



Bonjour, artistes AI ! 👋 Bienvenue dans notre tutoriel convivial pour les débutants sur ComfyUI, un outil incroyablement puissant et flexible pour créer de magnifiques œuvres d'art générées par l'IA. 🎨 Dans ce guide, nous vous guiderons à travers les bases de ComfyUI, explorerons ses fonctionnalités et vous aiderons à libérer son potentiel pour amener votre art AI au niveau supérieur. 🚀
Nous couvrirons :
1. Qu'est-ce que ComfyUI ?
- 1.1. ComfyUI vs AUTOMATIC1111
- 1.2. Par où commencer avec ComfyUI ?
- 1.3. Contrôles de base
2. Workflows ComfyUI : Texte-à-Image
- 2.1. Sélection d'un modèle
- 2.2. Saisie de l'invite positive et de l'invite négative
- 2.3. Génération d'une image
- 2.4. Explication technique de ComfyUI
- 2.4.1 Nœud Load Checkpoint
- 2.4.2. CLIP Text Encode
- 2.4.3. Empty Latent Image
- 2.4.4. VAE
- 2.4.5. KSampler
3. Workflow ComfyUI : Image-à-Image
4. ComfyUI SDXL
5. Inpainting ComfyUI
6. Outpainting ComfyUI
7. Upscale ComfyUI
- 7.1. Upscale Pixel
- 7.1.1. Upscale Pixel par algorithme
- 7.1.2. Upscale Pixel par modèle
- 7.2. Upscale Latent
- 7.3. Upscale Pixel vs Upscale Latent
8. ComfyUI ControlNet
9. ComfyUI Manager
- 9.1. Comment installer les nœuds personnalisés manquants
- 9.2. Comment mettre à jour les nœuds personnalisés
- 9.3. Comment charger des nœuds personnalisés dans votre workflow
10. Embeddings ComfyUI
- 10.1. Embedding avec autocomplétion
- 10.2. Poids d'Embedding
11. ComfyUI LoRA
- 11.1. Workflows LoRA simples
- 11.2. LoRAs multiples
12. Raccourcis et astuces pour ComfyUI
- 12.1. Copier et coller
- 12.2. Déplacement de plusieurs nœuds
- 12.3. Contourner un nœud
- 12.4. Minimiser un nœud
- 12.5. Générer une image
- 12.6. Workflow intégré
- 12.7. Fixer les seeds pour gagner du temps
13. ComfyUI en ligne
1. Qu'est-ce que ComfyUI ? 🤔
ComfyUI, c'est comme avoir une baguette magique 🪄 pour créer facilement de superbes œuvres d'art générées par l'IA. À la base, ComfyUI est une interface utilisateur graphique (GUI) basée sur des nœuds construite au-dessus de Stable Diffusion, un modèle d'apprentissage profond à la pointe de la technologie qui génère des images à partir de descriptions textuelles. 🌟 Mais ce qui rend ComfyUI vraiment spécial, c'est la façon dont il permet aux artistes comme vous de libérer votre créativité et de donner vie à vos idées les plus folles.
Imaginez un canevas numérique où vous pouvez construire vos propres workflows uniques de génération d'images en connectant différents nœuds, chacun représentant une fonction ou une opération spécifique. 🧩 C'est comme bâtir une recette visuelle pour vos chefs-d'œuvre générés par l'IA !
Vous voulez générer une image à partir de zéro en utilisant une invite textuelle ? Il y a un nœud pour ça ! Vous devez appliquer un échantillonneur spécifique ou ajuster le niveau de bruit ? Ajoutez simplement les nœuds correspondants et regardez la magie opérer. ✨
Mais voici la meilleure partie : ComfyUI décompose le workflow en éléments réarrangeables, vous donnant la liberté de créer vos propres workflows personnalisés adaptés à votre vision artistique. 🖼️ C'est comme avoir une boîte à outils personnalisée qui s'adapte à votre processus créatif.
1.1. ComfyUI vs AUTOMATIC1111 🆚
AUTOMATIC1111 est l'interface graphique par défaut pour Stable Diffusion. Alors, devriez-vous utiliser ComfyUI à la place ? Comparons :
✅ Avantages de l'utilisation de ComfyUI :
- Léger : Il fonctionne rapidement et efficacement.
- Flexible : Hautement configurable pour répondre à vos besoins.
- Transparent : Le flux de données est visible et facile à comprendre.
- Facile à partager : Chaque fichier représente un workflow reproductible.
- Bon pour le prototypage : Créez des prototypes avec une interface graphique au lieu de coder.
❌ Inconvénients de l'utilisation de ComfyUI :
- Interface incohérente : Chaque workflow peut avoir une disposition de nœuds différente.
- Trop de détails : Les utilisateurs moyens peuvent ne pas avoir besoin de connaître les connexions sous-jacentes.
1.2. Par où commencer avec ComfyUI ? 🏁
Nous pensons que la meilleure façon d'apprendre ComfyUI est de se plonger dans des exemples et d'en faire l'expérience directement. 🙌 C'est pourquoi nous avons créé ce tutoriel unique qui se distingue des autres. Dans ce tutoriel, vous trouverez un guide détaillé étape par étape que vous pourrez suivre.
Mais voici la meilleure partie : 🌟 Nous avons intégré ComfyUI directement dans cette page web ! Vous pourrez interagir avec des exemples ComfyUI en temps réel tout au long du guide.🌟 Plongeons-nous dedans !
2. Workflows ComfyUI : Texte-à-Image 🖼️
Commençons par le cas le plus simple : générer une image à partir d'un texte. Cliquez sur Queue Prompt pour exécuter le workflow. Après une courte attente, vous devriez voir votre première image générée ! Pour vérifier votre file d'attente, cliquez simplement sur View Queue.
Voici un workflow texte-à-image par défaut à essayer :
Blocs de construction de base 🕹️
Le workflow ComfyUI se compose de deux blocs de construction de base : les nœuds et les arêtes.
- Les nœuds sont les blocs rectangulaires, par exemple Load Checkpoint, Clip Text Encoder, etc. Chaque nœud exécute un code spécifique et nécessite des entrées, des sorties et des paramètres.
- Les arêtes sont les fils reliant les sorties et les entrées entre les nœuds.
Contrôles de base 🕹️
- Zoomez et dézoomez à l'aide de la molette de la souris ou du pincement à deux doigts.
- Faites glisser et maintenez le point d'entrée ou de sortie pour créer des connexions entre les nœuds.
- Déplacez-vous dans l'espace de travail en maintenant et en faisant glisser le bouton gauche de la souris.
Plongeons dans les détails de ce workflow.
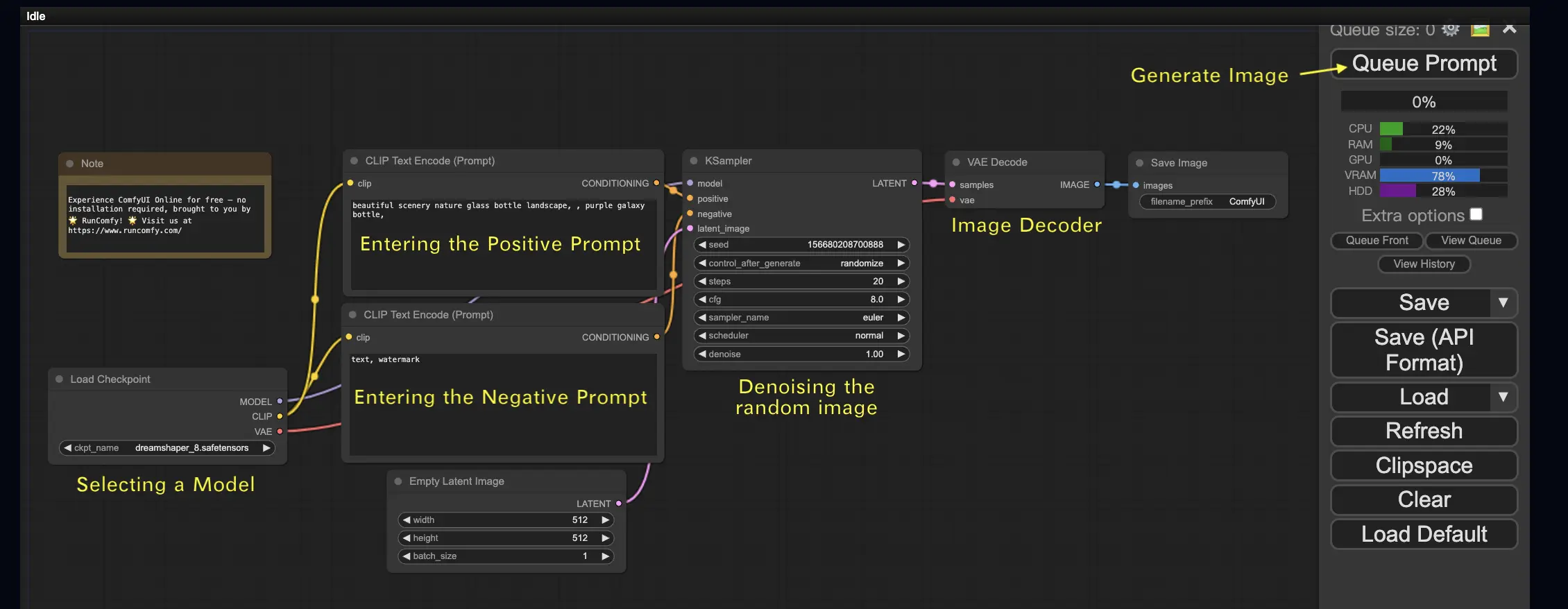
2.1. Sélection d'un modèle 🗃️
Tout d'abord, sélectionnez un modèle Stable Diffusion Checkpoint dans le nœud Load Checkpoint. Cliquez sur le nom du modèle pour voir les modèles disponibles. Si cliquer sur le nom du modèle ne fait rien, vous devrez peut-être télécharger un modèle personnalisé.
