Audioreactive Dancers Evolved
Le flux de travail Audioreactive Dancers Evolved transforme les sujets vidéo en animations captivantes synchronisées avec les rythmes musicaux, sur fond de décors dynamiques, géométriques et psychédéliques. Conçu pour la flexibilité, il permet aux utilisateurs de contrôler les images vidéo, le masquage, la réactivité audio et les détails des motifs. Avec des fonctionnalités telles que les masques de dilatation, ControlNet et l'animation de bruit synchronisée avec le rythme, ce flux de travail ComfyUI permet aux créatifs de mêler art, son et mouvement, créant des expériences visuellement immersives et rythmiques avec des visuels audioreactifs.Flux de travail ComfyUI Audioreactive Dancers Evolved

- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
Exemples ComfyUI Audioreactive Dancers Evolved
Description ComfyUI Audioreactive Dancers Evolved
Créez des animations vidéo époustouflantes en transformant votre sujet (danseur) et donnez-leur un arrière-plan audioreactif dynamique composé de diverses géométries complexes et de motifs psychédéliques. Vous pouvez utiliser ce flux de travail avec un ou plusieurs sujets. Avec ce flux de travail, vous pouvez produire des effets visuels audioreactifs fascinants qui se synchronisent parfaitement avec le rythme de la musique, offrant une expérience immersive. Le flux de travail vous permet de l'utiliser avec un seul sujet ou plusieurs sujets, tous enrichis d'éléments audioreactifs.
Comment utiliser le flux de travail Audioreactive Dancers Evolved :
- Téléchargez une vidéo de sujet dans la section Input
- Sélectionnez la largeur et la hauteur souhaitées de la vidéo finale, ainsi que le nombre d'images de la vidéo d'entrée à sauter avec "every_nth". Vous pouvez également limiter le nombre total d'images à rendre avec "frame_load_cap".
- Remplissez les invites positives et négatives. Définissez les temps de trame par lots pour correspondre aux transitions de scène souhaitées.
- Téléchargez des images pour chacune des couleurs de masque de sujet IP Adapter par défaut :
- Rouge, Vert, Bleu = sujet(s)
- Noir = Arrière-plan
- Blanc = Masque de dilatation audioreactif blanc
- Jaune, Magenta = Motifs de bruit de fond masqué
- Chargez un bon checkpoint LCM (j'utilise ParadigmLCM de Machine Delusions) dans la section "Models".
- Ajoutez des loras en utilisant le Lora stacker sous le chargeur de modèle
- Appuyez sur Queue Prompt
Guide vidéo
Couleur des nœuds et des groupes
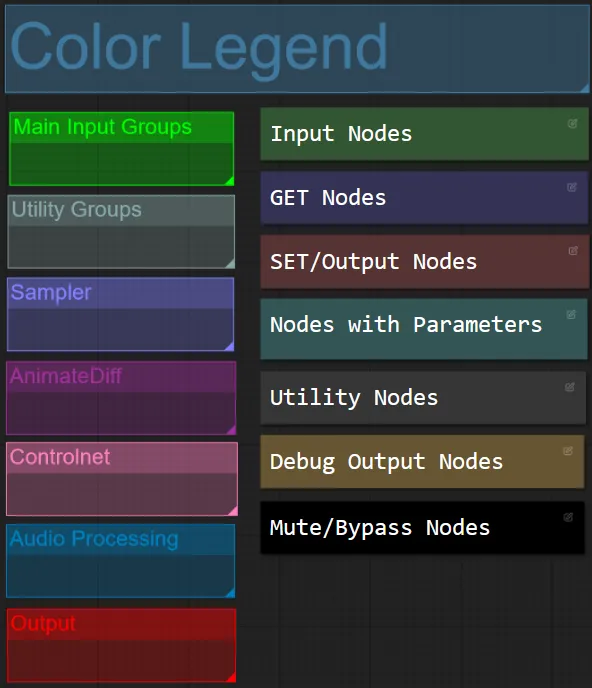
- Pour ce flux de travail, j'ai coordonné les nœuds par couleur en fonction de leur fonctionnalité dans chaque groupe.
- Les titres des sections de groupe sont coordonnés par couleur pour une différenciation plus facile.
Input
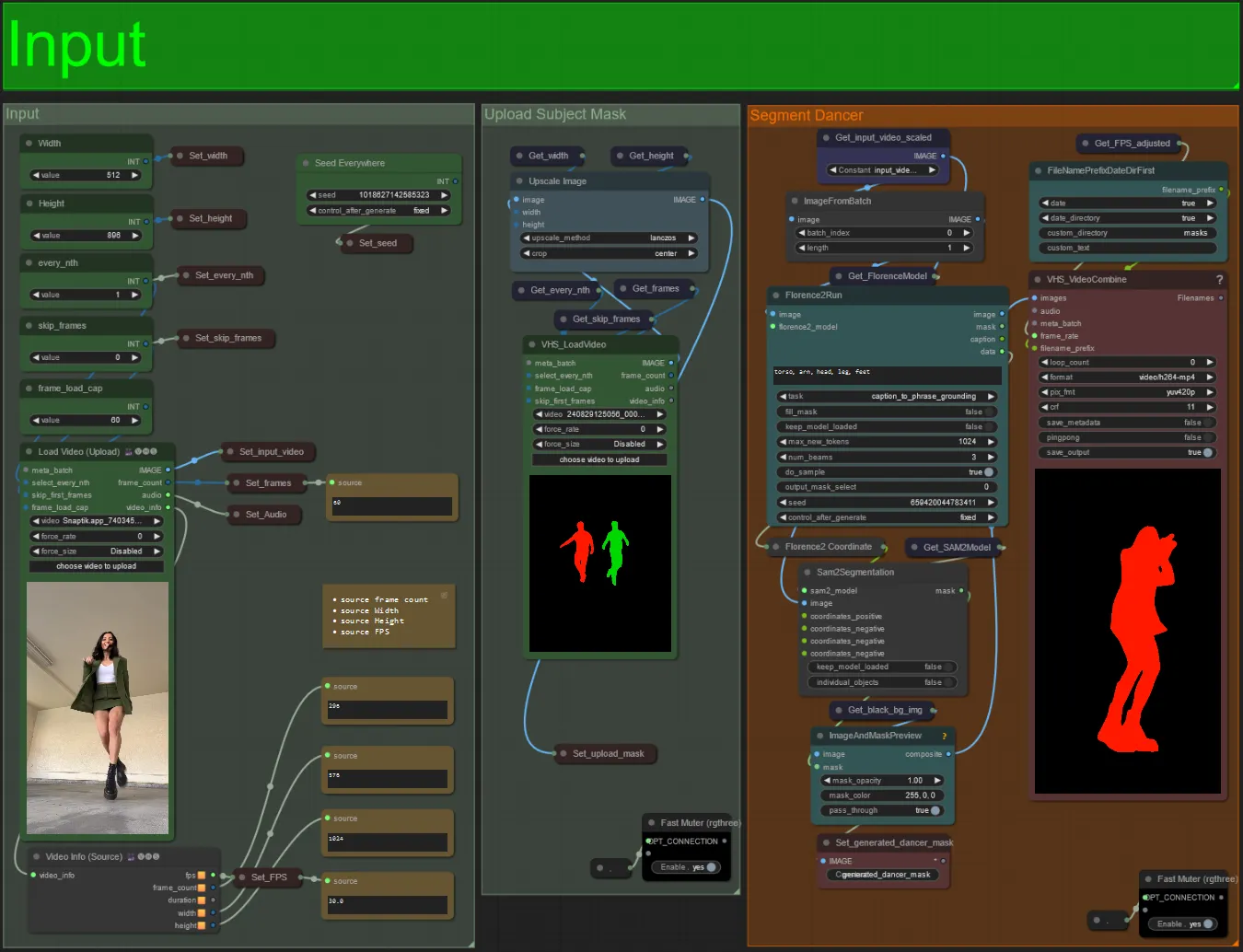
- Téléchargez votre vidéo de sujet souhaitée dans le nœud Load Video (Upload).
- Vous pouvez ajuster la largeur et la hauteur de sortie à l'aide des deux entrées en haut à gauche.
