Vid2Vid Parte 1 | Composición y Enmascaramiento
El ComfyUI Vid2Vid ofrece dos flujos de trabajo distintos para crear animaciones de alta calidad y profesionales: Vid2Vid Parte 1, que mejora tu creatividad al centrarse en la composición y el enmascaramiento de tu video original, y Vid2Vid Parte 2, que utiliza SDXL Style Transfer para transformar el estilo de tu video para que coincida con tu estética deseada. Esta página cubre específicamente Vid2Vid Parte 1ComfyUI Vid2Vid Flujo de trabajo

- Flujos de trabajo completamente operativos
- Sin nodos ni modelos faltantes
- No se requiere configuración manual
- Presenta visuales impresionantes
ComfyUI Vid2Vid Ejemplos
ComfyUI Vid2Vid Descripción
El flujo de trabajo ComfyUI Vid2Vid, creado por , presenta dos flujos de trabajo distintos para lograr animaciones de alta calidad y profesionales.
- El primer flujo de trabajo de ComfyUI: ComfyUI Vid2Vid Parte 1 | Composición y Enmascaramiento
- El segundo flujo de trabajo:
ComfyUI Vid2Vid Parte 1 | Composición y Enmascaramiento
Este flujo de trabajo mejora la creatividad al centrarse en la composición y el enmascaramiento de tu video original.
Paso 1: Cargador de Modelos | ComfyUI Vid2Vid Workflow Parte1
Selecciona los modelos apropiados para tu animación. Esto incluye elegir el modelo de checkpoint, el modelo VAE (Variational Autoencoder) y el modelo LoRA (Low-Rank Adaptation). Estos modelos son cruciales para definir las capacidades y el estilo de tu animación.
Paso 2: Cargador de Video | ComfyUI Vid2Vid Workflow Parte1
El nodo Input Video es responsable de importar el archivo de video que se utilizará para la animación. El nodo lee el video y lo convierte en fotogramas individuales, que luego se procesan en pasos posteriores. Esto permite una edición y mejora detallada fotograma a fotograma.