2.2. Saisie de l'invite positive et de l'invite négative 📝
Vous verrez deux nœuds étiquetés CLIP Text Encode (Prompt). L'invite du haut est connectée à l'entrée positive du nœud KSampler, tandis que l'invite du bas est connectée à l'entrée négative. Entrez donc votre invite positive dans celle du haut et votre invite négative dans celle du bas.
Le nœud CLIP Text Encode convertit l'invite en jetons et les encode en embeddings à l'aide de l'encodeur de texte.
💡 Astuce : Utilisez la syntaxe (mot-clé:poids) pour contrôler le poids d'un mot-clé, par exemple, (mot-clé:1.2) pour augmenter son effet ou (mot-clé:0.8) pour le diminuer.
2.3. Génération d'une image 🎨
Cliquez sur Queue Prompt pour exécuter le workflow. Après une courte attente, votre première image sera générée !
2.4. Explication technique de ComfyUI 🤓
La puissance de ComfyUI réside dans sa configurabilité. Comprendre ce que fait chaque nœud vous permet de les adapter à vos besoins. Mais avant de plonger dans les détails, jetons un coup d'œil au processus Stable Diffusion pour mieux comprendre le fonctionnement de ComfyUI.
Le processus Stable Diffusion peut être résumé en trois étapes principales :
- Encodage du texte : L'invite saisie par l'utilisateur est compilée en vecteurs de caractéristiques de mots individuels par un composant appelé Text Encoder. Cette étape convertit le texte dans un format que le modèle peut comprendre et avec lequel il peut travailler.
- Transformation de l'espace latent : Les vecteurs de caractéristiques de l'encodeur de texte et une image de bruit aléatoire sont transformés dans un espace latent. Dans cet espace, l'image aléatoire subit un processus de débruitage basé sur les vecteurs de caractéristiques, aboutissant à un produit intermédiaire. C'est à cette étape que la magie opère, car le modèle apprend à associer les caractéristiques du texte à des représentations visuelles.
- Décodage d'image : Enfin, le produit intermédiaire de l'espace latent est décodé par le décodeur d'image, le convertissant en une image réelle que nous pouvons voir et apprécier.
Maintenant que nous avons une compréhension de haut niveau du processus Stable Diffusion, plongeons dans les composants et nœuds clés de ComfyUI qui rendent ce processus possible.
2.4.1 Nœud Load Checkpoint 🗃️
Le nœud Load Checkpoint dans ComfyUI est crucial pour sélectionner un modèle Stable Diffusion. Un modèle Stable Diffusion se compose de trois composants principaux : MODEL, CLIP et VAE. Explorons chaque composant et sa relation avec les nœuds correspondants dans ComfyUI.
- MODEL : Le composant MODEL est le modèle de prédiction de bruit qui fonctionne dans l'espace latent. Il est responsable du processus central de génération d'images à partir de la représentation latente. Dans ComfyUI, la sortie MODEL du nœud Load Checkpoint se connecte au nœud KSampler, où se déroule le processus de diffusion inverse. Le nœud KSampler utilise le MODEL pour débruiter itérativement la représentation latente, raffinant progressivement l'image jusqu'à ce qu'elle corresponde à l'invite souhaitée.
- CLIP : CLIP (Contrastive Language-Image Pre-training) est un modèle de langage qui prétraite les invites positives et négatives fournies par l'utilisateur. Il convertit les invites textuelles dans un format que le MODEL peut comprendre et utiliser pour guider le processus de génération d'images. Dans ComfyUI, la sortie CLIP du nœud Load Checkpoint se connecte au nœud CLIP Text Encode. Le nœud CLIP Text Encode prend les invites fournies par l'utilisateur et les transmet au modèle de langage CLIP, transformant chaque mot en embeddings. Ces embeddings capturent le sens sémantique des mots et permettent au MODEL de générer des images alignées sur les invites données.
- VAE : VAE (Variational AutoEncoder) est responsable de la conversion de l'image entre l'espace pixel et l'espace latent. Il se compose d'un encodeur qui compresse l'image en une représentation latente de dimension inférieure et d'un décodeur qui reconstruit l'image à partir de la représentation latente. Dans le processus texte-à-image, le VAE n'est utilisé que dans l'étape finale pour convertir l'image générée de l'espace latent vers l'espace pixel. Le nœud VAE Decode dans ComfyUI prend la sortie du nœud KSampler (qui fonctionne dans l'espace latent) et utilise la partie décodeur du VAE pour transformer la représentation latente en l'image finale dans l'espace pixel.
Il est important de noter que le VAE est un composant distinct du modèle de langage CLIP. Alors que CLIP se concentre sur le traitement des invites textuelles, le VAE s'occupe de la conversion entre les espaces pixel et latent.
2.4.2. CLIP Text Encode 📝
Le nœud CLIP Text Encode dans ComfyUI est responsable de la prise des invites fournies par l'utilisateur et de leur transmission au modèle de langage CLIP. CLIP est un puissant modèle de langage qui comprend le sens sémantique des mots et peut les associer à des concepts visuels. Lorsqu'une invite est saisie dans le nœud CLIP Text Encode, elle subit un processus de transformation où chaque mot est converti en embeddings. Ces embeddings sont des vecteurs de haute dimension qui capturent les informations sémantiques des mots. En transformant les invites en embeddings, CLIP permet au MODEL de générer des images qui reflètent fidèlement le sens et l'intention des invites données.
2.4.3. Empty Latent Image 🌌
Dans le processus texte-à-image, la génération commence par une image aléatoire dans l'espace latent. Cette image aléatoire sert d'état initial avec lequel le MODEL travaille. La taille de l'image latente est proportionnelle à la taille réelle de l'image dans l'espace pixel. Dans ComfyUI, vous pouvez ajuster la hauteur et la largeur de l'image latente pour contrôler la taille de l'image générée. De plus, vous pouvez définir la taille du batch pour déterminer le nombre d'images générées à chaque exécution.
Les tailles optimales pour les images latentes dépendent du modèle Stable Diffusion spécifique utilisé. Pour les modèles SD v1.5, les tailles recommandées sont 512x512 ou 768x768, tandis que pour les modèles SDXL, la taille optimale est 1024x1024. ComfyUI offre une gamme de formats d'image courants parmi lesquels choisir, tels que 1:1 (carré), 3:2 (paysage), 2:3 (portrait), 4:3 (paysage), 3:4 (portrait), 16:9 (écran large) et 9:16 (vertical). Il est important de noter que la largeur et la hauteur de l'image latente doivent être divisibles par 8 pour assurer la compatibilité avec l'architecture du modèle.
2.4.4. VAE 🔍
Le VAE (Variational AutoEncoder) est un composant crucial dans le modèle Stable Diffusion qui gère la conversion des images entre l'espace pixel et l'espace latent. Il se compose de deux parties principales : un encodeur d'image et un décodeur d'image.
L'encodeur d'image prend une image dans l'espace pixel et la compresse en une représentation latente de dimension inférieure. Ce processus de compression réduit considérablement la taille des données, permettant un traitement et un stockage plus efficaces. Par exemple, une image de taille 512x512 pixels peut être compressée en une représentation latente de taille 64x64.
D'autre part, le décodeur d'image, également appelé décodeur VAE, est responsable de la reconstruction de l'image à partir de la représentation latente dans l'espace pixel. Il prend la représentation latente compressée et l'étend pour générer l'image finale.
L'utilisation d'un VAE offre plusieurs avantages :
- Efficacité : En compressant l'image dans un espace latent de dimension inférieure, le VAE permet une génération plus rapide et des temps d'entraînement plus courts. La taille réduite des données permet un traitement et une utilisation de la mémoire plus efficaces.
- Manipulation de l'espace latent : L'espace latent fournit une représentation plus compacte et significative de l'image. Cela permet un contrôle et une édition plus précis des détails et du style de l'image. En manipulant la représentation latente, il devient possible de modifier des aspects spécifiques de l'image générée.
