AnimateDiff + ControlNet + IPAdapter V1 | Style Cartoon
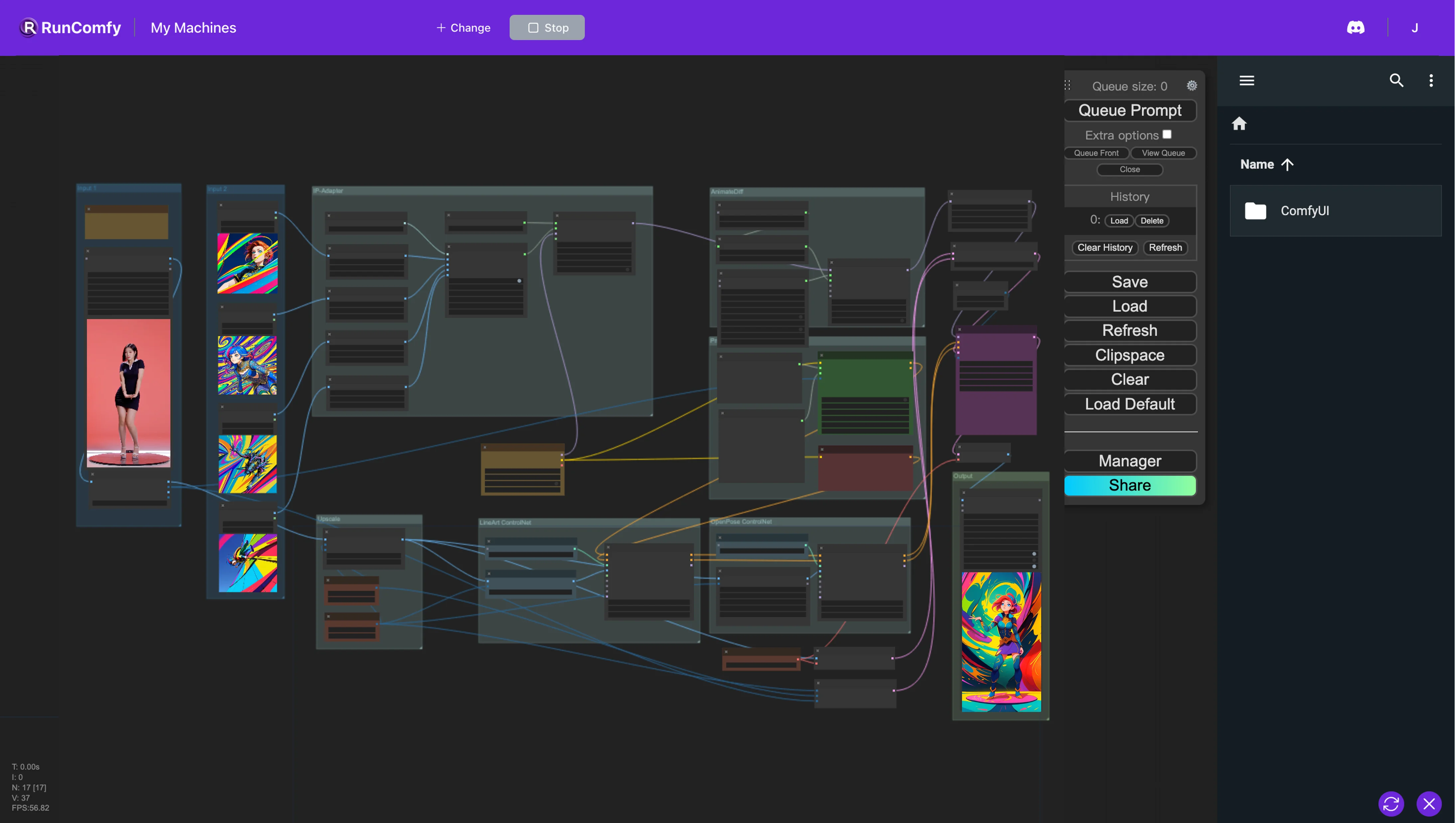
Dans le Workflow ComfyUI, nous intégrons plusieurs nœuds, notamment Animatediff, ControlNet (avec LineArt et OpenPose), IP-Adapter et FreeU. Cette intégration facilite la conversion de la vidéo originale en l'animation souhaitée en utilisant seulement une poignée d'images pour définir le style préféré. Cependant, les modèles de checkpoint affectent également le style. Nous encourageons l'expérimentation avec une variété d'images et de modèles de checkpoint pour obtenir les meilleurs résultats!Flux de travail ComfyUI Vid2Vid (Cartoon Style)
- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
Exemples ComfyUI Vid2Vid (Cartoon Style)
Description ComfyUI Vid2Vid (Cartoon Style)
1. Workflow ComfyUI AnimateDiff, ControlNet, IP-Adapter et FreeU
Le workflow ComfyUI implémente une méthodologie pour le restyling vidéo qui intègre plusieurs composants—AnimateDiff, ControlNet, IP-Adapter et FreeU—pour améliorer les capacités d'édition vidéo.
