
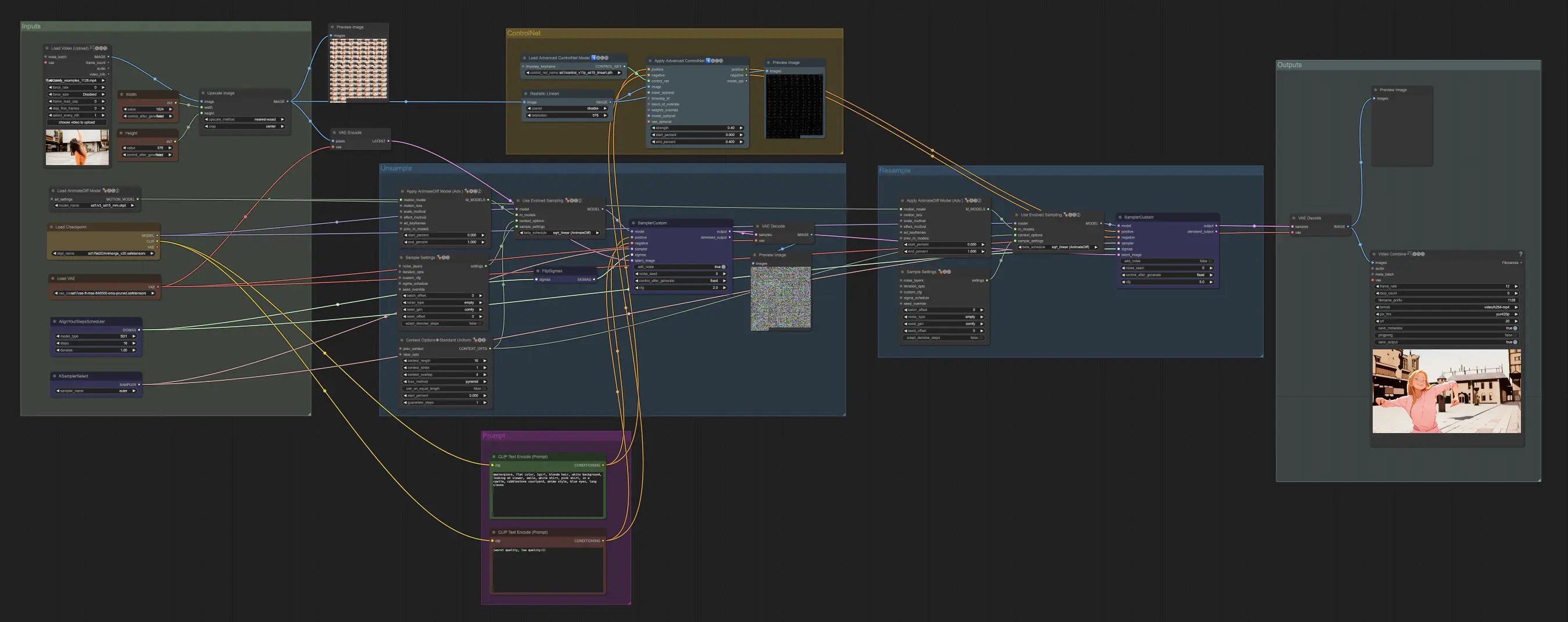
Dieser Unsampling-Leitfaden, geschrieben von Inner-Reflections, trägt maßgeblich zur Erforschung der Unsampling-Methode für dramatisch konsistenten Video-Stiltransfer bei.
1. Einführung: Latentes Rauschmanagement mit Unsampling#
Latentes Rauschen ist die Grundlage für alles, was wir mit Stable Diffusion tun. Es ist erstaunlich, einen Schritt zurückzutreten und darüber nachzudenken, was wir damit erreichen können. Im Allgemeinen sind wir jedoch gezwungen, eine Zufallszahl zu verwenden, um das Rauschen zu erzeugen. Was wäre, wenn wir es steuern könnten?
Ich bin nicht der Erste, der Unsampling verwendet. Es ist schon sehr lange in Gebrauch und wurde auf verschiedene Arten verwendet. Bis jetzt war ich jedoch generell nicht mit den Ergebnissen zufrieden. Ich habe mehrere Monate damit verbracht, die besten Einstellungen zu finden, und ich hoffe, Sie genießen diesen Leitfaden.
