Workflow/Tutoriel AnimateDiff ComfyUI - Animation Stable Diffusion
Updated: 5/17/2024
Salut ! Avez-vous déjà été émerveillé par l'idée de transformer du texte en vidéos ? Ce n'est pas tout nouveau, mais ça devient de plus en plus excitant. Aujourd'hui, parlons d'un de ces outils sympas, AnimateDiff dans l'environnement ComfyUI. Que vous soyez un artiste numérique ou que vous aimiez simplement explorer les nouvelles technologies, AnimateDiff offre un moyen passionnant de transformer vos idées textuelles en GIF animés et en vidéos.
Nous aborderons :
- Comment fonctionne AnimateDiff ?
- Workflow AnimateDiff ComfyUI - Aucune installation requise, totalement gratuit
- AnimateDiff V3 vs. Animatediff SDXL vs. AnimateDiff v2
- AnimateDiff V3 : Nouveau module de mouvement dans Animatediff
- AnimateDiff SDXL
- AnimateDiff V2
- Paramètres AnimateDiff : Comment utiliser AnimateDiff dans ComfyUI
- Modèles AnimateDiff
- Modèles CheckPoint pour AnimateDiff
- Calendrier bêta
- Échelle de mouvement
- La taille du lot de contexte détermine la durée de l'animation
- Longueur du contexte
- LoRA de mouvement pour la dynamique de caméra (AnimateDiff v2 uniquement)
- Prompt AnimateDiff
- Voyage de prompt AnimateDiff / Planification de prompt
- ComfyUI Hires Fix - Améliorer vos animations
- Workflow AnimateDiff ComfyUI prêt à l'emploi : Explorer l'animation Stable Diffusion
1. Comment fonctionne AnimateDiff ?
Le cœur d'AnimateDiff est un module de modélisation du mouvement. Considérez-le comme le cerveau de l'opération, apprenant tout sur le mouvement à partir de diverses séquences vidéo. C'est comme avoir un professeur de danse qui connaît tous les mouvements du livre. Ce module s'intègre parfaitement aux modèles pré-entraînés de texte à image. Donc, vous n'êtes plus limité aux images statiques - vos créations peuvent danser, sauter et tourbillonner !
2. Workflow AnimateDiff ComfyUI - Aucune installation requise, totalement gratuit
Jetez un œil à la vidéo ci-dessus qui est créée en utilisant le workflow AnimateDiff ComfyUI. Maintenant, vous pouvez vous plonger directement dans ce Workflow Animatediff sans aucun tracas d'installation. Nous avons tout configuré pour vous dans un ComfyUI basé sur le cloud, complet avec le workflow AnimateDiff et tous les modèles et nœuds personnalisés essentiels d'Animatediff V3, Animatediff SDXL et Animatediff V2.
N'hésitez pas à expérimenter et à jouer avec. Ou vous pouvez continuer à lire ce tutoriel sur l'utilisation d'AnimateDiff et l'essayer plus tard.
3. AnimateDiff V3 vs. Animatediff SDXL vs. AnimateDiff v2
Faisons un tour des différentes versions d'AnimateDiff. Chaque version a son charme, alors préparez-vous pour un rapide tour d'horizon !
3.1. AnimateDiff V3 : Nouveau module de mouvement dans Animatediff
AnimateDiff V3 n'est pas juste une nouvelle version, c'est une évolution de la technologie des modules de mouvement, se distinguant par ses fonctionnalités raffinées. Le module de mouvement v3_sd15_mm.ckpt est le cœur de cette version, responsable des animations nuancées et flexibles.
Décomposons la magie technologique derrière. Le joueur vedette ici est le module Domain Adapter LoRA, qui est essentiellement un apprêt pour le module de mouvement. En s'entraînant sur des images statiques provenant de l'ensemble de données vidéo, ce module LoRA équipe AnimateDiff pour mieux gérer le mouvement. Plutôt cool, non ?
Lorsque vous utilisez AnimateDiff V3, vous remarquerez qu'il ne surpasse pas nécessairement Animatediff V2 dans tous les aspects. Au lieu de cela, il offre différents types de mouvements, ajoutant plus d'outils à votre arsenal créatif.
Prompt positif:chef-d'œuvre, meilleure qualité, fille aux cheveux arc-en-ciel, cheveux vraiment sauvages, crinière
Prompt négatif: (basse qualité, nsfw, pire qualité:1.4), (déformé, distordu, défiguré:1.3), easynegative, mains, bad-hands-5, flou, laid, texte, embedding:easynegative
CheckPoint:
toonyou_beta6
3.2. AnimateDiff SDXL
Si vous aimez les vidéos haute résolution, AnimateDiff SDXL pourrait être un choix. Fonctionnant sur le module de mouvement mm_sdxl_v10_beta.ckpt, il est conçu pour créer des animations de résolution 1024x1024 avec 16 images. Juste un avertissement cependant, il est toujours en version bêta, il serait donc peut-être sage d'attendre un peu avant de plonger.
Utilisez le même prompt positif et négatif qu'avec AnimateDiff V3
CheckPoint:
dreamshaperXL10_alpha2Xl10
3.3. AnimateDiff V2
AnimateDiff V2 est le classique ! Avec mm_sd_v15_v2.ckpt, cette version propose MotionLoRA pour huit mouvements de caméra essentiels : Zoom avant/arrière, Panoramique gauche/droite, Inclinaison haut/bas et Rotation dans le sens horaire/antihoraire. Animatediff V2 est parfait si vous recherchez des mouvements de caméra dynamiques pour ajouter du drame à vos animations.
Utilisez le même prompt positif et négatif qu'avec AnimateDiff V3
CheckPoint:
toonyou_beta6
4. Paramètres AnimateDiff : Comment utiliser AnimateDiff dans ComfyUI
Une fois que vous entrez dans le workflow AnimateDiff de ComfyUI, vous rencontrerez un groupe étiqueté "Options AnimateDiff" comme indiqué ci-dessous. Cette zone contient les paramètres et fonctionnalités que vous utiliserez probablement en travaillant avec AnimateDiff.
