Formation FLUX LoRA
Ce workflow de formation ComfyUI FLUX LoRA vous permet d'affiner des modèles FLUX préexistants avec vos propres ensembles de données. Avec ce guide détaillé, vous apprendrez à préparer vos données de formation, à configurer le workflow, à configurer les paramètres essentiels et à exécuter le processus de formation. Débloquez tout le potentiel des modèles d'IA FLUX et créez des sorties sur mesure qui s'alignent parfaitement avec votre vision.Flux de travail ComfyUI FLUX LoRA Training
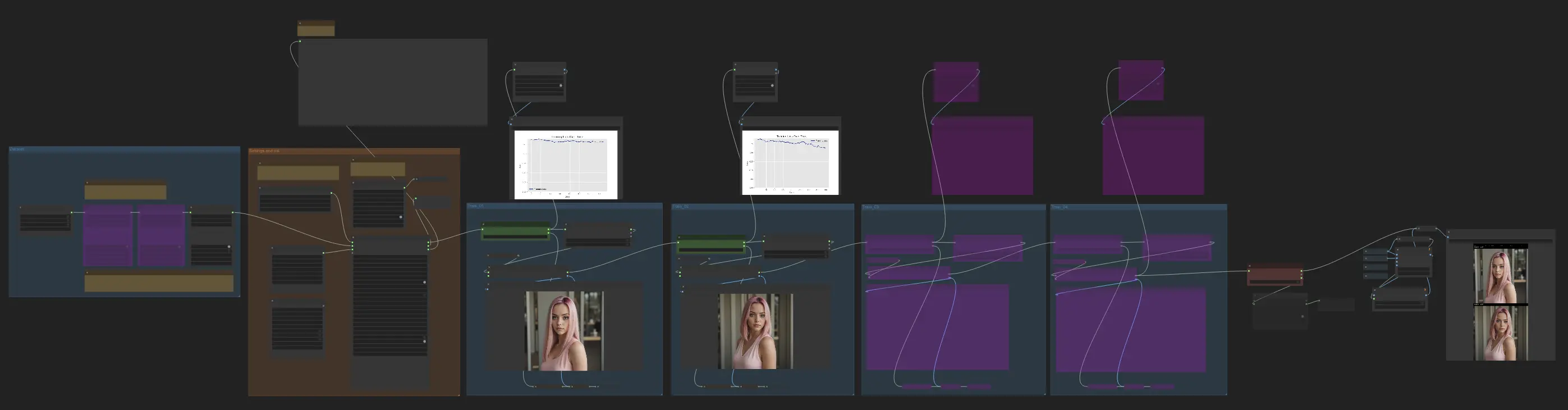
- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
Exemples ComfyUI FLUX LoRA Training

Description ComfyUI FLUX LoRA Training
FLUX LoRA a gagné une immense popularité dans la communauté de l'IA, en particulier parmi ceux qui cherchent à affiner des modèles d'IA avec leurs propres ensembles de données. Cette approche vous permet d'adapter sans effort des modèles FLUX préexistants à vos ensembles de données uniques, les rendant hautement personnalisables et efficaces pour une large gamme de projets créatifs. Si vous êtes déjà familier avec ComfyUI, utiliser le workflow de formation ComfyUI FLUX LoRA pour former votre modèle FLUX LoRA sera un jeu d'enfant. Le workflow et les nœuds associés ont été créés par Kijai, donc un grand merci à lui pour sa contribution ! Consultez le pour plus d'informations.
Tutoriel de formation ComfyUI FLUX LoRA
Le workflow de formation ComfyUI FLUX LoRA est un processus puissant conçu pour former des modèles FLUX LoRA. La formation avec ComfyUI offre plusieurs avantages, en particulier pour les utilisateurs déjà familiers avec son interface. Avec la formation FLUX LoRA, vous pouvez utiliser les mêmes modèles employés pour l'inférence, en veillant à ce qu'il n'y ait pas de problèmes de compatibilité lorsque vous travaillez dans le même environnement Python. De plus, vous pouvez créer des workflows pour comparer différents paramètres, améliorant ainsi votre processus de formation. Ce tutoriel vous guidera à travers les étapes pour configurer et utiliser la formation FLUX LoRA dans ComfyUI.
Nous couvrirons :
- Préparer votre ensemble de données pour la formation FLUX LoRA
- Le processus de formation FLUX LoRA
- Exécuter la formation FLUX LoRA
- Comment et où utiliser les modèles FLUX et FLUX LoRA
1. Préparer votre ensemble de données pour la formation FLUX LoRA
Lors de la préparation de vos données de formation pour la formation FLUX LoRA, il est essentiel d'avoir des images de haute qualité de votre sujet cible.
Dans cet exemple, nous formons un modèle FLUX LoRA pour générer des images d'un influenceur spécifique. Pour cela, vous aurez besoin d'un ensemble d'images de haute qualité de l'influenceur dans diverses poses et contextes. Une façon pratique de rassembler ces images est d'utiliser le , qui facilite la génération d'une collection d'images montrant le même personnage dans différentes poses tout en gardant leur apparence cohérente. Pour notre ensemble de données de formation, nous avons sélectionné cinq images de haute qualité de l'influenceur dans diverses poses et contextes, en veillant à ce que l'ensemble de données soit suffisamment robuste pour que la formation FLUX LoRA apprenne les détails complexes nécessaires pour produire des sorties cohérentes et précises.
Processus pour obtenir les données de formation
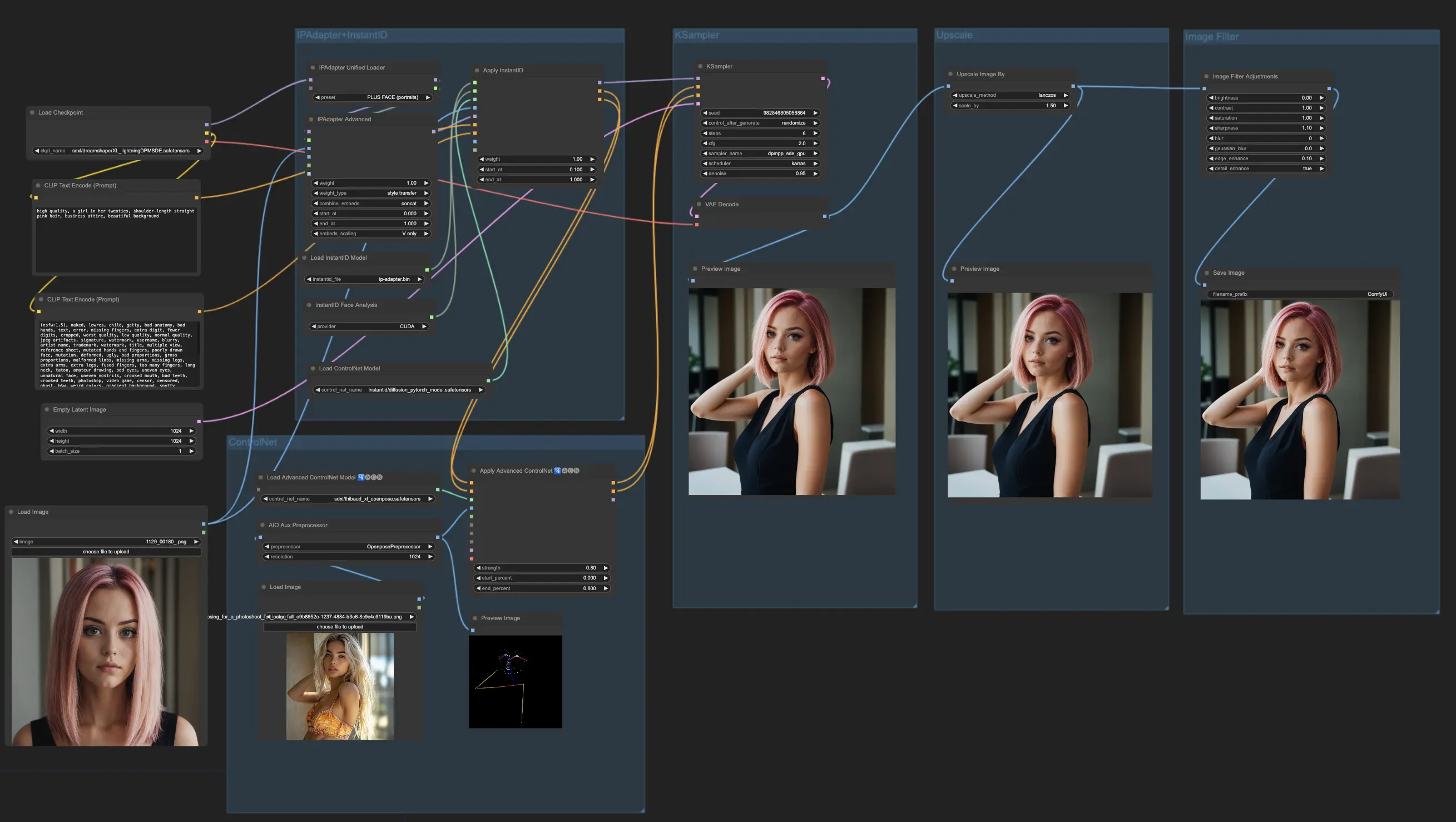
Exemple de données de formation

Vous pouvez également collecter votre propre ensemble de données en fonction de vos besoins spécifiques——la formation FLUX LoRA est flexible et fonctionne avec divers types de données.