- every_nth définit s'il faut utiliser chaque autre image, chaque troisième image, etc. (2 = chaque autre image). Laissé à 1 par défaut.
- skip_frames est utilisé pour sauter des images au début de la vidéo. (100 = sauter les 100 premières images de la vidéo d'entrée). Laissé à 0 par défaut.
- frame_load_cap est utilisé pour spécifier combien d'images totales de la vidéo d'entrée doivent être chargées. Il est préférable de garder bas lors du test des paramètres (30 - 60 par exemple) puis d'augmenter ou de régler à 0 (pas de limite d'images) lors du rendu de la vidéo finale.
- Les champs numériques en bas à droite affichent des informations sur la vidéo d'entrée téléchargée : nombre total d'images, largeur, hauteur et FPS de haut en bas.
- Si vous avez déjà une vidéo de masque du sujet générée, vous pouvez désactiver la section "Upload Subject Mask" et télécharger la vidéo de masque. Vous pouvez éventuellement désactiver la section "Segment Dancer" pour gagner du temps de traitement.
- Parfois, le sujet segmenté ne sera pas parfait, vous pouvez vérifier la qualité du masque à l'aide de la boîte de prévisualisation en bas à droite vue ci-dessus. Si c'est le cas, vous pouvez jouer avec l'invite dans le nœud "Florence2Run" pour cibler différentes parties du corps telles que "tête", "poitrine", "jambes", etc. et voir si vous obtenez un meilleur résultat.
Prompt
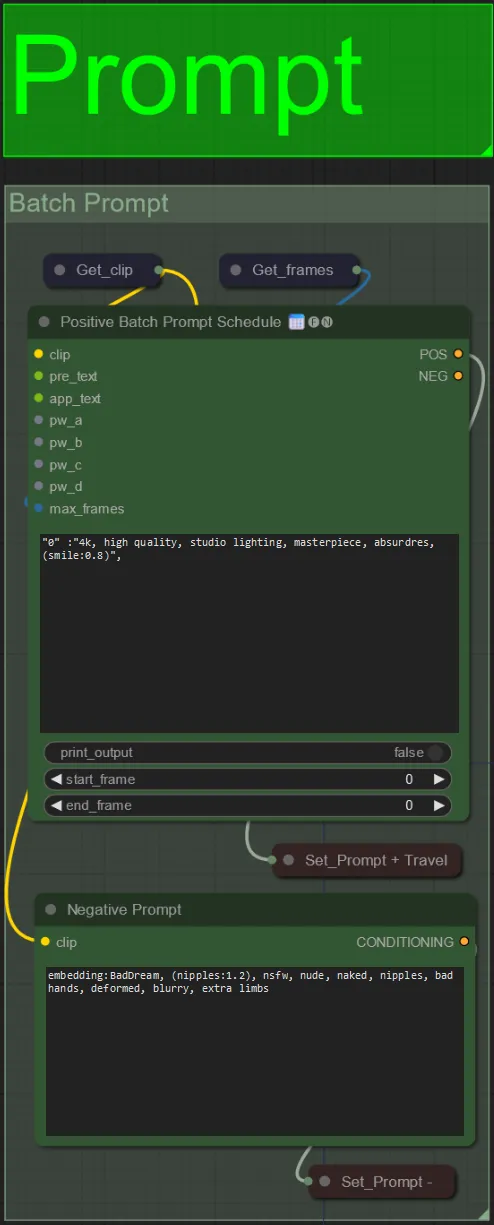
- Définissez l'invite positive en utilisant la mise en forme par lots :
- par ex. "0": "4k, chef-d'œuvre, 1fille debout sur la plage, absurdres", "25": "HDR, scène de coucher de soleil, 1fille avec cheveux noirs et une veste blanche, absurdres", …
- L'invite négative est au format normal, vous pouvez ajouter des embeddings si souhaité.
Traitement audio
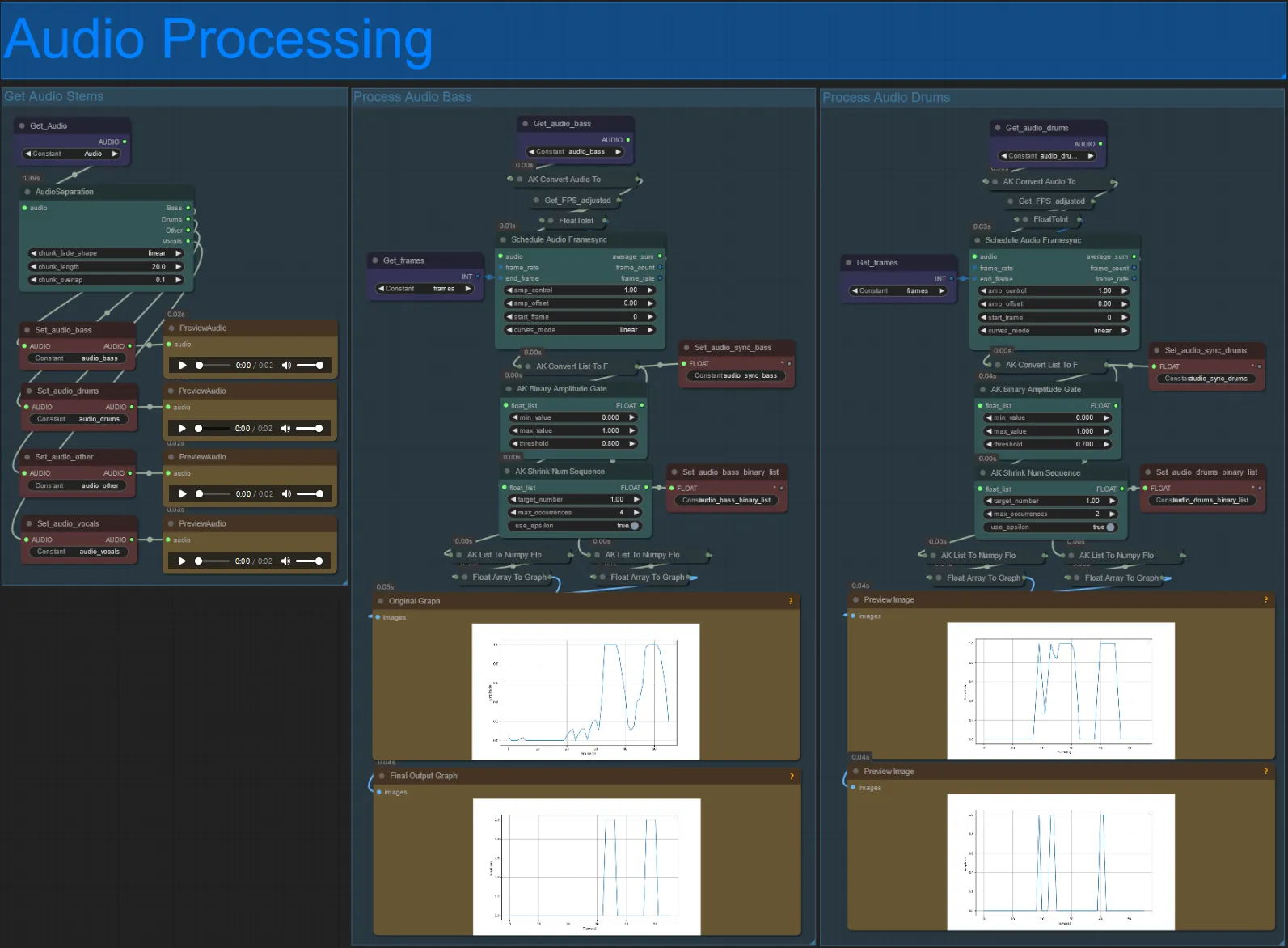
- Cette section prend l'audio de la vidéo d'entrée, extrait les stems (basse, batterie, voix, etc.) et le convertit en une amplitude normalisée synchronisée avec les images vidéo d'entrée, pour créer des visuels audioreactifs.
- amp_control = plage totale que l'amplitude peut parcourir.
- amp_offset = valeur minimale que l'amplitude peut prendre.
