
The ComfyUI-CogVideoXWrapper nodes and its associated workflow are fully developed by Kijai. We give all due credit to Kijai for this innovative work. On the RunComfy platform, we are simply presenting Kijai’s contributions to the community. It is important to note that there is currently no formal connection or partnership between RunComfy and Kijai. We deeply appreciate Kijai’s work!
CogVideoX Tora#
Tora introduces a novel framework for generating high-quality videos by leveraging trajectory-based guidance in a diffusion transformer model. By focusing on motion trajectories, Tora achieves more realistic and temporally coherent video synthesis. This approach bridges the gap between spatial-temporal modeling and generative diffusion frameworks.
Please note that this version of Tora is based on the CogVideoX-5B model and is intended for academic research purposes only. For licensing details, please refer here.
1.1 How to Use CogVideoX Tora Workflow?#
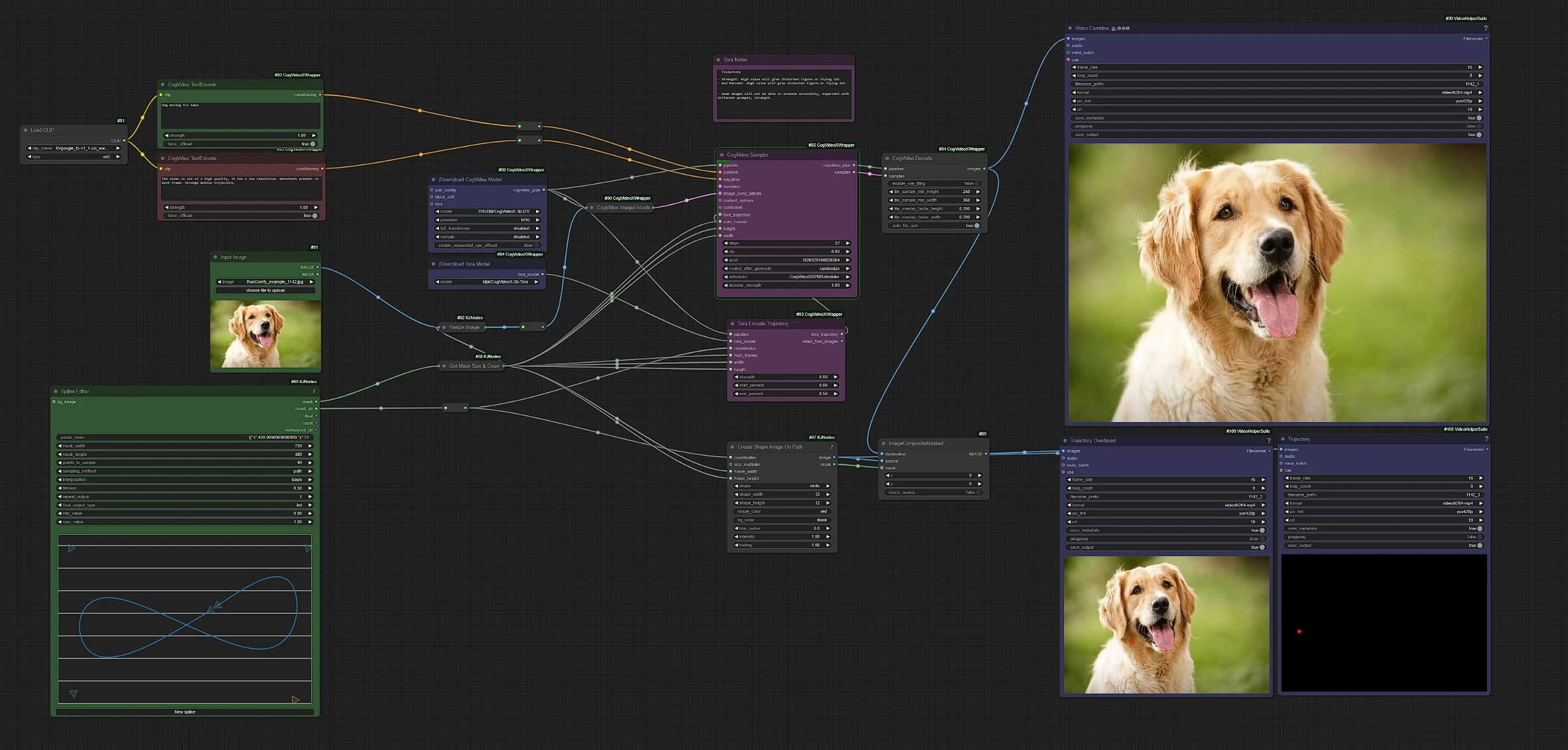
This is the CogVideoX Tora workflow, Left Side nodes are inputs, Middle are processing tora nodes, and right are the outputs node.
