
1. Qu'est-ce qu'Omost?#
Omost, abréviation de "Votre image est presque là!", est un projet innovant qui convertit les capacités de codage des Large Language Models (LLM) en génération d'images, ou plus précisément, en capacités de composition d'images. Le nom "Omost" a une double signification: il implique qu'à chaque fois que vous utilisez Omost, votre image est presque complète, et il signifie également "omni" (multi-modal) et "most" (tirer le meilleur parti de cela).
Omost fournit des modèles LLM pré-entraînés qui génèrent du code pour composer du contenu visuel d'image en utilisant l'agent Canvas virtuel d'Omost. Ce Canvas peut ensuite être rendu par des implémentations spécifiques de générateurs d'images pour créer les images finales. Omost est conçu pour simplifier et améliorer le processus de génération d'images, le rendant accessible et efficace pour les artistes AI.
2. Comment fonctionne Omost#
2.1. Canvas et Descriptions#
Omost utilise un Canvas virtuel où les éléments de l'image sont décrits et positionnés. Le Canvas est divisé en une grille de 9x9=81 positions, permettant un placement précis des éléments. Ces positions sont ensuite affinées en boîtes englobantes, offrant 729 emplacements différents possibles pour chaque élément. Cette approche structurée garantit que les éléments sont placés de manière précise et cohérente.
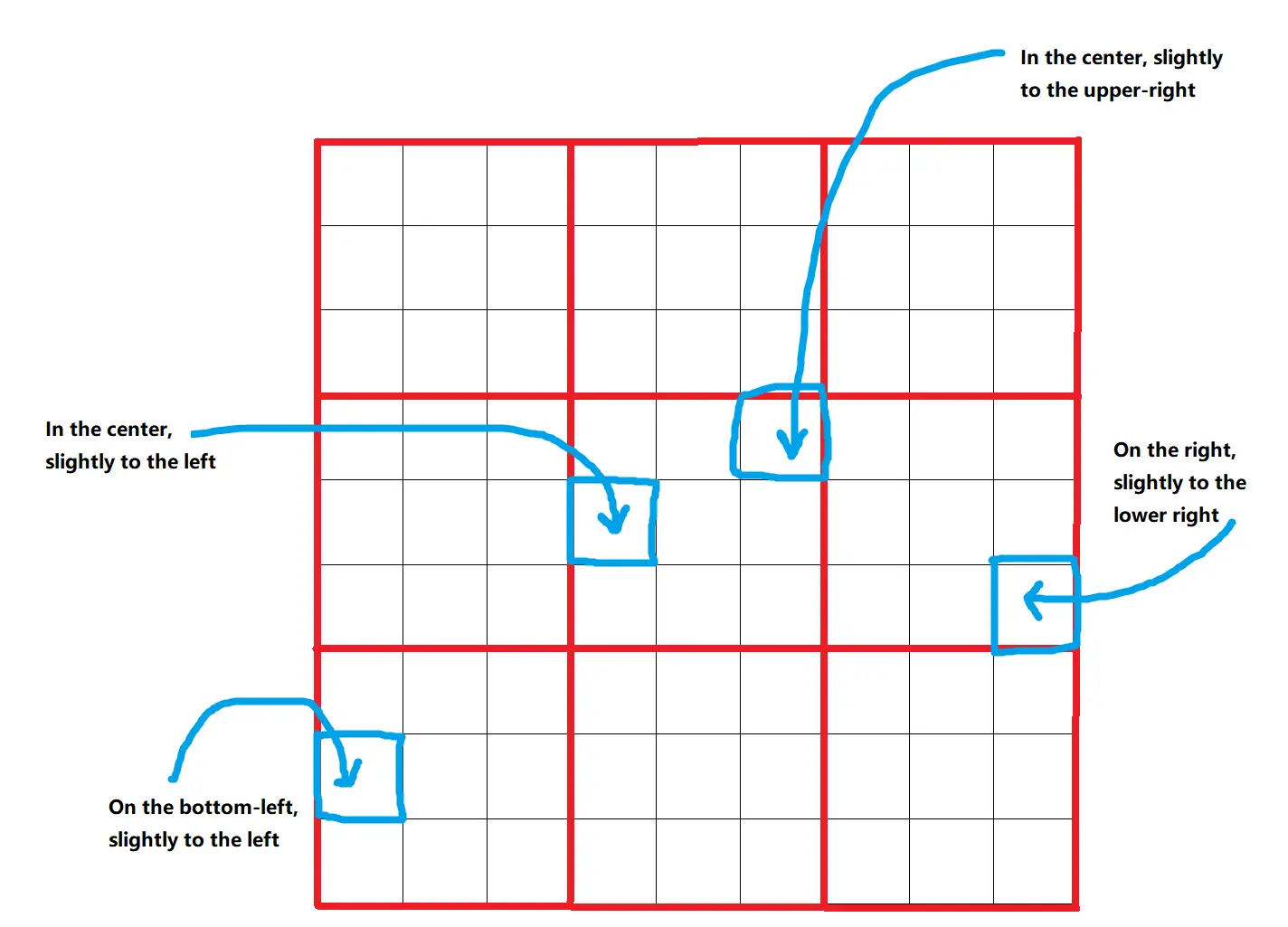
2.2. Profondeur et Couleur#
Les éléments sur le Canvas se voient attribuer un paramètre distance_to_viewer, qui aide à les trier en couches du fond au premier plan. Ce paramètre agit comme un indicateur de profondeur relative, garantissant que les éléments plus proches apparaissent devant ceux qui sont plus éloignés. De plus, le paramètre HTML_web_color_name fournit une représentation grossière des couleurs pour le rendu initial, qui peut être affiné à l'aide de modèles de diffusion. Cette couleur initiale aide à visualiser la composition avant l'affinage.

2.3. Ingénierie de Prompt#
Omost utilise des sous-prompts, qui sont des descriptions brèves et autonomes d'éléments, pour générer des compositions d'images détaillées et cohérentes. Chaque sous-prompt fait moins de 75 tokens et décrit un élément de manière indépendante. Ces sous-prompts sont fusionnés en prompts complets pour que le LLM les traite, garantissant que les images générées sont précises et sémantiquement riches. Cette méthode garantit que l'encodage du texte est efficace et évite les erreurs de troncature sémantique.