- Exemple : amp_control = 0.8 et amp_offset = 0.2 signifie que le signal variera entre 0.2 et 1.0.
- Parfois, le stem de batterie aura les notes de basse réelles de la chanson, prévisualisez chacun pour voir lequel utiliser pour vos masques audioreactifs.
- Utilisez les graphiques pour bien comprendre comment le signal pour ce stem change au fil de la vidéo
Générateurs Voronoi
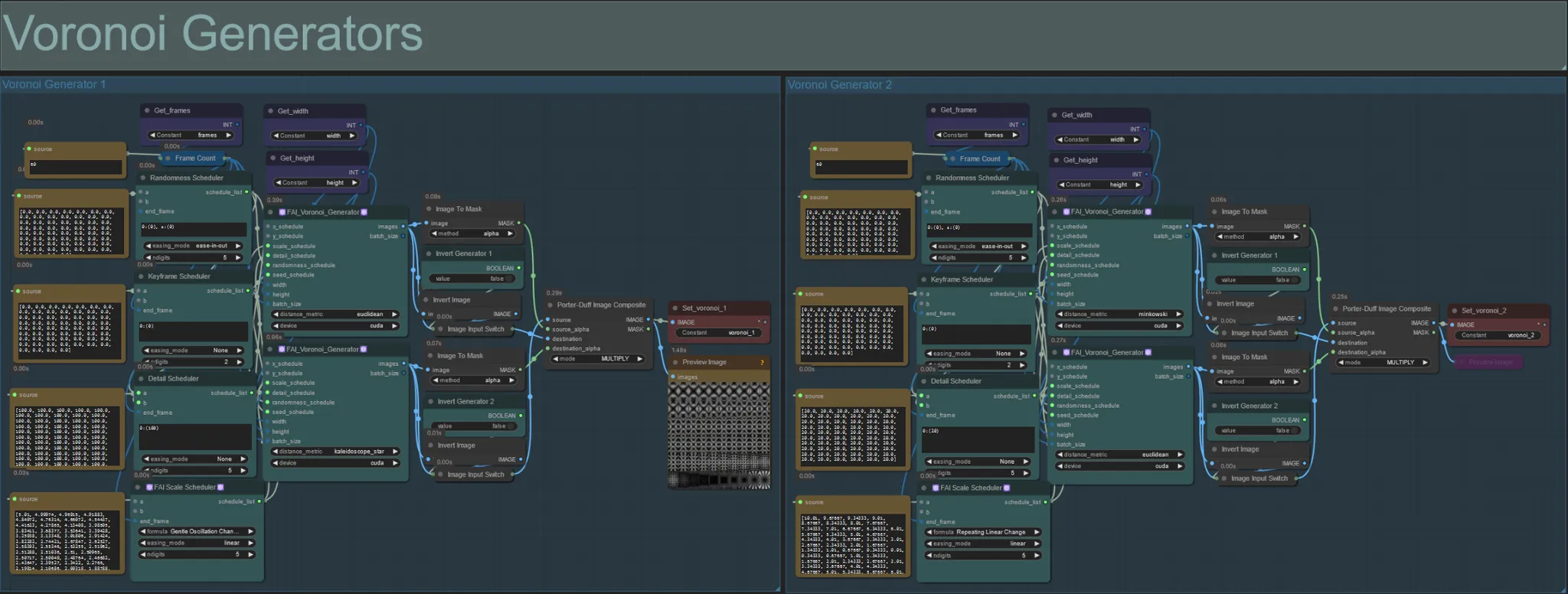
- Cette section génère des motifs de bruit Voronoi à l'aide de deux nœuds personnalisés FAI_Voronoi_Generator par groupe qui sont composés ensemble à l'aide d'un Multiply.
- Vous pouvez augmenter les valeurs du Randomness Scheduler entre parenthèses de 0 pour rompre les motifs symétriques dans le rendu final.
- Augmentez la valeur du Detail Scheduler entre parenthèses pour augmenter le nombre de détails dans les motifs de bruit de sortie. Des valeurs plus basses entraînent une différenciation de bruit plus faible.
- Modifiez les paramètres "formula" dans le nœud FAI Scale Scheduler pour avoir un impact important sur le mouvement final du motif de bruit.
- Vous pouvez également modifier la fonction "distance_metric" sur les nœuds FAI_Voronoi_Generator eux-mêmes pour affecter considérablement les motifs et formes générés du bruit résultant.
Masques audio
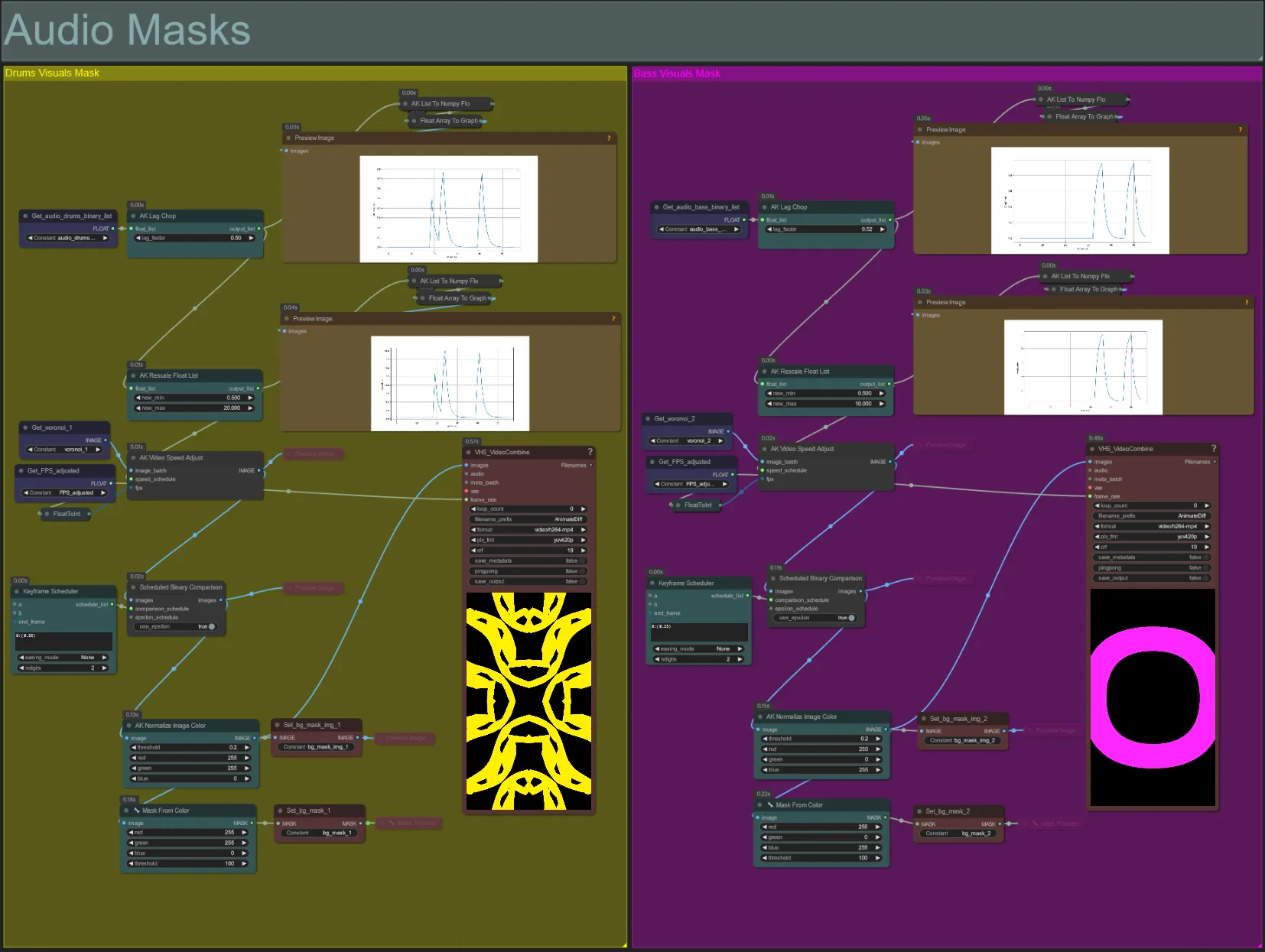
- Cette section est utilisée pour convertir les lots d'images de bruit voronoi en masques colorés à composer avec le sujet, ainsi que synchroniser leurs mouvements avec le rythme des stems audio de basse ou de batterie. Ces masques sont essentiels pour créer des effets audioreactifs.
