




Stability AI ha revelado Stable Diffusion 3.5 (SD3.5), un modelo de IA generativa multimodal de código abierto que incluye varias variantes como Stable Diffusion 3.5 (SD3.5) Large, Stable Diffusion 3.5 (SD3.5) Large Turbo y Stable Diffusion 3.5 (SD3.5) Medium. Estos modelos son altamente personalizables, capaces de ejecutarse en hardware de consumo. Los modelos SD3.5 Large y Large Turbo están disponibles de inmediato, mientras que la versión Medium se lanzará el 29 de octubre de 2024.
1. Cómo funciona Stable Diffusion 3.5 (SD3.5)#
A nivel técnico, Stable Diffusion 3.5 (SD3.5) toma una indicación de texto como entrada, la codifica en un espacio latente usando codificadores de texto basados en transformadores, y luego decodifica esa representación latente en una imagen de salida utilizando un decodificador basado en difusión. Los codificadores de texto transformadores, como el modelo CLIP (Contrastive Language-Image Pre-training), mapean la indicación de entrada en una representación comprimida semánticamente significativa en el espacio latente. Este código latente es luego iterativamente desruido por el decodificador de difusión durante múltiples pasos de tiempo para generar la imagen de salida final. El proceso de difusión implica eliminar gradualmente el ruido de una representación latente inicialmente ruidosa, condicionado en la incrustación de texto, hasta que emerge una imagen limpia.
Los diferentes tamaños de modelo en Stable Diffusion 3.5 (SD3.5) (Large, Medium) se refieren al número de parámetros entrenables: 8 mil millones para el modelo Large y 2.5 mil millones para el Medium. Más parámetros generalmente permiten que el modelo capture más conocimiento y matices de sus datos de entrenamiento. Los modelos Turbo son versiones destiladas que sacrifican algo de calidad por velocidades de inferencia mucho más rápidas. La destilación implica entrenar un modelo "estudiante" más pequeño para imitar las salidas de un modelo "maestro" más grande, con el objetivo de retener la mayoría de la capacidad en una arquitectura más eficiente.
2. Fortalezas de los modelos Stable Diffusion 3.5 (SD3.5)#
2.1. Personalización#
Los modelos Stable Diffusion 3.5 (SD3.5) están diseñados para ser fácilmente ajustables y ampliables para aplicaciones específicas. La Normalización de Consulta-Clave se integró en los bloques de transformador para estabilizar el entrenamiento y simplificar el desarrollo posterior. Esta técnica normaliza las puntuaciones de atención en las capas de transformador, lo que puede hacer que el modelo sea más robusto y fácil de adaptar a nuevos conjuntos de datos a través del aprendizaje por transferencia.
2.2. Diversidad de Salidas#
Stable Diffusion 3.5 (SD3.5) busca generar imágenes representativas de la diversidad del mundo sin necesidad de indicaciones extensas. Puede representar personas con diferentes tonos de piel, características y estéticas. Esto es probablemente debido al modelo que fue entrenado en un conjunto de datos grande y diverso de imágenes de todo internet.
2.3. Amplia Gama de Estilos#
Los modelos Stable Diffusion 3.5 (SD3.5) son capaces de generar imágenes en una amplia variedad de estilos, incluyendo renderizados en 3D, fotorrealismo, pinturas, arte lineal, anime y más. Esta versatilidad los hace adecuados para muchos casos de uso. La diversidad de estilos surge de la capacidad del modelo de difusión para capturar muchos patrones visuales diferentes y estéticas en su espacio latente.
2.4. Fuerte Adhesión a las Indicaciones#
Especialmente para el modelo Stable Diffusion 3.5 (SD3.5) Large, SD3.5 se destaca en generar imágenes que se alinean con el significado semántico de las indicaciones de texto de entrada. Se clasifica altamente en comparación con otros modelos en métricas de coincidencia de indicaciones. Esta capacidad para traducir con precisión texto en imágenes está impulsada por las capacidades de comprensión del lenguaje del codificador de texto transformador.
3. Limitaciones y Desventajas de los modelos Stable Diffusion 3.5 (SD3.5)#
3.1. Dificultades con la Anatomía y las Interacciones de Objetos#
Como la mayoría de los modelos de texto a imagen, Stable Diffusion 3.5 (SD3.5) todavía tiene dificultades para representar la anatomía humana realista, especialmente manos, pies y rostros en poses complejas. Las interacciones entre objetos y manos a menudo están distorsionadas. Esto es probablemente debido al desafío de aprender todos los matices de las relaciones espaciales 3D y la física a partir de imágenes 2D solamente.
3.2. Resolución Limitada#
El modelo Stable Diffusion 3.5 (SD3.5) Large es ideal para imágenes de 1 megapíxel (1024x1024), mientras que el Medium alcanza un máximo de alrededor de 2 megapíxeles. Generar imágenes coherentes a resoluciones más altas es un desafío para SD3.5. Esta limitación proviene de las restricciones computacionales y de memoria de la arquitectura de difusión.
3.3. Fallos Ocasionales y Alucinaciones#
Debido a que los modelos Stable Diffusion 3.5 (SD3.5) permiten una amplia diversidad de salidas a partir de la misma indicación con diferentes semillas aleatorias, puede haber cierta imprevisibilidad. Indicaciones que carecen de especificidad pueden conducir a elementos fallidos o inesperados. Esta es una propiedad inherente del proceso de muestreo de difusión, que implica aleatoriedad.
