AnimateDiff + ControlNet | Keramikkunststil
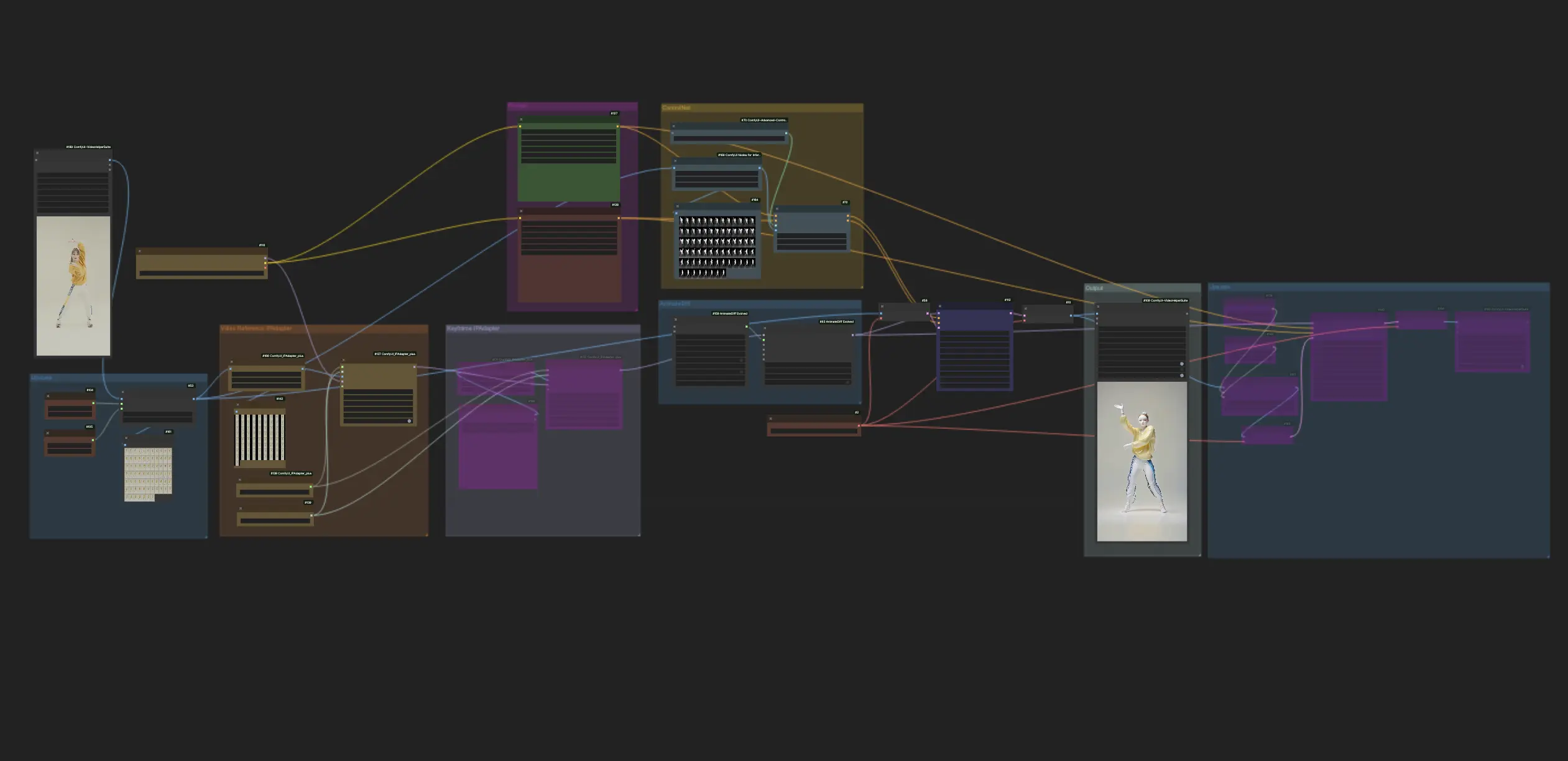
Dieser Workflow in ComfyUI verwendet AnimateDiff und ControlNet mit Fokus auf Tiefe, neben anderen wie Lora, um Videos gekonnt in Keramikkunststil zu transformieren. Er ermöglicht es den ursprünglichen Inhalten, ein unverwechselbares, künstlerisches Flair anzunehmen und sie effektiv in den Bereich der Keramikkunstmeisterwerke zu erheben.ComfyUI Vid2Vid (Art) Arbeitsablauf
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI Vid2Vid (Art) Beispiele
ComfyUI Vid2Vid (Art) Beschreibung
1. ComfyUI Workflow: AnimateDiff + ControlNet | Keramikkunststil
Dieser Workflow nutzt AnimateDiff, ControlNet mit Fokus auf Tiefe und spezielle Lora, um Videos gekonnt in einen Keramikkunststil zu transformieren. Sie werden ermutigt, verschiedene Prompts zu verwenden, um unterschiedliche Kunststile zu erreichen und Ihre Ideen in die Realität umzusetzen.
