Linear Mask Dilation | Animazioni Straordinarie
ComfyUI Linear Mask Dilation è un potente workflow per creare straordinarie animazioni video. Trasformando il tuo soggetto, come un ballerino, puoi farlo viaggiare senza soluzione di continuità attraverso diverse scene utilizzando un effetto di dilatazione della maschera. Questo workflow è specificamente progettato per video con un singolo soggetto. Segui la guida passo dopo passo per imparare a utilizzare Linear Mask Dilation in modo efficace, dall'upload del video del soggetto all'impostazione dei prompt e alla regolazione di vari parametri per risultati ottimali. Liberate la vostra creatività e date vita alle vostre animazioni video con ComfyUI Linear Mask Dilation.ComfyUI Linear Mask Dilation Flusso di lavoro
Vuoi eseguire questo workflow?
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Linear Mask Dilation Esempi
ComfyUI Linear Mask Dilation Descrizione
ComfyUI Linear Mask Dilation
Crea straordinarie animazioni video trasformando il tuo soggetto (ballerino) e falli viaggiare attraverso diverse scene tramite un effetto di dilatazione della maschera. Questo workflow è progettato per essere utilizzato con video di un singolo soggetto.
Come utilizzare il workflow ComfyUI Linear Mask Dilation:
- Carica un video del soggetto nella sezione Input
- Seleziona la larghezza e l'altezza desiderate del video finale, insieme a quanti fotogrammi del video di input devono essere saltati con "every_nth". Puoi anche limitare il numero totale di fotogrammi da renderizzare con "frame_load_cap".
- Compila il prompt positivo e negativo. Imposta i tempi dei fotogrammi batch per corrispondere al momento in cui desideri che avvengano le transizioni di scena.
- Carica le immagini per ciascun colore della maschera del soggetto IP Adapter:
- Bianco = soggetto (ballerino)
- Nero = Primo sfondo
- Rosso = Sfondo della maschera di dilatazione rossa
- Verde = Sfondo della maschera di dilatazione verde
- Blu = Sfondo della maschera di dilatazione blu
- Carica un buon checkpoint LCM (io uso ParadigmLCM di Machine Delusions) nella sezione "Models".
- Aggiungi eventuali loras utilizzando il Lora stacker sotto il caricatore del modello
- Premi Queue Prompt
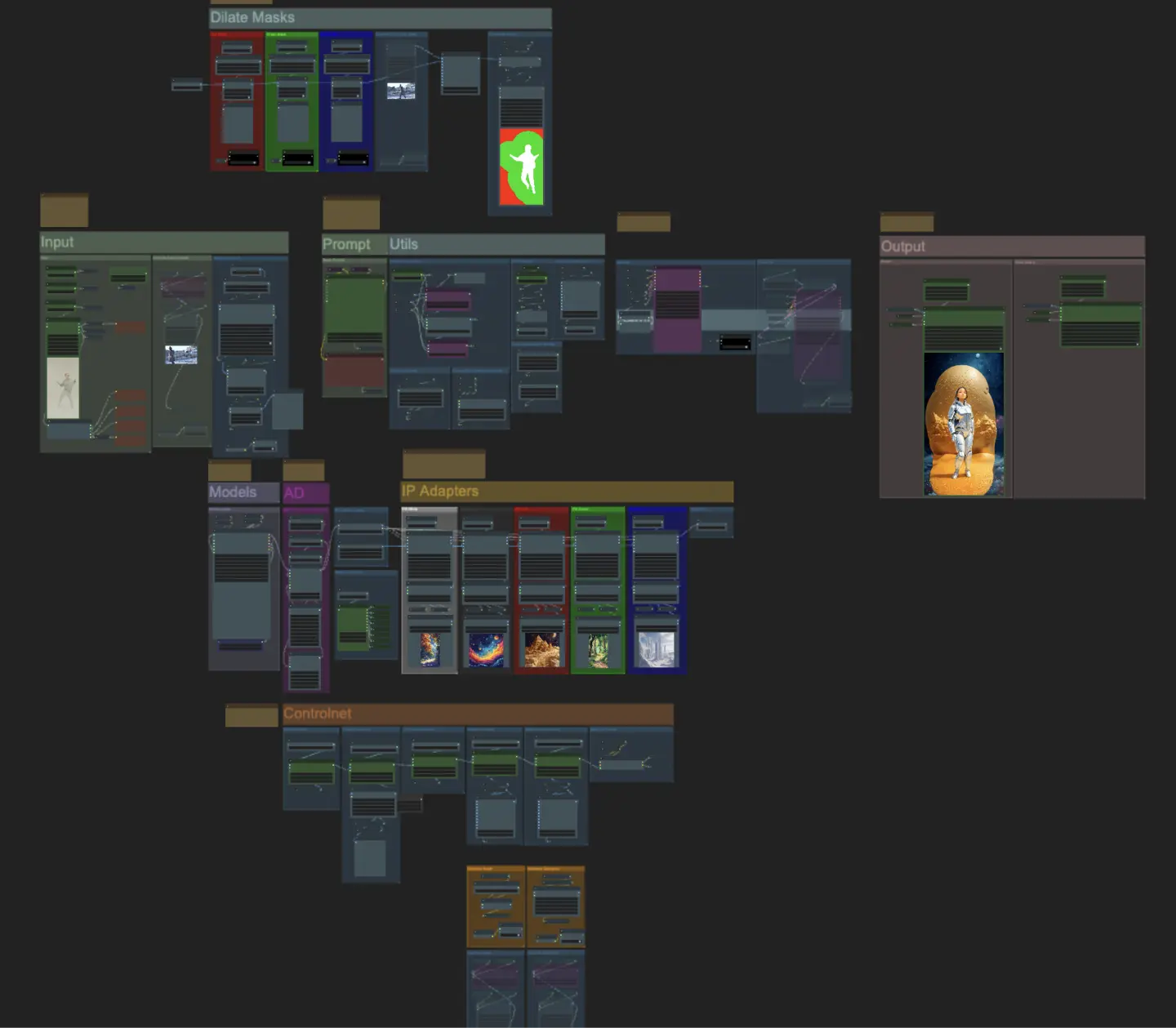
Input
- Puoi regolare la larghezza e l'altezza utilizzando i due input in alto a sinistra
- every_nth imposta quanti fotogrammi dell'input devono essere saltati (2 = ogni altro fotogramma)
