Linear Mask Dilation | Atemberaubende Animationen
ComfyUI Linear Mask Dilation ist ein leistungsstarker Workflow zur Erstellung atemberaubender Videoanimationen. Indem Sie Ihr Motiv, wie einen Tänzer, transformieren, können Sie es nahtlos durch verschiedene Szenen reisen lassen, indem Sie einen Maskenvergrößerungseffekt verwenden. Dieser Workflow ist speziell für Videos mit einem einzelnen Motiv konzipiert. Folgen Sie der Schritt-für-Schritt-Anleitung, um zu lernen, wie Sie Linear Mask Dilation effektiv nutzen, vom Hochladen Ihres Motivvideos bis hin zum Setzen von Prompts und Anpassen verschiedener Parameter für optimale Ergebnisse. Entfesseln Sie Ihre Kreativität und erwecken Sie Ihre Videoanimationen mit ComfyUI Linear Mask Dilation zum Leben.ComfyUI Linear Mask Dilation Arbeitsablauf
Möchtest du diesen Workflow ausführen?
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI Linear Mask Dilation Beispiele
ComfyUI Linear Mask Dilation Beschreibung
ComfyUI Linear Mask Dilation
Erstellen Sie atemberaubende Videoanimationen, indem Sie Ihr Motiv (Tänzer) transformieren und es mithilfe eines Maskenvergrößerungseffekts durch verschiedene Szenen reisen lassen. Dieser Workflow ist für Videos mit einem einzelnen Motiv konzipiert.
