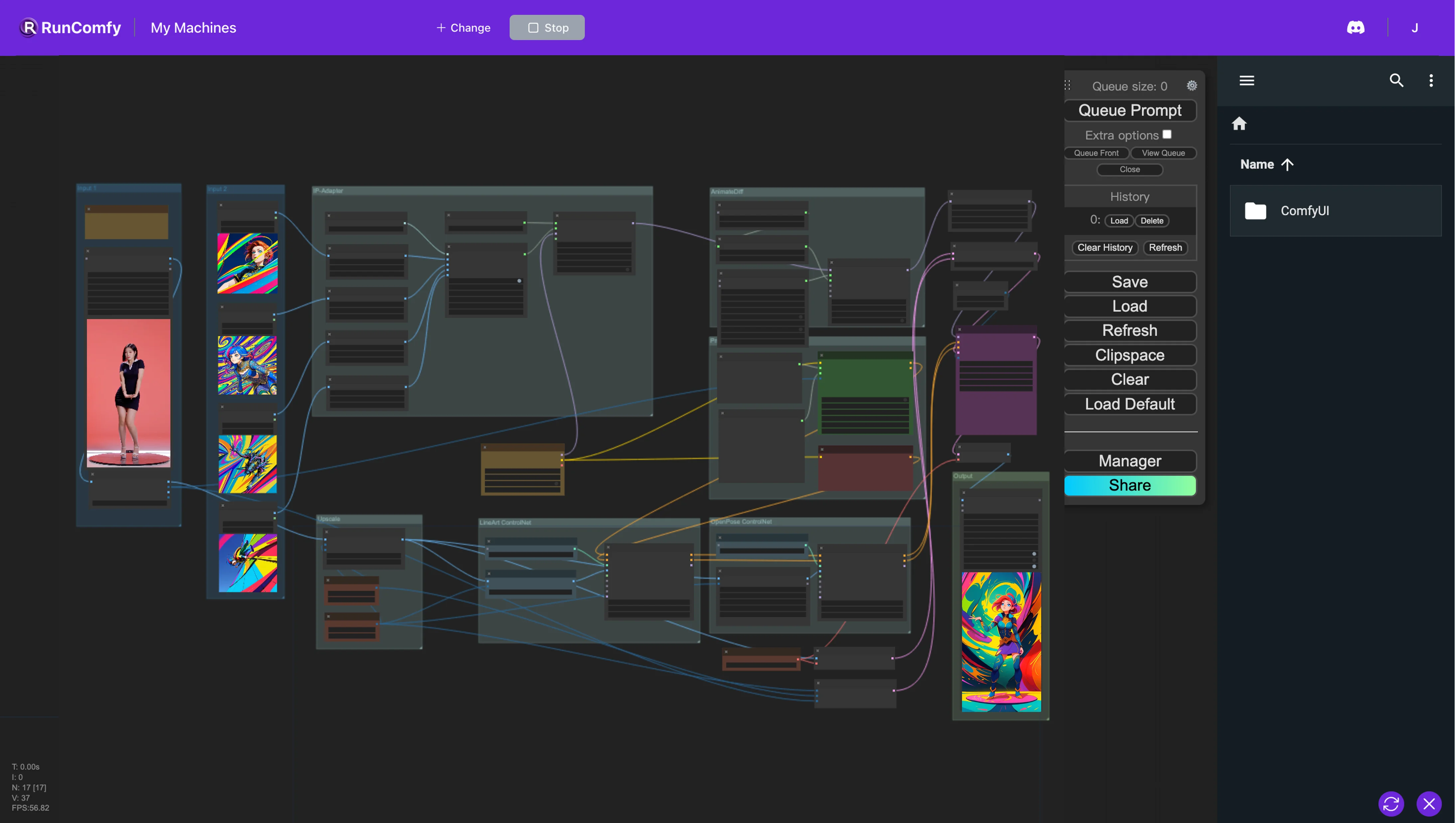
AnimateDiff + ControlNet + IPAdapter V1 | Cartoon-Stil
Im ComfyUI-Workflow integrieren wir mehrere Nodes, darunter Animatediff, ControlNet (mit LineArt und OpenPose), IP-Adapter und FreeU. Diese Integration erleichtert die Umwandlung des Originalvideos in die gewünschte Animation mit nur wenigen Bildern, um den bevorzugten Stil zu definieren. Die Checkpoint-Modelle beeinflussen jedoch auch den Stil. Wir empfehlen, mit einer Vielzahl von Bildern und Checkpoint-Modellen zu experimentieren, um die besten Ergebnisse zu erzielen!ComfyUI Vid2Vid (Cartoon Style) Arbeitsablauf
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI Vid2Vid (Cartoon Style) Beispiele
ComfyUI Vid2Vid (Cartoon Style) Beschreibung
1. ComfyUI AnimateDiff, ControlNet, IP-Adapter und FreeU Workflow
Der ComfyUI-Workflow implementiert eine Methodik zur Video-Umgestaltung, die mehrere Komponenten—AnimateDiff, ControlNet, IP-Adapter und FreeU—integriert, um die Videoeditingfähigkeiten zu verbessern.