- Drag and drop your horizontal image in the input node.
- Write your action prompts
- Make a trajectory path
1.2 Load Input Image#
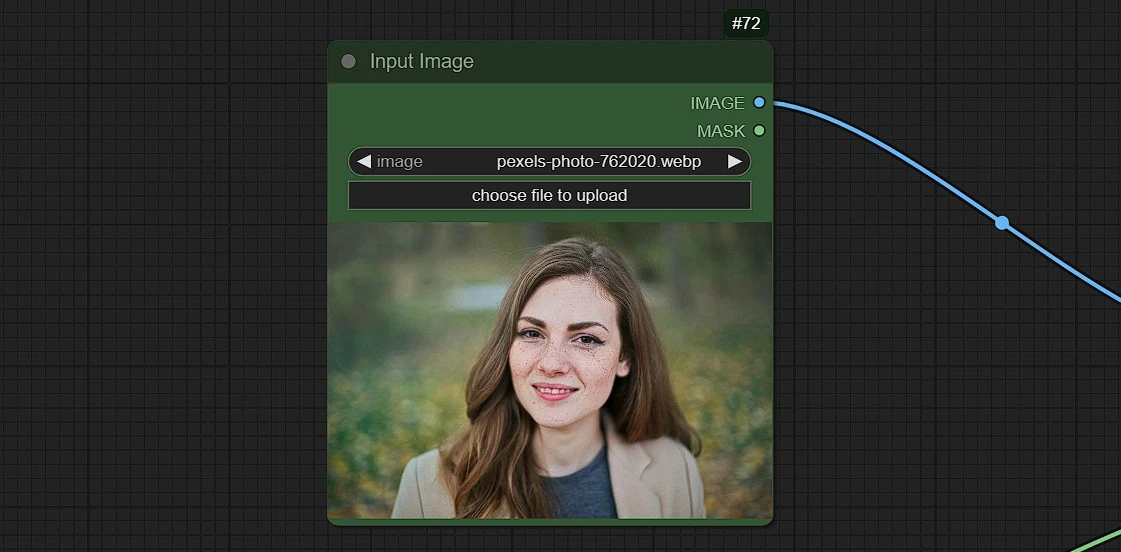
- Upload, Drag and drop or Copy and Paste (Ctrl+V) your image in the load image node
[!CAUTION] Only Horizontal Format Images of Dimensions - 720*480 will work. Other Dimensions will give error.
1.3 Add Your Positive and Negative Prompts#
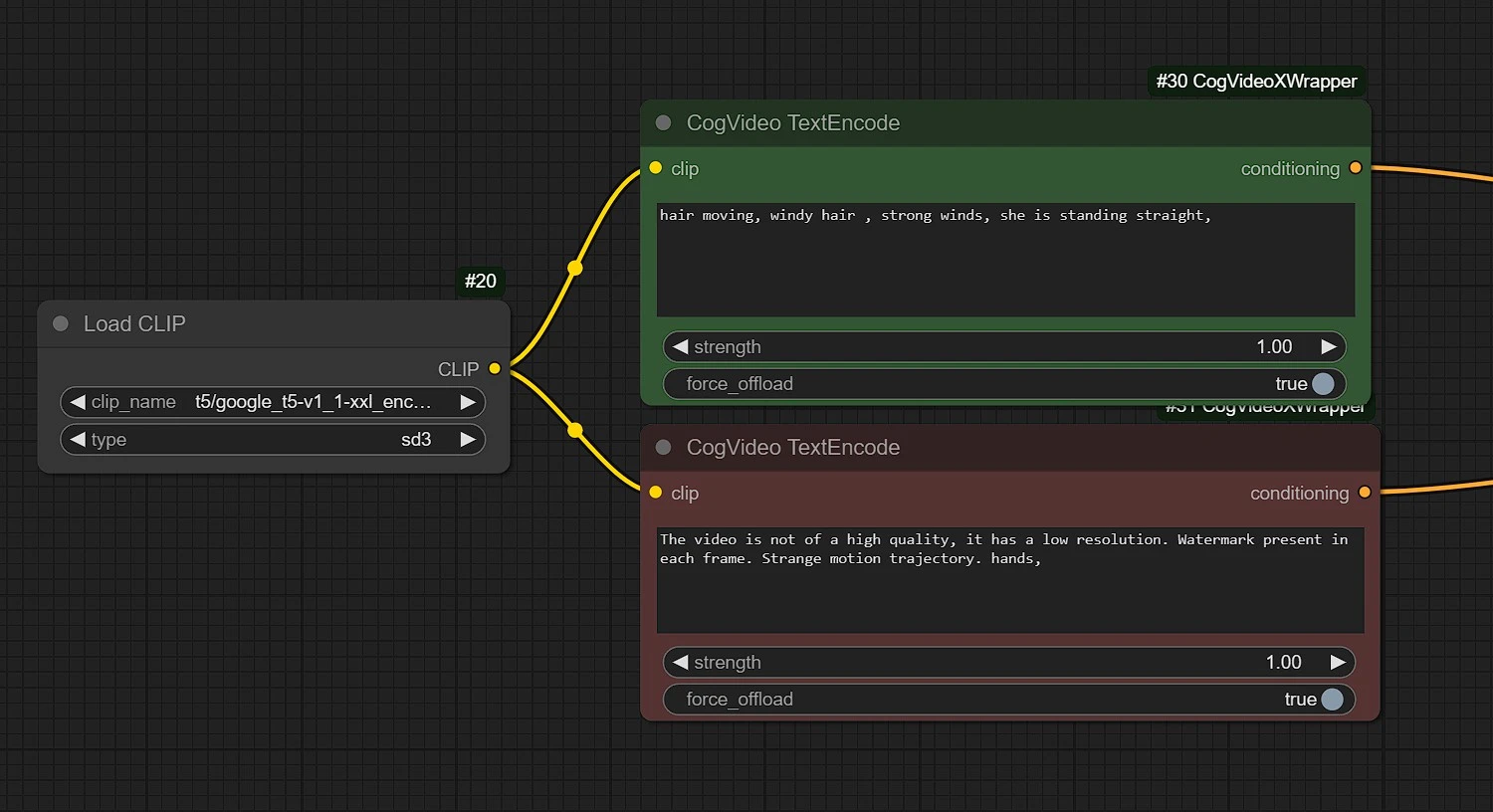
Positive: Enter the actions taking place with the Subject based of Trajectory defined in the trajectory node (moving, flowing....etc).Negative: Enter what you don't want to happen (Distorted hands, blurry...etc)
1.4 Make Trajectory for motion#
