
1. Acerca de CogVideoX-5B#
CogVideoX-5B es un modelo de difusión de texto a video de vanguardia desarrollado por Zhipu AI en la Universidad de Tsinghua. Como parte de la serie CogVideoX, este modelo crea videos directamente a partir de indicaciones de texto utilizando técnicas avanzadas de IA como un 3D Variational Autoencoder (VAE) y un Expert Transformer. CogVideoX-5B genera resultados de alta calidad y consistencia temporal que capturan movimientos complejos y semántica detallada.
Con CogVideoX-5B, se logra una claridad y fluidez excepcionales. El modelo asegura un flujo sin interrupciones, capturando detalles intrincados y elementos dinámicos con una precisión extraordinaria. Aprovechar CogVideoX-5B reduce inconsistencias y artefactos, llevando a una presentación pulida y atractiva. Las salidas de alta fidelidad de CogVideoX-5B facilitan la creación de escenas ricamente detalladas y coherentes a partir de indicaciones de texto, convirtiéndolo en una herramienta esencial para calidad superior e impacto visual.
2. La Técnica de CogVideoX-5B#
2.1 3D Causal Variational Autoencoder (VAE) de CogVideoX-5B#
El 3D Causal VAE es un componente clave de CogVideoX-5B, permitiendo una generación de video eficiente al comprimir datos de video tanto espacial como temporalmente. A diferencia de los modelos tradicionales que usan 2D VAEs para procesar cada cuadro individualmente—lo que a menudo resulta en parpadeos entre cuadros—CogVideoX-5B utiliza convoluciones 3D para capturar información espacial y temporal a la vez. Este enfoque asegura transiciones suaves y coherentes entre cuadros.
La arquitectura del 3D Causal VAE incluye un codificador, un decodificador y un regulador de espacio latente. El codificador comprime los datos de video en una representación latente, que el decodificador luego usa para reconstruir el video. Un regulador Kullback-Leibler (KL) restringe el espacio latente, asegurando que el video codificado permanezca dentro de una distribución gaussiana. Esto ayuda a mantener alta calidad de video durante la reconstrucción.
Características Clave del 3D Causal VAE
- Compresión Espacial y Temporal: El VAE comprime los datos de video por un factor de 4x en la dimensión temporal y 8x8 en las dimensiones espaciales, logrando una relación de compresión total de 4x8x8. Esto reduce las demandas computacionales, permitiendo al modelo procesar videos más largos con menos recursos.
- Convolución Causal: Para preservar el orden de los cuadros en un video, el modelo utiliza convoluciones temporalmente causales. Esto asegura que los cuadros futuros no influyan en la predicción de cuadros actuales o pasados, manteniendo la integridad de la secuencia durante la generación.
- Paralelismo de Contexto: Para gestionar la alta carga computacional de procesar videos largos, el modelo utiliza paralelismo de contexto en la dimensión temporal, distribuyendo la carga de trabajo a través de múltiples dispositivos. Esto optimiza el proceso de entrenamiento y reduce el uso de memoria.
2.2 Arquitectura Expert Transformer de CogVideoX-5B#
La arquitectura expert transformer de CogVideoX-5B está diseñada para manejar de manera efectiva la compleja interacción entre datos de texto y video. Utiliza una técnica adaptativa de LayerNorm para procesar los distintos espacios de características del texto y el video.
Características Clave del Expert Transformer
- Patchificación: Después de que el 3D Causal VAE codifica los datos de video, estos se dividen en parches más pequeños a lo largo de las dimensiones espaciales. Este proceso, llamado patchificación, convierte el video en una secuencia de segmentos más pequeños, facilitando al transformer procesar y alinear con los datos de texto correspondientes.
- 3D Rotary Positional Embedding (RoPE): Para capturar relaciones espaciales y temporales dentro del video, CogVideoX-5B extiende el RoPE 2D tradicional a 3D. Esta técnica de incrustación aplica codificación posicional a las dimensiones x, y, y t del video, ayudando al transformer a modelar efectivamente secuencias largas de video y mantener consistencia entre cuadros.
- Expert Adaptive LayerNorm (AdaLN): El transformer utiliza un expert adaptive LayerNorm para procesar las incrustaciones de texto y video por separado. Esto permite al modelo alinear los diferentes espacios de características del texto y el video, permitiendo una fusión suave de estas dos modalidades.
2.3 Técnicas de Entrenamiento Progresivo de CogVideoX-5B#
CogVideoX-5B utiliza varias técnicas de entrenamiento progresivo para mejorar su rendimiento y estabilidad durante la generación de video.
Estrategias Clave de Entrenamiento Progresivo
- Entrenamiento de Duración Mixta: El modelo se entrena en videos de varias longitudes dentro del mismo lote. Esta técnica mejora la capacidad del modelo para generalizar, permitiéndole generar videos de diferentes duraciones mientras mantiene una calidad consistente.
- Entrenamiento Progresivo de Resolución: El modelo se entrena primero en videos de baja resolución y luego se ajusta gradualmente en videos de mayor resolución. Este enfoque permite al modelo aprender la estructura y contenido básicos de los videos antes de refinar su comprensión en resoluciones más altas.
