AnimateDiff + IPAdapter V1 | Image vers Vidéo
IPAdapter est une solution légère qui améliore les modèles pré-entraînés avec des capacités d'incitation d'image. En utilisant AnimateDiff aux côtés d'IPAdapter, vous pouvez facilement générer des animations plus contrôlables à partir d'images de référence.Flux de travail ComfyUI AnimateDiff IPAdapter
- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
Exemples ComfyUI AnimateDiff IPAdapter
Description ComfyUI AnimateDiff IPAdapter
1. Workflow ComfyUI : AnimateDiff + IPAdapter | Image vers Vidéo
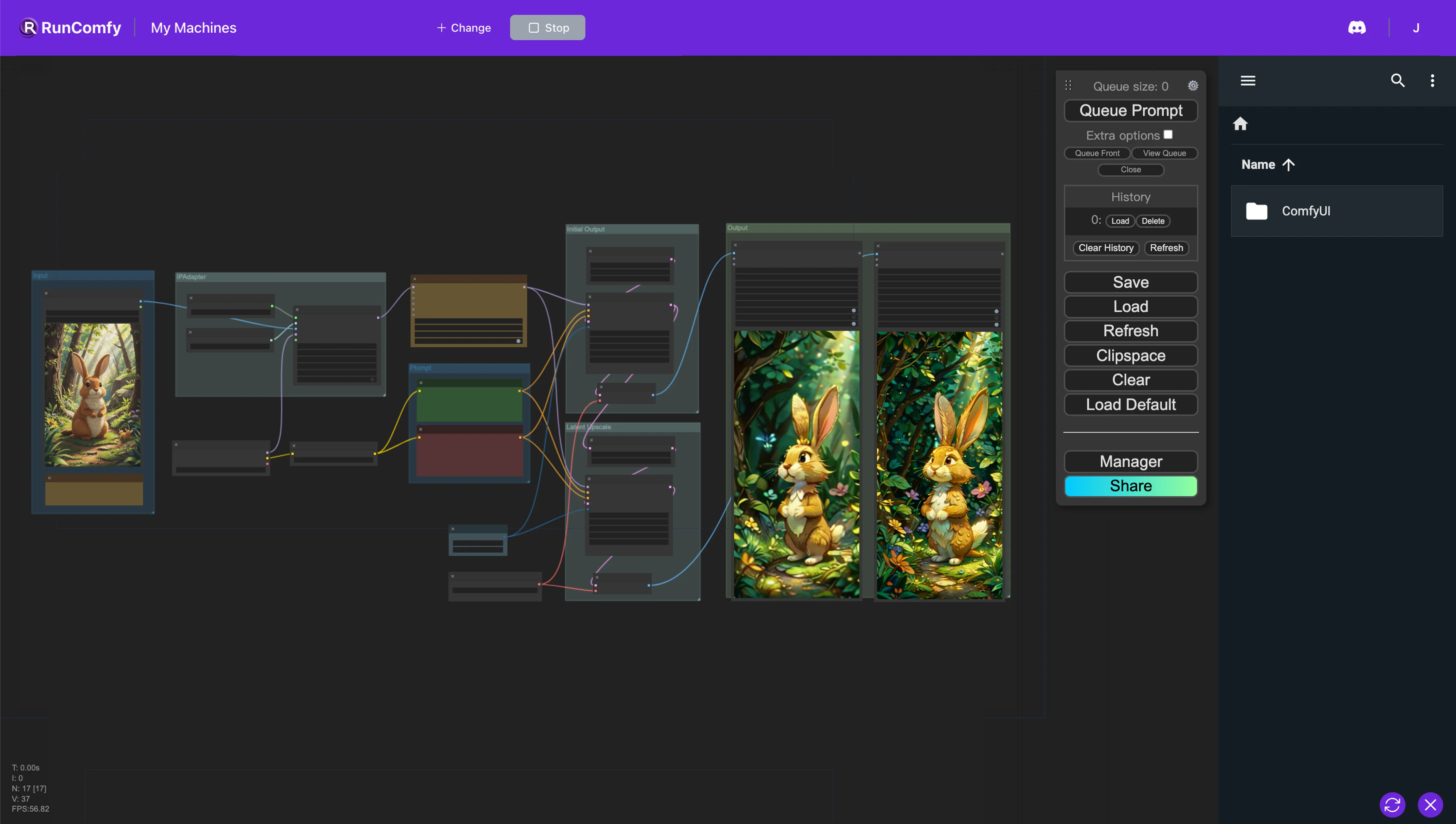
Ce workflow ComfyUI est conçu pour créer des animations à partir d'images de référence en utilisant AnimateDiff et IP-Adapter. Le nœud AnimateDiff intègre des options de modèle et de contexte pour ajuster la dynamique d'animation. Inversement, le nœud IP-Adapter facilite l'utilisation d'images comme invites de manière à imiter le style, la composition ou les caractéristiques faciales de l'image de référence, améliorant considérablement la personnalisation et la qualité des animations ou des images générées.
2. Aperçu d'AnimateDiff
Veuillez consulter les détails sur
3. Aperçu d'IP-Adapter
3.1. Introduction à IP-Adapter
IP-Adapter signifie "Adaptateur d'Invite d'Image", une nouvelle approche pour améliorer les modèles de diffusion de texte en image avec la capacité d'utiliser des invites d'image dans les tâches de génération d'image. IP-Adapter vise à remédier aux lacunes des invites de texte qui nécessitent souvent une ingénierie complexe des invites pour générer les images souhaitées. L'introduction d'invites d'image, parallèlement au texte, permet un moyen plus intuitif et efficace de guider le processus de synthèse d'image.
