
Hunyuan video, an open-source AI model developed by Tencent, allows you to generate stunning and dynamic visuals with ease. The Hunyuan model harnesses advanced architecture and training techniques to understand and generate content of high quality, motion diversity, and stability.
About Hunyuan Video to Video Workflow
This Hunyuan Workflow in ComfyUI utilizes the Hunyuan model to create new visual content by combining input text prompts with an existing driving video. Leveraging the capabilities of the Hunyuan model, you can generate impressive video translations that seamlessly incorporate the motion and key elements from the driving video while aligning the output with your desired text prompt.
How to Use Hunyuan Video to Video Workflow
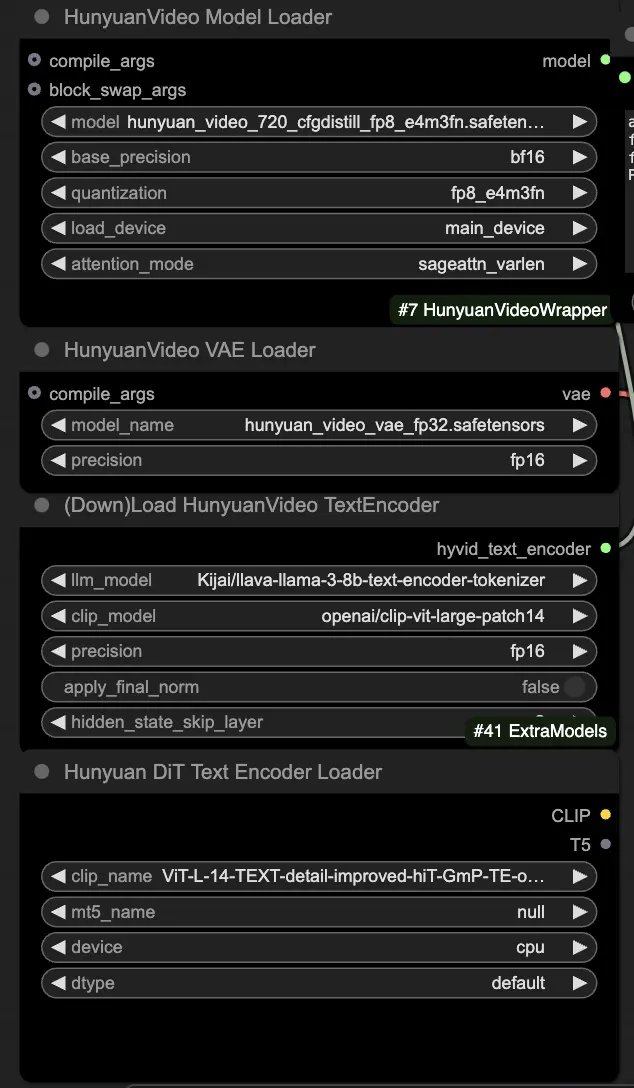
🟥 Step 1: Load Hunyuan Models
- Load the Hunyuan model by selecting the "hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors" file in the HyVideoModelLoader node. This is the main transformer model.
- The HunyuanVideo VAE model will be automatically downloaded in the HunyuanVideoVAELoader node. It is used for encoding/decoding video frames.
- Load a text encoder in the DownloadAndLoadHyVideoTextEncoder node. The workflow defaults to using the "Kijai/llava-llama-3-8b-text-encoder-tokenizer" LLM encoder and the "openai/clip-vit-large-patch14" CLIP encoder, which will be auto-downloaded. You can use other CLIP or T5 encoders that have worked with previous models as well.
