Audioreactive Mask Dilation | Atemberaubende Animationen
Dieser ComfyUI Audioreactive Mask Dilation Workflow ermöglicht es Ihnen, Ihre Videomotive kreativ zu transformieren. Er erlaubt es Ihnen, Ihre Motive, sei es eine Einzelperson oder eine Gruppe von Darstellern, mit einer dynamischen und reaktionsfähigen Aura zu umhüllen, die sich perfekt synchron zum Rhythmus der Musik ausdehnt und zusammenzieht. Dieser Effekt verleiht Ihren Videos eine fesselnde visuelle Dimension und erhöht ihre Gesamtwirkung und Engagement.ComfyUI Audioreactive Mask Dilation Arbeitsablauf

Möchtest du diesen Workflow ausführen?
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI Audioreactive Mask Dilation Beispiele
ComfyUI Audioreactive Mask Dilation Beschreibung
Erstellen Sie atemberaubende Videoanimationen, indem Sie Ihr Motiv (z.B. einen Tänzer) mit einer dynamischen Aura transformieren, die sich rhythmisch im Takt ausdehnt und zusammenzieht. Verwenden Sie diesen Workflow mit einzelnen Motiven oder mehreren Motiven, wie in den Beispielen zu sehen.
So verwenden Sie den Audioreactive Mask Dilation Workflow:
- Laden Sie ein Motivvideo im Abschnitt Eingabe hoch
- Wählen Sie die gewünschte Breite und Höhe für das endgültige Video sowie die Anzahl der Frames aus dem Eingabevideo, die mit 'every_nth' übersprungen werden sollen. Sie können auch die Gesamtanzahl der zu rendernden Frames mit 'frame_load_cap' begrenzen.
- Füllen Sie die positiven und negativen Eingabeaufforderungen aus. Stellen Sie die Batch-Frame-Zeiten ein, um festzulegen, wann die Szenenübergänge erfolgen sollen.
- Laden Sie Bilder für jede der Standard-IP-Adapter-Maskenfarben hoch:
- Rot = Motiv (Tänzer)
- Schwarz = Hintergrund
- Weiß = Weiße audioreaktive Dilationsmaske
- Laden Sie einen guten LCM-Checkpoint (ich verwende ParadigmLCM von Machine Delusions) im Abschnitt 'Models'.
- Fügen Sie beliebige Loras mithilfe des Lora-Stackers unterhalb des Modellladers hinzu
- Klicken Sie auf Queue Prompt
Eingabe
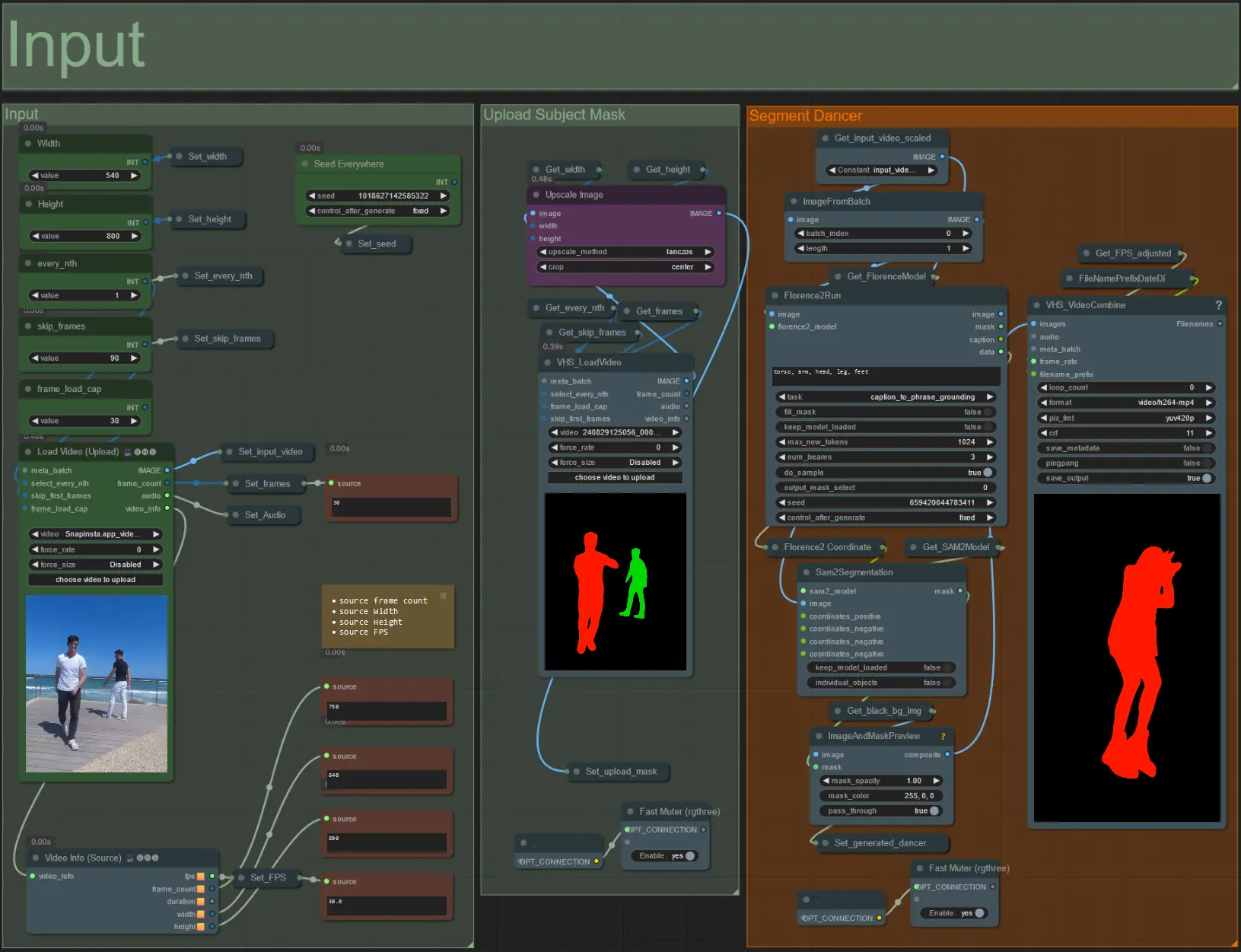
- Laden Sie Ihr gewünschtes Motivvideo in den Knoten Load Video (Upload) hoch.