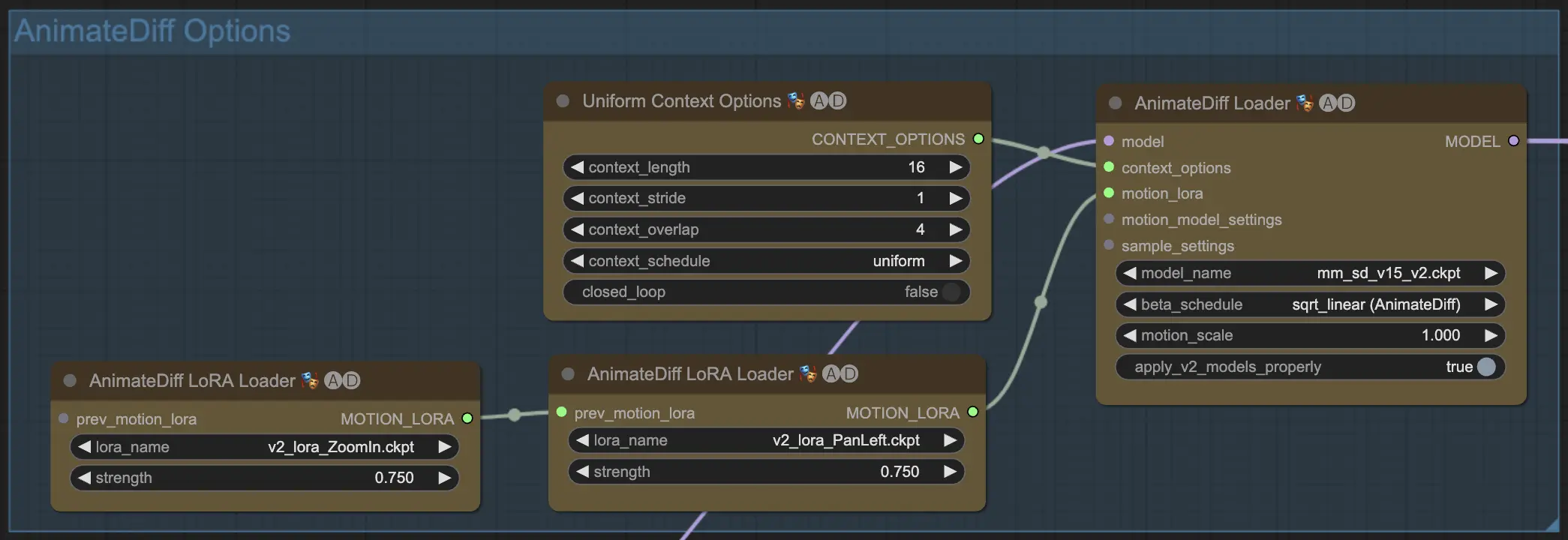
4.1. Modèles AnimateDiff
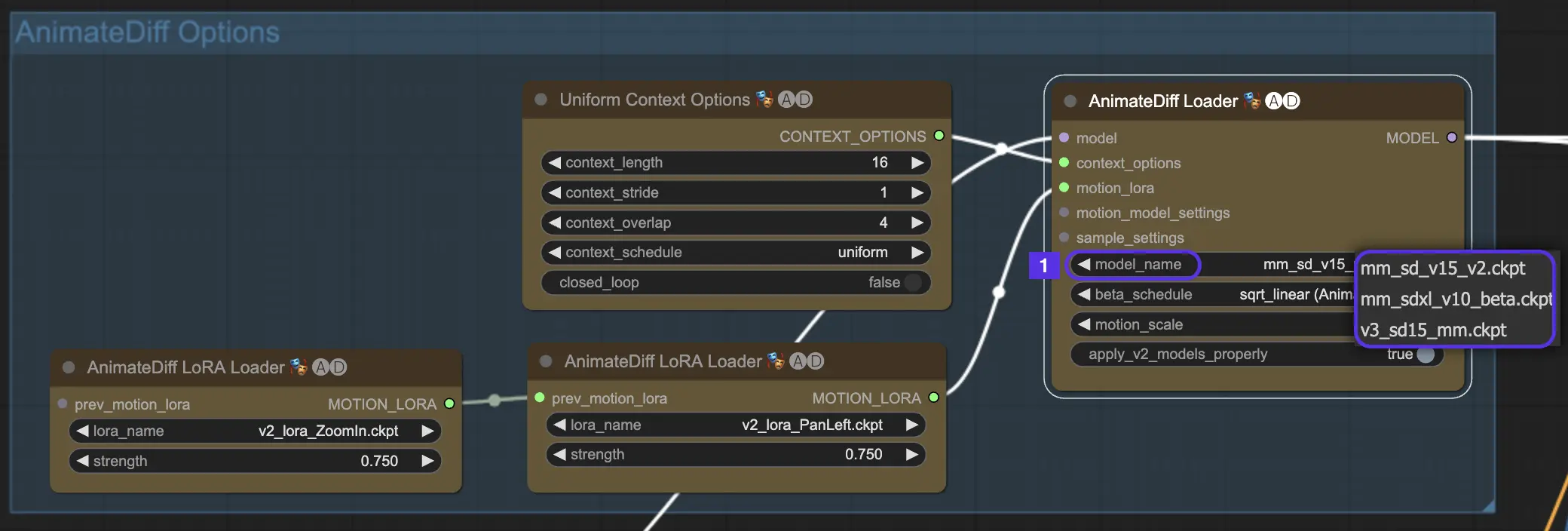
Avant toute chose, choisissez le module de mouvement AnimateDiff que vous voulez essayer dans la liste déroulante model_name :
v3_sd15_mm.ckptpour AnimateDiff V3mm_sdxl_v10_beta.ckptpour AnimateDiff SDXLmm_sd_v15_v2.ckptpour AnimateDiff V2
4.2. Modèles CheckPoint pour AnimateDiff
AnimateDiff a besoin d'un modèle Stable Diffusion chickpoint.