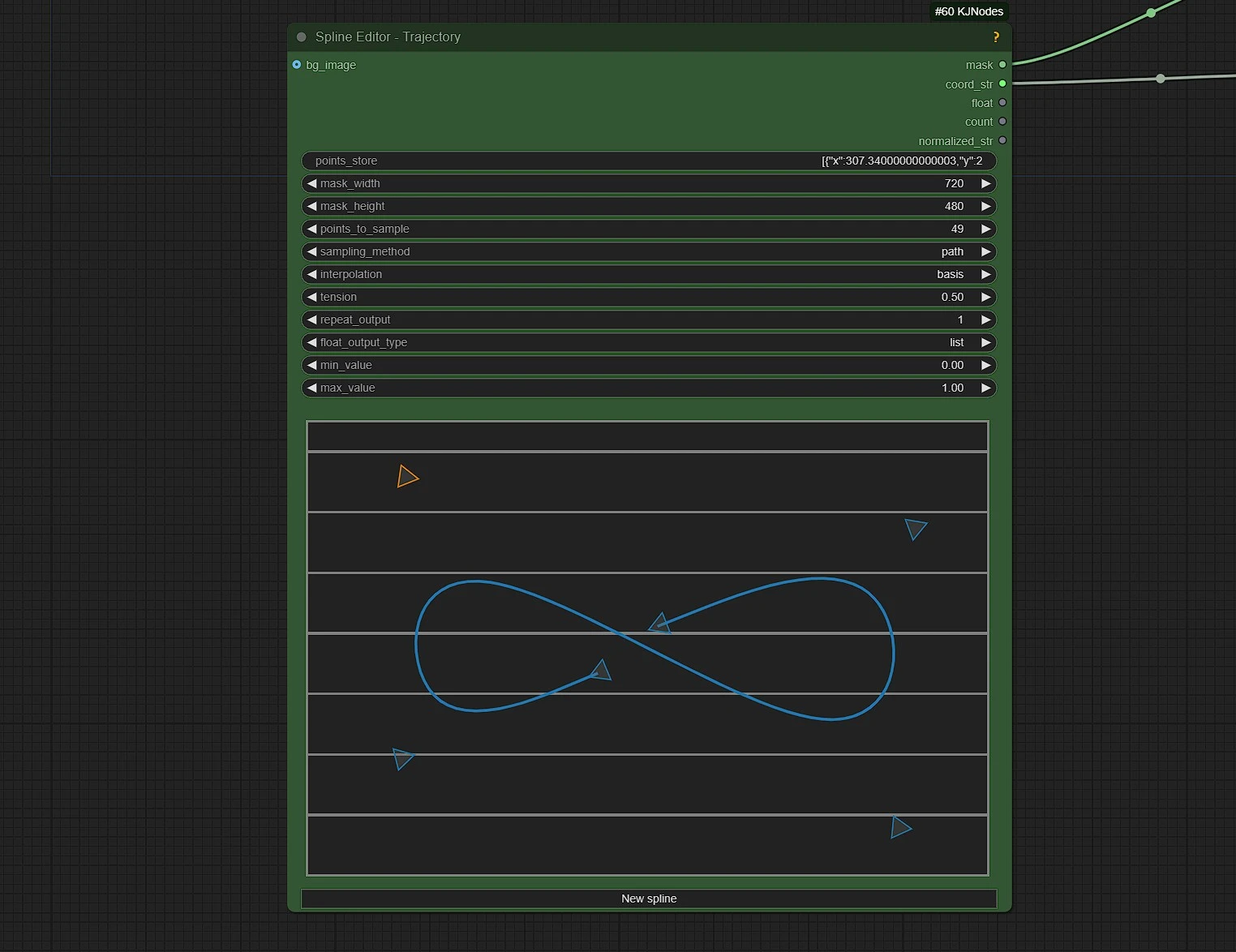
Here you set the Trajectory path of the motion of the subject in the uploaded photo.
points_to_sample: This Set the Number of frames for Rendering, or Duration of your video in frames.mask_width: Default is 720. DO NOT CHANGE!mask_height: Default is 480. DO NOT CHANGE!
Node Guide:
- Shift + click to add control point at end. Ctrl + click to add control point (subdivide) between two points.
- Right click on a point to delete it.
- Note that you can't delete from start/end.
- Right click on canvas for context menu:
- These are purely visual options, doesn't affect the output:
Toggle handles visibility
- Display sample points: display the points to be returned.