Cependant, il y a aussi quelques inconvénients à prendre en compte :
- Perte de données : Pendant le processus d'encodage et de décodage, certains détails de l'image originale peuvent être perdus. Les étapes de compression et de reconstruction peuvent introduire des artefacts ou de légères variations dans l'image finale par rapport à l'original.
- Capture limitée des données originales : L'espace latent de dimension inférieure peut ne pas être en mesure de capturer pleinement toutes les caractéristiques et détails complexes de l'image originale. Certaines informations peuvent être perdues lors du processus de compression, ce qui entraîne une représentation légèrement moins précise des données originales.
Malgré ces limitations, le VAE joue un rôle essentiel dans le modèle Stable Diffusion en permettant une conversion efficace entre l'espace pixel et l'espace latent, facilitant une génération plus rapide et un contrôle plus précis sur les images générées.
2.4.5. KSampler ⚙️
Le nœud KSampler dans ComfyUI est au cœur du processus de génération d'images dans Stable Diffusion. Il est responsable du débruitage de l'image aléatoire dans l'espace latent pour correspondre à l'invite fournie par l'utilisateur. Le KSampler utilise une technique appelée diffusion inverse, où il affine itérativement la représentation latente en supprimant le bruit et en ajoutant des détails significatifs basés sur les indications des embeddings CLIP.
Le nœud KSampler offre plusieurs paramètres qui permettent aux utilisateurs d'affiner le processus de génération d'images :
Seed : La valeur de la seed contrôle le bruit initial et la composition de l'image finale. En définissant une seed spécifique, les utilisateurs peuvent obtenir des résultats reproductibles et maintenir la cohérence entre plusieurs générations.
Control_after_generation : Ce paramètre détermine comment la valeur de la seed change après chaque génération. Il peut être réglé sur randomize (générer une nouvelle seed aléatoire pour chaque exécution), increment (augmenter la valeur de la seed de 1), decrement (diminuer la valeur de la seed de 1) ou fixed (garder la valeur de la seed constante).
Step : Le nombre d'étapes d'échantillonnage détermine l'intensité du processus de raffinement. Des valeurs plus élevées entraînent moins d'artefacts et des images plus détaillées, mais augmentent également le temps de génération.
Sampler_name : Ce paramètre permet aux utilisateurs de choisir l'algorithme d'échantillonnage spécifique utilisé par le KSampler. Différents algorithmes d'échantillonnage peuvent donner des résultats légèrement différents et avoir des vitesses de génération variables.
Scheduler : Le scheduler contrôle la façon dont le niveau de bruit change à chaque étape du processus de débruitage. Il détermine le taux auquel le bruit est supprimé de la représentation latente.
Denoise : Le paramètre denoise définit la quantité de bruit initial qui doit être effacée par le processus de débruitage. Une valeur de 1 signifie que tout le bruit sera supprimé, donnant une image propre et détaillée.
En ajustant ces paramètres, vous pouvez affiner le processus de génération d'images pour obtenir les résultats souhaités.
Maintenant, êtes-vous prêt à vous lancer dans votre voyage ComfyUI ?
Chez RunComfy, nous avons créé l'expérience ComfyUI en ligne ultime rien que pour vous. Dites adieu aux installations compliquées ! 🎉 Essayez ComfyUI Online maintenant et libérez votre potentiel artistique comme jamais auparavant ! 🎉
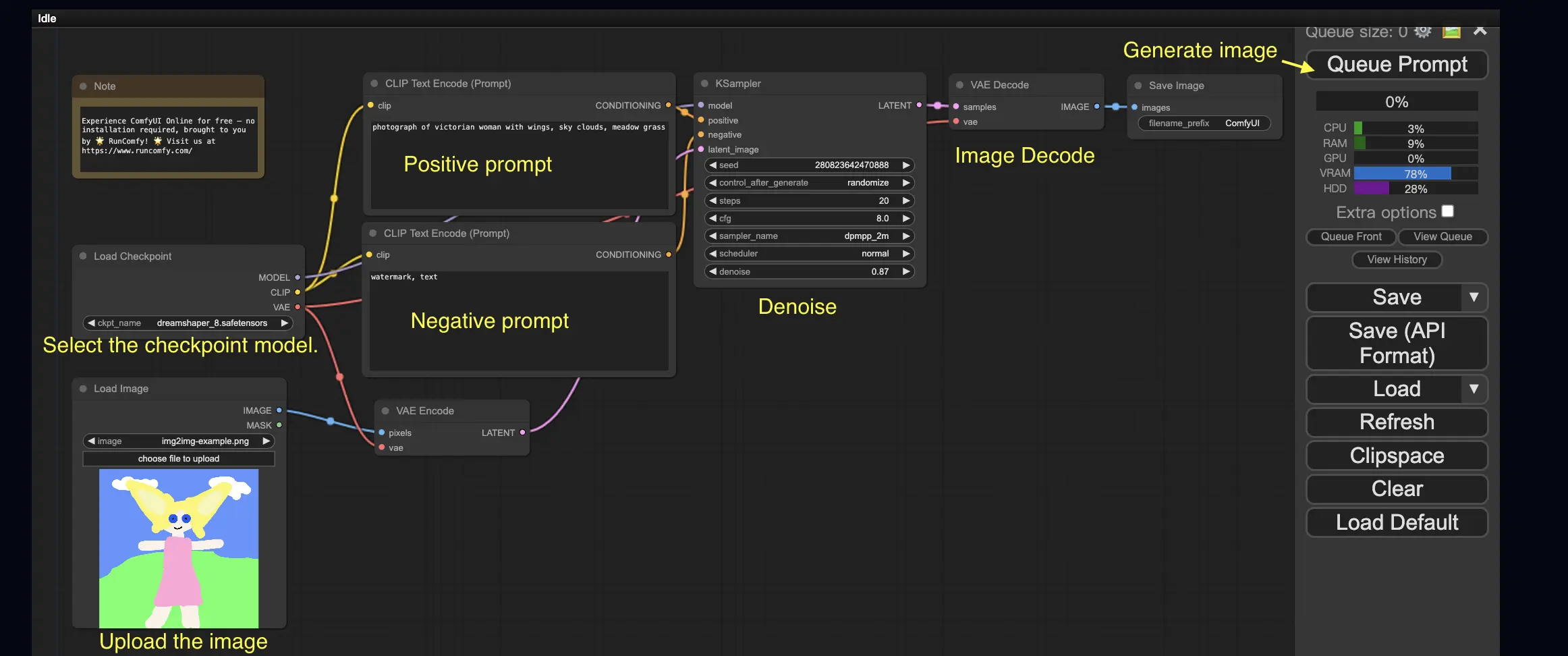
3. Workflow ComfyUI : Image-à-Image 🖼️
Le workflow Image-à-Image génère une image basée sur une invite et une image d'entrée. Essayez-le vous-même !
Pour utiliser le workflow Image-à-Image :
- Sélectionnez le modèle checkpoint.
- Téléchargez l'image comme invite d'image.
- Révisez les invites positives et négatives.
- Ajustez éventuellement le denoise (force de débruitage) dans le nœud KSampler.
- Appuyez sur Queue Prompt pour lancer la génération.
Pour plus de workflows ComfyUI premium, visitez notre 🌟Liste des workflows ComfyUI🌟
4. ComfyUI SDXL 🚀
Grâce à son extrême configurabilité, ComfyUI est l'une des premières interfaces graphiques à prendre en charge le modèle Stable Diffusion XL. Essayons-le !
Pour utiliser le workflow ComfyUI SDXL :
- Révisez les invites positives et négatives.
- Appuyez sur Queue Prompt pour lancer la génération.