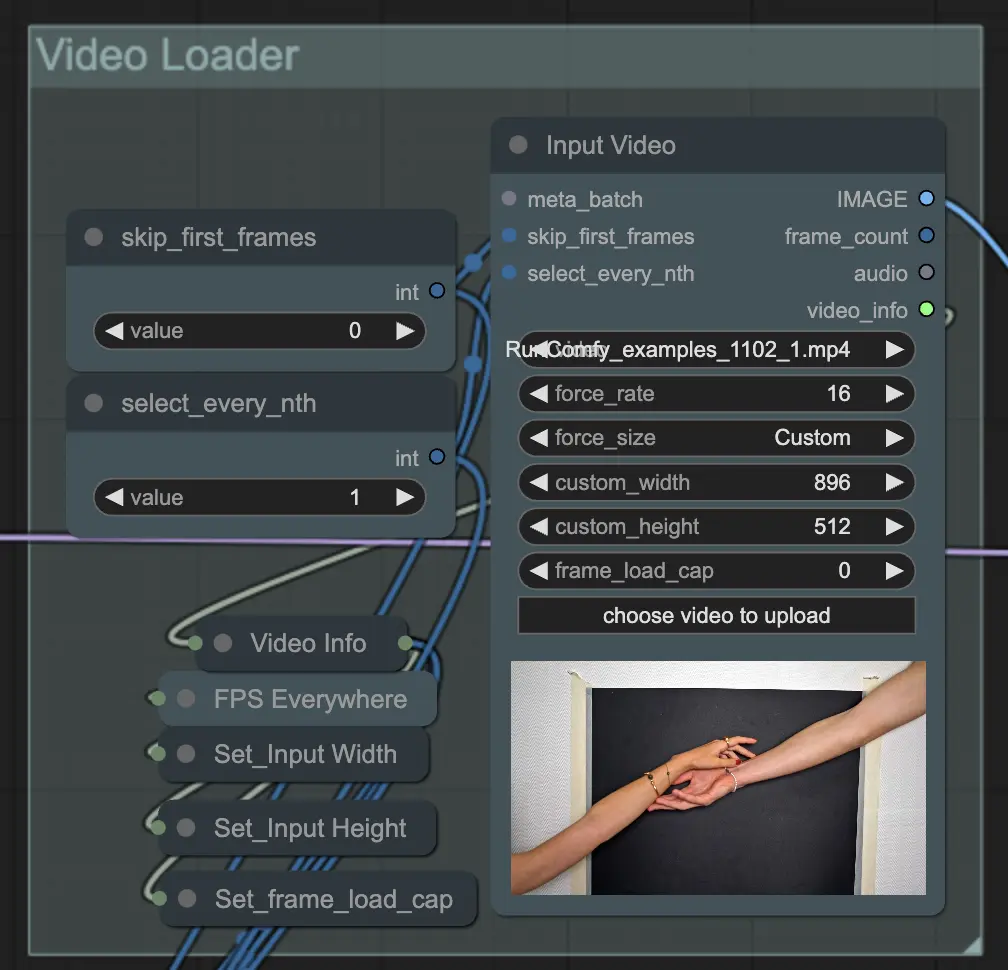
Paso 3: Eliminar Fondo (Enmascaramiento Automático) | ComfyUI Vid2Vid Workflow Parte1
Remove Background (Auto Masking) aísla el sujeto del fondo utilizando una técnica de enmascaramiento automatizada. Esto implica modelos que detectan y separan el sujeto del primer plano del fondo, creando una máscara binaria. Este paso es crucial para garantizar que el sujeto pueda ser manipulado independientemente del fondo.
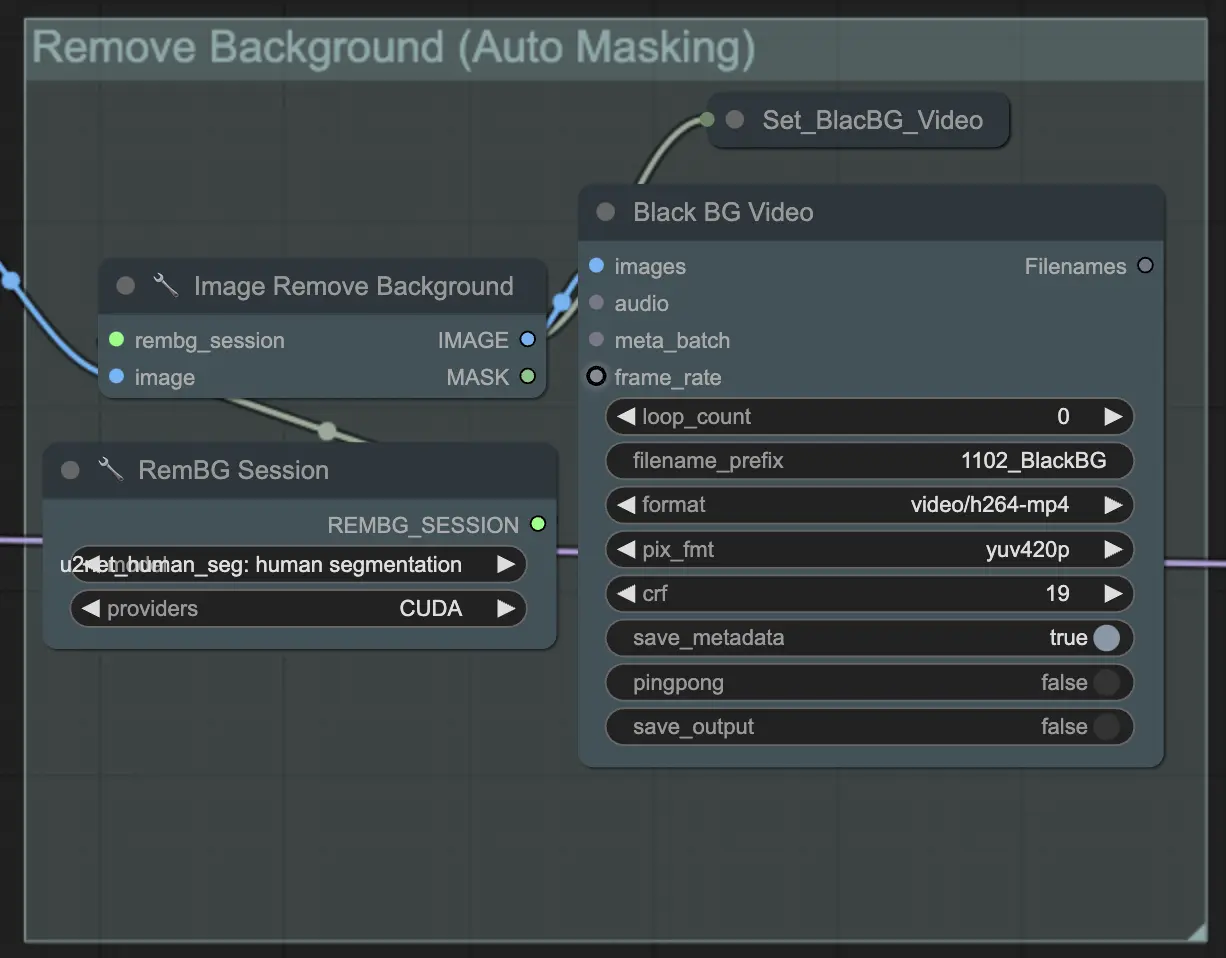
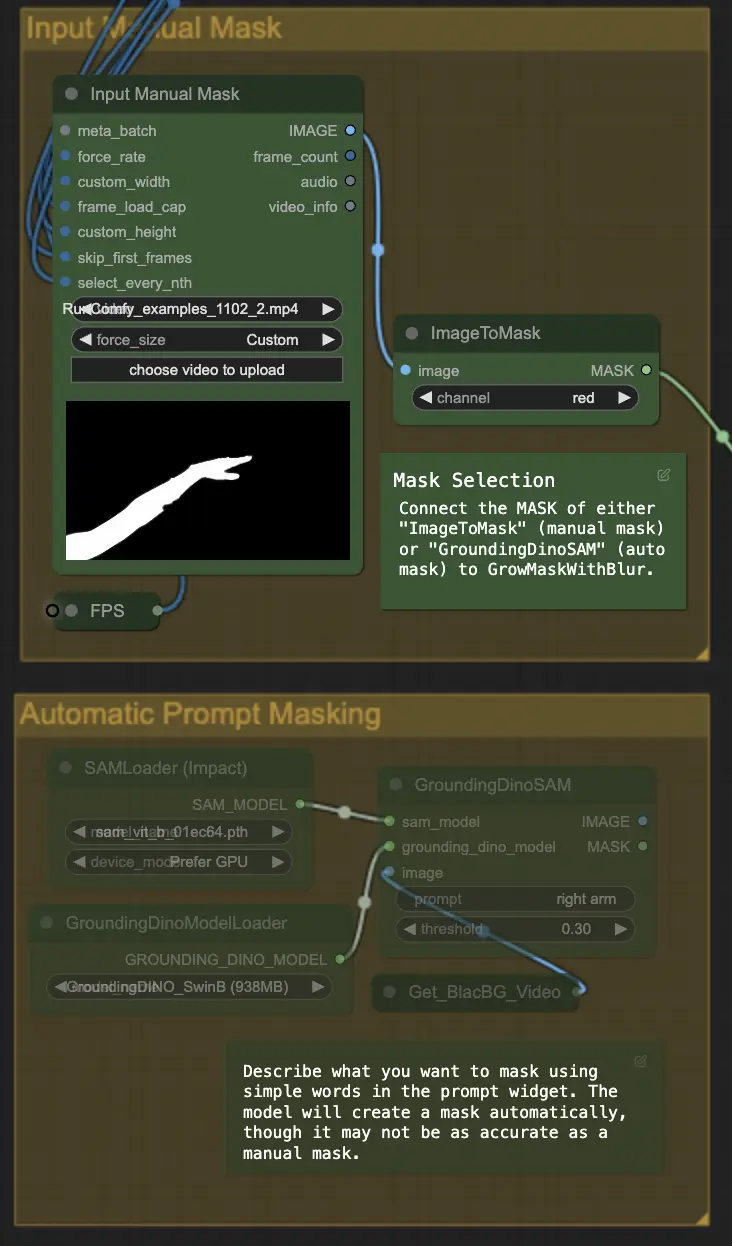
Paso 4: Enmascarar Área Específica (Máscara Manual o Automática) | ComfyUI Vid2Vid Workflow Parte1
Este paso permite la refinación de la máscara creada en el paso anterior. Puedes enmascarar áreas específicas manualmente usando otro software o confiar en la función de máscara automatizada 'Segment Anything' de ComfyUI.