2. Le processus de formation FLUX LoRA
Le workflow de formation FLUX LoRA se compose de plusieurs nœuds clés qui travaillent ensemble pour former et valider votre modèle. Voici un aperçu détaillé des principaux nœuds, séparés en trois parties : Ensemble de données, Paramètres et Init, et Formation.
2.1. Définir les ensembles de données pour la formation FLUX LoRA
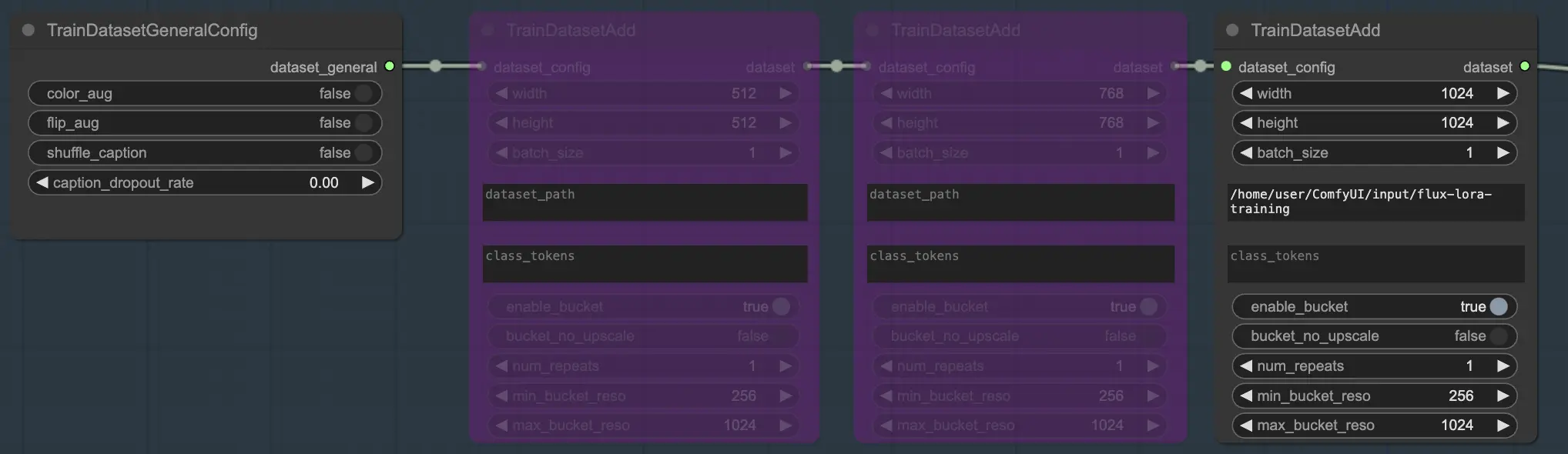
La section Ensemble de données se compose de deux nœuds essentiels qui vous aident à configurer et personnaliser vos données de formation : TrainDatasetGeneralConfig et TrainDatasetAdd.
2.1.1. TrainDatasetGeneralConfig
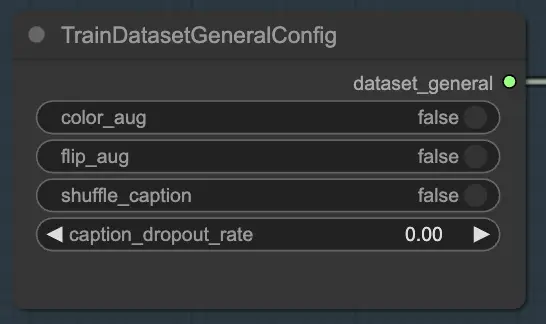
Le nœud TrainDatasetGeneralConfig est l'endroit où vous définissez les paramètres généraux de votre ensemble de données de formation dans FLUX LoRA Training. Ce nœud vous donne le contrôle sur divers aspects de l'augmentation et du prétraitement des données. Par exemple, vous pouvez choisir d'activer ou de désactiver l'augmentation des couleurs, ce qui peut aider à améliorer la capacité du modèle à généraliser à différentes variations de couleurs. De même, vous pouvez activer l'augmentation par retournement pour retourner les images horizontalement au hasard, fournissant des échantillons de formation plus diversifiés. De plus, vous avez la possibilité de mélanger les légendes associées à chaque image, introduisant de l'aléatoire et réduisant le surapprentissage. Le taux de dropout des légendes vous permet de supprimer des légendes au hasard pendant la formation, ce qui peut aider le modèle à devenir plus robuste face aux légendes manquantes ou incomplètes.
