AnimateDiff + ControlNet + IPAdapter V1 | Cartoon Style
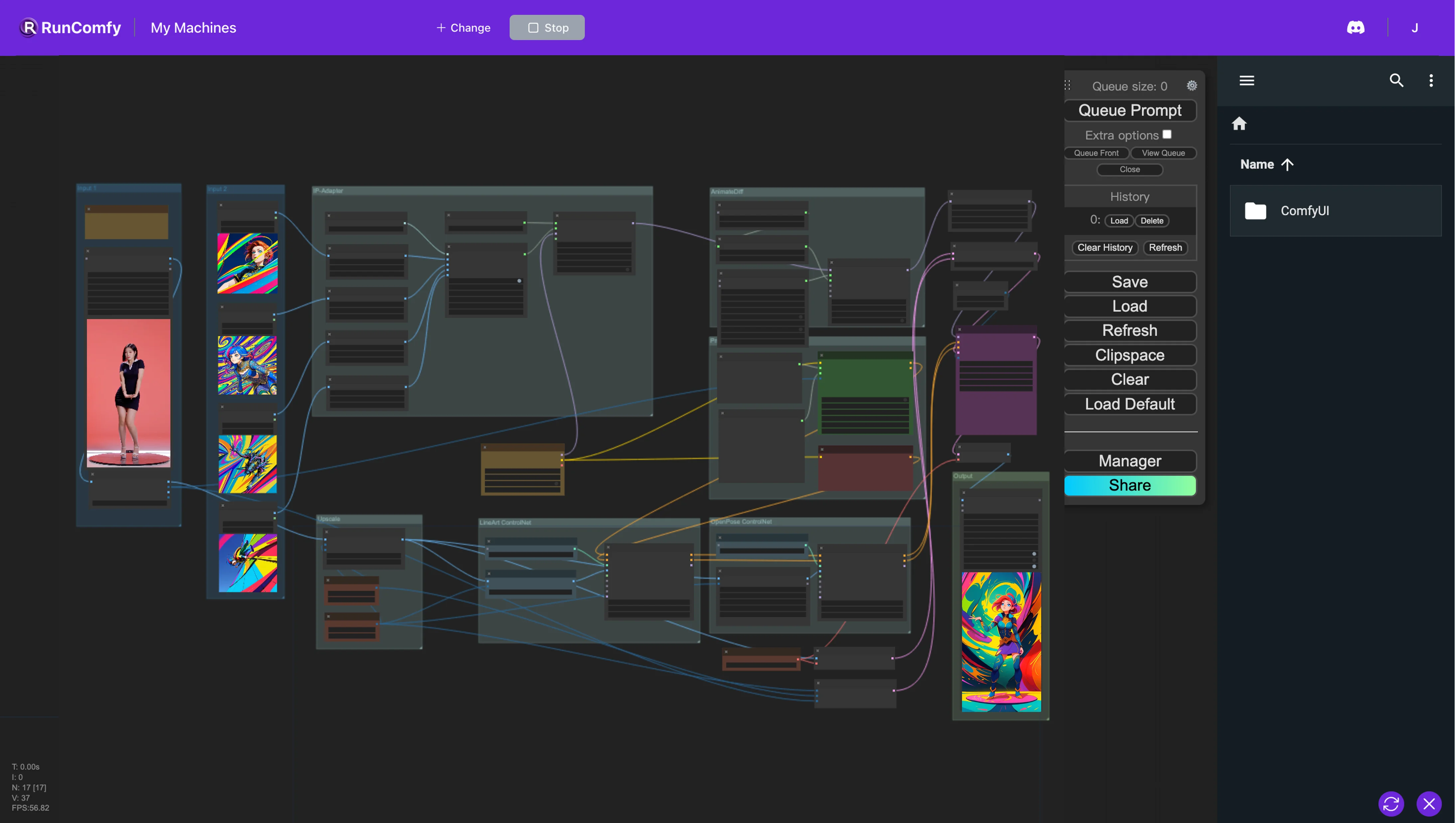
In the ComfyUI Workflow, we integrate multiple nodes, including Animatediff, ControlNet (featuring LineArt and OpenPose), IP-Adapter, and FreeU. This integration facilitates the conversion of the original video into the desired animation using just a handful of images to define the preferred style. However, the checkpoint models also affect the style. We encourage experimenting with a variety of images and checkpoint models to achieve the best results!ComfyUI Vid2Vid (Cartoon Style) Workflow
- Fully operational workflows
- No missing nodes or models
- No manual setups required
- Features stunning visuals
ComfyUI Vid2Vid (Cartoon Style) Examples
ComfyUI Vid2Vid (Cartoon Style) Description
1. ComfyUI AnimateDiff, ControlNet, IP-Adapter and FreeU Workflow
The ComfyUI workflow implements a methodology for video restyling that integrates several components—AnimateDiff, ControlNet, IP-Adapter, and FreeU—to enhance video editing capabilities.
AnimateDiff: This component employs temporal difference models to create smooth animations from static images over time. It operates by identifying the differences between consecutive frames and incrementally applying these variations to reduce abrupt changes, thus preserving the motion's coherence.
ControlNet: ControlNet harnesses control signals, such as those derived from pose estimation tools like OpenPose, to guide the animation's movement and flow. These control signals are layered and processed by models akin to control nets, which in turn shape the final animated output.
IP-Adapter: The IP-Adapter is designed to adapt input images so that they align more closely with the targeted output styles or features. It undertakes processes such as colorization and style transfer, altering image attributes unsupervisedly.
FreeU: As a cost-effective enhancement tool, FreeU refines diffusion models by fine-tuning the existing U-Net architectures. This results in a substantial boost in the quality of image and video generation, requiring only minimal modifications.
Together, these components synergize within this ComfyUI workflow to transform inputs into stylized animations through a sophisticated, multi-stage diffusion process.
2. Overview of AnimateDiff
Please check out the details on
3. Overview of ControlNet
Please check out the details on
4. Overview of IP-Adapter
Please check out the details in the
5. Overview of FreeU
5.1. Introduction to FreeU
FreeU is a cutting-edge enhancement for diffusion models that elevates sample quality without additional overhead. It works within the existing system, requiring no further training, no extra parameters, and maintaining current memory and processing time. FreeU utilizes the diffusion U-Net architecture's existing mechanisms to instantly improve generation quality.
The innovation of FreeU lies in its ability to harness the diffusion U-Net's architecture more effectively. It refines the balance between the U-Net's denoising backbone and its high-frequency feature-adding skip connections, optimizing the quality of generated images and videos without compromising semantic integrity.
FreeU is designed for easy integration with popular diffusion models, requiring minimal adjustments and the tuning of just two scaling factors during inference to deliver marked improvements in output quality. This makes FreeU an attractive option for those seeking to enhance their generative workflows efficiently.
Parameters for Optimal FreeU Performance
Feel free to adjust these parameters based on your models, image/video style, or tasks. The following parameters are for reference only.
SD1.4: (will be updated soon)
b1: 1.3, b2: 1.4, s1: 0.9, s2: 0.2
SD1.5: (will be updated soon)
b1: 1.5, b2: 1.6, s1: 0.9, s2: 0.2
SD2.1
b1: 1.4, b2: 1.6, s1: 0.9, s2: 0.2
SDXL
b1: 1.3, b2: 1.4, s1: 0.9, s2: 0.2
Range for More Parameters
When trying additional parameters, consider the following ranges:
- b1: 1 ≤ b1 ≤ 1.2
- b2: 1.2 ≤ b2 ≤ 1.6
- s1: s1 ≤ 1
- s2: s2 ≤ 1
For more information, check it on
