





ComfyUI FLUX: Leitfaden zur Einrichtung, Workflows wie FLUX-ControlNet, FLUX-LoRA und FLUX-IPAdapter... und Online-Zugang
Updated: 8/26/2024
Hallo, liebe KI-Enthusiasten! 👋 Willkommen zu unserem Einführungsguide zur Nutzung von FLUX innerhalb von ComfyUI. FLUX ist ein hochmodernes Modell, das von Black Forest Labs entwickelt wurde. 🌟 In diesem Tutorial werden wir die Grundlagen von ComfyUI FLUX durchgehen und zeigen, wie dieses leistungsstarke Modell Ihren kreativen Prozess verbessern und Ihnen helfen kann, die Grenzen der KI-generierten Kunst zu erweitern. 🚀
Wir werden behandeln:
1. Einführung in FLUX
2. Verschiedene Versionen von FLUX
3. FLUX Hardwareanforderungen
- 3.1. FLUX.1 [Pro] Hardwareanforderungen
- 3.2. FLUX.1 [Dev] Hardwareanforderungen
- 3.3. FLUX.1 [Schnell] Hardwareanforderungen
4. Wie man FLUX in ComfyUI installiert
- 4.1. Installation oder Aktualisierung von ComfyUI
- 4.2. Herunterladen von ComfyUI FLUX Text Encoders und CLIP Modellen
- 4.3. Herunterladen des FLUX.1 VAE Modells
- 4.4. Herunterladen des FLUX.1 UNET Modells
5. ComfyUI FLUX Workflow | Download, Online-Zugang und Leitfaden
- 5.1. ComfyUI Workflow: FLUX Txt2Img
- 5.2. ComfyUI Workflow: FLUX Img2Img
- 5.3. ComfyUI Workflow: FLUX LoRA
- 5.4. ComfyUI Workflow: FLUX ControlNet
- 5.5. ComfyUI Workflow: FLUX Inpainting
- 5.6. ComfyUI Workflow: FLUX NF4 & Upscale
- 5.7. ComfyUI Workflow: FLUX IPAdapter
- 5.8. ComfyUI Workflow: Flux LoRA Trainer
- 5.9. ComfyUI Workflow: Flux Latent Upscale
1. Einführung in FLUX
FLUX.1, das hochmoderne KI-Modell von Black Forest Labs, revolutioniert die Art und Weise, wie wir Bilder aus Textbeschreibungen erstellen. Mit seiner beispiellosen Fähigkeit, atemberaubend detaillierte und komplexe Bilder zu generieren, die den Eingabeaufforderungen genau entsprechen, hebt sich FLUX.1 von der Konkurrenz ab. Das Geheimnis des Erfolgs von FLUX.1 liegt in seiner einzigartigen hybriden Architektur, die verschiedene Arten von Transformer-Blöcken kombiniert und von beeindruckenden 12 Milliarden Parametern angetrieben wird. Dies ermöglicht es FLUX.1, visuell fesselnde Bilder zu produzieren, die die Textbeschreibungen mit bemerkenswerter Präzision darstellen.
Ein besonders spannender Aspekt von FLUX.1 ist seine Vielseitigkeit bei der Generierung von Bildern in verschiedenen Stilen, von fotorealistisch bis künstlerisch. FLUX.1 hat sogar die bemerkenswerte Fähigkeit, Text nahtlos in die generierten Bilder zu integrieren, was vielen anderen Modellen schwerfällt. Darüber hinaus ist FLUX.1 für seine außergewöhnliche Einhaltung der Eingabeaufforderungen bekannt und bewältigt mühelos sowohl einfache als auch komplexe Beschreibungen. Dies hat dazu geführt, dass FLUX.1 häufig mit anderen bekannten Modellen wie Stable Diffusion und Midjourney verglichen wird, wobei FLUX.1 oft als bevorzugte Wahl hervorgeht, dank seiner benutzerfreundlichen Natur und erstklassigen Ergebnisse.
Die beeindruckenden Fähigkeiten von FLUX.1 machen es zu einem unverzichtbaren Werkzeug für eine Vielzahl von Anwendungen, von der Erstellung atemberaubender visueller Inhalte und der Inspiration innovativer Designs bis hin zur Unterstützung bei wissenschaftlicher Visualisierung. Die Fähigkeit von FLUX.1, hochdetaillierte und präzise Bilder aus Textbeschreibungen zu generieren, eröffnet kreative Möglichkeiten für Fachleute, Forscher und Enthusiasten gleichermaßen. Da sich das Feld der KI-generierten Bilder weiterhin entwickelt, steht FLUX.1 an vorderster Front und setzt neue Maßstäbe in Bezug auf Qualität, Vielseitigkeit und Benutzerfreundlichkeit.
Black Forest Labs, das wegweisende KI-Unternehmen hinter dem revolutionären FLUX.1, wurde von Robin Rombach gegründet, einer bekannten Persönlichkeit in der KI-Branche, der zuvor ein Kernmitglied von Stability AI war. Wenn Sie mehr über Black Forest Labs und ihre bahnbrechende Arbeit mit FLUX.1 erfahren möchten, besuchen Sie unbedingt ihre offizielle Website unter https://blackforestlabs.ai/.

2. Verschiedene Versionen von FLUX
FLUX.1 ist in drei verschiedenen Versionen erhältlich, die jeweils auf spezifische Benutzerbedürfnisse zugeschnitten sind:
- FLUX.1 [pro]: Dies ist die Spitzenversion, die die beste Qualität und Leistung bietet, perfekt für den professionellen Einsatz und hochwertige Projekte.
- FLUX.1 [dev]: Optimiert für nicht-kommerzielle Nutzung, bietet diese Version eine hohe Ausgabequalität bei höherer Effizienz, was sie ideal für Entwickler und Enthusiasten macht.
- FLUX.1 [schnell]: Diese Version konzentriert sich auf Geschwindigkeit und Leichtigkeit und ist perfekt für die lokale Entwicklung und persönliche Projekte. Sie ist auch Open Source und unter der Apache 2.0 Lizenz verfügbar, sodass sie für eine breite Nutzerbasis zugänglich ist.
| Name | HuggingFace repo | License | md5sum |
FLUX.1 [pro] | Nur in unserer API verfügbar. | ||
FLUX.1 [dev] | https://huggingface.co/black-forest-labs/FLUX.1-dev | FLUX.1-dev Non-Commercial License | a6bd8c16dfc23db6aee2f63a2eba78c0 |
FLUX.1 [schnell] | https://huggingface.co/black-forest-labs/FLUX.1-schnell | apache-2.0 | a9e1e277b9b16add186f38e3f5a34044 |
3. FLUX Hardwareanforderungen
3.1. FLUX.1 [Pro] Hardwareanforderungen
- Empfohlene GPU: NVIDIA RTX 4090 oder gleichwertig mit 24 GB oder mehr VRAM. Das Modell ist für High-End-GPUs optimiert, um seine komplexen Operationen zu bewältigen.
- RAM: 32 GB oder mehr Systemspeicher.
- Speicherplatz: Ungefähr 30 GB.
- Rechenanforderungen: Hohe Präzision ist erforderlich; verwenden Sie FP16 (Halbpräzision), um Speicherüberläufe zu vermeiden. Für beste Ergebnisse wird empfohlen, das
fp16Clip-Modell-Variant für maximale Qualität zu verwenden. - Weitere Anforderungen: Eine schnelle SSD wird für schnellere Ladezeiten und insgesamt bessere Leistung empfohlen.
3.2. FLUX.1 [Dev] Hardwareanforderungen
- Empfohlene GPU: NVIDIA RTX 3080/3090 oder gleichwertig mit mindestens 16 GB VRAM. Diese Version ist hinsichtlich der Hardwareanforderungen etwas nachsichtiger als das Pro-Modell, erfordert aber dennoch erhebliche GPU-Leistung.
- RAM: 16 GB oder mehr Systemspeicher.
- Speicherplatz: Ungefähr 25 GB.
- Rechenanforderungen: Ähnlich wie bei Pro, verwenden Sie FP16-Modelle, jedoch mit einer gewissen Toleranz für niedrigere Präzisionsberechnungen. Kann
fp16oderfp8Clip-Modelle basierend auf den GPU-Fähigkeiten verwenden. - Weitere Anforderungen: Eine schnelle SSD wird für optimale Leistung empfohlen.
3.3. FLUX.1 [Schnell] Hardwareanforderungen
- Empfohlene GPU: NVIDIA RTX 3060/4060 oder gleichwertig mit 12 GB VRAM. Diese Version ist für schnellere Inferenz und niedrigere Hardwareanforderungen optimiert.
- RAM: 8 GB oder mehr Systemspeicher.