So verwenden Sie den ComfyUI Linear Mask Dilation Workflow:
- Laden Sie ein Motivvideo im Eingabebereich hoch
- Wählen Sie die gewünschte Breite und Höhe des endgültigen Videos sowie die Anzahl der Frames des Eingabevideos, die mit "every_nth" übersprungen werden sollen. Sie können auch die Gesamtanzahl der zu rendernden Frames mit "frame_load_cap" begrenzen.
- Füllen Sie den positiven und negativen Prompt aus. Stellen Sie die Batch-Frame-Zeiten ein, um festzulegen, wann die Szenenübergänge stattfinden sollen.
- Laden Sie Bilder für jede der IP Adapter-Maskenfarben des Motivs hoch:
- Weiß = Motiv (Tänzer)
- Schwarz = Erster Hintergrund
- Rot = Roter Maskenvergrößerungshintergrund
- Grün = Grüner Maskenvergrößerungshintergrund
- Blau = Blauer Maskenvergrößerungshintergrund
- Laden Sie einen guten LCM-Checkpoint (ich verwende ParadigmLCM von Machine Delusions) im Abschnitt "Models".
- Fügen Sie beliebige Loras mithilfe des Lora-Stackers unter dem Modell-Loader hinzu
- Klicken Sie auf "Queue Prompt"
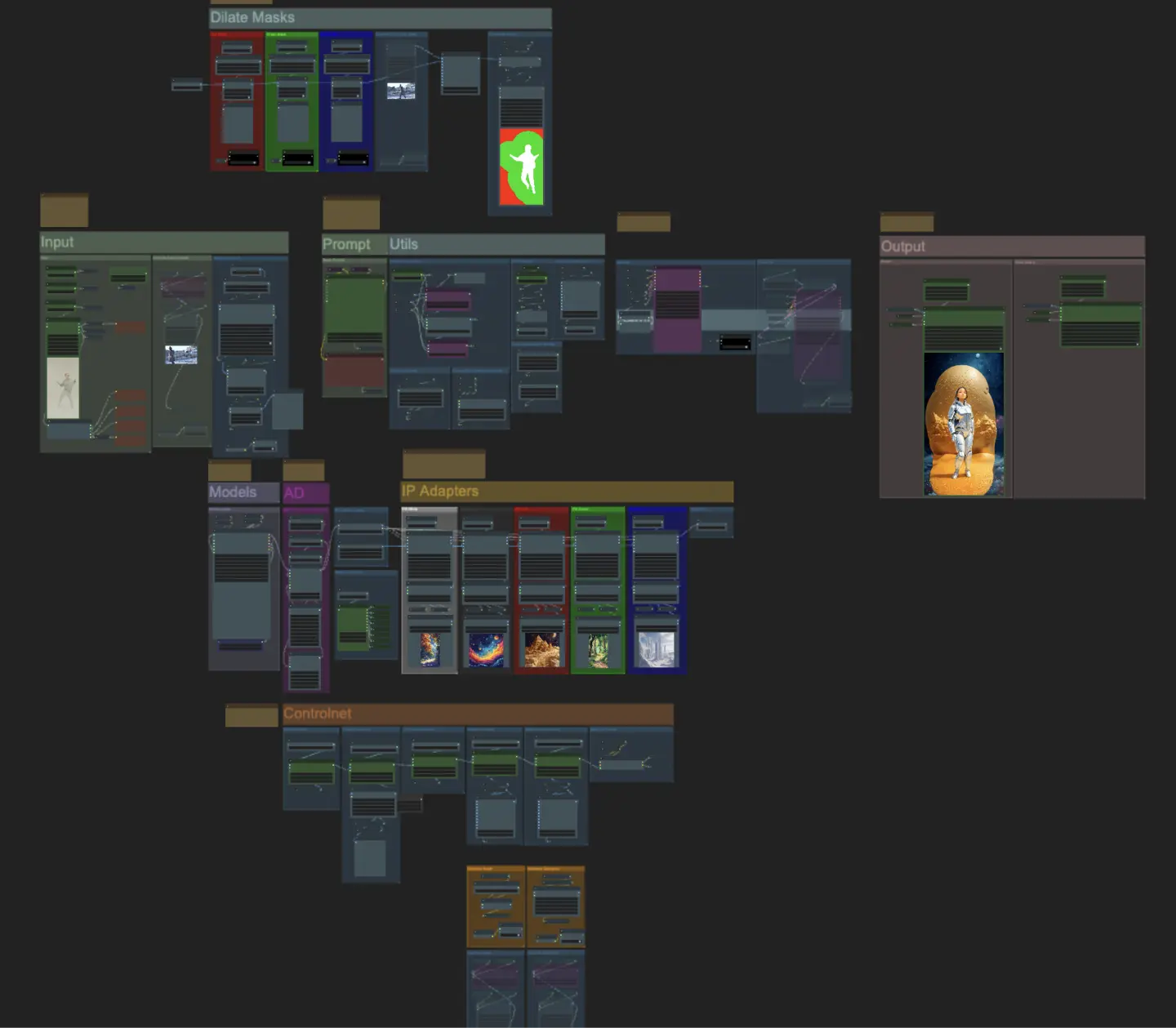
Input
- Sie können die Breite und Höhe mit den beiden Eingaben oben links anpassen
- "every_nth" legt fest, wie viele Frames des Eingangs übersprungen werden sollen (2 = jeder zweite Frame)
