ComfyUI > Flujos de trabajo > Linear Mask Dilation | Animaciones Impresionantes
Linear Mask Dilation | Animaciones Impresionantes
ComfyUI Linear Mask Dilation es un flujo de trabajo poderoso para crear impresionantes animaciones de video. Transformando tu sujeto, como un bailarín, puedes hacer que viaje sin problemas a través de diferentes escenas usando un efecto de dilatación de máscara. Este flujo de trabajo está diseñado específicamente para videos de un solo sujeto. Sigue la guía paso a paso para aprender a usar Linear Mask Dilation de manera efectiva, desde subir tu video del sujeto hasta configurar los prompts y ajustar varios parámetros para obtener resultados óptimos. Desata tu creatividad y da vida a tus animaciones de video con ComfyUI Linear Mask Dilation.ComfyUI Linear Mask Dilation Flujo de trabajo
¿Quiere ejecutar este flujo de trabajo?
- Flujos de trabajo completamente operativos
- Sin nodos ni modelos faltantes
- No se requiere configuración manual
- Presenta visuales impresionantes
ComfyUI Linear Mask Dilation Ejemplos
ComfyUI Linear Mask Dilation Descripción
ComfyUI Linear Mask Dilation
Crea impresionantes animaciones de video transformando tu sujeto (bailarín) y haz que viaje a través de diferentes escenas mediante un efecto de dilatación de máscara. Este flujo de trabajo está diseñado para ser utilizado con videos de un solo sujeto.
