
Salut ! 🌟 Aujourd'hui, nous allons explorer l'art de remplacer et corriger les visages dans les images et vidéos avec quelque chose de super cool : le Face Detailer ComfyUI. Saisissez vos pinceaux numériques et devenons artistiques !
Nous couvrirons :
- Qu'est-ce que le Face Detailer dans ComfyUI ?
- After Detailer (ADetailer) pour Automatic111 vs Face Detailer pour ComfyUI
- ComfyUI Impact Pack - Face Detailer
- Flux de travail Face Detailer ComfyUI - Aucune installation nécessaire, totalement gratuit
- Ajouter le nœud Face Detailer
- Entrée pour Face Detailer
- Entrez l'image que vous souhaitez restaurer
- Choisissez le modèle, Clip, VAE et saisissez à la fois un prompt positif et négatif
- La différence entre le détecteur BBox et le détecteur Segm (modèle Sam)
- Paramètres de Face Detailer : Comment utiliser Face Detailer dans ComfyUI
- Face Detailer - Guide Size, Guide Size For, Max Size et BBX Crop Factor
- Face Detailer - Feather
- Face Detailer - Noise Mask
- Face Detailer - Force Inpainting
- Face Detailer - Drop Size
- Face Detailer - Fonctionnalités liées à BBox
- Face Detailer - Fonctionnalités liées à Segm/Sam
- Autres améliorations
- Deux passes de raffinement avec Face Detailer(Pipe)
- Agrandissement de la vidéo avec 4x-UltraSharp
- Exécuter le flux de travail Face Detailer ComfyUI gratuitement
1. Qu'est-ce que le Face Detailer dans ComfyUI ?
1.1 After Detailer (ADetailer) pour Automatic111 vs Face Detailer pour ComfyUI
Je pense que vous connaissez peut-être ou avez entendu parler de l'extension After Detailer (ADetailer) pour Automatic111, utilisée pour corriger les visages. Une fonction similaire à cette extension, connue sous le nom de Face Detailer, existe dans ComfyUI et fait partie du nœud Impact Pack. Par conséquent, si vous souhaitez utiliser ADetailer dans ComfyUI, vous devriez plutôt opter pour le Face Detailer d'Impact Pack dans ComfyUI.
1.2 ComfyUI Impact Pack - Face Detailer
Le ComfyUI Impact Pack sert de boîte à outils numérique pour l'amélioration d'images, à l'instar d'un couteau suisse pour vos images. Il est équipé de divers modules tels que Detector, Detailer, Upscaler, Pipe, et plus encore. Le point fort est le Face Detailer, qui restaure sans effort les visages dans les images, les vidéos et les animations.
2. Flux de travail Face Detailer ComfyUI - Aucune installation nécessaire, totalement gratuit
Regardez la vidéo ci-dessus, créée à l'aide du flux de travail Face Detailer ComfyUI. Maintenant, vous pouvez expérimenter le flux de travail Face Detailer sans aucune installation. Tout est configuré pour vous dans un ComfyUI basé sur le cloud, préchargé avec le nœud Impact Pack - Face Detailer et chaque modèle requis pour une expérience transparente. Vous pouvez exécuter ce flux de travail Face Detailer dès maintenant ou continuer à lire ce tutoriel sur la façon de l'utiliser, puis l'essayer plus tard.
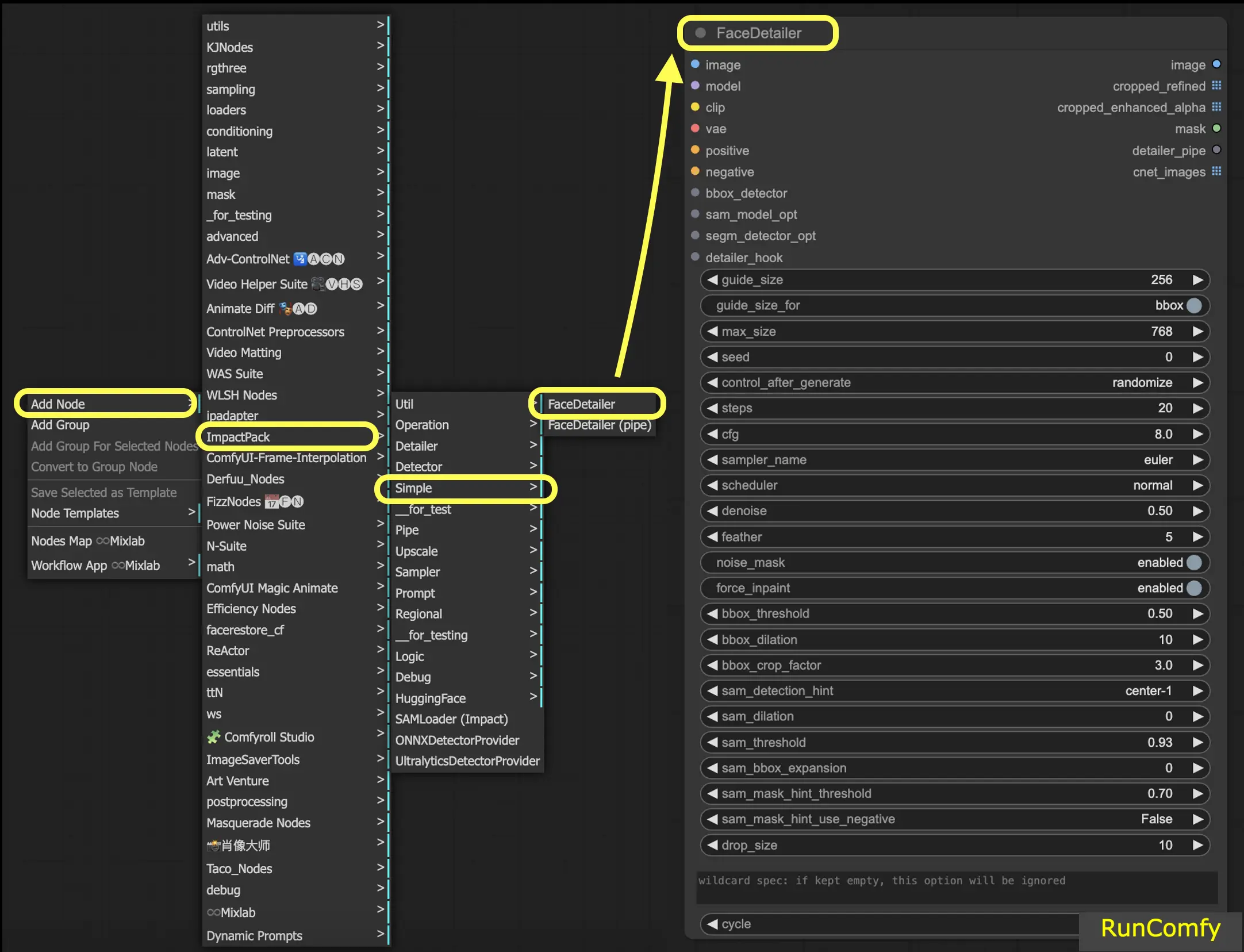
3. Ajouter le nœud Face Detailer
Bien, mettons les mains dans le cambouis avec le Face Detailer ComfyUI. Le nœud Face Detailer peut sembler complexe au premier abord, mais n'ayez crainte, nous allons le décomposer morceau par morceau. En comprenant chaque entrée, sortie et paramètre, vous maîtriserez rapidement cet outil puissant.