- Speicherplatz: Ungefähr 15 GB.
- Rechenanforderungen: Diese Version ist weniger anspruchsvoll und erlaubt
fp8Berechnungen, wenn der Speicher knapp wird. Sie ist auf Schnelligkeit und Effizienz ausgelegt, mit dem Fokus auf Geschwindigkeit statt auf ultrahohe Qualität. - Weitere Anforderungen: SSD ist nützlich, aber nicht so kritisch wie bei den Pro- und Dev-Versionen.
4. Wie man FLUX in ComfyUI installiert
4.1. Installation oder Aktualisierung von ComfyUI
Um FLUX.1 effektiv innerhalb der ComfyUI-Umgebung zu nutzen, ist es wichtig sicherzustellen, dass Sie die neueste Version von ComfyUI installiert haben. Diese Version unterstützt die notwendigen Funktionen und Integrationen, die für FLUX.1-Modelle erforderlich sind.
4.2. Herunterladen von ComfyUI FLUX Text Encoders und CLIP Modellen
Für optimale Leistung und genaue Text-zu-Bild-Generierung mit FLUX.1 müssen Sie spezifische Textencoder und CLIP-Modelle herunterladen. Die folgenden Modelle sind je nach Hardware Ihres Systems unerlässlich:
| Model File Name | Size | Note | Link |
t5xxl_fp16.safetensors | 9.79 GB | Für bessere Ergebnisse, wenn Sie hohe VRAM und RAM haben (mehr als 32GB RAM). | Download |
t5xxl_fp8_e4m3fn.safetensors | 4.89 GB | Für geringeren Speicherverbrauch (8-12GB) | Download |
clip_l.safetensors | 246 MB | Download |
Schritte zum Herunterladen und Installieren:
- Laden Sie das
clip_l.safetensorsModell herunter. - Laden Sie je nach VRAM und RAM Ihres Systems entweder
t5xxl_fp8_e4m3fn.safetensors(für geringeren VRAM) odert5xxl_fp16.safetensors(für höheren VRAM und RAM) herunter. - Platzieren Sie die heruntergeladenen Modelle im Verzeichnis
ComfyUI/models/clip/. Hinweis: Wenn Sie zuvor SD 3 Medium verwendet haben, haben Sie diese Modelle möglicherweise bereits.
4.3. Herunterladen des FLUX.1 VAE Modells
Das Variational Autoencoder (VAE) Modell ist entscheidend für die Verbesserung der Bildgenerierungsqualität in FLUX.1. Das folgende VAE Modell steht zum Download zur Verfügung:
| File Name | Size | Link |
ae.safetensors | 335 MB | Download(opens in a new tab) |
Schritte zum Herunterladen und Installieren:
- Laden Sie die Datei
ae.safetensorsherunter. - Platzieren Sie die heruntergeladene Datei im Verzeichnis
ComfyUI/models/vae. - Zur einfachen Identifizierung wird empfohlen, die Datei in
flux_ae.safetensorsumzubenennen.
4.4. Herunterladen des FLUX.1 UNET Modells
Das UNET-Modell ist das Rückgrat der Bildsynthese in FLUX.1. Je nach Systemkonfiguration können Sie zwischen verschiedenen Varianten wählen:
| File Name | Size | Link | Note |
flux1-dev.safetensors | 23.8GB | Download | Wenn Sie hohe VRAM und RAM haben. |
flux1-schnell.safetensors | 23.8GB | Download | Für geringeren Speicherverbrauch |
Schritte zum Herunterladen und Installieren:
- Laden Sie das entsprechende UNET-Modell basierend auf der Speicherkonfiguration Ihres Systems herunter.
- Platzieren Sie die heruntergeladene Modelldatei im Verzeichnis
ComfyUI/models/unet/.
5. ComfyUI FLUX Workflow | Download, Online-Zugang und Leitfaden
Wir werden den ComfyUI FLUX Workflow kontinuierlich aktualisieren, um Ihnen die neuesten und umfassendsten Workflows zur Generierung atemberaubender Bilder mit ComfyUI FLUX bereitzustellen.
5.1. ComfyUI Workflow: FLUX Txt2Img
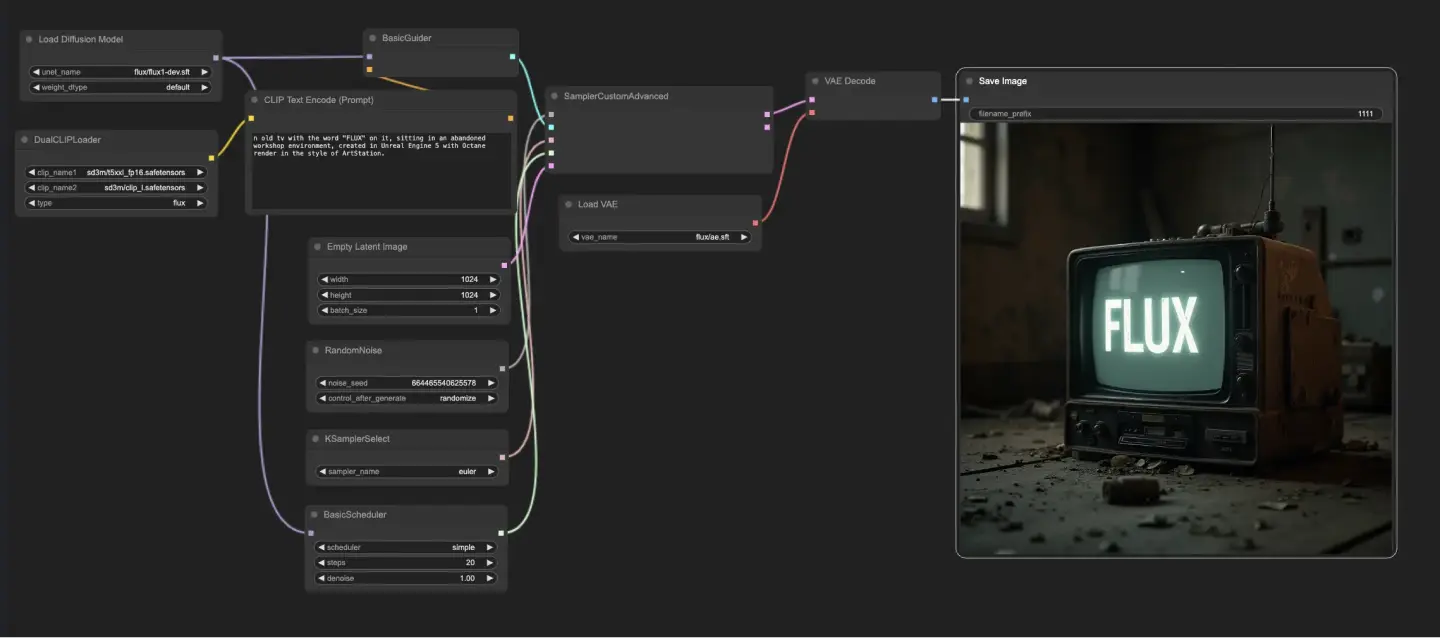
5.1.1. ComfyUI FLUX Txt2Img : Download
5.1.2. ComfyUI FLUX Txt2Img Online-Version: ComfyUI FLUX Txt2Img
Auf der RunComfy-Plattform lädt unsere Online-Version alle notwendigen Modi und Knoten für Sie vor. Außerdem bieten wir Hochleistungs-GPU-Maschinen, sodass Sie das ComfyUI FLUX Txt2Img-Erlebnis mühelos genießen können.
5.1.3. Erklärung zu ComfyUI FLUX Txt2Img:
Der ComfyUI FLUX Txt2Img Workflow beginnt mit dem Laden der wesentlichen Komponenten, einschließlich des FLUX UNET (UNETLoader), FLUX CLIP (DualCLIPLoader) und FLUX VAE (VAELoader). Diese bilden die Grundlage des ComfyUI FLUX Bildgenerierungsprozesses.
- UNETLoader: Lädt das UNET-Modell zur Bildgenerierung.
- Checkpoint: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: Lädt das CLIP-Modell zur Textcodierung.
- Einbettungsmodell 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- Einbettungsmodell 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- Gruppierung: Die Gruppierungsstrategie für das CLIP-Modell ist flux
- VAELoader: Lädt das Variational Autoencoder (VAE) Modell zum Dekodieren latenter Repräsentationen.
- VAE-Modell: flux/ae.sft
Die Texteingabe, die das gewünschte Ergebnis beschreibt, wird mit dem CLIPTextEncode codiert. Dieser Knoten nimmt die Texteingabe als Eingabe und gibt die codierte Textkonditionierung aus, die ComfyUI FLUX während der Generierung leitet.