Cómo usar el flujo de trabajo ComfyUI Linear Mask Dilation:
- Sube un video del sujeto en la sección de Entrada
- Selecciona el ancho y alto deseados del video final, junto con cuántos cuadros del video de entrada deben ser omitidos con “every_nth”. También puedes limitar el número total de cuadros a renderizar con “frame_load_cap”.
- Completa el prompt positivo y negativo. Establece los tiempos de cuadro por lote para que coincidan con el momento en que deseas que ocurran las transiciones de escena.
- Sube imágenes para cada uno de los colores de máscara del sujeto del IP Adapter:
- Blanco = sujeto (bailarín)
- Negro = Primer fondo
- Rojo = Fondo de máscara de dilatación roja
- Verde = Fondo de máscara de dilatación verde
- Azul = Fondo de máscara de dilatación azul
- Carga un buen checkpoint LCM (yo uso ParadigmLCM de Machine Delusions) en la sección de “Models”.
- Añade cualquier lora usando el Lora stacker debajo del cargador de modelos
- Pulsa Queue Prompt
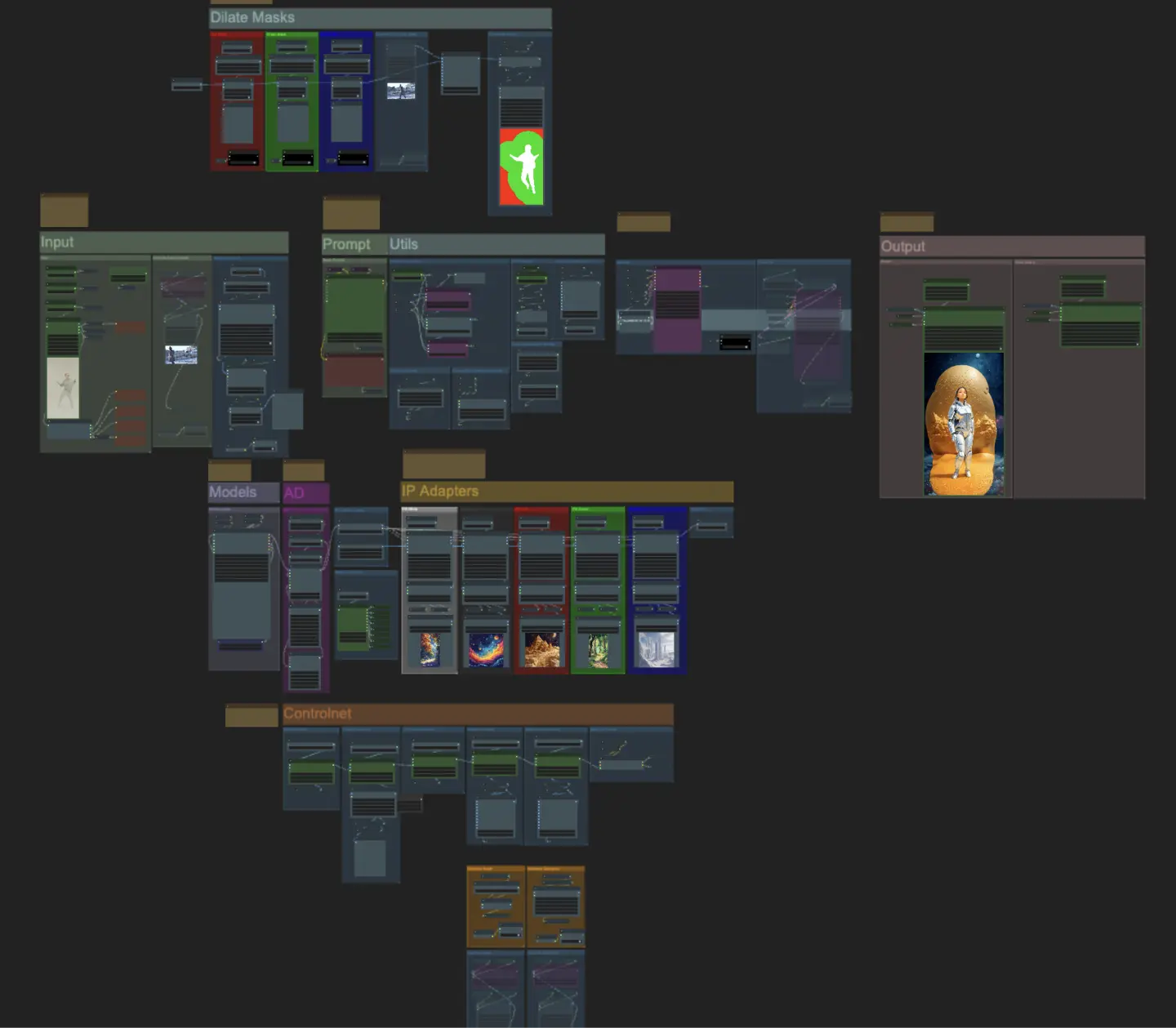
Entrada
- Puedes ajustar el ancho y alto usando las dos entradas superiores de la izquierda
- every_nth establece cuántos cuadros del video de entrada deben ser omitidos (2 = cada otro cuadro)