- Passen Sie die Ausgabebreite und -höhe mit den beiden Eingaben oben links an.
- every_nth legt fest, ob jeder zweite Frame, jeder dritte Frame usw. verwendet werden soll (2 = jeder zweite Frame). Standardmäßig auf 1 belassen.
- skip_frames wird verwendet, um Frames am Anfang des Videos zu überspringen. (100 = die ersten 100 Frames aus dem Eingabevideo überspringen). Standardmäßig auf 0 belassen.
- frame_load_cap gibt an, wie viele Frames aus dem Eingabevideo insgesamt geladen werden sollen. Am besten niedrig halten, wenn Einstellungen getestet werden (z.B. 30 - 60) und dann erhöhen oder auf 0 setzen (keine Frame-Begrenzung), wenn das endgültige Video gerendert wird.
- Die Zahlenfelder unten rechts zeigen Informationen über das hochgeladene Eingabevideo an: Gesamtanzahl der Frames, Breite, Höhe und FPS von oben nach unten.
- Wenn Sie bereits ein Maskenvideo des Motivs generiert haben, heben Sie die Stummschaltung des Abschnitts 'Upload Subject Mask' auf und laden Sie das Maskenvideo hoch. Optional können Sie den Abschnitt 'Segment Dancer' stummschalten, um etwas Verarbeitungszeit zu sparen.
- Manchmal wird das segmentierte Motiv nicht perfekt sein, dann überprüfen Sie die Maskenqualität mithilfe des Vorschaufensters unten rechts, wie oben zu sehen. In diesem Fall können Sie mit der Eingabeaufforderung im Knoten 'Florence2Run' herumspielen, um verschiedene Körperteile wie 'Kopf', 'Brust', 'Beine' usw. anzusprechen und zu sehen, ob Sie ein besseres Ergebnis erzielen.
Eingabeaufforderung
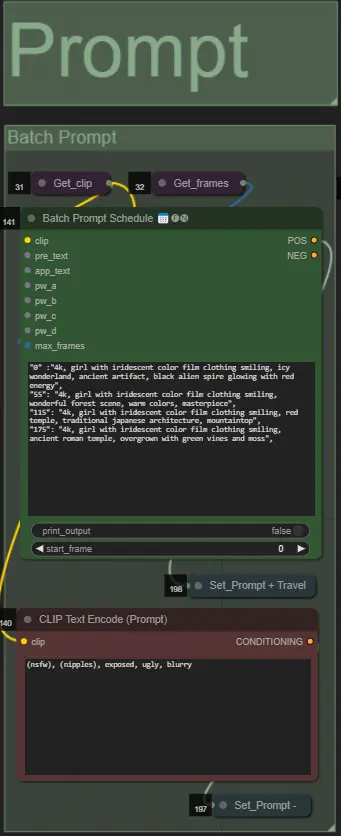
- Setzen Sie die positive Eingabeaufforderung mit Batch-Formatierung:
- z.B. '0': '4k, Meisterwerk, 1 Mädchen steht am Strand, absurdres', '25': 'HDR, Sonnenuntergangsszene, 1 Mädchen mit schwarzen Haaren und einer weißen Jacke, absurdres', …
- Negative Eingabeaufforderung im normalen Format, fügen Sie bei Bedarf Einbettungen hinzu.