Pour localiser le Face Detailer dans ComfyUI, allez simplement dans Add Node → Impact Pack → Simple → Face Detailer / Face Detailer (pipe).
Commençons par "Face Detailer", puis plongeons dans le "Face Detailer Pipe".
- FaceDetailer - Détecte facilement les visages et les améliore.
- FaceDetailer (pipe) - Détecte facilement les visages et les améliore (pour multipass).
Dans ce tutoriel, nous explorons comment corriger ou remplacer les visages dans les vidéos. La vidéo est générée à l'aide d'AnimateDiff. Si vous êtes impatient d'en apprendre davantage sur AnimateDiff, nous avons un tutoriel dédié à AnimateDiff !
Si vous êtes plus à l'aise pour travailler avec des images, il suffit d'échanger les nœuds liés à la vidéo par ceux liés à l'image. Le Face Detailer est suffisamment polyvalent pour gérer à la fois la vidéo et l'image.
4. Entrée pour Face Detailer
4.1 Entrez l'image que vous souhaitez restaurer
Commençons par l'entrée d'image (bouton en haut à gauche dans Face Detailer), ce qui signifie alimenter une image ou une vidéo dans le Face Detailer ComfyUI. C'est ici que la transformation commence ! Ici, nous alimentons le Face Detailer avec la vidéo générée par AnimateDiff.
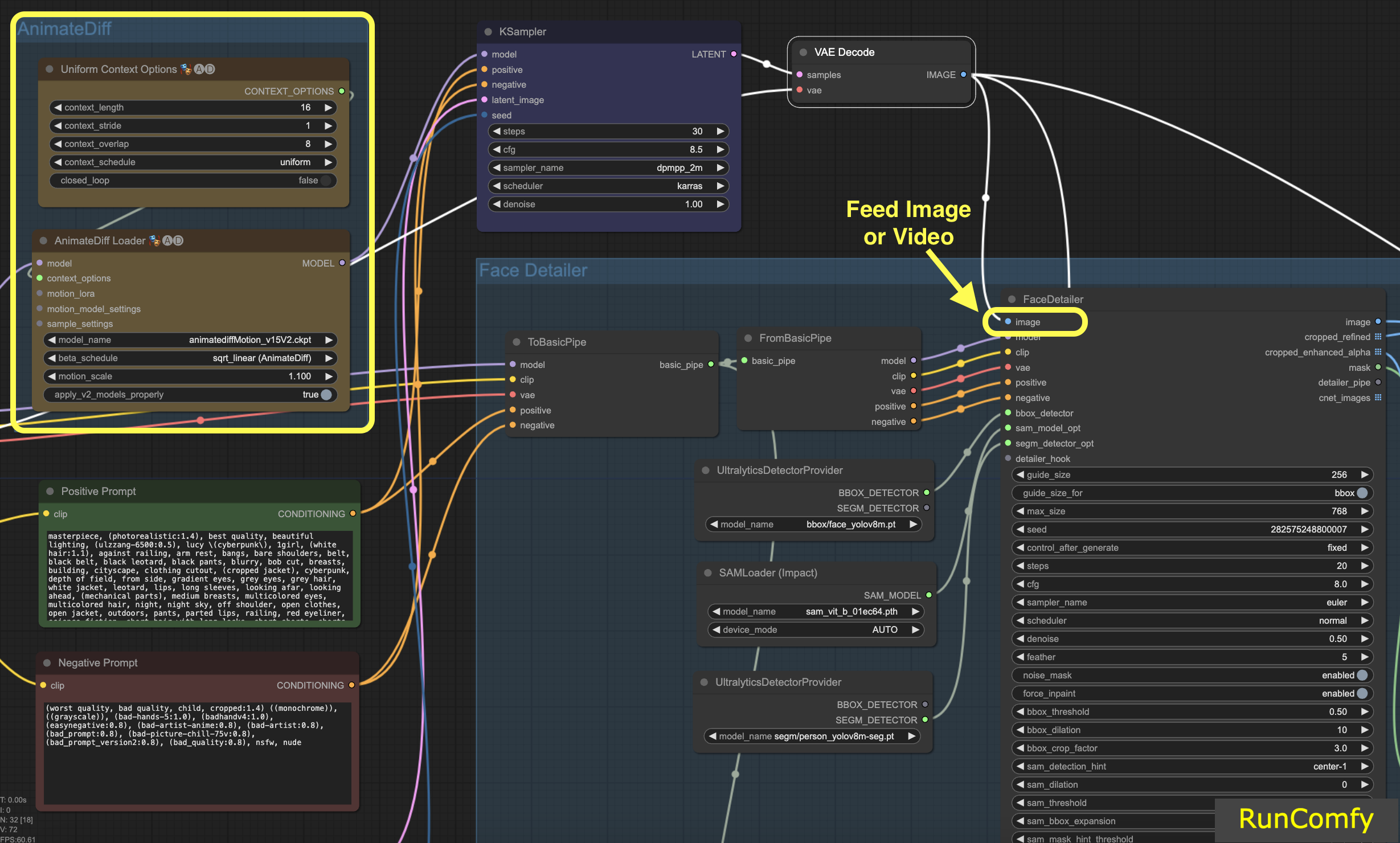
4.2 Choisissez le modèle, Clip, VAE et saisissez à la fois un prompt positif et négatif
Vous connaissez probablement déjà ces paramètres. Nous allons passer les bases et noter simplement que les prompts - à la fois positifs et négatifs - jouent un rôle crucial ici. Nous allons utiliser les mêmes prompts que ceux qui ont généré la vidéo. Cependant, vous avez la flexibilité de personnaliser ces prompts, en particulier pour le visage que vous avez l'intention de remplacer.
Voici un point intéressant : l'utilisation des mêmes prompts que la génération d'image conduit à la restauration du visage. D'autre part, des prompts différents signifient que vous optez pour un remplacement complet du visage. C'est vous qui décidez !