Um den ComfyUI FLUX Generierungsprozess zu starten, wird eine leere latente Repräsentation mit dem EmptyLatentImage erstellt. Dies dient als Ausgangspunkt für ComfyUI FLUX.
Der BasicGuider spielt eine entscheidende Rolle bei der Steuerung des ComfyUI FLUX Generierungsprozesses. Er nimmt die codierte Textkonditionierung und das geladene FLUX UNET als Eingaben und sorgt dafür, dass das generierte Ergebnis der bereitgestellten Textbeschreibung entspricht.
Der KSamplerSelect ermöglicht es Ihnen, die Abtastmethode für die ComfyUI FLUX Generierung auszuwählen, während der RandomNoise zufälliges Rauschen als Eingabe für ComfyUI FLUX generiert. Der BasicScheduler plant die Rauschpegel (Sigmas) für jeden Schritt im Generierungsprozess und steuert dabei den Detailgrad und die Klarheit des Endergebnisses.
Der SamplerCustomAdvanced bringt alle Komponenten des ComfyUI FLUX Txt2Img Workflows zusammen. Er nimmt das zufällige Rauschen, den Guider, den ausgewählten Sampler, die geplanten Sigmas und die leere latente Repräsentation als Eingaben. Durch einen fortschrittlichen Abtastprozess wird eine latente Repräsentation erzeugt, die die Texteingabe darstellt.
Schließlich dekodiert der VAEDecode die generierte latente Repräsentation in das endgültige Ergebnis unter Verwendung des geladenen FLUX VAE. Der SaveImage ermöglicht es Ihnen, das generierte Ergebnis an einem bestimmten Ort zu speichern und damit die atemberaubende Kreation zu bewahren, die durch den ComfyUI FLUX Txt2Img Workflow möglich wurde.
5.2. ComfyUI Workflow: FLUX Img2Img
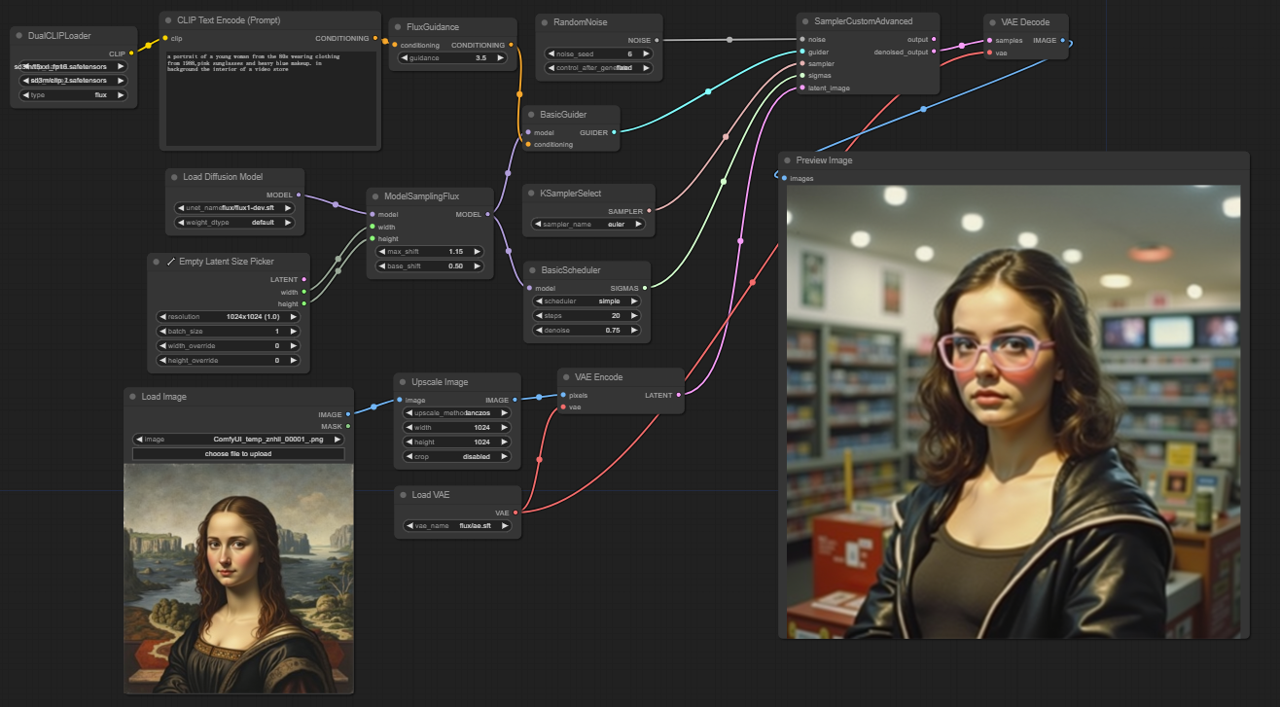
5.2.1. ComfyUI FLUX Img2Img: Download
5.2.2. ComfyUI FLUX Img2Img Online-Version: ComfyUI FLUX Img2Img
Auf der RunComfy-Plattform lädt unsere Online-Version alle notwendigen Modi und Knoten für Sie vor. Außerdem bieten wir Hochleistungs-GPU-Maschinen, sodass Sie das ComfyUI FLUX Img2Img-Erlebnis mühelos genießen können.
5.2.3. Erklärung zu ComfyUI FLUX Img2Img:
Der ComfyUI FLUX Img2Img Workflow baut auf der Leistungsfähigkeit von ComfyUI FLUX auf, um Ausgaben basierend auf sowohl Texteingaben als auch Eingabedarstellungen zu erzeugen. Er beginnt mit dem Laden der notwendigen Komponenten, einschließlich des CLIP-Modells (DualCLIPLoader), des UNET-Modells (UNETLoader) und des VAE-Modells (VAELoader).
- UNETLoader: Lädt das UNET-Modell zur Bildgenerierung.
- Checkpoint: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: Lädt das CLIP-Modell zur Textcodierung.
- Einbettungsmodell 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- Einbettungsmodell 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- Gruppierung: Die Gruppierungsstrategie für das CLIP-Modell ist flux
- VAELoader: Lädt das Variational Autoencoder (VAE) Modell zum Dekodieren latenter Repräsentationen.
- VAE-Modell: flux/ae.sft
Die Eingabedarstellung, die als Ausgangspunkt für den ComfyUI FLUX Img2Img Prozess dient, wird mit dem LoadImage geladen. Der ImageScale skaliert die Eingabedarstellung auf die gewünschte Größe, um die Kompatibilität mit ComfyUI FLUX zu gewährleisten.
Die skalierte Eingabedarstellung wird mit dem VAEEncode codiert, wodurch sie in eine latente Repräsentation umgewandelt wird. Diese latente Repräsentation erfasst die wesentlichen Merkmale und Details der Eingabe und bietet eine Grundlage, auf der ComfyUI FLUX aufbauen kann.
Die Texteingabe, die die gewünschten Modifikationen oder Verbesserungen der Eingabe beschreibt, wird mit dem CLIPTextEncode codiert. Die FluxGuidance wendet dann eine Anleitung auf die Konditionierung basierend auf der angegebenen Anleitungsskala an und beeinflusst die Stärke des Einflusses der Texteingabe auf das Endergebnis.
Der ModelSamplingFlux setzt die Abtastparameter für ComfyUI FLUX, einschließlich der Zeitschrittreduktion, des Polsterungsverhältnisses und der Ausgabedimensionen. Diese Parameter steuern die Granularität und Auflösung des generierten Ergebnisses.
Der KSamplerSelect ermöglicht es Ihnen, die Abtastmethode für die ComfyUI FLUX Generierung auszuwählen, während der BasicGuider den Generierungsprozess basierend auf der codierten Textkonditionierung und dem geladenen FLUX UNET leitet.
Zufälliges Rauschen wird mit dem RandomNoise generiert, und der BasicScheduler plant die Rauschpegel (Sigmas) für jeden Schritt im Generierungsprozess. Diese Komponenten führen kontrollierte Variationen ein und verfeinern die Details im Endergebnis.
Der SamplerCustomAdvanced bringt das zufällige Rauschen, den Guider, den ausgewählten Sampler, die geplanten Sigmas und die latente Repräsentation der Eingabe zusammen. Durch einen fortschrittlichen Abtastprozess wird eine latente Repräsentation erzeugt, die die Modifikationen der Texteingabe integriert und gleichzeitig die wesentlichen Merkmale der Eingabe bewahrt.
Schließlich dekodiert der VAEDecode die denoised latente Repräsentation in das endgültige Ergebnis unter Verwendung des geladenen FLUX VAE. Der PreviewImage zeigt eine Vorschau des generierten Ergebnisses und zeigt die beeindruckenden Ergebnisse des ComfyUI FLUX Img2Img Workflows.