Audioverarbeitung
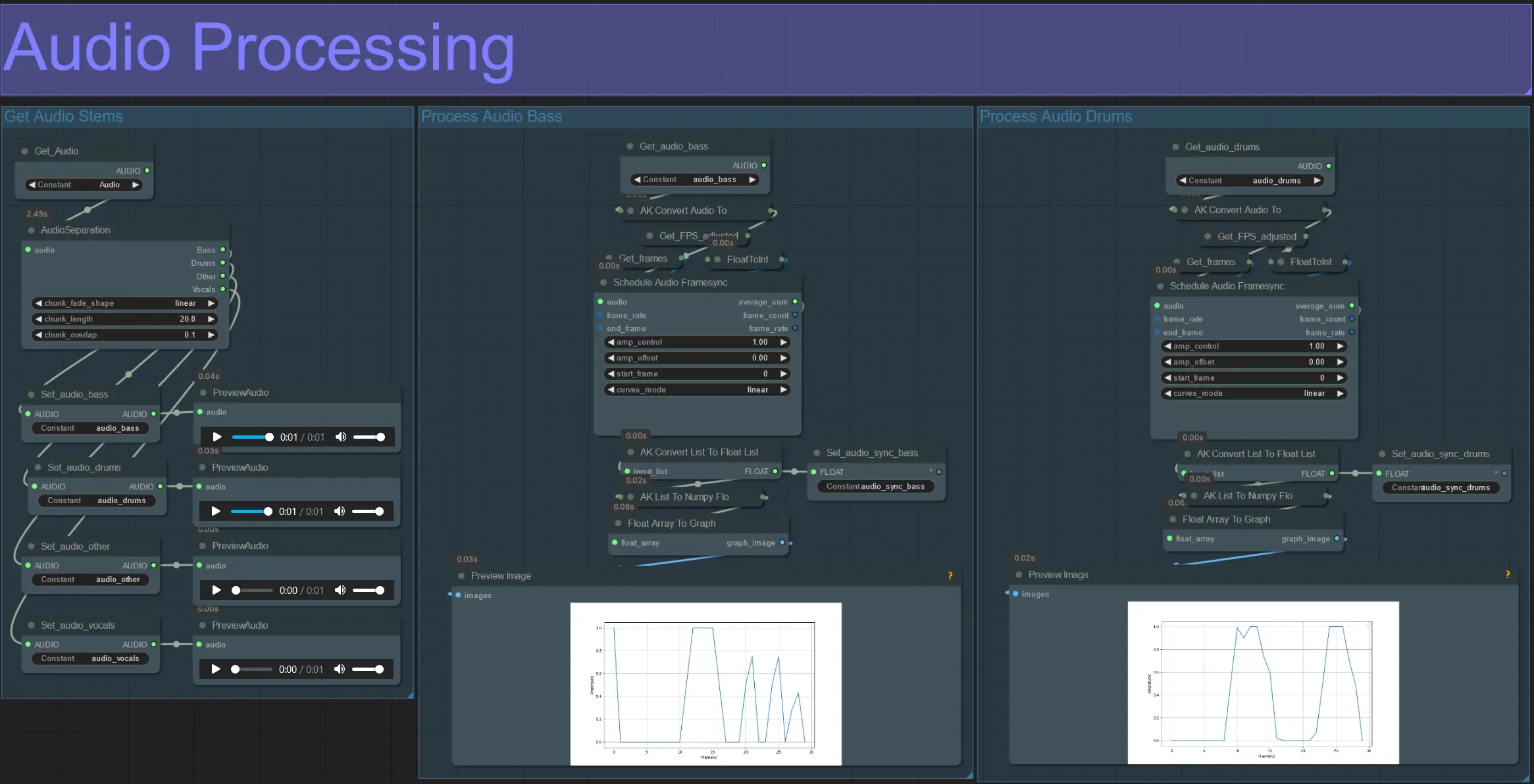
- Dieser Abschnitt nimmt Audio aus dem Eingabevideo auf, extrahiert die Stems (Bass, Schlagzeug, Gesang usw.) und wandelt sie in eine normalisierte Amplitude um, die mit den Frames des Eingabevideos synchronisiert ist.
- amp_control = Gesamtbereich, den die Amplitude durchlaufen kann.
- amp_offset = der Mindestwert, den die Amplitude annehmen kann.
- Beispiel: amp_control = 0.8 und amp_offset = 0.2 bedeutet, dass das Signal zwischen 0.2 und 1.0 schwankt.
- Manchmal enthält der Schlagzeug-Stem die eigentlichen Bassnoten des Songs; Vorschau jedes Stems, um zu bestimmen, welches am besten für Ihre Masken geeignet ist.
- Verwenden Sie die Diagramme, um ein klares Verständnis dafür zu gewinnen, wie sich das Signal für diesen Stem im Verlauf des Videos ändert.