- Máscara Manual: Esto debe manejarse con otro software fuera de ComfyUI para un control preciso.
- Máscara Automática: Usando la función de máscara automática, puedes describir lo que quieres enmascarar usando palabras simples en el widget de prompt. El modelo creará una máscara automáticamente, aunque puede no ser tan precisa como una máscara manual.
La versión predeterminada usa una máscara manual. Si deseas probar la automática, por favor omite el grupo de máscara manual y habilita el grupo de máscara automática. Además, conecta la MÁSCARA de 'GroundingDinoSAM' (máscara automática) a 'GrowMaskWithBlur' en lugar de conectar 'ImageToMask' (máscara manual) a 'GrowMaskWithBlur'.
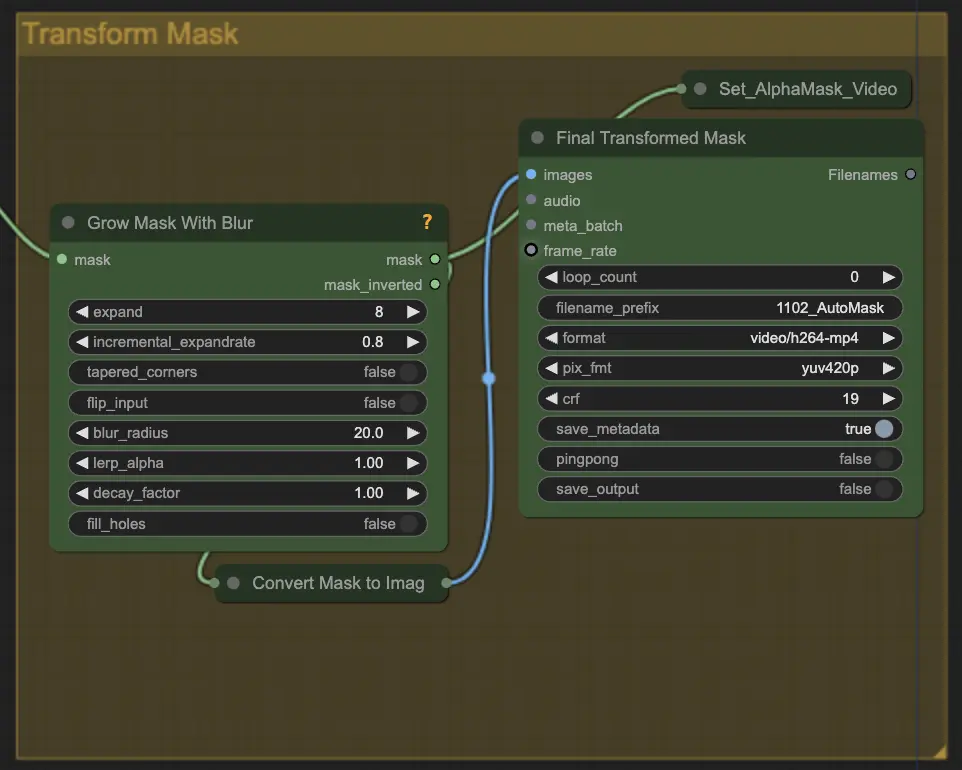
Paso 5: Transformar Máscara | ComfyUI Vid2Vid Workflow Parte1
Transform Mask convierte la máscara en una imagen y permite ajustes adicionales como agregar desenfoque a la máscara original. Esto ayuda a suavizar los bordes y hacer que la máscara se mezcle más naturalmente con el resto de la imagen.
