LatentSync| Modelo de Sincronización Labial
LatentSync redefine la sincronización labial con modelos de difusión latente condicionados por audio, evitando representaciones de movimiento intermedias para un alineamiento audio-visual perfecto. Aprovechando Stable Diffusion, captura correlaciones intrincadas mientras asegura suavidad temporal. A diferencia de los enfoques basados en píxeles, LatentSync garantiza una consistencia temporal superior con su innovador módulo de Alineación de Representación Temporal (TREPA). El módulo TREPA ayuda a entregar una precisión y realismo incomparables.ComfyUI LatentSync Flujo de trabajo
- Flujos de trabajo completamente operativos
- Sin nodos ni modelos faltantes
- No se requiere configuración manual
- Presenta visuales impresionantes
ComfyUI LatentSync Ejemplos
ComfyUI LatentSync Descripción
LatentSync es un marco de sincronización labial de última generación de extremo a extremo que aprovecha el poder de los modelos de difusión latente condicionados por audio para la generación realista de sincronización labial. Lo que distingue a LatentSync es su capacidad para modelar directamente las complejas correlaciones entre los componentes de audio y visuales sin depender de ninguna representación de movimiento intermedia, revolucionando el enfoque de la síntesis de sincronización labial.
En el núcleo del pipeline de LatentSync está la integración de Stable Diffusion, un poderoso modelo generativo reconocido por su excepcional capacidad para capturar y generar imágenes de alta calidad. Al aprovechar las capacidades de Stable Diffusion, LatentSync puede aprender y reproducir efectivamente las complejas dinámicas entre el audio del habla y los movimientos labiales correspondientes, resultando en animaciones de sincronización labial altamente precisas y convincentes.
Uno de los desafíos clave en los métodos de sincronización labial basados en difusión es mantener la consistencia temporal a través de los cuadros generados, lo cual es crucial para obtener resultados realistas. LatentSync aborda este problema de frente con su innovador módulo de Alineación de Representación Temporal (TREPA), específicamente diseñado para mejorar la coherencia temporal de las animaciones de sincronización labial. TREPA emplea técnicas avanzadas para extraer representaciones temporales de los cuadros generados utilizando modelos de video auto-supervisados a gran escala. Al alinear estas representaciones con los cuadros de verdad de terreno, el marco de