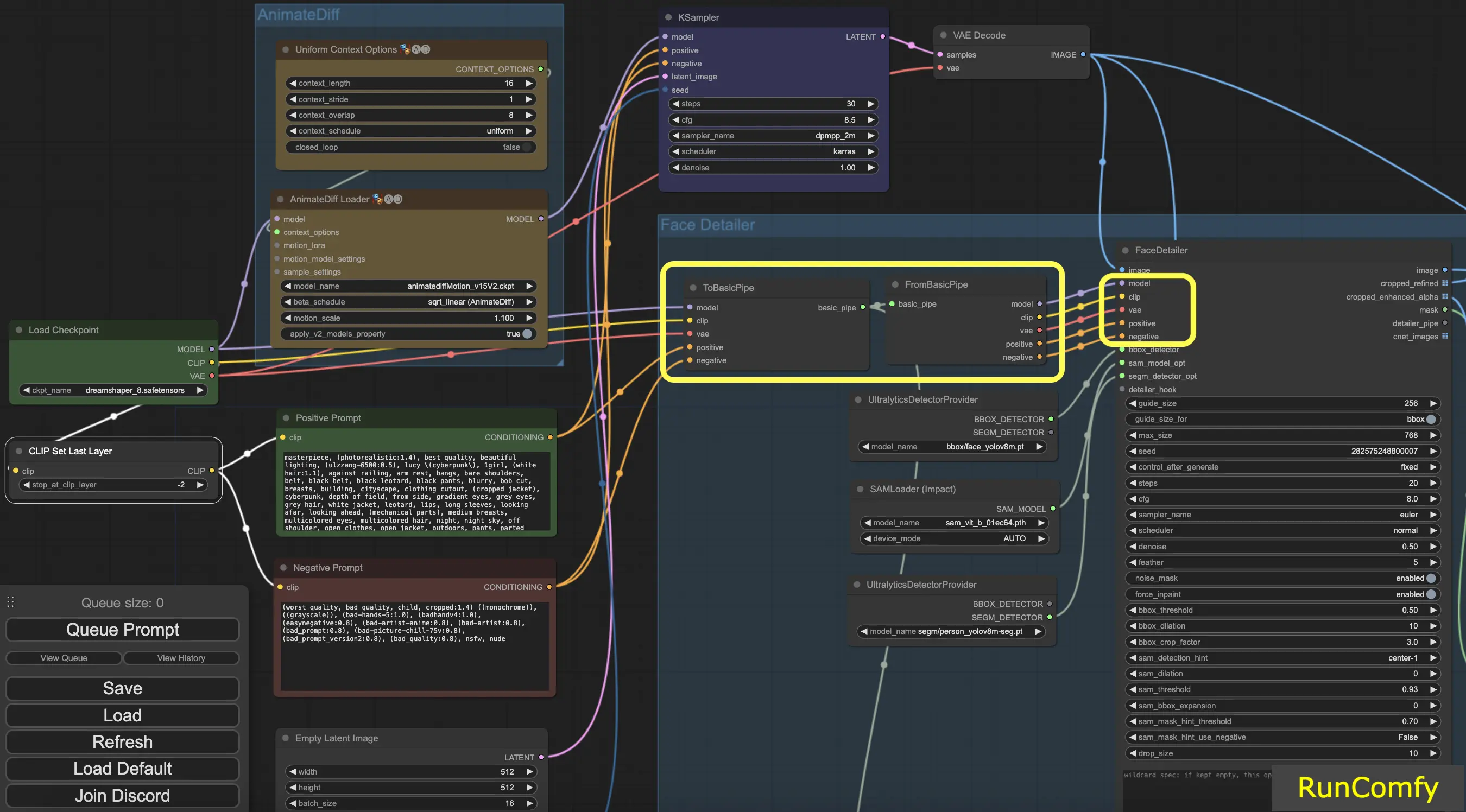
Conseil : Utilisez "To Basic Pipe" et "From Basic Pipe"
Pour simplifier le processus de connexion de nombreux nœuds, utilisez le système "Pipe". Commencez par "To Basic Pipe", un combinateur d'entrées, pour rassembler diverses entrées. Ensuite, utilisez "From Basic Pipe" pour déballer ces entrées. Connectez simplement ces deux pipes et vous aurez toutes les entrées nécessaires prêtes pour une intégration rapide et efficace.
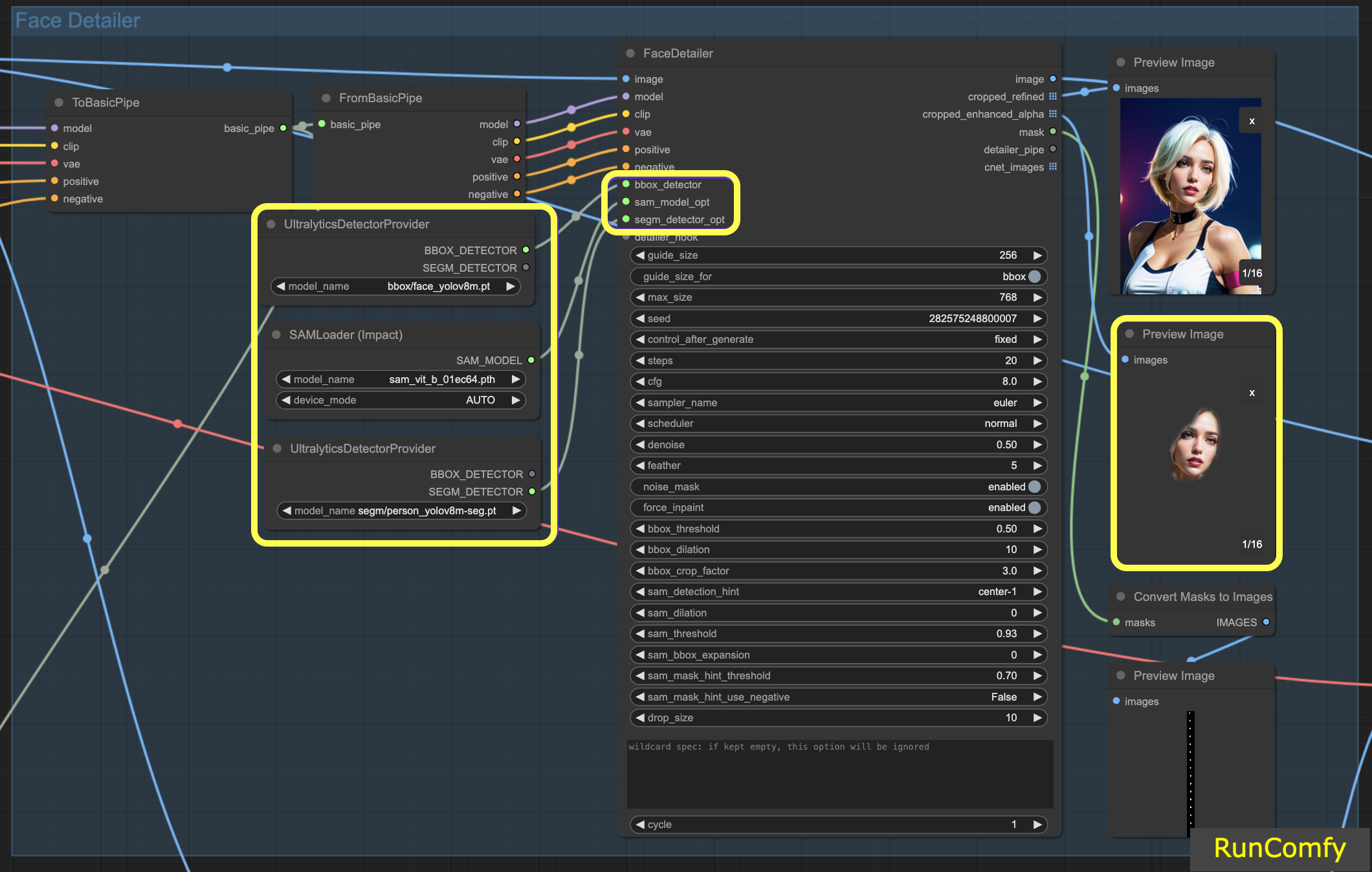
4.3 La différence entre le détecteur BBox et le détecteur Segm (modèle Sam)
Les modèles BBox se spécialisent dans l'identification des éléments à l'aide de boîtes englobantes, tandis que les modèles Segm/person utilisent des masques pour la détection.