Masken erweitern
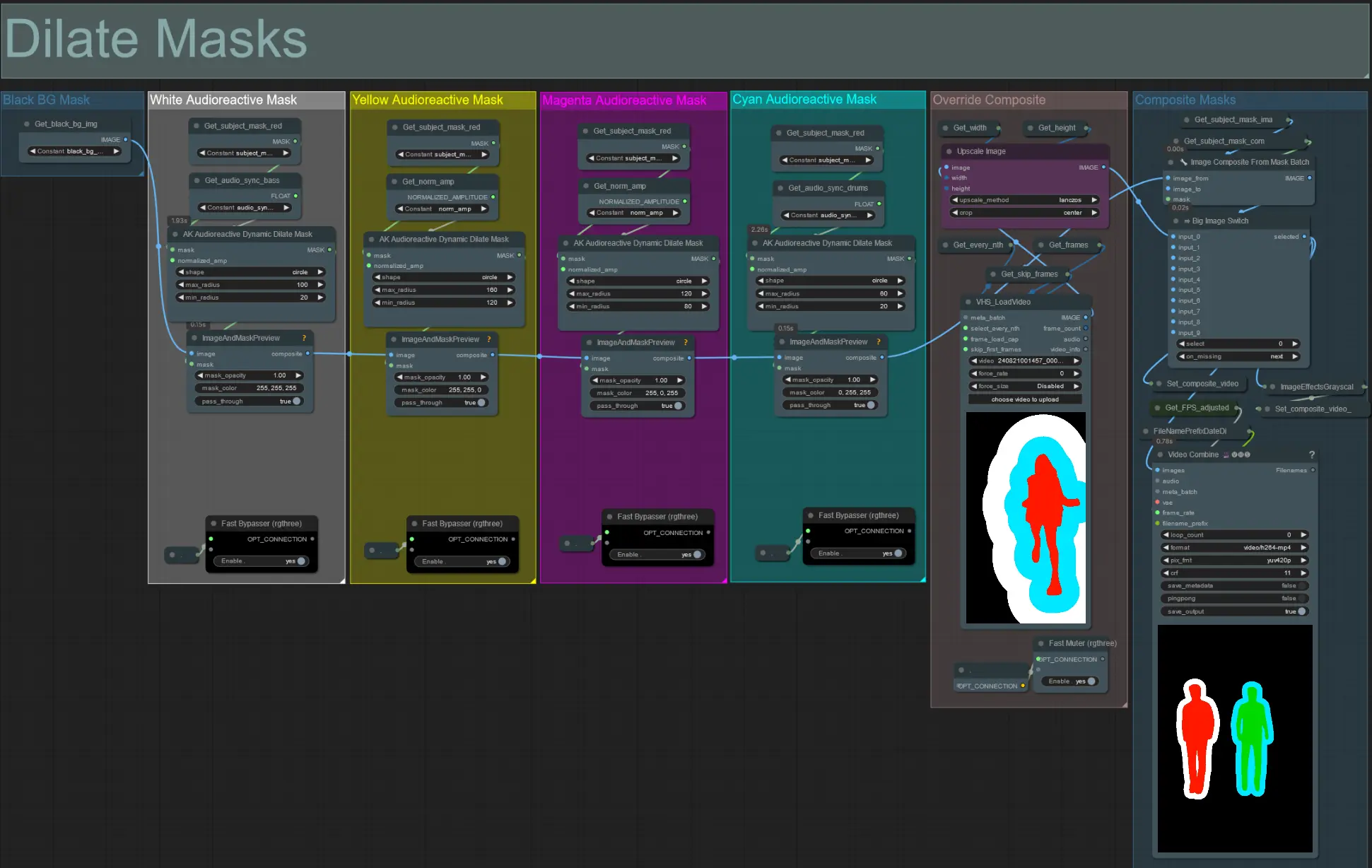
- Jede farbige Gruppe entspricht der Farbe der Dilationsmaske, die dadurch erzeugt wird.
- Legen Sie den minimalen und maximalen Radius der Dilationsmaske sowie ihre Form mithilfe des folgenden Knotens fest:
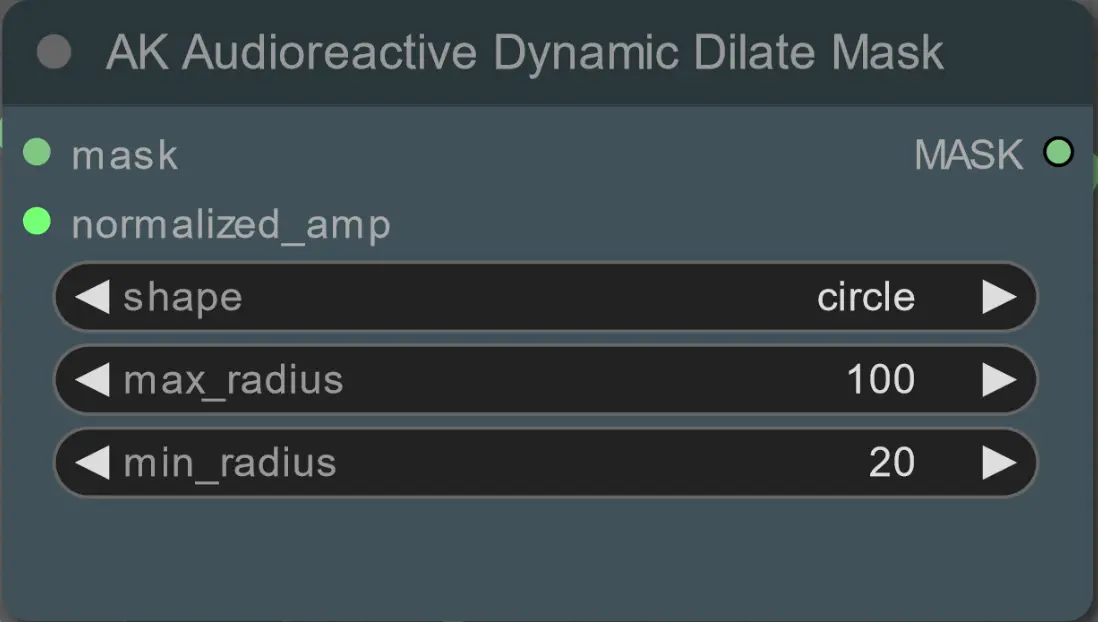
- Form: 'Kreis' ist am genauesten, benötigt aber länger zur Generierung. Stellen Sie dies ein, wenn Sie bereit sind, das endgültige Rendering durchzuführen. 'Quadrat' ist schnell zu berechnen, aber weniger genau, am besten zum Testen des Workflows und zum Entscheiden über IP-Adapter-Bilder.