5.3. ComfyUI Workflow: FLUX LoRA
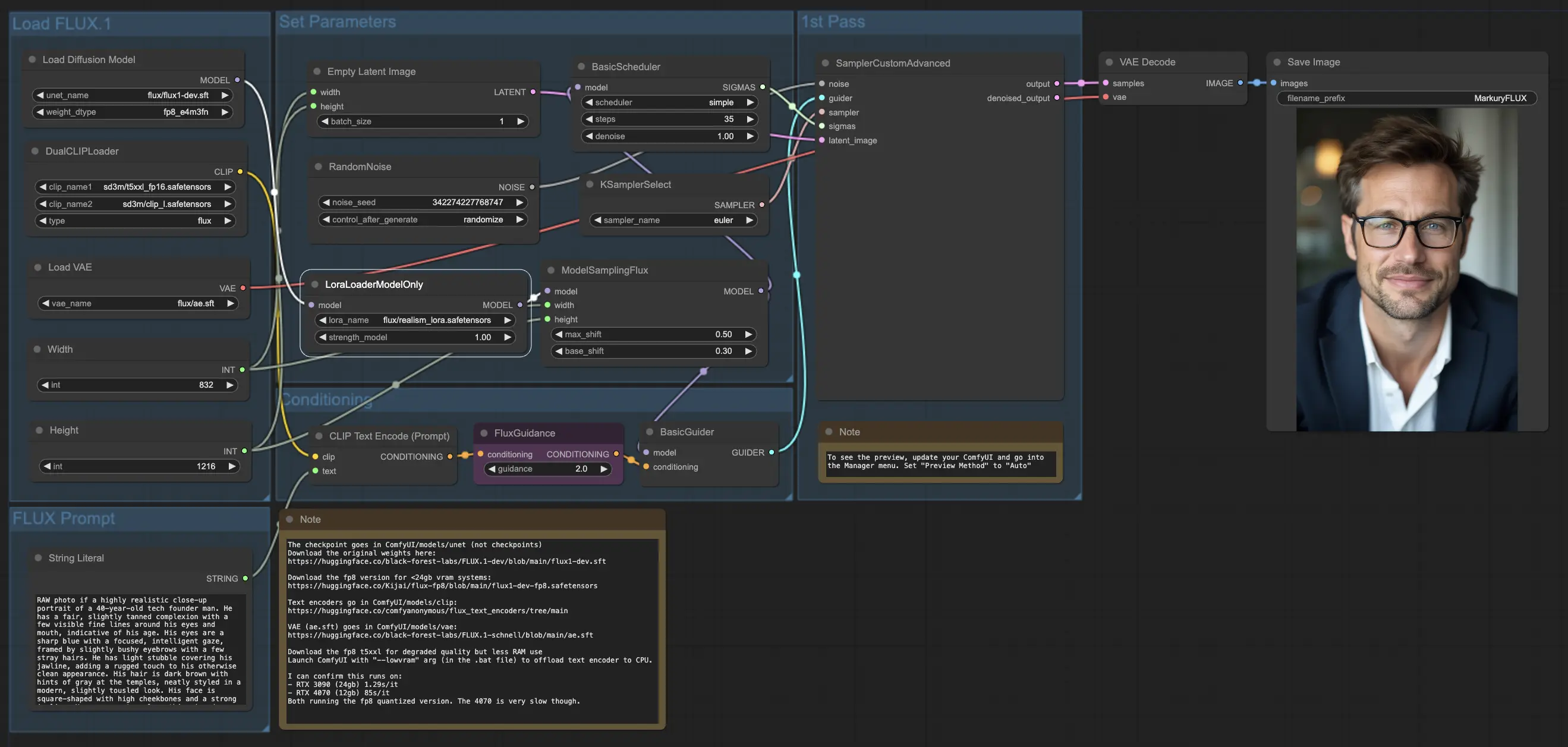
5.3.1. ComfyUI FLUX LoRA: Download
5.3.2. ComfyUI FLUX LoRA Online-Version: ComfyUI FLUX LoRA
Auf der RunComfy-Plattform lädt unsere Online-Version alle notwendigen Modi und Knoten für Sie vor. Außerdem bieten wir Hochleistungs-GPU-Maschinen, sodass Sie das ComfyUI FLUX LoRA-Erlebnis mühelos genießen können.
5.3.3. Erklärung zu ComfyUI FLUX LoRA:
Der ComfyUI FLUX LoRA Workflow nutzt die Leistungsfähigkeit der Low-Rank Adaptation (LoRA), um die Leistung von ComfyUI FLUX zu verbessern. Er beginnt mit dem Laden der notwendigen Komponenten, einschließlich des UNET-Modells (UNETLoader), des CLIP-Modells (DualCLIPLoader), des VAE-Modells (VAELoader) und des LoRA-Modells (LoraLoaderModelOnly).
- UNETLoader: Lädt das UNET-Modell zur Bildgenerierung.
- Checkpoint: flux/flux1-dev.sft
- DualCLIPLoader: Lädt das CLIP-Modell zur Textcodierung.
- Einbettungsmodell 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- Einbettungsmodell 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- Gruppierung: Die Gruppierungsstrategie für das CLIP-Modell ist flux
- VAELoader: Lädt das Variational Autoencoder (VAE) Modell zum Dekodieren latenter Repräsentationen.
- VAE-Modell: flux/ae.sft
- LoraLoaderModelOnly: Lädt das LoRA (Low-Rank Adaptation) Modell zur Verbesserung des UNET-Modells.
- LoaderModel: flux/realism_lora.safetensors
Die Texteingabe, die das gewünschte Ergebnis beschreibt, wird mit dem String Literal spezifiziert. Der CLIPTextEncode codiert dann die Texteingabe und erzeugt die codierte Textkonditionierung, die den ComfyUI FLUX Generierungsprozess leitet.
Die FluxGuidance wendet eine Anleitung auf die codierte Textkonditionierung an und beeinflusst die Stärke und Richtung der Einhaltung der Texteingabe durch ComfyUI FLUX.
Eine leere latente Repräsentation, die als Ausgangspunkt für die Generierung dient, wird mit dem EmptyLatentImage erstellt. Die Breite und Höhe des generierten Ergebnisses werden mit dem Int Literal spezifiziert und stellen sicher, dass die gewünschten Abmessungen des Endergebnisses eingehalten werden.
Der ModelSamplingFlux setzt die Abtastparameter für ComfyUI FLUX, einschließlich des Polsterungsverhältnisses und der Zeitschrittreduktion. Diese Parameter steuern die Auflösung und Granularität des generierten Ergebnisses.
Der KSamplerSelect ermöglicht es Ihnen, die Abtastmethode für die ComfyUI FLUX Generierung auszuwählen, während der BasicGuider den Generierungsprozess basierend auf der codierten Textkonditionierung und dem geladenen FLUX UNET, das mit FLUX LoRA verbessert wurde, leitet.
Zufälliges Rauschen wird mit dem RandomNoise generiert, und der BasicScheduler plant die Rauschpegel (Sigmas) für jeden Schritt im Generierungsprozess. Diese Komponenten führen kontrollierte Variationen ein und verfeinern die Details im Endergebnis.
Der SamplerCustomAdvanced bringt das zufällige Rauschen, den Guider, den ausgewählten Sampler, die geplanten Sigmas und die leere latente Repräsentation zusammen. Durch einen fortschrittlichen Abtastprozess wird eine latente Repräsentation erzeugt, die die Texteingabe darstellt und die Leistungsfähigkeit von FLUX und die Verbesserung durch FLUX LoRA nutzt.
Schließlich dekodiert der VAEDecode die generierte latente Repräsentation in das endgültige Ergebnis unter Verwendung des geladenen FLUX VAE. Der SaveImage ermöglicht es Ihnen, das generierte Ergebnis an einem bestimmten Ort zu speichern und damit die atemberaubende Kreation zu bewahren, die durch den ComfyUI FLUX LoRA Workflow möglich wurde.
