LayerDiffuse | Text to Transparent Image
The LayerDiffuse model introduces a novel approach to image manipulation, enabling the direct creation of transparent images. Within this ComfyUI LayerDiffuse workflow, three specialized sub-workflows are integrated: creating transparent images, generating background from the foreground, and the inverse process of creating foreground based on the existing background.ComfyUI LayerDiffuse Workflow

- Fully operational workflows
- No missing nodes or models
- No manual setups required
- Features stunning visuals
ComfyUI LayerDiffuse Examples

ComfyUI LayerDiffuse Description
1. ComfyUI LayerDiffuse Workflow Overview
The ComfyUI LayerDiffuse workflow integrates three specialized sub-workflows: creating transparent images, generating background from the foreground, and the inverse process of generating foreground based on existing background. Each of these LayerDiffuse sub-workflows operates independently, providing you the flexibility to choose and activate the specific LayerDiffuse functionality that meets your creative needs.
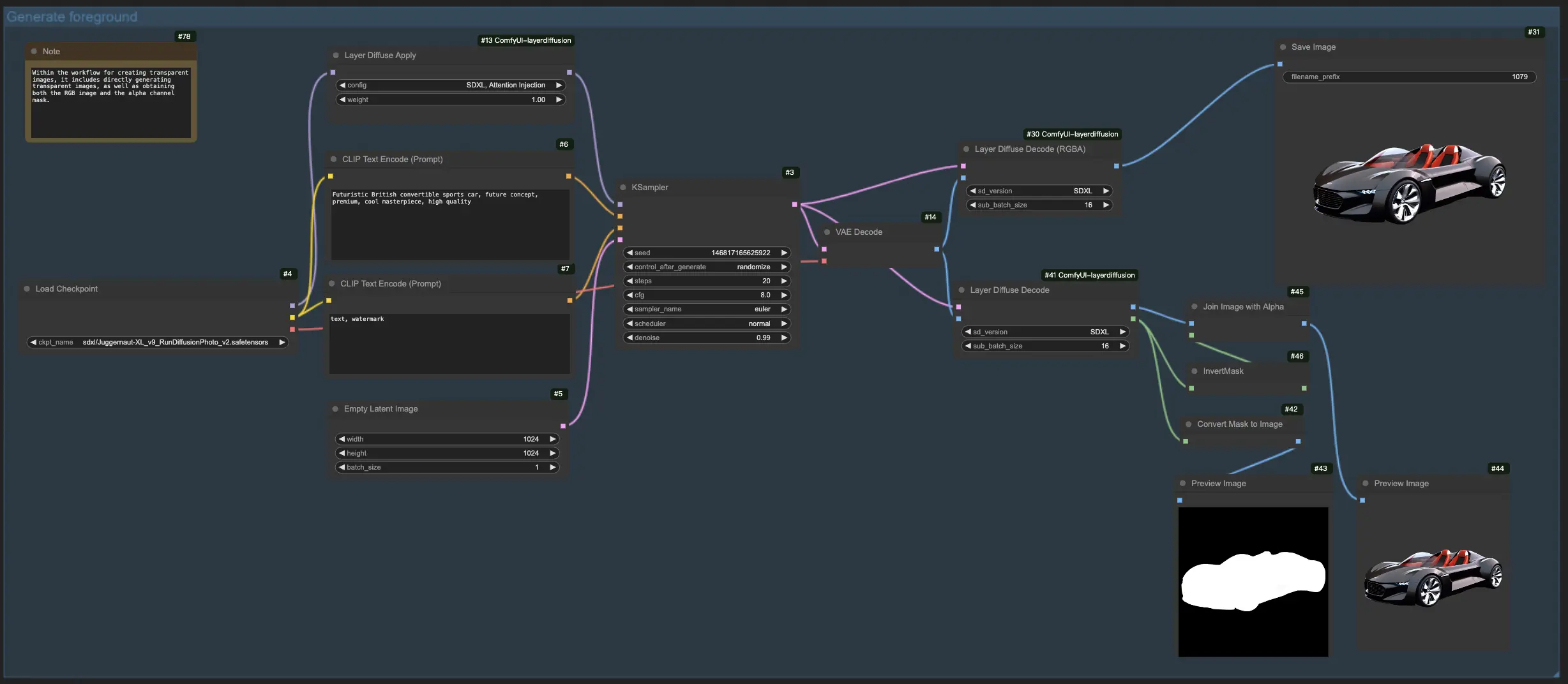
1.1. Creating Transparent Images with LayerDiffuse:
This workflow enables the direct creation of transparent images, providing you with the flexibility to generate images with or without specifying the alpha channel mask.