2. Wie man AnimateDiff verwendet
AnimateDiff wurde entwickelt, um statische Bilder und Textprompts mithilfe von Stable Diffusion-Modellen und einem speziellen Bewegungsmodul in dynamische Videos zu animieren. Es automatisiert den Animationsprozess durch die Vorhersage nahtloser Übergänge zwischen Frames, wodurch es für Benutzer ohne Programmierkenntnisse zugänglich wird.
2.1 AnimateDiff-Bewegungsmodule
Wählen Sie zunächst das gewünschte AnimateDiff-Bewegungsmodul aus dem Dropdown-Menü model_name aus:
- Verwenden Sie v3_sd15_mm.ckpt für AnimateDiff V3
- Verwenden Sie mm_sd_v15_v2.ckpt für AnimateDiff V2
- Verwenden Sie mm_sdxl_v10_beta.ckpt für AnimateDiff SDXL
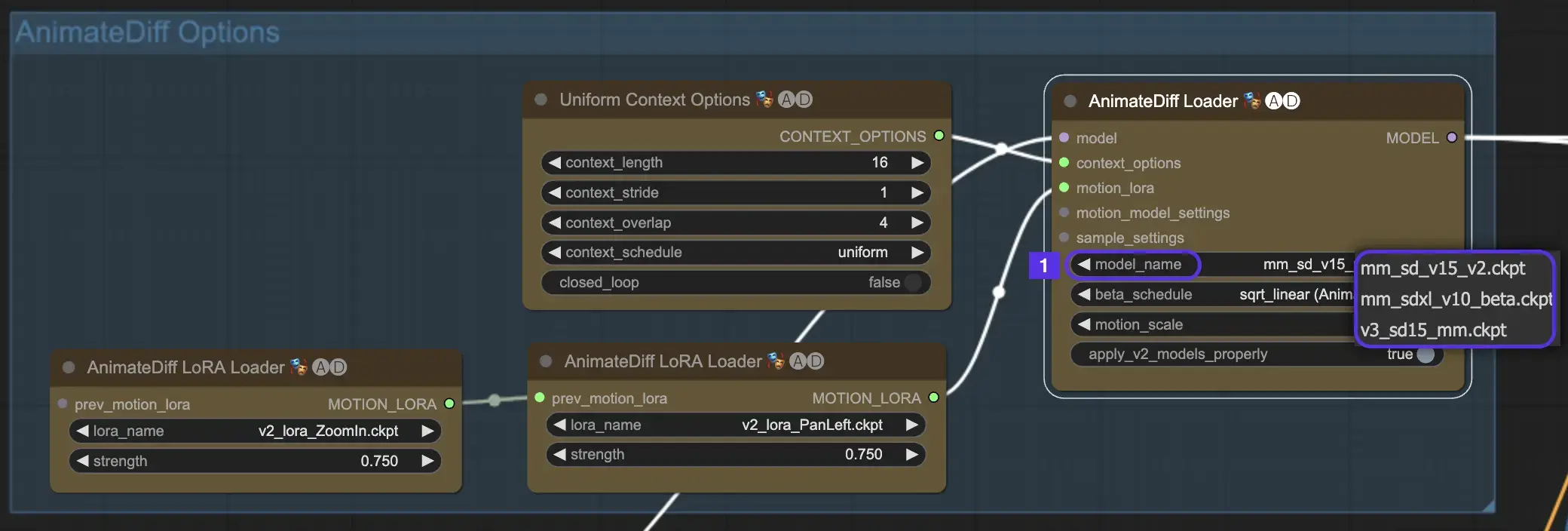
2.2 Beta Schedule
Der Beta Schedule in AnimateDiff ist entscheidend für die Anpassung des Rauschunterdrückungsprozesses während der Animationserstellung.