- Die Zahlenfelder unten links zeigen Informationen über das hochgeladene Eingabevideo an: Gesamtframes, Breite, Höhe und FPS von oben nach unten.
- Wenn Sie bereits ein Maskenvideo des Motivs generiert haben (muss weißes Motiv auf schwarzem Hintergrund sein), können Sie den Abschnitt "Override Subject Mask" aktivieren und das Maskenvideo hochladen. Optional können Sie den Abschnitt "Segment Subject" deaktivieren, um etwas Verarbeitungszeit zu sparen.
- Manchmal ist das segmentierte Motiv nicht perfekt, Sie können die Maskenqualität mithilfe des Vorschaukastens unten rechts überprüfen. Wenn dies der Fall ist, können Sie im "Florence2Run"-Knoten mit dem Prompt spielen, um verschiedene Körperteile wie "Kopf", "Brust", "Beine" usw. zu zielen und zu sehen, ob Sie ein besseres Ergebnis erzielen.
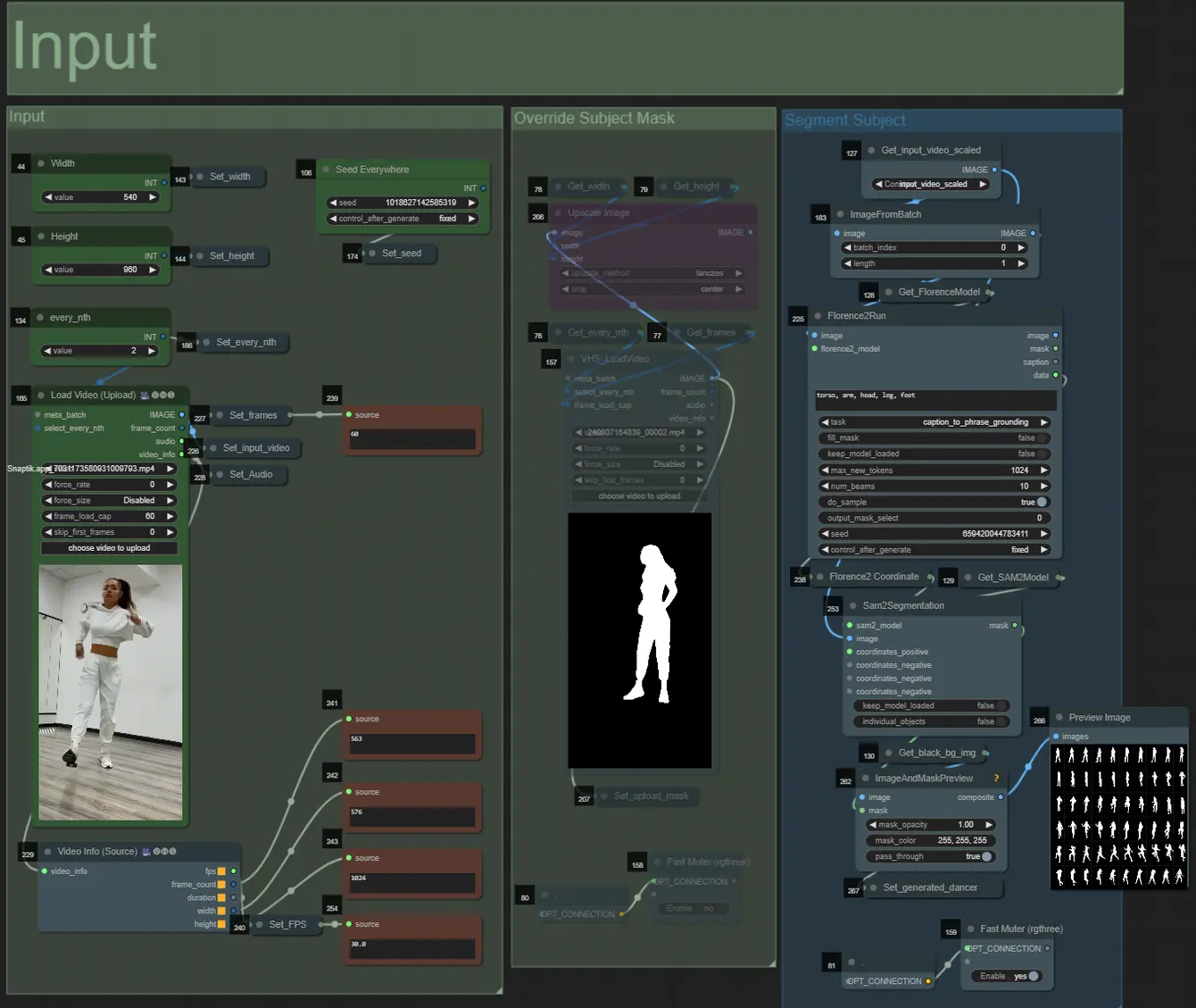
Prompt
- Setzen Sie den positiven Prompt mithilfe der Batch-Formatierung:
- z.B. "0": "4k, Meisterwerk, 1 Mädchen, das am Strand steht, absurdres", "25": "HDR, Sonnenuntergangsszene, 1 Mädchen mit schwarzen Haaren und einer weißen Jacke, absurdres", …
- Negativer Prompt im normalen Format, Sie können Einbettungen hinzufügen, wenn gewünscht.
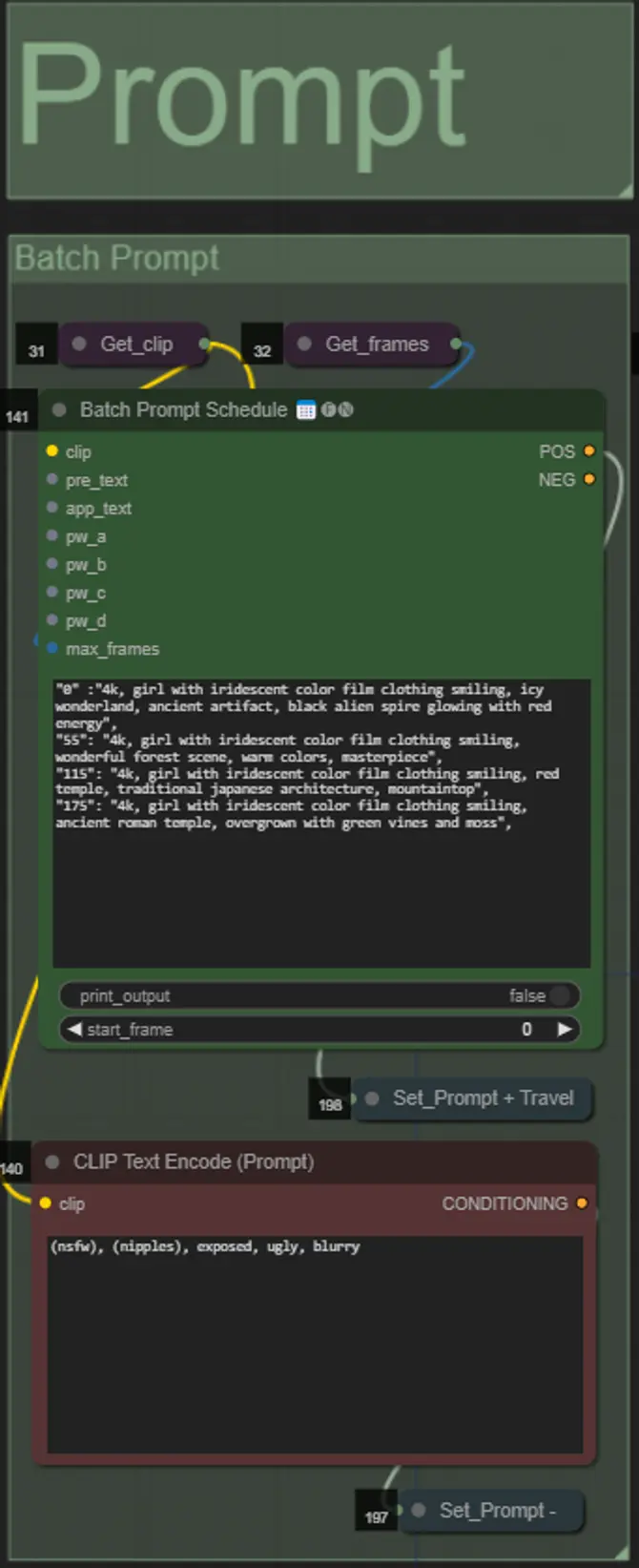
Mask Dilations
- Jede farbige Gruppe entspricht der Farbe der Maskenvergrößerung, die dadurch generiert wird.