- Los campos numéricos en la parte inferior izquierda muestran información sobre el video de entrada subido: cuadros totales, ancho, alto y FPS de arriba a abajo.
- Si ya tienes un video de máscara del sujeto generado (debe ser sujeto blanco sobre fondo negro), puedes desactivar la sección “Override Subject Mask” y subir el video de máscara. Opcionalmente, puedes desactivar la sección “Segment Subject” para ahorrar tiempo de procesamiento.
- A veces el sujeto segmentado no será perfecto, puedes verificar la calidad de la máscara usando la caja de vista previa en la parte inferior derecha que se ve arriba. Si ese es el caso, puedes jugar con el prompt en el nodo “Florence2Run” para apuntar a diferentes partes del cuerpo como “cabeza”, “pecho”, “piernas”, etc. y ver si obtienes un mejor resultado.
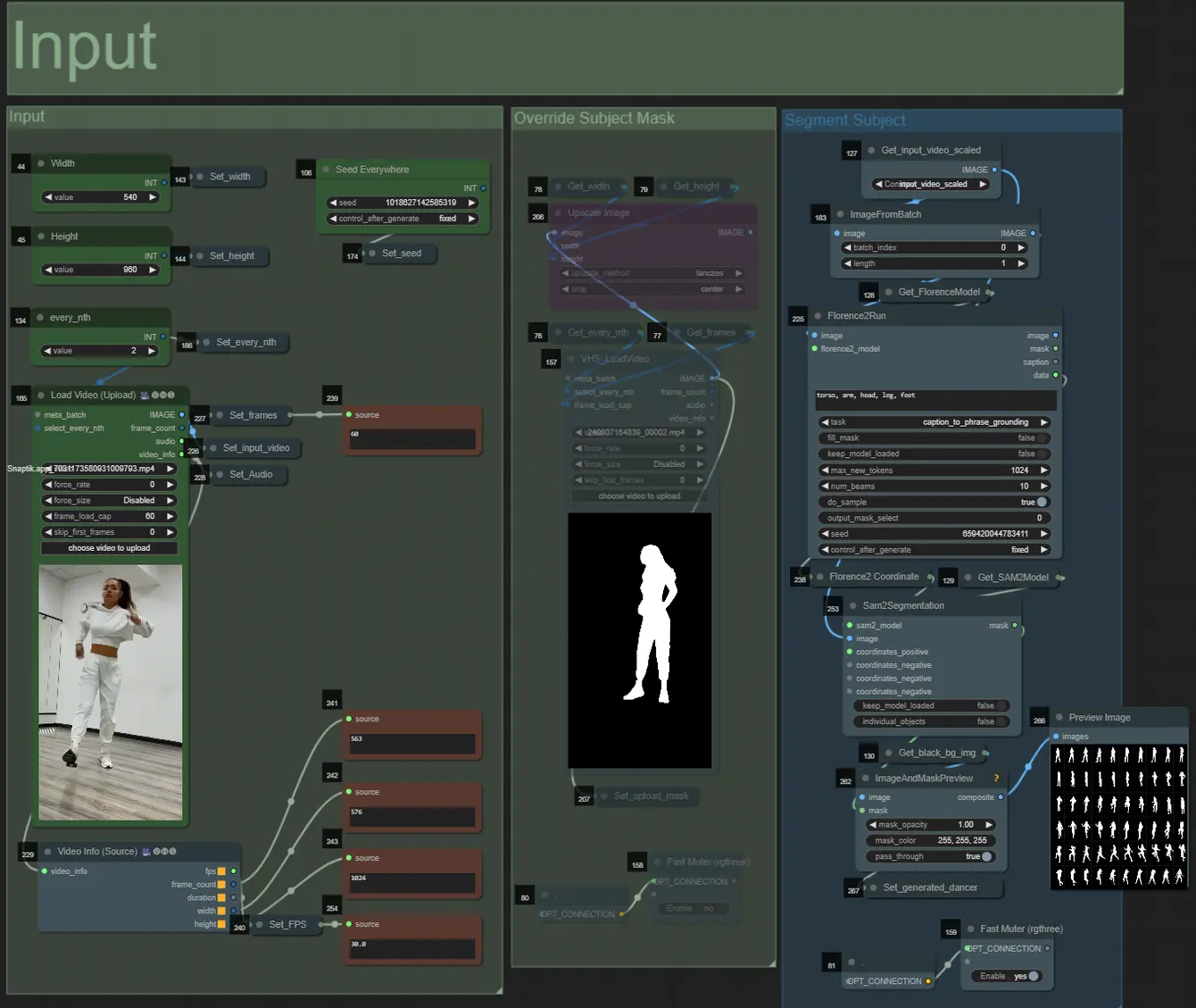
Prompt
- Establece el prompt positivo usando formato por lote:
- ej. “0”: “4k, masterpiece, 1girl standing on the beach, absurdres”, “25”: “HDR, sunset scene, 1girl with black hair and a white jacket, absurdres”, …
- El prompt negativo es de formato normal, puedes añadir embeddings si lo deseas.
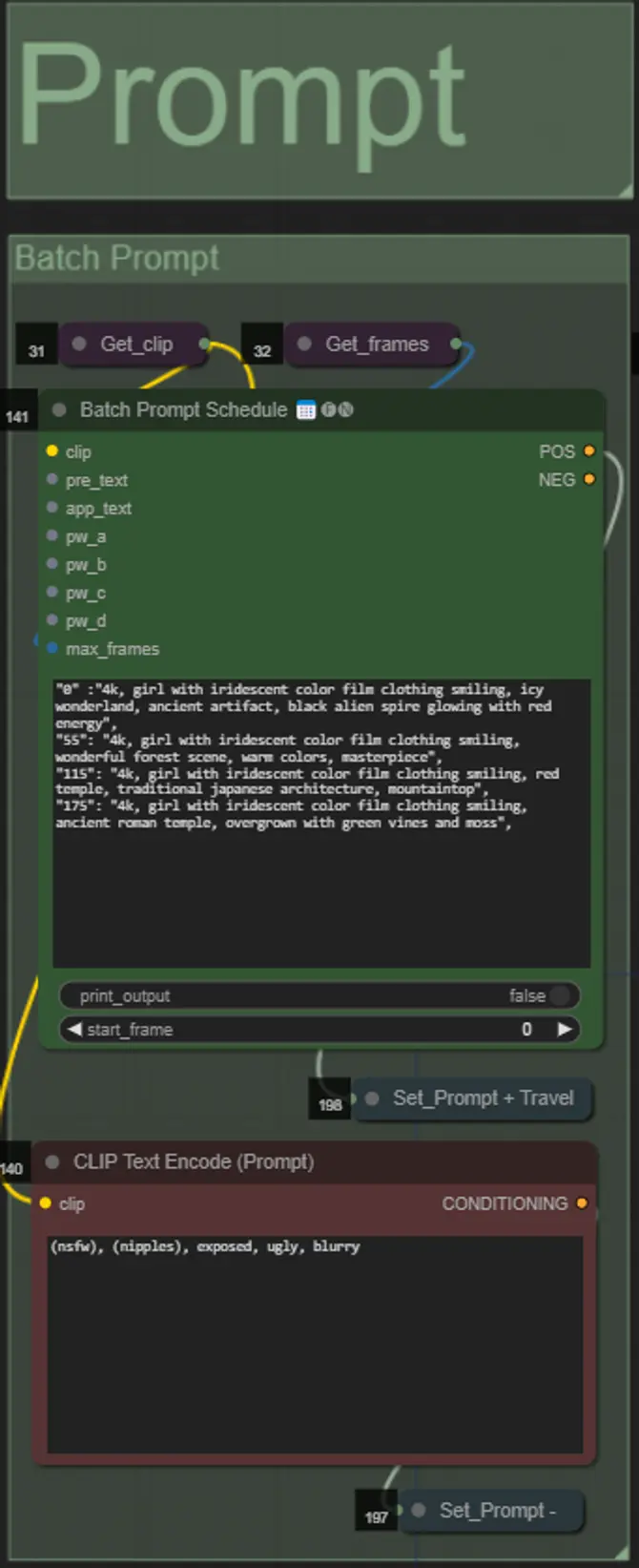
Dilataciones de Máscara
- Cada grupo de colores corresponde al color de la máscara de dilatación que será generada por él.
