南中,我们将带你了解ComfyUI的基础知识,探索其功能,并帮助你释放其潜力,将你的AI艺术提升到一个新的水平。 🚀
我们将涵盖:
- 1. 什么是ComfyUI?
- 1.1. ComfyUI vs. AUTOMATIC1111
- 1.2. 从哪里开始使用ComfyUI?
- 1.3. 基本控件
- 2. ComfyUI工作流: 从文本到图像
- 2.1. 选择一个模型
- 2.2. 输入正面提示词和负面提示词
- 2.3. 生成图像
- 2.4. ComfyUI的技术解释
- 2.4.1 Load Checkpoint节点
- 2.4.2. CLIP Text Encode
- 2.4.3. Empty Latent Image
- 2.4.4. VAE
- 2.4.5. KSampler
- 3. ComfyUI工作流: 从图像到图像
- 4. ComfyUI SDXL
- 5. ComfyUI Inpainting
- 6. ComfyUI Outpainting
- 7. ComfyUI Upscale
- 7.1. Upscale Pixel
- 7.1.1. 使用算法进行Upscale Pixel
- 7.1.2. 使用模型进行Upscale Pixel
- 7.2. Upscale Latent
- 7.3. Upscale Pixel vs. Upscale Latent
- 8. ComfyUI ControlNet
- 9. ComfyUI管理器
- 9.1. 如何安装缺失的自定义节点
- 9.2. 如何更新自定义节点
- 9.3. 如何在工作流中加载自定义节点
- 10. ComfyUI Embeddings
- 10.1. 带自动补全的Embedding
- 10.2. Embedding权重
- 11. ComfyUI LoRA
- 11.1. 简单的LoRA工作流
- 11.2. 多个LoRA
- 12. ComfyUI的快捷方式和技巧
- 12.1. 复制和粘贴
- 12.2. 移动多个节点
- 12.3. 绕过一个节点
- 12.4. 最小化一个节点
- 12.5. 生成图像
- 12.6. 嵌入式工作流
- 12.7. 固定种子以节省时间
1. 什么是ComfyUI? 🤔#
ComfyUI就像拥有一支神奇魔杖🪄,可以轻松创造出令人惊叹的AI生成艺术。从本质上讲,ComfyUI是构建在Stable Diffusion之上的基于节点的图形用户界面(GUI),而Stable Diffusion是一种最先进的深度学习模型,可以根据文本描述生成图像。 🌟 但ComfyUI真正特别之处在于,它如何让像你这样的艺术家释放创造力,将你最疯狂的想法变为现实。
想象一下有一块数字画布,你可以通过连接不同的节点来构建自己独特的图像生成工作流,每个节点代表一个特定的功能或操作。 🧩 就像为你的AI生成杰作构建一个视觉食谱!
想从头开始使用文本提示生成图像?这里有一个节点可以实现!需要应用特定的采样器或微调噪声级别?只需添加相应的节点,观察魔法的发生。 ✨
但这里是最精彩的部分:ComfyUI将工作流分解成可重组的元素,让你可以自由创建适合你艺术愿景的自定义工作流。 🖼️ 就像拥有一个适应你创作过程的个性化工具包。
1.1. ComfyUI vs. AUTOMATIC1111 🆚#
AUTOMATIC1111是Stable Diffusion的默认GUI。那么,你应该使用ComfyUI吗?让我们对比一下:
✅ 使用ComfyUI的好处:
- 轻量级: 运行速度快,效率高。
- 灵活性: 高度可配置以满足你的需求。
- 透明度: 数据流可见,易于理解。
- 易于分享: 每个文件代表一个可重现的工作流。
- 适合原型开发: 使用图形界面而不是编码来创建原型。
❌ 使用ComfyUI的缺点:
- 界面不一致: 每个工作流可能有不同的节点布局。
- 细节太多: 普通用户可能不需要知道底层连接。
1.2. 从哪里开始使用ComfyUI? 🏁#
我们相信,学习ComfyUI的最佳方式是通过深入示例并亲身体验。 🙌 这就是为什么我们创建了这个独特的教程,使它与众不同。在本教程中,你将找到一个详细的、循序渐进的指南,你可以跟着一起学习。
但这里是最棒的部分: 🌟 我们已经将ComfyUI直接整合到这个网页中!当你浏览指南时,你可以实时与ComfyUI示例互动。 🌟 让我们开始吧!
2. ComfyUI工作流: 从文本到图像 🖼️#
让我们从最简单的案例开始:从文本生成图像。点击Queue Prompt运行工作流。短暂等待后,你应该看到你的第一个生成的图像!要查看你的队列,只需点击View Queue。
这里有一个默认的从文本到图像工作流供你尝试:
基本构建块 🕹️#
ComfyUI工作流由两个基本构建块组成: 节点和边。
- 节点是矩形块,例如Load Checkpoint、Clip Text Encoder等。每个节点执行特定的代码,需要输入、输出和参数。
- 边是连接节点之间输出和输入的连线。
基本控件 🕹️#
- 使用鼠标滚轮或双指捏合来放大和缩小。
- 拖动并按住输入或输出点,在节点之间创建连接。
- 按住鼠标左键并拖动,在工作区内移动。
让我们深入探讨这个工作流的细节。#
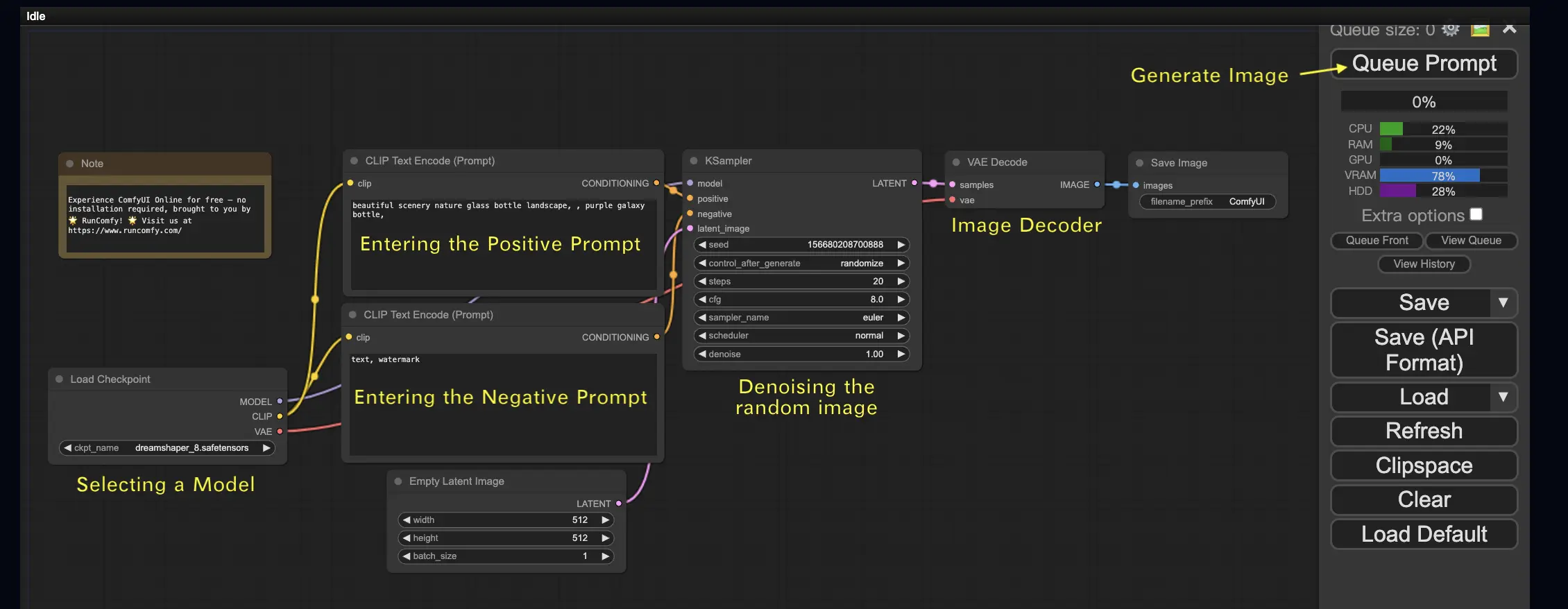
2.1. 选择一个模型 🗃️#
首先,在Load Checkpoint节点中选择一个Stable Diffusion Checkpoint模型。点击模型名称以查看可用的模型。如果点击模型名称没有任何反应,你可能需要上传一个自定义模型。
2.2. 输入正面提示词和负面提示词 📝#
你会看到两个标有CLIP Text Encode (Prompt)的节点。顶部的提示词连接到KSampler节点的positive输入,而底部的提示词连接到negative输入。所以在顶部输入你的正面提示词,在底部输入你的负面提示词。
CLIP Text Encode节点将提示词转换为令牌,并使用文本编码器将它们编码为嵌入。
💡 小贴士:使用(keyword:weight)语法来控制关键词的权重,例如(keyword:1.2)来增加其效果,或(keyword:0.8)来减少它。
2.3. 生成图像 🎨#
点击Queue Prompt运行工作流。短暂等待后,你的第一张图像将生成!