2.4. Prompteur Régional#
Omost implémente des techniques avancées de manipulation de l'attention pour gérer les prompts régionaux, garantissant que chaque partie de l'image est générée avec précision en fonction des descriptions fournies. Des techniques telles que la manipulation des scores d'attention garantissent que les activations dans les zones masquées sont encouragées, tandis que celles à l'extérieur sont découragées. Ce contrôle précis de l'attention résulte en une génération d'images de haute qualité, spécifique à la région.
3. Explication Détaillée des Nœuds ComfyUI Omost#
3.1. Nœud de Chargement Omost LLM#
Paramètres d'entrée du Nœud de Chargement Omost LLM#
llm_name: Le nom du modèle LLM pré-entraîné à charger. Les options disponibles incluent:lllyasviel/omost-phi-3-mini-128k-8bitslllyasviel/omost-llama-3-8b-4bitslllyasviel/omost-dolphin-2.9-llama3-8b-4bits
Ce paramètre spécifie quel modèle charger, chacun offrant des capacités et des optimisations différentes.
Paramètres de sortie du Nœud de Chargement Omost LLM#
OMOST_LLM: Le modèle LLM chargé.
Cette sortie fournit le LLM chargé, prêt à générer des descriptions et des compositions d'images.
3.2. Nœud de Chat Omost LLM#
Paramètres d'entrée du Nœud de Chat Omost LLM#
llm: Le modèle LLM chargé par leOmostLLMLoader.text: Le prompt textuel pour générer une image. C'est l'entrée principale où vous décrivez la scène ou les éléments que vous souhaitez générer.max_new_tokens: Nombre maximum de nouveaux tokens à générer. Cela contrôle la longueur du texte généré, un nombre plus élevé permettant des descriptions plus détaillées.top_p: Contrôle la diversité de la sortie générée. Une valeur proche de 1.0 inclut plus de possibilités diverses, tandis qu'une valeur plus basse se concentre sur les résultats les plus probables.temperature: Contrôle l'aléatoirité de la sortie générée. Des valeurs plus élevées entraînent des sorties plus aléatoires, tandis que des valeurs plus basses rendent la sortie plus déterministe.conversation(Facultatif): Contexte de conversation précédent. Cela permet au modèle de continuer à partir des interactions précédentes, en maintenant le contexte et la cohérence.