- max_radius: Der Maskenradius in Pixeln, wenn der Amplitudenwert maximal ist (1.0).
- min_radius: Der Maskenradius in Pixeln, wenn der Amplitudenwert minimal ist (0.0).
- Wenn Sie bereits ein zusammengesetztes Maskenvideo generiert haben, können Sie die Stummschaltung der Gruppe 'Override Composite Mask' aufheben und es hochladen. Es wird empfohlen, die Dilationsmaskengruppen zu umgehen, wenn überschrieben wird, um Verarbeitungszeit zu sparen.
Modelle
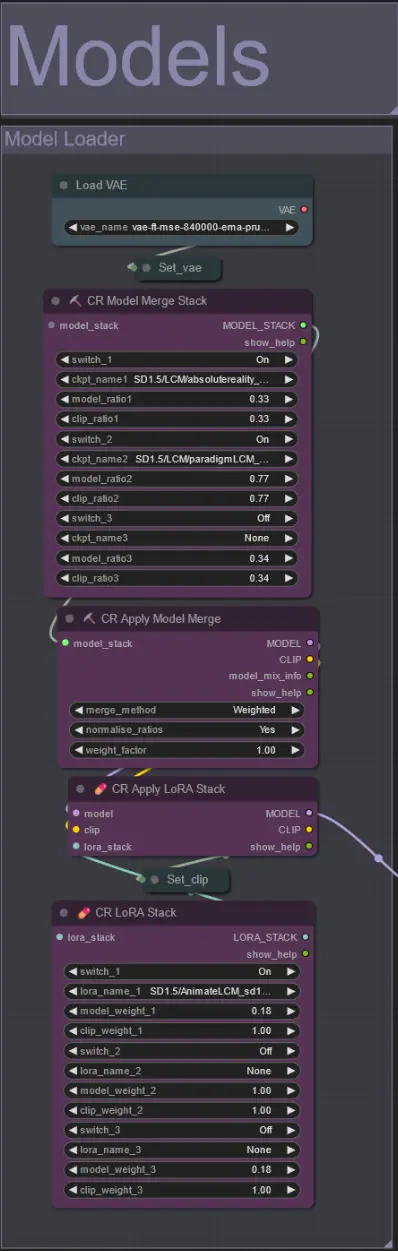
- Verwenden Sie ein gutes LCM-Modell für den Checkpoint. Ich empfehle ParadigmLCM von Machine Delusions.
- Kombinieren Sie mehrere Modelle mithilfe des Model Merge Stack, um verschiedene interessante Effekte zu erzielen. Stellen Sie sicher, dass die Gewichte für die aktivierten Modelle insgesamt 1.0 ergeben.
- Optional können Sie das AnimateLCM_sd15_t2v_lora.safetensors mit einem niedrigen Gewicht von 0.18 angeben, um das Endergebnis weiter zu verbessern.