2.4. ComfyUI的技术解释 🤓#
ComfyUI的强大之处在于它的可配置性。了解每个节点的作用,可以让你根据需要对其进行定制。但在深入细节之前,让我们先看看Stable Diffusion的过程,以更好地理解ComfyUI是如何工作的。
Stable Diffusion的过程可以概括为三个主要步骤:
- 文本编码:用户输入的提示词由一个称为Text Encoder的组件编译成单个词特征向量。这一步将文本转换为模型可以理解和使用的格式。
- 潜在空间转换:来自Text Encoder的特征向量和一个随机噪声图像被转换到潜在空间。在这个空间中,随机图像根据特征向量进行去噪处理,生成一个中间产品。这一步是魔法发生的地方,因为模型学习将文本特征与视觉表示联系起来。
- 图像解码:最后,潜在空间中的中间产品由Image Decoder解码,将其转换为我们可以看到和欣赏的实际图像。
现在我们对Stable Diffusion过程有了高层次的理解,让我们深入研究ComfyUI中实现这一过程的关键组件和节点。
2.4.1 Load Checkpoint节点 🗃️#
ComfyUI中的Load Checkpoint节点对于选择Stable Diffusion模型至关重要。一个Stable Diffusion模型由三个主要组件组成:MODEL、CLIP和VAE。让我们探讨每个组件以及它们与ComfyUI中相应节点的关系。
- MODEL:MODEL组件是在潜在空间中运行的噪声预测模型。它负责从潜在表示生成图像的核心过程。在ComfyUI中,Load Checkpoint节点的MODEL输出连接到KSampler节点,在那里进行反向扩散过程。KSampler节点使用MODEL迭代地去噪潜在表示,逐步细化图像,直到它与所需的提示匹配。
- CLIP:CLIP(Contrastive Language-Image Pre-training)是一个语言模型,用于预处理用户提供的正面和负面提示词。它将文本提示词转换为MODEL可以理解和使用的格式,以指导图像生成过程。在ComfyUI中,Load Checkpoint节点的CLIP输出连接到CLIP Text Encode节点。CLIP Text Encode节点接受用户提供的提示词,并将它们输入到CLIP语言模型中,将每个词转换为嵌入。这些嵌入捕捉词语的语义含义,使MODEL能够生成与给定提示词一致的图像。
- VAE:VAE(Variational AutoEncoder)负责在像素空间和潜在空间之间转换图像。它由一个将图像压缩到低维潜在表示的编码器和一个从潜在表示重建图像的解码器组成。在从文本到图像的过程中,VAE仅用于最后一步,将生成的图像从潜在空间转换回像素空间。ComfyUI中的VAE Decode节点接受KSampler节点(在潜在空间中运行)的输出,并使用VAE的解码器部分将潜在表示转换为像素空间中的最终图像。
需要注意的是,VAE是一个独立于CLIP语言模型的组件。虽然CLIP专注于处理文本提示词,但VAE处理像素和潜在空间之间的转换。
2.4.2. CLIP Text Encode 📝#
ComfyUI中的CLIP Text Encode节点负责接受用户提供的提示词,并将它们输入到CLIP语言模型中。CLIP是一个强大的语言模型,可以理解词语的语义含义,并将它们与视觉概念联系起来。当一个提示词被输入到CLIP Text Encode节点时,它会经历一个转换过程,将每个词转换为嵌入。这些嵌入是高维向量,捕捉词语的语义信息。通过将提示词转换为嵌入,CLIP使MODEL能够生成准确反映给定提示词含义和意图的图像。
2.4.3. Empty Latent Image 🌌#
在从文本到图像的过程中,生成从潜在空间中的一个随机图像开始。这个随机图像作为MODEL开始工作的初始状态。潜在图像的大小与像素空间中实际图像的大小成比例。在ComfyUI中,你可以调整潜在图像的高度和宽度来控制生成图像的大小。此外,你可以设置批量大小来确定每次运行生成的图像数量。
潜在图像的最佳尺寸取决于使用的特定Stable Diffusion模型。对于SD v1.5模型,推荐的尺寸是512x512或768x768,而对于SDXL模型,最佳尺寸是1024x1024。ComfyUI提供了一系列常见的纵横比可供选择,如1:1(正方形)、3:2(横向)、2:3(纵向)、4:3(横向)、3:4(纵向)、16:9(宽屏)和9:16(垂直)。需要注意的是,潜在图像的宽度和高度必须能被8整除,以确保与模型架构的兼容性。