Dans les deux cas, que ce soit pour le détecteur BBox ou le détecteur Segm, nous employons le nœud "Ultral Litic Detector Provider". Cependant, il est important de noter que pour le détecteur BBox, nous utilisons spécifiquement les modèles bbox/face_yolov8m et bbox/hand_yolov8s. En revanche, le modèle segm/person_yolov8m-seg est exclusivement utilisé pour le détecteur Segm.
Ce qui suit concerne uniquement le détecteur BBox. Par conséquent, vous observerez que l'aperçu de l'image recadrée et améliorée apparaît sous forme de boîte.
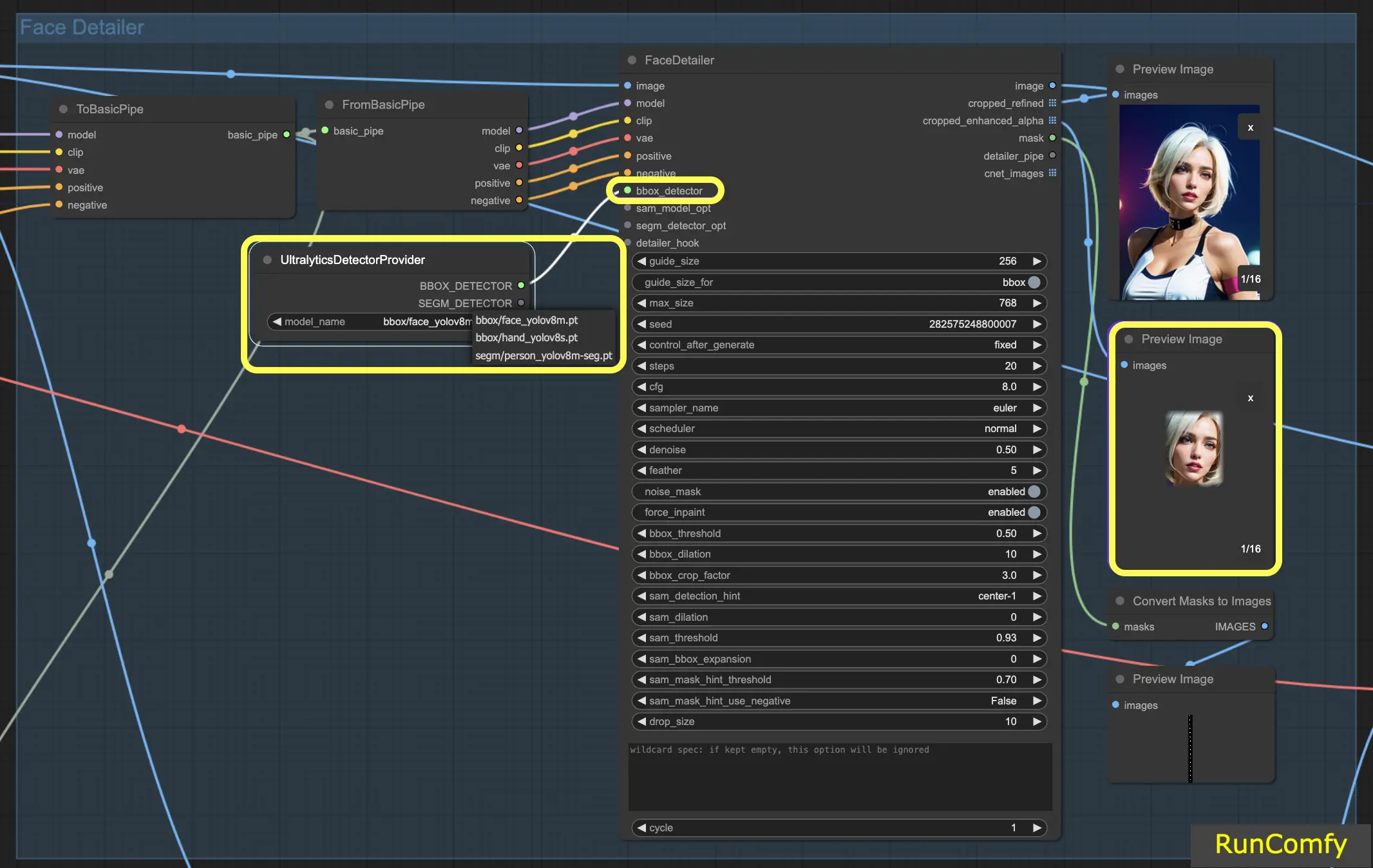
Par la suite, lorsque nous combinons les capacités du détecteur BBox et du détecteur Segm, et intégrons le modèle Sam, l'aperçu de l'image recadrée et améliorée prend un aspect de masque.
5. Paramètres de Face Detailer : Comment utiliser Face Detailer ComfyUI
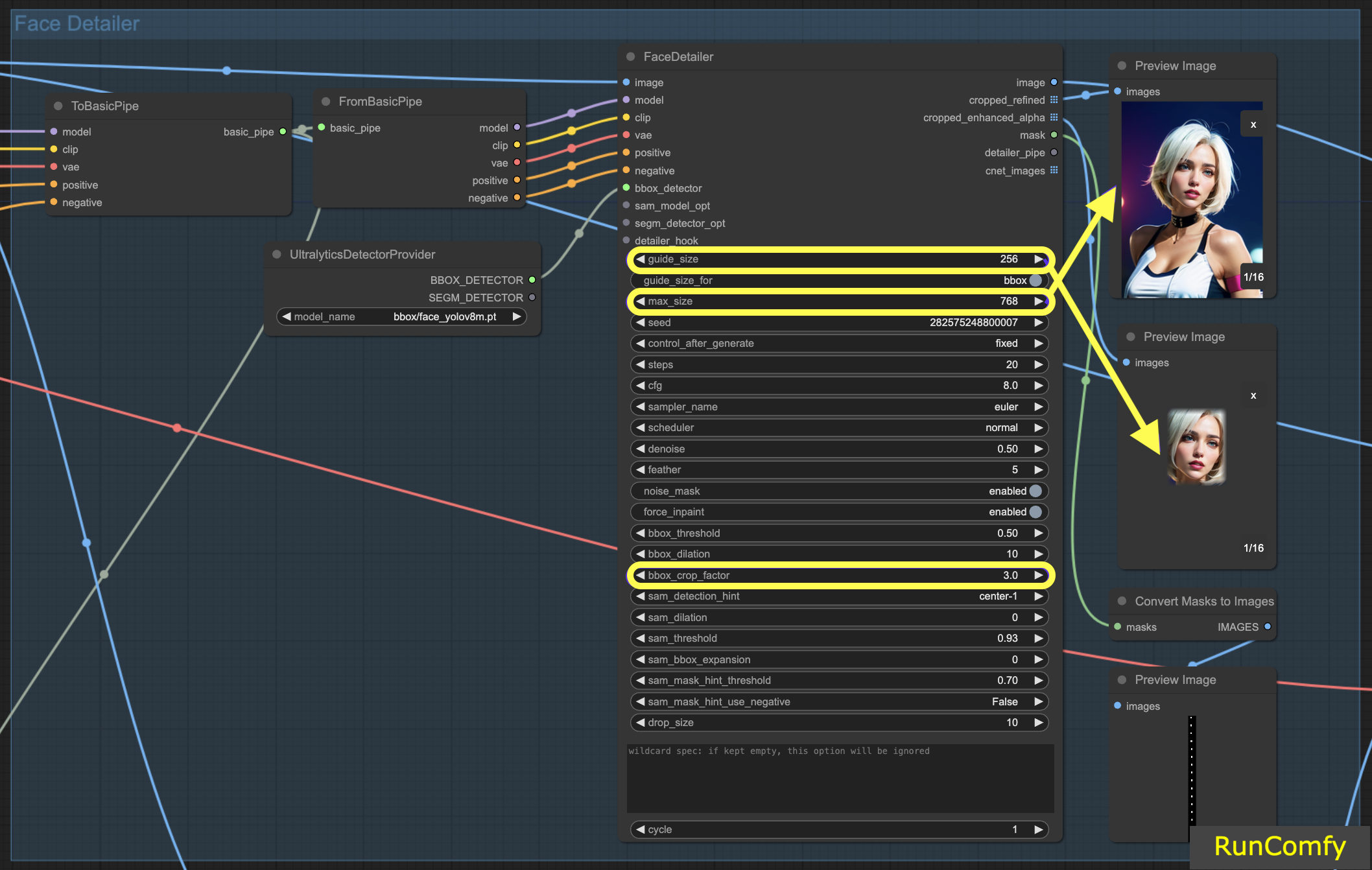
5.1 Face Detailer - Guide Size, Guide Size For, Max Size et BBX Crop Factor
Guide Size : La taille du guide pour BBX focalise le face detailer de l'image sur la zone du visage de la boîte englobante (comme indiqué dans l'aperçu de l'image recadrée améliorée). Défini par défaut à 256, cela signifie que si la zone du visage de la boîte englobante est inférieure à 256 pixels, le système la met automatiquement à l'échelle jusqu'à un minimum de 256 pixels.