Durch die Verwendung des Sampling-Prozesses mit AnimateDiff/Hotshot können wir Rauschen finden, das unser ursprüngliches Video repräsentiert und somit jede Art von Stiltransfer erleichtert. Es ist besonders hilfreich, Hotshot konsistent zu halten, da es ein 8-Frame-Kontextfenster hat.
Dieser Unsampling-Prozess konvertiert im Wesentlichen unser Eingabevideo in latentes Rauschen, das die Bewegung und Komposition des Originals beibehält. Wir können dieses repräsentative Rauschen dann als Ausgangspunkt für den Diffusionsprozess verwenden, anstatt zufälliges Rauschen. Dies ermöglicht es der KI, den Zielstil anzuwenden und gleichzeitig die zeitliche Konsistenz zu wahren.
Dieser Leitfaden setzt voraus, dass Sie AnimateDiff und/oder Hotshot installiert haben. Wenn nicht, sind die Leitfäden hier verfügbar:
AnimateDiff: https://civitai.com/articles/2379
Hotshot XL guide: https://civitai.com/articles/2601/
Link to resource - Wenn Sie Videos auf Civitai mit diesem Workflow posten möchten: https://civitai.com/models/544534
2. Systemanforderungen für diesen Workflow#
Ein Windows-Computer mit einer NVIDIA-Grafikkarte, die mindestens 12 GB VRAM hat, wird empfohlen. Auf der RunComfy-Plattform verwenden Sie eine Medium-Maschine (16 GB VRAM) oder höher. Dieser Prozess erfordert nicht mehr VRAM als Standard-AnimateDiff- oder Hotshot-Workflows, dauert jedoch fast doppelt so lange, da der Diffusionsprozess im Wesentlichen zweimal läuft – einmal für das Upsampling und einmal für das Resampling mit dem Zielstil.
3. Knoten-Erklärungen und Einstellungsleitfaden#
Knoten: Custom Sampler#
Der Hauptteil davon ist die Verwendung des Custom Sampler, der alle Einstellungen, die Sie normalerweise im regulären KSampler sehen, in Stücke teilt:
Dies ist der Haupt-KSampler-Knoten – das Hinzufügen von Rauschen/Samen hat keine Wirkung (soweit ich weiß). Der CFG-Wert ist wichtig – im Allgemeinen gilt: Je höher der CFG-Wert in diesem Schritt ist, desto näher wird das Video an Ihrem Original aussehen. Ein höherer CFG-Wert zwingt den Unsampler, das Eingangsbild genauer zu entsprechen.
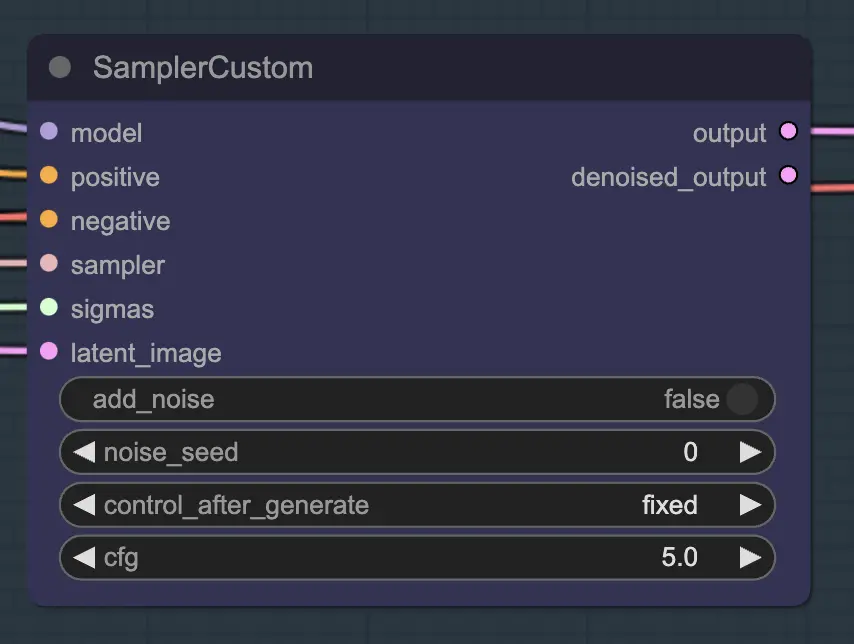
Knoten: KSampler Select#
Das Wichtigste ist, einen Sampler zu verwenden, der konvergiert! Deshalb verwenden wir euler statt euler a, da letzterer zu mehr Zufälligkeit/Instabilität führt. Ancestral Sampler, die in jedem Schritt Rauschen hinzufügen, verhindern, dass das Unsampling sauber konvergiert. Wenn Sie mehr darüber lesen möchten, finde ich immer diesen Artikel nützlich. @spacepxl auf reddit schlägt vor, dass DPM++ 2M Karras je nach Anwendungsfall der genauere Sampler ist.