Paso 6: Prompt de Entrada | ComfyUI Vid2Vid Workflow Parte1
Introduce prompts textuales para guiar el proceso de animación. El prompt puede describir el estilo deseado, la apariencia o las acciones del sujeto. Es crucial para definir la dirección creativa de la animación, asegurando que el resultado final coincida con el estilo artístico previsto.
Paso 7: AnimateDiff | ComfyUI Vid2Vid Workflow Parte1
El nodo AnimateDiff crea animaciones suaves identificando diferencias entre fotogramas consecutivos y aplicando estos cambios de manera incremental. Esto ayuda a preservar la coherencia del movimiento y reducir cambios bruscos en la animación, lo que conduce a una apariencia más fluida y natural.
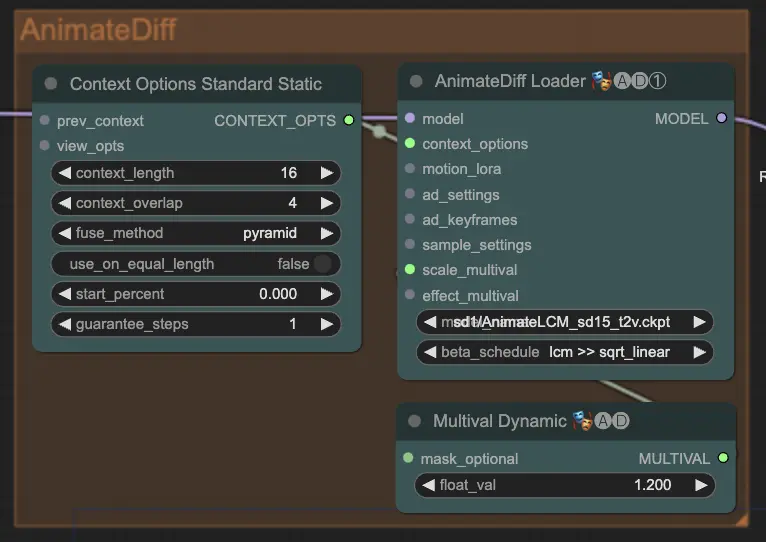
Paso 8: IPAdapter | ComfyUI Vid2Vid Workflow Parte1
El nodo IPAdapter adapta las imágenes de entrada para alinearlas con los estilos o características de salida deseados. Esto incluye tareas como la colorización y la transferencia de estilo, asegurando que cada fotograma de la animación mantenga una apariencia y sensación consistentes.