Pour AnimateDiff V2 et V3, vous devez utiliser un modèle SD v1.5. Les modèles comme realisticVisionV60B1_V51VAE , toonyou_beta6 et cardos_Animev2.0 sont des choix de premier ordre.
Si vous penchez plutôt pour AnimateDiff SDXL, visez un modèle SDXL, comme sd_xl_base_1.0 ou dreamshaperXL10_alpha2Xl10.
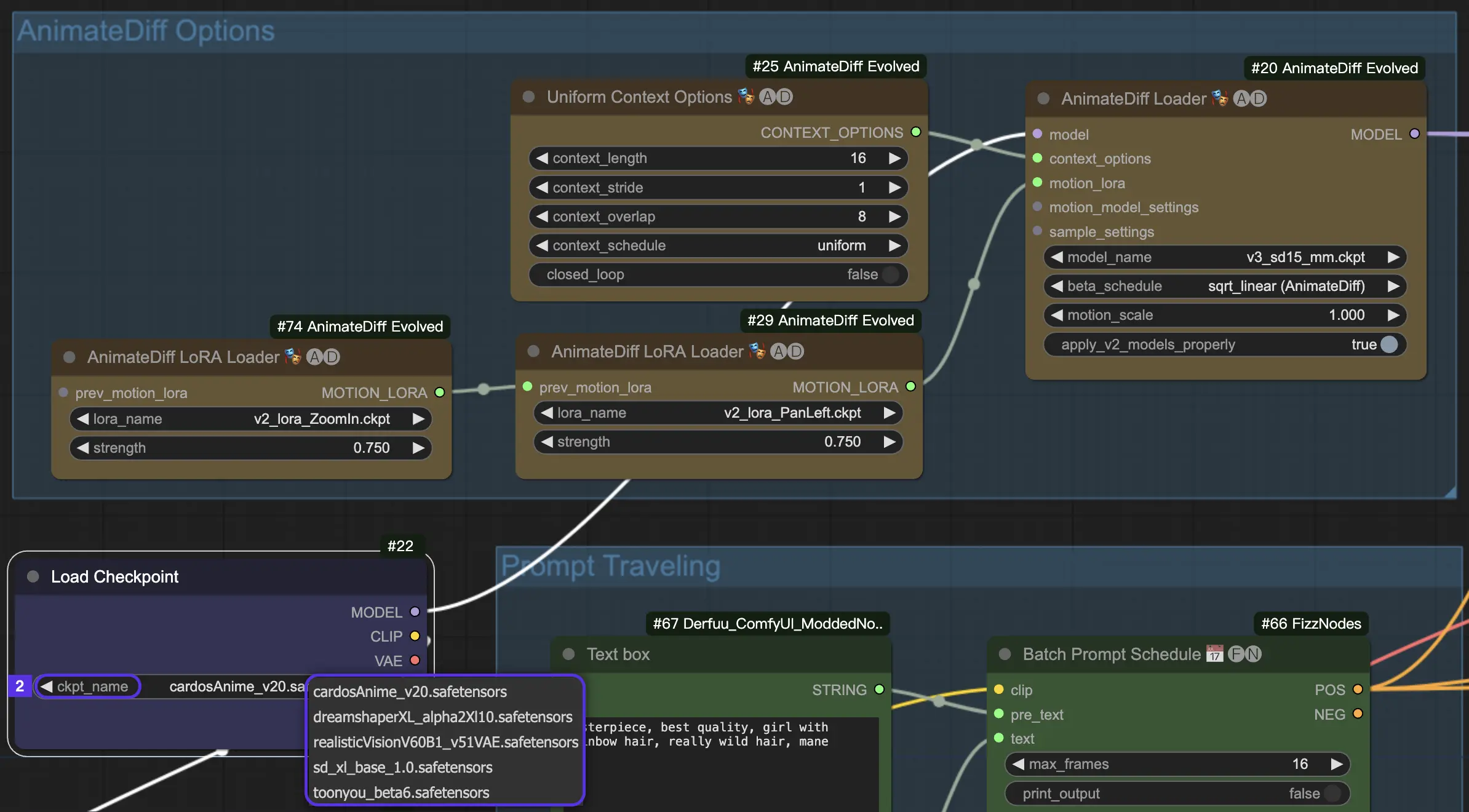
Dans l'environnement cloud RunComfy, tous les modules de mouvement et modèles checkpoint sont pré-installés pour votre commodité.