5.4. ComfyUI Workflow: FLUX ControlNet
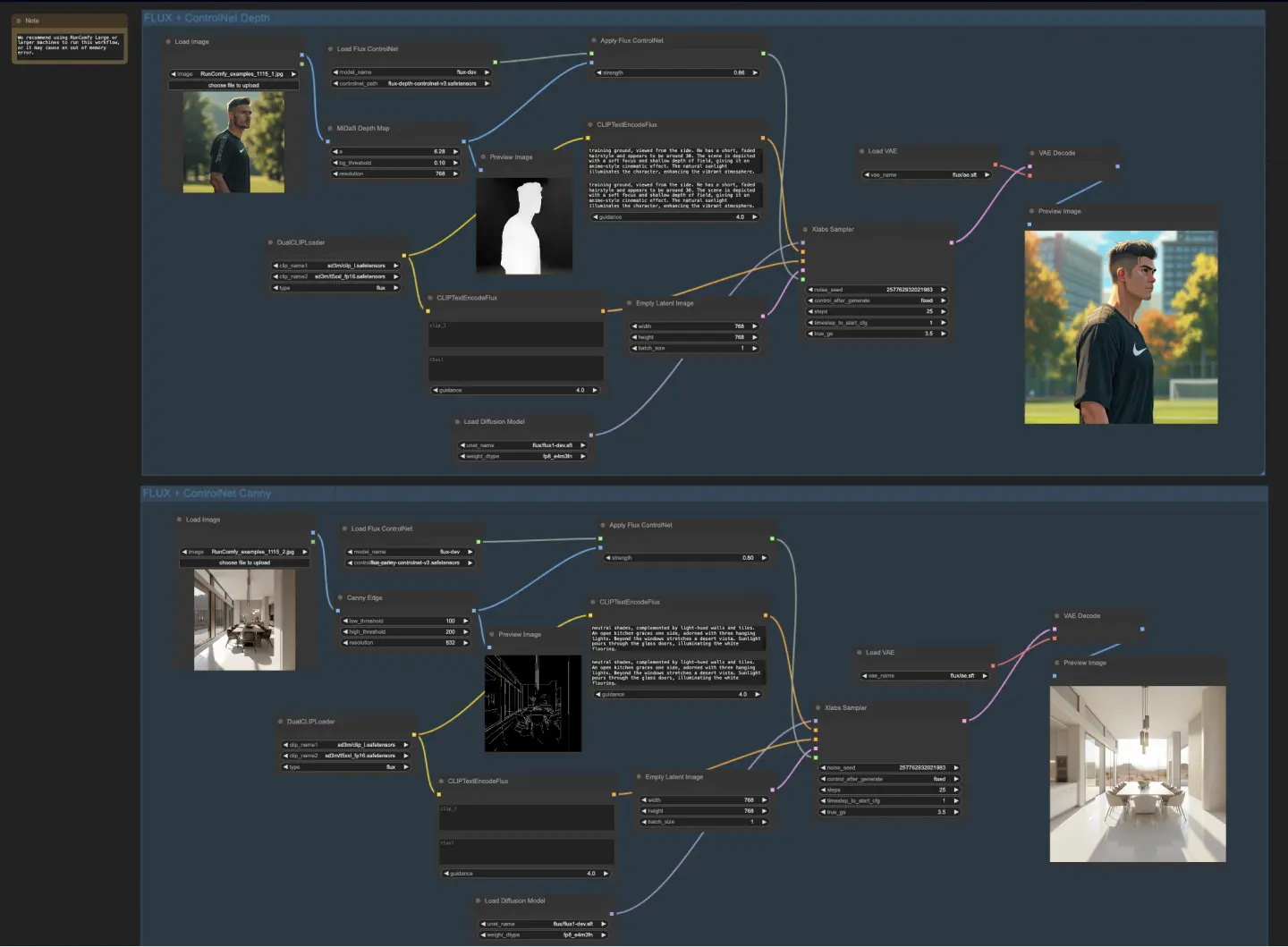
5.4.1. ComfyUI FLUX ControlNet: Download
5.4.2. ComfyUI FLUX ControlNet Online-Version: ComfyUI FLUX ControlNet
Auf der RunComfy-Plattform lädt unsere Online-Version alle notwendigen Modi und Knoten für Sie vor. Außerdem bieten wir Hochleistungs-GPU-Maschinen, sodass Sie das ComfyUI FLUX ControlNet-Er lebnis mühelos genießen können.
5.4.3. Erklärung zu ComfyUI FLUX ControlNet:
Der ComfyUI FLUX ControlNet Workflow demonstriert die Integration von ControlNet mit ComfyUI FLUX zur verbesserten Ausgabeerzeugung. Der Workflow zeigt zwei Beispiele: tiefenbasierte Konditionierung und Canny-Kanten-basierte Konditionierung.
- UNETLoader: Lädt das UNET-Modell zur Bildgenerierung.
- Checkpoint: flux/flux1-dev.sft
- DualCLIPLoader: Lädt das CLIP-Modell zur Textcodierung.
- Einbettungsmodell 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- Einbettungsmodell 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- Gruppierung: Die Gruppierungsstrategie für das CLIP-Modell ist flux
- VAELoader: Lädt das Variational Autoencoder (VAE) Modell zum Dekodieren latenter Repräsentationen.
- VAE-Modell: flux/ae.sft
Im tiefenbasierten Workflow wird die Eingabedarstellung mit dem MiDaS-DepthMapPreprocessor vorverarbeitet und eine Tiefenkarte generiert. Die Tiefenkarte wird dann zusammen mit dem geladenen FLUX ControlNet für die Tiefenkonditionierung durch das ApplyFluxControlNet (Depth) geleitet. Die resultierende FLUX ControlNet-Konditionierung dient als Eingabe für den XlabsSampler (Depth) zusammen mit dem geladenen FLUX UNET, der codierten Textkonditionierung, der negativen Textkonditionierung und der leeren latenten Repräsentation. Der XlabsSampler erzeugt eine latente Repräsentation basierend auf diesen Eingaben, die anschließend mit dem VAEDecode in das endgültige Ergebnis dekodiert wird.
- MiDaS-DepthMapPreprocessor (Depth): Verarbeitet das Eingabebild zur Tiefenschätzung mit MiDaS vor.
- LoadFluxControlNet: Lädt das ControlNet-Modell.
- Pfad: flux-depth-controlnet.safetensors
Ähnlich wird im Canny-Kanten-basierten Workflow die Eingabedarstellung mit dem CannyEdgePreprocessor vorverarbeitet, um Canny-Kanten zu generieren. Die Canny-Kanten-Darstellung wird zusammen mit dem geladenen FLUX ControlNet für die Canny-Kanten-Konditionierung durch das ApplyFluxControlNet (Canny) geleitet. Die resultierende FLUX ControlNet-Konditionierung dient als Eingabe für den XlabsSampler (Canny) zusammen mit dem geladenen FLUX UNET, der codierten Textkonditionierung, der negativen Textkonditionierung und der leeren latenten Repräsentation. Der XlabsSampler erzeugt eine latente Repräsentation basierend auf diesen Eingaben, die anschließend mit dem VAEDecode in das endgültige Ergebnis dekodiert wird.
- CannyEdgePreprocessor (Canny): Verarbeitet das Eingabebild zur Canny-Kantenerkennung vor.
- LoadFluxControlNet: Lädt das ControlNet-Modell.
- Pfad: flux-canny-controlnet.safetensors
Der ComfyUI FLUX ControlNet Workflow integriert Knoten zum Laden der notwendigen Komponenten (DualCLIPLoader, UNETLoader, VAELoader, LoadFluxControlNet), zur Codierung von Texteingaben (CLIPTextEncodeFlux), zur Erstellung leerer latenter Repräsentationen (EmptyLatentImage) und zur Vorschau der generierten und vorverarbeiteten Ausgaben (PreviewImage).
Durch die Nutzung der Leistungsfähigkeit von FLUX ControlNet ermöglicht der ComfyUI FLUX ControlNet Workflow die Erzeugung von Ausgaben, die spezifischen Konditionierungen wie Tiefenkarten oder Canny-Kanten entsprechen. Diese zusätzliche Ebene der Kontrolle und Anleitung verbessert die Flexibilität und Präzision des Generierungsprozesses und ermöglicht die Erstellung atemberaubender und kontextuell relevanter Ausgaben mit ComfyUI FLUX.
5.5. ComfyUI Workflow: FLUX Inpainting
5.5.1. ComfyUI FLUX Inpainting: Download
5.5.2. ComfyUI FLUX Inpainting Online-Version: ComfyUI FLUX Inpainting
Auf der RunComfy-Plattform lädt unsere Online-Version alle notwendigen Modi und Knoten für Sie vor. Außerdem bieten wir Hochleistungs-GPU-Maschinen, sodass Sie das ComfyUI FLUX Inpainting-Erlebnis mühelos genießen können.