2.4.4. VAE 🔍#
VAE(Variational AutoEncoder)是Stable Diffusion模型中的一个关键组件,负责处理像素空间和潜在空间之间的图像转换。它由两个主要部分组成:图像编码器和图像解码器。
图像编码器接受像素空间中的图像,并将其压缩到低维潜在表示。这个压缩过程大大减少了数据大小,允许更高效的处理和存储。例如,一个512x512像素的图像可以被压缩到64x64的潜在表示。
另一方面,图像解码器,也称为VAE解码器,负责将潜在表示重建为像素空间中的图像。它接受压缩后的潜在表示,并将其扩展以生成最终图像。
使用VAE有几个优点:
- 效率:通过将图像压缩到低维潜在空间,VAE实现了更快的生成和更短的训练时间。减少的数据大小允许更高效的处理和内存使用。
- 潜在空间操纵:潜在空间提供了一个更紧凑和有意义的图像表示。这允许更精确地控制和编辑图像的细节和风格。通过操纵潜在表示,可以修改生成图像的特定方面。
然而,也有一些缺点需要考虑:
- 数据丢失:在编码和解码过程中,原始图像的一些细节可能会丢失。压缩和重建步骤可能会在最终图像中引入伪影或与原始图像略有不同。
- 对原始数据捕捉有限:低维潜在空间可能无法完全捕捉原始图像的所有复杂特征和细节。在压缩过程中,一些信息可能会丢失,导致对原始数据的表示略有不准确。
尽管有这些限制,VAE在Stable Diffusion模型中发挥着至关重要的作用,通过在像素空间和潜在空间之间进行高效转换,促进更快的生成和对生成图像的更精确控制。
2.4.5. KSampler ⚙️#
ComfyUI中的KSampler节点是Stable Diffusion中图像生成过程的核心。它负责对潜在空间中的随机图像进行去噪,以匹配用户提供的提示。KSampler采用一种称为反向扩散的技术,通过删除噪声和根据CLIP嵌入的指导添加有意义的细节,迭代地细化潜在表示。
KSampler节点提供了几个参数,允许用户微调图像生成过程:
Seed: 种子值控制最终图像的初始噪声和构图。通过设置特定的种子,用户可以获得可重复的结果,并在多次生成中保持一致性。
Control_after_generation: 这个参数决定了每次生成后种子值的变化方式。它可以设置为随机(每次运行生成一个新的随机种子)、递增(将种子值增加1)、递减(将种子值减少1)或固定(保持种子值不变)。
Step: 采样步数决定了细化过程的强度。较高的值会产生较少的伪影和更详细的图像,但也会增加生成时间。
Sampler_name: 这个参数允许用户选择KSampler使用的特定采样算法。不同的采样算法可能会产生略有不同的结果,并具有不同的生成速度。
Scheduler: 调度器控制每一步去噪过程中噪声水平的变化。它决定了从潜在表示中去除噪声的速率。
Denoise: 去噪参数设置去噪过程应该消除的初始噪声量。值为1意味着所有噪声将被去除,从而产生一个干净和详细的图像。
通过调整这些参数,你可以微调图像生成过程,以达到预期的结果。
现在,你准备好开始ComfyUI之旅了吗?#
在RunComfy,我们专门为你创建了终极ComfyUI在线体验。告别复杂的安装! 🎉 现在试试ComfyUI在线版,释放你前所未有的艺术潜力!** 🎉
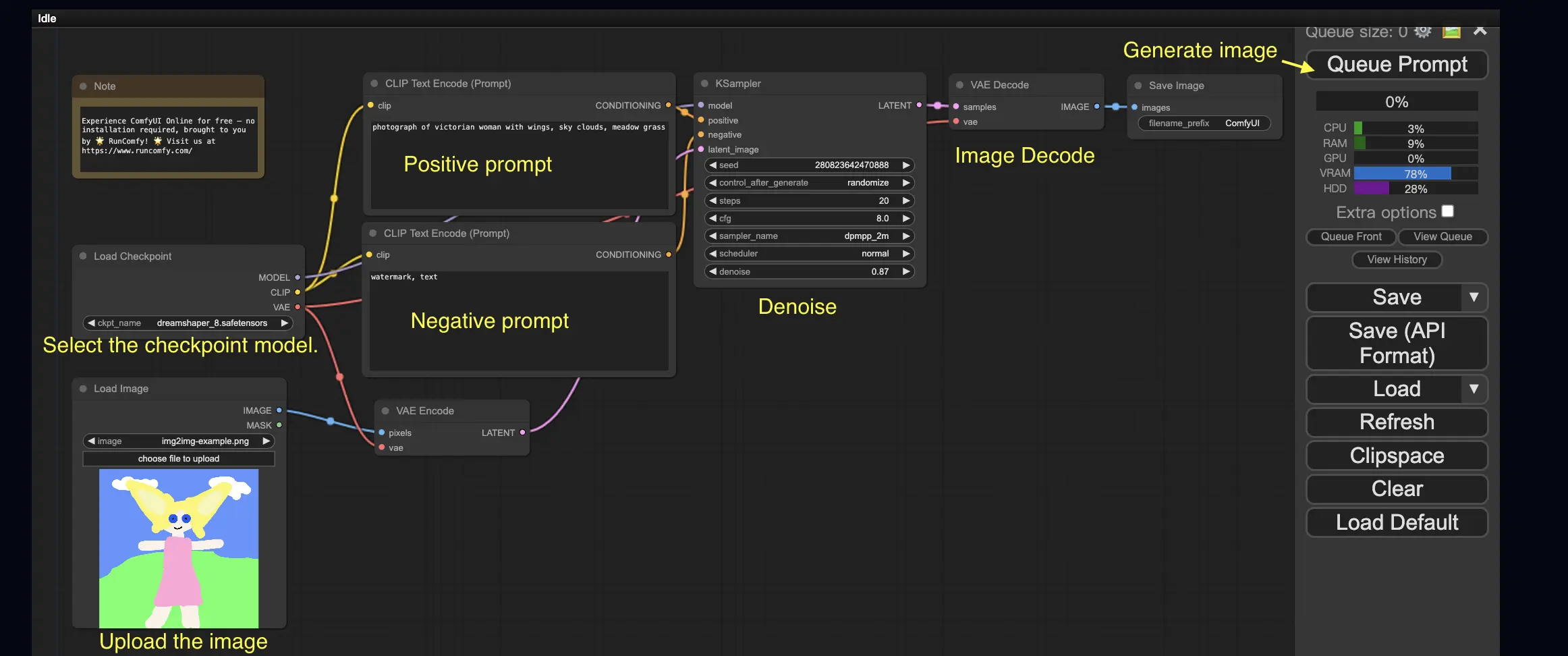
3. ComfyUI工作流: 从图像到图像 🖼️#
从图像到图像工作流根据提示词和输入图像生成图像。自己试试吧!
使用从图像到图像工作流:
- 选择Checkpoint模型。
- 上传图像作为图像提示。
- 修改正面和负面提示词。
- 可选地在KSampler节点中调整denoise(去噪强度)。
- 按Queue Prompt开始生成。
更多高级ComfyUI工作流,请访问我们的🌟ComfyUI工作流列表🌟
4. ComfyUI SDXL 🚀#
得益于其极端的可配置性,ComfyUI是首批支持Stable Diffusion XL模型的GUI之一。让我们试一试吧!
使用ComfyUI SDXL工作流:
- 修改正面和负面提示词。
- 按Queue Prompt开始生成。
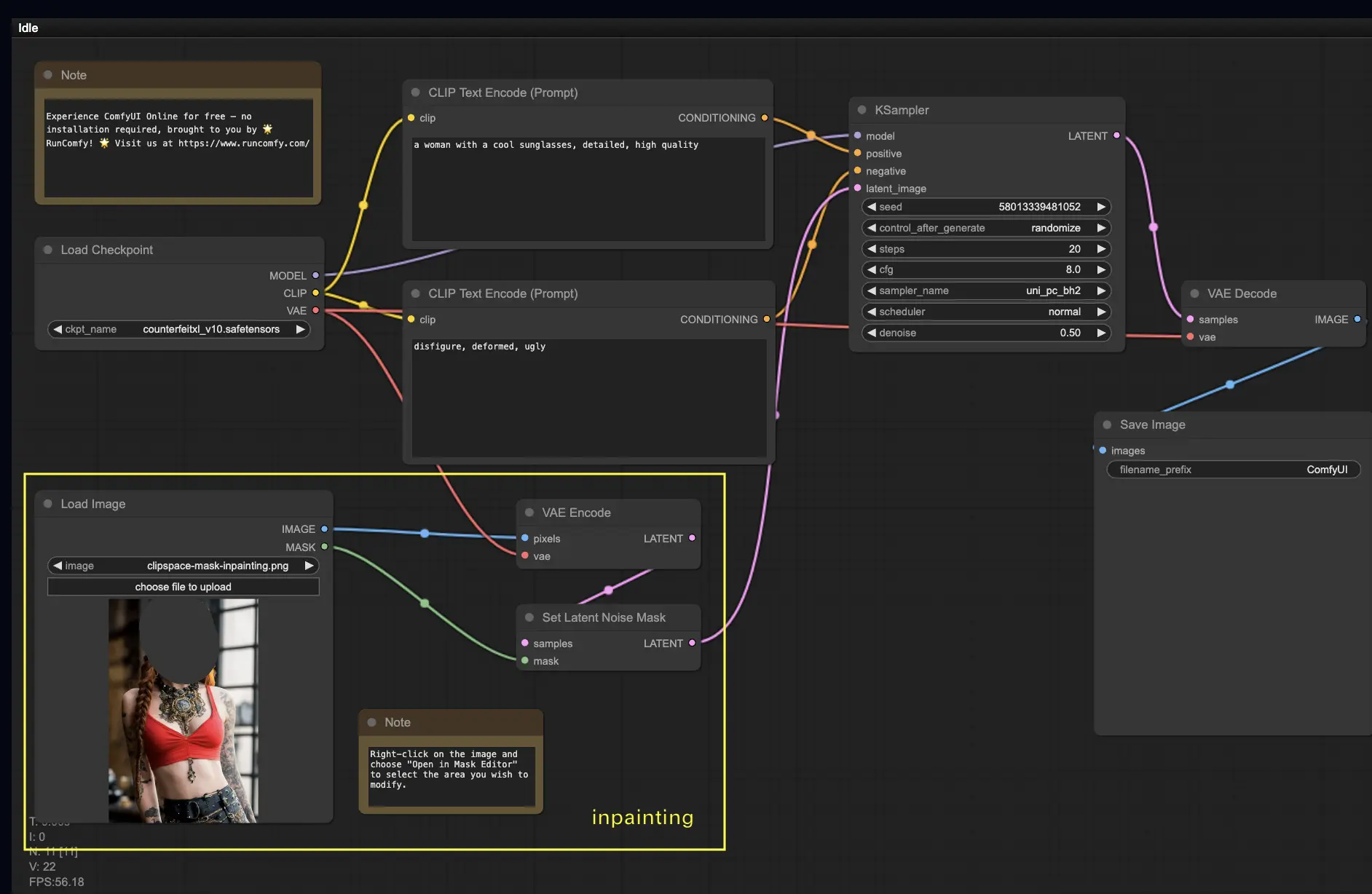
5. ComfyUI Inpainting 🎨#
让我们深入一些更复杂的东西:inpainting!当你有一个很棒的图像,但想修改特定部分时,inpainting是最佳方法。在这里试试吧!