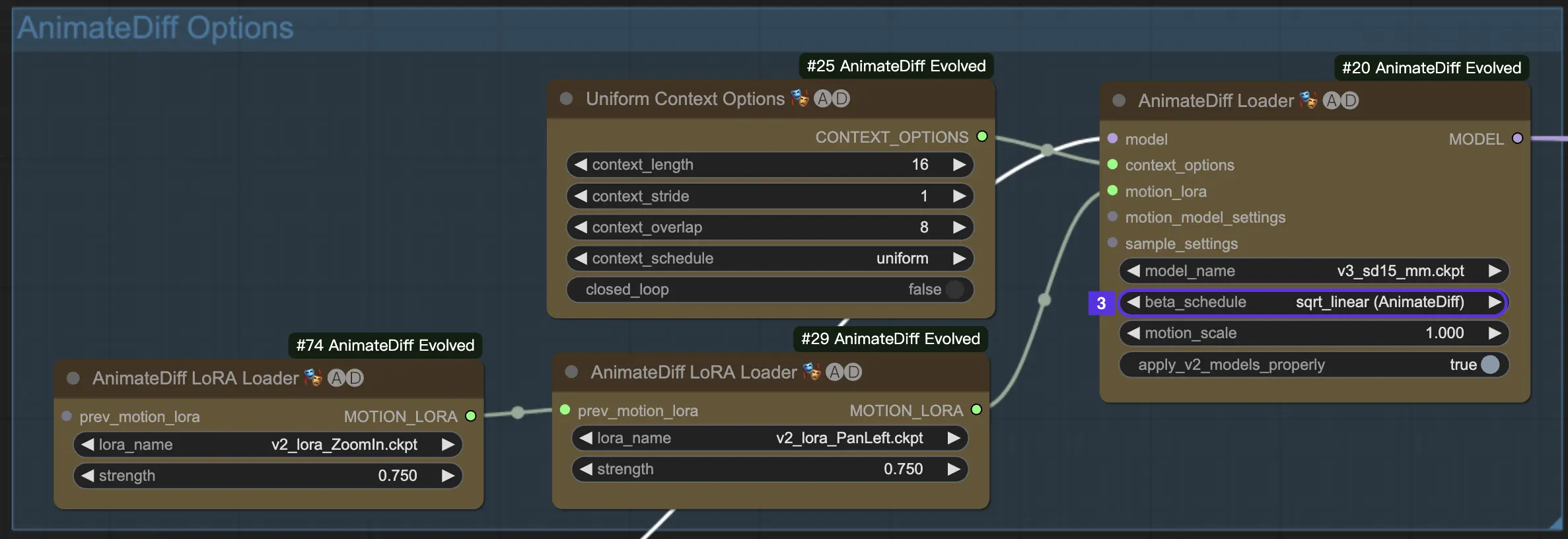
4.3. Calendrier bêta
Le calendrier bêta dans AnimateDiff détermine le comportement du processus de réduction du bruit pendant la génération de l'animation.
Pour AnimateDiff V3 et V2, le paramètre sqrt_linear est généralement la voie à suivre, mais n'hésitez pas à essayer linear pour des effets intéressants.
Pour AnimateDiff XL, restez sur linear (AnimateDiff-SDXL).
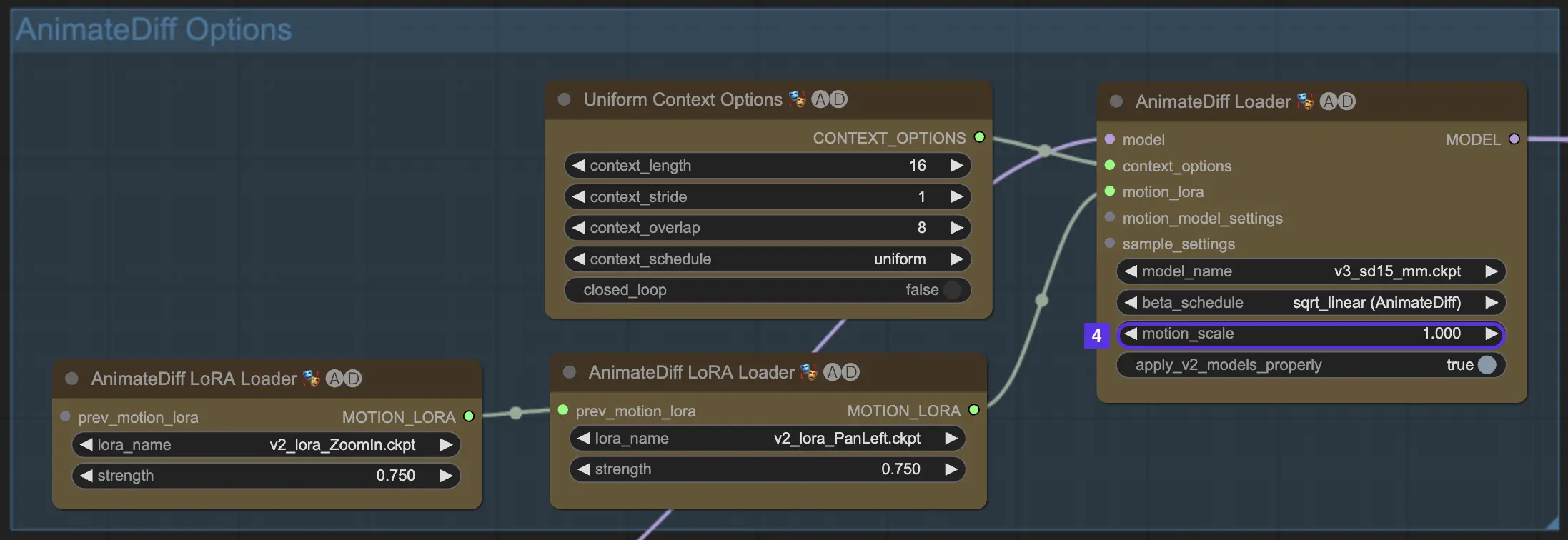
4.4. Échelle de mouvement
L'échelle de mouvement dans AnimateDiff vous permet de contrôler l'intensité du mouvement. En dessous de 1 signifie un mouvement plus subtil ; au-dessus de 1 signifie un mouvement plus prononcé.
4.5. La taille du lot de contexte détermine la durée de l'animation
La taille du lot dans AnimateDiff représente les blocs de construction de votre animation. Il sert de facteur fondamental influençant la durée de votre animation. Il détermine le nombre de "scènes" ou de segments dont votre animation sera composée.
Des tailles de lot plus grandes conduisent à plus de scènes dans votre animation, permettant une expérience de narration plus longue et plus élaborée. Il n'y a pas de limite supérieure à la taille du lot, vous êtes donc libre de créer des animations aussi longues ou courtes que vous le souhaitez. La taille de lot par défaut est de 16.