2.1.2. TrainDatasetAdd
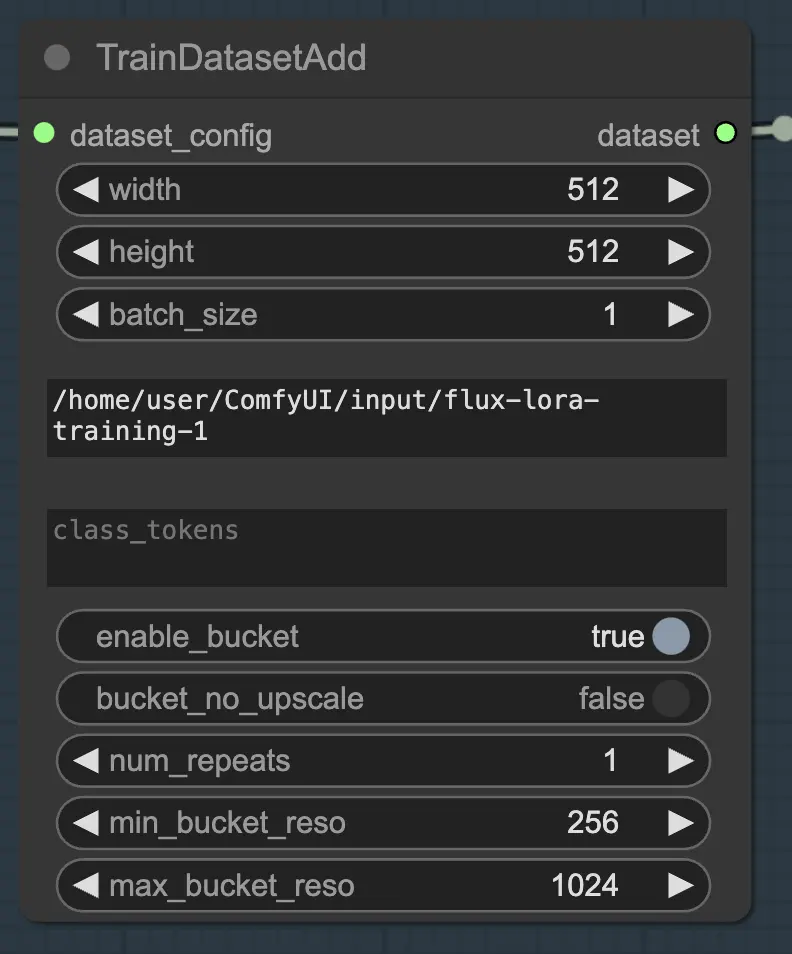
Le nœud TrainDatasetAdd est l'endroit où vous spécifiez les détails de chaque ensemble de données individuel à inclure dans votre formation FLUX LoRA.
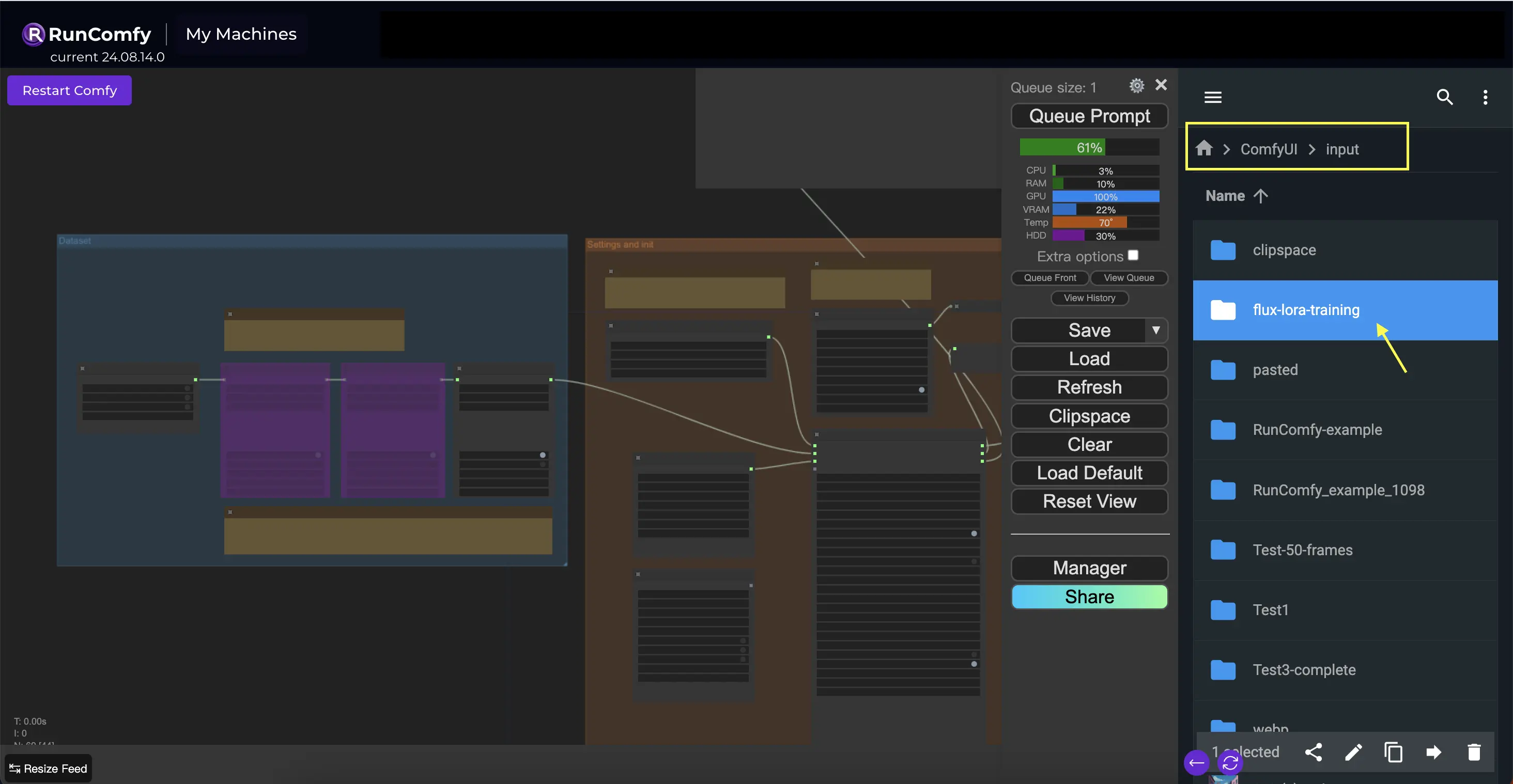
Répertoire d'entrée : Chemin de l'ensemble de données de formation
Pour tirer le meilleur parti de ce nœud, il est important d'organiser correctement vos données de formation. En utilisant le navigateur de fichiers de RunComfy, placez les données de formation dans le répertoire /home/user/ComfyUI/input/{file-name}, où {file-name} est un nom significatif que vous attribuez à votre ensemble de données.
Une fois que vous avez placé vos données de formation dans le répertoire approprié, vous devez fournir le chemin vers ce répertoire dans le paramètre image_dir du nœud TrainDatasetAdd. Cela indique au nœud où trouver vos images de formation.
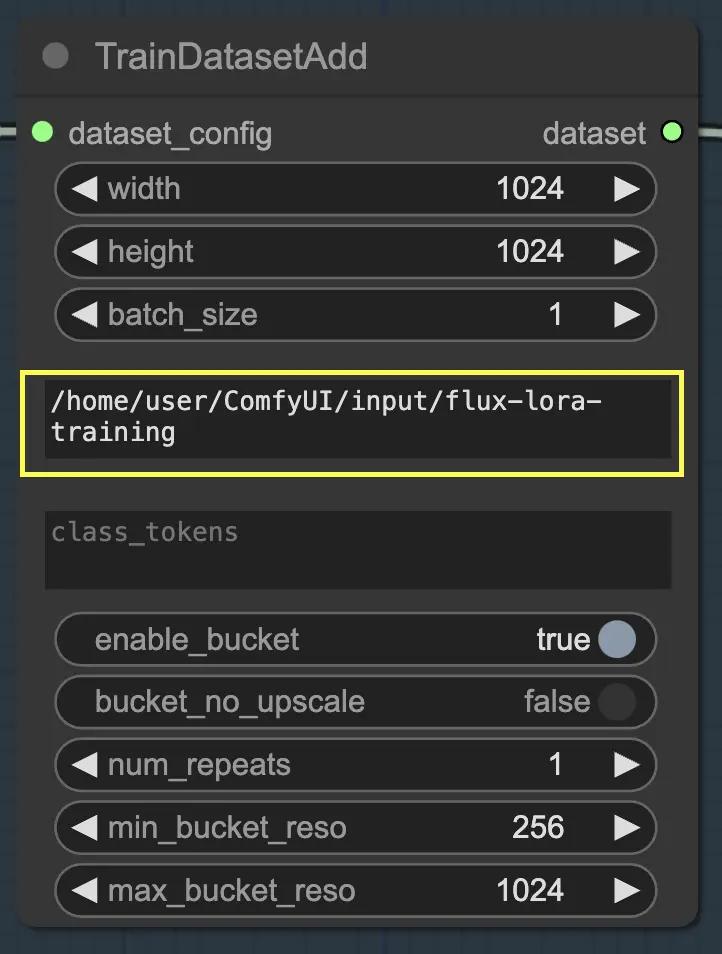
Class Token
Si votre ensemble de données bénéficie de l'utilisation de tokens de classe ou de mots déclencheurs spécifiques, vous pouvez les saisir dans le paramètre class_tokens. Les tokens de classe sont des mots ou des phrases spéciaux qui sont ajoutés au début de chaque légende et aident à guider le processus de génération du modèle. Par exemple, si vous formez un ensemble de données de différentes espèces animales, vous pourriez utiliser des tokens de classe comme "chien", "chat" ou "oiseau" pour indiquer l'animal souhaité dans les images générées. Lorsque vous utilisez ces tokens de classe dans vos invites, vous pouvez contrôler les aspects spécifiques que vous souhaitez que le modèle génère.