- points_to_sample value sets the number of samples
- returned from the drawn spline itself, this is independent from the
- actual control points, so the interpolation type matters.
Sampling_method:
- time: samples along the time axis, used for schedules
- path: samples along the path itself, useful for coordinates
1.5 Load CogVideoX & Tora Models#
These are the model downloader nodes, it will automatically download models in your comfyui in 2-3 mins.
1.6 CogVideo Sampler#
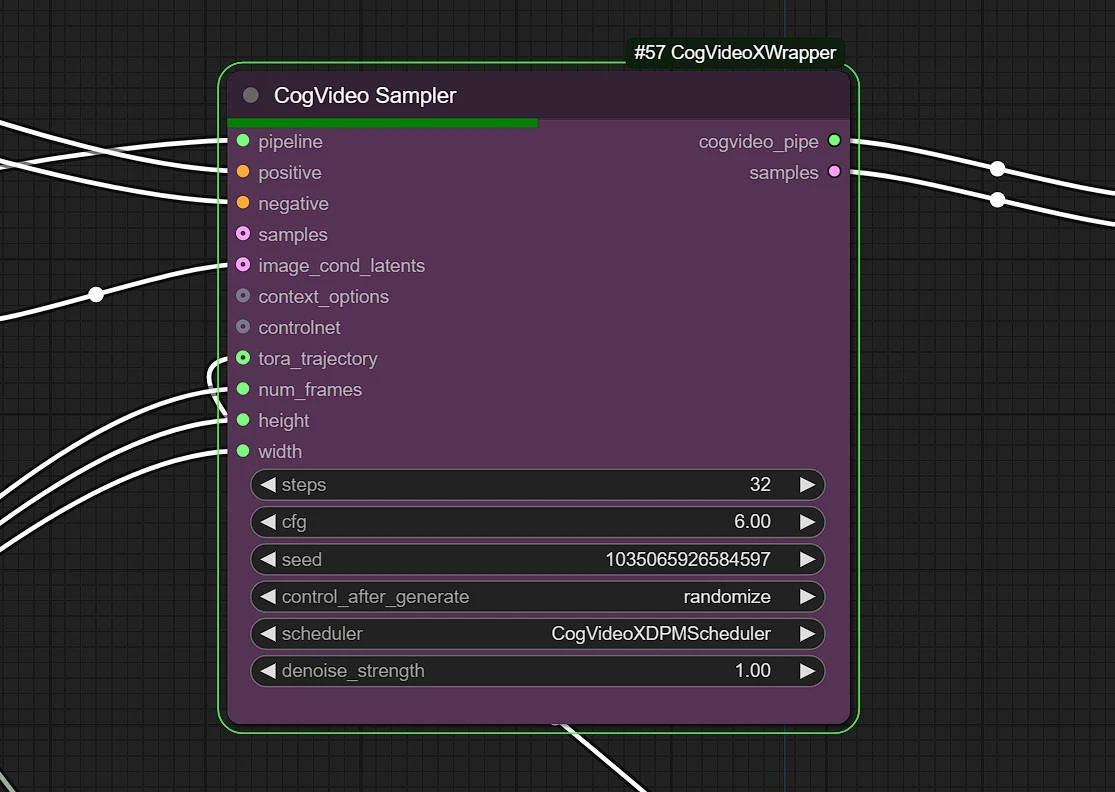
Steps: This value decides the quality of your render. Keep in between 25 - 35 for best and effcient value.cfg: Default value is 6.0 for CogVideo Sampling.denoising strengthandScheduler: Do not change this.