- Taille de lot 16 = Une vidéo rapide de 2 secondes
- Taille de lot 32 = Un bref clip de 4 secondes
- Taille de lot 64 = Une fonctionnalité étendue de 8 secondes

4.6. Longueur du contexte
La longueur de contexte uniforme dans AnimateDiff joue un rôle essentiel pour assurer des transitions fluides entre les scènes définies par votre taille de lot. C'est comme avoir un monteur qualifié qui sait exactement comment assembler les scènes pour obtenir le flux le plus naturel.
La longueur que vous définissez pour le contexte uniforme dictera la nature des transitions entre les scènes. Une longueur de contexte uniforme plus longue conduit à des transitions plus fluides et plus progressives, rendant le passage d'une scène à l'autre presque imperceptible. D'autre part, une longueur plus courte créera des transitions plus rapides et plus perceptibles, ce qui peut être idéal pour certains effets narratifs. La longueur de contexte uniforme par défaut est de 16.
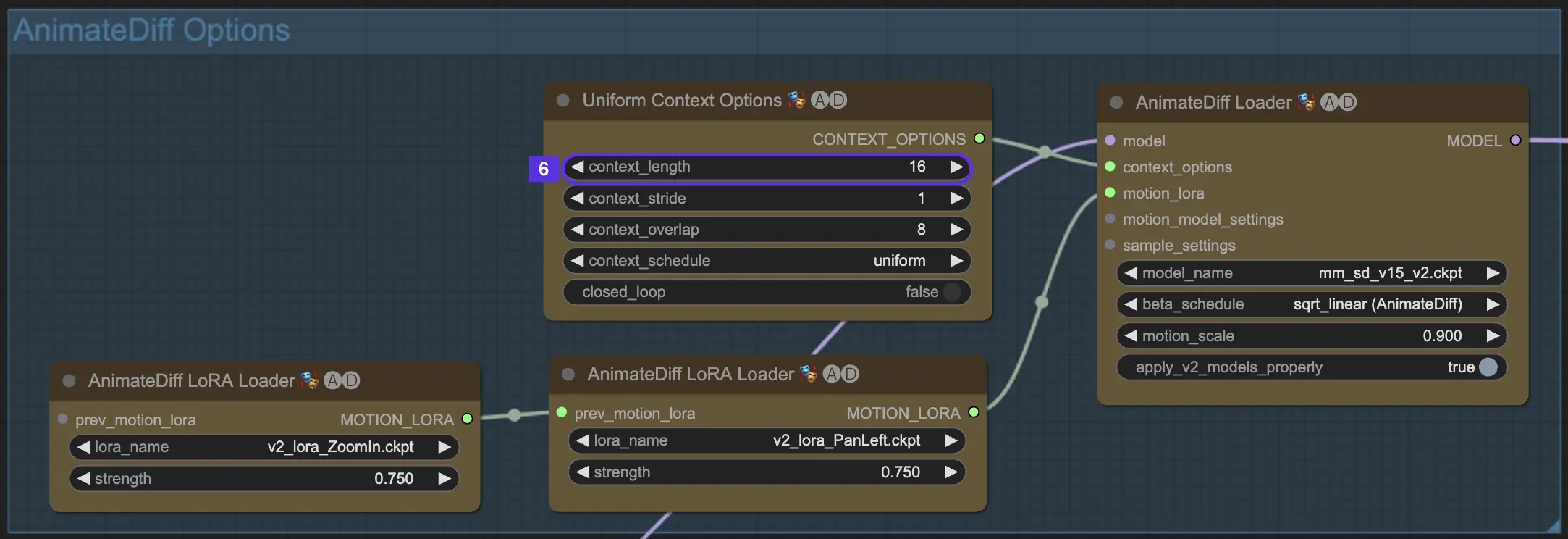
4.7. LoRA de mouvement pour la dynamique de caméra (AnimateDiff v2 uniquement)
Les LoRA de mouvement sont exclusivement compatibles avec AnimateDiff v2. Ces ajouts astucieux apportent une couche dynamique de mouvement de caméra à vos animations. Lors de l'utilisation des LoRA de mouvement, il est crucial de trouver le bon équilibre avec le poids LoRA. Le régler autour de 0,75 tend à atteindre le juste équilibre, vous donnant des mouvements de caméra fluides sans artefacts gênants en arrière-plan.
De plus, vous avez la liberté créative d'enchaîner plusieurs LoRA de mouvement. En combinant stratégiquement différents modèles LoRA de mouvement, vous pouvez orchestrer des mouvements de caméra complexes, expérimenter et trouver le mélange parfait de mouvements pour votre vision unique d'animation, élevant ainsi votre animation au rang de chef-d'œuvre cinématographique.