- Fügen Sie dem Modell mithilfe des Lora-Stackers unterhalb des Modellladers beliebige zusätzliche Loras hinzu.
AnimateDiff

- Setzen Sie ein anderes Motion Lora anstelle des von mir verwendeten (LiquidAF-0-1.safetensors)
- Erhöhen/Verkleinern Sie die Scale- und Effect-Floats, um die Menge an Bewegung im Ausgang zu erhöhen/verringern.
IP-Adapter
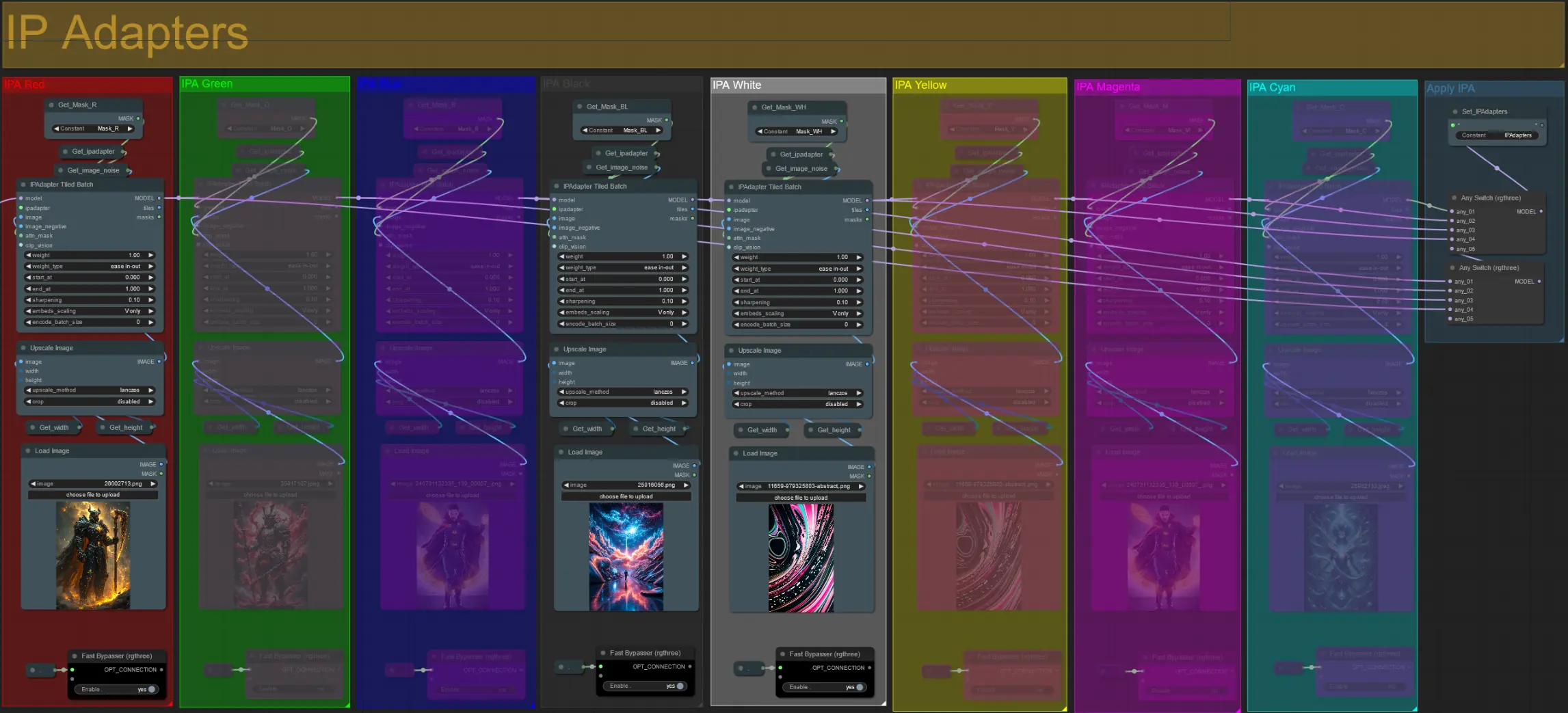
- Hier können Sie die Referenzbilder angeben, die zum Rendern der Hintergründe für jede der Dilationsmasken sowie Ihre Videomotive verwendet werden.
- Die Farbe jeder Gruppe repräsentiert die Maske, die sie anvisiert:
Rot, Grün, Blau:
- Referenzbilder der Motivmaske.
Schwarz:
- Hintergrundmaskenbild, laden Sie ein Referenzbild für den Hintergrund hoch.
Weiß, Gelb, Magenta, Cyan:
- Referenzbilder der Dilationsmasken, laden Sie ein Referenzbild für jede verwendete Farbdilationsmaske hoch.
ControlNet
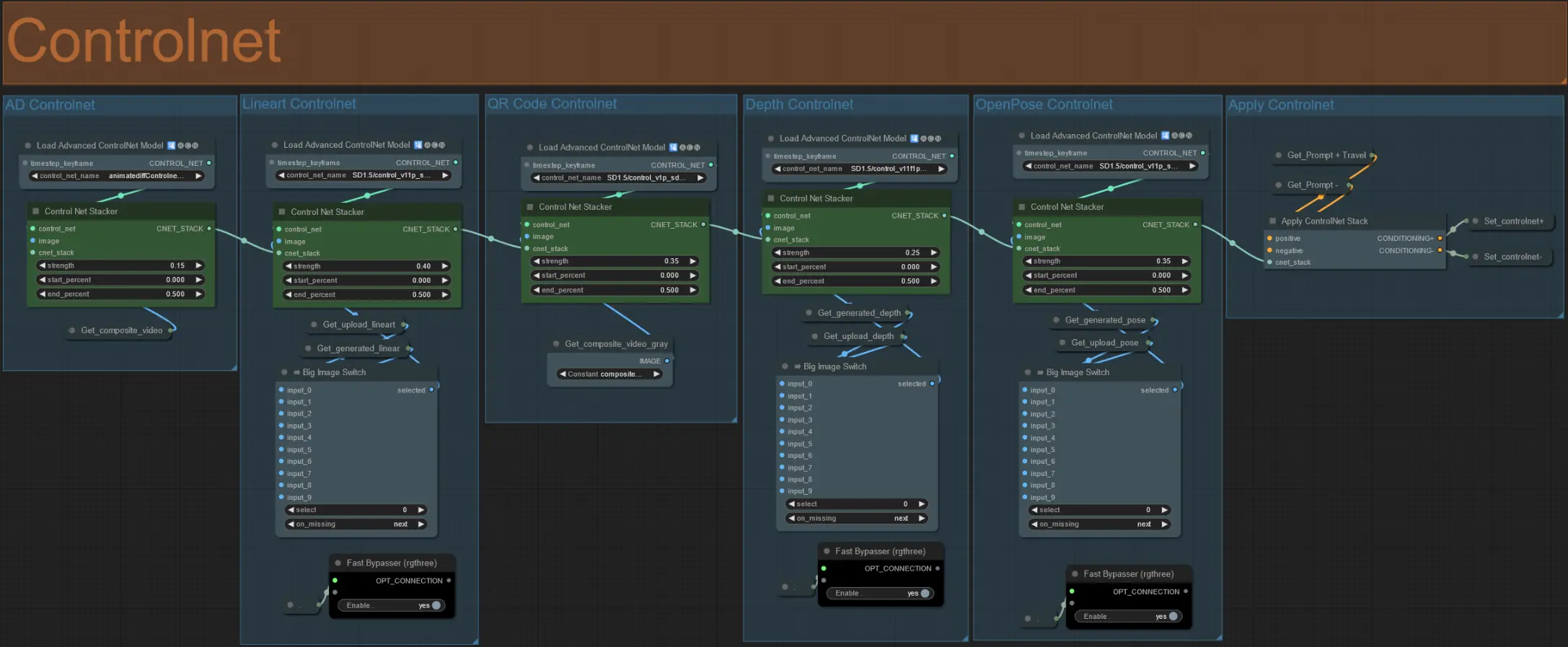
- Dieser Workflow nutzt 5 verschiedene Controlnets, einschließlich AD, Lineart, QR Code, Depth und OpenPose.