- I campi numerici in basso a sinistra visualizzano le informazioni sul video di input caricato: fotogrammi totali, larghezza, altezza e FPS dall'alto verso il basso.
- Se hai già un video della maschera del soggetto generato (deve essere soggetto bianco su sfondo nero), puoi disattivare la sezione "Override Subject Mask" e caricare il video della maschera. Facoltativamente, puoi disattivare la sezione "Segment Subject" per risparmiare tempo di elaborazione.
- A volte il soggetto segmentato non sarà perfetto, puoi controllare la qualità della maschera utilizzando la casella di anteprima in basso a destra come visto sopra. Se questo è il caso, puoi giocare con il prompt nel nodo "Florence2Run" per mirare a diverse parti del corpo come "testa", "petto", "gambe", ecc. e vedere se ottieni un risultato migliore.
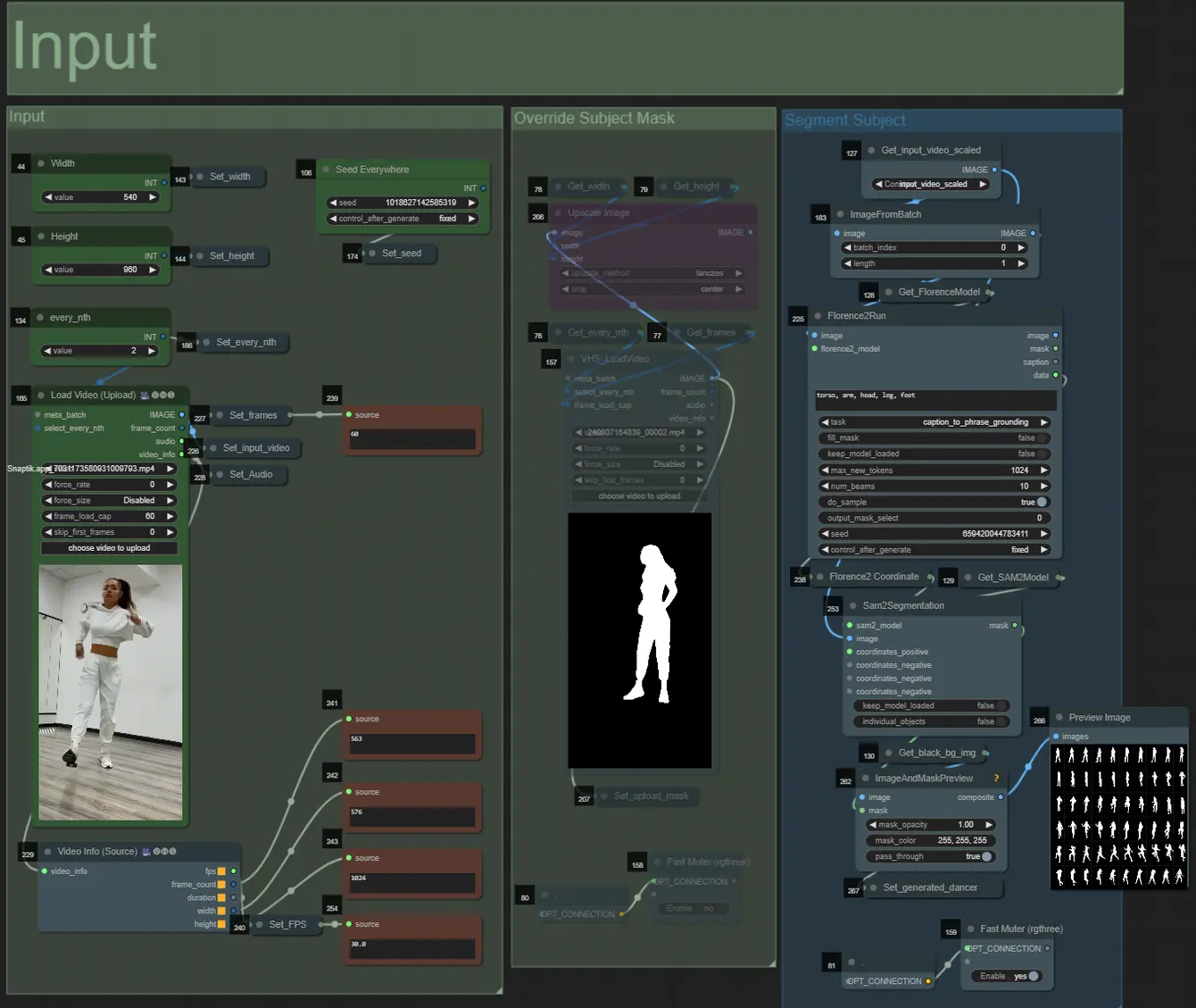
Prompt
- Imposta il prompt positivo utilizzando la formattazione batch:
- es. "0": "4k, masterpiece, 1girl standing on the beach, absurdres", "25": "HDR, sunset scene, 1girl with black hair and a white jacket, absurdres", ...
- Il prompt negativo è in formato normale, puoi aggiungere embedding se desiderato.
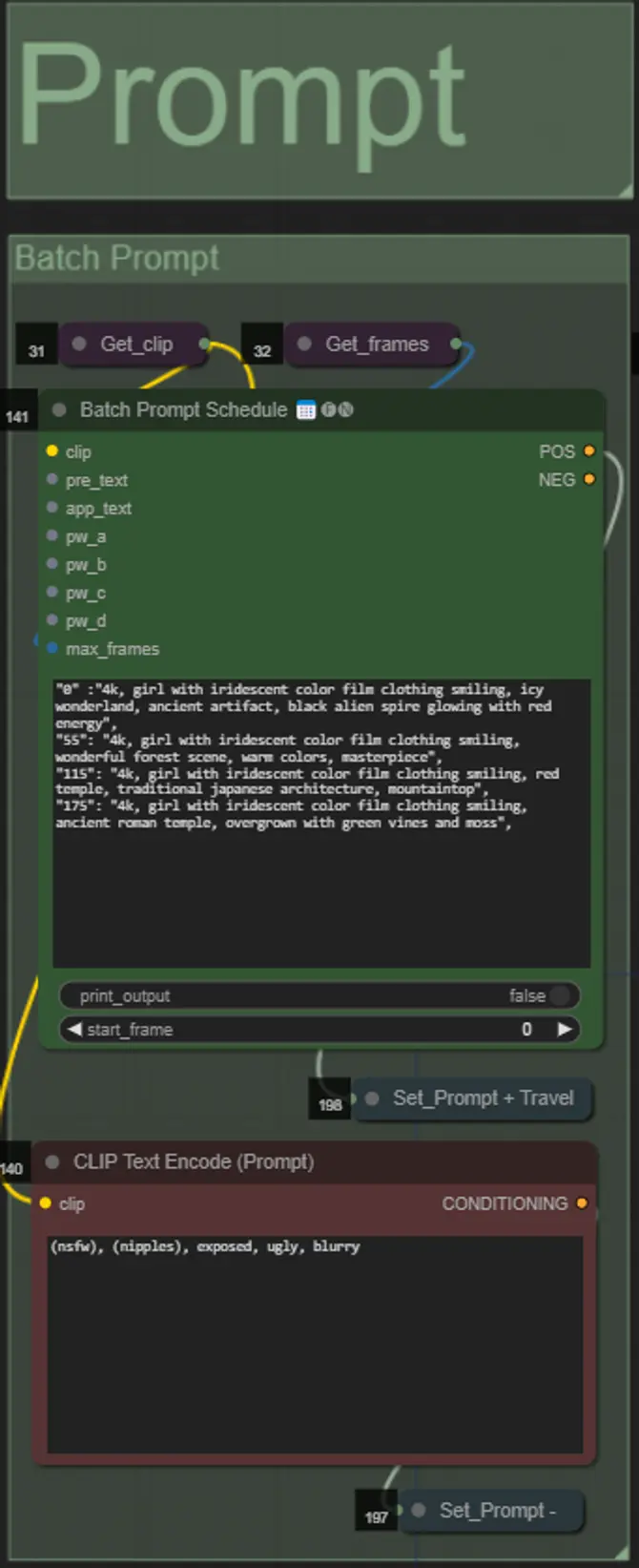
Mask Dilations
- Ogni gruppo colorato corrisponde al colore della maschera di dilatazione che verrà generato.