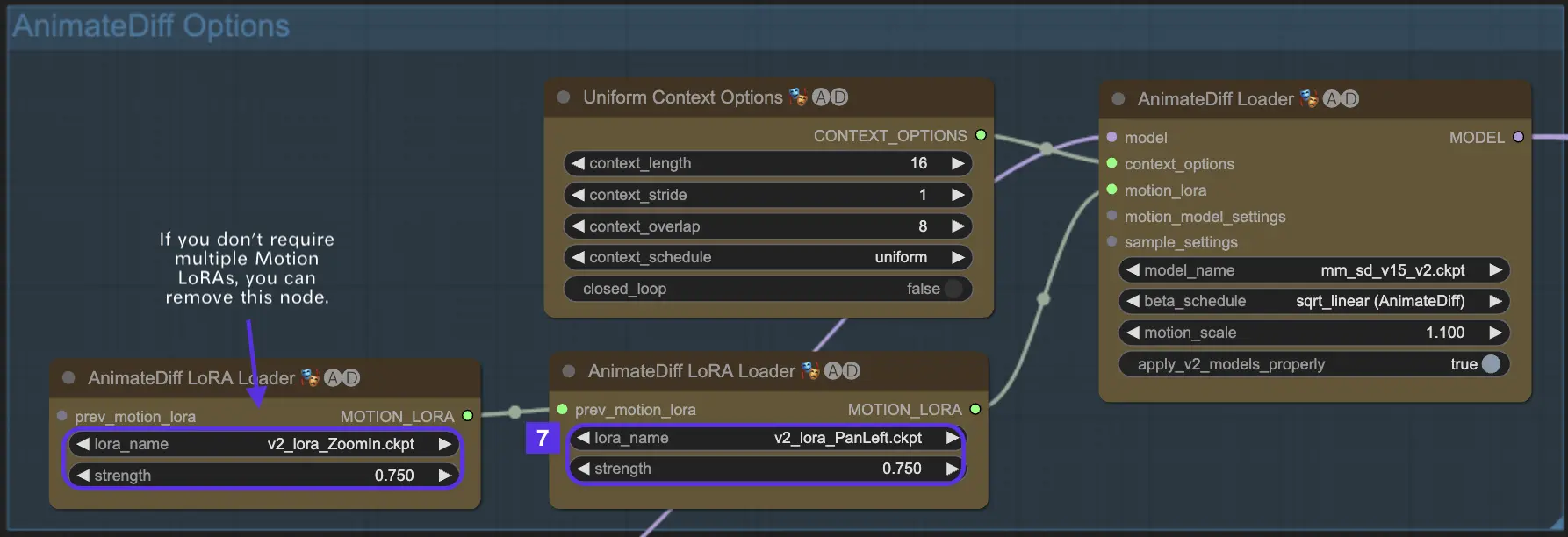
Voici un exemple d'utilisation conjointe des fonctionnalités "Pan Left" et "Zoom In" de Motion LoRa.
5. Prompt AnimateDiff
Bien, maintenant que vous avez réglé votre modèle et vos paramètres AnimateDiff, c'est l'heure du spectacle ! C'est là que vous transformez votre texte en animations vidéo.
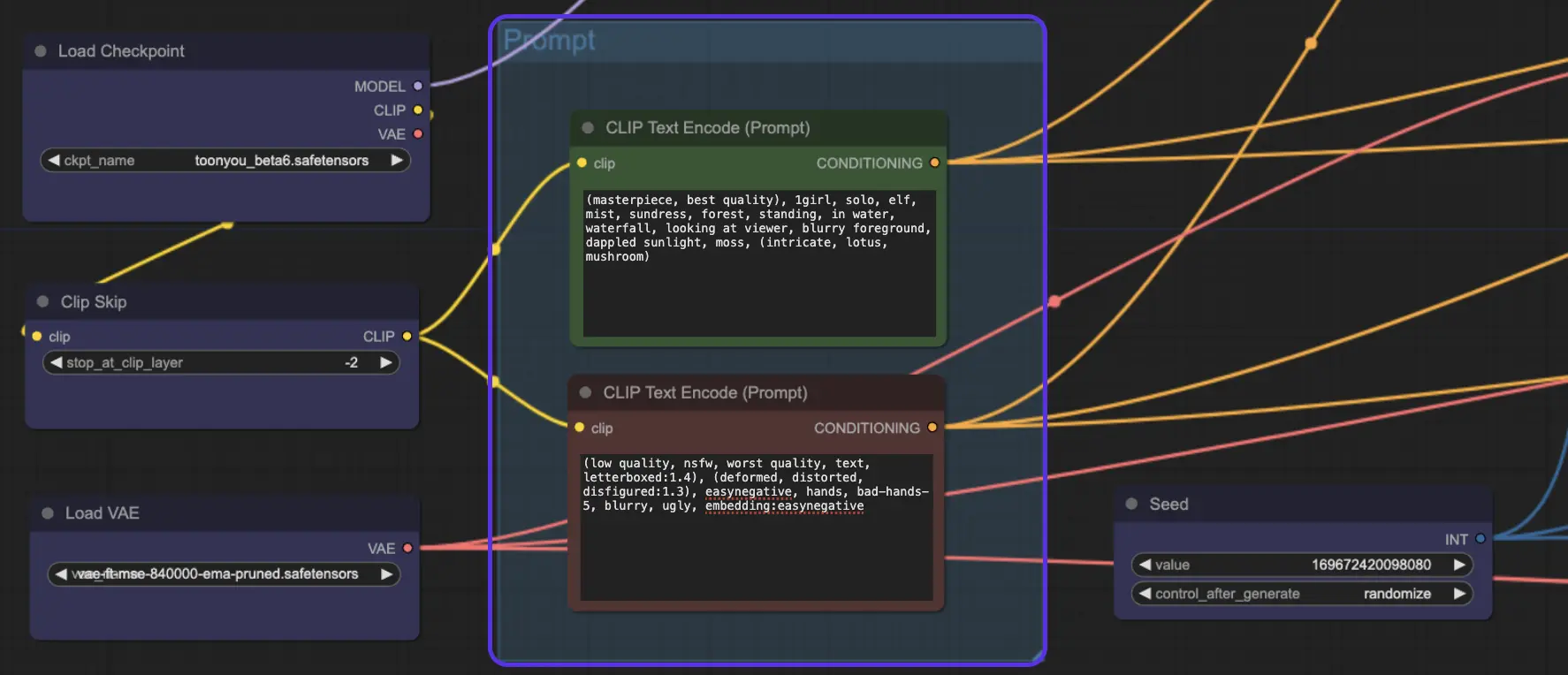
Voici un exemple de prompt positif et de prompt négatif :
Prompt positif:(chef-d'œuvre, meilleure qualité), 1girl, solo, elfe, brume, robe d'été, forêt, debout, dans l'eau, cascade, regardant le spectateur, premier plan flou, lumière du soleil tachetée, mousse, (intriqué, lotus, champignon)
Prompt négatif: (basse qualité, nsfw, pire qualité, texte, letterboxed:1.4), (déformé, distordu, défiguré:1.3), easynegative, mains, bad-hands-5, flou, laid, embedding:easynegative
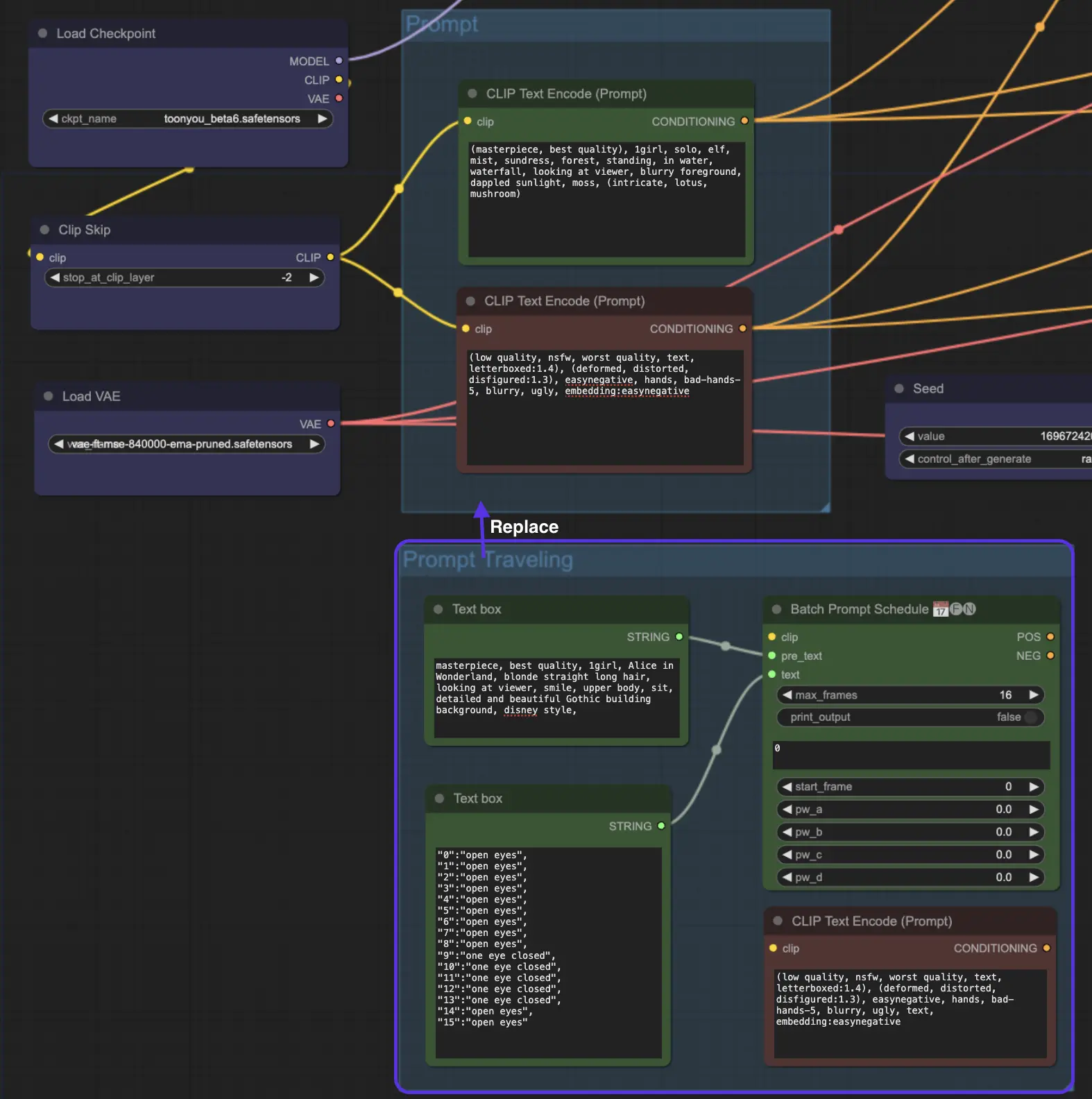
6. Voyage de prompt AnimateDiff / Planification de prompt
Mais attendez, il y a plus ! Avez-vous essayé le voyage de prompt / la planification de prompt ? Imaginez que vous endossez le rôle d'un réalisateur de cinéma. Vous avez le contrôle, créant votre histoire scène par scène. C'est comme assembler un puzzle où chaque pièce est un moment de votre histoire.
Comment fonctionne le voyage de prompt ?