- Puedes establecer la forma de la máscara, junto con la velocidad de dilatación y el retraso de cuadro con el siguiente nodo:
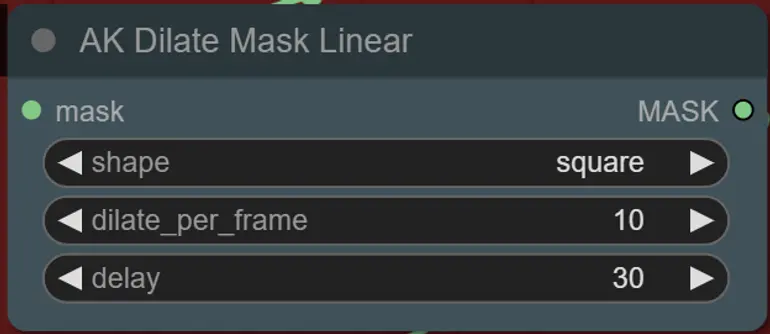
- forma: “circle” es la más precisa pero tarda más en generarse. Establece esto cuando estés listo para realizar el renderizado final. “square” es rápido de calcular pero menos preciso, mejor para probar el flujo de trabajo y decidir sobre las imágenes del IP adapter.
- dilate_per_frame: Qué tan rápido debe dilatarse la máscara, números más grandes = mayor velocidad de dilatación
- delay: Cuántos cuadros esperar antes de que la máscara comience a dilatarse.
- Si ya tienes un video de máscara compuesto generado, puedes desactivar el grupo “Override Composite Mask” y subirlo. Se recomienda omitir los grupos de máscara de dilatación si se anula para ahorrar tiempo de procesamiento.
Modelos
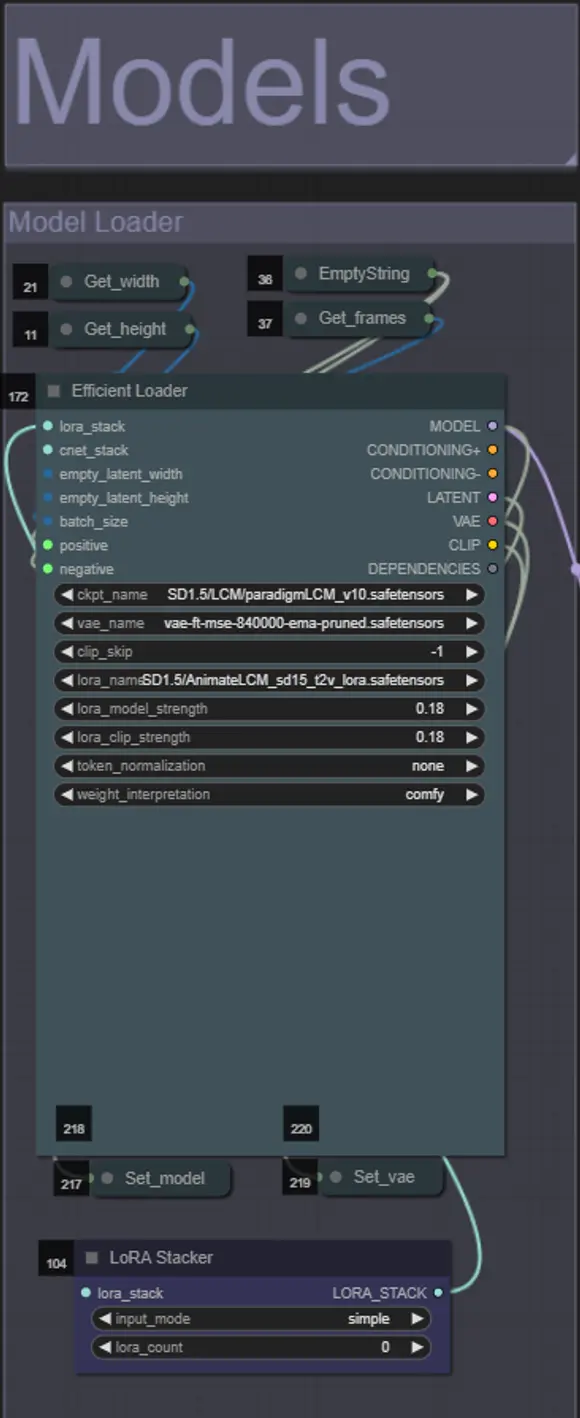
- Usa un buen modelo LCM para el checkpoint. Recomiendo ParadigmLCM de Machine Delusions.
- Opcionalmente, puedes especificar el AnimateLCM_sd15_t2v_lora.safetensors con un peso bajo de 0.18 para mejorar aún más el resultado final.