Définir la résolution (largeur et hauteur), taille du lot
En plus des paramètres image_dir et class_tokens, le nœud TrainDatasetAdd offre plusieurs autres options pour affiner votre ensemble de données. Vous pouvez définir la résolution (largeur et hauteur) des images, spécifier la taille du lot pour la formation et déterminer le nombre de fois que l'ensemble de données doit être répété par époque.
Plusieurs ensembles de données
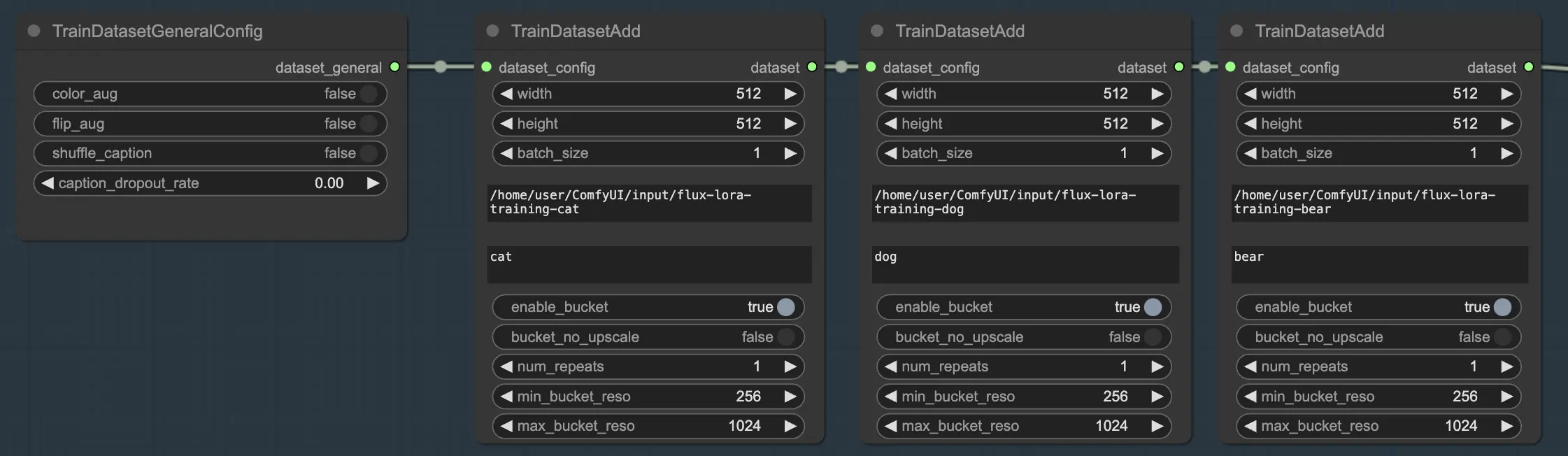
L'une des fonctionnalités puissantes de la formation FLUX LoRA est la capacité de combiner plusieurs ensembles de données de manière transparente. Dans le workflow de formation FLUX LoRA, il y a trois nœuds TrainDatasetAdd connectés en séquence. Chaque nœud représente un ensemble de données distinct avec ses propres paramètres uniques. En reliant ces nœuds ensemble, vous pouvez créer un ensemble de formation riche et diversifié qui incorpore des images et des légendes de diverses sources.
Pour illustrer cela, considérons un scénario où vous avez trois ensembles de données distincts : un pour les chats, un pour les chiens et un autre pour les ours. Vous pouvez configurer trois nœuds TrainDatasetAdd, chacun dédié à l'un de ces ensembles de données. Dans le premier nœud, vous spécifiez le chemin vers l'ensemble de données "chats" dans le paramètre image_dir, définissez le token de classe sur "chat" et ajustez d'autres paramètres comme la résolution et la taille du lot pour répondre à vos besoins. De même, vous configurez les deuxième et troisième nœuds pour les ensembles de données "chiens" et "ours", respectivement.
Cette approche permet au processus de formation FLUX LoRA de tirer parti d'une gamme diversifiée d'images, améliorant la capacité du modèle à généraliser à différentes catégories.
Exemple
Dans notre exemple, nous utilisons un seul ensemble de données pour former le modèle, donc nous activons un nœud TrainDatasetAdd et contournons les deux autres. Voici comment vous pouvez le configurer :
2.2. Paramètres et Initialisation
La section Paramètres et Initialisation est l'endroit où vous configurez les composants clés et les paramètres pour la formation FLUX LoRA. Cette section comprend plusieurs nœuds essentiels qui travaillent ensemble pour configurer votre environnement de formation.
2.2.1. FluxTrainModelSelect
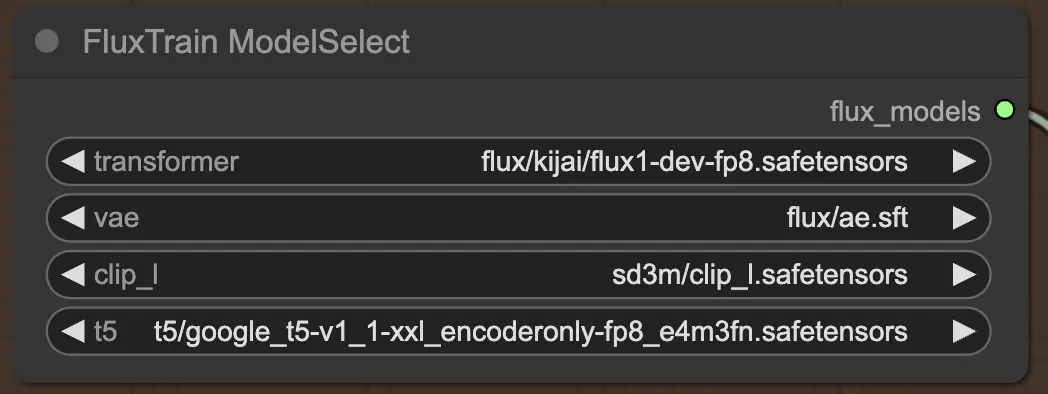
Tout d'abord, vous avez le nœud FluxTrainModelSelect, qui est responsable de la sélection des modèles FLUX qui seront utilisés pendant la formation FLUX LoRA. Ce nœud vous permet de spécifier les chemins vers quatre modèles critiques : le transformateur, le VAE (Auto-encodeur variationnel), le CLIP_L (Pré-formation de langage-Image Contraste) et le T5 (Transformateur Texte-à-Texte). Ces modèles forment la colonne vertébrale du processus de formation FLUX et ont tous été configurés sur la plateforme RunComfy.