使用inpainting工作流:
- 上传你想要inpainting的图像。
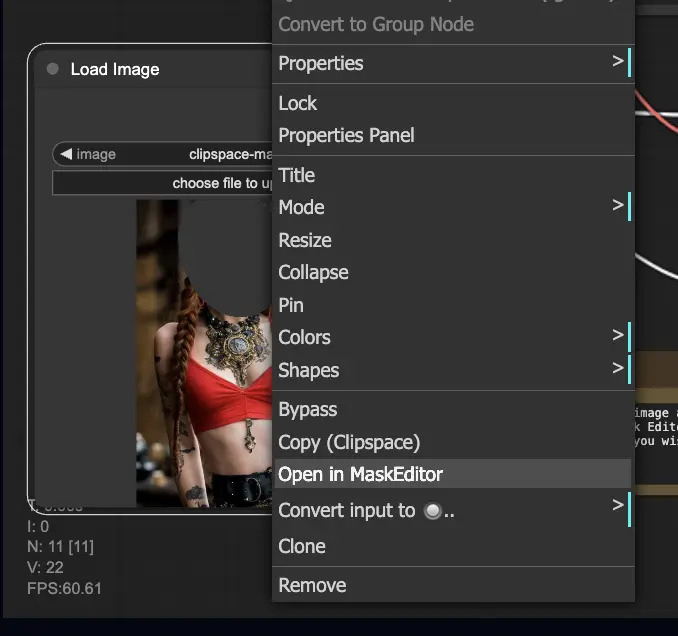
- 右键单击图像,选择"Open in MaskEditor"。在要重新生成的区域上绘制遮罩,然后单击"Save to node"。
- 选择一个Checkpoint模型:
- 这个工作流只适用于标准的Stable Diffusion模型,不适用于Inpainting模型。
- 如果你想利用inpainting模型,请将"VAE Encode"和"Set Noise Latent Mask"节点切换为专门为inpainting模型设计的"VAE Encode (Inpaint)"节点。
- 自定义inpainting过程:
- 在CLIP Text Encode (Prompt)节点中,你可以输入额外的信息来指导inpainting。例如,你可以指定你想在inpainting区域包含的风格、主题或元素。
- 设置原始去噪强度(denoise),例如0.6。
- 按Queue Prompt执行inpainting。
6. ComfyUI Outpainting 🖌️#
Outpainting是另一项令人兴奋的技术,让你可以将图像扩展到其原始边界之外。🌆 就像拥有一块无限的画布一样!
使用ComfyUI Outpainting工作流:
- 从你想要扩展的图像开始。
- 在你的工作流中使用Pad Image for Outpainting节点。
- 配置outpainting设置:
- left, top, right, bottom: 指定每个方向上要扩展的像素数。
- feathering: 调整原始图像和outpainting区域之间过渡的平滑度。较高的值会创建更渐进的混合,但可能会引入模糊效果。
- 自定义outpainting过程:
- 在CLIP Text Encode (Prompt)节点中,你可以输入额外的信息来指导outpainting。例如,你可以指定你想在扩展区域包含的风格、主题或元素。