Für die Versionen V3 und V2 von AnimateDiff wird die Einstellung sqrt_linear empfohlen, obwohl das Experimentieren mit der linearen Einstellung einzigartige Effekte erzielen kann.
Für AnimateDiff SDXL wird die lineare Einstellung (AnimateDiff-SDXL) empfohlen.
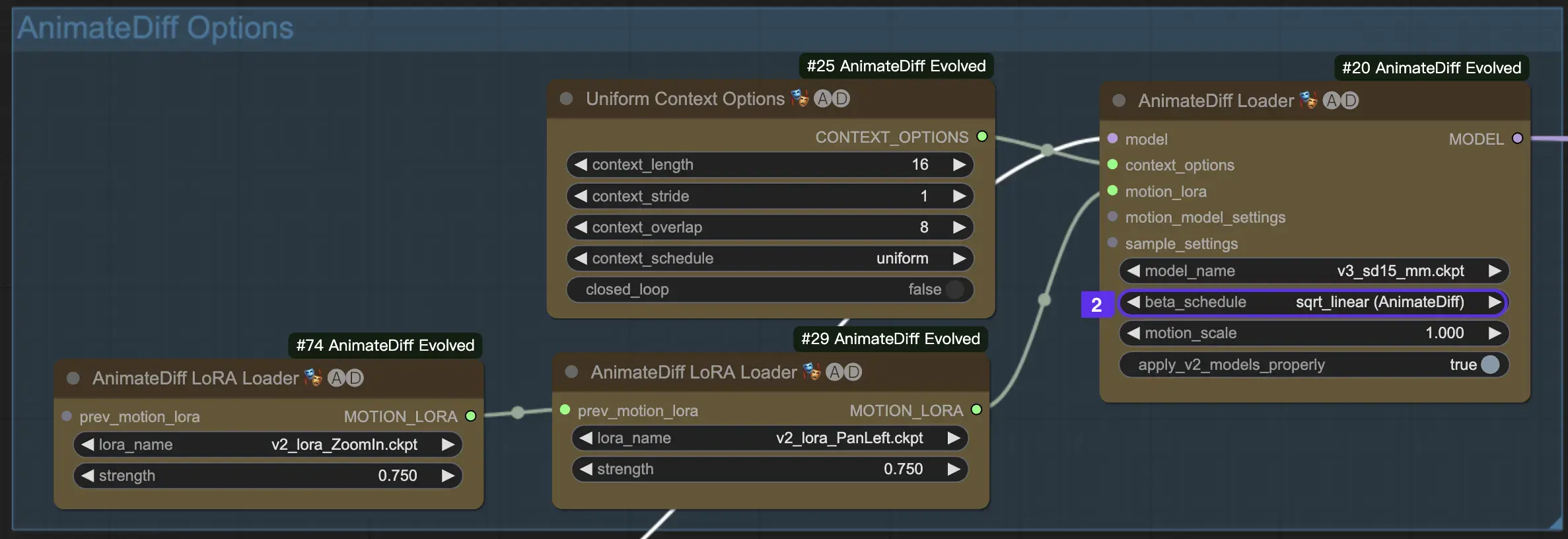
2.3 Motion Scale
Die Funktion Motion Scale in AnimateDiff ermöglicht die Anpassung der Bewegungsintensität in Ihren Animationen. Ein Motion Scale unter 1 führt zu subtileren Bewegungen, während ein Wert über 1 die Bewegung verstärkt.