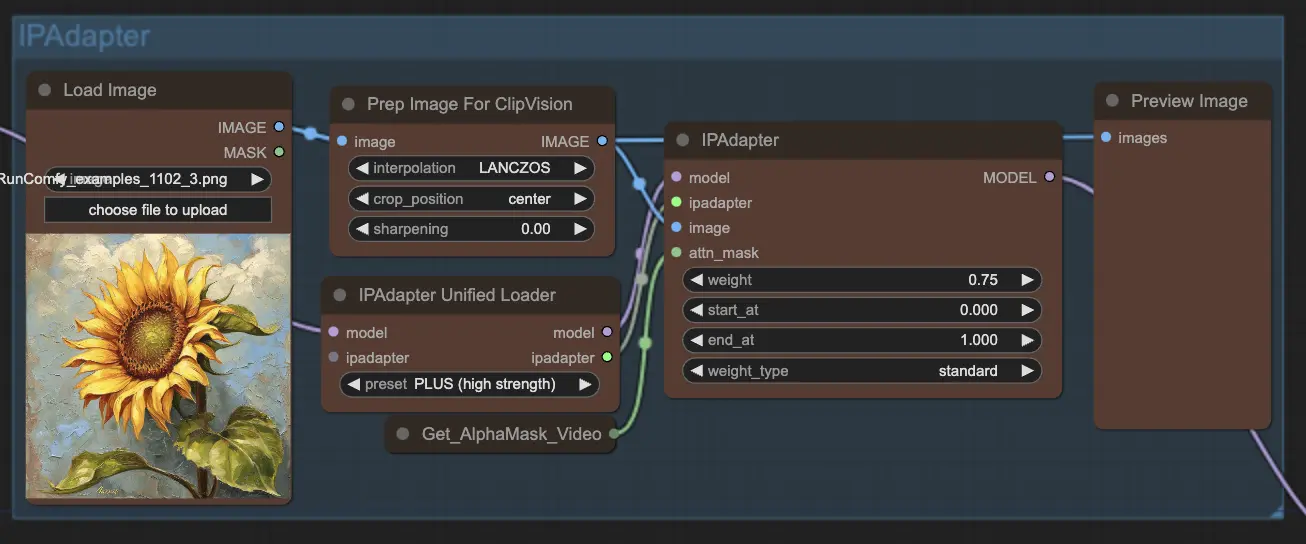
Paso 9: ControlNet | ComfyUI Vid2Vid Workflow Parte1
Usar ControlNet - v1.1 - Instruct Pix2Pix Version model mejora los modelos de difusión permitiéndoles procesar condiciones de entrada adicionales (por ejemplo, mapas de bordes, mapas de segmentación). Facilita la generación de texto a imagen controlando estos modelos preentrenados con condiciones específicas de la tarea de manera integral, permitiendo un aprendizaje robusto incluso con conjuntos de datos más pequeños.
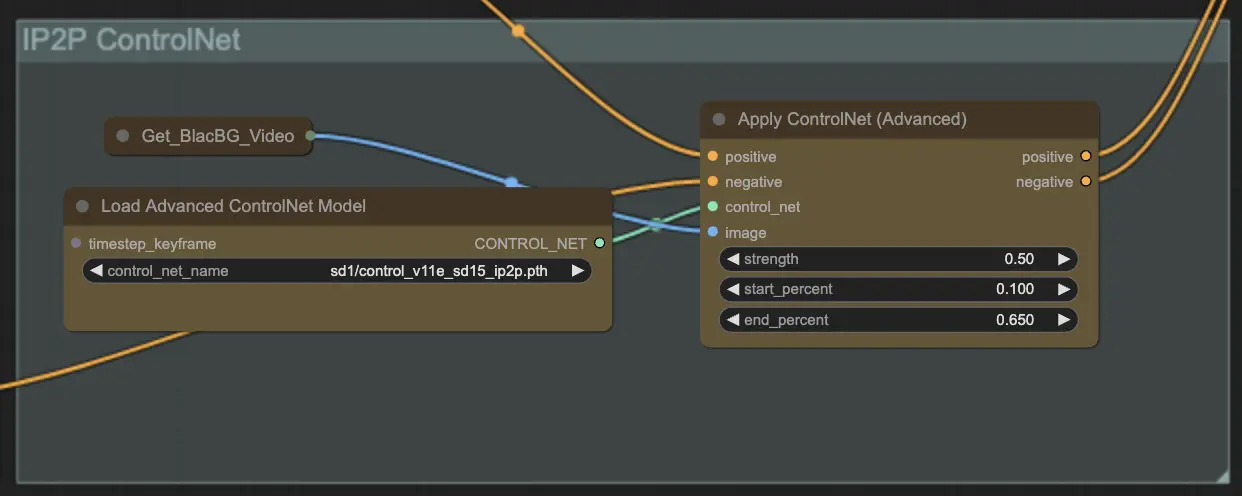
Paso 10: Renderizar | ComfyUI Vid2Vid Workflow Parte1
En el paso de Render, los fotogramas procesados se compilan en una salida final de video. Este paso asegura que todos los fotogramas individuales se combinen sin problemas en una animación coherente, lista para exportar y usar ulteriormente.