- 尝试不同的提示词以获得理想的结果。
- 微调VAE Encode (for Inpainting)节点:
- 调整grow_mask_by参数以控制outpainting遮罩的大小。建议使用大于10的值以获得最佳结果。
- 按Queue Prompt开始outpainting过程。
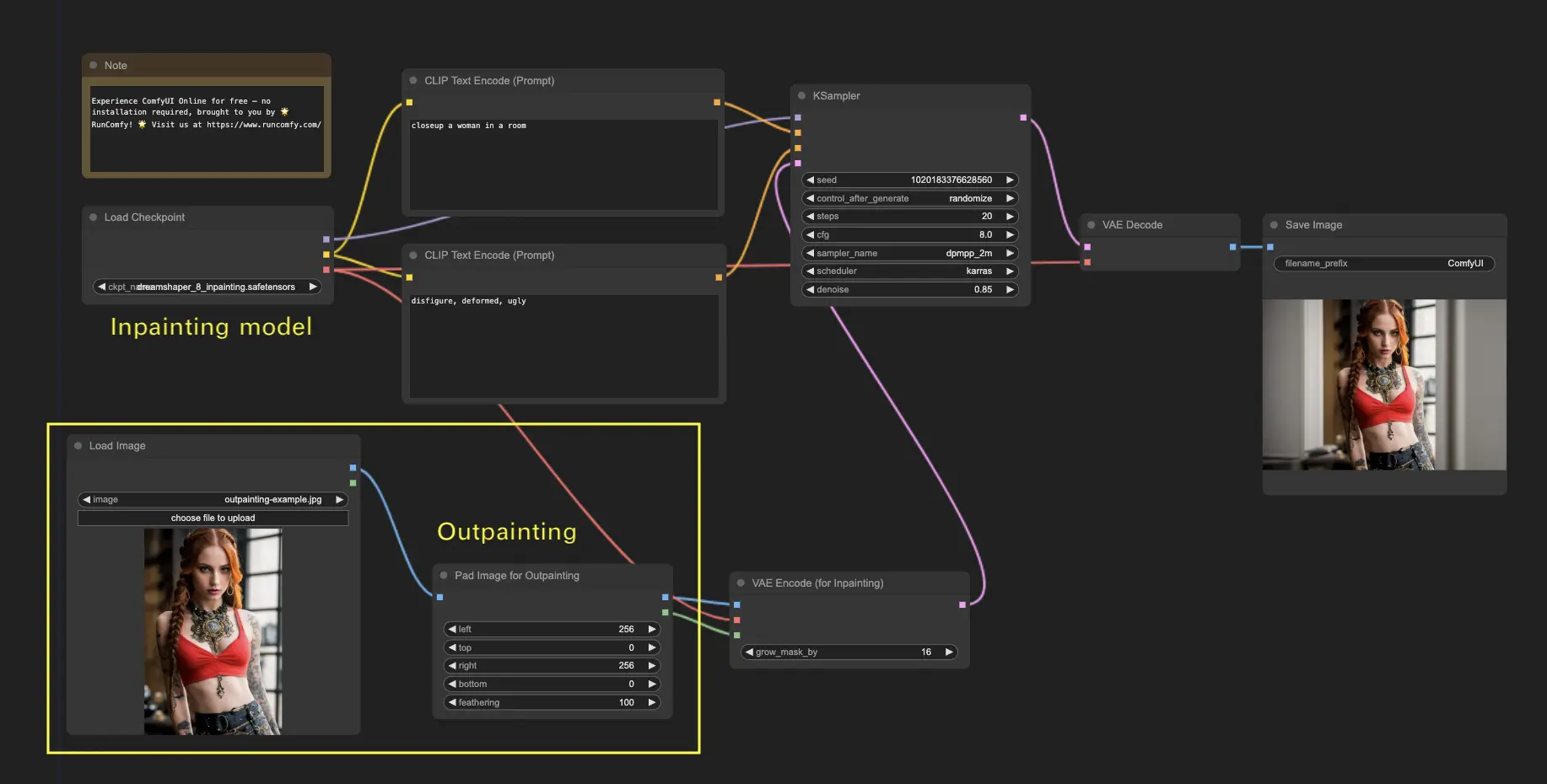
更多高级inpainting/outpainting工作流,请访问我们的🌟ComfyUI工作流列表🌟
7. ComfyUI Upscale ⬆️#
接下来,让我们探索ComfyUI放大。我们将介绍三个基本工作流,帮助你高效地放大。
有两种主要的放大方法:
- Upscale pixel: 直接放大可见图像。
- 输入:图像,输出:放大后的图像
- Upscale latent: 放大不可见的潜在空间图像。
- 输入:潜在空间,输出:放大后的潜在空间(需要解码成可见图像)
7.1. Upscale Pixel 🖼️#
两种实现方式:
- 使用算法:生成速度最快,但结果略逊于模型。
- 使用模型:结果更好,但生成时间更长。
7.1.1. 使用算法进行Upscale Pixel 🧮#
- 添加Upscale Image by节点。
- method参数:选择放大算法(bicubic, bilinear, nearest-exact)。
- Scale参数:指定放大因子(例如2表示2倍)。
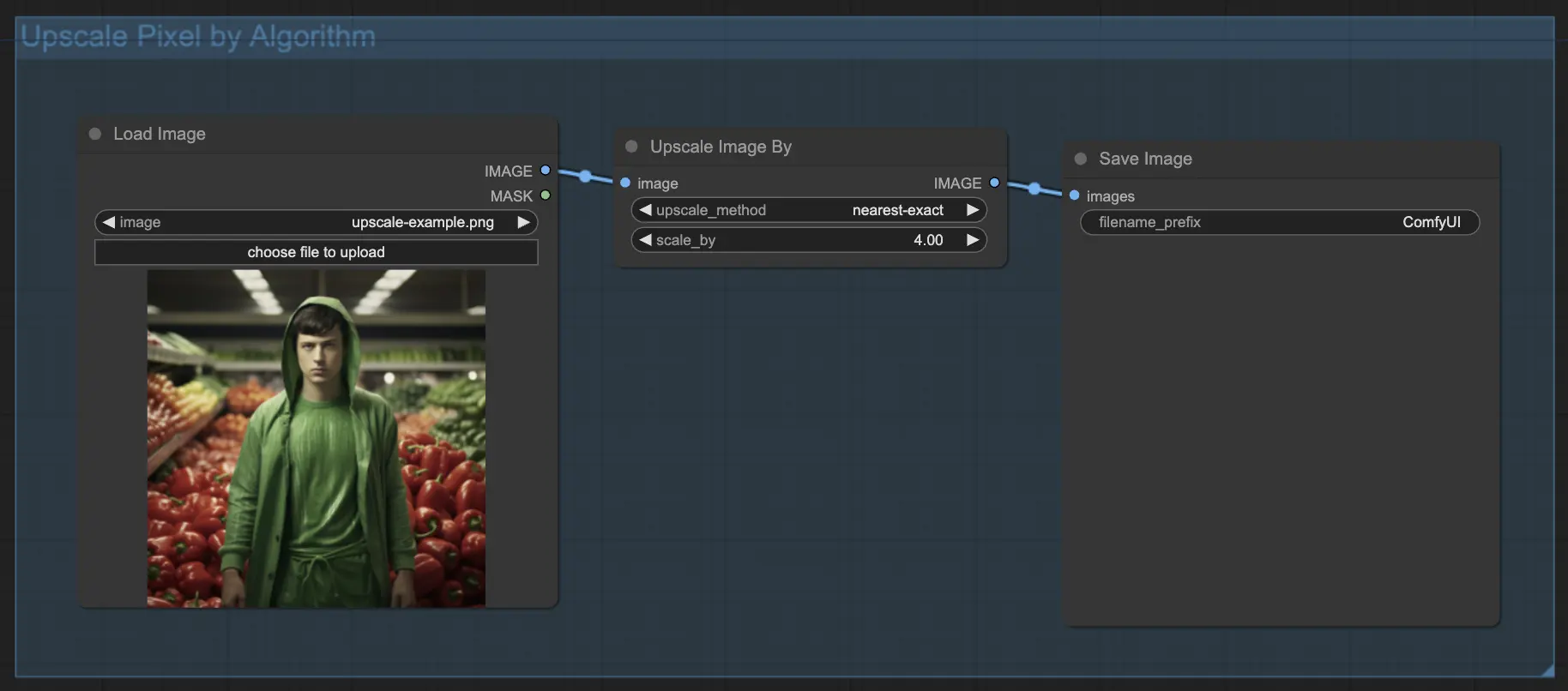
7.1.2. 使用模型进行Upscale Pixel 🤖#
- 添加Upscale Image (using Model)节点。
- 添加Load Upscale Model节点。
- 选择适合你图像类型的模型(例如动漫或真实)。
- 选择放大因子(X2或X4)。
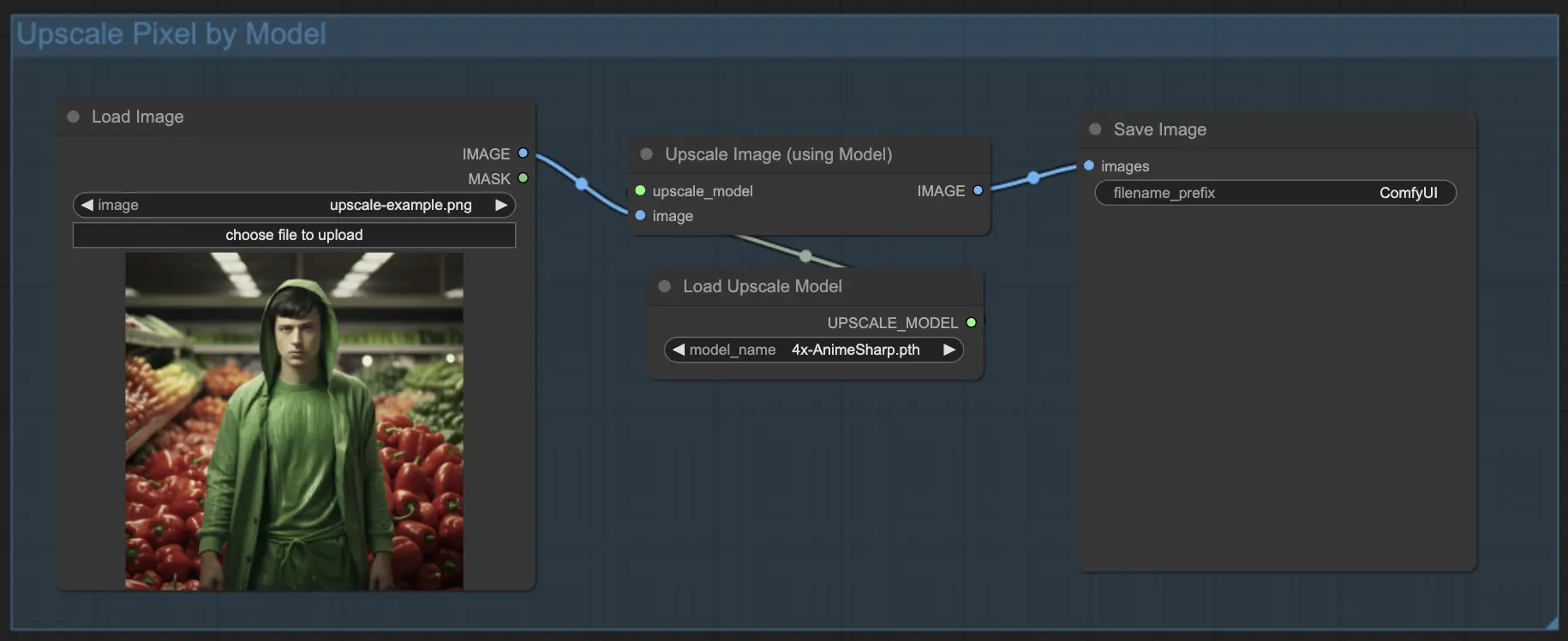