- Augmentez le "lag_factor" dans le nœud AK Lag Chop pour augmenter à quel point les graphiques d'amplitude finale seront "pointus". Cela accélérera et ralentira plus soudainement le mouvement du bruit de sortie, alors qu'un lag_factor plus faible entraînera une décélération plus progressive du mouvement après chaque battement. Cela sert à éviter que l'animation du masque de bruit ne paraisse trop "saccadée" et rigide.
- L'AK Rescale Float List est utilisé pour réaffecter les valeurs d'amplitude normalisées de 0-1 à new_min et new_max. Une valeur de 1.0 représente une vitesse de lecture de l'animation de bruit de 30FPS, tandis que 0.5 représente 15FPS, 2.0 représente 60FPS, etc. Ajustez cette valeur pour modifier la vitesse à laquelle le motif de bruit audioreactif s'anime en dehors du rythme (amplitude 0.0), et à quelle vitesse il se déplace sur le rythme (amplitude 1.0).
- Le Keyframe Scheduler a un impact important sur l'apparence du masque. Il crée une liste de valeurs flottantes pour spécifier le seuil des valeurs de luminosité des pixels à utiliser pour les images de bruit d'entrée, ce qui entraînera une partie du bruit à être recadrée et transformée en masque final. Abaissez cette valeur pour conserver plus de bruit d'entrée, et augmentez pour en conserver moins.
Masques de dilatation
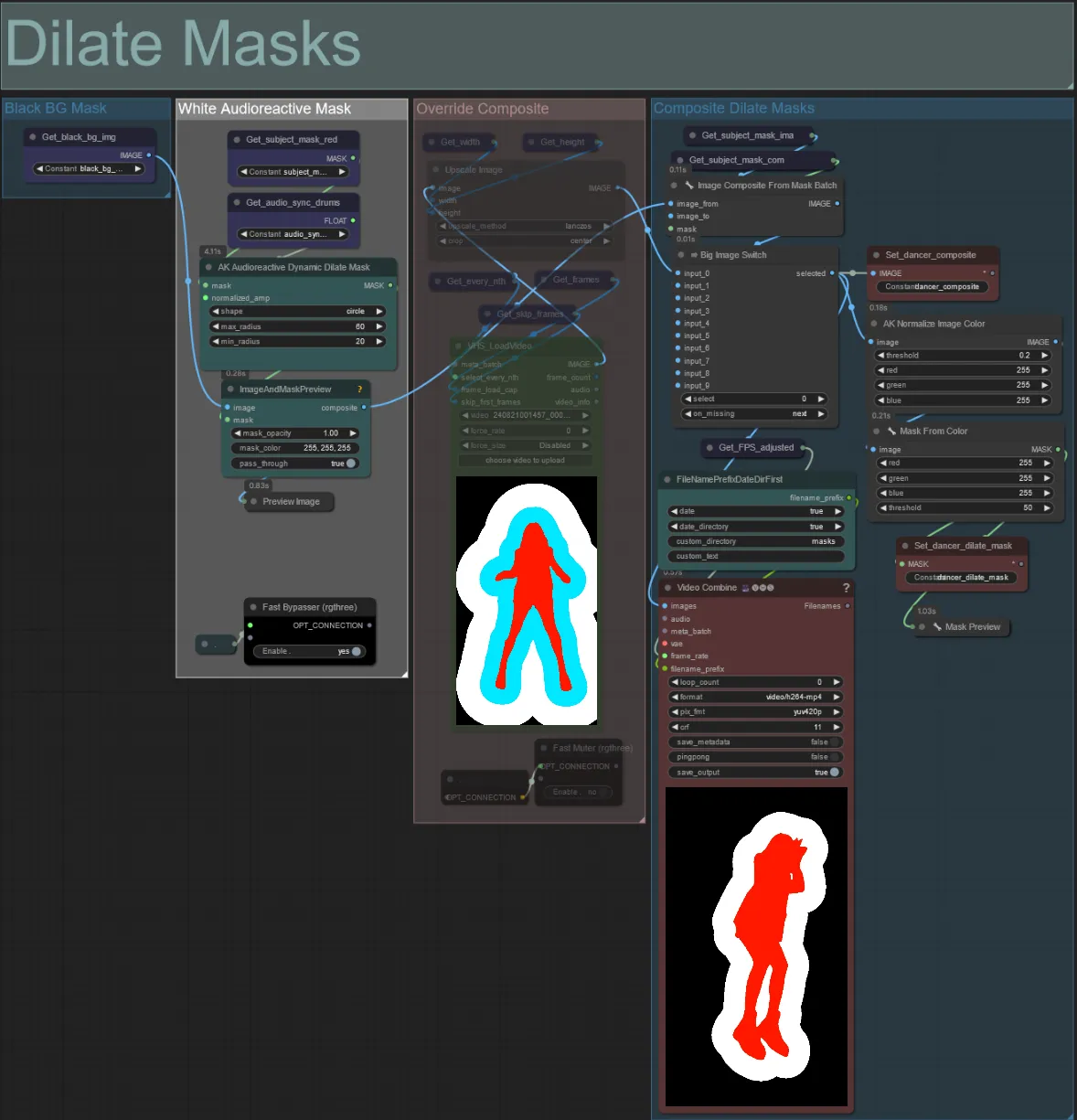
- Chaque groupe coloré correspond à la couleur du masque de dilatation qui sera généré par lui.
- Vous pouvez définir le rayon minimum et maximum du masque de dilatation, ainsi que la forme à l'aide du nœud suivant :
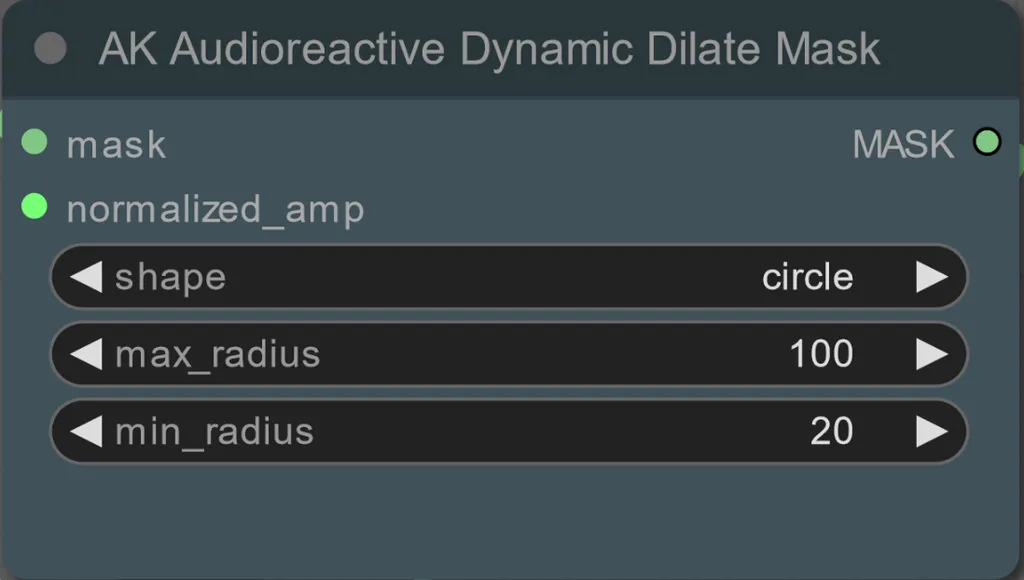
- shape: "circle" est le plus précis mais prend plus de temps à générer. Définissez cela lorsque vous êtes prêt à effectuer le rendu final. "square" est rapide à calculer mais moins précis, le mieux pour tester le flux de travail et décider des images IP adapter.
- max_radius: Le rayon du masque en pixels lorsque la valeur d'amplitude est maximale (1.0).