Max Size : La taille maximale établit la limite supérieure de la taille que peut avoir la zone recadrée (comme indiqué dans l'aperçu de l'image recadrée raffinée). Ce plafond est destiné à empêcher que la zone ne devienne trop grande, ce qui pourrait entraîner d'autres problèmes. La taille maximale par défaut est de 768 pixels.
Maintenir une plage optimale : En définissant ces paramètres, nous maintenons la taille de l'image dans une plage de 256 à 768 pixels, idéale pour le point de contrôle SD 1.5. Cependant, si vous passez au modèle de point de contrôle SDXL, connu pour de meilleures performances avec des images plus grandes, il peut être avantageux d'ajuster la taille du guide à 512 et la taille maximale à 1024. Cet ajustement vaut la peine d'être expérimenté.
Guide Size for : Sous la taille du guide, il y a une option intitulée "guide size for bbox". Cela vous permet de déplacer le focus vers la région de recadrage, qui est une zone plus grande que la zone du visage de la boîte englobante.
BBX Crop Factor : Le facteur de recadrage BBX est actuellement défini à 3. Réduire le facteur de recadrage à 1,0 signifie une zone de recadrage plus petite, égale à la zone du visage. Lorsqu'il est défini à 3, cela indique que la zone de recadrage est 3 fois plus grande que la zone du visage.
L'essence de l'ajustement du facteur de recadrage réside dans la recherche d'un équilibre entre fournir une mise au point adéquate pour le face detailer et laisser suffisamment d'espace pour le mélange contextuel. Le définir à 3 signifie que la zone de recadrage inclut un peu plus du contexte environnant, ce qui est généralement bénéfique. Cependant, vous devez également prendre en compte la taille du visage dans l'image lorsque vous décidez du réglage approprié.
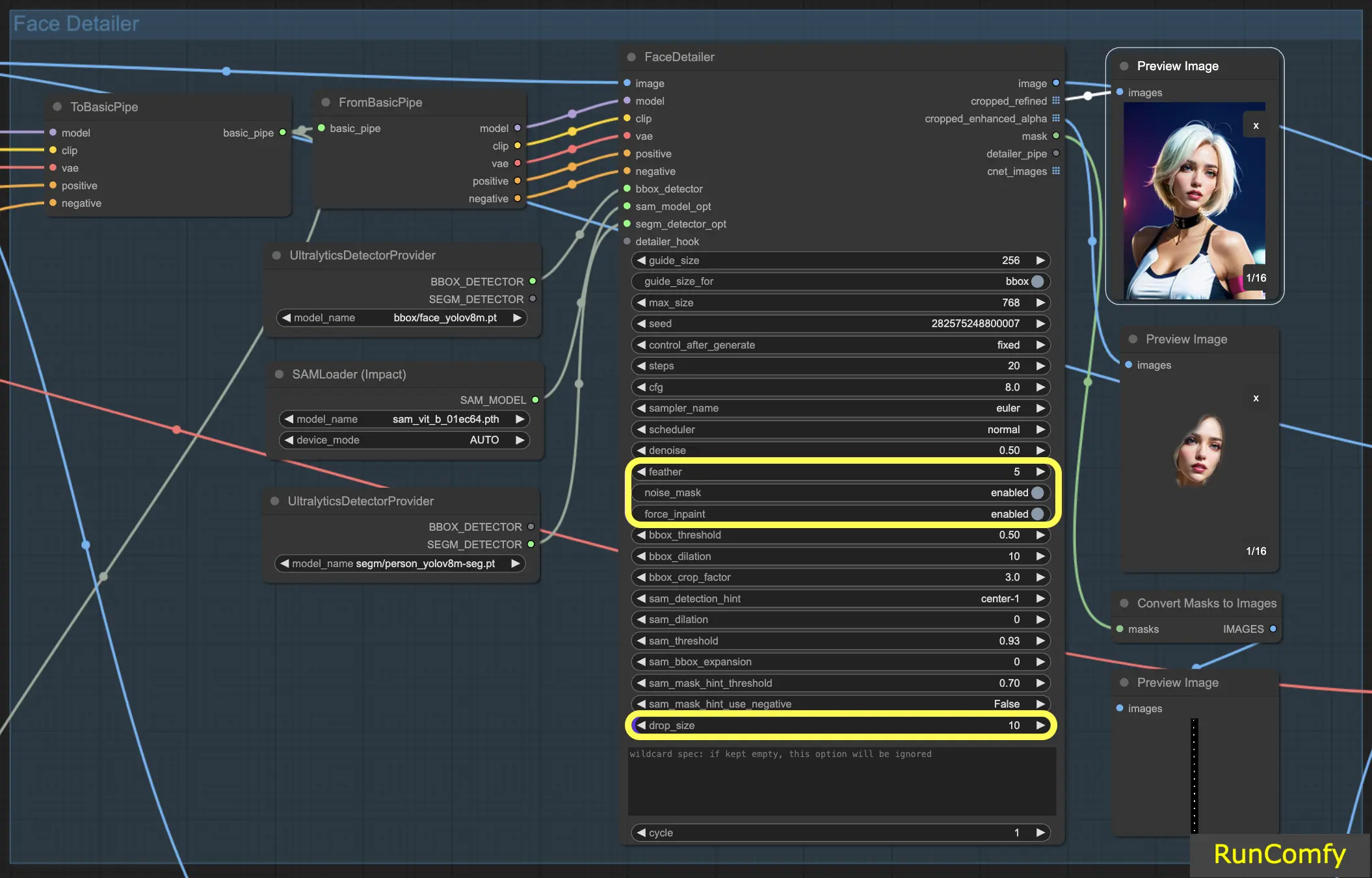
5.2 Face Detailer - Feather
Le réglage Feather détermine dans quelle mesure les bords de l'image ou les zones de remplissage se fondent de manière transparente avec le reste de l'image. Je le règle généralement à cinq, ce qui fonctionne bien dans la plupart des cas. Cependant, si vous remarquez que le remplissage dans vos images a des bords particulièrement nets, vous pouvez envisager d'augmenter cette valeur. Comme nous n'observons pas de bords nets dans cet exemple, il n'y a pas de besoin immédiat de l'ajuster.