7.2. Upscale Latent ⚙️#
另一种放大方法是Upscale Latent,也称为Hi-res Latent Fix Upscale,直接在潜在空间中放大。
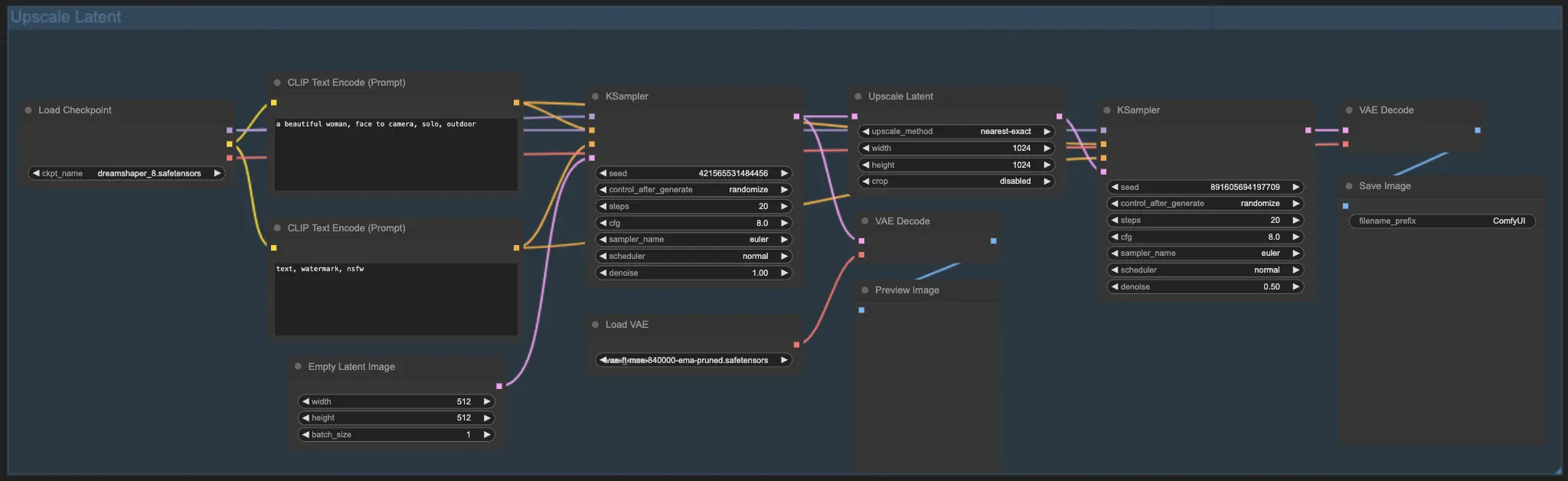
7.3. Upscale Pixel vs. Upscale Latent 🆚#
- Upscale Pixel: 只放大图像,不添加新信息。生成速度更快,但可能有模糊效果,缺乏细节。
- Upscale Latent: 除了放大,还改变一些原始图像信息,丰富细节。可能偏离原始图像,生成速度更慢。
更多高级还原/放大工作流,请访问我们的🌟ComfyUI工作流列表🌟
8. ComfyUI ControlNet 🎮#
准备好用ControlNet将你的AI艺术提升到新的水平吧,这是一项革命性的技术,它彻底改变了图像生成方式!
ControlNet就像一根魔杖🪄,赋予你前所未有的控制力,可以指导AI生成的图像。它与Stable Diffusion等强大的模型携手合作,增强它们的能力,让你比以往任何时候都更能引导图像创作过程!
想象一下,你可以指定图像的边缘、人体姿势、深度,甚至是分割图。🌠 有了ControlNet,你就可以做到这一切!
如果你渴望更深入地探索ControlNet的世界,释放它的全部潜力,我们为你准备了全面的内容。查看我们详细的ComfyUI中掌握ControlNet的教程吧!📚 它包含分步指南和令人振奋的示例,帮助你成为ControlNet专家。🏆
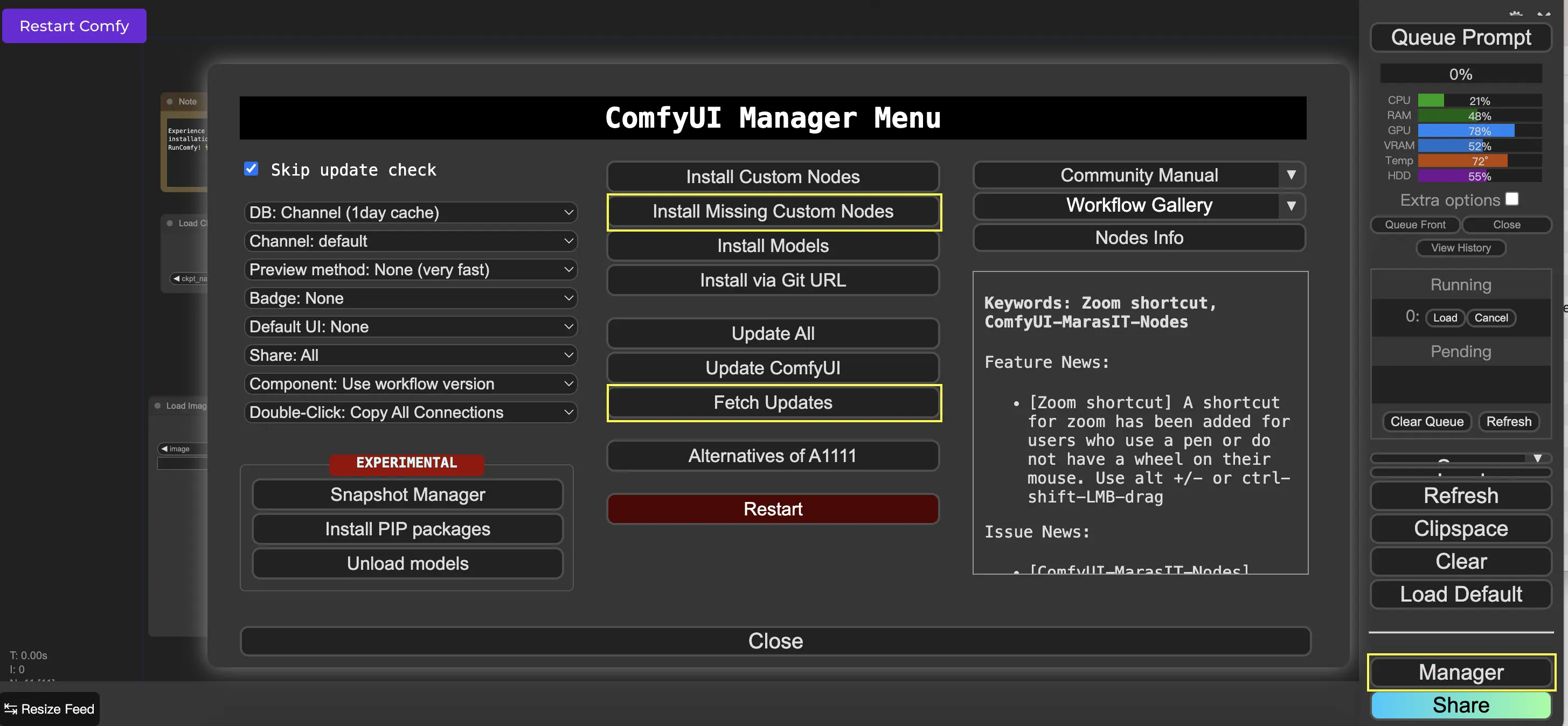
9. ComfyUI管理器 🛠️#
ComfyUI管理器是一个自定义节点,允许你通过ComfyUI界面安装和更新其他自定义节点。你可以在Queue Prompt菜单上找到Manager按钮。
9.1. 如何安装缺失的自定义节点 📥#
如果一个工作流需要你尚未安装的自定义节点,请按照以下步骤操作:
- 在菜单中点击Manager。