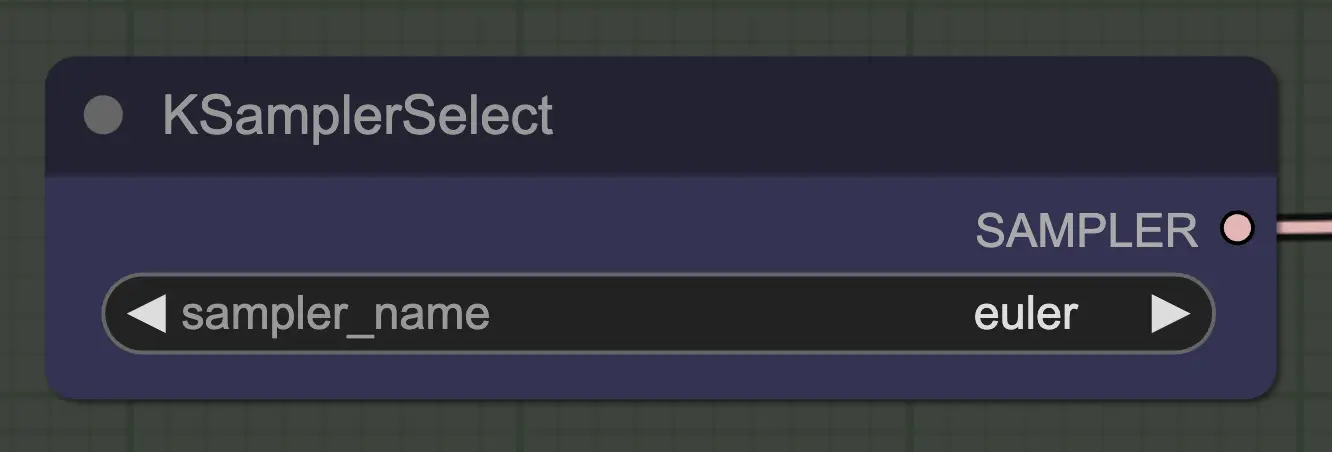
Knoten: Align Your Step Scheduler#
Jeder Scheduler funktioniert hier gut – Align Your Steps (AYS) erzielt jedoch gute Ergebnisse mit 16 Schritten, daher habe ich mich entschieden, diesen zu verwenden, um die Rechenzeit zu verkürzen. Mehr Schritte führen zu einer vollständigen Konvergenz, jedoch mit abnehmenden Erträgen.
Knoten: Flip Sigma#
Flip Sigma ist der magische Knoten, der das Unsampling verursacht! Durch das Umkehren des Sigma-Zeitplans kehren wir den Diffusionsprozess um, um von einem sauberen Eingangsbild zu repräsentativem Rauschen zu gelangen.