LatentSync asegura un alto grado de coherencia temporal, resultando en animaciones de sincronización labial notablemente suaves y convincentes que coinciden estrechamente con la entrada de audio.
1.1 ¿Cómo usar el flujo de trabajo de LatentSync?
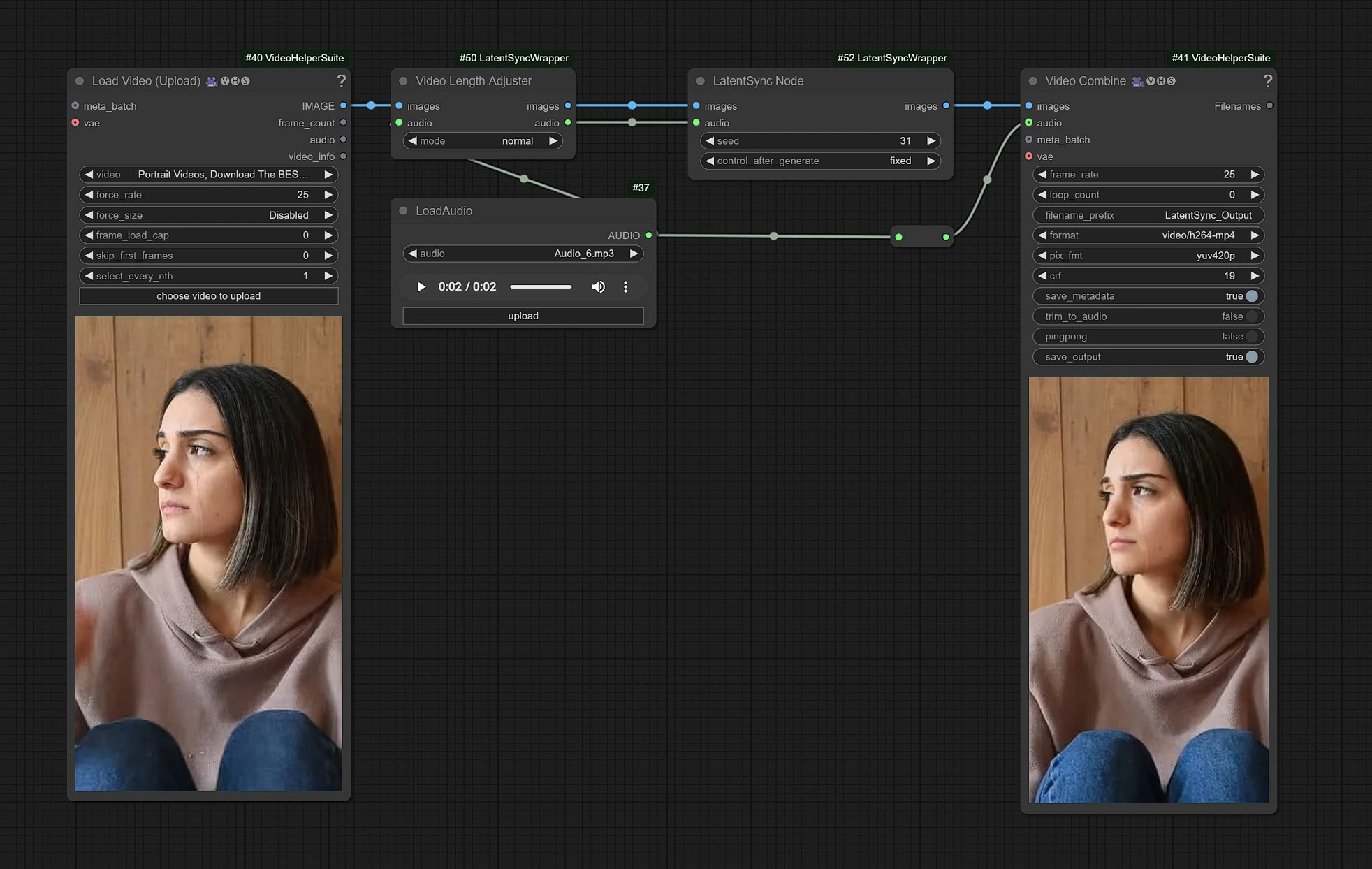
Este es el flujo de trabajo de LatentSync, los nodos del lado izquierdo son entradas para subir video, el medio es el procesamiento de nodos de LatentSync, y la derecha es el nodo de salidas.
- Suba su Video en los nodos de entrada.
- Suba su entrada de Audio de diálogos.
- Haga clic en Renderizar !!!
1.2 Entrada de Video
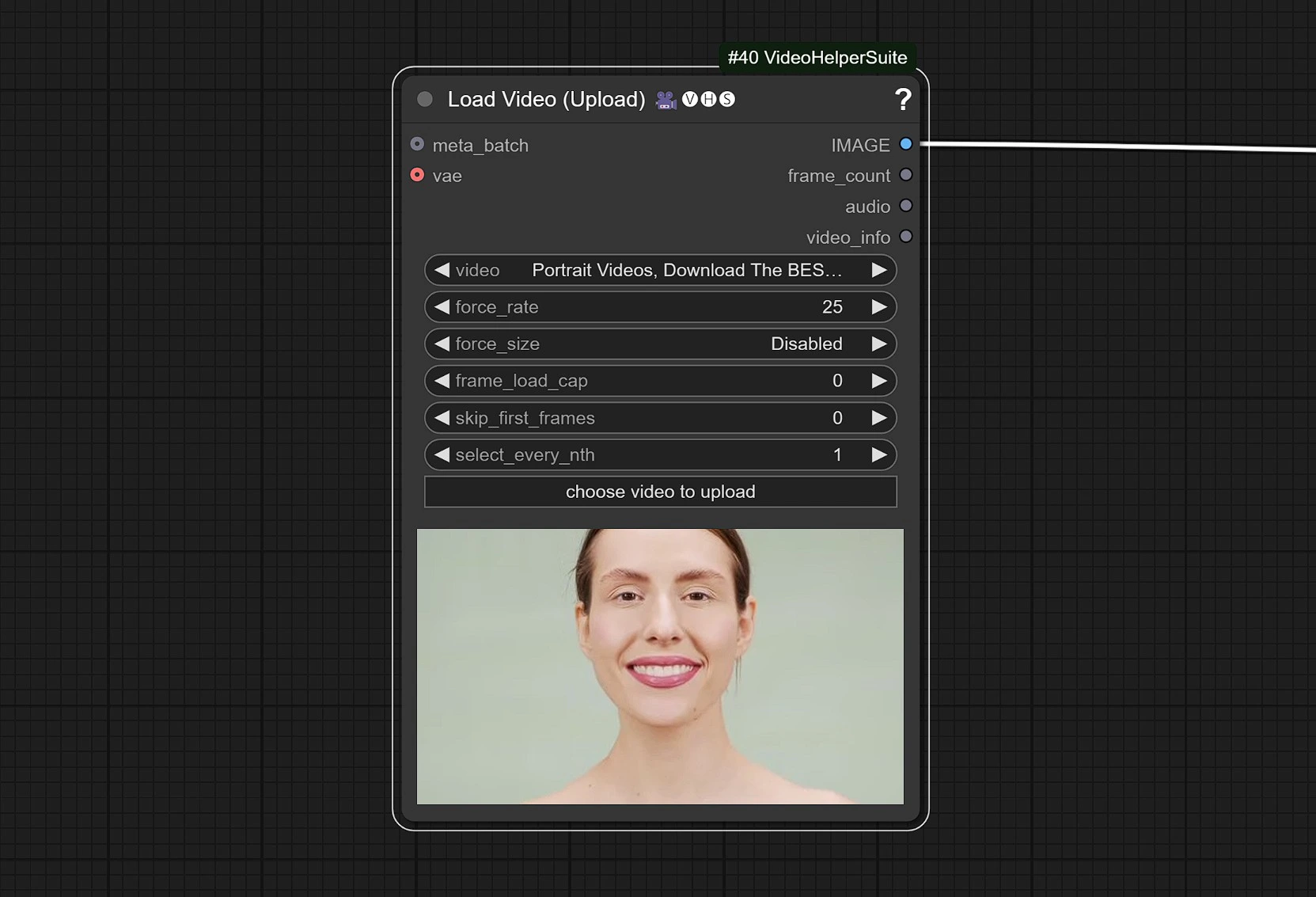
- Haga clic y suba su Video de Referencia que tenga rostro en él.
El video se ajusta a 25 FPS para sincronizar correctamente con el modelo de Audio
1.3 Entrada de Audio
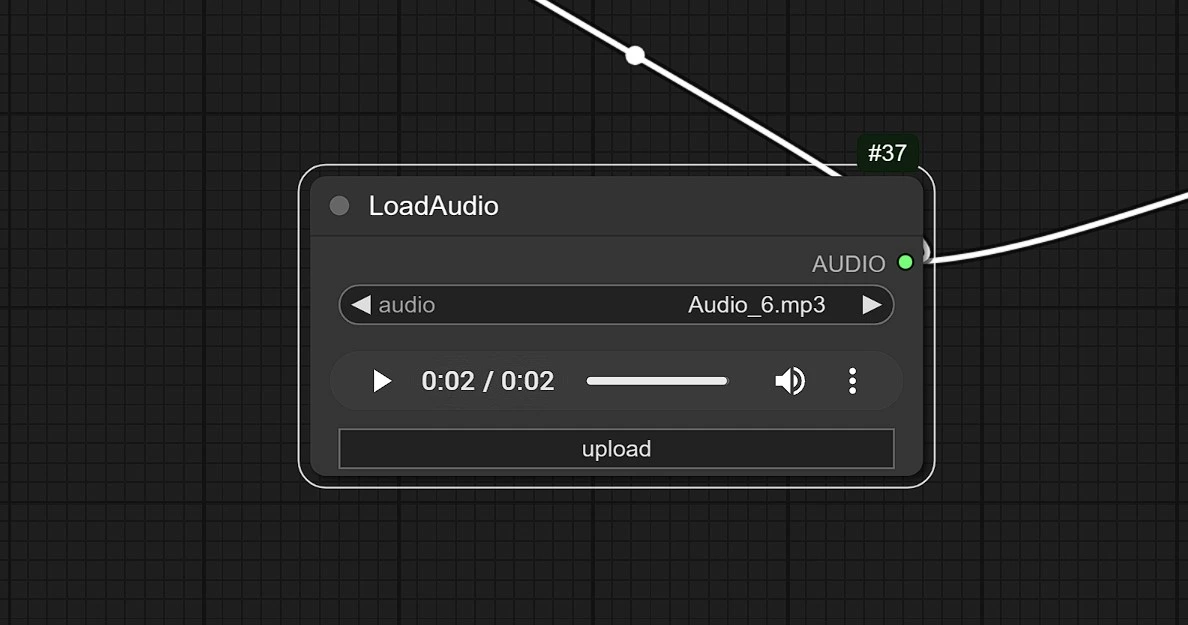
- Haga clic y suba su audio aquí.
LatentSync establece un nuevo punto de referencia para la sincronización labial con su enfoque innovador para la generación audio-visual. Al combinar precisión, consistencia temporal y el poder de Stable Diffusion, LatentSync transforma la forma en que creamos contenido sincronizado. Redefina lo que es posible en la sincronización labial con LatentSync.