- min_radius: Le rayon du masque en pixels lorsque la valeur d'amplitude est minimale (0.0).
- Si vous avez déjà une vidéo de masque composite générée, vous pouvez désactiver le groupe "Override Composite Mask" et la télécharger. Il est recommandé de contourner les groupes de masques de dilatation si vous contournez pour gagner du temps de traitement.
Masque de bruit latent
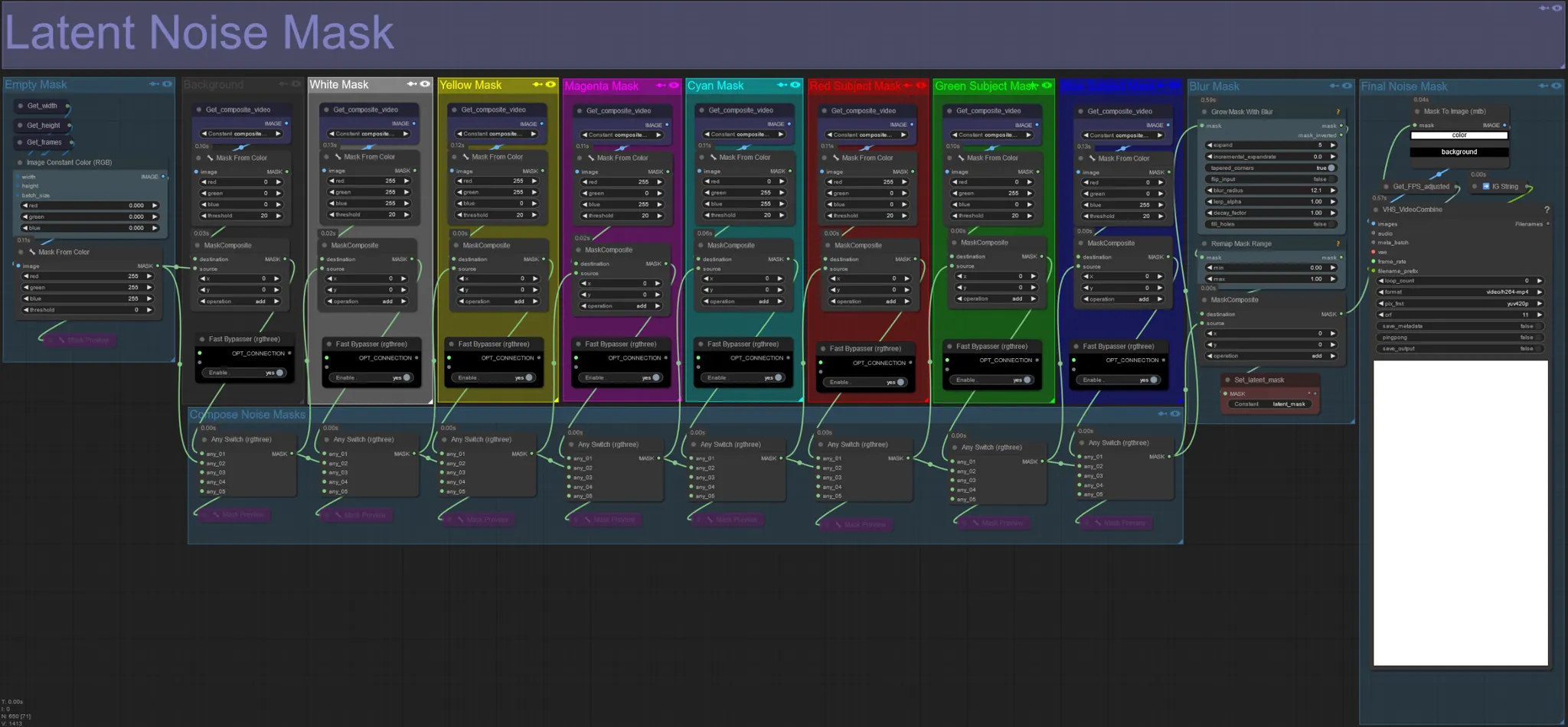
- Utilisez des masques de bruit latent pour contrôler quels masques sont réellement diffusés (rêvés) par le ksampler. Ignorez le groupe correspondant au masque coloré que vous ne voulez pas diffuser (c'est-à-dire que vous voulez que des éléments de la vidéo originale apparaissent dessus).
- Laisser tous les groupes de masques activés entraîne un masque de bruit final blanc (tout sera diffusé).
- Exemple : Ignorez le groupe Red Subject Mask en cliquant sur le nœud Fast Bypasser pour que votre danseur ou sujet apparaisse dans le rendu final.
Vidéo d'entrée originale :

Contourner les groupes de masques rouge et jaune :

Masque composite
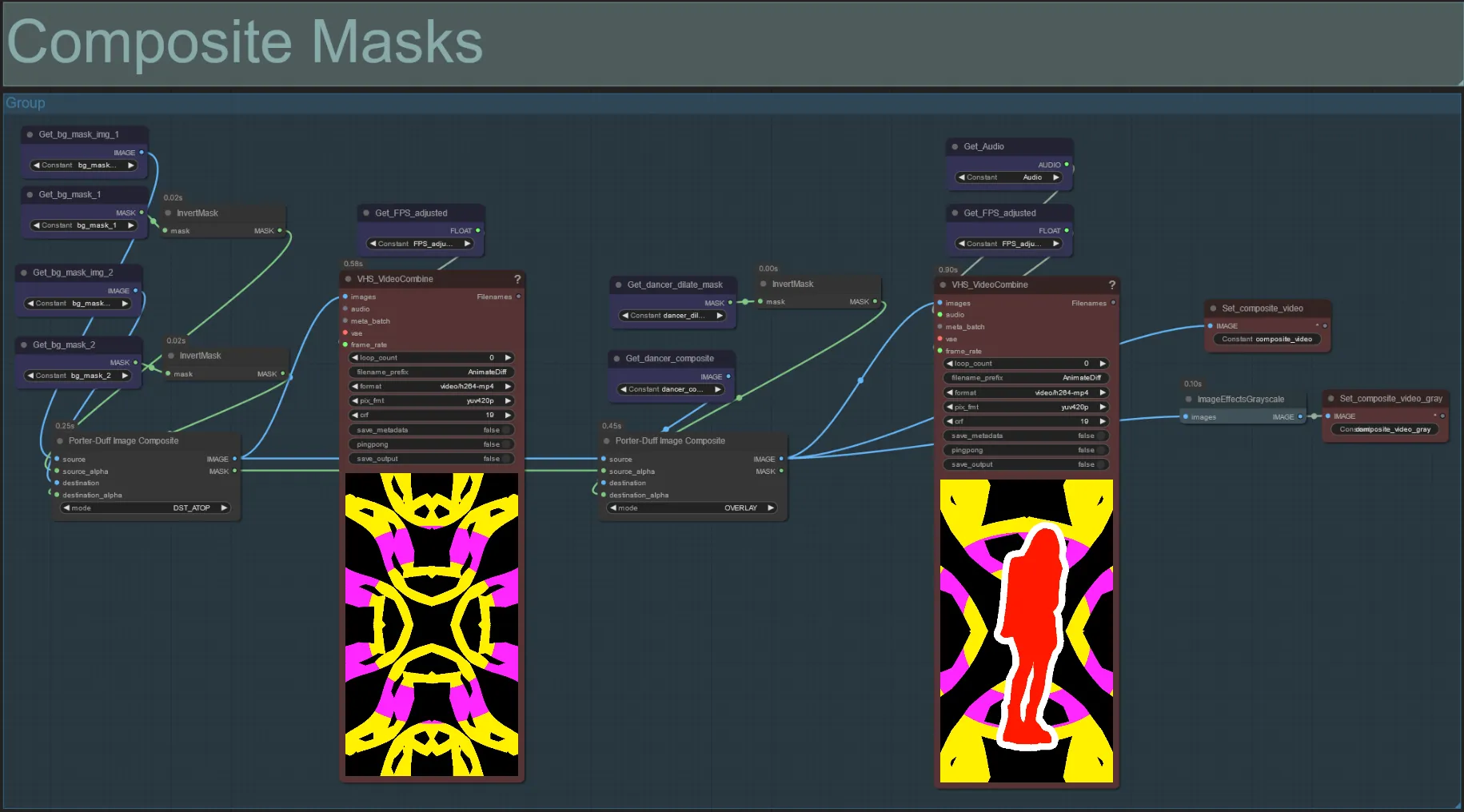
- Cette section crée le composite final des masques de bruit voronoi avec le masque du sujet (et le masque de dilatation audioreactif si activé).