2.2.2. OptimizerConfig
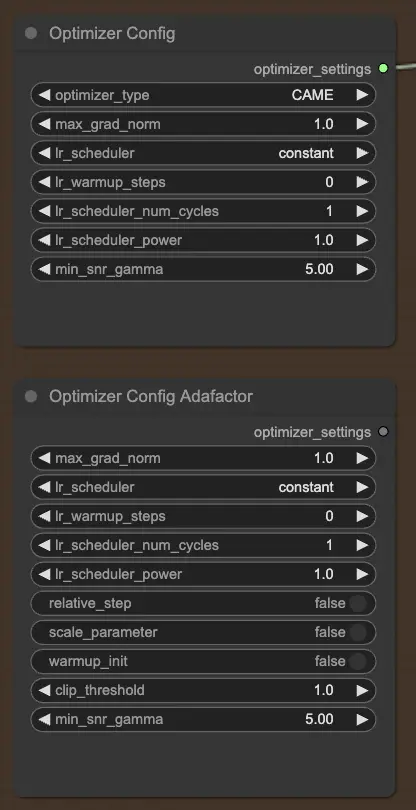
Le nœud OptimizerConfig est crucial pour configurer l'optimiseur dans la formation FLUX LoRA, qui détermine comment les paramètres du modèle sont mis à jour pendant la formation. Vous pouvez choisir le type d'optimiseur (par exemple, AdamW, CAME), définir la norme maximale du gradient pour le clipping du gradient afin de prévenir les gradients explosifs, et sélectionner le planificateur de taux d'apprentissage (par exemple, constant, cosinus). De plus, vous pouvez affiner les paramètres spécifiques à l'optimiseur comme les étapes de warmup et la puissance du planificateur, et fournir des arguments supplémentaires pour une personnalisation supplémentaire.
Si vous préférez l'optimiseur Adafactor, connu pour son efficacité en mémoire et sa capacité à gérer de grands modèles, vous pouvez utiliser le nœud OptimizerConfigAdafactor à la place.
2.2.3. InitFluxLoRATraining
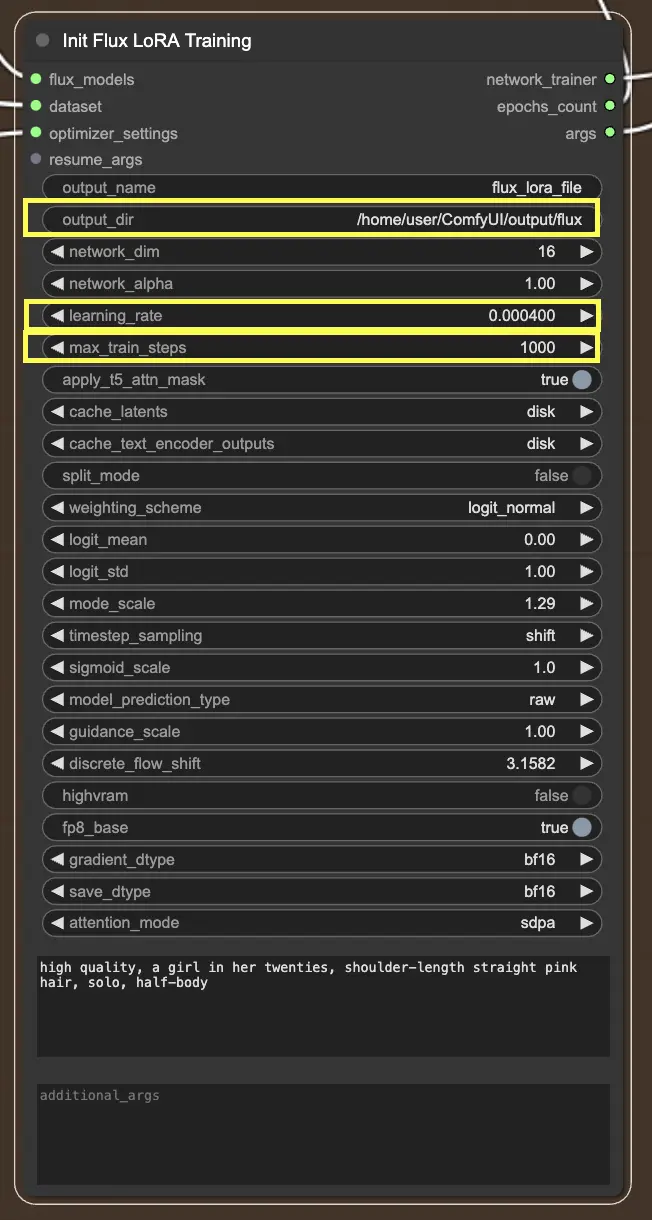
Le nœud InitFluxLoRATraining est le centre où tous les composants essentiels convergent pour lancer le processus de formation FLUX LoRA.
Répertoire de sortie : Chemin FLUX LoRA
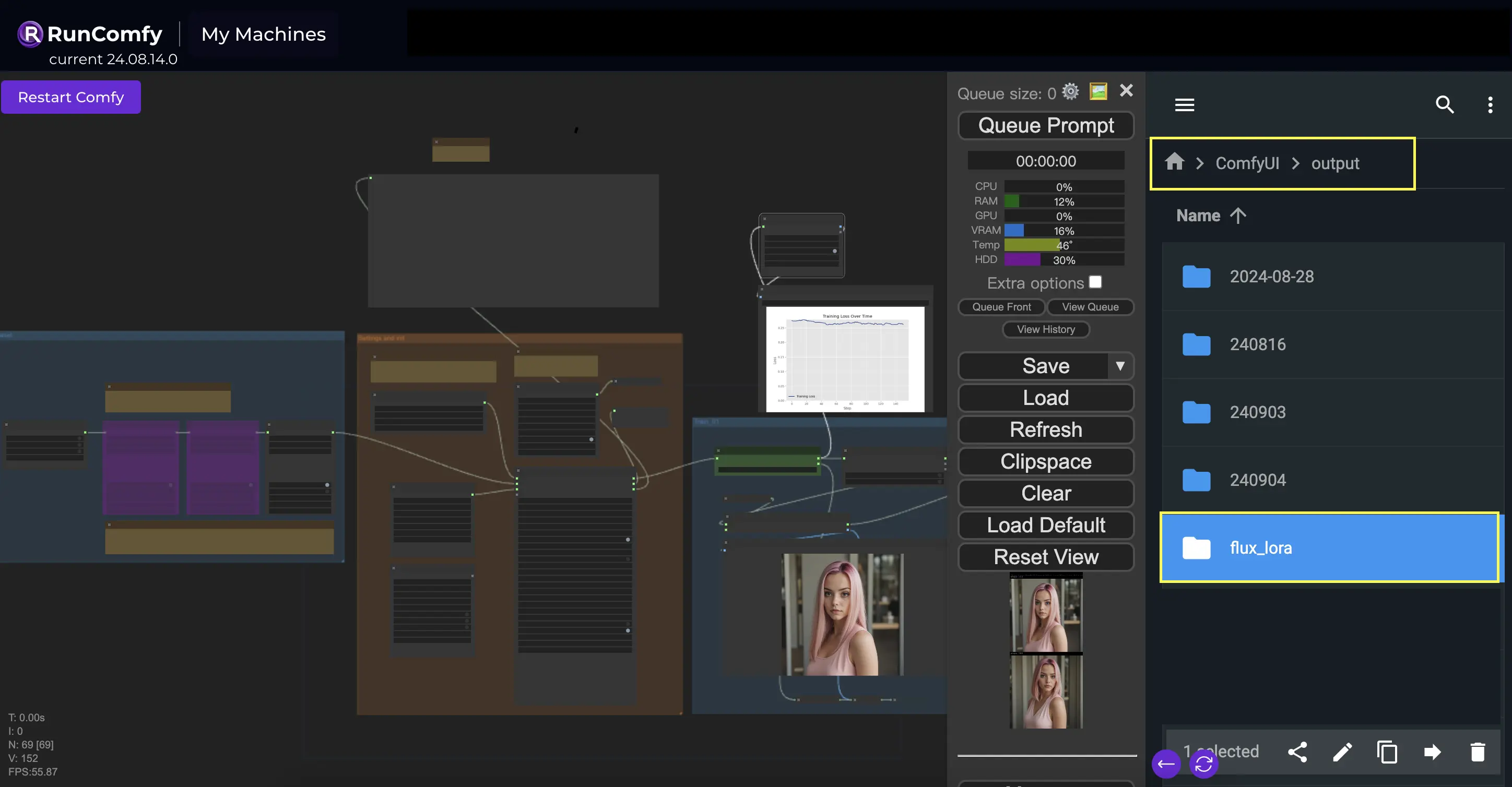
L'une des choses clés que vous devrez spécifier dans le nœud InitFluxLoRATraining est le répertoire de sortie, où votre modèle formé sera sauvegardé. Sur la plateforme RunComfy, vous pouvez choisir /home/user/ComfyUI/output/{file_name} comme emplacement pour votre sortie. Une fois la formation terminée, vous pourrez la visualiser dans le navigateur de fichiers.