- 点击Install Missing Custom Nodes。
- 完全重启ComfyUI。
- 刷新浏览器。
9.2. 如何更新自定义节点 🔄#
- 在菜单中点击Manager。
- 点击Fetch Updates(可能需要一段时间)。
- 点击Install Custom Nodes。
- 如果有可用的更新,已安装的自定义节点旁边会出现一个Update按钮。
- 点击Update以更新节点。
- 重启ComfyUI。
- 刷新浏览器。
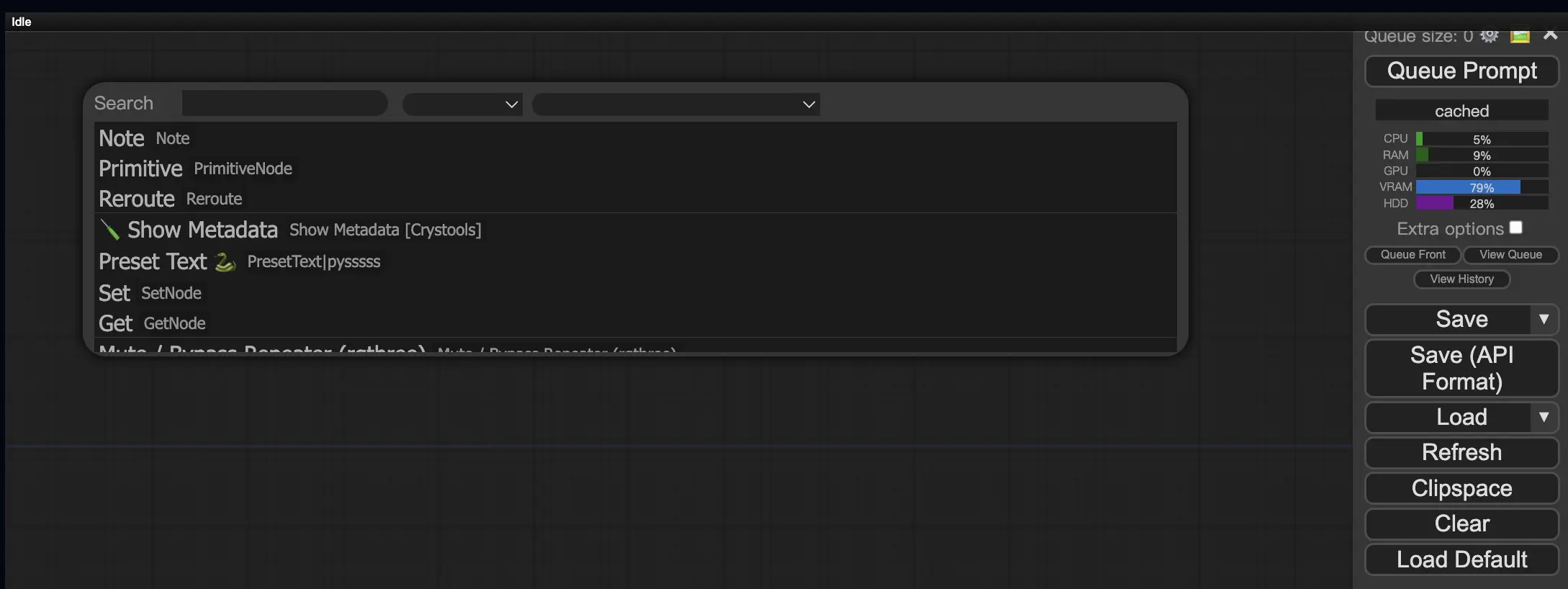
9.3. 如何在工作流中加载自定义节点 🔍#
双击任意空白区域,弹出菜单搜索节点。
10. ComfyUI Embeddings 📝#
Embeddings,也称为textual inversion,是ComfyUI中一项强大的功能,让你可以将自定义概念或风格注入到AI生成的图像中。💡 这就像教AI一个新词或短语,并将其与特定的视觉特征关联起来。
要在ComfyUI中使用embeddings,只需在正面或负面提示词框中输入"embedding:",后跟你的embedding名称。例如:
embedding: BadDream
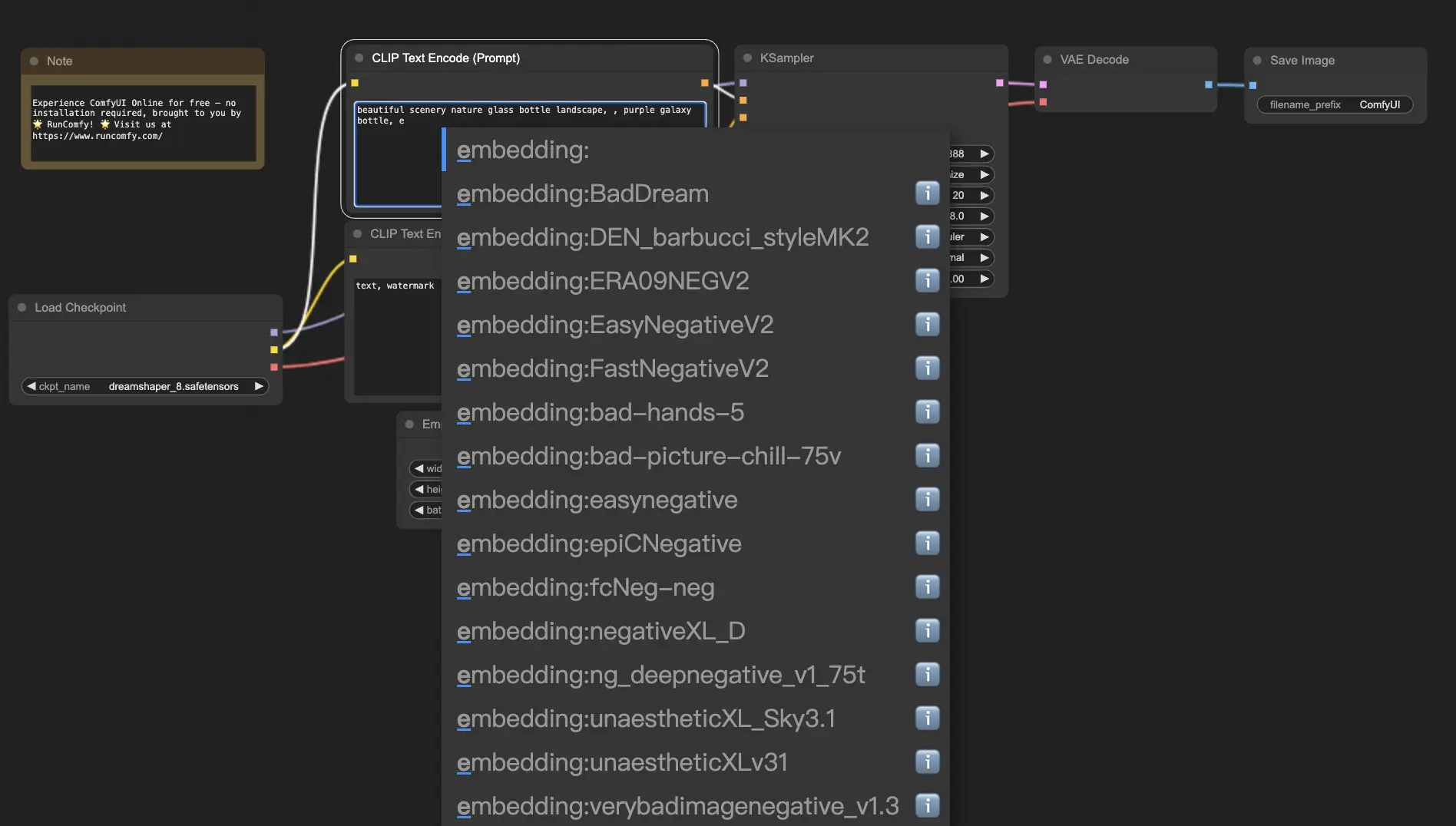
当你使用这个提示词时,ComfyUI会在ComfyUI > models > embeddings文件夹中搜索名为"BadDream"的embedding文件。📂 如果找到匹配项,它将把相应的视觉特征应用到你生成的图像中。
Embeddings是个性化AI艺术和实现特定风格或美学的好方法。🎨 你可以通过在一组代表所需概念或风格的图像上训练embeddings来创建自己的embeddings。
10.1. 带自动补全的Embedding 🔠#
记住你的embeddings的确切名称可能很麻烦,尤其是当你有大量embeddings时。😅 这时ComfyUI-Custom-Scripts自定义节点就派上用场了!