Models
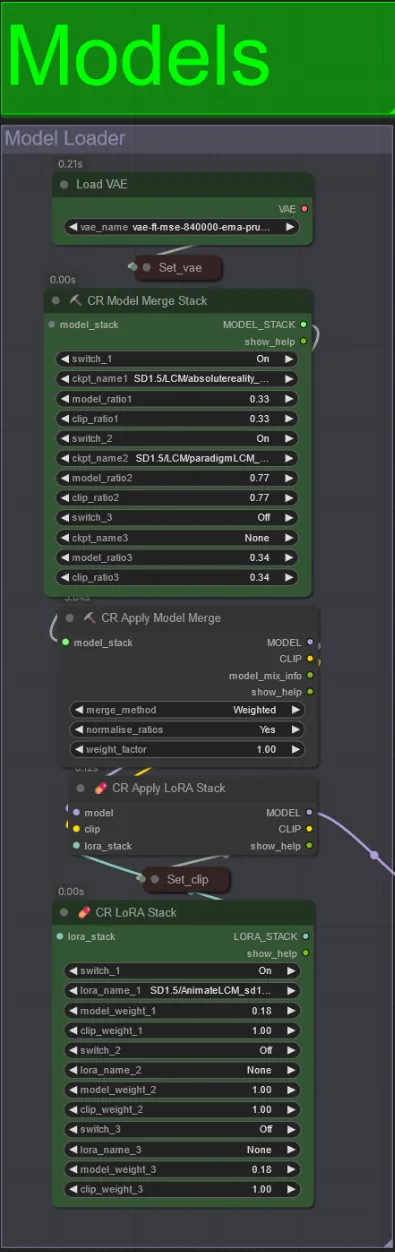
- Utilisez un bon modèle LCM pour le checkpoint. Je recommande ParadigmLCM de Machine Delusions.
- Vous pouvez fusionner plusieurs modèles ensemble en utilisant le Model Merge Stack pour obtenir divers effets intéressants. Assurez-vous que les poids s'additionnent à 1.0 pour les modèles activés.
- Vous pouvez éventuellement spécifier le AnimateLCM_sd15_t2v_lora.safetensors avec un poids faible de 0.18 pour améliorer encore le résultat final.
- Ajoutez des Loras supplémentaires au modèle en utilisant le Lora stacker sous le chargeur de modèle.
AnimateDiff

- Vous pouvez définir un Motion Lora différent de celui que j'ai utilisé (LiquidAF-0-1.safetensors)
- Augmentez/diminuez les floats Scale et Effect pour augmenter/diminuer la quantité de mouvement dans le rendu.
IP Adapters
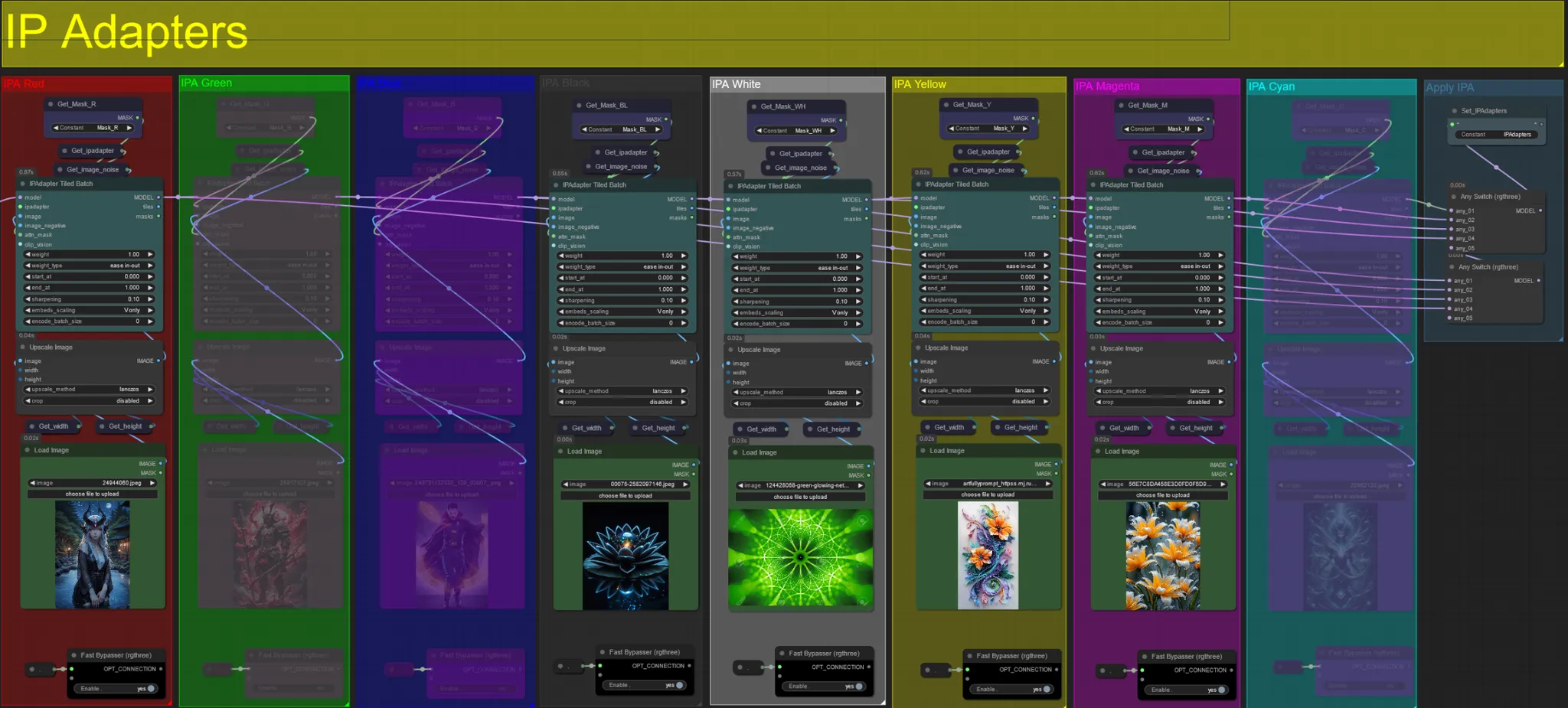
- Ici, vous pouvez spécifier les images de référence qui seront utilisées pour rendre les arrière-plans pour chacun des masques de dilatation, ainsi que votre sujet(s) vidéo.
- La couleur de chaque groupe représente le masque qu'il cible :
Rouge, Vert, Bleu :
- Images de référence du masque de sujet.
Noir :
- Image de masque d'arrière-plan, téléchargez une image de référence pour l'arrière-plan.
Blanc :
- Images de référence du masque de dilatation, téléchargez une image de référence pour chaque couleur de masque de dilatation en cours d'utilisation.
Jaune, Magenta
- Images de référence du masque de bruit voronoi.