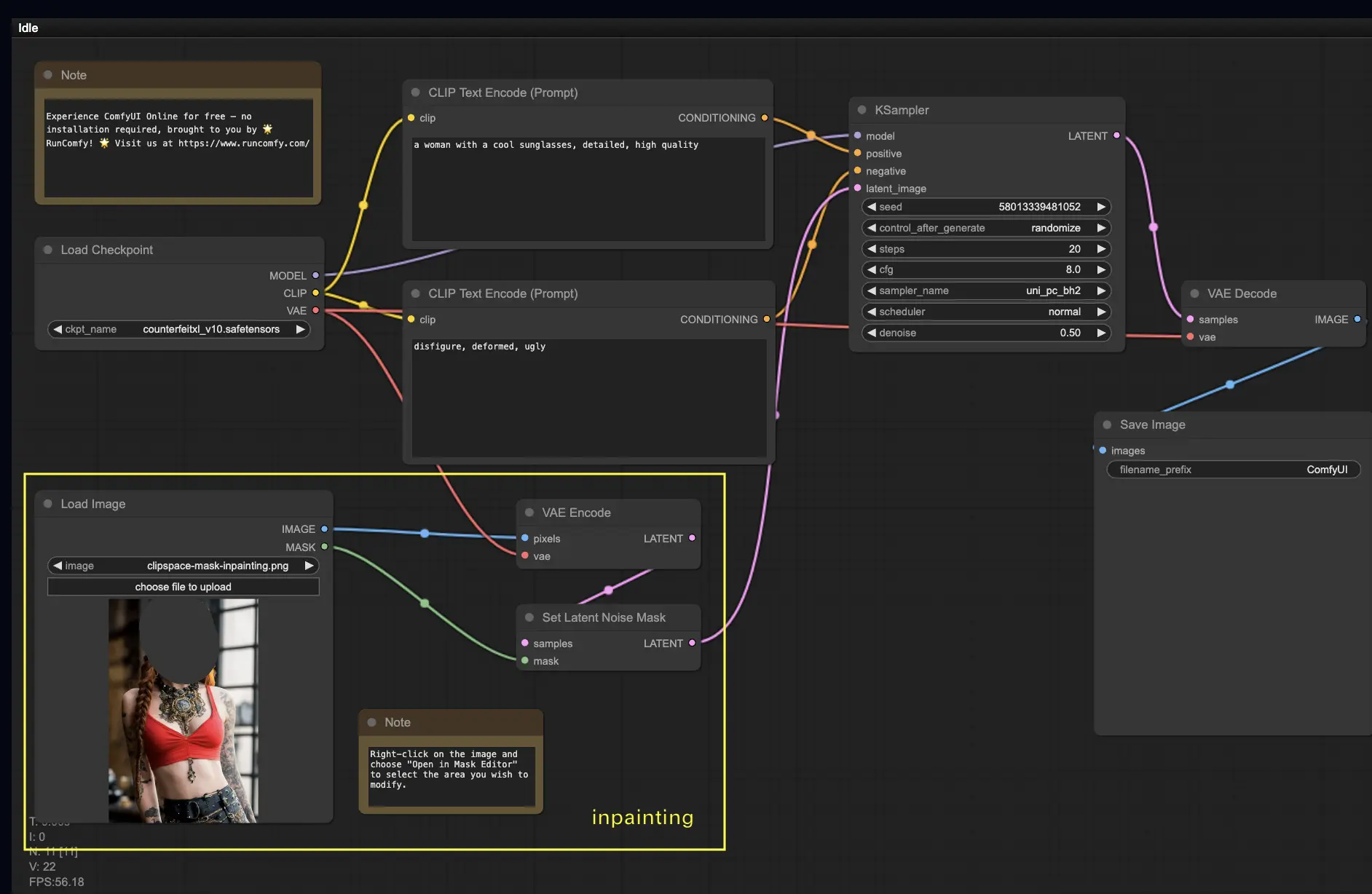
5. Inpainting ComfyUI 🎨
Plongeons dans quelque chose de plus complexe : l'inpainting ! Lorsque vous avez une superbe image mais que vous souhaitez modifier des parties spécifiques, l'inpainting est la meilleure méthode. Essayez-le ici !
Pour utiliser le workflow d'inpainting :
- Téléchargez une image que vous souhaitez inpainter.
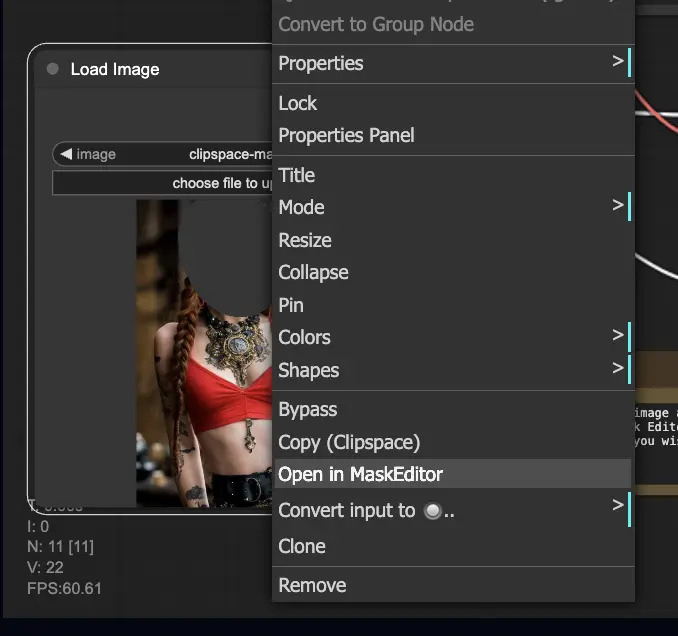
- Faites un clic droit sur l'image et sélectionnez "Open in MaskEditor". Masquez la zone à régénérer, puis cliquez sur "Save to node".
- Sélectionnez un modèle Checkpoint :
- Ce workflow ne fonctionne qu'avec un modèle Stable Diffusion standard, pas avec un modèle Inpainting.
- Si vous voulez utiliser un modèle d'inpainting, veuillez changer les nœuds "VAE Encode" et "Set Noise Latent Mask" pour le nœud "VAE Encode (Inpaint)", spécialement conçu pour les modèles d'inpainting.
- Personnalisez le processus d'inpainting :
- Dans le nœud CLIP Text Encode (Prompt), vous pouvez saisir des informations supplémentaires pour guider l'inpainting. Par exemple, vous pouvez spécifier le style, le thème ou les éléments que vous souhaitez inclure dans la zone d'inpainting.
- Définissez la force de débruitage d'origine (denoise), par exemple, 0.6.
- Appuyez sur Queue Prompt pour effectuer l'inpainting.
6. Outpainting ComfyUI 🖌️
L'outpainting est une autre technique passionnante qui vous permet d'étendre vos images au-delà de leurs limites d'origine. 🌆 C'est comme avoir une toile infinie sur laquelle travailler !
Pour utiliser le workflow Outpainting ComfyUI :
- Commencez avec une image que vous souhaitez étendre.
- Utilisez le nœud Pad Image for Outpainting dans votre workflow.
- Configurez les paramètres d'outpainting :
- left, top, right, bottom : Spécifiez le nombre de pixels à étendre dans chaque direction.
- feathering : Ajustez la douceur de la transition entre l'image d'origine et la zone d'outpainting. Des valeurs plus élevées créent un mélange plus progressif mais peuvent introduire un effet de flou.
- Personnalisez le processus d'outpainting :
- Dans le nœud CLIP Text Encode (Prompt), vous pouvez saisir des informations supplémentaires pour guider l'outpainting. Par exemple, vous pouvez spécifier le style, le thème ou les éléments que vous souhaitez inclure dans la zone étendue.
- Expérimentez avec différentes invites pour obtenir les résultats souhaités.
- Ajustez le nœud VAE Encode (pour Inpainting) :
- Ajustez le paramètre grow_mask_by pour contrôler la taille du masque d'outpainting. Une valeur supérieure à 10 est recommandée pour des résultats optimaux.
- Appuyez sur Queue Prompt pour lancer le processus d'outpainting.
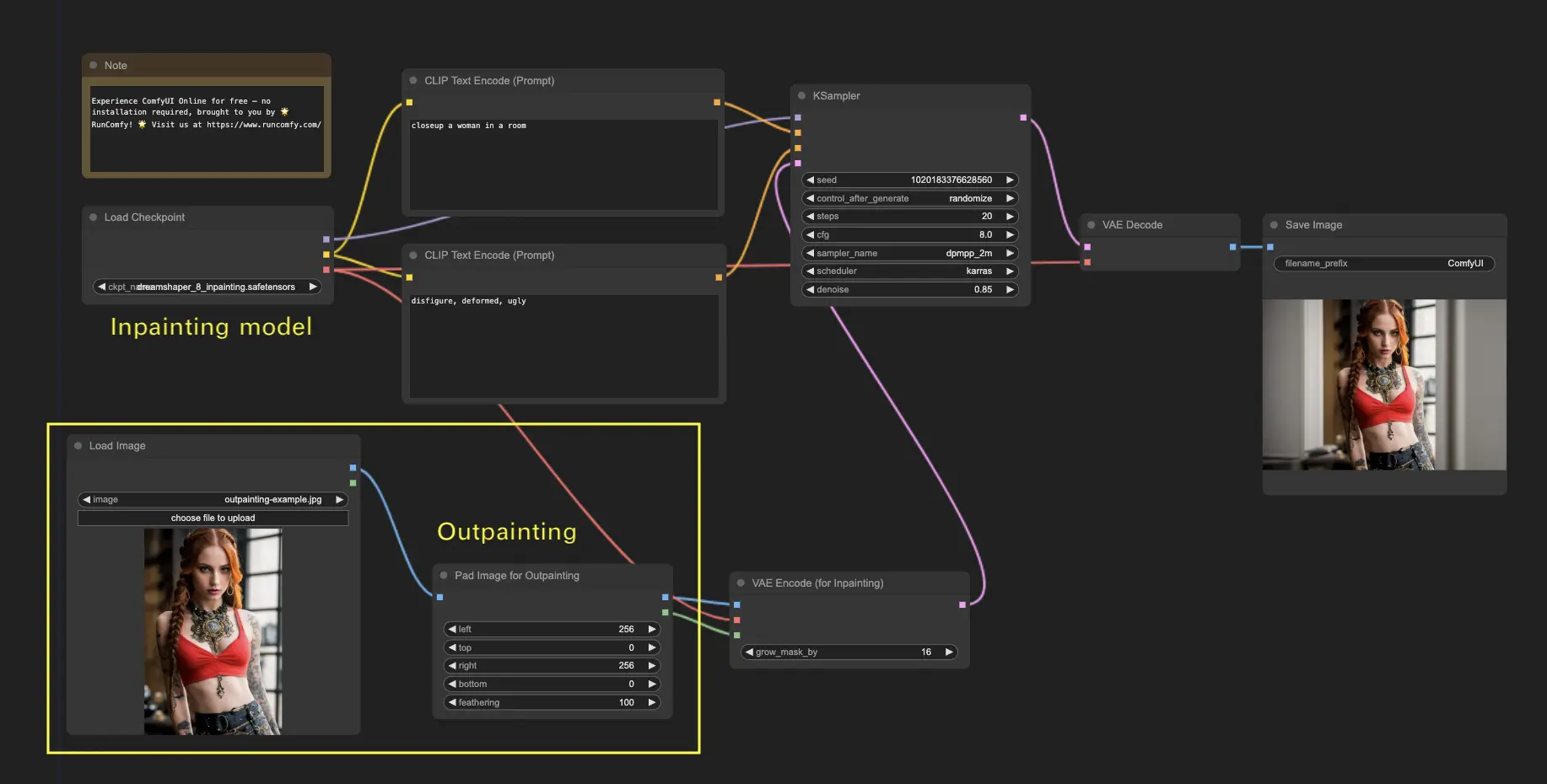
Pour plus de workflows premium d'inpainting/outpainting, visitez notre 🌟Liste des workflows ComfyUI🌟
7. Upscale ComfyUI ⬆️
Ensuite, explorons l'upscale ComfyUI. Nous allons introduire trois workflows fondamentaux pour vous aider à upscaler efficacement.