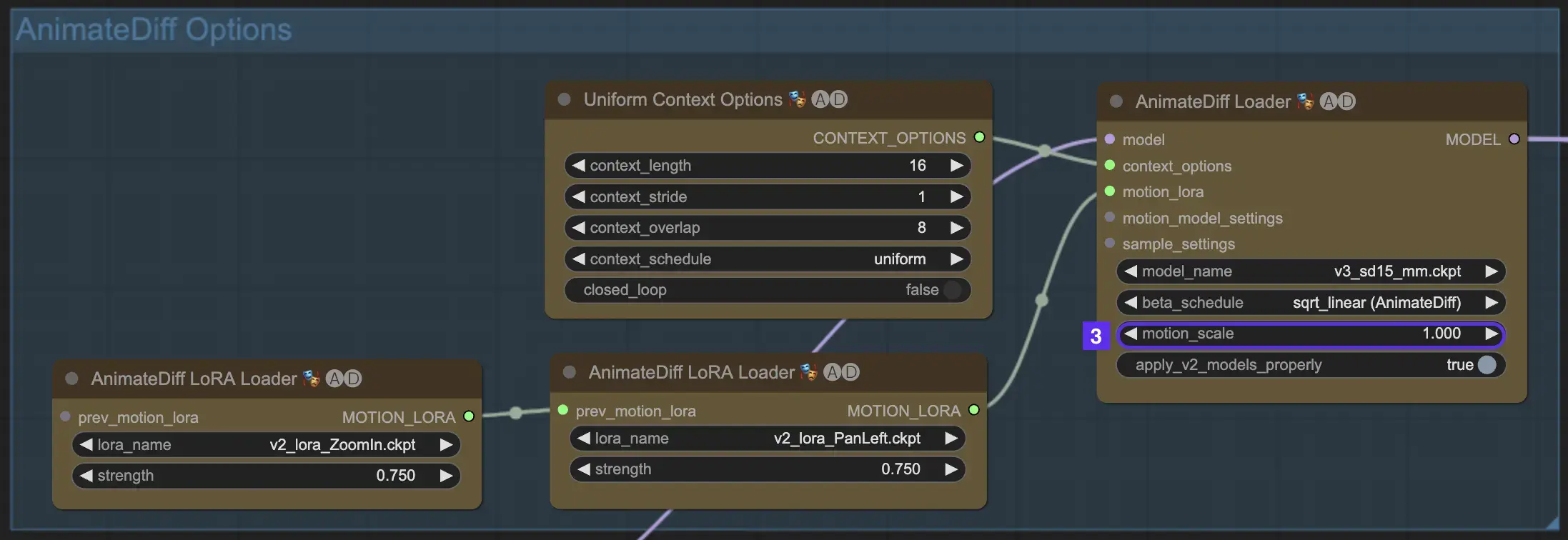
2.4 Context Length
Die Uniform Context Length in AnimateDiff ist entscheidend, um nahtlose Übergänge zwischen den durch Ihre Batch Size definierten Szenen sicherzustellen. Sie agiert wie ein Experteneditor und verbindet Szenen nahtlos für eine flüssige Erzählung. Das Einstellen einer längeren Uniform Context Length sorgt für weichere Übergänge, während eine kürzere Länge schnellere, distinktivere Szenenwechsel bietet, was für bestimmte Effekte vorteilhaft ist. Die Standard-Uniform Context Length ist auf 16 festgelegt.