5.5.3. Erklärung zu ComfyUI FLUX Inpainting:
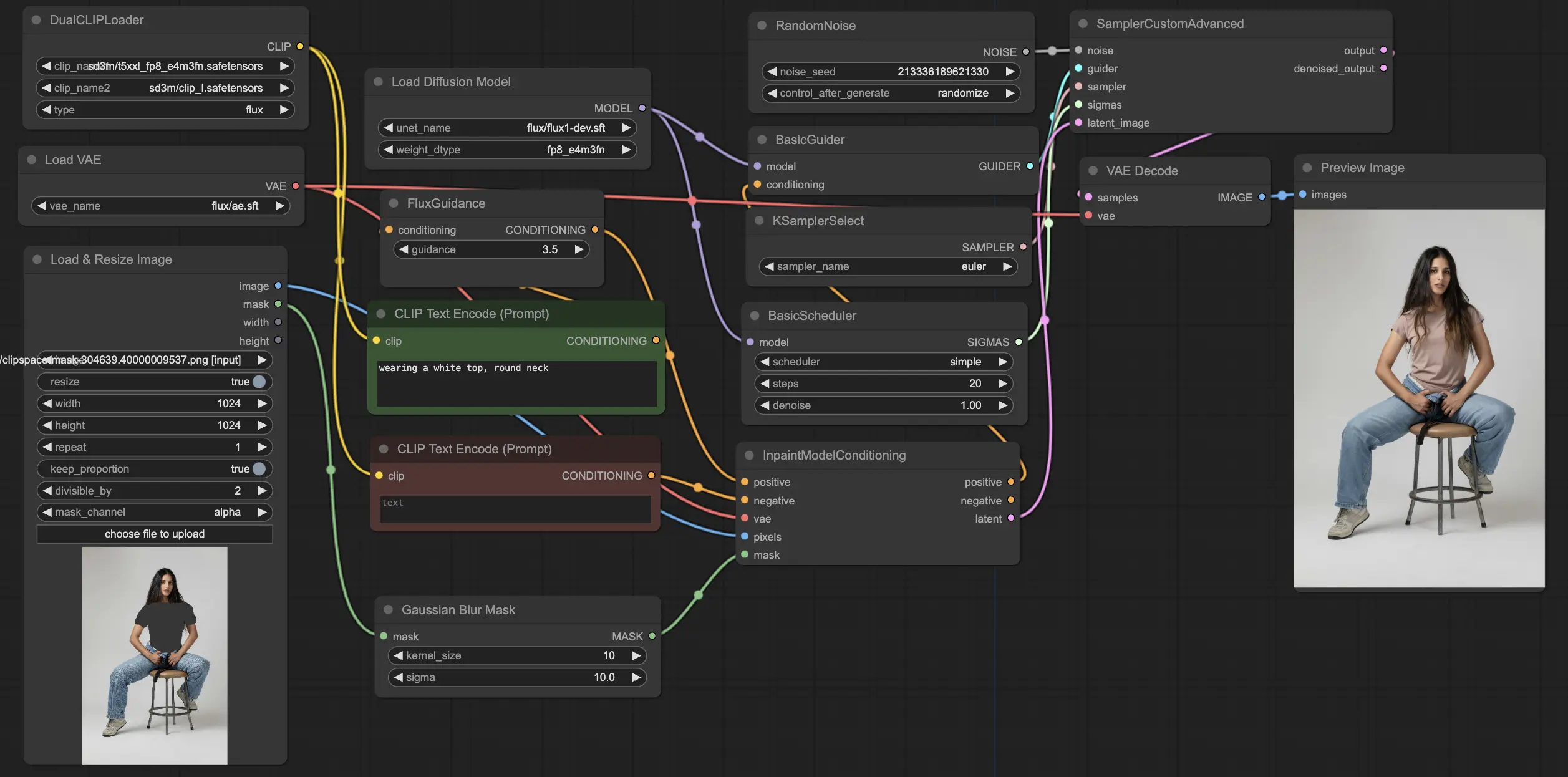
Der ComfyUI FLUX Inpainting Workflow demonstriert die Fähigkeit von ComfyUI FLUX, Inpainting durchzuführen, bei dem fehlende oder maskierte Bereiche eines Ausgabebildes basierend auf dem umgebenden Kontext und den bereitgestellten Texteingaben ausgefüllt werden. Der Workflow beginnt mit dem Laden der notwendigen Komponenten, einschließlich des UNET-Modells (UNETLoader), des VAE-Modells (VAELoader) und des CLIP-Modells (DualCLIPLoader).
- UNETLoader: Lädt das UNET-Modell zur Bildgenerierung.
- Checkpoint: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: Lädt das CLIP-Modell zur Textcodierung.
- Einbettungsmodell 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- Einbettungsmodell 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- Gruppierung: Die Gruppierungsstrategie für das CLIP-Modell ist flux
- VAELoader: Lädt das Variational Autoencoder (VAE) Modell zum Dekodieren latenter Repräsentationen.
- VAE-Modell: flux/ae.sft
Die positiven und negativen Texteingaben, die den gewünschten Inhalt und Stil für den zu überarbeitenden Bereich beschreiben, werden mit dem CLIPTextEncodes codiert. Die positive Textkonditionierung wird weiter mit der FluxGuidance geleitet, um den ComfyUI FLUX Inpainting-Prozess zu beeinflussen.
Die Eingabedarstellung und die Maske werden mit dem LoadAndResizeImage geladen und skaliert, um die Kompatibilität mit den Anforderungen von ComfyUI FLUX zu gewährleisten. Der ImpactGaussianBlurMask wendet einen Gaußschen Weichzeichner auf die Maske an und schafft so einen sanfteren Übergang zwischen dem überarbeiteten Bereich und der ursprünglichen Darstellung.
Die InpaintModelConditioning bereitet die Konditionierung für das FLUX Inpainting vor, indem die geleitete positive Textkonditionierung, die codierte negative Textkonditionierung, das geladene FLUX VAE, die geladene und skalierte Eingabedarstellung und die weichgezeichnete Maske kombiniert werden. Diese Konditionierung dient als Grundlage für den ComfyUI FLUX Inpainting-Prozess.
Zufälliges Rauschen wird mit dem RandomNoise generiert, und die Abtastmethode wird mit dem KSamplerSelect ausgewählt. Der BasicScheduler plant die Rauschpegel (Sigmas) für den ComfyUI FLUX Inpainting-Prozess und steuert dabei den Detailgrad und die Klarheit im überarbeiteten Bereich.
Der BasicGuider leitet den ComfyUI FLUX Inpainting-Prozess basierend auf der vorbereiteten Konditionierung und dem geladenen FLUX UNET. Der SamplerCustomAdvanced führt den fortschrittlichen Abtastprozess durch und nimmt das generierte zufällige Rauschen, den Guider, den ausgewählten Sampler, die geplanten Sigmas und die latente Repräsentation der Eingabe als Eingaben. Er gibt die überarbeitete latente Repräsentation aus.
Schließlich dekodiert der VAEDecode die überarbeitete latente Repräsentation in das endgültige Ergebnis und fügt den überarbeiteten Bereich nahtlos in die ursprüngliche Darstellung ein. Der PreviewImage zeigt das endgültige Ergebnis und demonstriert die beeindruckenden Inpainting-Fähigkeiten von FLUX.
Durch die Nutzung der Leistungsfähigkeit von FLUX und des sorgfältig gestalteten Inpainting-Workflows ermöglicht FLUX Inpainting die Erstellung visueller kohärenter und kontextuell relevanter überarbeiteter Ausgaben. Ob es darum geht, fehlende Teile wiederherzustellen, unerwünschte Objekte zu entfernen oder spezifische Bereiche zu modifizieren, der ComfyUI FLUX Inpainting Workflow bietet ein leistungsstarkes Werkzeug zur Bearbeitung und Manipulation.
5.6. ComfyUI Workflow: FLUX NF4
5.6.1. ComfyUI FLUX NF4: Download
5.6.2. ComfyUI FLUX NF4 Online-Version: ComfyUI FLUX NF4
Auf der RunComfy-Plattform lädt unsere Online-Version alle notwendigen Modi und Knoten für Sie vor. Außerdem bieten wir Hochleistungs-GPU-Maschinen, sodass Sie das ComfyUI FLUX NF4-Erlebnis mühelos genießen können.