ControlNet
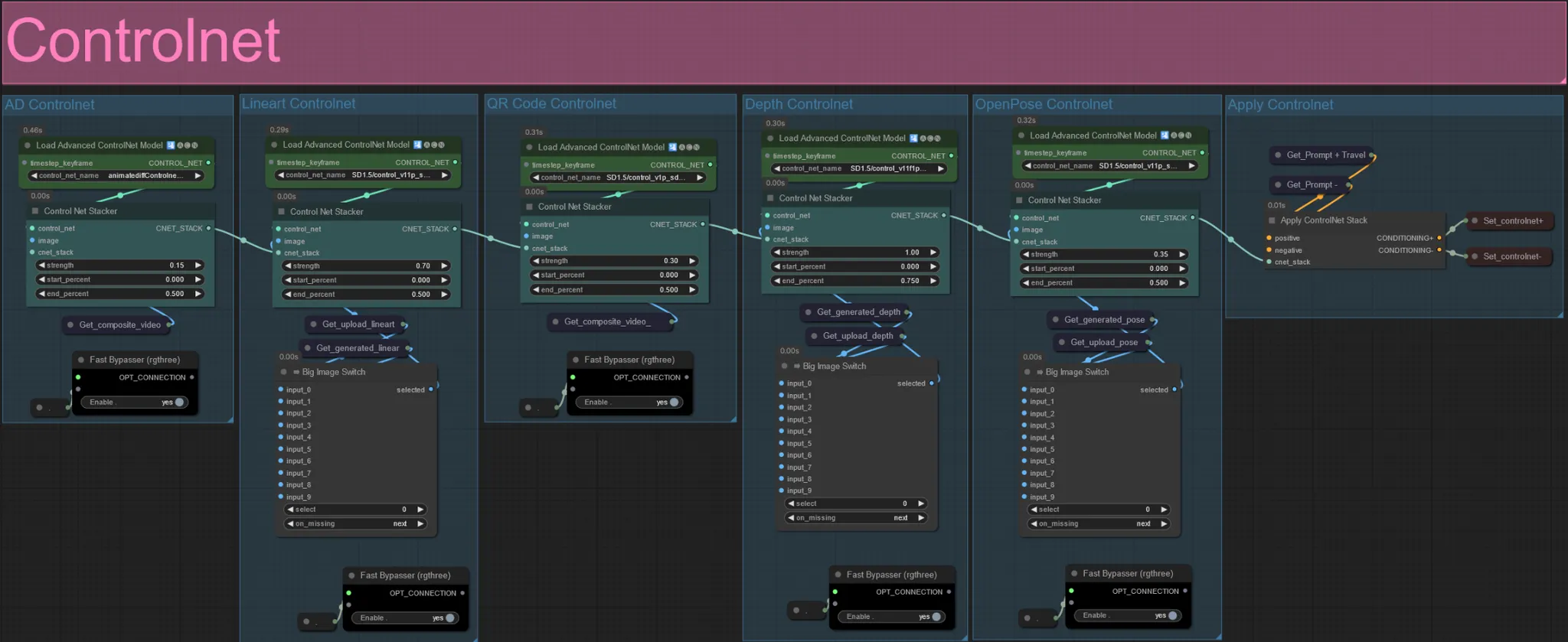
- Ce flux de travail utilise 5 controlnets différents, y compris AD, Lineart, QR Code, Depth et OpenPose.
- Toutes les entrées des controlnets sont générées automatiquement
- Vous pouvez choisir de remplacer la vidéo d'entrée pour les controlnets Lineart, Depth et Openpose si souhaité en désactivant les groupes "Override" comme vu ci-dessous :
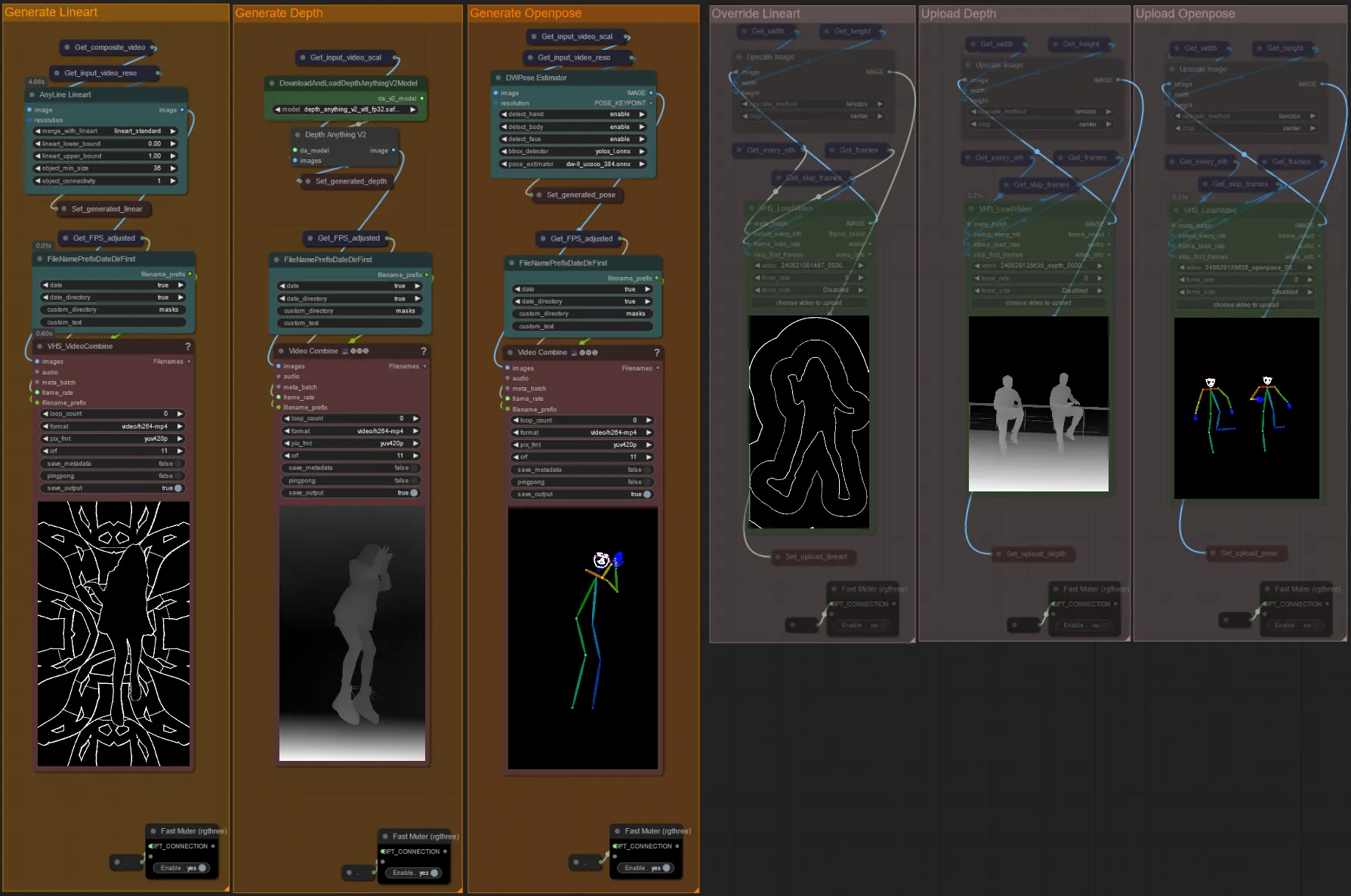
- Il est recommandé de désactiver également les groupes "Generate" si vous remplacez pour gagner du temps de traitement.
Conseil :
- Ignorez le Ksampler et commencez un rendu avec votre vidéo d'entrée complète. Une fois que toutes les vidéos de prétraitement sont générées, enregistrez-les et téléchargez-les dans les remplacements respectifs. Désormais, lors du test du flux de travail, vous n'aurez pas à attendre que chaque vidéo de prétraitement soit générée individuellement.