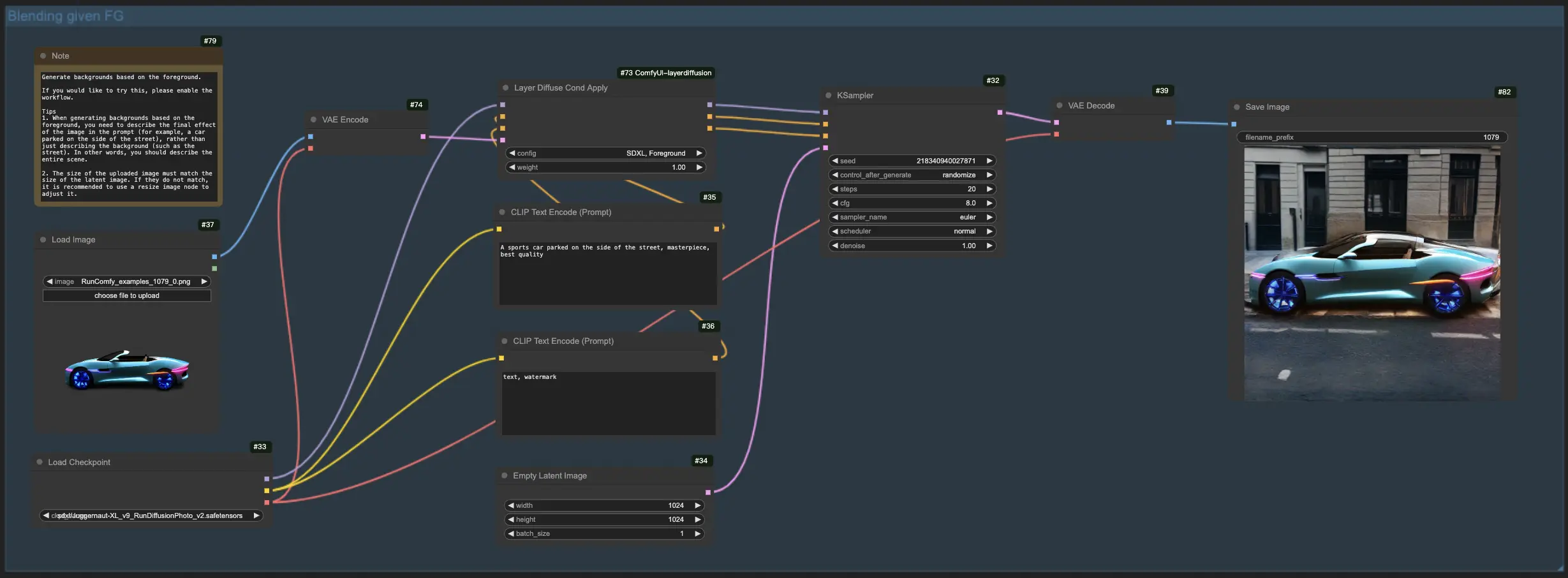
1.2. Generating Background from the Foreground with LayerDiffuse:
For this LayerDiffuse workflow, start by uploading your foreground image and crafting a descriptive prompt. LayerDiffuse then blends these elements to produce your desired image. When drafting your prompt for LayerDiffuse, it's crucial to detail the complete scene (e.g., "a car parked on the side of the street") instead of merely describing the background element (e.g., "the street").