Il existe deux méthodes principales pour l'upscale :
- Upscale Pixel : Upscale directement l'image visible.
- Entrée : image, Sortie : image upscalée
- Upscale Latent : Upscale l'image invisible de l'espace latent.
- Entrée : latent, Sortie : latent upscalé (nécessite un décodage pour devenir une image visible)
7.1. Upscale Pixel 🖼️
Deux façons d'y parvenir :
- En utilisant des algorithmes : Vitesse de génération la plus rapide, mais résultats légèrement inférieurs par rapport aux modèles.
- En utilisant des modèles : Meilleurs résultats, mais temps de génération plus lent.
7.1.1. Upscale Pixel par algorithme 🧮
- Ajoutez le nœud Upscale Image by.
- Paramètre method : Choisissez l'algorithme d'upscale (bicubic, bilinear, nearest-exact).
- Paramètre Scale : Spécifiez le facteur d'upscale (ex : 2 pour 2x).
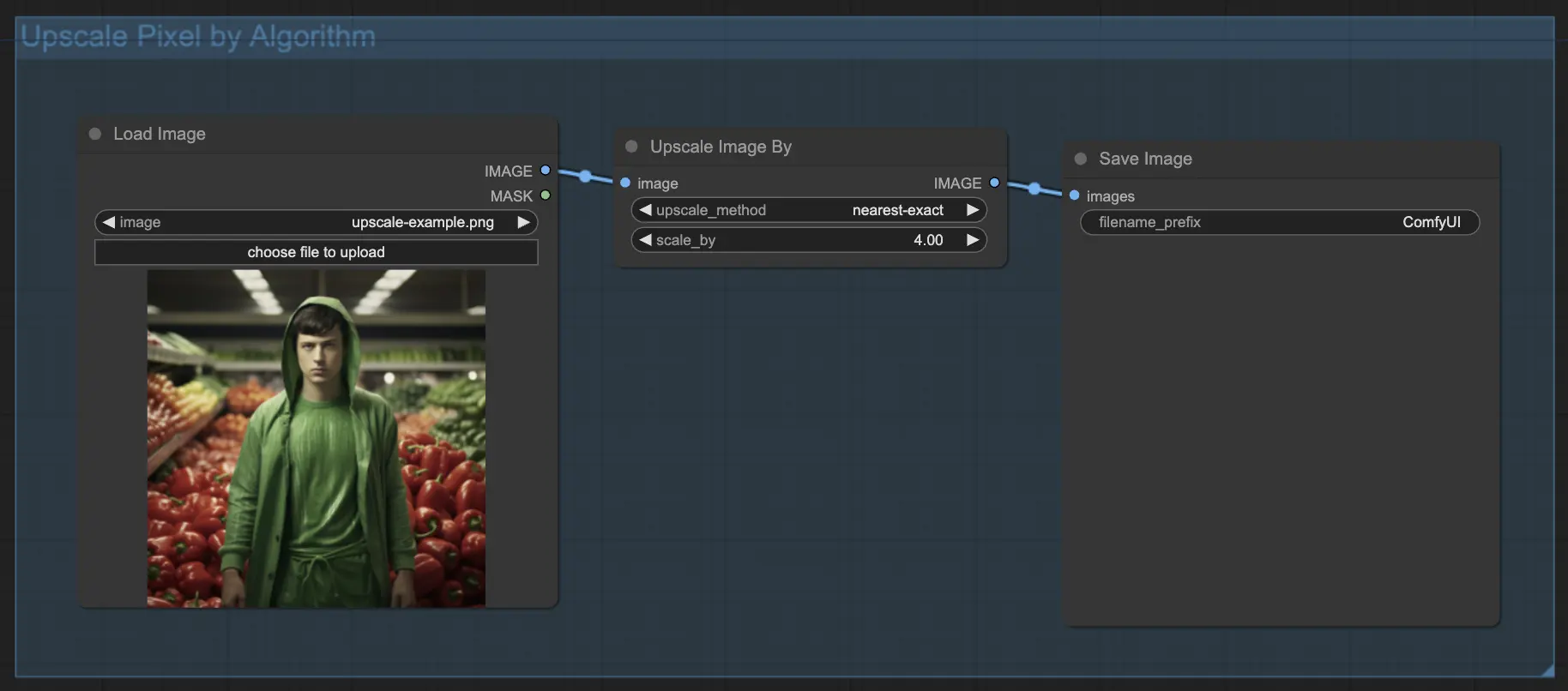
7.1.2. Upscale Pixel par modèle 🤖
- Ajoutez le nœud Upscale Image (using Model).
- Ajoutez le nœud Load Upscale Model.
- Choisissez un modèle adapté à votre type d'image (ex : anime ou réel).
- Sélectionnez le facteur d'upscale (X2 ou X4).
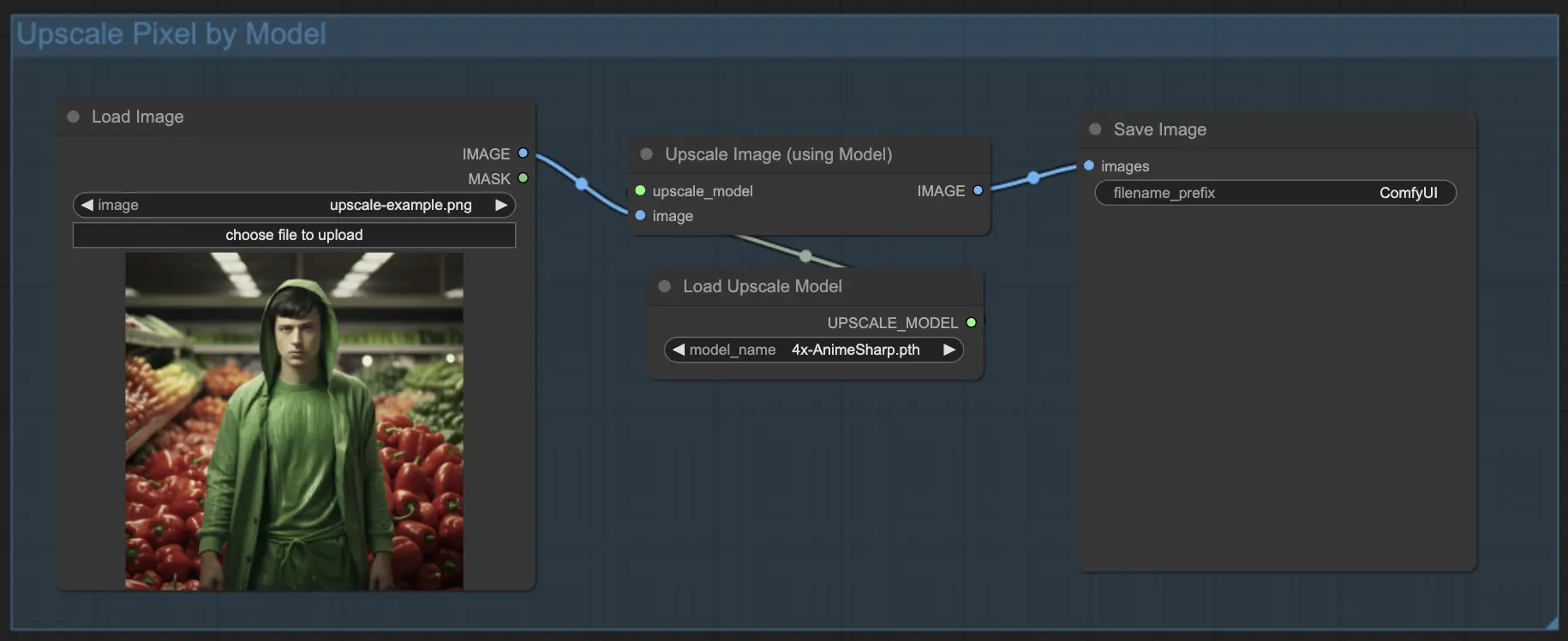
7.2. Upscale Latent ⚙️
Une autre méthode d'upscale est Upscale Latent, également connue sous le nom de Hi-res Latent Fix Upscale, qui upscale directement dans l'espace latent.