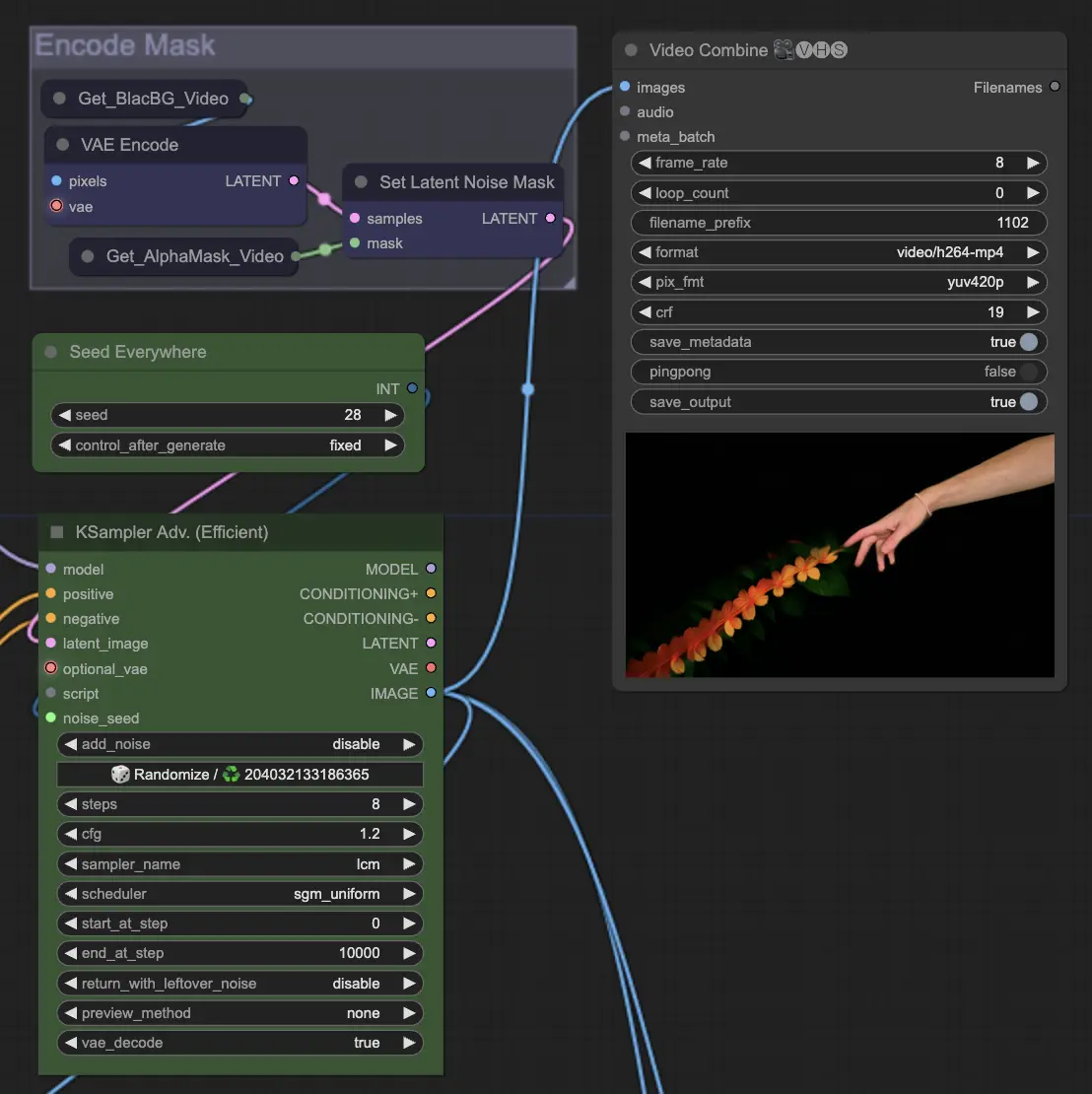
Paso 11: Componer Fondo | ComfyUI Vid2Vid Workflow Parte1
Esto implica componer el sujeto animado con el fondo. Puedes agregar un fondo estático o dinámico a la animación, asegurando que el sujeto se integre suavemente con el nuevo fondo para crear un producto final visualmente atractivo.