Imaginez que vous créez un mini-film. Vous définissez le prompt 1 à l'image 1 et le prompt 2 à l'image 8, et ainsi de suite. AnimateDiff mélangera ces prompts de manière transparente, créant une transition fluide de l'image 1 à l'image 8.
Astuce : Bien que le voyage de prompt puisse être intriguant, il est important de noter qu'il n'est pas toujours un succès garanti. L'efficacité du voyage de prompt dépend également du modèle checkpoint que vous sélectionnez. Par exemple, le modèle cardos_Animev2.0 est compatible avec le voyage de prompt, mais ce n'est pas le cas pour tous les modèles. De plus, le résultat peut être imprévisible - certains prompts peuvent ne pas se mélanger correctement, entraînant des transitions moins qu'idéales. Cela fait du voyage de prompt une fonctionnalité plus expérimentale qu'un outil garanti pour une animation fluide.
Nous avons placé le nœud "Voyage de prompt / Planification de prompt" à la fin du workflow AnimateDiff ComfyUI. Si vous êtes curieux d'expérimenter, vous devrez utiliser "Voyage de prompt" à la place de l'option "Prompt" standard.
7. ComfyUI Hires Fix - Améliorer vos animations
En utilisant AnimateDiff avec le correctif Hi-Res, vous pouvez améliorer la résolution de vos images. Ce processus transforme des images légèrement floues en chefs-d'œuvre d'une clarté cristalline. Dans cette section, nous présenterons deux méthodes.
