SDXL Turbo | Du Texte à l'Image Rapidement
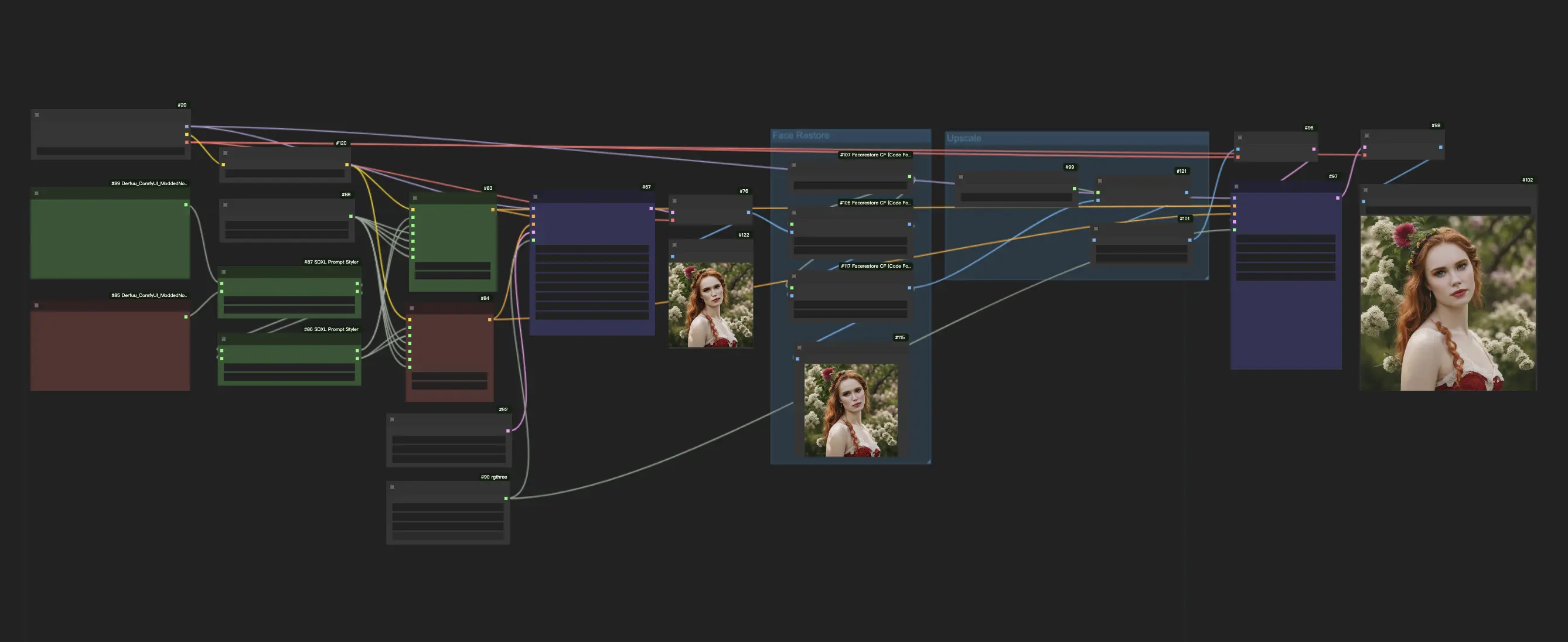
Ce workflow ComfyUI utilise le modèle SDXL Turbo pour offrir un processus rapide de génération d'images à partir de texte, nécessitant seulement 1 à 4 étapes. Pour améliorer la stabilité et obtenir de meilleurs résultats, il intègre également un modèle de restauration des visages et un modèle d'upscaling.Flux de travail ComfyUI SDXL Turbo
- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
Exemples ComfyUI SDXL Turbo

Description ComfyUI SDXL Turbo
1. Workflow ComfyUI SDXL Turbo
SDXL Turbo synthétise des images en une seule étape et génère des sorties de texte en image en temps réel. La qualité de SDXL Turbo est relativement bonne, bien qu'elle ne soit pas toujours stable. Pour améliorer les résultats, il est recommandé d'incorporer un modèle de restauration des visages et un modèle d'upscaling pour ceux qui recherchent des résultats de plus haute qualité.
2. Aperçu de SDXL Turbo
SDXL Turbo est un modèle génératif de texte en image qui convertit efficacement les prompts textuels en images photoréalistes en une seule évaluation de réseau. En utilisant une technique appelée Adversarial Diffusion Distillation (ADD), développée par Stability AI, il réduit considérablement le processus de synthèse d'image à 1 à 4 étapes, bien moins que les 50 étapes traditionnellement requises par les modèles précédents. Ce modèle, une avancée par rapport à SDXL 1.0, utilise ADD pour fusionner la distillation de score avec une perte adversariale, optimisant l'utilisation des modèles de diffusion d'image existants pour une qualité supérieure avec moins d'étapes d'échantillonnage. L'introduction de cette technique de distillation préserve non seulement la qualité de l'image, mais réduit également de manière significative l'effort de calcul nécessaire pour la génération d'images.
3. Limites de SDXL Turbo
Malgré ses capacités avancées, SDXL Turbo a certaines limites. Il génère des images à une résolution fixe de 512x512 pixels et peut avoir du mal à rendre du texte lisible, à représenter avec précision les visages et les personnes, et à atteindre un photoréalisme parfait. Ces contraintes soulignent l'utilisation prévue du modèle pour la recherche et l'exploration plutôt que pour des représentations factuelles ou précises d'entités du monde réel.