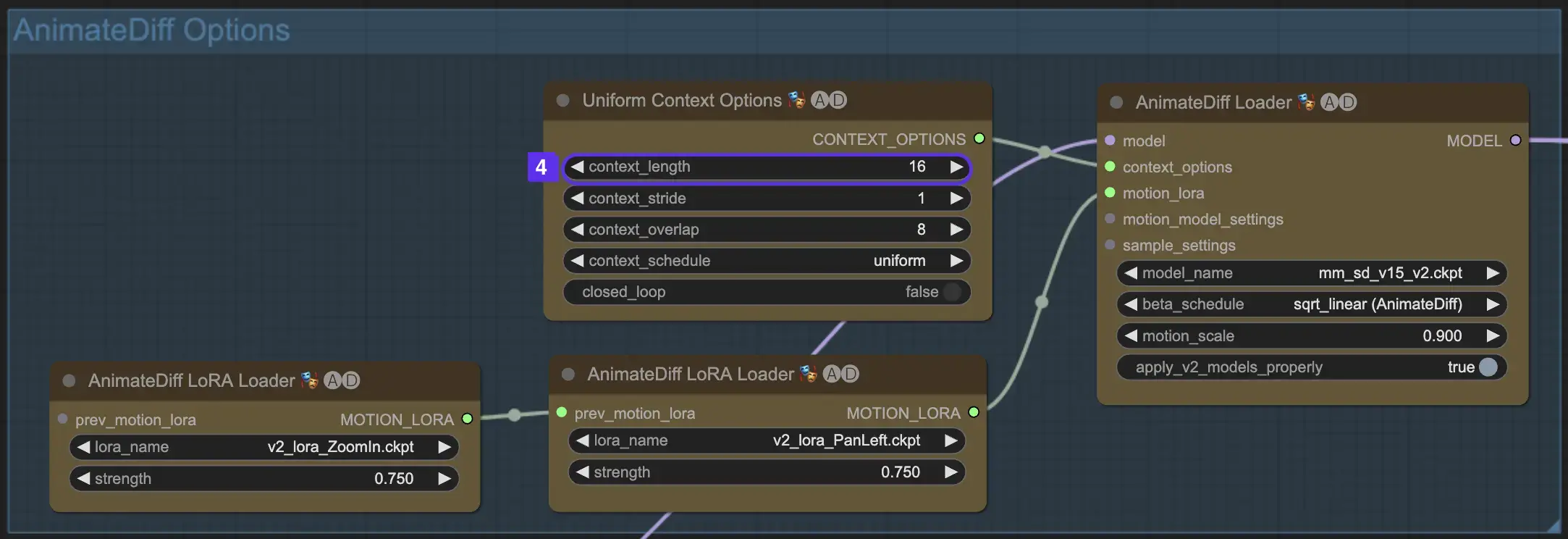
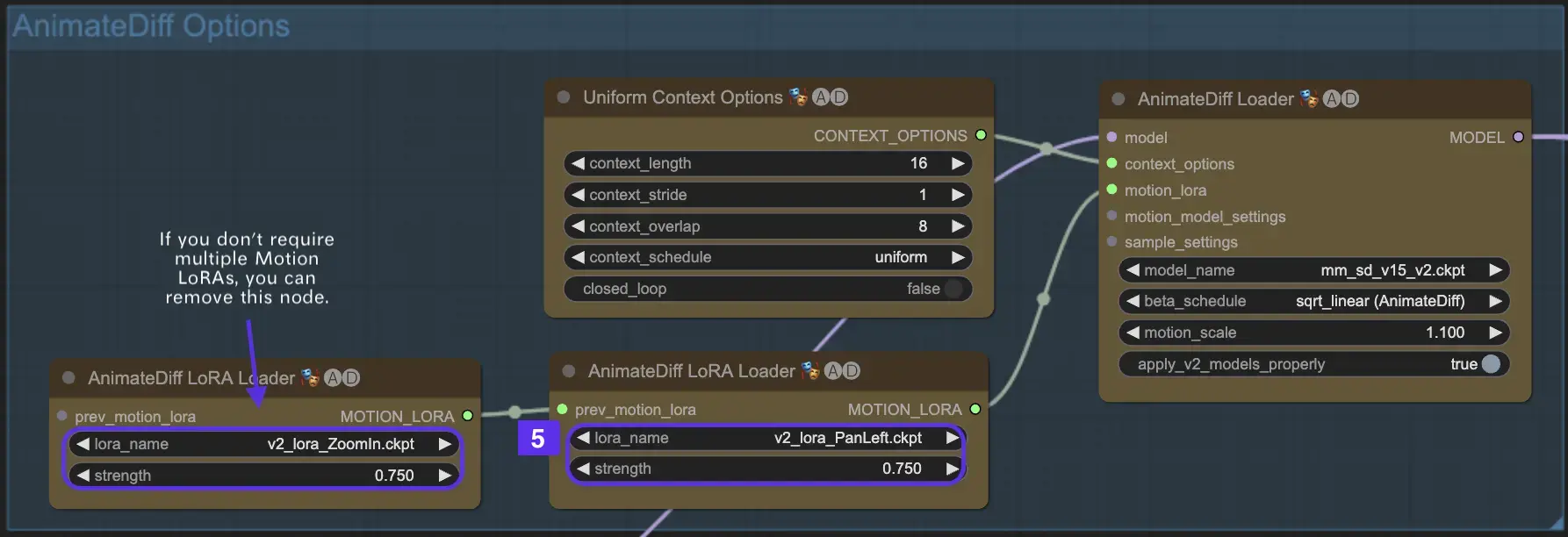
2.5 Verwendung von Motion LoRA für verbesserte Kameradynamik (spezifisch für AnimateDiff v2)
Motion LoRAs, die nur mit AnimateDiff v2 kompatibel sind, führen eine zusätzliche Ebene dynamischer Kamerabewegung ein. Das Erreichen der optimalen Balance mit dem LoRA-Gewicht, typischerweise um 0,75, stellt eine flüssige Kamerabewegung ohne Hintergrundverzerrungen sicher.
Darüber hinaus ermöglicht die Verkettung verschiedener Motion LoRA-Modelle komplexe Kameradynamiken. Dies ermöglicht es Erstellern, zu experimentieren und die ideale Kombination für ihre Animation zu finden, um sie auf ein filmisches Niveau zu heben.
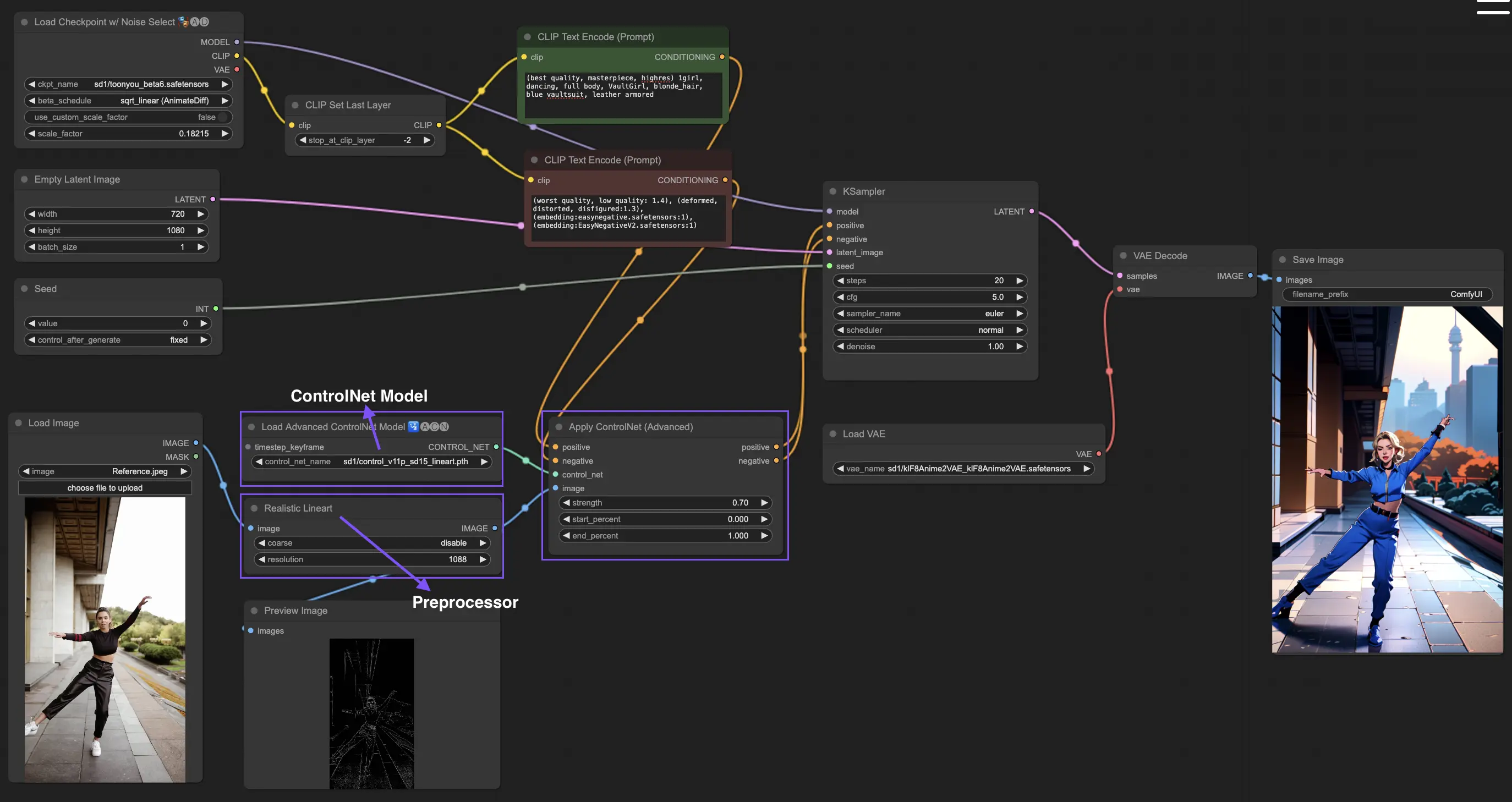
3. Wie man ControlNet verwendet