Sampler
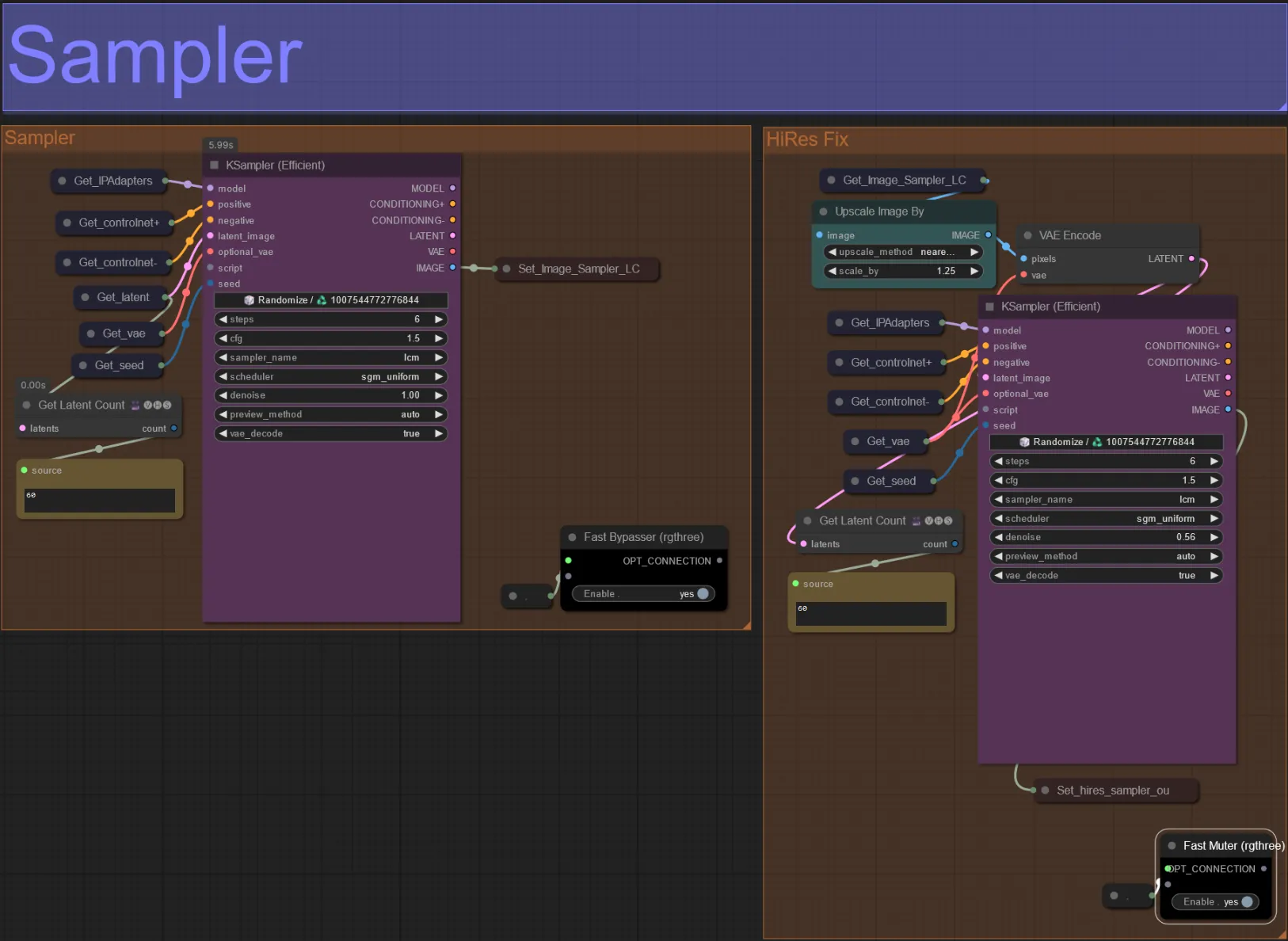
- Par défaut, le groupe HiRes Fix sampler sera désactivé pour économiser du temps de traitement lors des tests
- Je recommande de contourner également le groupe Sampler lors de l'expérimentation des paramètres du masque de dilatation pour gagner du temps.
- Lors des rendus finaux, vous pouvez réactiver le groupe HiRes Fix qui mettra à l'échelle et ajoutera des détails au résultat final.
Output
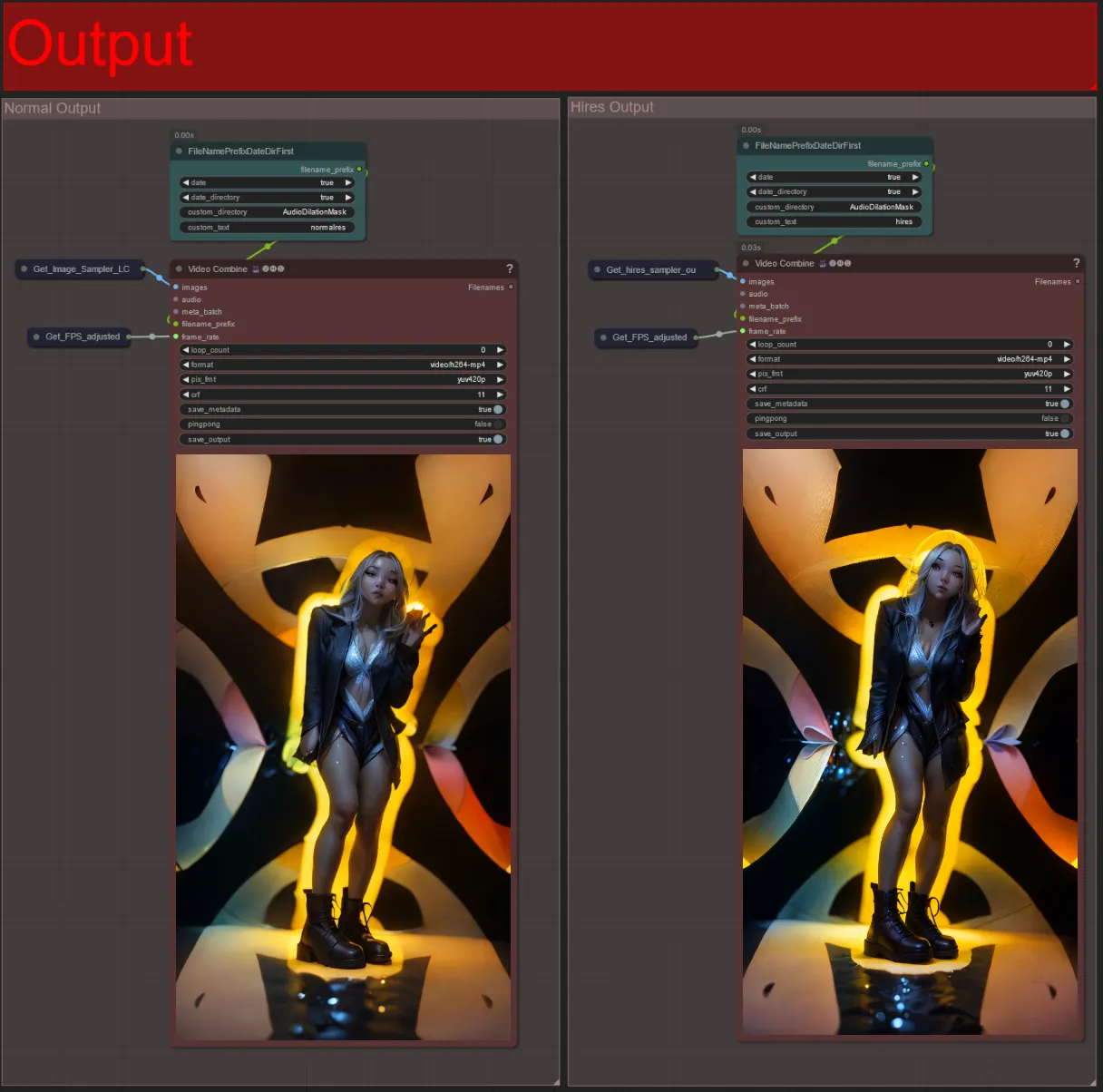
- Il y a deux groupes de sortie : la gauche est pour la sortie du sampler standard, et la droite est pour la sortie du HiRes Fix sampler.
- Vous pouvez changer l'emplacement où les fichiers seront enregistrés en modifiant la chaîne "custom_directory" dans les nœuds "FileNamePrefixDateDirFirst". Par défaut, ce nœud enregistrera les vidéos de sortie dans un répertoire horodaté dans le répertoire "output" de ComfyUI
- par ex.
…/ComfyUI/output/240812/<custom_directory>/<my_video>.mp4
- par ex.
Créer une vidéo audioreactive peut ajouter une énergie immersive et pulsante à votre sujet, avec chaque image répondant au rythme en temps réel. Alors, plongez dans le monde de l'art audioreactif et profitez des transformations guidées par le rythme !
À propos de l'auteur
Akatz AI :
- Site Web :
Contacts:
- Email: akatzfey@sendysoftware.com