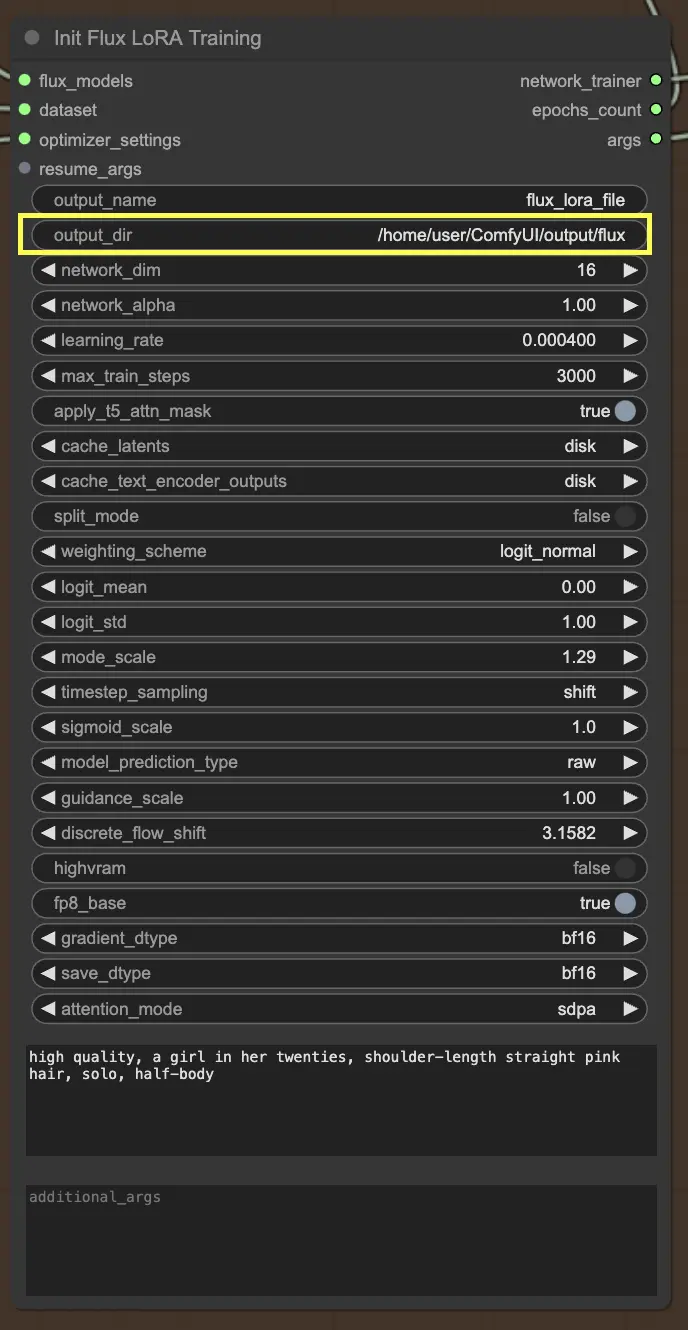
Dimensions du réseau et taux d'apprentissage
Ensuite, vous voudrez définir les dimensions du réseau et les taux d'apprentissage. Les dimensions du réseau déterminent la taille et la complexité de votre réseau LoRA, tandis que les taux d'apprentissage contrôlent la vitesse à laquelle votre modèle apprend et s'adapte.
Étapes maximales de formation
Un autre paramètre important à considérer est le max_train_steps. Il détermine la durée de la formation, ou en d'autres termes, combien d'étapes vous souhaitez que votre modèle prenne avant qu'il ne soit complètement formé. Vous pouvez ajuster cette valeur en fonction de vos besoins spécifiques et de la taille de votre ensemble de données. Il s'agit de trouver le juste milieu où votre modèle a suffisamment appris pour produire des résultats optimaux !
2.3.4. FluxTrainValidationSettings
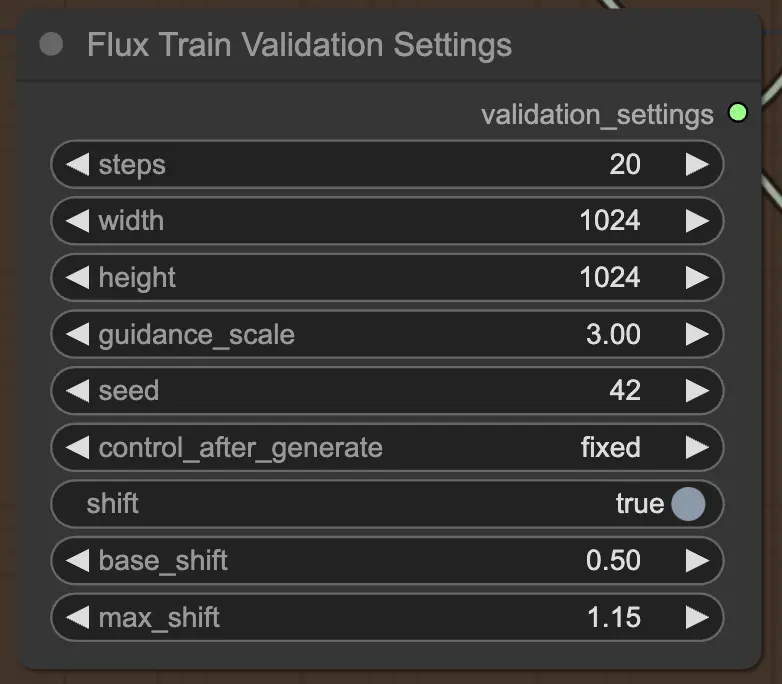
Enfin, le nœud FluxTrainValidationSettings vous permet de configurer les paramètres de validation pour évaluer les performances de votre modèle pendant le processus de formation FLUX LoRA. Vous pouvez définir le nombre d'étapes de validation, la taille des images, l'échelle de guidage et la graine pour la reproductibilité. De plus, vous pouvez choisir la méthode d'échantillonnage des timesteps et ajuster les paramètres d'échelle et de décalage sigmoïdes pour contrôler la planification des timesteps et améliorer la qualité des images générées.