ControlNet verbessert die Bilderzeugung, indem es Text-to-Image-Modellen präzise räumliche Kontrolle hinzufügt und es Benutzern ermöglicht, Bilder auf anspruchsvolle Weise zu manipulieren, die über einfache Textprompts hinausgehen, indem es umfangreiche Bibliotheken von Modellen wie Stable Diffusion für komplexe Aufgaben wie Skizzieren, Mapping und Segmentierung von Bildern nutzt.
Im Folgenden finden Sie den einfachsten Workflow mit ControlNet.
3.1 Laden des "Apply ControlNet" Knotens
Beginnen Sie Ihre Bildgestaltung, indem Sie den "Apply ControlNet"-Knoten in ComfyUI laden und so die Bühne für die Kombination von visuellen und textlichen Elementen in Ihrem Design vorbereiten.
3.2 Eingänge des "Apply ControlNet" Knotens
Verwenden Sie Positive und Negative Conditioning, um Ihr Bild zu formen, wählen Sie ein ControlNet-Modell, um Stileigenschaften zu definieren, und verarbeiten Sie Ihr Bild vor, um sicherzustellen, dass es den Anforderungen des ControlNet-Modells entspricht und so für die Transformation bereit ist.
3.3 Ausgänge des "Apply ControlNet" Knotens
Die Knotenausgänge leiten das Diffusionsmodell und bieten die Wahl zwischen weiterer Verfeinerung des Bildes oder Hinzufügen weiterer ControlNets für mehr Details und Anpassung basierend auf der Interaktion von ControlNet mit Ihren kreativen Eingaben.
3.4 Optimierung von "Apply ControlNet" für beste Ergebnisse
Steuern Sie den Einfluss von ControlNet auf Ihr Bild durch Einstellungen wie Bestimmung der Stärke, Anpassung des Startprozentsatzes und Festlegung des Endprozentsatzes, um den kreativen Prozess und das Ergebnis des Bildes fein abzustimmen.
Für detailliertere Informationen lesen Sie bitte
Dieser Workflow ist von inspiriert, mit einigen Modifikationen. Für weitere Informationen besuchen Sie bitte seinen YouTube-Kanal.