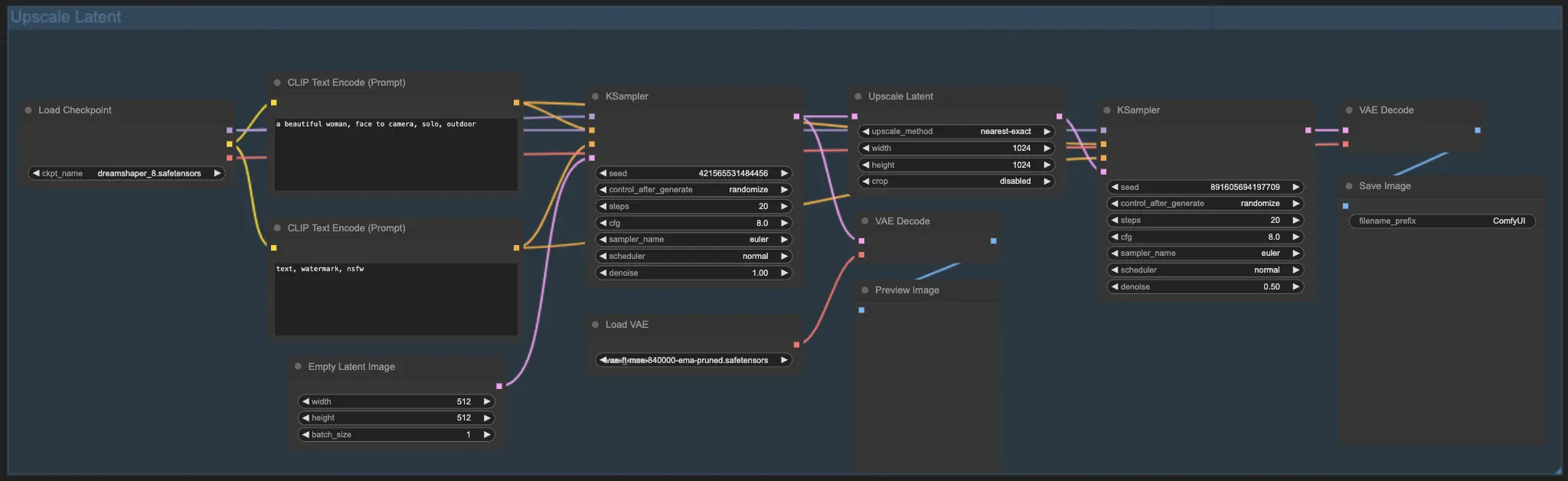
7.3. Upscale Pixel vs Upscale Latent 🆚
- Upscale Pixel : Agrandit simplement l'image sans ajouter de nouvelles informations. Génération plus rapide, mais peut avoir un effet de flou et manquer de détails.
- Upscale Latent : En plus d'agrandir, il change certaines informations de l'image d'origine, enrichissant les détails. Peut s'écarter de l'image d'origine et a une vitesse de génération plus lente.
Pour plus de workflows premium de restauration/upscale, visitez notre 🌟Liste des workflows ComfyUI🌟
8. ComfyUI ControlNet 🎮
Préparez-vous à faire passer votre art AI au niveau supérieur avec ControlNet, une technologie révolutionnaire qui bouleverse la génération d'images !
ControlNet est comme une baguette magique 🪄 qui vous donne un contrôle sans précédent sur vos images générées par l'IA. Il travaille main dans la main avec des modèles puissants comme Stable Diffusion, améliorant leurs capacités et vous permettant de guider le processus de création d'images comme jamais auparavant !
Imaginez pouvoir spécifier les bords, les poses humaines, la profondeur ou même les cartes de segmentation de l'image souhaitée. 🌠 Avec ControlNet, vous pouvez le faire !
Si vous êtes impatient d'approfondir le monde de ControlNet et de libérer tout son potentiel, nous vous avons couverts. Consultez notre tutoriel détaillé sur la maîtrise de ControlNet dans ComfyUI ! 📚 Il est rempli de guides étape par étape et d'exemples inspirants pour vous aider à devenir un pro de ControlNet. 🏆
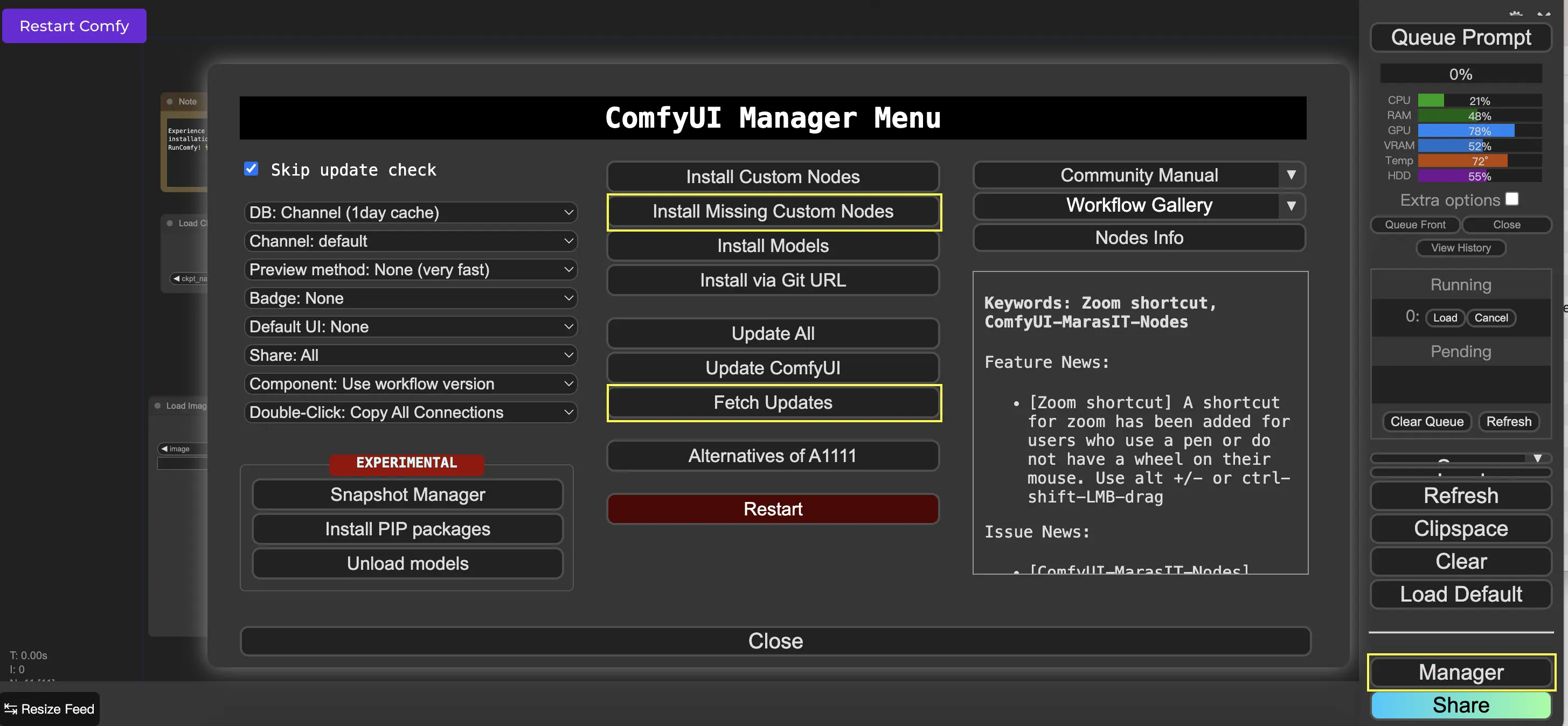
9. ComfyUI Manager 🛠️
ComfyUI Manager est un nœud personnalisé qui vous permet d'installer et de mettre à jour d'autres nœuds personnalisés via l'interface ComfyUI. Vous trouverez le bouton Manager dans le menu Queue Prompt.
9.1. Comment installer les nœuds personnalisés manquants 📥
Si un workflow nécessite des nœuds personnalisés que vous n'avez pas installés, suivez ces étapes :
- Cliquez sur Manager dans le menu.