- Añade cualquier Lora adicional al modelo usando el Lora stacker azul debajo del cargador de modelos.
AnimateDiff
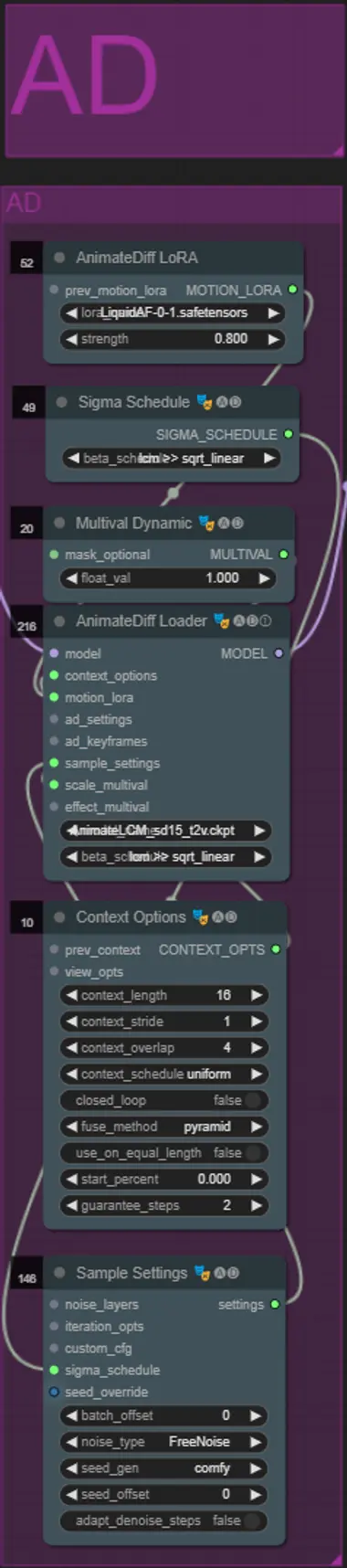
- Puedes establecer un Motion Lora diferente en lugar del que usé (LiquidAF-0-1.safetensors)
- Ajusta el valor dinámico de Multival Dynamic más alto o más bajo dependiendo de si quieres que el resultado tenga más o menos movimiento.
IP Adapters
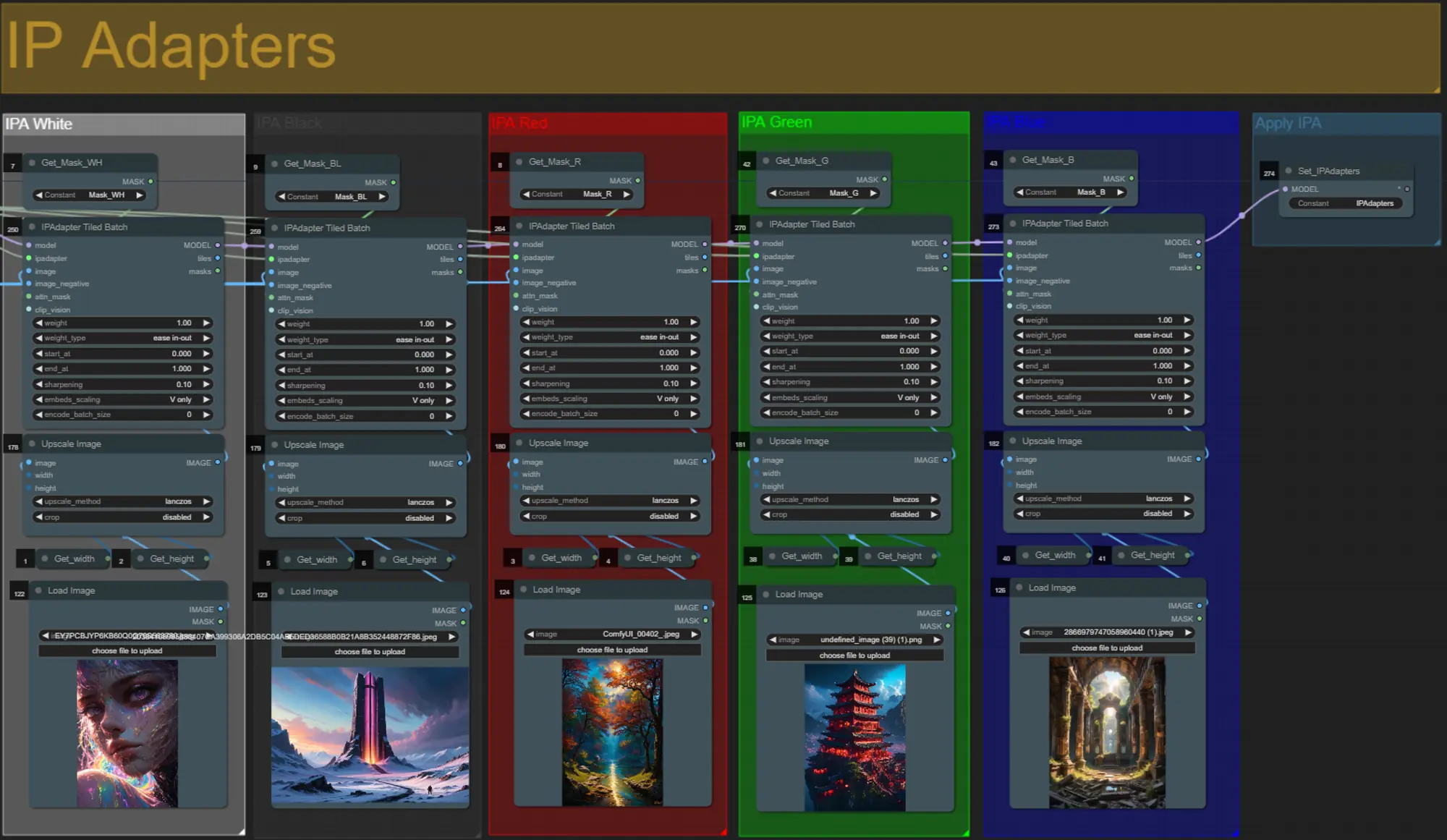
- Aquí puedes especificar los sujetos de referencia que se utilizarán para renderizar los fondos para cada una de las máscaras de dilatación, así como tu sujeto de video.