5.3 Face Detailer - Noise Mask
L'activation du Noise Mask dirige efficacement le modèle pour qu'il concentre ses opérations de bruit et de débruitage exclusivement sur la zone masquée. Cela transforme la boîte englobante en un masque, qui indique précisément les zones où le bruit est appliqué puis affiné. Cette fonctionnalité est particulièrement importante lorsque l'on travaille avec des détecteurs Segm et des modèles Sam.
5.4 Face Detailer - Force Inpainting
Force Inpaint fonctionne comme un outil spécialisé pour améliorer des zones spécifiques d'une image avec des détails supplémentaires. Souvent, nous nous concentrons sur les visages dans les images. Il y a des moments où le système automatique peut ne pas ajouter suffisamment de détails à ces visages, en supposant à tort qu'ils sont déjà suffisamment détaillés. C'est le scénario parfait pour utiliser Force Inpaint.
En essence, Force Inpaint est idéal pour augmenter les détails dans certaines zones de votre image, en particulier lorsque les paramètres automatiques sont insuffisants.
5.5 Face Detailer - Drop Size
Particulièrement utile dans les scénarios de remplacement de plusieurs visages, le paramètre de taille de chute indique au modèle d'ignorer les masques plus petits qu'une taille spécifiée, comme 10 pixels. Cette fonctionnalité est inestimable dans les scènes bondées où l'accent est mis sur les visages plus grands.
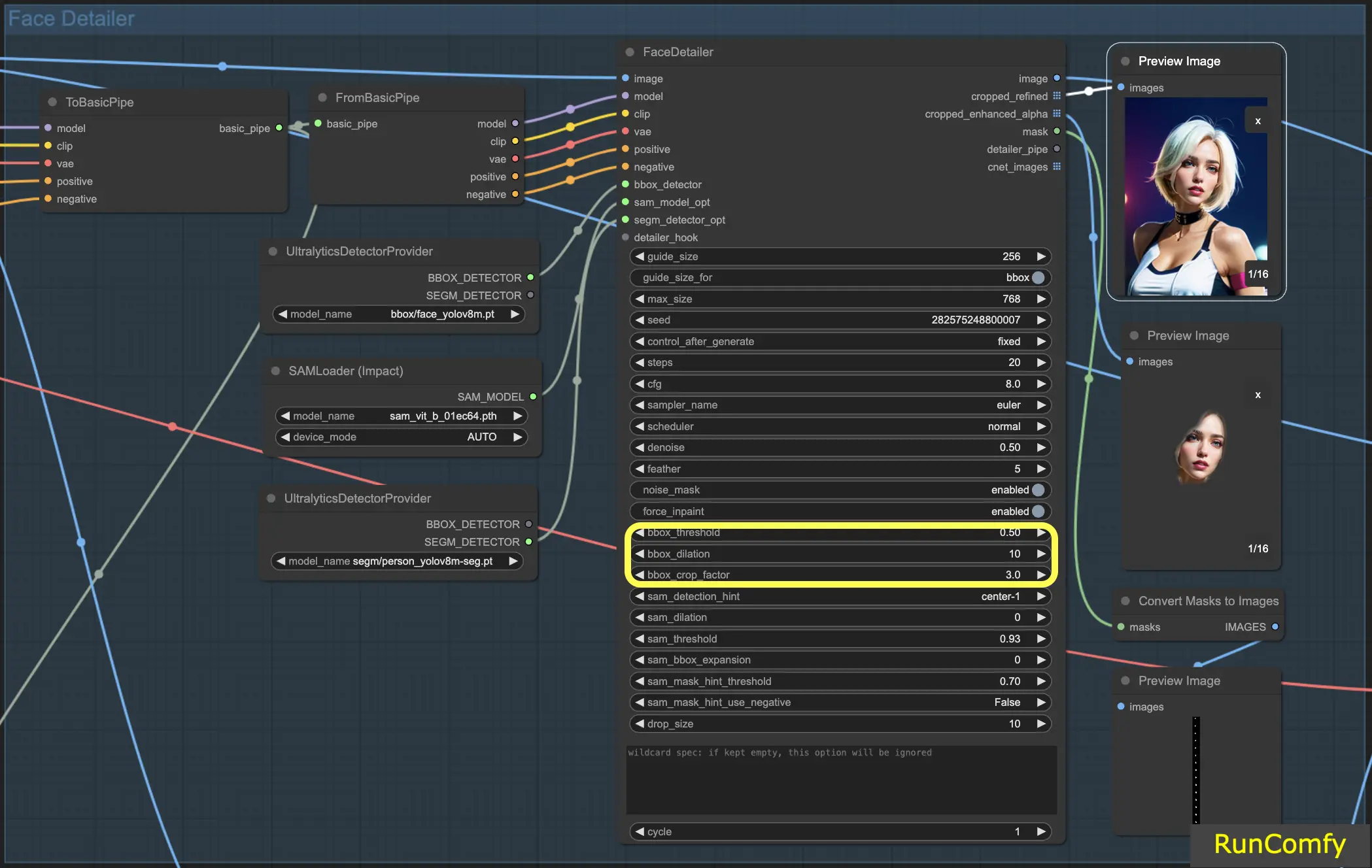
5.6 Face Detailer - Fonctionnalités liées à BBox
BBox Threshold : Le seuil bbox est essentiel pour affiner le modèle de détection des visages. Opter pour un nombre inférieur signifie un processus de détection plus indulgent. Le modèle évalue l'image, attribuant des pourcentages de confiance aux visages potentiels. La modification du seuil modifie le niveau de confiance requis pour que le modèle reconnaisse et remplace un visage.
Considérons une image présentant des masques en arrière-plan avec une personne au premier plan. Le modèle pourrait confondre les masques avec des visages. Dans de tels cas, vous pouvez augmenter le seuil pour vous assurer qu'il reconnaît et se concentre sur le visage clairement défini, plutôt que sur les masques. À l'inverse, pour remplacer plusieurs visages dans une foule, où les visages sont moins distincts, abaisser le seuil bbox peut aider à identifier ces visages moins évidents.
BBox Dilation : Le réglage de la dilatation bbox permet une expansion au-delà de la zone de recadrage initiale, généralement limitée au visage. Lorsque vous augmentez la dilatation, davantage de zones entourant le visage sont incluses dans le processus de remplacement. Cependant, ces changements sont souvent nuancés et peuvent nécessiter un ajustement du facteur de recadrage pour des résultats plus visibles.