5.6.3. Erklärung zu ComfyUI FLUX NF4:
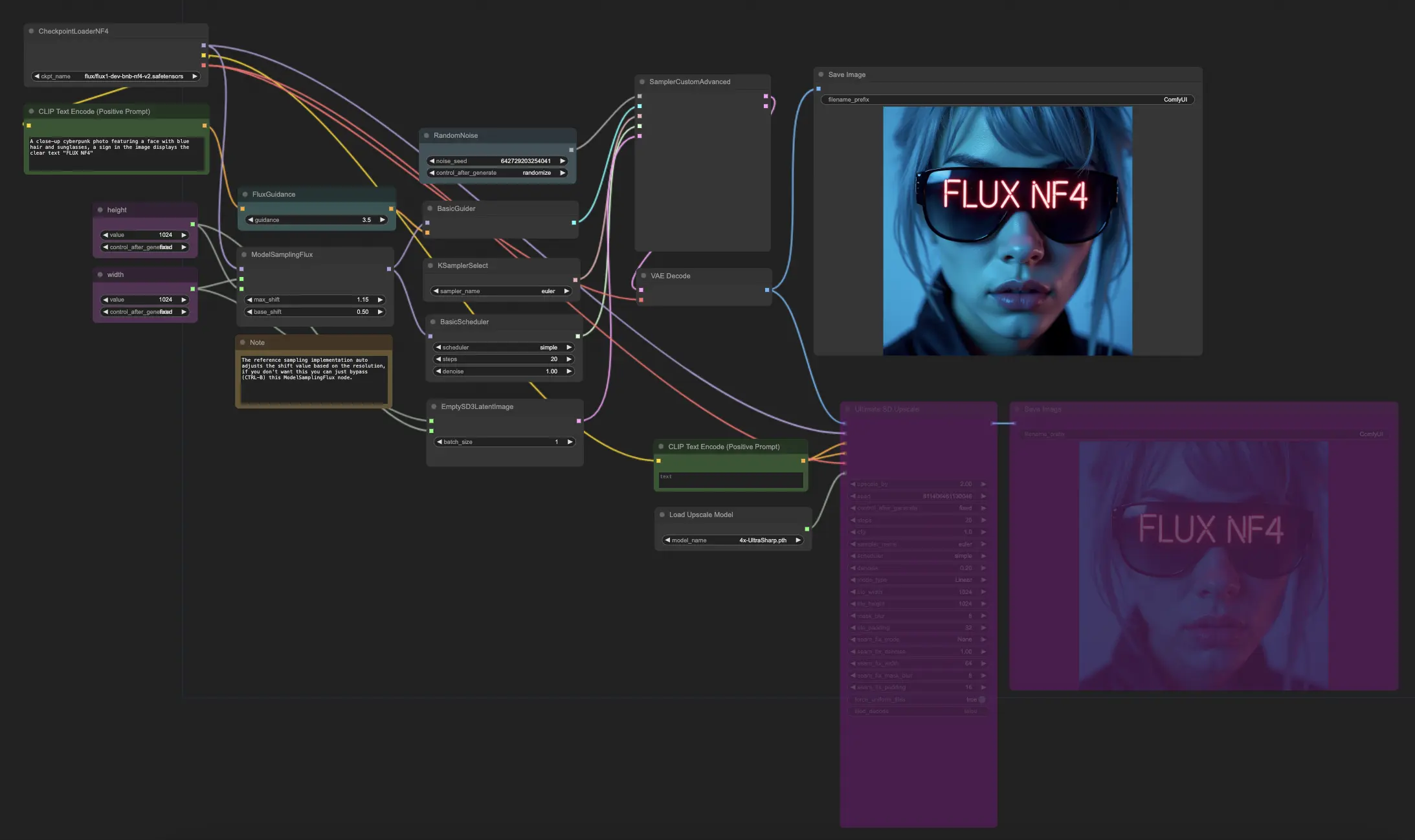
Der ComfyUI FLUX NF4 Workflow zeigt die Integration von ComfyUI FLUX mit der NF4 (Normalizing Flow 4) Architektur zur hochwertigen Ausgabeerzeugung. Der Workflow beginnt mit dem Laden der notwendigen Komponenten mit dem CheckpointLoaderNF4, einschließlich des FLUX UNET, des FLUX CLIP und des FLUX VAE.
- UNETLoader: Lädt das UNET-Modell zur Bildgenerierung.
- Checkpoint: TBD
Die PrimitiveNode (height) und PrimitiveNode (width) Knoten spezifizieren die gewünschte Höhe und Breite der generierten Ausgabe. Der ModelSamplingFlux Knoten setzt die Abtastparameter für ComfyUI FLUX basierend auf dem geladenen FLUX UNET und der spezifizierten Höhe und Breite.
Der EmptySD3LatentImage Knoten erstellt eine leere latente Repräsentation als Ausgangspunkt für die Generierung. Der BasicScheduler Knoten plant die Rauschpegel (Sigmas) für den ComfyUI FLUX Generierungsprozess.
Der RandomNoise Knoten generiert zufälliges Rauschen für den ComfyUI FLUX Generierungsprozess. Der BasicGuider Knoten leitet den Generierungsprozess basierend auf der konditionierten ComfyUI FLUX.
Der KSamplerSelect Knoten wählt die Abtastmethode für die ComfyUI FLUX Generierung. Der SamplerCustomAdvanced Knoten führt den fortschrittlichen Abtastprozess durch und nimmt das generierte zufällige Rauschen, den Guider, den ausgewählten Sampler, die geplanten Sigmas und die leere latente Repräsentation als Eingaben. Er gibt die generierte latente Repräsentation aus.
Der VAEDecode Knoten dekodiert die generierte latente Repräsentation in das endgültige Ergebnis unter Verwendung des geladenen FLUX VAE. Der SaveImage Knoten speichert die generierte Ausgabe an einem bestimmten Ort.
Zum Hochskalieren wird der UltimateSDUpscale Knoten verwendet. Er nimmt die generierte Ausgabe, das geladene FLUX, die positive und negative Konditionierung zum Hochskalieren, das geladene FLUX VAE und das geladene FLUX Hochskalieren als Eingaben. Der CLIPTextEncode (Upscale Positive Prompt) Knoten codiert die positive Texteingabe zum Hochskalieren. Der UpscaleModelLoader Knoten lädt das FLUX Hochskalieren. Der UltimateSDUpscale Knoten führt den Hochskalierungsprozess durch und gibt die hochskalierte Repräsentation aus. Schließlich speichert der SaveImage (Upscaled) Knoten die hochskalierte Ausgabe an einem bestimmten Ort.
Durch die Nutzung der Leistungsfähigkeit von ComfyUI FLUX und der NF4 Architektur ermöglicht der ComfyUI FLUX NF4 Workflow die Erzeugung hochwertiger Ausgaben mit verbesserter Treue und Realismus. Die nahtlose Integration von ComfyUI FLUX mit der NF4 Architektur bietet ein leistungsstarkes Werkzeug zur Erstellung atemberaubender und fesselnder Ausgaben.
5.7. ComfyUI Workflow: FLUX IPAdapter
5.7.1. ComfyUI FLUX IPAdapter: Download
5.7.2. ComfyUI FLUX IPAdapter Online-Version: ComfyUI FLUX IPAdapter
Auf der RunComfy-Plattform lädt unsere Online-Version alle notwendigen Modi und Knoten für Sie vor. Außerdem bieten wir Hochleistungs-GPU-Maschinen, sodass Sie das ComfyUI FLUX IPAdapter-Erlebnis mühelos genießen können.
5.7.3. Erklärung zu ComfyUI FLUX IPAdapter:
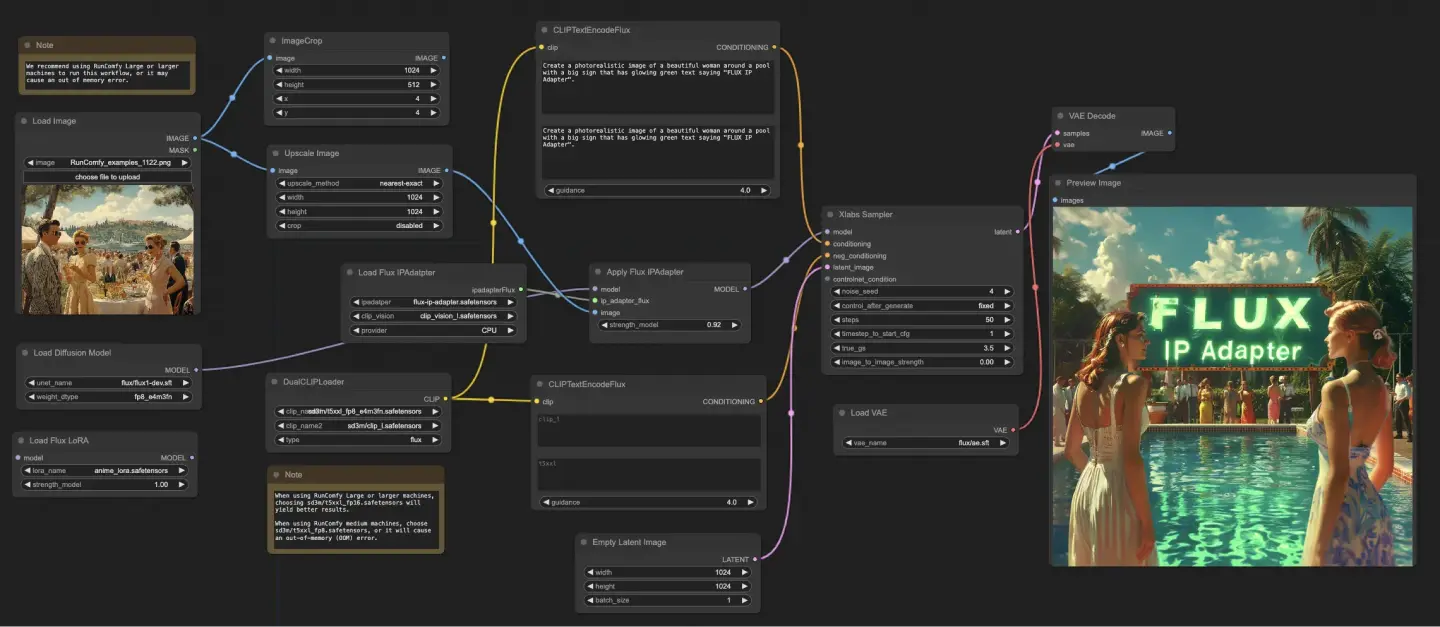
Der ComfyUI FLUX IPAdapter Workflow beginnt mit dem Laden der notwendigen Modelle, einschließlich des UNET-Modells (UNETLoader), des CLIP-Modells (DualCLIPLoader) und des VAE-Modells (VAELoader).