要启用embedding名称自动补全:
- 通过单击顶部菜单中的"Manager"打开ComfyUI管理器。
- 转到"Install Custom nodes",搜索"ComfyUI-Custom-Scripts"。
- 单击"Install"将自定义节点添加到你的ComfyUI设置中。
- 重启ComfyUI以应用更改。
安装ComfyUI-Custom-Scripts节点后,你将体验到更加用户友好的embeddings使用方式。😊 只需在提示词框中开始输入"embedding:",就会出现可用embeddings的列表。然后,你可以从列表中选择所需的embedding,节省你的时间和精力!
10.2. Embedding权重 ⚖️#
你知道你可以控制embeddings的强度吗?💪 由于embeddings本质上是关键词,你可以像对提示词中的普通关键词一样对它们应用权重。
要调整embedding的权重,使用以下语法:
(embedding: BadDream:1.2)
在这个例子中,"BadDream" embedding的权重增加了20%。因此,较高的权重(例如1.2)会使embedding更突出,而较低的权重(例如0.8)会减少其影响。🎚️ 这让你对最终结果有更多的控制!
11. ComfyUI LoRA 🧩#
LoRA,即低秩适应(Low-rank Adaptation),是ComfyUI中另一个令人兴奋的功能,让你可以修改和微调checkpoint模型。🎨 它就像在基础模型之上添加一个小型专门模型,以实现特定的风格或融入自定义元素。
LoRA模型紧凑高效,易于使用和共享。它们通常用于修改图像的艺术风格或将特定人物或物体注入生成结果的任务。
当你将LoRA模型应用于checkpoint模型时,它会修改MODEL和CLIP组件,同时保持VAE(Variational Autoencoder)不变。这意味着LoRA专注于调整图像的内容和风格,而不改变其整体结构。
11.1. 如何使用LoRA 🔧#
在ComfyUI中使用LoRA很简单。让我们看看最简单的方法:
- 选择一个checkpoint模型作为图像生成的基础。
- 选择一个LoRA模型,用于修改风格或注入特定元素。
- 修改正面和负面提示词,指导图像生成过程。
- 单击"Queue Prompt"开始生成应用了LoRA的图像。▶
ComfyUI将结合checkpoint模型和LoRA模型,创建一个反映指定提示词并融入LoRA引入的修改的图像。
11.2. 多个LoRA 🧩🧩#
但如果你想在一个图像上应用多个LoRA呢?没问题!ComfyUI允许你在同一个从文本到图像的工作流中使用两个或多个LoRA。
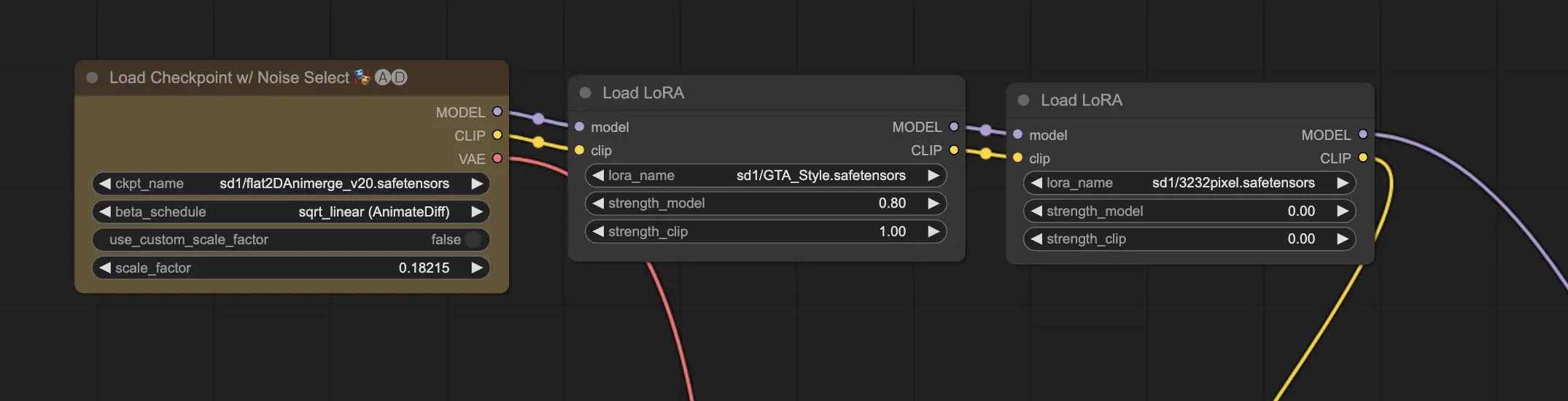
过程与使用单个LoRA类似,但你需要选择多个LoRA模型,而不是只选择一个。ComfyUI将按顺序应用LoRA,这意味着每个LoRA将在前一个的修改基础上进行修改。
这为在AI生成的图像中组合不同的风格、元素和修改打开了一个充满可能性的世界。🌍💡 尝试不同的LoRA组合,以实现独特和创造性的结果!
12. ComfyUI的快捷方式和技巧 ⌨️🖱️#
12.1. 复制和粘贴 📋#
- 选择一个节点,按Ctrl+C复制。
- 按Ctrl+V粘贴。
- 按Ctrl+Shift+V粘贴,保持输入连接不变。
12.2. 移动多个节点 🖱️#
- 创建一个组,将一组节点一起移动。
- 或者,按住Ctrl并拖动以创建一个框来选择多个节点,或按住Ctrl单独选择多个节点。
- 要移动选定的节点,按住Shift并移动鼠标。
12.3. 绕过一个节点 🔇#
- 通过将节点静音来暂时禁用它。选择一个节点,按Ctrl+M。
- 没有静音组的键盘快捷键。在右键菜单中选择Bypass Group Node,或静音组中的第一个节点以禁用它。
12.4. 最小化一个节点 🔍#
- 单击节点左上角的点以最小化它。
12.5. 生成图像 ▶️#
- 按Ctrl+Enter将工作流放入队列并生成图像。
12.6. 嵌入式工作流 🖼️#
- ComfyUI将整个工作流保存在它生成的PNG文件的元数据中。要加载工作流,将图像拖放到ComfyUI中。
12.7. 固定种子以节省时间 ⏰#
- ComfyUI只在输入改变时重新运行节点。处理一长串节点时,通过固定种子来避免重新生成上游结果,从而节省时间。
13. 在线使用ComfyUI 🚀#
恭喜你完成了这份ComfyUI初学者指南!🙌 你现在已经准备好潜入令人兴奋的AI艺术创作世界了。但当你可以立即开始创作时,为什么还要费心安装呢?🤔
在RunComfy,我们让你无需任何设置就可以在线使用ComfyUI。我们的ComfyUI在线服务预装了200多个流行的节点和模型,以及50多个令人惊叹的工作流来激发你的创作灵感。🌟
🌟 无论你是初学者还是有经验的AI艺术家,RunComfy都提供了你将艺术愿景变为现实所需的一切。💡 不要再等了–立即尝试ComfyUI在线版,感受指尖上AI艺术创作的力量!🚀