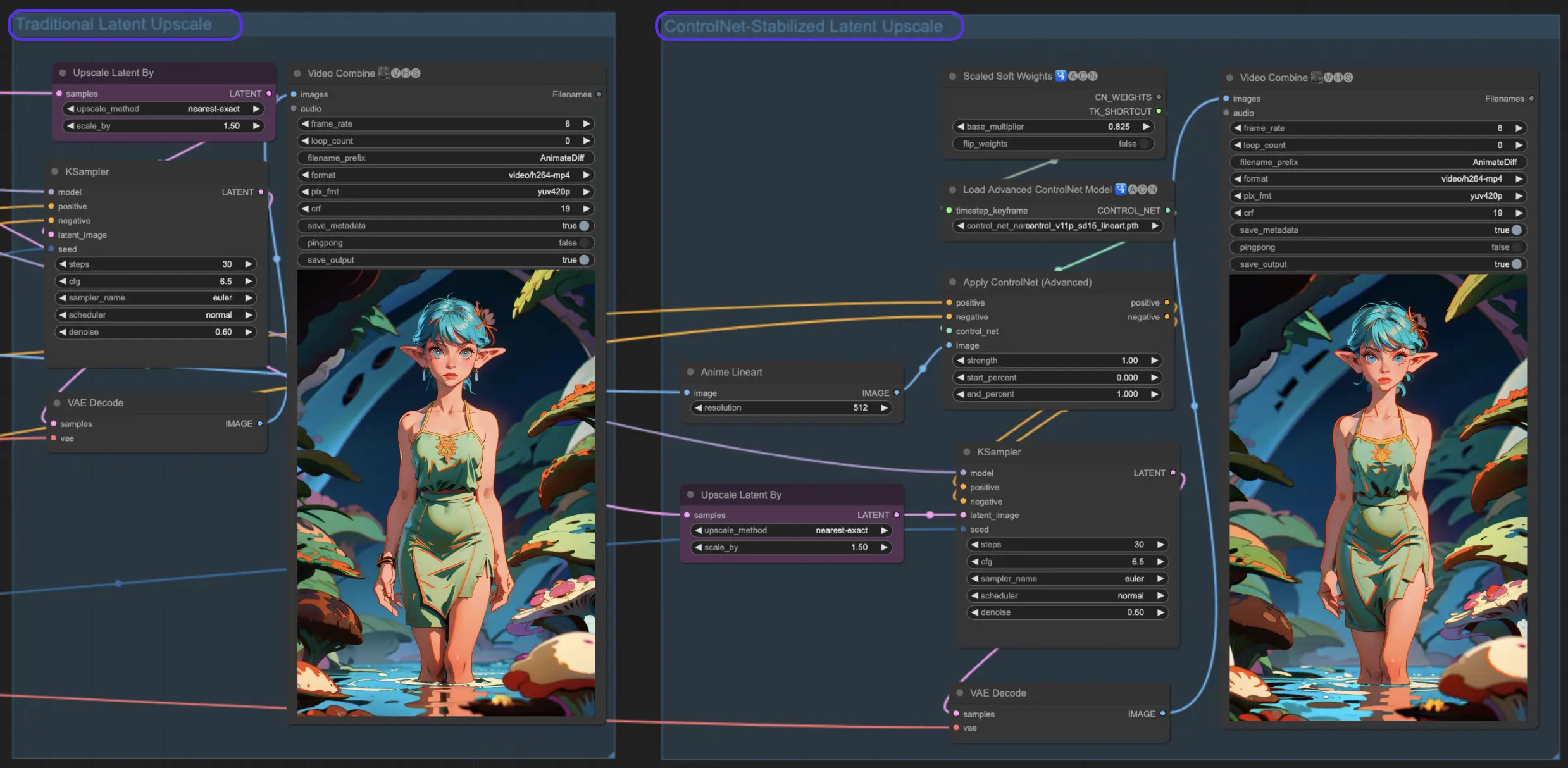
7.1. Mise à l'échelle latente
La mise à l'échelle latente traditionnelle dans ComfyUI. En appliquant des paramètres comme une force de débruitage de 0,6 et en choisissant une mise à l'échelle de 1,5x, vous verrez vos animations se transformer avec des détails plus riches et une clarté plus nette. C'est comme mettre des lunettes et soudain voir le monde en haute définition !
7.2. Mise à l'échelle ControlNet
La mise à l'échelle latente traditionnelle est cool, mais passons au niveau supérieur avec la mise à l'échelle latente assistée par Control Net. Elle utilise ControlNets pour une mise à l'échelle plus précise, garantissant que votre animation conserve son intégrité. Avec l'ajout d'un préprocesseur de dessin au trait et du bon modèle controlnet, vous améliorerez votre art tout en conservant son âme intacte.
8. Workflow AnimateDiff ComfyUI prêt à l'emploi : Explorer l'animation Stable Diffusion
Nous avons plongé dans le monde passionnant d'AnimateDiff dans ComfyUI. Pour ceux qui sont impatients d'expérimenter le workflow AnimateDiff ComfyUI que nous avons mis en avant, essayez définitivement RunComfy, un environnement cloud équipé d'un puissant GPU et entièrement préparé, comprenant tout, des modèles essentiels aux nœuds personnalisés. Pas besoin de configuration manuelle ! Juste un terrain de jeu pour libérer votre créativité. 🌟
Auteur : Éditeurs RunComfy
Notre équipe d'éditeurs travaille avec l'IA depuis plus de 15 ans, en commençant par le NLP/Vision à l'ère du RNN/CNN. Nous avons amassé une énorme expérience sur le chatbot/art/animation AI, comme BERT/GAN/Transformer, etc. Parlez-nous si vous avez besoin d'aide sur l'art, l'animation et la vidéo AI.