- Alle Eingaben zu den Controlnets werden automatisch generiert
- Sie können wählen, das Eingabevideo für die Lineart-, Depth- und Openpose-Controlnets zu überschreiben, wenn gewünscht, indem Sie die 'Override'-Gruppen aufheben, wie unten zu sehen:
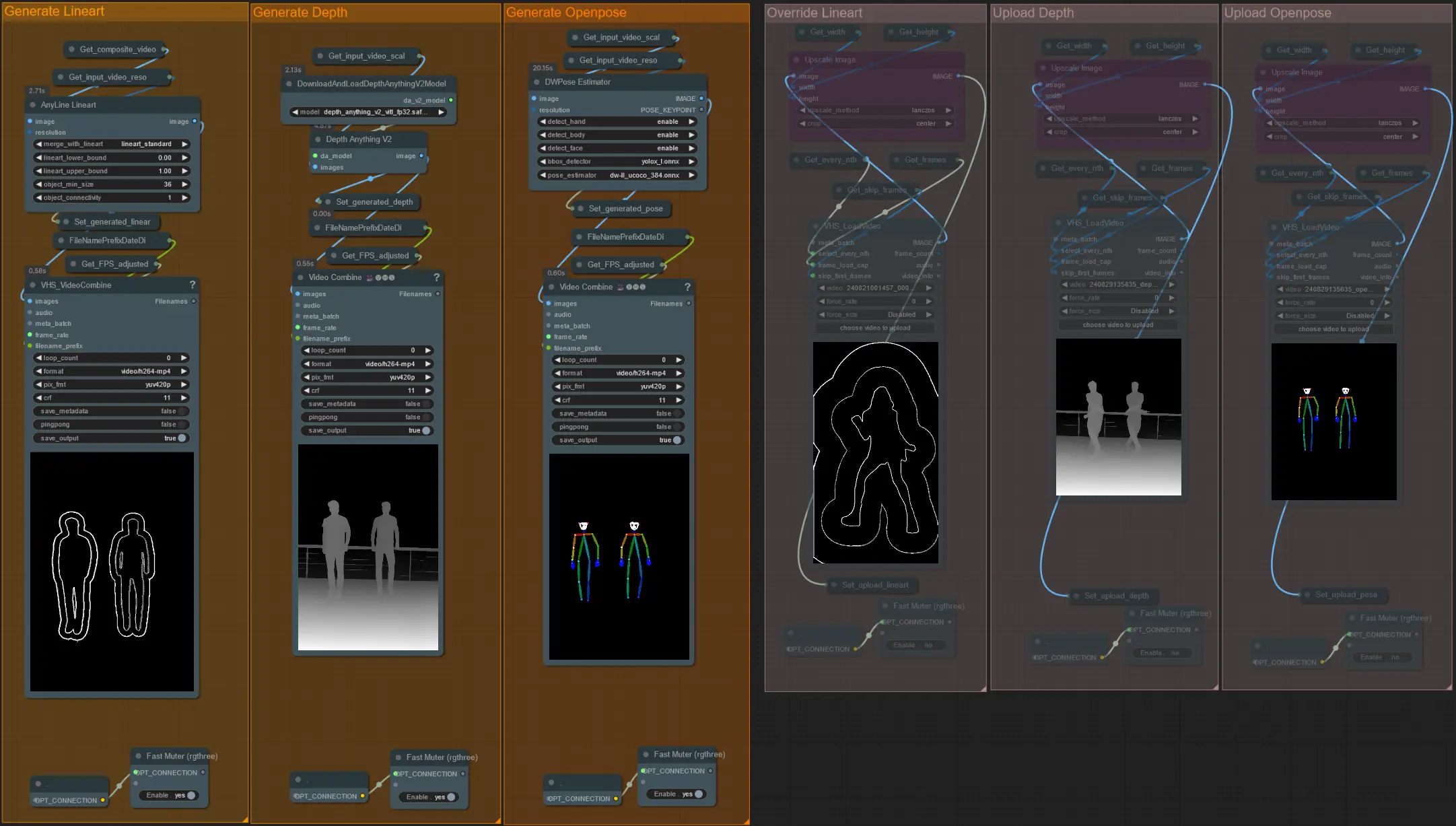
- Es wird empfohlen, auch die 'Generate'-Gruppen stummzuschalten, wenn überschrieben wird, um Verarbeitungszeit zu sparen.