- Puoi impostare la forma della maschera, insieme alla velocità di dilatazione e al ritardo dei fotogrammi con il seguente nodo:
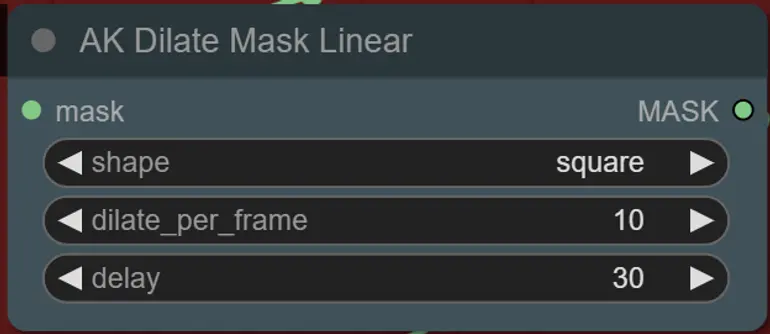
- forma: "circle" è la più accurata ma richiede più tempo per essere generata. Imposta questa opzione quando sei pronto per eseguire il rendering finale. "square" è veloce da calcolare ma meno accurata, ideale per testare il workflow e decidere sulle immagini IP adapter.
- dilate_per_frame: Quanto rapidamente la maschera dovrebbe dilatarsi, numeri più grandi = maggiore velocità di dilatazione
- delay: Quanti fotogrammi attendere prima che la maschera inizi a dilatarsi.
- Se hai già un video della maschera composita generato, puoi disattivare il gruppo "Override Composite Mask" e caricarlo. Si consiglia di bypassare i gruppi di maschere di dilatazione se si sovrascrive per risparmiare tempo di elaborazione.
Models
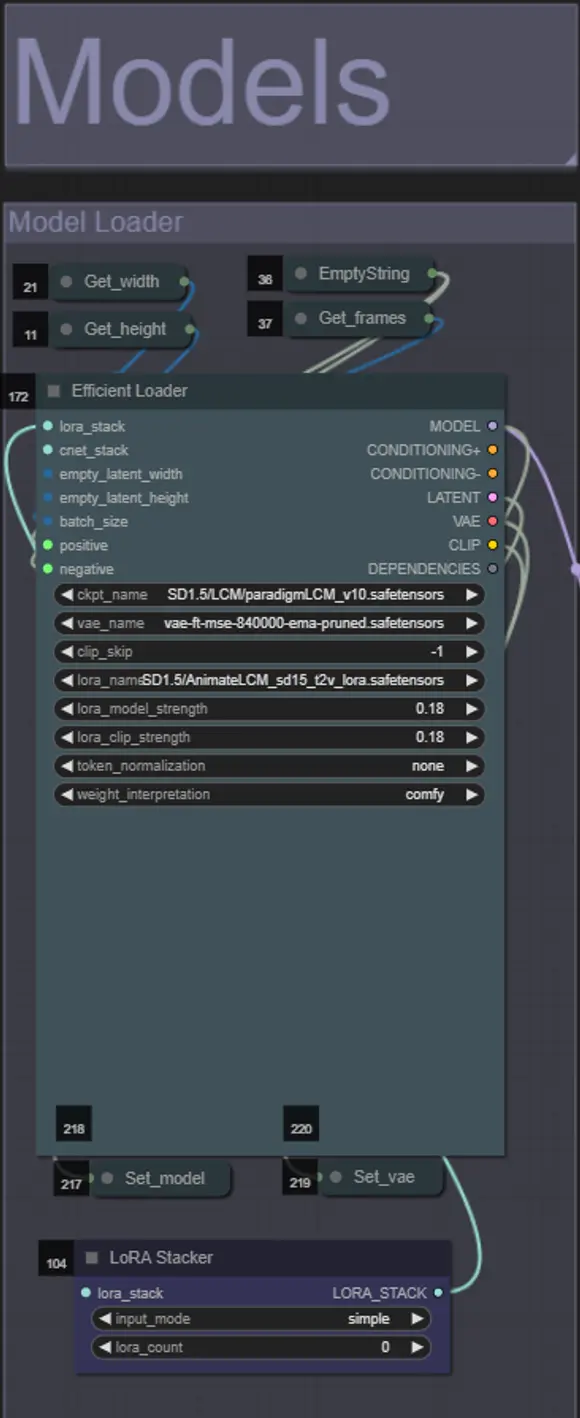
- Usa un buon modello LCM per il checkpoint. Raccomando ParadigmLCM di Machine Delusions.
- Puoi opzionalmente specificare AnimateLCM_sd15_t2v_lora.safetensors con un peso basso di 0.18 per migliorare ulteriormente il risultato finale.
- Aggiungi eventuali ulteriori Loras al modello utilizzando il Lora stacker blu sotto il caricatore del modello.