1.7 Trajectory Weights and Strength#
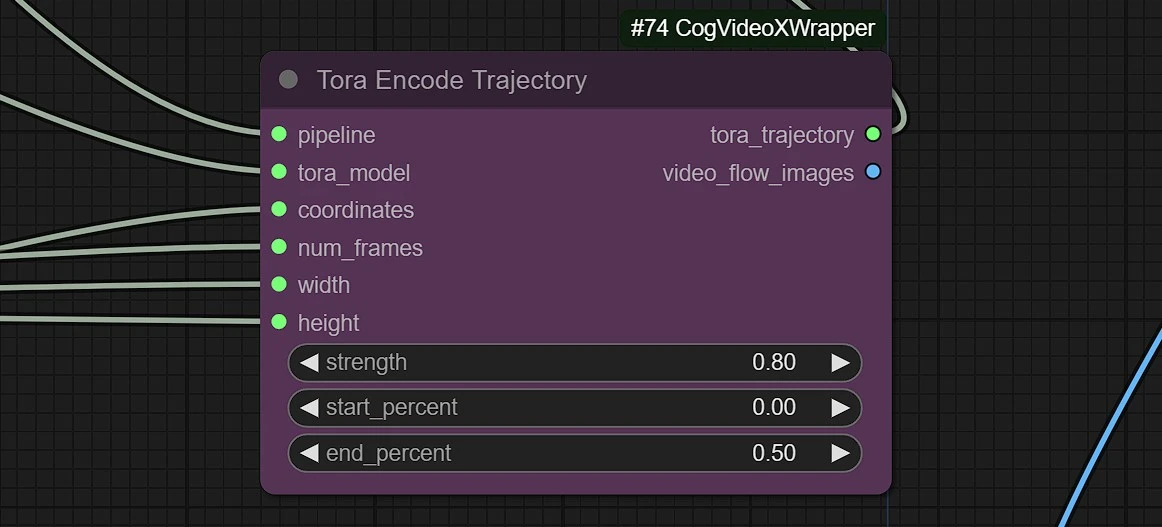
This node will set the strength of your motion trajectory.
strength: High value will give distorted figure or flying dot. Use between 0.5 - 0.9.start_percent: Use this value to ease in the effect of strength motion.end_percent: - High value will give distorted figure or flying dot. Use between 0.3 - 0.7
1.8 Outputs#
These nodes will give you 3 outputs.
- Output Rendered Video
- Trajectory path overlayed on rendered video
- Trajectory Video on black background
"CogVideoX Tora: Trajectory-oriented Diffusion Transformer for Video Generation" presents an innovative approach to video generation by introducing trajectory-based guidance within a diffusion transformer framework. Unlike traditional video synthesis models that struggle to maintain temporal consistency and realistic motion, CogVideoX Tora explicitly focuses on modeling motion trajectories. This enables the system to generate coherent and visually convincing videos by understanding how objects and elements evolve over time. By combining the power of diffusion models, known for high-quality image generation, with the temporal reasoning capabilities of transformers, CogVideoX Tora bridges the gap between spatial and temporal modeling.
CogVideoX Tora's trajectory-oriented mechanism provides fine-grained control over object movements and dynamic interactions, making it particularly suitable for applications requiring precise motion guidance, such as video editing, animation, and special effects generation. The model's ability to maintain temporal consistency and realistic transitions enhances its applicability in creating smooth and coherent video content. By integrating trajectory priors, CogVideoX Tora not only improves motion dynamics but also reduces artifacts often seen in frame-based generation. This breakthrough sets a new benchmark for video synthesis, offering a powerful tool for creators and developers in fields like filmmaking, virtual reality, and video-based AI.