Paramètres de sortie du Nœud de Chat Omost LLM#
OMOST_CONVERSATION: L'historique des conversations, y compris la nouvelle réponse. Cela aide à suivre le dialogue et à maintenir le contexte au fil des interactions multiples.OMOST_CANVAS_CONDITIONING: Les paramètres de conditionnement du Canvas générés pour le rendu. Ces paramètres définissent comment les éléments sont placés et décrits sur le Canvas.
3.3. Nœud de Conditionnement de Rendu du Canvas Omost#
Paramètres d'entrée du Nœud de Conditionnement de Rendu du Canvas Omost#
canvas_conds: Les paramètres de conditionnement du Canvas. Ces paramètres incluent des descriptions détaillées et des positions des éléments sur le Canvas.
Paramètres de sortie du Nœud de Conditionnement de Rendu du Canvas Omost#
IMAGE: L'image rendue en fonction du conditionnement du Canvas. Cette sortie est la représentation visuelle de la scène décrite, générée à partir des paramètres de conditionnement.
3.4. Nœud de Conditionnement de Mise en Page Omost#
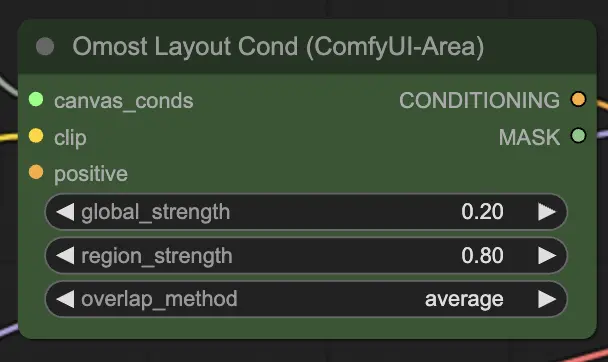
Paramètres d'entrée du Nœud de Conditionnement de Mise en Page Omost#
canvas_conds: Les paramètres de conditionnement du Canvas.clip: Le modèle CLIP pour l'encodage du texte. Ce modèle encode les descriptions textuelles en vecteurs utilisables par le générateur d'images.global_strength: La force du conditionnement global. Cela contrôle à quel point la description générale affecte l'image.region_strength: La force du conditionnement régional. Cela contrôle à quel point les descriptions régionales spécifiques affectent leurs zones respectives.overlap_method: La méthode pour gérer les zones de chevauchement (par exemple,overlay,average). Cela définit comment fusionner les régions qui se chevauchent dans l'image.positive(Facultatif): Conditionnement positif supplémentaire. Cela peut inclure des prompts ou des conditions supplémentaires pour améliorer des aspects spécifiques de l'image.
Paramètres de sortie du Nœud de Conditionnement de Mise en Page Omost#
CONDITIONING: Les paramètres de conditionnement pour la génération d'images. Ces paramètres guident le processus de génération d'images, garantissant que la sortie correspond à la scène décrite.MASK: Le masque utilisé pour le conditionnement. Cela aide à déboguer et à appliquer des conditions supplémentaires à des régions spécifiques.
3.5. Nœud de Chargement de Conditionnement du Canvas Omost#
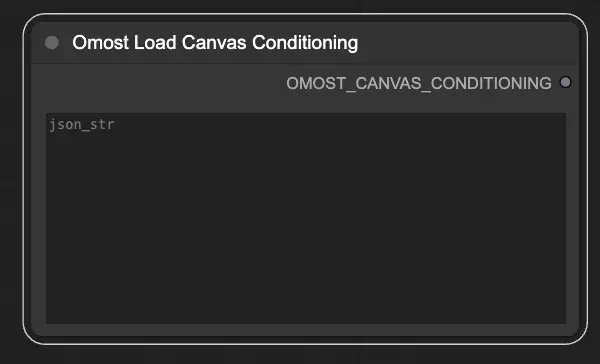
Paramètres d'entrée du Nœud de Chargement de Conditionnement du Canvas Omost#
json_str: La chaîne JSON représentant les paramètres de conditionnement du Canvas. Cela permet de charger des conditions prédéfinies à partir d'un fichier JSON.
Paramètres de sortie du Nœud de Chargement de Conditionnement du Canvas Omost#
OMOST_CANVAS_CONDITIONING: Les paramètres de conditionnement du Canvas chargés. Ces paramètres initialisent le Canvas avec des conditions spécifiques, prêt pour la génération d'images.