AnimateDiff
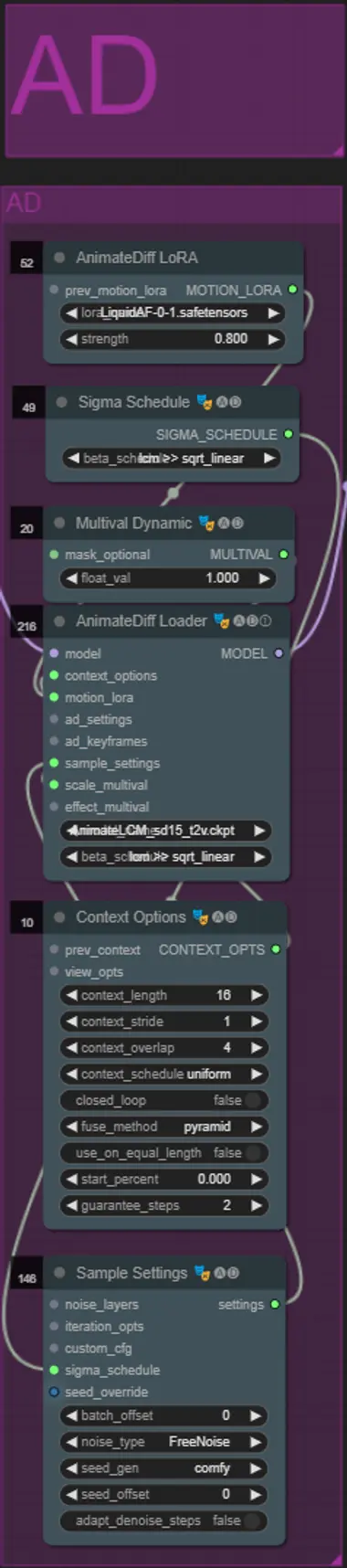
- Puoi impostare un diverso Motion Lora rispetto a quello che ho usato (LiquidAF-0-1.safetensors)
- Regola il valore float Dynamic Multival più alto o più basso a seconda se desideri che il risultato abbia più o meno movimento.
IP Adapters
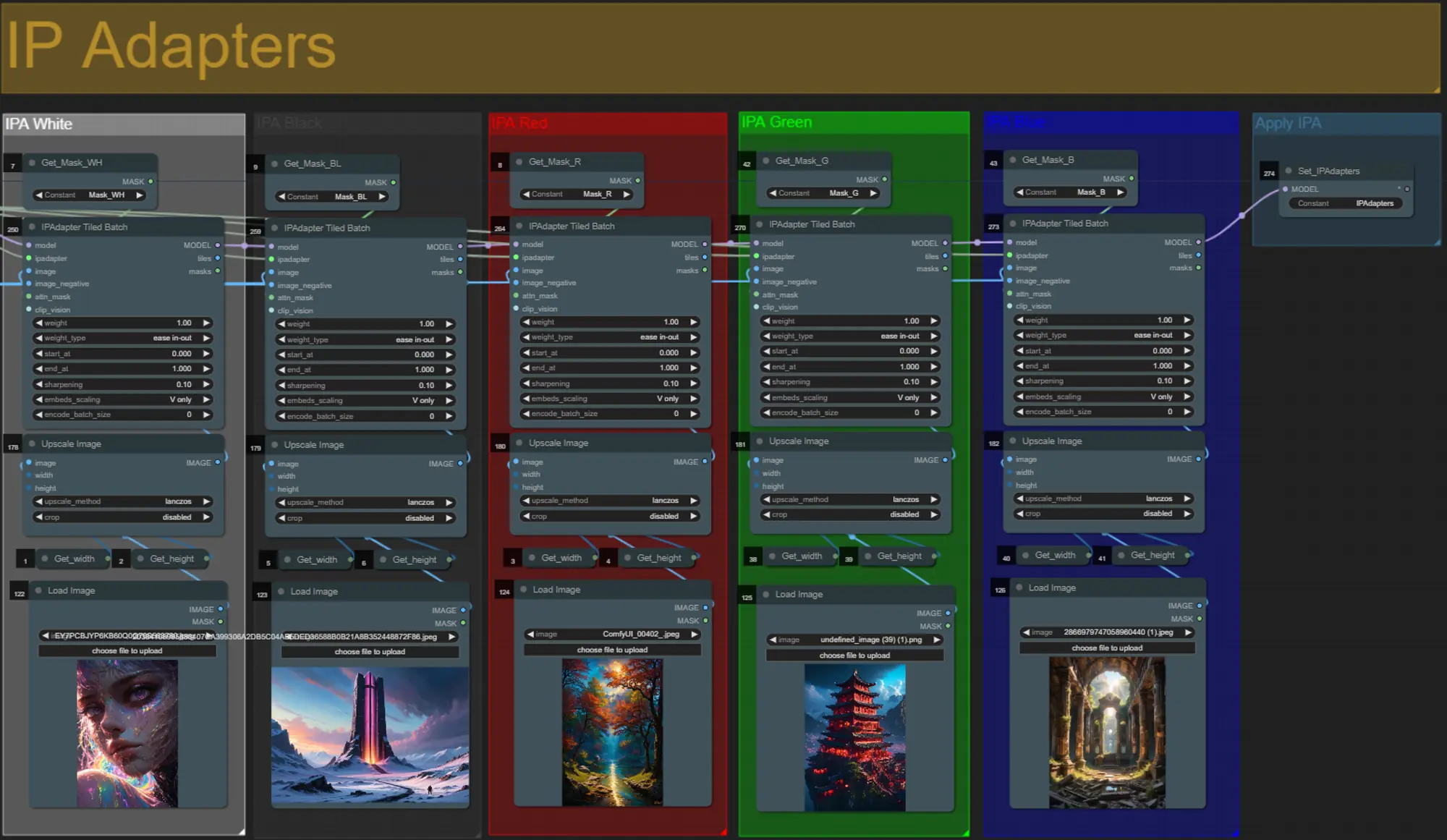
- Qui puoi specificare i soggetti di riferimento che verranno utilizzati per renderizzare gli sfondi per ciascuna delle maschere di dilatazione, nonché il soggetto del tuo video.