- Cliquez sur Install Missing Custom Nodes.
- Redémarrez complètement ComfyUI.
- Actualisez le navigateur.
9.2. Comment mettre à jour les nœuds personnalisés 🔄
- Cliquez sur Manager dans le menu.
- Cliquez sur Fetch Updates (peut prendre un certain temps).
- Cliquez sur Install Custom Nodes.
- Si une mise à jour est disponible, un bouton Update apparaîtra à côté du nœud personnalisé installé.
- Cliquez sur Update pour mettre à jour le nœud.
- Redémarrez ComfyUI.
- Actualisez le navigateur.
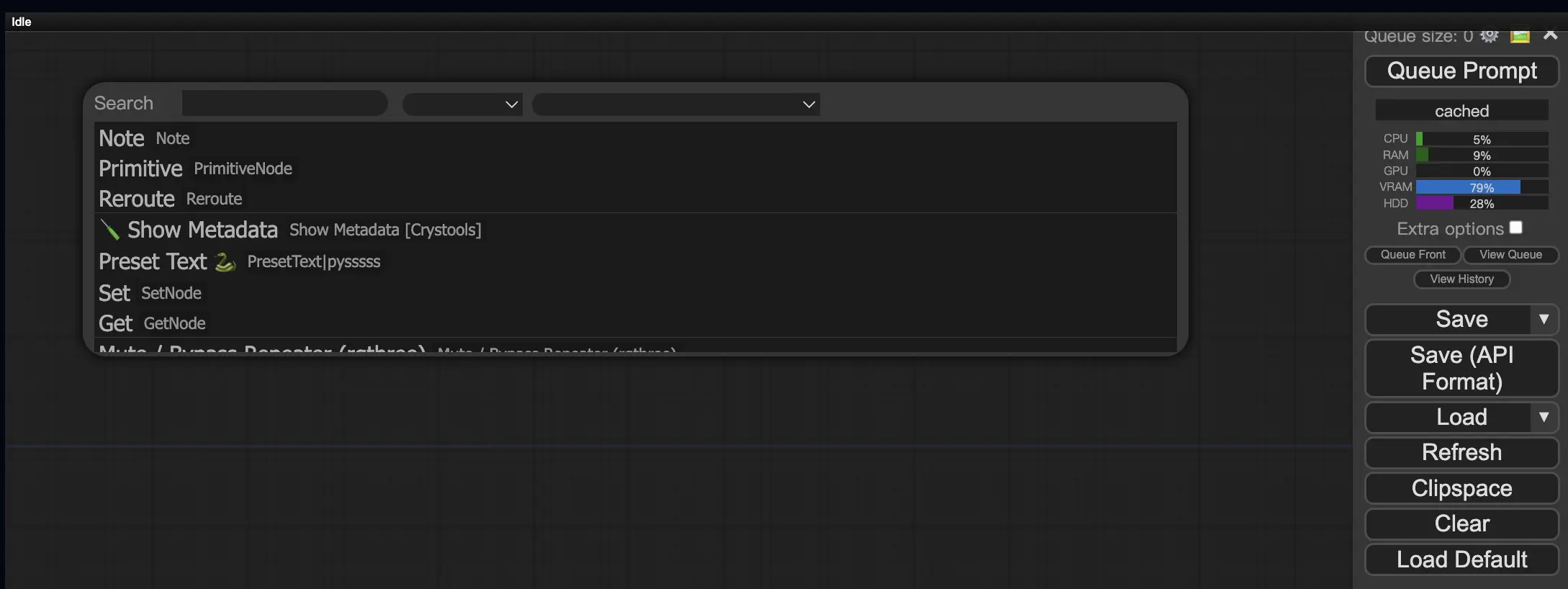
9.3. Comment charger des nœuds personnalisés dans votre workflow 🔍
Double-cliquez sur n'importe quelle zone vide pour faire apparaître un menu permettant de rechercher des nœuds.
10. Embeddings ComfyUI 📝
Les embeddings, également connus sous le nom d'inversion textuelle, sont une fonctionnalité puissante de ComfyUI qui vous permet d'injecter des concepts ou des styles personnalisés dans vos images générées par l'IA. 💡 C'est comme apprendre à l'IA un nouveau mot ou une nouvelle phrase et l'associer à des caractéristiques visuelles spécifiques.
Pour utiliser les embeddings dans ComfyUI, tapez simplement "embedding:" suivi du nom de votre embedding dans la boîte d'invite positive ou négative. Par exemple :
embedding: BadDream
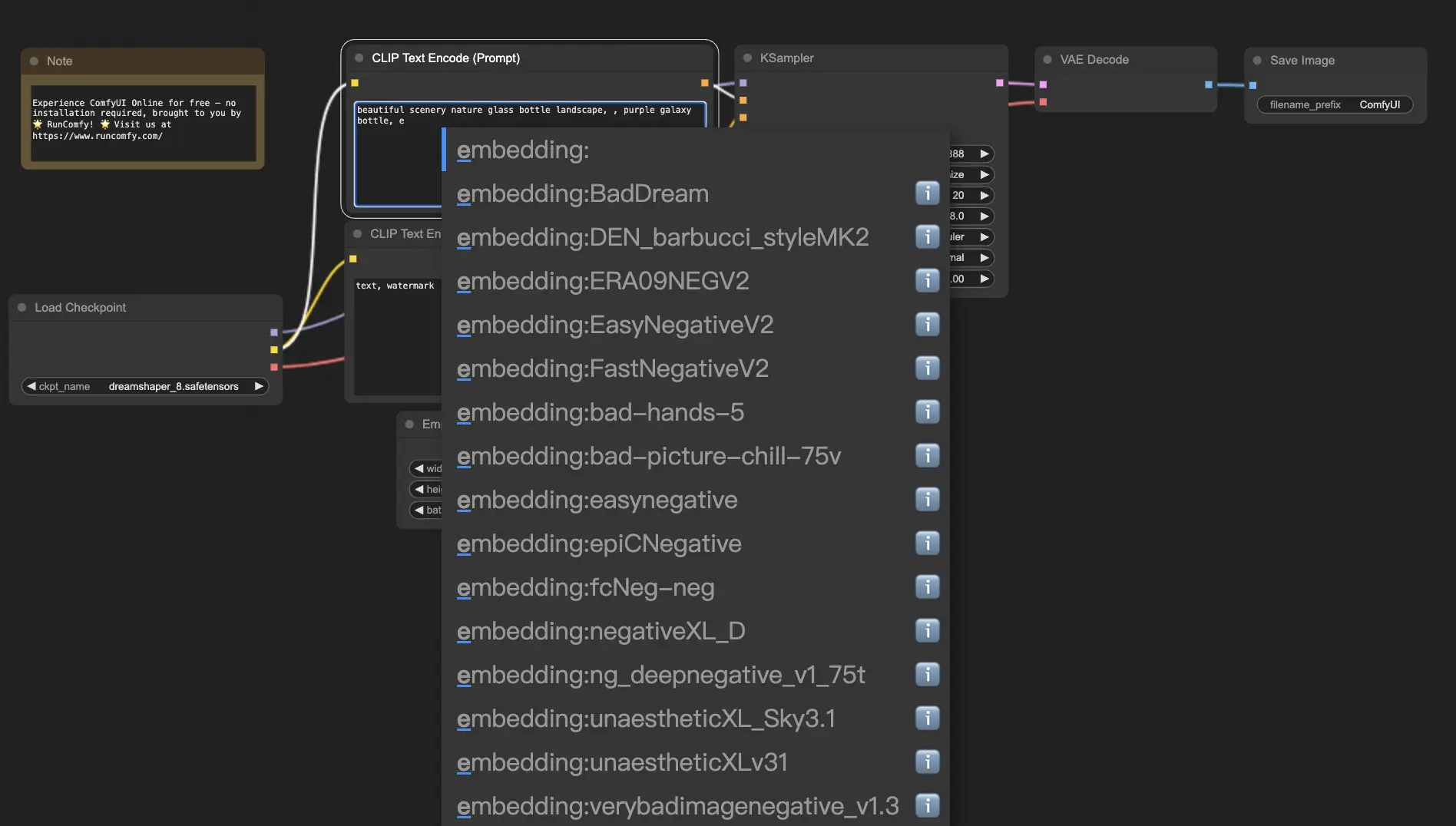
Lorsque vous utilisez cette invite, ComfyUI recherchera un fichier d'embedding nommé "BadDream" dans le dossier ComfyUI > models > embeddings. 📂 S'il trouve une correspondance, il appliquera les caractéristiques visuelles correspondantes à votre image générée.
Les embeddings sont un excellent moyen de personnaliser votre art AI et d'obtenir des styles ou des esthétiques spécifiques. 🎨 Vous pouvez créer vos propres embeddings en les entraînant sur un ensemble d'images représentant le concept ou le style souhaité.
10.1. Embedding avec autocomplétion 🔠
Se souvenir des noms exacts de vos embeddings peut être fastidieux, surtout si vous en avez une grande collection. 😅 C'est là que le nœud personnalisé ComfyUI-Custom-Scripts vient à la rescousse !