- Sie können die Form der Maske zusammen mit der Geschwindigkeit der Vergrößerung und der Frame-Verzögerung mit dem folgenden Knoten einstellen:
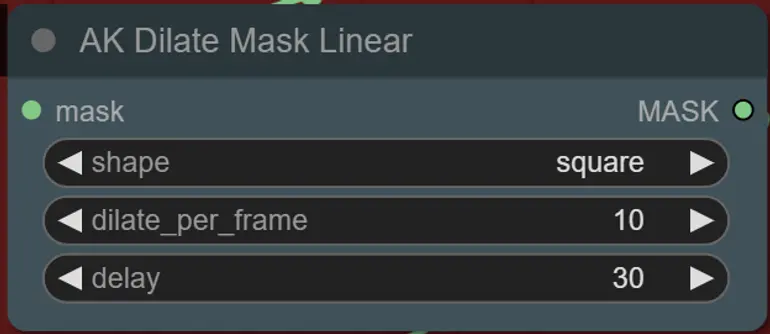
- Form: "Kreis" ist am genauesten, benötigt jedoch länger zur Generierung. Stellen Sie dies ein, wenn Sie bereit sind, das endgültige Rendering durchzuführen. "Quadrat" ist schnell zu berechnen, aber weniger genau, am besten geeignet, um den Workflow zu testen und IP Adapter-Bilder auszuwählen.
- dilate_per_frame: Wie schnell die Maske vergrößert werden soll, größere Zahlen = schnellere Vergrößerungsgeschwindigkeit
- Verzögerung: Wie viele Frames gewartet werden sollen, bevor die Maske zu vergrößern beginnt.
- Wenn Sie bereits ein zusammengesetztes Maskenvideo generiert haben, können Sie die Gruppe "Override Composite Mask" aktivieren und es hochladen. Es wird empfohlen, die Maskenvergrößerungsgruppen zu umgehen, wenn überschrieben wird, um Verarbeitungszeit zu sparen.
Models
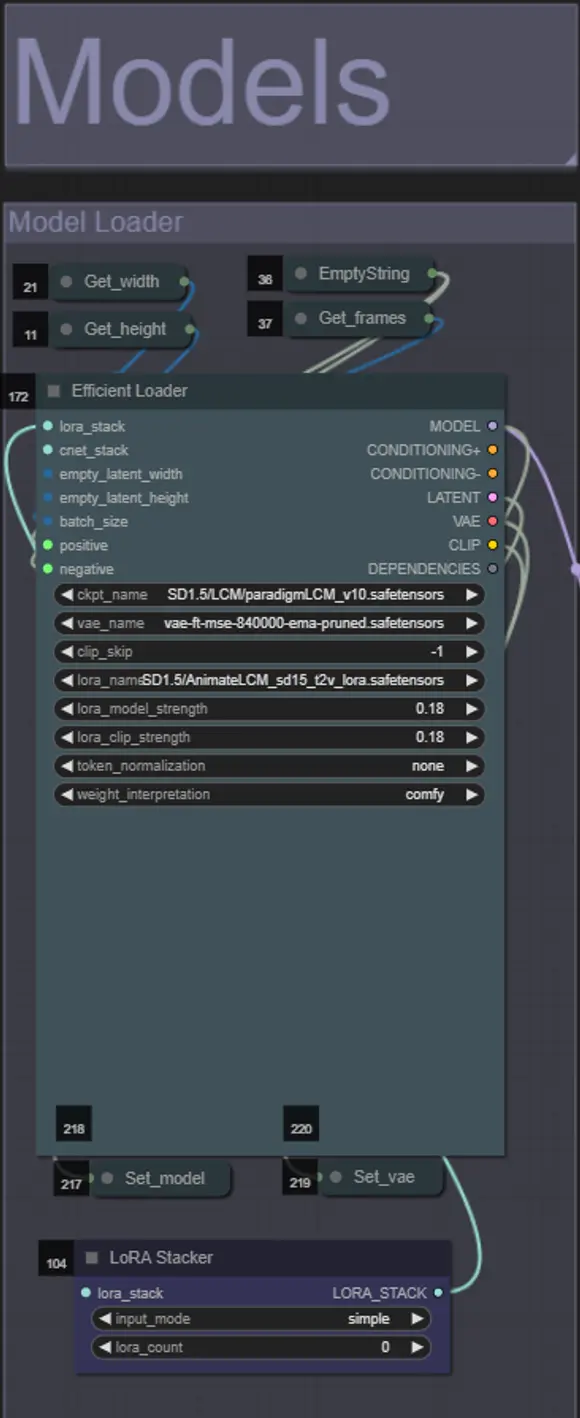
- Verwenden Sie ein gutes LCM-Modell für den Checkpoint. Ich empfehle ParadigmLCM von Machine Delusions.