AnimateDiff : Ce composant utilise des modèles de différence temporelle pour créer des animations fluides à partir d'images statiques au fil du temps. Il fonctionne en identifiant les différences entre les images consécutives et en appliquant progressivement ces variations pour réduire les changements brusques, préservant ainsi la cohérence du mouvement.
ControlNet : ControlNet exploite les signaux de contrôle, tels que ceux dérivés des outils d'estimation de pose comme OpenPose, pour guider le mouvement et le flux de l'animation. Ces signaux de contrôle sont superposés et traités par des modèles similaires aux réseaux de contrôle, qui à leur tour façonnent la sortie animée finale.
IP-Adapter : L'IP-Adapter est conçu pour adapter les images d'entrée afin qu'elles s'alignent plus étroitement avec les styles ou caractéristiques de sortie ciblés. Il entreprend des processus tels que la colorisation et le transfert de style, modifiant les attributs de l'image de manière non supervisée.
FreeU : En tant qu'outil d'amélioration rentable, FreeU affine les modèles de diffusion en ajustant les architectures U-Net existantes. Cela se traduit par une augmentation substantielle de la qualité de la génération d'images et de vidéos, ne nécessitant que des modifications minimales.
Ensemble, ces composants se synergisent dans ce workflow ComfyUI pour transformer les entrées en animations stylisées grâce à un processus de diffusion sophistiqué en plusieurs étapes.
2. Aperçu d'AnimateDiff
Veuillez consulter les détails sur
3. Aperçu de ControlNet
Veuillez consulter les détails sur
4. Aperçu d'IP-Adapter
Veuillez consulter les détails dans l
5. Aperçu de FreeU
5.1. Introduction à FreeU
FreeU est une amélioration de pointe pour les modèles de diffusion qui élève la qualité de l'échantillon sans surcharge supplémentaire. Il fonctionne au sein du système existant, ne nécessitant pas de formation supplémentaire, pas de paramètres supplémentaires et maintenant la mémoire et le temps de traitement actuels. FreeU utilise les mécanismes existants de l'architecture de diffusion U-Net pour améliorer instantanément la qualité de la génération.
L'innovation de FreeU réside dans sa capacité à exploiter plus efficacement l'architecture de diffusion U-Net. Il affine l'équilibre entre le squelette de débruitage de l'U-Net et ses connexions de saut ajoutant des fonctionnalités haute fréquence, optimisant la qualité des images et vidéos générées sans compromettre l'intégrité sémantique.
FreeU est conçu pour une intégration facile avec les modèles de diffusion populaires, nécessitant des ajustements minimaux et le réglage de seulement deux facteurs d'échelle pendant l'inférence pour fournir des améliorations marquées de la qualité de sortie. Cela fait de FreeU une option attrayante pour ceux qui cherchent à améliorer efficacement leurs workflows génératifs.
Paramètres pour des performances FreeU optimales
N'hésitez pas à ajuster ces paramètres en fonction de vos modèles, du style d'image/vidéo ou des tâches. Les paramètres suivants sont donnés à titre indicatif uniquement.
SD1.4 : (sera bientôt mis à jour)
b1 : 1.3, b2 : 1.4, s1 : 0.9, s2 : 0.2
SD1.5 : (sera bientôt mis à jour)
b1 : 1.5, b2 : 1.6, s1 : 0.9, s2 : 0.2
SD2.1
b1 : 1.4, b2 : 1.6, s1 : 0.9, s2 : 0.2
SDXL
b1 : 1.3, b2 : 1.4, s1 : 0.9, s2 : 0.2
Plage pour plus de paramètres
Lorsque vous essayez des paramètres supplémentaires, considérez les plages suivantes :
- b1 : 1 ≤ b1 ≤ 1.2
- b2 : 1.2 ≤ b2 ≤ 1.6
- s1 : s1 ≤ 1
- s2 : s2 ≤ 1
Pour plus d'informations, consultez