3.4. No Alcanza el Máximo de Vanguardia#
Según algunas pruebas iniciales, en términos de calidad de imagen y coherencia, Stable Diffusion 3.5 (SD3.5) no iguala actualmente el rendimiento de los modelos de texto a imagen de última generación como Midjourney. Y las comparaciones iniciales entre Stable Diffusion 3.5 (SD3.5) y FLUX.1 revelan que cada modelo se destaca en diferentes áreas. Mientras que FLUX.1 parece tener una ventaja en la producción de imágenes fotorrealistas, SD3.5 Large tiene mayor competencia en generar obras de arte estilo anime sin requerir ajustes o modificaciones adicionales.
4. Stable Diffusion 3.5 en ComfyUI#
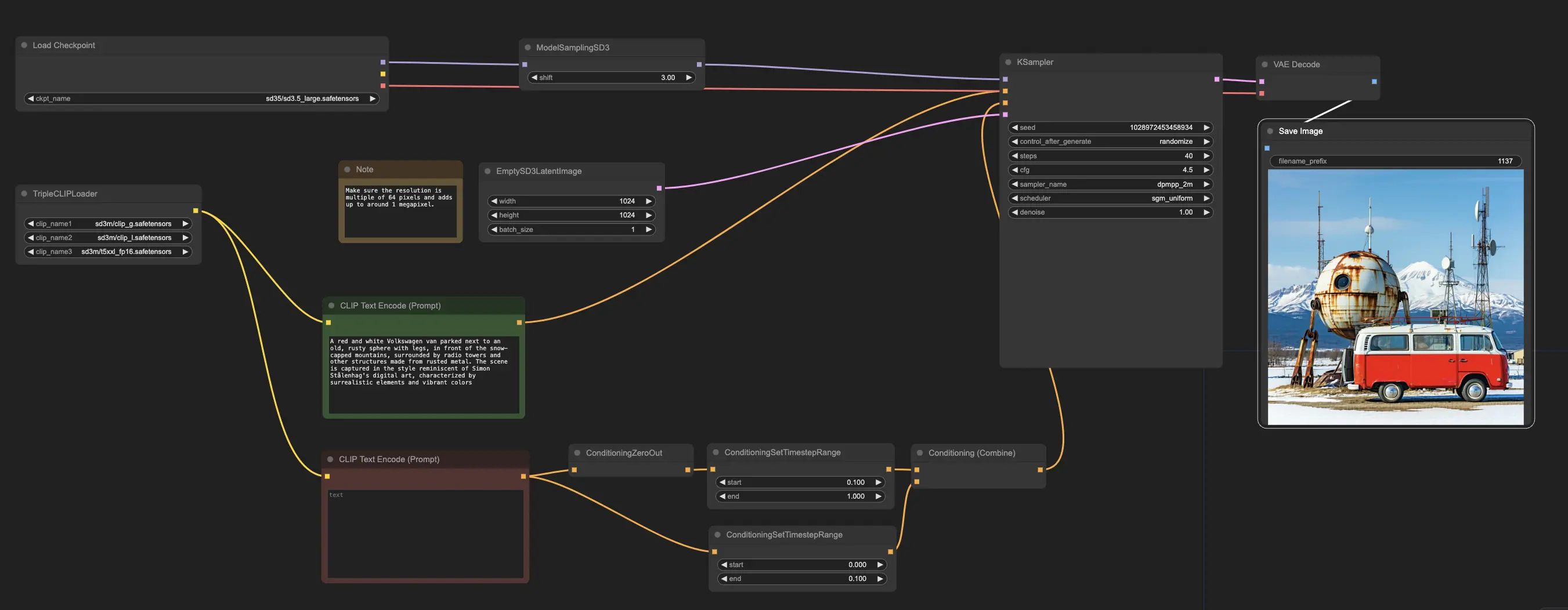
En RunComfy, hemos facilitado que comiences a usar los modelos Stable Diffusion 3.5 (SD3.5) precargándolos para tu conveniencia. Puedes empezar directamente y ejecutar inferencias usando el flujo de trabajo de ejemplo
El flujo de trabajo de ejemplo comienza con el nodo CheckpointLoaderSimple, que carga el modelo pre-entrenado Stable Diffusion 3.5 Large. Y para ayudar a traducir tus indicaciones de texto en un formato que el modelo pueda entender, se utiliza el nodo TripleCLIPLoader para cargar los codificadores correspondientes. Estos codificadores son cruciales en guiar el proceso de generación de imágenes basado en el texto que proporciones.
El nodo EmptySD3LatentImage luego crea un lienzo en blanco con las dimensiones especificadas, típicamente 1024x1024 píxeles, que sirve como punto de partida para que el modelo genere la imagen. Los nodos CLIPTextEncode procesan las indicaciones de texto que proporcionas, utilizando los codificadores cargados para crear un conjunto de instrucciones para que el modelo siga.
Antes de que estas instrucciones se envíen al modelo, se refinan aún más a través de los nodos ConditioningCombine, ConditioningZeroOut y ConditioningSetTimestepRange. Estos nodos eliminan la influencia de cualquier indicación negativa, especifican cuándo las indicaciones deben aplicarse durante el proceso de generación y combinan las instrucciones en un conjunto único y cohesivo.
Finalmente, puedes ajustar el proceso de generación de imágenes utilizando el nodo ModelSamplingSD3, que te permite ajustar varios parámetros como el modo de muestreo, el número de pasos y la escala de salida del modelo. Finalmente, el nodo KSampler te da control sobre el número de pasos, la fuerza de la influencia de las instrucciones (escala CFG) y el algoritmo específico utilizado para la generación, permitiéndote lograr los resultados deseados.