Knoten: Prompt#
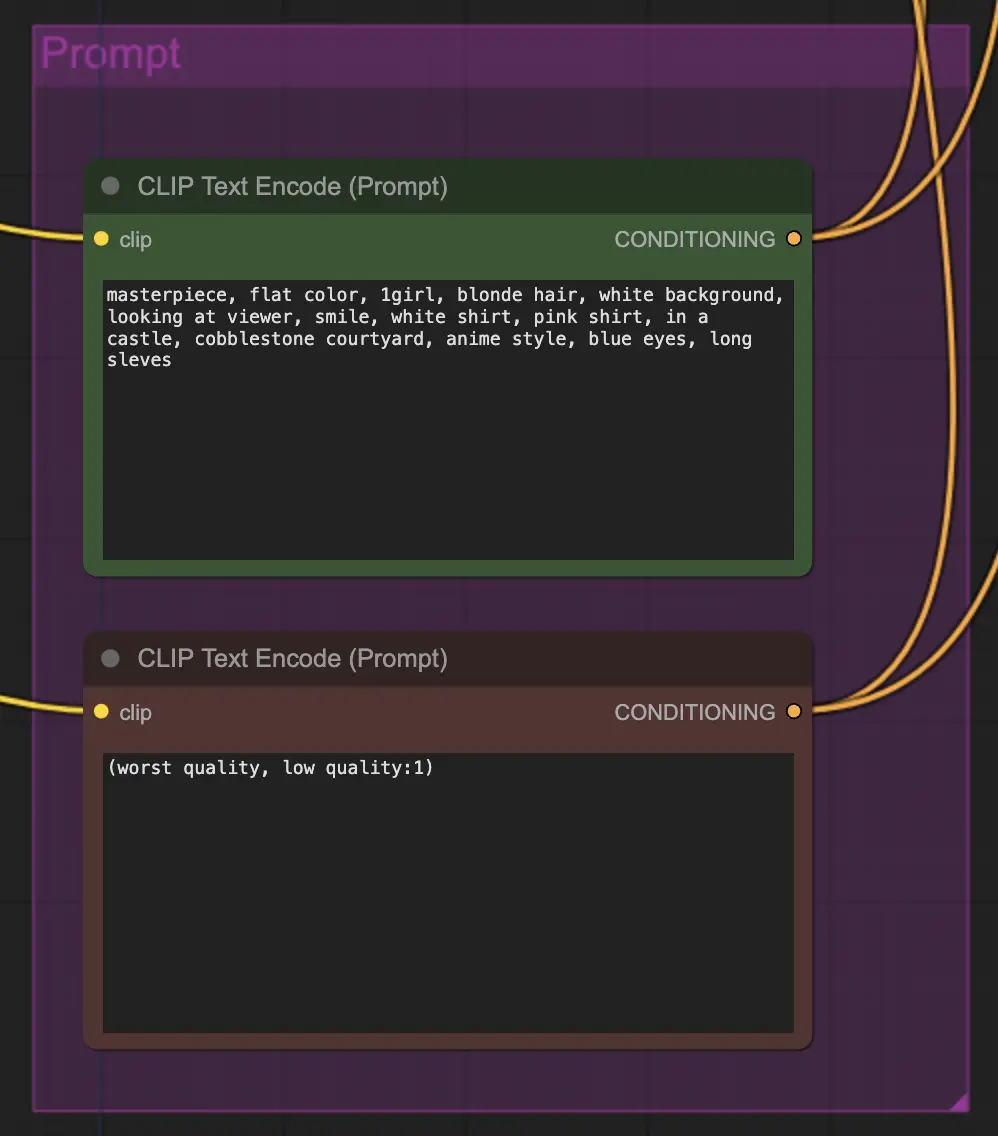
Prompting spielt bei dieser Methode aus irgendeinem Grund eine große Rolle. Ein guter Prompt kann die Kohärenz des Videos wirklich verbessern, insbesondere je mehr Sie die Transformation vorantreiben möchten. In diesem Beispiel habe ich dieselbe Konditionierung sowohl dem Unsampler als auch dem Resampler zugeführt. Es scheint im Allgemeinen gut zu funktionieren – nichts hindert Sie jedoch daran, eine leere Konditionierung in den Unsampler zu setzen – ich finde, es hilft, den Stiltransfer zu verbessern, vielleicht mit einem gewissen Verlust an Konsistenz.