- Sie können optional die AnimateLCM_sd15_t2v_lora.safetensors mit einem niedrigen Gewicht von 0.18 angeben, um das Endergebnis weiter zu verbessern.
- Fügen Sie dem Modell mithilfe des blauen Lora-Stackers unter dem Modell-Loader beliebige zusätzliche Loras hinzu.
AnimateDiff
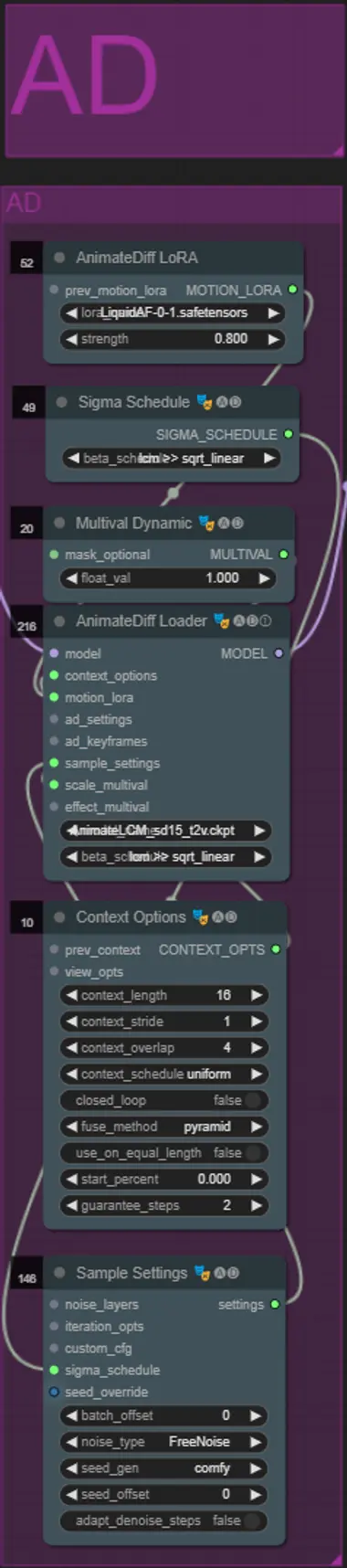
- Sie können ein anderes Motion Lora anstelle des von mir verwendeten (LiquidAF-0-1.safetensors) einstellen
- Passen Sie den Multival Dynamic float-Wert höher oder niedriger an, je nachdem, ob Sie möchten, dass das Ergebnis mehr oder weniger Bewegung hat.
IP Adapters
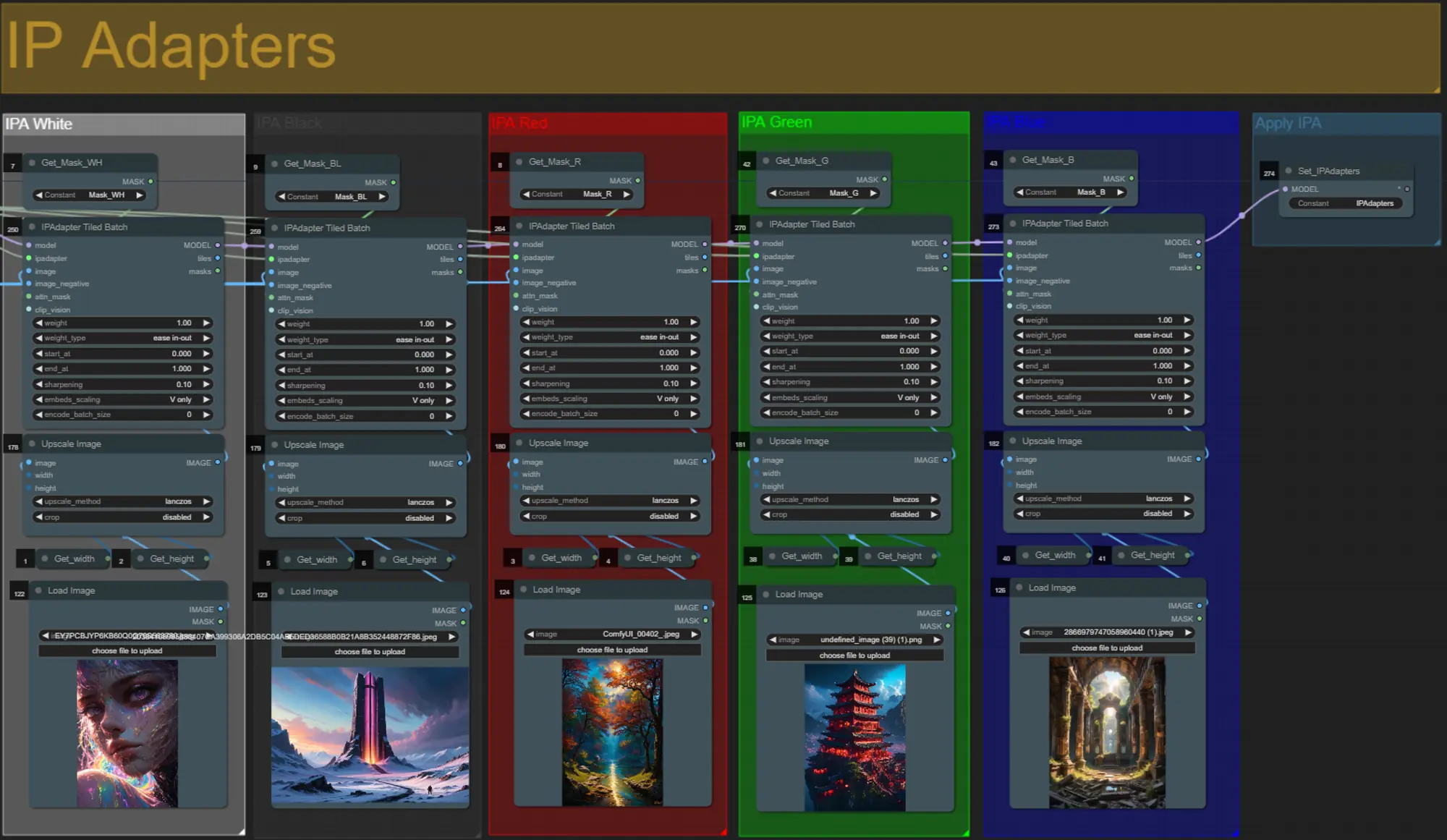
- Hier können Sie die Referenzmotive angeben, die verwendet werden, um die Hintergründe für jede der Maskenvergrößerungen sowie Ihr Videomotiv zu rendern.