- Il colore di ciascun gruppo rappresenta la maschera a cui è destinato:
- Bianco = soggetto (ballerino)
- Nero = Primo sfondo
- Rosso = Sfondo della maschera di dilatazione rossa
- Verde = Sfondo della maschera di dilatazione verde
- Blu = Sfondo della maschera di dilatazione blu
- Se desideri che il rendering finale segua più da vicino le immagini IP adapter di input, puoi cambiare il preset IPAdapter da VIT-G a PLUS nel gruppo IPA Unified Loader.
ControlNet
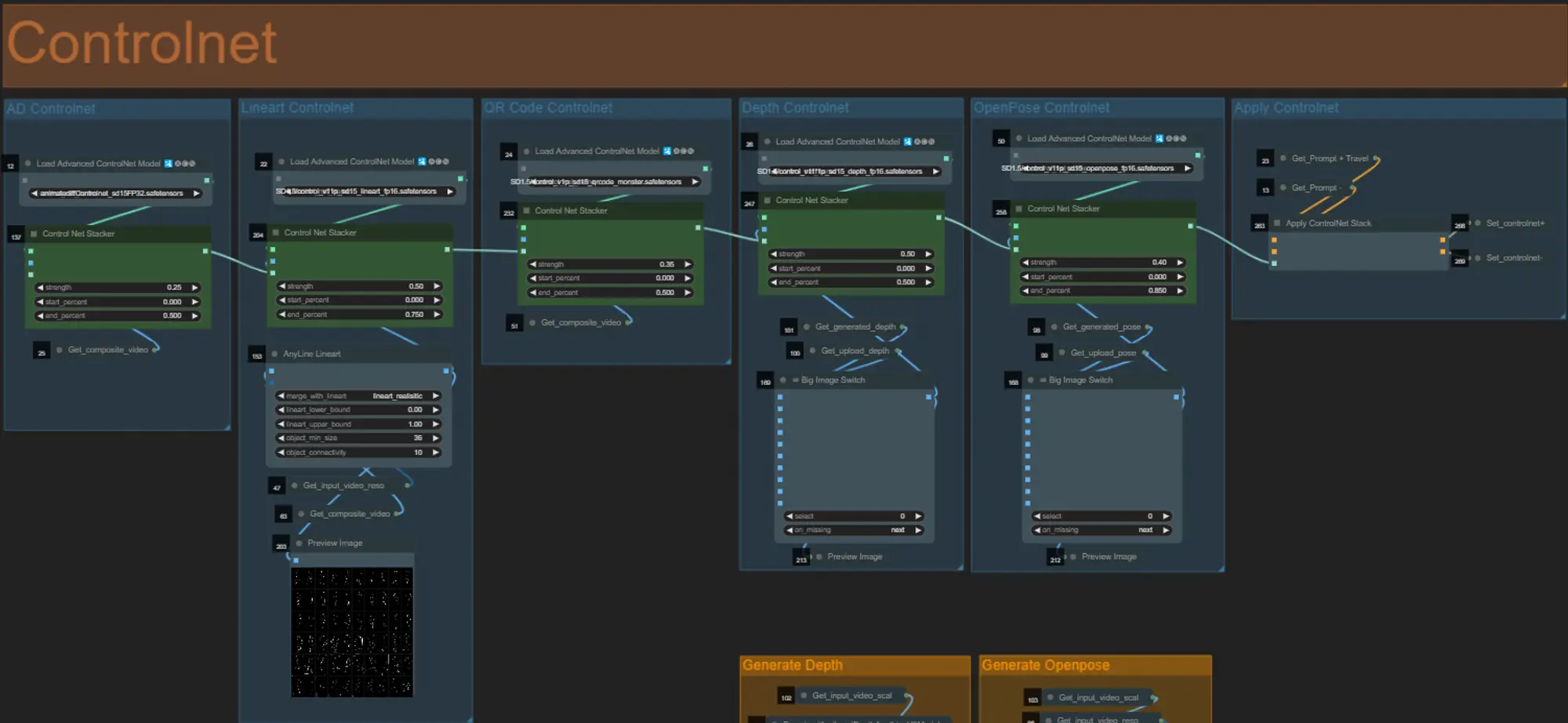
- Questo workflow utilizza 5 diversi controlnets, tra cui AD, Lineart, QR Code, Depth e OpenPose.