- El color de cada grupo representa la máscara a la que apunta:
- Blanco = sujeto (bailarín)
- Negro = Primer fondo
- Rojo = Fondo de máscara de dilatación roja
- Verde = Fondo de máscara de dilatación verde
- Azul = Fondo de máscara de dilatación azul
- Si deseas que el render final siga más de cerca las imágenes del IP adapter de entrada, puedes cambiar el preset del IPAdapter de VIT-G a PLUS en el grupo IPA Unified Loader.
ControlNet
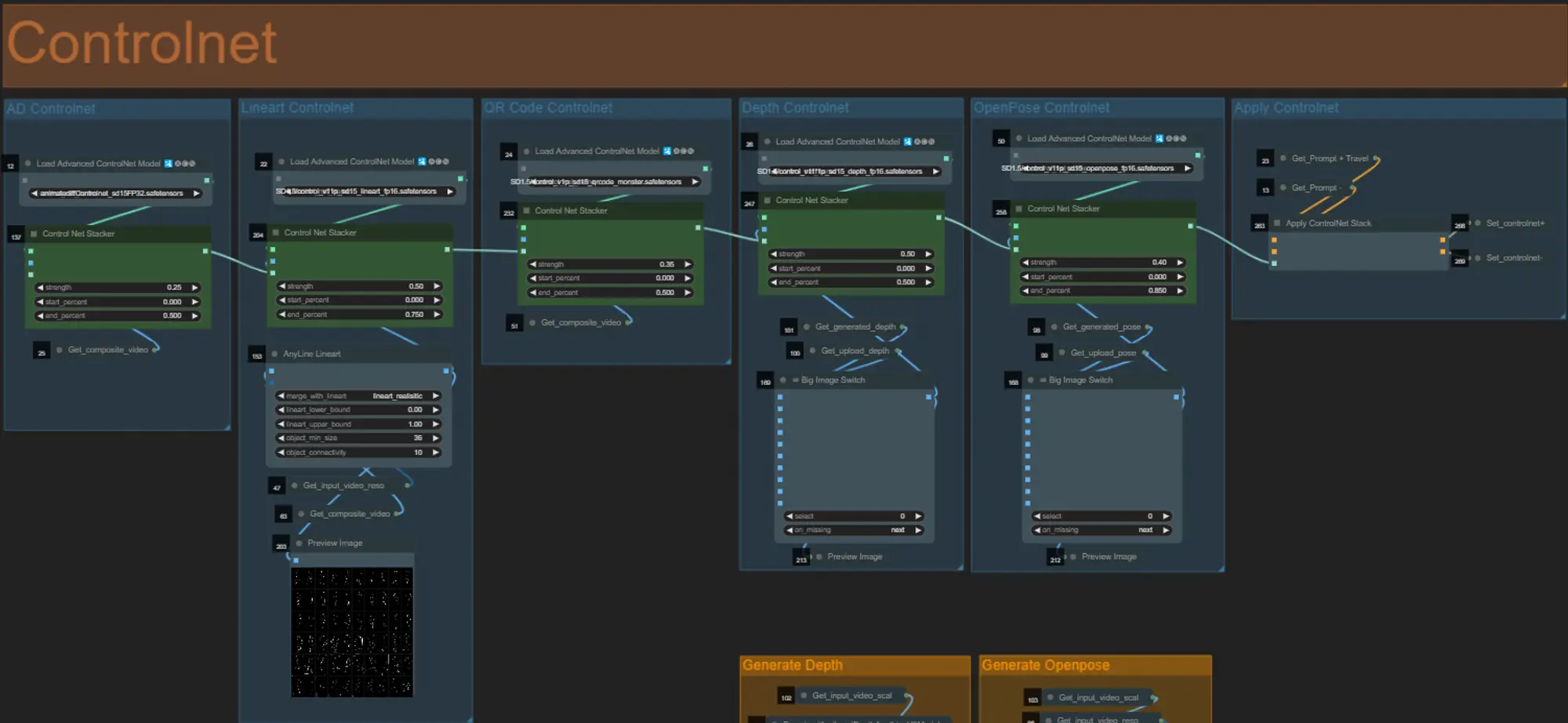
- Este flujo de trabajo utiliza 5 controlnets diferentes, incluyendo AD, Lineart, QR Code, Depth y OpenPose.