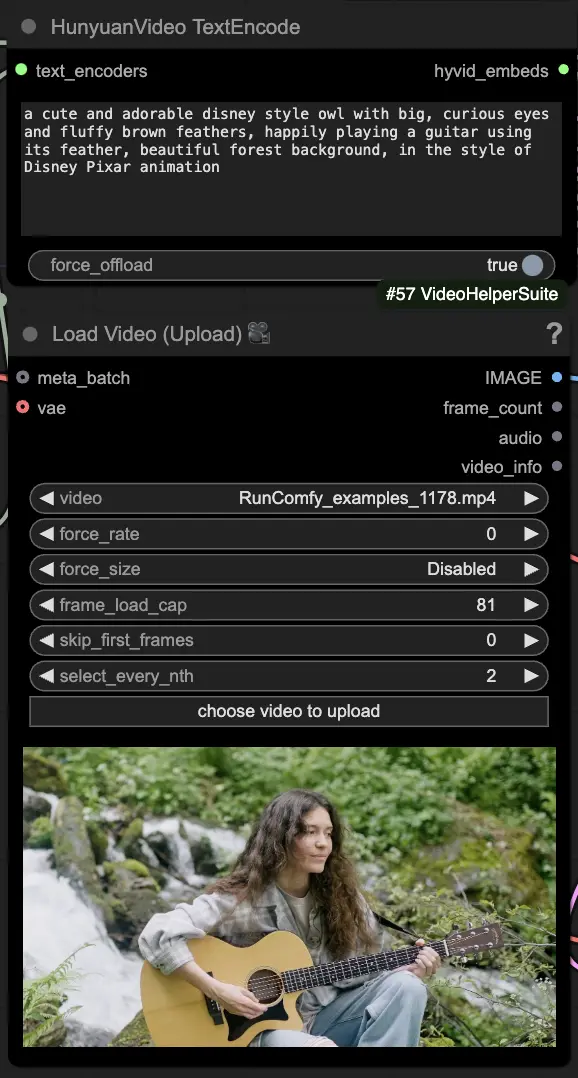
🟨 Step 2: Enter Prompt & Load Driving Video
- Enter your text prompt describing the visual you want to generate in the HyVideoTextEncode node.
- Load the driving video you want to use as the motion reference in the VHS_LoadVideo node.
- frame_load_cap: Number of frames to generate. When setting the number, you need to ensure that the number minus one is divisible by 4; otherwise, a ValueError will be triggered, indicating that the video length is invalid.
- skip_first_frames: Adjust this parameter to control which part of the video is used.
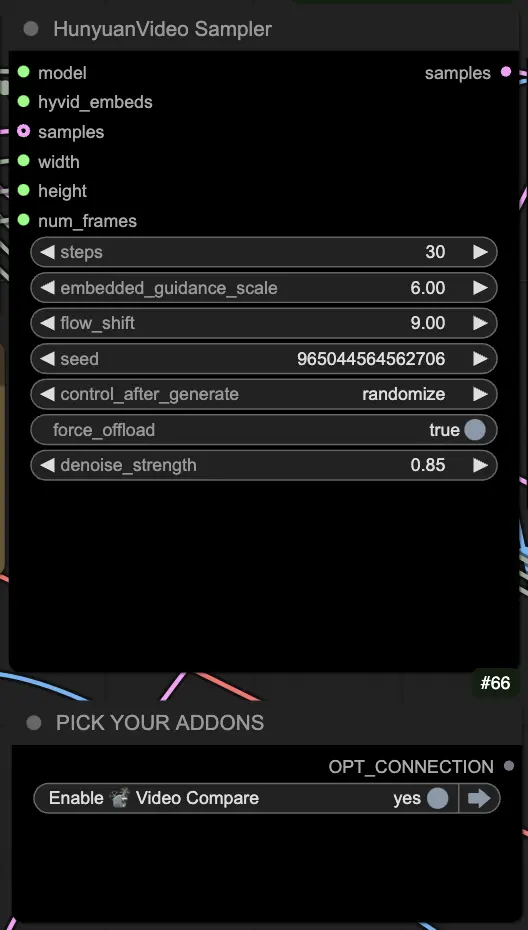
🟦 Step 3: Hunyuan Generation Settings
- In the HyVideoSampler node, configure the video generation hyperparameters:
- Steps: Number of diffusion steps per frame, higher means better quality but slower generation. Default 30.