- Tutti gli input ai controlnets vengono generati automaticamente
- Puoi scegliere di sovrascrivere il video di input per i controlnets Depth e Openpose se desiderato disattivando i gruppi "Override Depth" e "Override Openpose" come visto sotto:
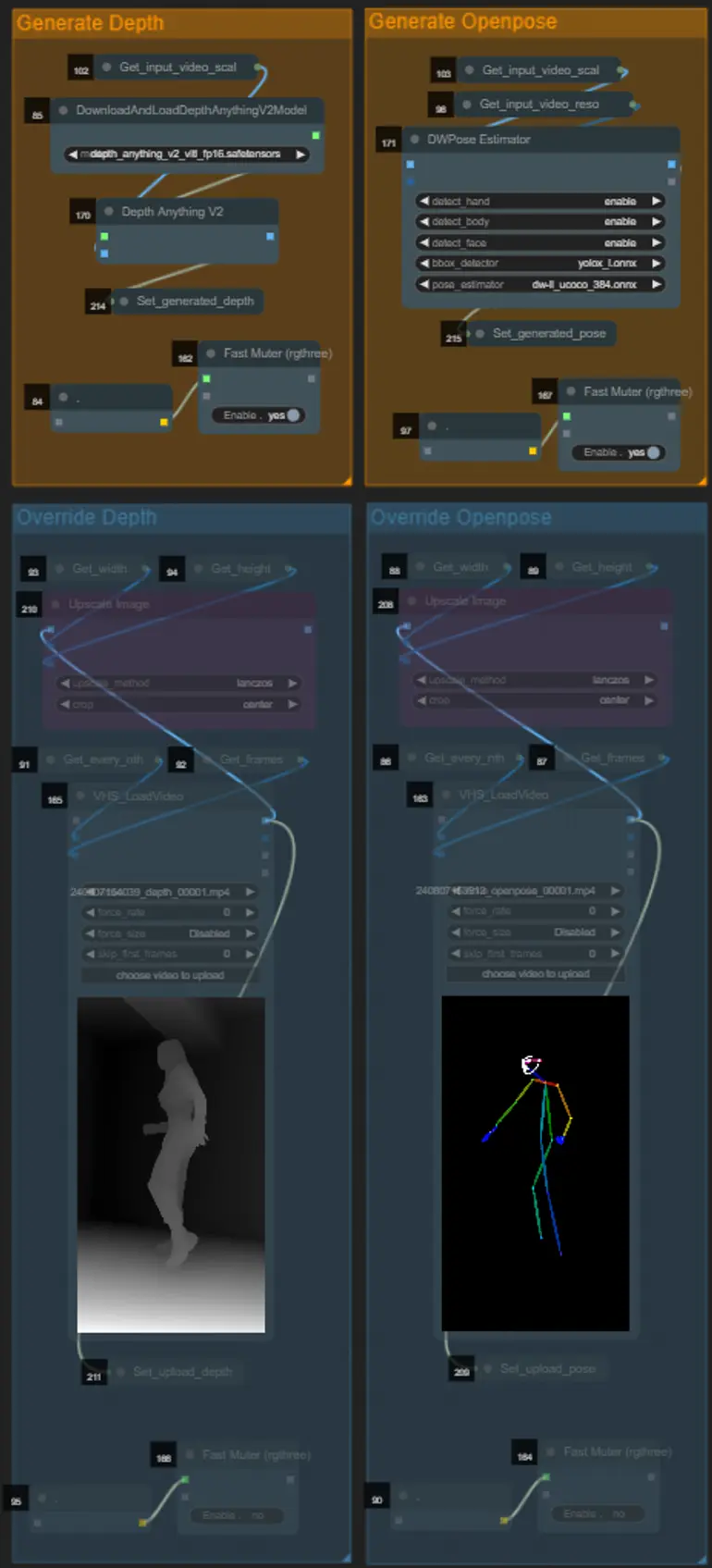
- Si consiglia di disattivare i gruppi "Generate Depth" e "Generate Openpose" se si sovrascrive per risparmiare tempo di elaborazione.