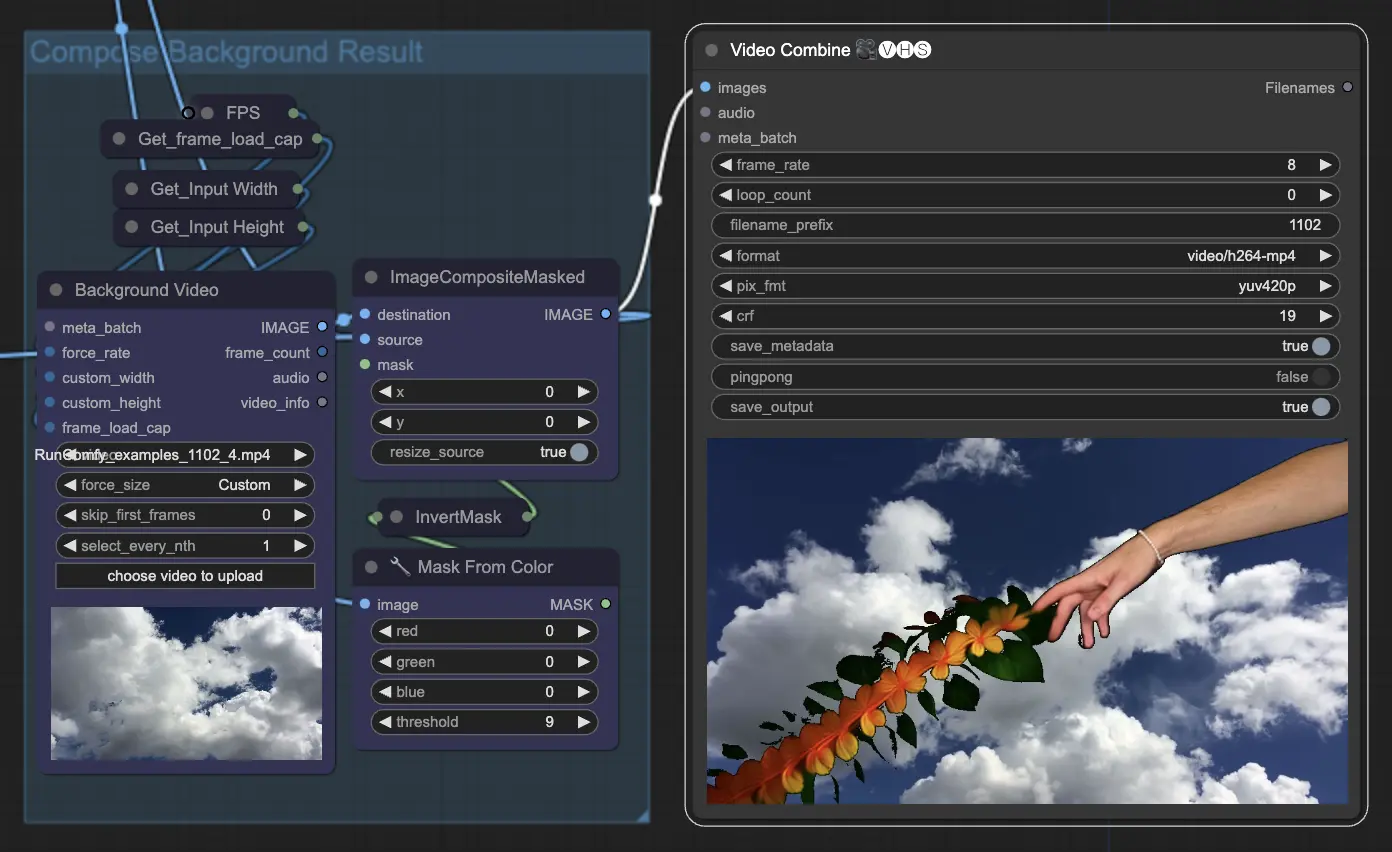
Al utilizar el flujo de trabajo ComfyUI Vid2Vid Parte1, puedes crear animaciones intrincadas con control preciso sobre cada aspecto del proceso, desde la composición y el enmascaramiento hasta el renderizado final.