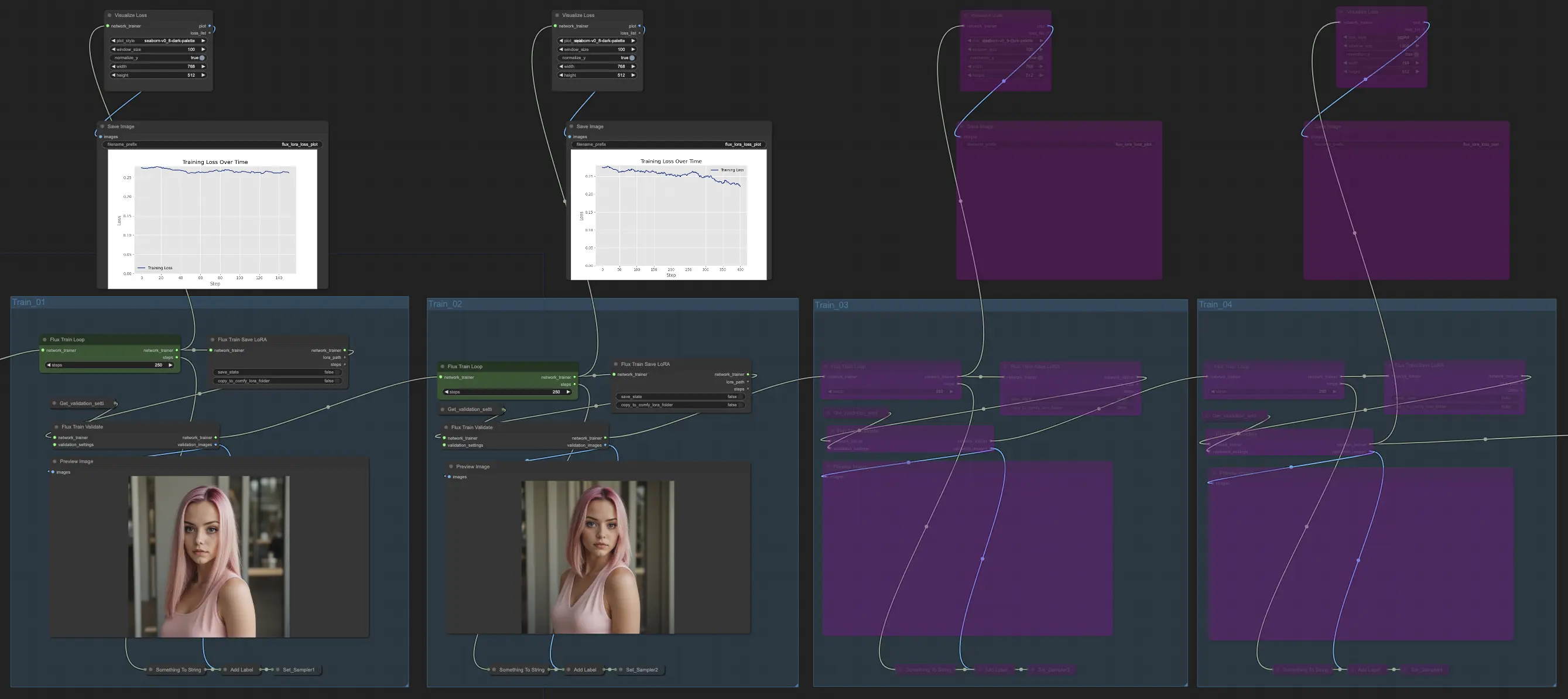
3. Formation
La section Formation de FLUX LoRA Training est l'endroit où la magie opère. Elle est divisée en quatre parties : Train_01, Train_02, Train_03 et Train_04. Chacune de ces parties représente une étape différente du processus de formation FLUX LoRA, vous permettant de raffiner et d'améliorer progressivement votre modèle.
3.1. Train_01
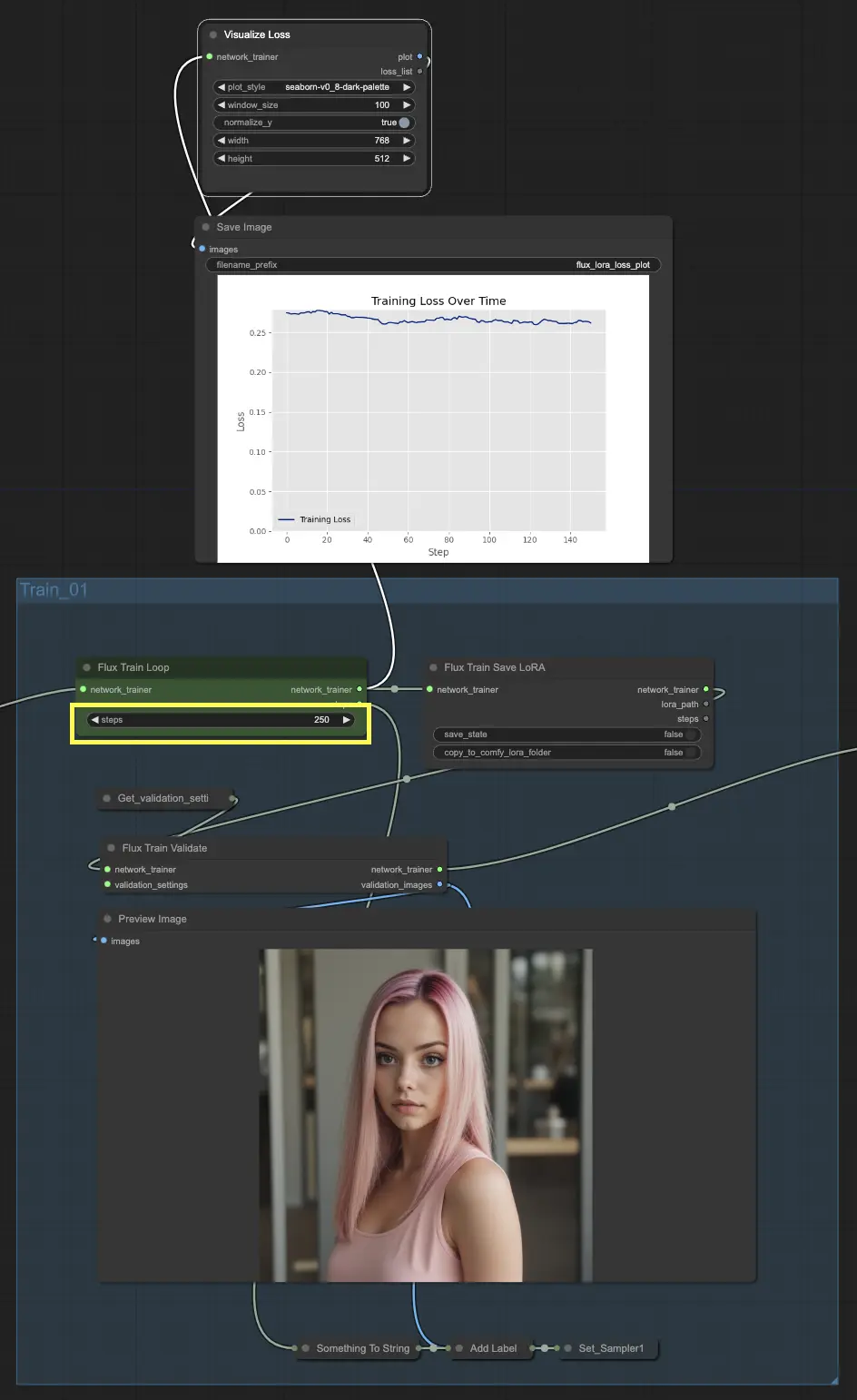
Commençons par Train_01. C'est ici que la boucle de formation initiale a lieu. La star de cette section est le nœud FluxTrainLoop, qui est responsable de l'exécution de la boucle de formation pour un nombre spécifié d'étapes. Dans cet exemple, nous l'avons défini à 250 étapes, mais vous pouvez ajuster cela en fonction de vos besoins. Une fois la boucle de formation terminée, le modèle formé est transmis au nœud FluxTrainSave, qui sauvegarde le modèle à intervalles réguliers. Cela garantit que vous avez des points de contrôle de votre modèle à différentes étapes de la formation, ce qui peut être utile pour suivre les progrès et récupérer en cas d'interruptions inattendues.