Sampler
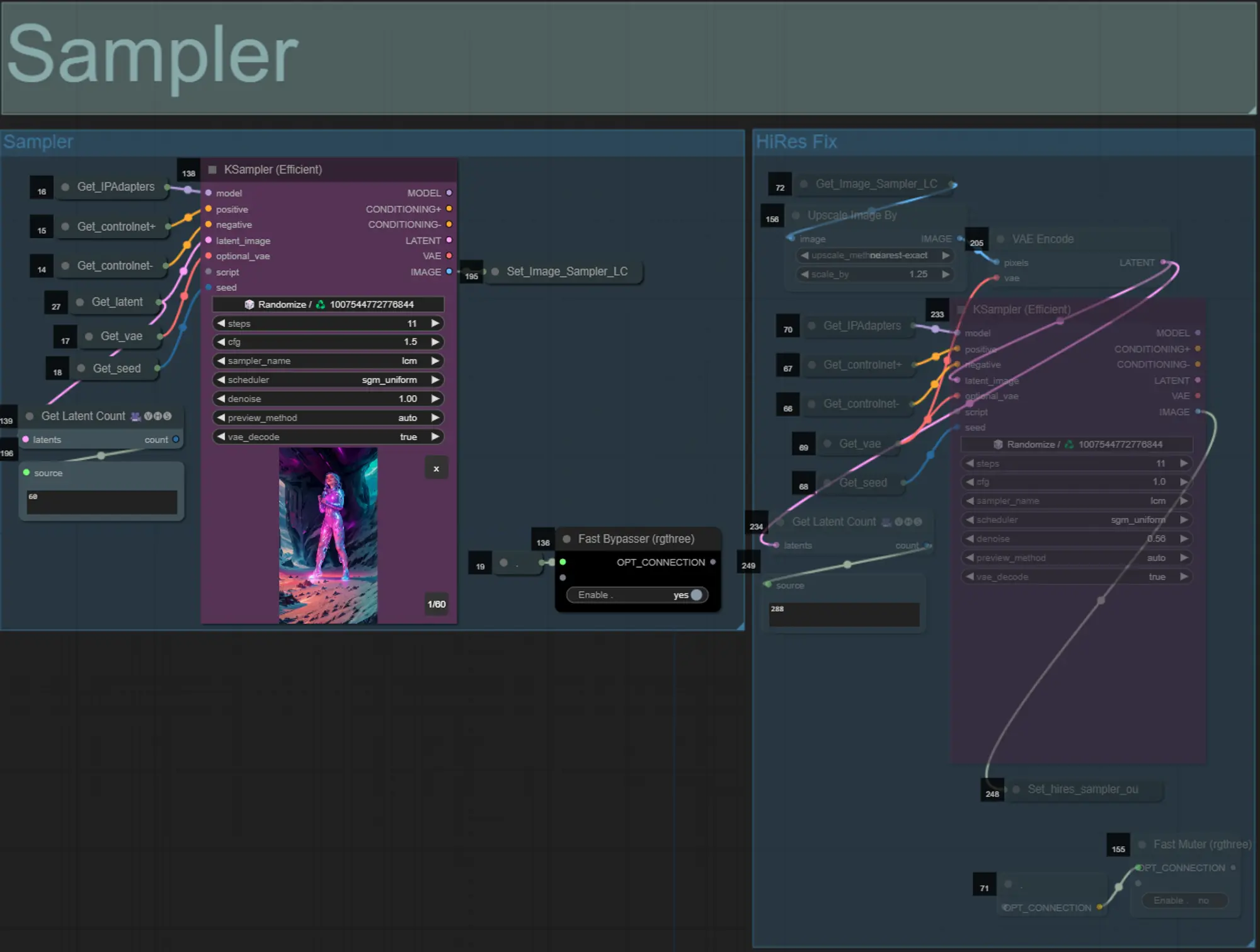
- Per impostazione predefinita, il gruppo HiRes Fix sampler sarà disattivato per risparmiare tempo di elaborazione durante i test
- Raccomando di bypassare anche il gruppo Sampler quando si tenta di sperimentare le impostazioni della maschera di dilatazione per risparmiare tempo.
- Nei rendering finali puoi attivare il gruppo HiRes Fix che scalerà e aggiungerà dettagli al risultato finale.
Output

- Ci sono due gruppi di output: a sinistra per l'output del campionatore standard, e a destra per l'output del campionatore HiRes Fix.
- Puoi cambiare dove verranno salvati i file cambiando la stringa "custom_directory" nei nodi "FileNamePrefixDateDirFirst". Per impostazione predefinita, questo nodo salverà i video di output in una directory con timestamp nella directory "output" di ComfyUI
- es. …/ComfyUI/output/240812/
<custom_directory>/<my_video>.mp4
- es. …/ComfyUI/output/240812/
About Author
Akatz AI:
- Website:
- https://www.youtube.com/@akatz_ai
- https://www.instagram.com/akatz.ai/
- https://www.tiktok.com/@akatz_ai
- https://x.com/akatz_ai
- https://github.com/akatz-ai
Contatti:
- Email: akatzfey@sendysoftware.com