BBX Crop Factor : Déjà mentionné en 4.1
5.7 Face Detailer - Fonctionnalités liées à Segm/Sam
Segm/Sam affine la boîte englobante conventionnelle en un masque plus précis, améliorant la précision du remplacement du visage. Cette précision est particulièrement utile dans les scénarios où la boîte englobante chevauche les cheveux et où vous préférez ne pas modifier les cheveux. En utilisant le modèle Sam, vous pouvez concentrer le remplacement uniquement sur le visage.
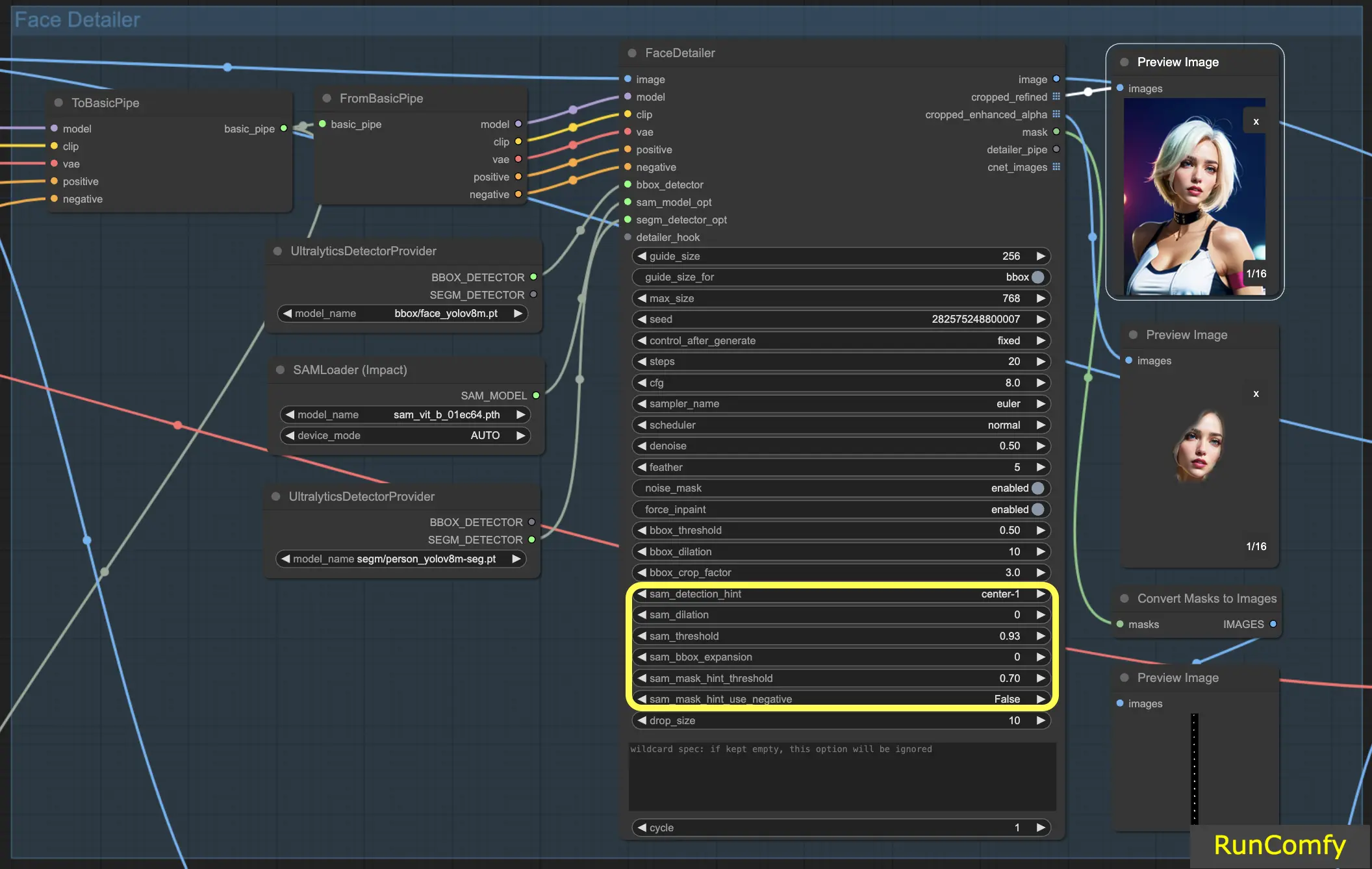
Sam Detection Hint : L'indice de détection Sam est un réglage crucial. Il guide le modèle sur l'endroit où se concentrer lors de l'identification des visages. Vous avez plusieurs options, notamment Centre, Horizontal (un ou deux visages), Vertical (deux visages) et des dispositions pour quatre visages dans des formations rectangulaires ou en diamant.
Sam Dilation : Similaire à la dilatation de la boîte englobante, le réglage de la dilatation Sam ajuste la zone à l'extérieur du masque ou du point focal que le modèle remplacera. L'augmentation de cette dilatation ré-étend la zone de masque vers une forme de boîte.
Sam Threshold : Réglé à un niveau élevé de 93 %, le seuil Sam fonctionne comme son homologue de la boîte englobante mais exige un niveau de confiance plus élevé en raison de la précision du modèle.
Sam Box Expansion : Ce réglage affine la boîte englobante initiale, définissant davantage la zone du visage. L'augmentation de l'expansion de la boîte est bénéfique lorsque la boîte englobante initiale est trop restrictive, permettant au modèle de capturer davantage le visage.
Sam Mask Hint Threshold : Travaillant de concert avec l'indice de détection Sam, ce réglage détermine l'agressivité du modèle pour répondre à l'indice. Le réglage par défaut est de 0,7.
Avec ces informations, vous devriez avoir une compréhension beaucoup plus profonde du fonctionnement du face detailer.