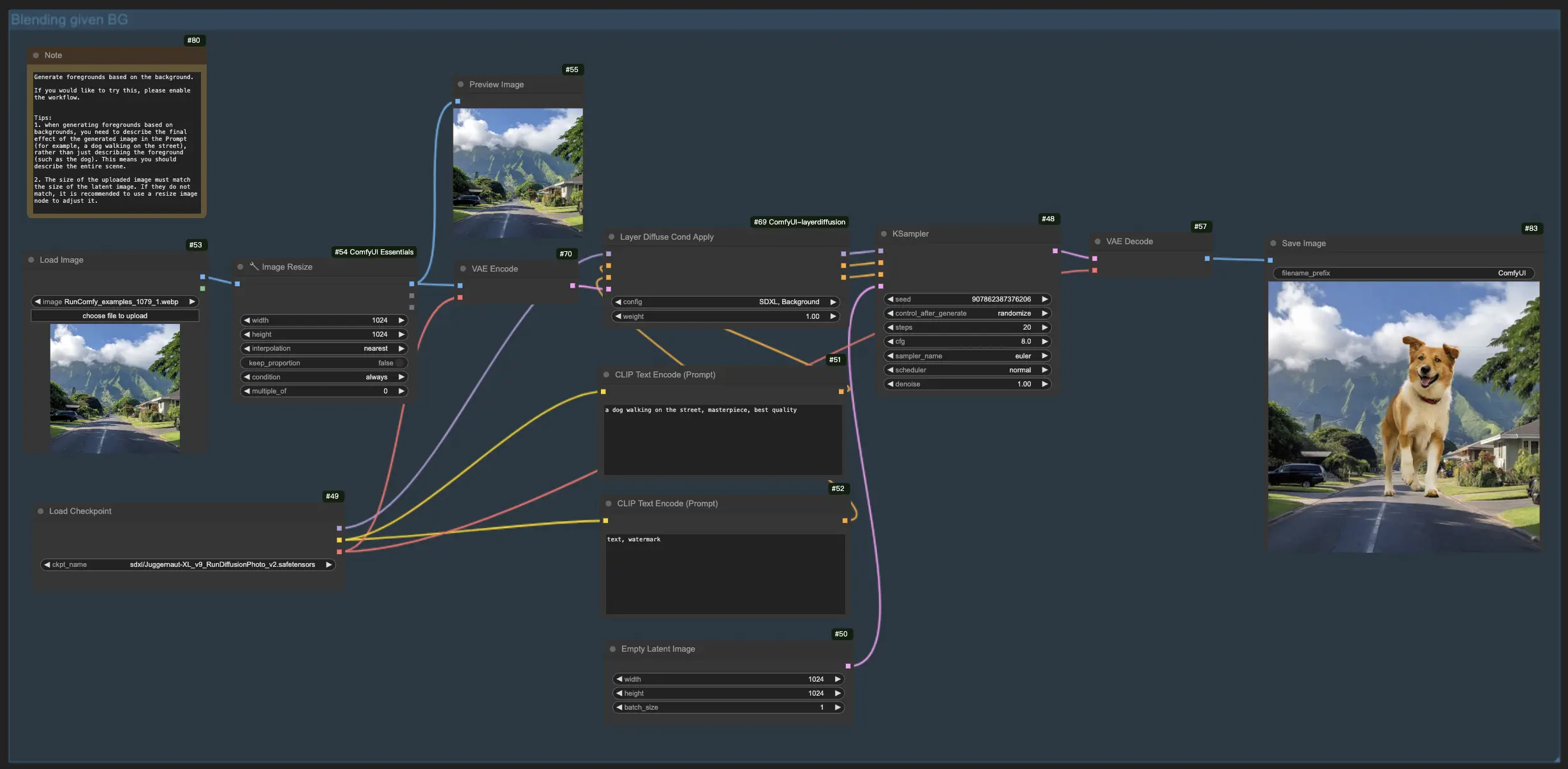
1.3. Generating Foreground Based on the Background:
Mirroring the previous workflow, this LayerDiffuse functionality reverses the focus, aiming to merge foreground elements with an existing background. Therefore, you need to upload the background image and describing the envisioned final image in your prompt, emphasizing the complete scene (e.g., "a dog walking on the street") over individual elements (e.g., "the dog").
For more LayerDiffuse workflows, check it on
2. LayerDiffuse Workflow Efficacy
While the process of creating transparent images is robust and reliably produces high-quality results, the workflows for blending backgrounds and foregrounds are more experimental. They may not always achieve a perfect blend, indicative of the innovative but developing nature of this technology.
3. Technical introduction to LayerDiffuse
LayerDiffuse is an innovative approach designed to enable large-scale pretrained latent diffusion models to generate images with transparency. This technique introduces the concept of "latent transparency," which involves encoding alpha channel transparency directly into the latent manifold of existing models. This allows for the creation of transparent images or multiple transparent layers without significantly altering the original latent distribution of the pretrained model. The goal is to maintain the high-quality output of these models while adding the capability to generate images with transparency.
To achieve this, LayerDiffuse fine-tunes pretrained latent diffusion models by adjusting their latent space to include transparency as a latent offset. This process involves minimal changes to the model, preserving its original qualities and performance. The training of LayerDiffuse utilizes a dataset of 1 million transparent image layer pairs, collected through a human-in-the-loop scheme to ensure a wide variety of transparency effects.
The method has been shown to be adaptable to various open-source image generators and can be integrated into different conditional control systems. This versatility allows for a range of applications, such as generating images with foreground/background-specific transparency, creating layers with joint generation capabilities, and controlling the structural content of the layers.