Mais la formation n'est pas seulement une question de sauvegarde du modèle. Nous devons également valider ses performances pour voir à quel point il fonctionne. C'est là que le nœud FluxTrainValidate entre en jeu. Il prend le modèle formé et le met à l'épreuve en utilisant un ensemble de données de validation. Cet ensemble de données est séparé des données de formation et aide à évaluer la capacité du modèle à généraliser à des exemples non vus. Le nœud FluxTrainValidate génère des images d'échantillon basées sur lesjson données de validation, vous donnant une représentation visuelle de la sortie du modèle à ce stade.
Pour suivre les progrès de la formation, nous avons le nœud VisualizeLoss. Ce nœud pratique visualise la perte de formation au fil du temps, vous permettant de voir à quel point le modèle apprend et s'il converge vers une bonne solution. C'est comme avoir un entraîneur personnel qui suit vos progrès et vous aide à rester sur la bonne voie.
3.2. Train_02, Train_03, Train_04
Dans Train_02, en continuant à partir de Train_01 dans la formation FLUX LoRA, la sortie est encore formée pour un nombre supplémentaire d'étapes spécifié (par exemple, 250 étapes). Train_03 et Train_04 suivent un modèle similaire, prolongeant la formation avec des connexions mises à jour pour une progression en douceur. Chaque étape produit un modèle FLUX LoRA, vous permettant de tester et de comparer les performances.
Exemple
Dans notre exemple, nous avons choisi d'utiliser uniquement Train_01 et Train_02, chacun fonctionnant pendant 250 étapes. Nous avons contourné Train_03 et Train_04 pour l'instant. Mais n'hésitez pas à expérimenter et à ajuster le nombre de sections de formation et les étapes en fonction de vos besoins spécifiques et des ressources disponibles.
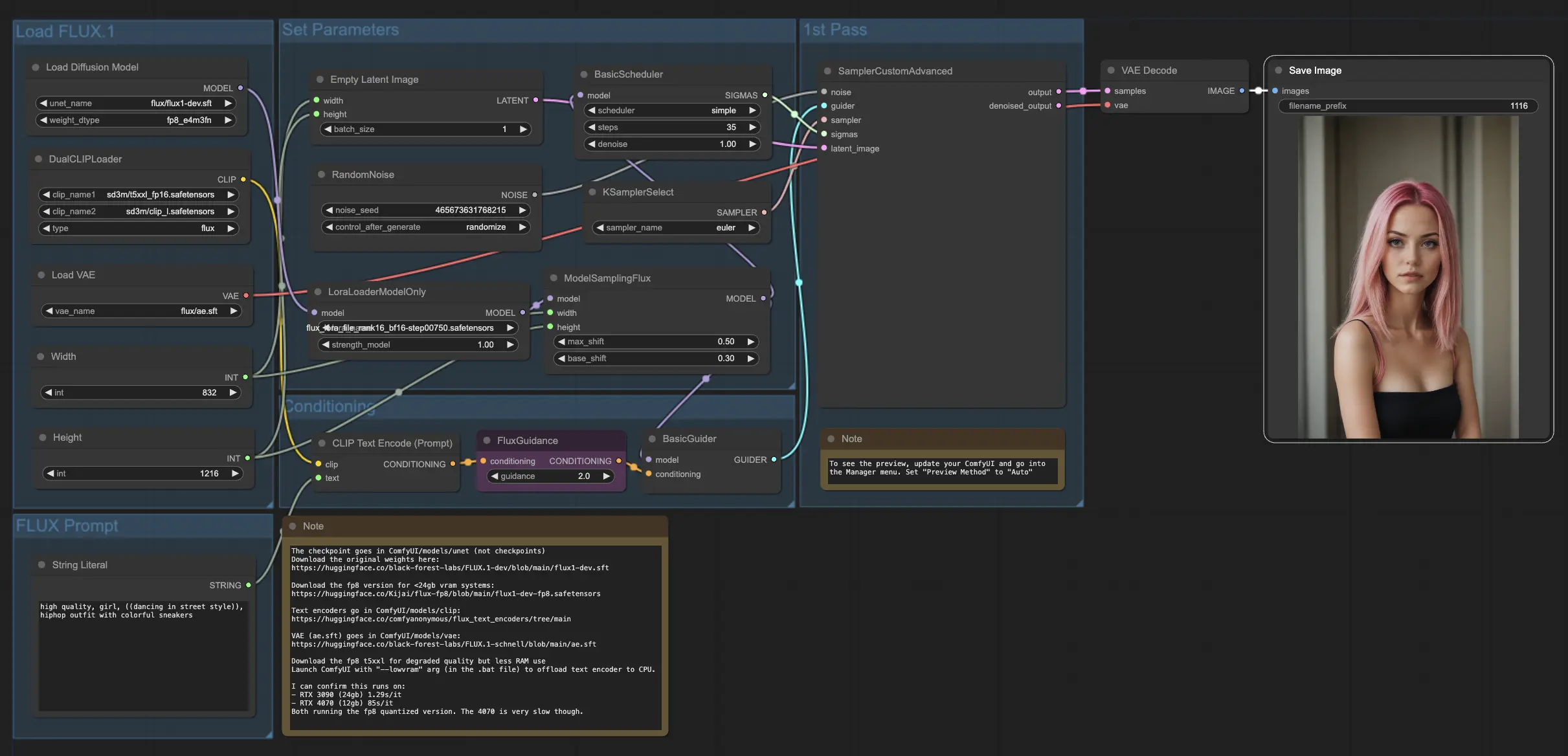
4. Comment et où utiliser les modèles FLUX et FLUX LoRA
Une fois que vous avez le modèle FLUX LoRA, vous pouvez l'incorporer dans le . Remplacez le modèle LoRA existant par votre modèle formé, puis testez les résultats pour évaluer ses performances.
Exemple
Dans notre exemple, nous utilisons le workflow FLUX LoRA pour générer plus d'images d'influenceurs en appliquant le modèle FLUX LoRA et en observant ses performances.
Licence
Consultez les fichiers de licence :
Le modèle FLUX.1 [dev] est sous licence de Black Forest Labs. Inc. sous la licence FLUX.1 [dev] Non-Commercial License. Copyright Black Forest Labs. Inc.
EN AUCUN CAS BLACK FOREST LABS, INC. NE SERA RESPONSABLE DE TOUTE RÉCLAMATION, DOMMAGE OU AUTRE RESPONSABILITÉ, QUE CE SOIT DANS LE CADRE D'UNE ACTION CONTRACTUELLE, DÉLICTUELLE OU AUTRE, DÉCOULANT DE, OU EN LIEN AVEC L'UTILISATION DE CE MODÈLE.