- Todas las entradas para los controlnets se generan automáticamente.
- Puedes elegir anular el video de entrada para los controlnets Depth y Openpose si lo deseas desactivando los grupos “Override Depth” y “Override Openpose” como se ve a continuación:
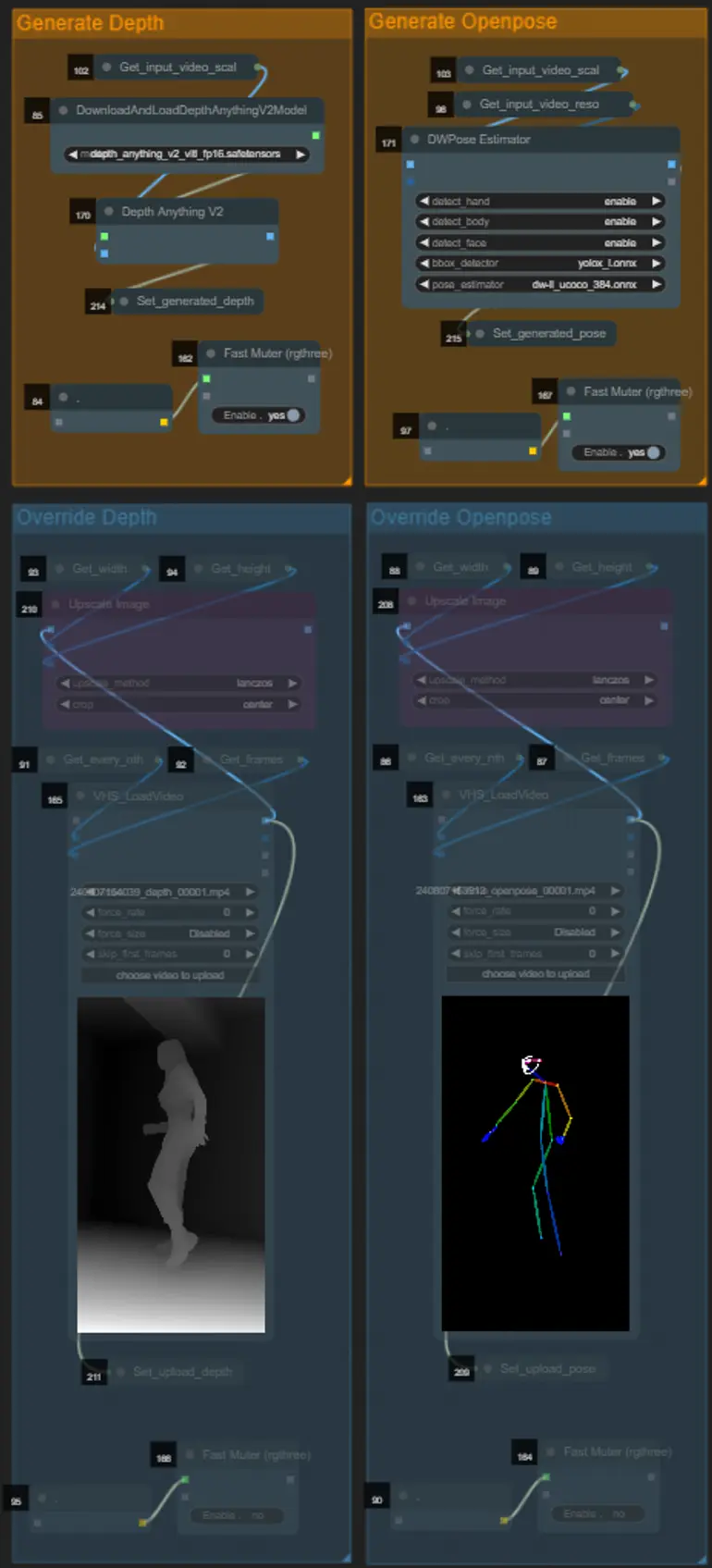
- Se recomienda desactivar los grupos “Generate Depth” y “Generate Openpose” si se anula para ahorrar tiempo de procesamiento.