Différents Modèles d'IP-Adapter
La suite IP-Adapter comprend une variété de modèles, chacun adapté à des cas d'utilisation spécifiques et à des niveaux de complexité de synthèse d'image. Voici un aperçu des différents modèles disponibles :
3.1.1. Modèles v1.5
ip-adapter_sd15: Le modèle standard pour la version 1.5, qui utilise la puissance d'IP-Adapter pour le conditionnement d'image à image et l'augmentation d'invite de texte.ip-adapter_sd15_light: Une version plus légère du modèle standard, optimisée pour les applications moins gourmandes en ressources tout en exploitant la technologie IP-Adapter.ip-adapter-plus_sd15: Un modèle amélioré qui produit des images plus proches de la référence d'origine, améliorant les détails fins.ip-adapter-plus-face_sd15: Similaire à IP-Adapter Plus, avec un accent sur une réplication plus précise des caractéristiques faciales dans les images générées.ip-adapter-full-face_sd15: Un modèle qui met l'accent sur les détails du visage complet, offrant probablement un effet de "permutation de visage" avec une haute fidélité.ip-adapter_sd15_vit-G: Une variante du modèle standard utilisant l'encodeur d'image Vision Transformer (ViT) BigG pour une extraction plus détaillée des caractéristiques de l'image.
3.1.2. Modèles SDXL
ip-adapter_sdxl: Le modèle de base pour le SDXL, qui est conçu pour gérer des invites d'image plus grandes et plus complexes.ip-adapter_sdxl_vit-h: Le modèle SDXL associé à l'encodeur d'image ViT H, équilibrant les performances avec l'efficacité de calcul.ip-adapter-plus_sdxl_vit-h: Une version avancée du modèle SDXL avec des détails d'invite d'image et une qualité améliorés.ip-adapter-plus-face_sdxl_vit-h: Une variante SDXL axée sur les détails du visage, idéale pour les projets où la précision du visage est primordiale.
3.1.3. Modèles FaceID
FaceID: Un modèle utilisant InsightFace pour extraire les incorporations Face ID, offrant une approche unique de la génération d'images liées au visage.FaceID Plus: Une version améliorée du modèle FaceID, combinant InsightFace pour les caractéristiques faciales et l'encodage d'image CLIP pour les caractéristiques faciales globales.FaceID Plus v2: Une itération sur FaceID Plus avec un point de contrôle de modèle amélioré et la capacité de définir un poids sur l'incorporation d'image CLIP.FaceID Portrait: Un modèle similaire à FaceID mais conçu pour accepter plusieurs images de visages recadrés pour un conditionnement de visage plus diversifié.
3.1.4. Modèles SDXL FaceID
FaceID SDXL: La version SDXL de FaceID, conservant le même modèle InsightFace que la v1.5 mais adapté aux applications SDXL.FaceID Plus v2 SDXL: Une adaptation SDXL de FaceID Plus v2 pour la génération d'images haute définition avec une fidélité améliorée.
3.2. Caractéristiques Clés d'IP-Adapter
3.2.1. Intégration d'Invite de Texte et d'Image : La capacité unique d'IP-Adapter à utiliser à la fois des invites de texte et d'image permet une génération d'image multimodale, fournissant un outil polyvalent et puissant pour contrôler les sorties de modèle de diffusion.
3.2.2. Mécanisme d'Attention Croisée Découplée : L'IP-Adapter emploie une stratégie d'attention croisée découplée qui améliore l'efficacité du modèle dans le traitement de diverses modalités en séparant les caractéristiques de texte et d'image.
3.2.3. Modèle Léger : Malgré sa fonctionnalité complète, l'IP-Adapter maintient un nombre de paramètres relativement faible (22M), offrant des performances qui rivalisent ou dépassent celles des modèles d'invite d'image fine-tunés.
3.2.4. Compatibilité et Généralisation : L'IP-Adapter est conçu pour une large compatibilité avec les outils contrôlables existants et peut être appliqué aux modèles personnalisés dérivés du même modèle de base pour une meilleure généralisation.
3.2.5. Contrôle de Structure : IP-Adapter prend en charge un contrôle détaillé de la structure, permettant aux créateurs de guider le processus de génération d'image avec une plus grande précision.
3.2.6. Capacités d'Image à Image et de Peinture : Avec la prise en charge de la traduction image à image guidée par image et de la peinture, l'IP-Adapter élargit le champ des applications possibles, permettant des utilisations créatives et pratiques dans une variété de tâches de synthèse d'image.
3.2.7. Personnalisation avec Différents Encodeurs : L'IP-Adapter permet l'utilisation de divers encodeurs, tels que OpenClip ViT H 14 et ViT BigG 14, pour traiter les images de référence. Cette flexibilité facilite la gestion de différentes résolutions et complexités d'images, ce qui en fait un outil polyvalent pour les créateurs cherchant à adapter le processus de génération d'images à des besoins spécifiques ou à des résultats souhaités.
L'incorporation de la technologie IP-Adapter dans les projets de génération d'images non seulement simplifie la création d'images complexes et détaillées, mais améliore également considérablement la qualité et la fidélité des images générées aux invites d'origine. En comblant le fossé entre les invites de texte et d'image, IP-Adapter fournit une approche puissante, intuitive et efficace pour contrôler les nuances de la synthèse d'image, ce qui en fait un outil indispensable dans l'arsenal des artistes numériques, des concepteurs et des créateurs travaillant dans le workflow ComfyUI ou tout autre contexte qui exige une génération d'image personnalisée de haute qualité.