Pour activer l'autocomplétion des noms d'embedding :
- Ouvrez le ComfyUI Manager en cliquant sur "Manager" dans le menu supérieur.
- Allez dans "Install Custom Nodes" et recherchez "ComfyUI-Custom-Scripts".
- Cliquez sur "Install" pour ajouter le nœud personnalisé à votre configuration ComfyUI.
- Redémarrez ComfyUI pour appliquer les changements.
Une fois le nœud ComfyUI-Custom-Scripts installé, vous bénéficierez d'une utilisation plus conviviale des embeddings. 😊 Commencez simplement à taper "embedding:" dans une boîte d'invite, et une liste des embeddings disponibles apparaîtra. Vous pourrez alors sélectionner l'embedding souhaité dans la liste, vous faisant gagner du temps et des efforts !
10.2. Poids d'Embedding ⚖️
Saviez-vous que vous pouvez contrôler la force de vos embeddings ? 💪 Puisque les embeddings sont essentiellement des mots-clés, vous pouvez leur appliquer des poids comme vous le feriez avec des mots-clés normaux dans vos invites.
Pour ajuster le poids d'un embedding, utilisez la syntaxe suivante :
(embedding: BadDream:1.2)
Dans cet exemple, le poids de l'embedding "BadDream" est augmenté de 20%. Ainsi, des poids plus élevés (par exemple, 1.2) rendront l'embedding plus proéminent, tandis que des poids plus faibles (par exemple, 0.8) réduiront son influence. 🎚 e0f Cela vous donne encore plus de contrôle sur le résultat final !
11. ComfyUI LoRA 🧩
LoRA, abréviation de Low-rank Adaptation, est une autre fonctionnalité passionnante de ComfyUI qui vous permet de modifier et d'affiner vos modèles checkpoint. 🎨 C'est comme ajouter un petit modèle spécialisé au-dessus de votre modèle de base pour obtenir des styles spécifiques ou incorporer des éléments personnalisés.
Les modèles LoRA sont compacts et efficaces, ce qui les rend faciles à utiliser et à partager. Ils sont couramment utilisés pour des tâches telles que la modification du style artistique d'une image ou l'injection d'une personne ou d'un objet spécifique dans le résultat généré.
Lorsque vous appliquez un modèle LoRA à un modèle checkpoint, il modifie les composants MODEL et CLIP tout en laissant le VAE (Variational Autoencoder) intact. Cela signifie que le LoRA se concentre sur l'ajustement du contenu et du style de l'image sans altérer sa structure globale.
11.1. Comment utiliser LoRA 🔧
L'utilisation de LoRA dans ComfyUI est simple. Jetons un coup d'œil à la méthode la plus simple :
- Sélectionnez un modèle checkpoint qui servira de base à la génération d'images.
- Choisissez un modèle LoRA que vous souhaitez appliquer pour modifier le style ou injecter des éléments spécifiques.
- Révisez les invites positives et négatives pour guider le processus de génération d'images.
- Cliquez sur "Queue Prompt" pour commencer à générer l'image avec le LoRA appliqué. ▶
ComfyUI combinera alors le modèle checkpoint et le modèle LoRA pour créer une image qui reflète les invites spécifiées et intègre les modifications introduites par le LoRA.
11.2. LoRAs multiples 🧩🧩
Mais que faire si vous voulez appliquer plusieurs LoRAs à une seule image ? Pas de problème ! ComfyUI vous permet d'utiliser deux LoRAs ou plus dans le même workflow texte-à-image.
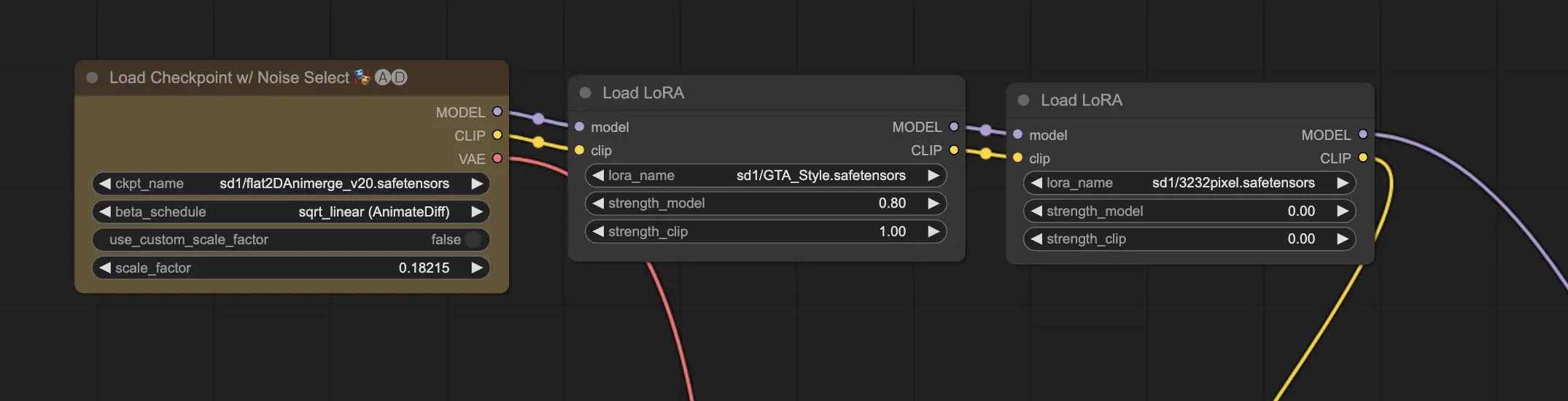
Le processus est similaire à l'utilisation d'un seul LoRA, mais vous devrez sélectionner plusieurs modèles LoRA au lieu d'un seul. ComfyUI appliquera les LoRAs de manière séquentielle, ce qui signifie que chaque LoRA s'appuiera sur les modifications introduites par le précédent.
Cela ouvre tout un monde de possibilités pour combiner différents styles, éléments et modifications dans vos images générées par l'IA. 🌍💡 Expérimentez différentes combinaisons de LoRAs pour obtenir des résultats uniques et créatifs !
12. Raccourcis et astuces pour ComfyUI ⌨️🖱️
12.1. Copier et coller 📋
- Sélectionnez un nœud et appuyez sur Ctrl+C pour copier.
- Appuyez sur Ctrl+V pour coller.
- Appuyez sur Ctrl+Shift+V pour coller avec les connexions d'entrée intactes.
12.2. Déplacement de plusieurs nœuds 🖱️
- Créez un groupe pour déplacer un ensemble de nœuds ensemble.
- Alternativement, maintenez la touche Ctrl enfoncée et faites glisser pour créer une boîte permettant de sélectionner plusieurs nœuds ou maintenez la touche Ctrl enfoncée pour sélectionner plusieurs nœuds individuellement.
- Pour déplacer les nœuds sélectionnés, maintenez la touche Shift enfoncée et déplacez la souris.
12.3. Contourner un nœud 🔇
- Désactivez temporairement un nœud en le mettant en sourdine. Sélectionnez un nœud et appuyez sur Ctrl+M.
- Il n'y a pas de raccourci clavier pour mettre en sourdine un groupe. Sélectionnez Bypass Group Node dans le menu contextuel ou mettez en sourdine le premier nœud du groupe pour le désactiver.
12.4. Minimiser un nœud 🔍
- Cliquez sur le point situé dans le coin supérieur gauche du nœud pour le minimiser.
12.5. Générer une image ▶️
- Appuyez sur Ctrl+Enter pour mettre le workflow en file d'attente et générer des images.
12.6. Workflow intégré 🖼️
- ComfyUI sauvegarde l'intégralité du workflow dans les métadonnées du fichier PNG qu'il génère. Pour charger le workflow, faites glisser et déposez l'image dans ComfyUI.
12.7. Fixer les seeds pour gagner du temps ⏰
- ComfyUI ne réexécute un nœud que si l'entrée change. Lorsque vous travaillez sur une longue chaîne de nœuds, gagnez du temps en fixant la seed pour éviter de régénérer les résultats en amont.
13. ComfyUI en ligne 🚀
Félicitations pour avoir terminé ce guide du débutant sur ComfyUI ! 🙌 Vous êtes maintenant prêt à plonger dans le monde passionnant de la création d'art AI. Mais pourquoi se soucier de l'installation alors que vous pouvez commencer à créer immédiatement ? 🤔
Chez RunComfy, nous avons simplifié l'utilisation de ComfyUI en ligne sans aucune configuration. Notre service ComfyUI Online est préchargé avec plus de 200 nœuds et modèles populaires, ainsi que plus de 50 workflows époustouflants pour inspirer vos créations.
🌟 Que vous soyez un débutant ou un artiste AI expérimenté, RunComfy a tout ce dont vous avez besoin pour donner vie à vos visions artistiques. 💡 N'attendez plus – essayez ComfyUI Online maintenant et découvrez la puissance de la création d'art AI au bout de vos doigts ! 🚀