Knoten: Resampling#
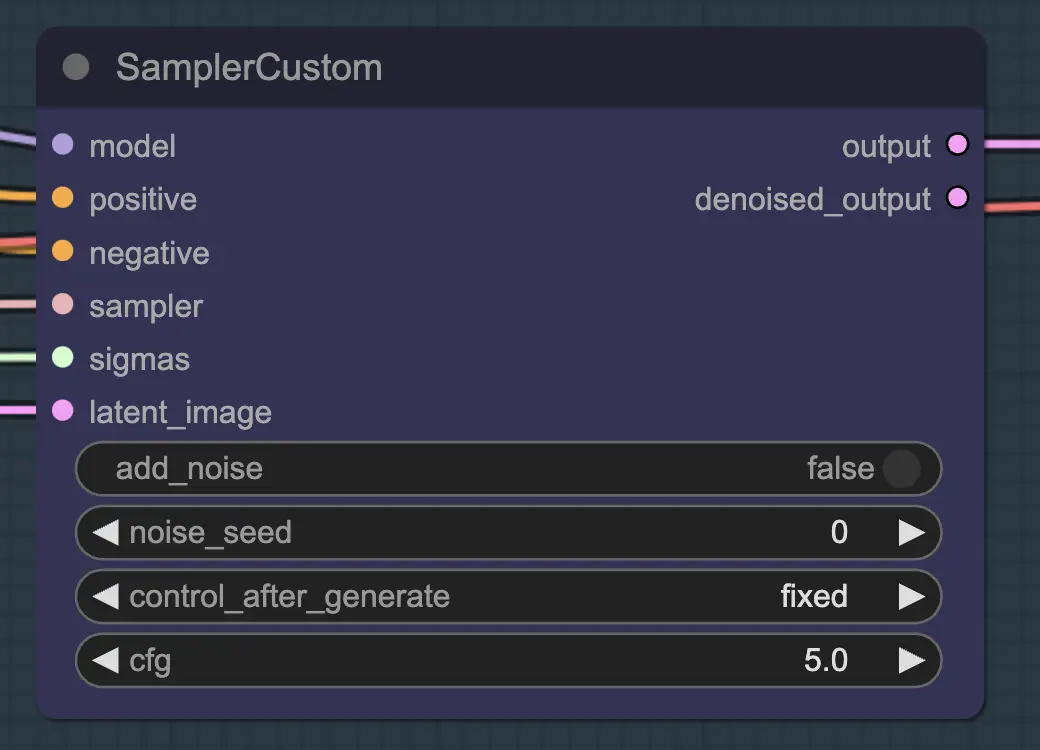
Beim Resampling ist es wichtig, dass das Hinzufügen von Rauschen deaktiviert ist (auch wenn leeres Rauschen in den AnimateDiff-Sample-Einstellungen denselben Effekt hat – ich habe beides in meinem Workflow gemacht). Wenn Sie während des Resamplings Rauschen hinzufügen, erhalten Sie ein inkonsistentes, rauschiges Ergebnis, zumindest mit den Standardeinstellungen. Andernfalls schlage ich vor, mit einem ziemlich niedrigen CFG-Wert in Kombination mit schwachen ControlNet-Einstellungen zu beginnen, da dies die konsistentesten Ergebnisse zu liefern scheint, während der Prompt weiterhin den Stil beeinflussen kann.
Andere Einstellungen#
Der Rest meiner Einstellungen ist persönliche Präferenz. Ich habe diesen Workflow so weit wie möglich vereinfacht, während ich die wichtigsten Komponenten und Einstellungen beibehalten habe.
4. Workflow-Informationen#
Der Standard-Workflow verwendet das SD1.5-Modell. Sie können jedoch zu SDXL wechseln, indem Sie einfach das Checkpoint, VAE, AnimateDiff-Modell, ControlNet-Modell und das Step-Schedule-Modell auf SDXL ändern.
5. Wichtige Hinweise/Probleme#
- Flackern – Wenn Sie sich die dekodierten und vorgemusterten Latenzen ansehen, die durch Unsampling in meinen Workflows erstellt wurden, werden Sie einige mit offensichtlichen Farbabweichungen bemerken. Die genaue Ursache ist mir unklar, und im Allgemeinen beeinflussen sie die Endergebnisse nicht. Diese Abweichungen sind besonders bei SDXL auffällig. Sie können jedoch manchmal Flackern in Ihrem Video verursachen. Die Hauptursache scheint mit den ControlNets zusammenzuhängen – das Reduzieren ihrer Stärke kann helfen. Das Ändern des Prompts oder sogar eine leichte Änderung des Schedulers kann ebenfalls einen Unterschied machen. Ich stoße immer noch manchmal auf dieses Problem – wenn Sie eine Lösung haben, lassen Sie es mich bitte wissen!
- DPM++ 2M kann manchmal das Flackern verbessern.
6. Wohin von hier?#
Dies fühlt sich wie eine völlig neue Art an, die Konsistenz von Videos zu steuern, daher gibt es viel zu erforschen. Wenn Sie meine Vorschläge möchten:
- Versuchen Sie, Rauschen aus mehreren Quellvideos zu kombinieren/maskieren.
- Fügen Sie IPAdapter für konsistente Charaktertransformationen hinzu.
Über den Autor#
Inner-Reflections
- https://x.com/InnerRefle11312
- https://civitai.com/user/Inner_Reflections_AI