6. Autres améliorations
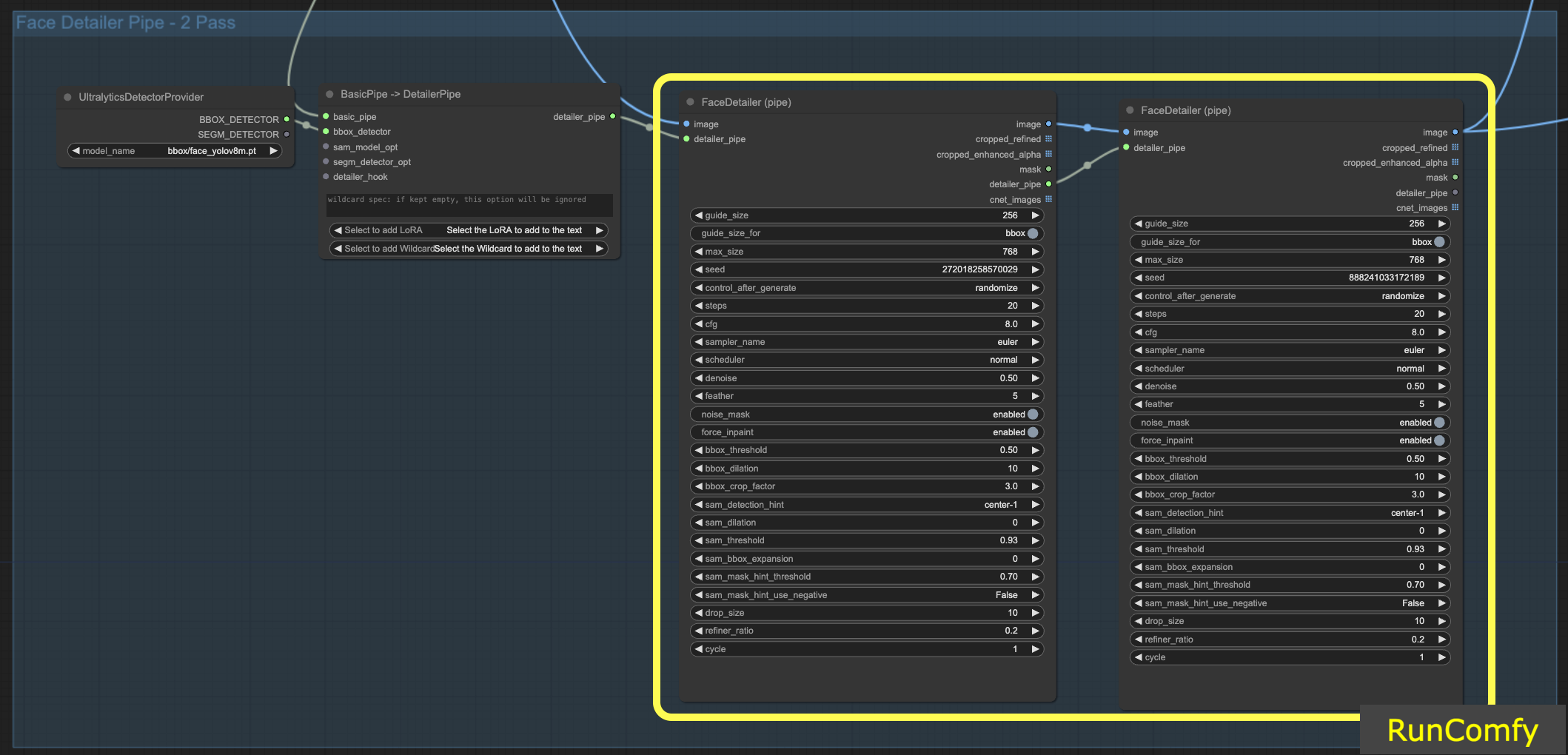
6.1 Deux passes de raffinement avec Face Detailer(Pipe)
L'intégration de deux FaceDetailer pour une configuration à double passe est faisable ; il suffit de transférer le Face Detailer vers le FaceDetailerPipe.
Dans une configuration à passe unique (1pass), l'accent est principalement mis sur la restauration d'un contour de base. Cela nécessite l'utilisation d'une résolution modérée avec des options minimales. Cependant, l'expansion de la dilatation ici peut être avantageuse, car elle couvre non seulement les traits du visage mais s'étend également aux zones environnantes. Cette technique est particulièrement bénéfique lorsque le remodelage s'étend au-delà de la partie faciale. Vous pouvez expérimenter selon les besoins.
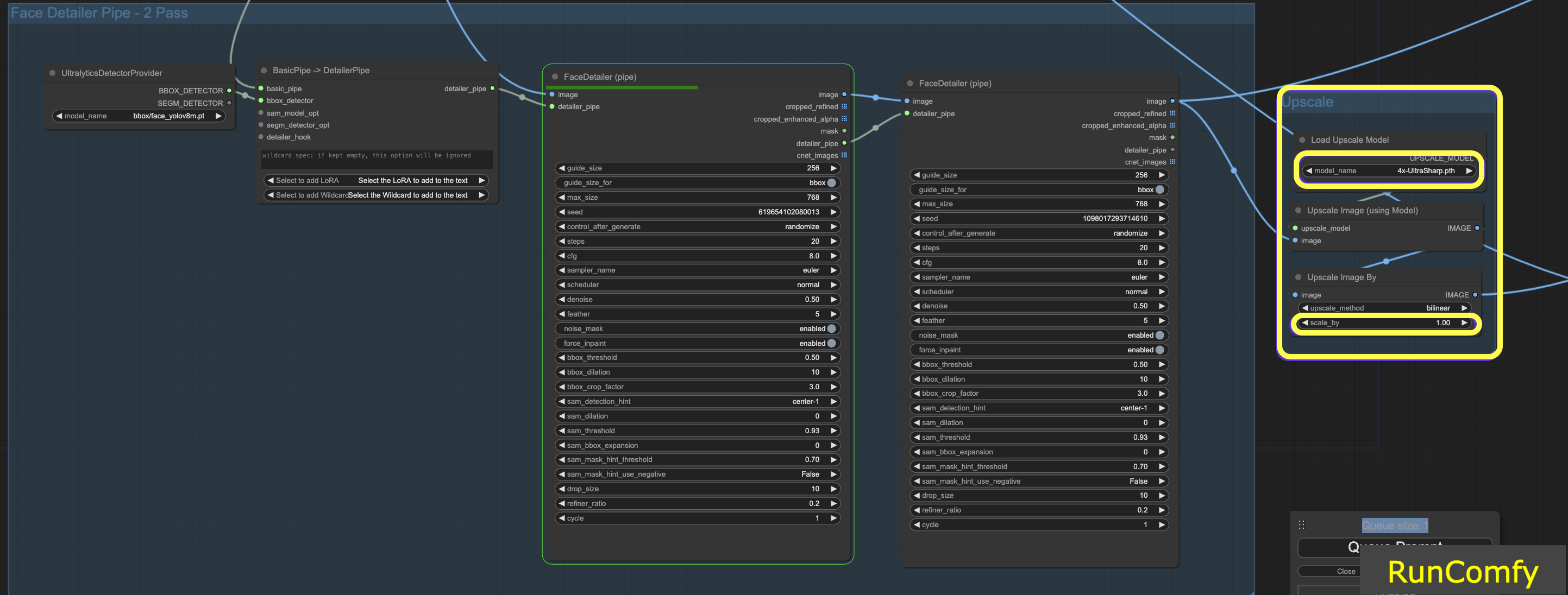
6.2 Agrandissement de la vidéo avec 4x-UltraSharp
Pour obtenir des résultats encore meilleurs, nous pouvons utiliser le nœud ultra sharp pour la mise à l'échelle. En redimensionnant l'image et en sélectionnant l'upscaler approprié, vous pouvez améliorer considérablement la qualité de l'image.
7. Exécuter le flux de travail Face Detailer ComfyUI gratuitement
C'est parti ! Avec le flux de travail Face Detailer ComfyUI, vous pouvez maintenant corriger les visages dans n'importe quelle vidéo et animation !
Vous avez hâte d'essayer le flux de travail Face Detailer ComfyUI dont nous avons discuté ? Pensez sérieusement à utiliser RunComfy, un environnement cloud équipé d'un puissant GPU. Il est entièrement préparé et comprend tout ce qui concerne le ComfyUI Impact Pack - Face Detailer, des modèles aux nœuds personnalisés. Aucune configuration manuelle n'est requise ! C'est votre terrain de jeu pour libérer cette étincelle créative.
Auteur : Éditeurs RunComfy
Notre équipe d'éditeurs travaille avec l'IA depuis plus de 15 ans, en commençant par le NLP/Vision à l'ère des RNN/CNN. Nous avons accumulé une énorme quantité d'expérience sur les chatbots/arts/animations d'IA, tels que BERT/GAN/Transformer, etc. Parlez-nous si vous avez besoin d'aide pour l'art, l'animation et la vidéo d'IA.