Muestrador
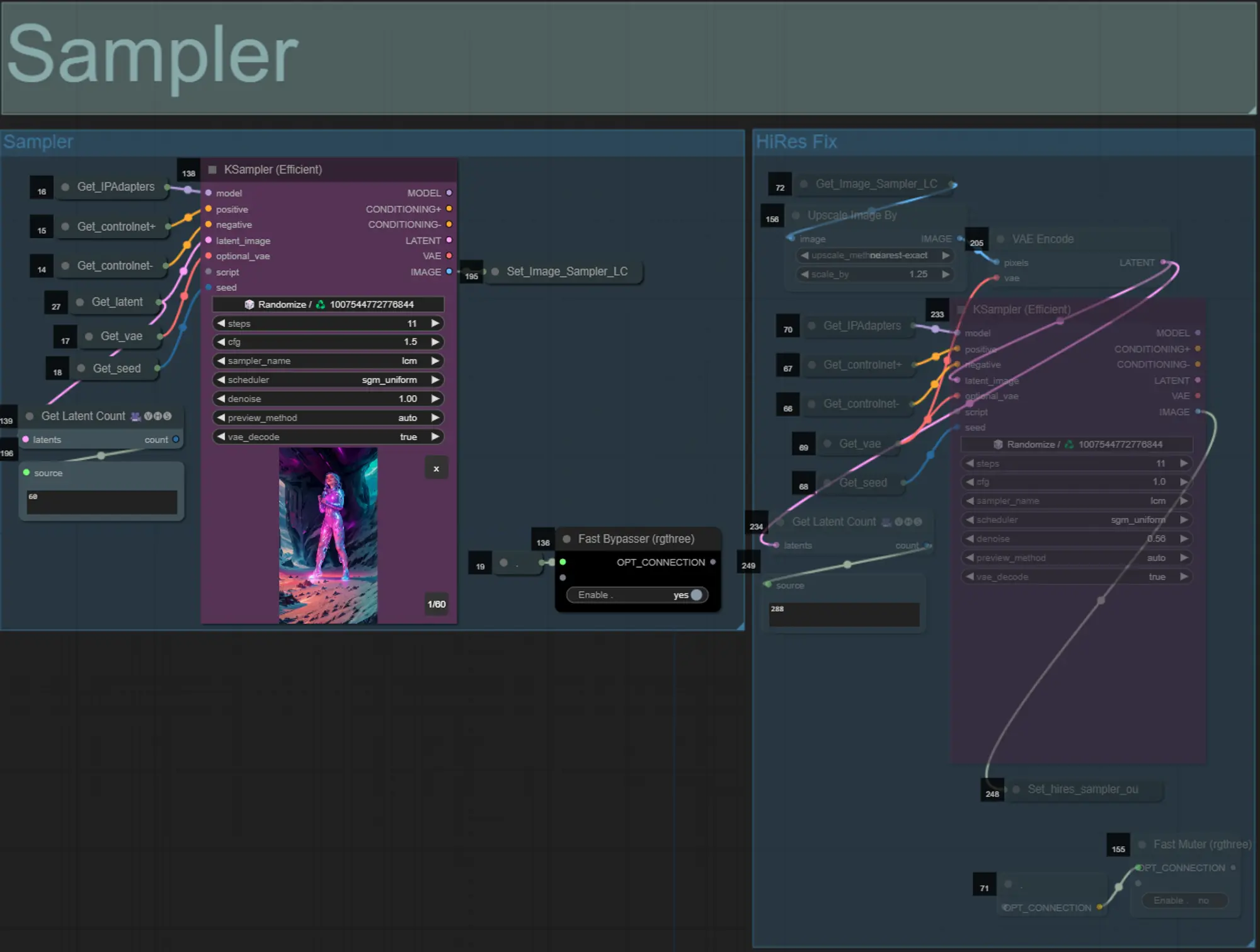
- Por defecto, el grupo de muestrador HiRes Fix estará desactivado para ahorrar tiempo de procesamiento al probar
- Recomiendo omitir el grupo de muestrador también al intentar experimentar con configuraciones de máscara de dilatación para ahorrar tiempo.
- En renderizados finales, puedes activar el grupo HiRes Fix que mejorará la escala y añadirá detalles al resultado final.
Salida

- Hay dos grupos de salida: el de la izquierda es para la salida del muestrador estándar y el de la derecha es para la salida del muestrador HiRes Fix.
- Puedes cambiar dónde se guardarán los archivos cambiando la cadena “custom_directory” en los nodos “FileNamePrefixDateDirFirst”. Por defecto, este nodo guardará los videos de salida en un directorio con marca de tiempo en el directorio “output” de ComfyUI
- ej. …/ComfyUI/output/240812/
<custom_directory>/<my_video>.mp4
- ej. …/ComfyUI/output/240812/
Sobre el Autor
Akatz AI:
- Website:
- https://www.youtube.com/@akatz_ai
- https://www.instagram.com/akatz.ai/
- https://www.tiktok.com/@akatz_ai
- https://x.com/akatz_ai
- https://github.com/akatz-ai
Contactos:
- Email: akatzfey@sendysoftware.com