- Die Farbe jeder Gruppe repräsentiert die Maske, die sie anvisiert:
- Weiß = Motiv (Tänzer)
- Schwarz = Erster Hintergrund
- Rot = Roter Maskenvergrößerungshintergrund
- Grün = Grüner Maskenvergrößerungshintergrund
- Blau = Blauer Maskenvergrößerungshintergrund
- Wenn Sie möchten, dass das endgültige Rendering den Eingangs-IP Adapter-Bildern genauer folgt, können Sie das IPAdapter-Preset von VIT-G auf PLUS im IPA Unified Loader-Gruppe ändern.
ControlNet
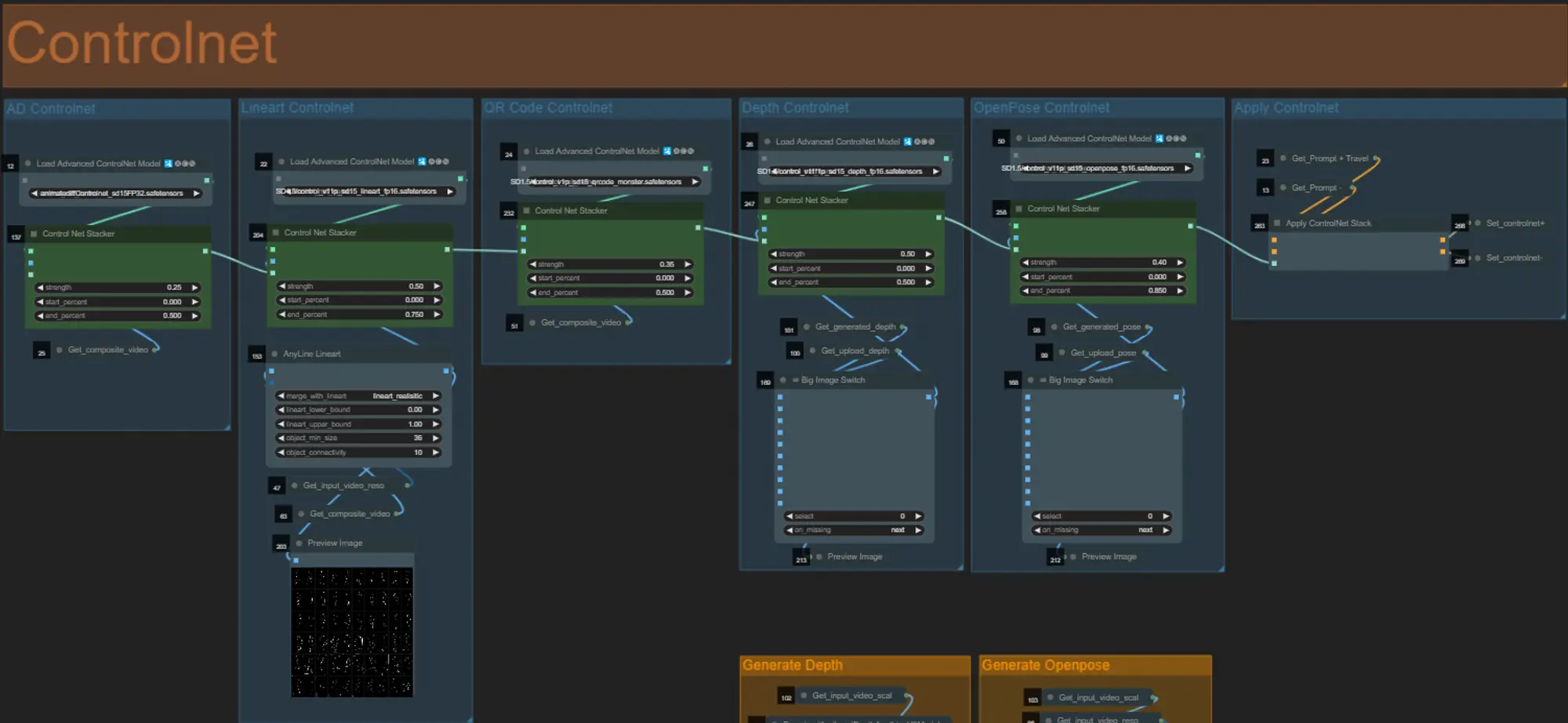
- Dieser Workflow verwendet 5 verschiedene Controlnets, darunter AD, Lineart, QR Code, Depth und OpenPose.