Tipp:
- Umgehen Sie den Ksampler und starten Sie ein Rendering mit Ihrem vollständigen Eingabevideo. Sobald alle Vorverarbeitungsvideos generiert sind, speichern Sie sie und laden Sie sie in die jeweiligen Überschreibungen hoch. Von nun an müssen Sie beim Testen des Workflows nicht mehr warten, bis jedes Vorverarbeitungsvideo einzeln generiert wird.
Sampler
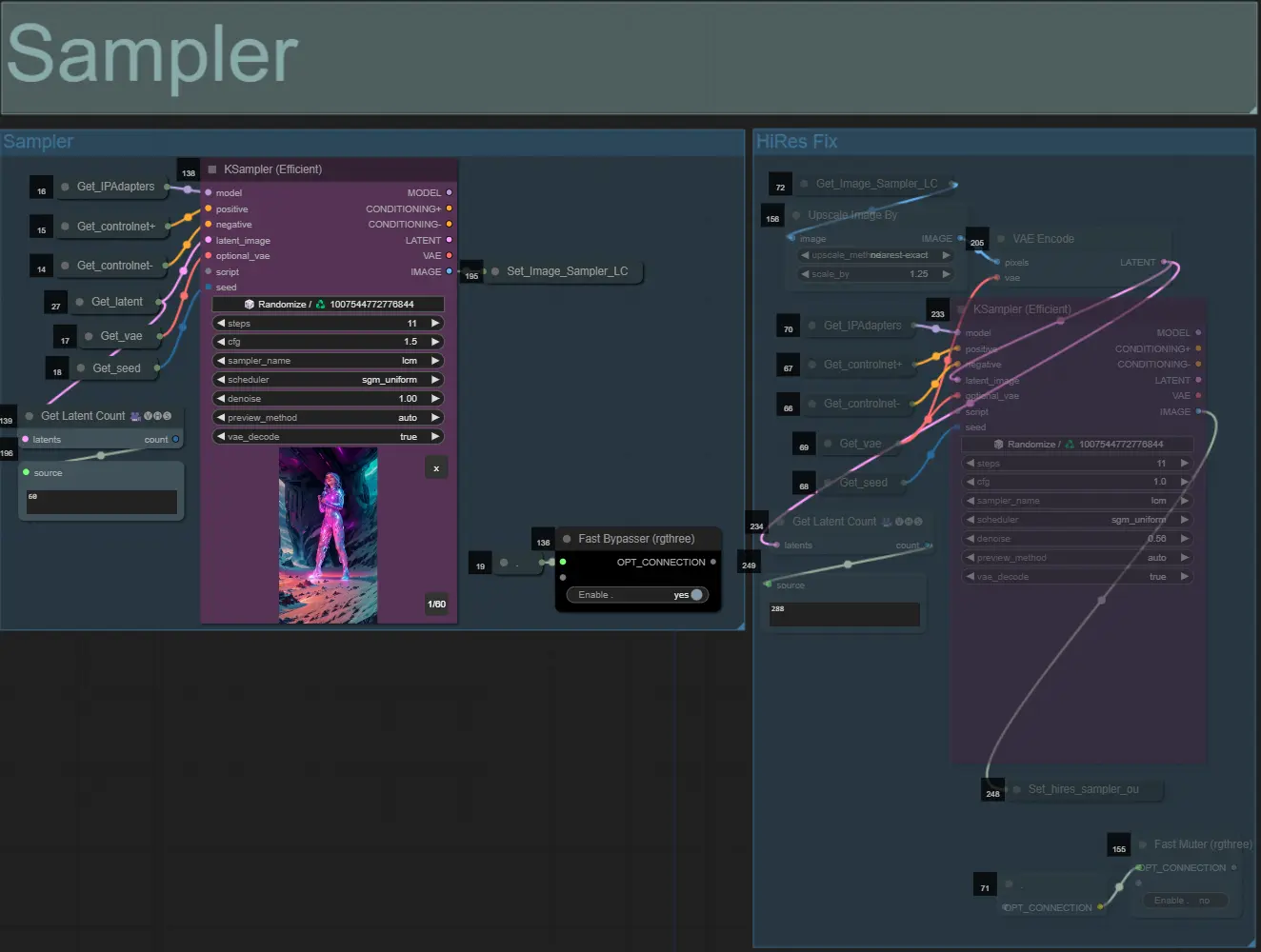
- Standardmäßig wird die HiRes Fix-Sampler-Gruppe stummgeschaltet, um Verarbeitungszeit beim Testen zu sparen
- Ich empfehle, die Sampler-Gruppe ebenfalls zu umgehen, wenn Sie mit den Einstellungen der Dilationsmaske experimentieren, um Zeit zu sparen.
- Bei endgültigen Renderings können Sie die HiRes Fix-Gruppe aufheben, die das Endergebnis hochskaliert und Details hinzufügt.
Ausgabe

- Es gibt zwei Ausgabengruppen: die linke ist für die Standard-Sampler-Ausgabe und die rechte für die HiRes Fix-Sampler-Ausgabe.
Über den Autor
Akatz AI:
- Website:
- http://patreon.com/Akatz
- https://civitai.com/user/akatz
- https://www.youtube.com/@akatz_ai
- https://www.instagram.com/akatz.ai/
- https://www.tiktok.com/@akatz_ai
- https://x.com/akatz_ai
- https://github.com/akatz-ai
Kontakte:
- Email: akatz.hello@gmail.com