AnimateDiff: Diese Komponente verwendet zeitliche Differenzmodelle, um im Laufe der Zeit flüssige Animationen aus statischen Bildern zu erstellen. Sie funktioniert, indem sie die Unterschiede zwischen aufeinanderfolgenden Frames identifiziert und diese Variationen schrittweise anwendet, um abrupte Änderungen zu reduzieren und so die Kohärenz der Bewegung zu erhalten.
ControlNet: ControlNet nutzt Steuersignale, wie sie beispielsweise von Posen-Schätzwerkzeugen wie OpenPose abgeleitet werden, um die Bewegung und den Fluss der Animation zu steuern. Diese Steuersignale werden von Modellen ähnlich wie Control Nets geschichtet und verarbeitet, die wiederum die endgültige animierte Ausgabe formen.
IP-Adapter: Der IP-Adapter ist darauf ausgelegt, Eingabebilder so anzupassen, dass sie besser mit den anvisierten Ausgabestilen oder -funktionen übereinstimmen. Er führt Prozesse wie Kolorierung und Stilübertragung durch und verändert Bildattribute unüberwacht.
FreeU: Als kostengünstiges Verbesserungstool verfeinert FreeU Diffusionsmodelle durch Feinabstimmung der bestehenden U-Net-Architekturen. Dies führt zu einer erheblichen Steigerung der Qualität der Bild- und Videogenerierung und erfordert nur minimale Änderungen.
Zusammen synergieren diese Komponenten innerhalb dieses ComfyUI-Workflows, um Eingaben durch einen anspruchsvollen, mehrstufigen Diffusionsprozess in stilisierte Animationen umzuwandeln.
2. Übersicht über AnimateDiff
Bitte lesen Sie die Details unter
3. Übersicht über ControlNet
Bitte lesen Sie die Details unter
4. Übersicht über IP-Adapter
Bitte lesen Sie die Details in der
5. Übersicht über FreeU
5.1. Einführung in FreeU
FreeU ist eine hochmoderne Verbesserung für Diffusionsmodelle, die die Qualität der Stichproben ohne zusätzlichen Aufwand erhöht. Es arbeitet innerhalb des bestehenden Systems, erfordert kein weiteres Training, keine zusätzlichen Parameter und erhält die aktuelle Speicher- und Verarbeitungszeit. FreeU nutzt die vorhandenen Mechanismen der Diffusions-U-Net-Architektur, um die Erzeugungsqualität sofort zu verbessern.
Die Innovation von FreeU liegt in seiner Fähigkeit, die Architektur des Diffusions-U-Net effektiver zu nutzen. Es verfeinert das Gleichgewicht zwischen dem Entrauschungs-Backbone des U-Net und seinen hochfrequenten Feature-Adding-Skip-Verbindungen und optimiert so die Qualität der generierten Bilder und Videos, ohne die semantische Integrität zu beeinträchtigen.
FreeU ist für eine einfache Integration mit populären Diffusionsmodellen konzipiert und erfordert nur minimale Anpassungen und die Abstimmung von nur zwei Skalierungsfaktoren während der Inferenz, um deutliche Verbesserungen der Ausgabequalität zu erzielen. Das macht FreeU zu einer attraktiven Option für diejenigen, die ihre generativen Workflows effizient verbessern wollen.
Parameter für optimale FreeU-Leistung
Passen Sie diese Parameter gerne an Ihre Modelle, Bild-/Videostil oder Aufgaben an. Die folgenden Parameter dienen nur als Referenz.
SD1.4: (wird bald aktualisiert)
b1: 1.3, b2: 1.4, s1: 0.9, s2: 0.2
SD1.5: (wird bald aktualisiert)
b1: 1.5, b2: 1.6, s1: 0.9, s2: 0.2
SD2.1
b1: 1.4, b2: 1.6, s1: 0.9, s2: 0.2
SDXL
b1: 1.3, b2: 1.4, s1: 0.9, s2: 0.2
Bereich für weitere Parameter
Wenn Sie zusätzliche Parameter ausprobieren, berücksichtigen Sie die folgenden Bereiche:
- b1: 1 ≤ b1 ≤ 1.2
- b2: 1.2 ≤ b2 ≤ 1.6
- s1: s1 ≤ 1
- s2: s2 ≤ 1
Für weitere Informationen, besuchen Sie