- Alle Eingaben in die Controlnets werden automatisch generiert
- Sie können wählen, das Eingabevideo für die Depth- und OpenPose-Controlnets zu überschreiben, indem Sie die Gruppen "Override Depth" und "Override Openpose" wie unten gezeigt aktivieren:
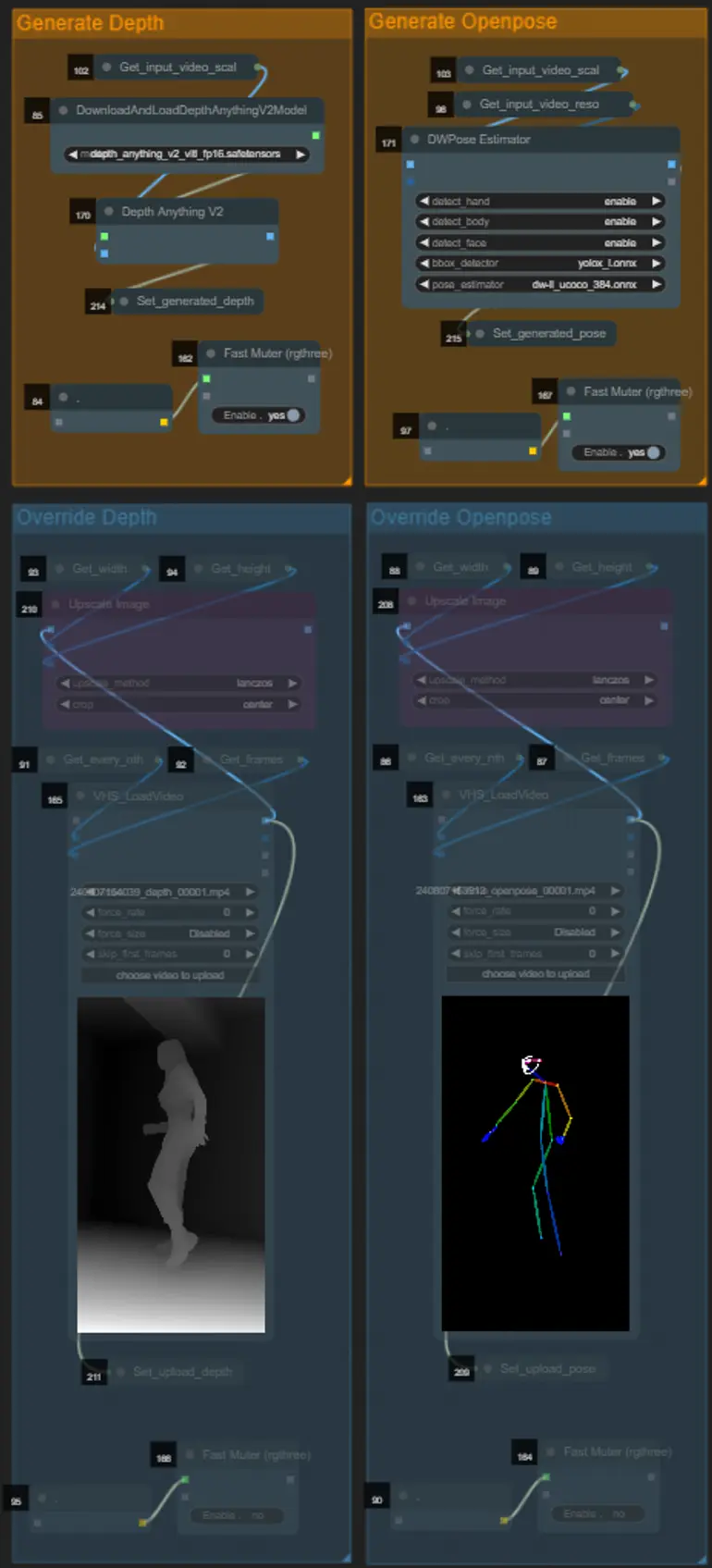
- Es wird empfohlen, die Gruppen "Generate Depth" und "Generate Openpose" zu deaktivieren, wenn überschrieben wird, um Verarbeitungszeit zu sparen.