- Embedded_guidance_scale: How much to adhere to the prompt, higher values stick closer to prompt.
- Denoise_strength: Controls strength of using the init driving video. Lower values (e.g. 0.6) make output look more like init.
- Pick addons and toggles in the "Fast Groups Bypasser" node to enable/disable extra features like the comparison video.
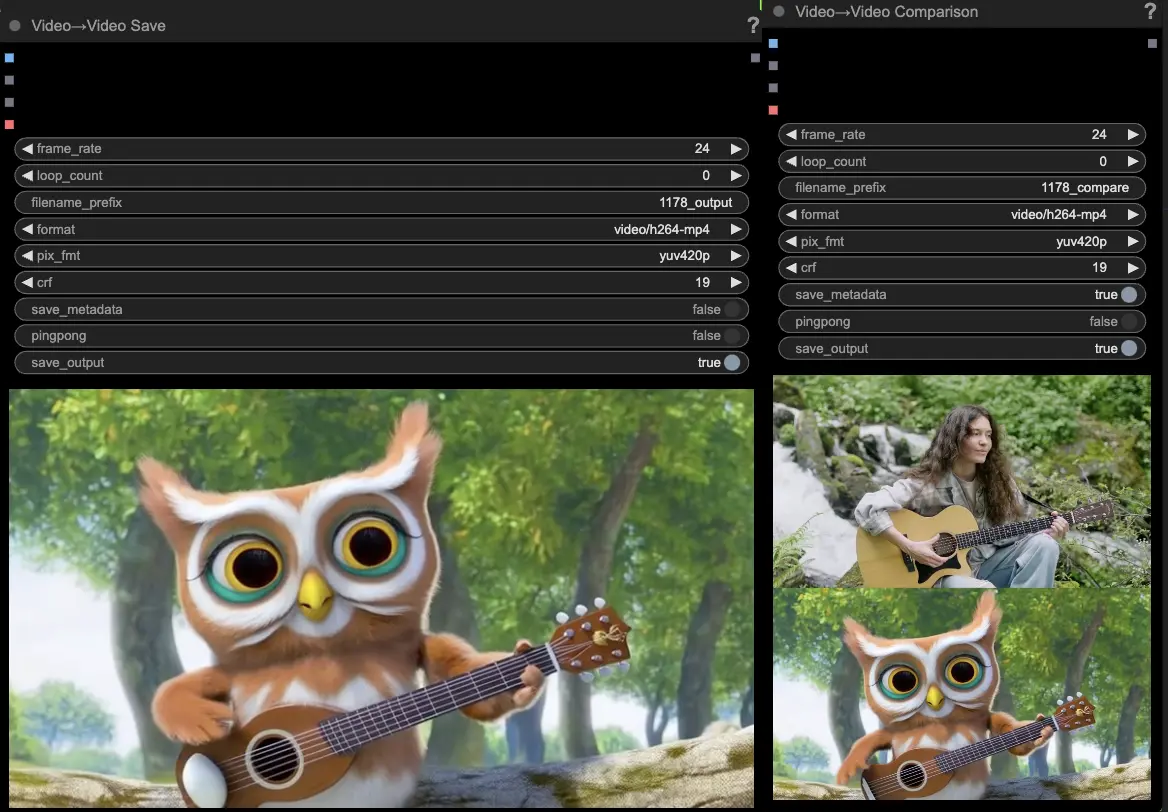
🟩 Step 4: Generate Huanyuan Video
- The VideoCombine nodes will generate and save two outputs by default:
- The translated video result
- A comparison video showing the driving video and the generated result
Tweaking the prompt and generation settings allows for impressive flexibility in creating new videos driven by the motion of an existing video using the Hunyuan model. Have fun exploring the creative possibilities of this Hunyuan workflow!
This Hunyuan workflow was designed by Black Mixture. Please visit Black Mixture's youtube channel for more information. Also Special thanks to Kijai for the Hunyuan wrappers nodes and workflow examples.