- Muestreo Uniforme Explícito: Para estabilizar el proceso de entrenamiento, CogVideoX-5B utiliza muestreo uniforme explícito, estableciendo diferentes intervalos de muestreo de tiempo para cada rango paralelo de datos. Este método acelera la convergencia y asegura que el modelo aprenda efectivamente a lo largo de toda la secuencia de video.
3. Cómo Usar el Workflow de CogVideoX-5B en ComfyUI#
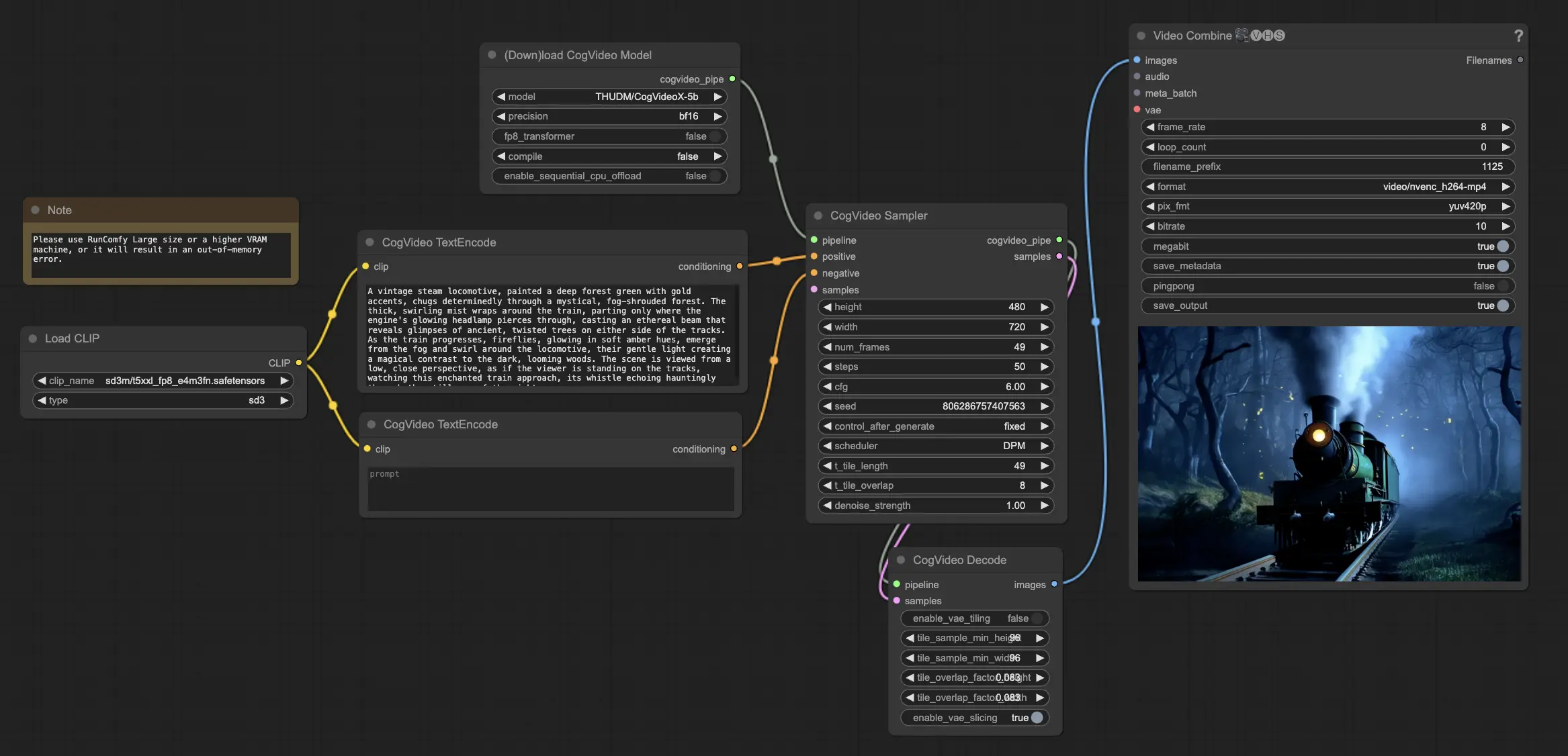
Paso 1: Cargar el Modelo CogVideoX-5B#
Comienza cargando el modelo CogVideoX-5B en el workflow de ComfyUI. Los modelos CogVideoX-5B han sido precargados en la plataforma de RunComfy.
Paso 2: Introduce Tu Indicación de Texto#
Ingresa tu indicación de texto deseada en el nodo designado para guiar el proceso de generación de video de CogVideoX-5B. CogVideoX-5B sobresale en interpretar y transformar indicaciones de texto en contenido de video dinámico.
4. Acuerdo de Licencia#
El código de los modelos CogVideoX se libera bajo la Apache 2.0 License.
El modelo CogVideoX-2B (incluyendo su módulo de Transformers correspondiente y módulo VAE) se libera bajo la Apache 2.0 License.
El modelo CogVideoX-5B (módulo de Transformers) se libera bajo la CogVideoX LICENSE.