Die positiven und negativen Texteingaben werden mit dem CLIPTextEncodeFlux codiert. Die positive Textkonditionierung wird verwendet, um den ComfyUI FLUX Generierungsprozess zu leiten.
Das Eingabebild wird mit dem LoadImage geladen. Der LoadFluxIPAdapter lädt den IP-Adapter für das FLUX-Modell, der dann auf das geladene UNET-Modell mit dem ApplyFluxIPAdapter angewendet wird. Der ImageScale skaliert das Eingabebild auf die gewünschte Größe, bevor der IP-Adapter angewendet wird.
- LoadFluxIPAdapter: Lädt den IP-Adapter für das FLUX-Modell.
- IP Adapter Modell: flux-ip-adapter.safetensors
- CLIP Vision Encoder: clip_vision_l.safetensors
Der EmptyLatentImage erstellt eine leere latente Repräsentation als Ausgangspunkt für die ComfyUI FLUX Generierung.
Der XlabsSampler führt den Abtastprozess durch und nimmt das FLUX UNET mit angewendetem IP-Adapter, die codierte positive und negative Textkonditionierung und die leere latente Repräsentation als Eingaben. Er erzeugt eine latente Repräsentation.
Der VAEDecode dekodiert die generierte latente Repräsentation in das endgültige Ergebnis unter Verwendung des geladenen FLUX VAE. Der PreviewImage Knoten zeigt eine Vorschau des endgültigen Ergebnisses.
Der ComfyUI FLUX IPAdapter Workflow nutzt die Leistungsfähigkeit von ComfyUI FLUX und den IP-Adapter zur Erzeugung hochwertiger Ausgaben, die den bereitgestellten Texteingaben entsprechen. Durch die Anwendung des IP-Adapters auf das FLUX UNET ermöglicht der Workflow die Erzeugung von Ausgaben, die die gewünschten Eigenschaften und den gewünschten Stil der Textkonditionierung erfassen.
5.8. ComfyUI Workflow: Flux LoRA Trainer

5.8.1. ComfyUI FLUX LoRA Trainer: Download
5.8.2. Erklärung zu ComfyUI Flux LoRA Trainer:
Der ComfyUI FLUX LoRA Trainer Workflow besteht aus mehreren Phasen zum Training einer LoRA unter Verwendung der FLUX-Architektur in ComfyUI.
ComfyUI FLUX Auswahl und Konfiguration: Der FluxTrainModelSelect Knoten wird verwendet, um die Komponenten für das Training auszuwählen, einschließlich des UNET, VAE, CLIP und CLIP Text Encoders. Der OptimizerConfig Knoten konfiguriert die Optimierer-Einstellungen für das ComfyUI FLUX Training, wie den Optimierertyp, die Lernrate und den Gewichtungsverfall. Die TrainDatasetGeneralConfig und TrainDatasetAdd Knoten werden verwendet, um das Trainingsdatenset zu konfigurieren, einschließlich der Auflösung, der Augmentationseinstellungen und der Batch-Größen.
ComfyUI FLUX Training Initialisierung: Der InitFluxLoRATraining Knoten initialisiert den LoRA Trainingsprozess unter Verwendung der ausgewählten Komponenten, der Datenset-Konfiguration und der Optimierer-Einstellungen. Der FluxTrainValidationSettings Knoten konfiguriert die Validierungseinstellungen für das Training, wie die Anzahl der Validierungsproben, die Auflösung und die Batch-Größe.
ComfyUI FLUX Trainingsschleife: Der FluxTrainLoop Knoten führt die Trainingsschleife für die LoRA durch und iteriert eine bestimmte Anzahl von Schritten. Nach jeder Trainingsschleife validiert der FluxTrainValidate Knoten die trainierte LoRA unter Verwendung der Validierungseinstellungen und erzeugt Validierungsausgaben. Der PreviewImage Knoten zeigt eine Vorschau der Validierungsergebnisse. Der FluxTrainSave Knoten speichert die trainierte LoRA in festgelegten Intervallen.
ComfyUI FLUX Verlustvisualisierung: Der VisualizeLoss Knoten visualisiert iert den Trainingsverlust im Verlauf des Trainings. Der SaveImage Knoten speichert das Verlustdiagramm zur weiteren Analyse.
ComfyUI FLUX Validierungsausgabe-Verarbeitung: Die AddLabel und SomethingToString Knoten werden verwendet, um den Validierungsausgaben Labels hinzuzufügen, die die Trainingsschritte angeben. Die ImageBatchMulti und ImageConcatFromBatch Knoten kombinieren und verketten die Validierungsausgaben zu einem einzigen Ergebnis zur einfacheren Visualisierung.
ComfyUI FLUX Trainingsabschluss: Der FluxTrainEnd Knoten finalisiert den LoRA Trainingsprozess und speichert die trainierte LoRA. Der UploadToHuggingFace Knoten kann verwendet werden, um die trainierte LoRA zu Hugging Face hochzuladen, um sie weiter zu teilen und mit ComfyUI FLUX zu nutzen.
5.9. ComfyUI Workflow: Flux Latent Upscaler
5.9.1. ComfyUI Flux Latent Upscaler: Download
5.9.2. Erklärung zu ComfyUI Flux Latent Upscaler:
Der ComfyUI Flux Latent Upscale Workflow beginnt mit dem Laden der notwendigen Komponenten, einschließlich des CLIP (DualCLIPLoader), des UNET (UNETLoader) und des VAE (VAELoader). Die Texteingabe wird mit dem CLIPTextEncode Knoten codiert, und Anleitungen werden mit dem FluxGuidance Knoten angewendet.
Der SDXLEmptyLatentSizePicker+ Knoten spezifiziert die Größe der leeren latenten Repräsentation, die als Ausgangspunkt für den Hochskalierungsprozess in FLUX dient. Die latente Repräsentation wird dann durch eine Reihe von Hochskalierungs- und Zuschneideschritten mit den Knoten LatentUpscale und LatentCrop verarbeitet.
Der Hochskalierungsprozess wird durch die codierte Textkonditionierung geleitet und verwendet den SamplerCustomAdvanced Knoten mit der ausgewählten Abtastmethode (KSamplerSelect) und den geplanten Rauschpegeln (BasicScheduler). Der ModelSamplingFlux Knoten setzt die Abtastparameter.
Die hochskalierte latente Repräsentation wird dann mit der ursprünglichen latenten Repräsentation unter Verwendung des LatentCompositeMasked Knotens und einer Maske, die von den Knoten SolidMask und FeatherMask erzeugt wird, zusammengesetzt. Rauschen wird in die hochskalierte latente Repräsentation mit dem InjectLatentNoise+ Knoten injiziert.
Schließlich wird die hochskalierte latente Repräsentation mit dem VAEDecode Knoten in das endgültige Ergebnis dekodiert, und eine intelligente Schärfung wird mit dem ImageSmartSharpen+ Knoten angewendet. Der PreviewImage Knoten zeigt eine Vorschau des endgültigen Ergebnisses, das von ComfyUI FLUX generiert wurde.
Der ComfyUI FLUX Latent Upscaler Workflow umfasst auch verschiedene mathematische Operationen unter Verwendung der Knoten SimpleMath+, SimpleMathFloat+, SimpleMathInt+ und SimpleMathPercent+, um Dimensionen, Verhältnisse und andere Parameter für den Hochskalierungsprozess zu berechnen.