Sampler
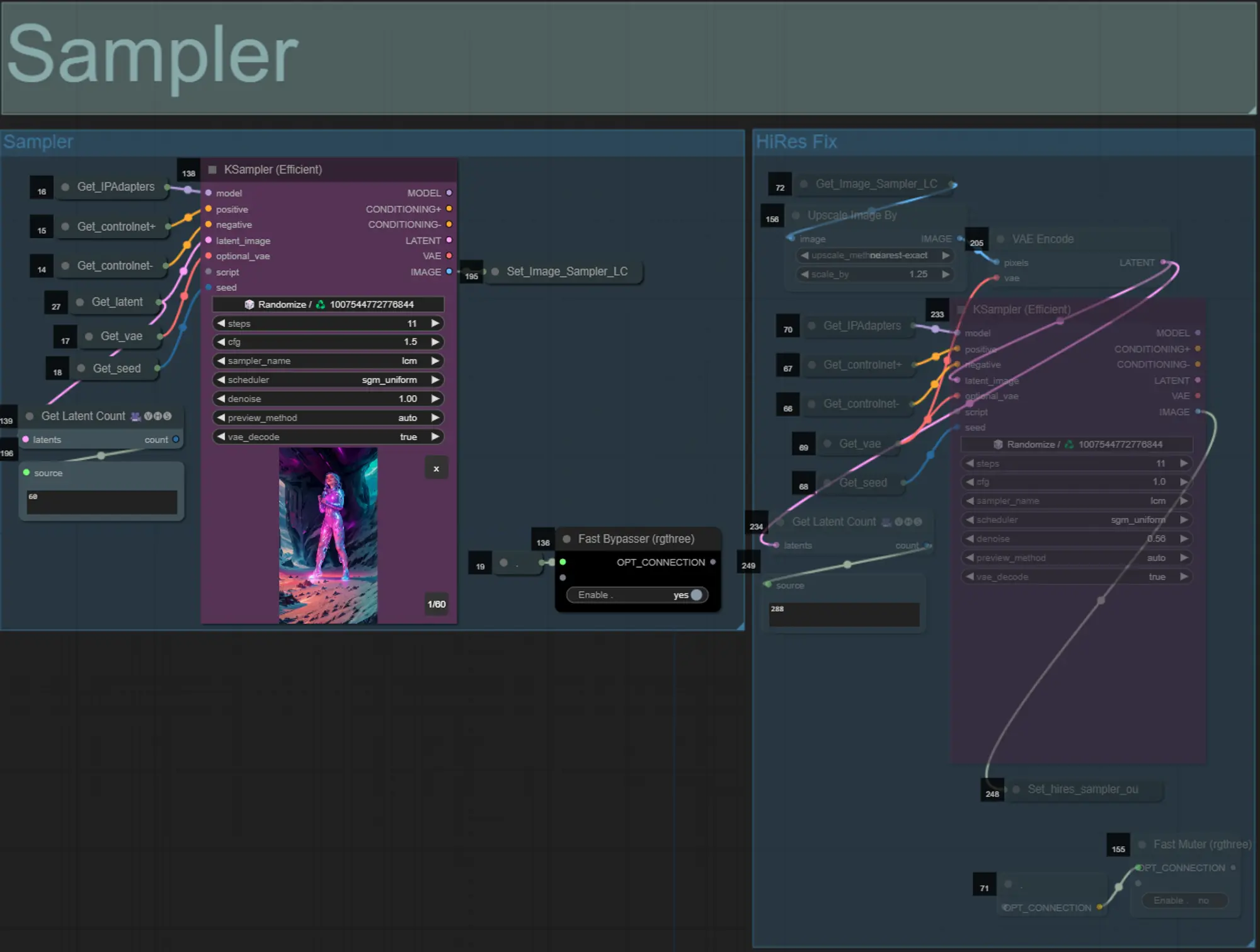
- Standardmäßig wird die HiRes Fix Sampler-Gruppe deaktiviert, um Verarbeitungszeit beim Testen zu sparen
- Ich empfehle, die Sampler-Gruppe auch zu umgehen, wenn Sie mit den Einstellungen der Maskenvergrößerung experimentieren, um Zeit zu sparen.
- Bei endgültigen Renderings können Sie die HiRes Fix Gruppe aktivieren, die das Endergebnis hochskaliert und Details hinzufügt.
Output

- Es gibt zwei Ausgabengruppen: links für die Standard-Sampler-Ausgabe und rechts für die HiRes Fix Sampler-Ausgabe.
- Sie können den Speicherort der Dateien ändern, indem Sie die Zeichenfolge "custom_directory" in den "FileNamePrefixDateDirFirst"-Knoten ändern. Standardmäßig speichert dieser Knoten Ausgabenvideos in einem mit Zeitstempel versehenen Verzeichnis im ComfyUI "output"-Verzeichnis
- z.B. …/ComfyUI/output/240812/
<custom_directory>/<my_video>.mp4
- z.B. …/ComfyUI/output/240812/
Über den Autor
Akatz AI:
- Website:
- https://www.youtube.com/@akatz_ai
- https://www.instagram.com/akatz.ai/
- https://www.tiktok.com/@akatz_ai
- https://x.com/akatz_ai
- https://github.com/akatz-ai
Kontakte:
- Email: akatzfey@sendysoftware.com



