Vid2Vid Parte 1 | Composizione e Mascheratura
Il ComfyUI Vid2Vid offre due workflow distinti per creare animazioni di alta qualità e professionali: Vid2Vid Parte 1, che migliora la tua creatività concentrandosi sulla composizione e mascheratura del video originale, e Vid2Vid Parte 2, che utilizza SDXL Style Transfer per trasformare lo stile del tuo video in base all'estetica desiderata. Questa pagina copre specificamente Vid2Vid Parte 1ComfyUI Vid2Vid Flusso di lavoro

- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Vid2Vid Esempi
ComfyUI Vid2Vid Descrizione
Il workflow ComfyUI Vid2Vid, creato da , introduce due workflow distinti per ottenere animazioni di alta qualità e professionali.
- Il primo workflow ComfyUI: ComfyUI Vid2Vid Parte 1 | Composizione e Mascheratura
- Il secondo workflow:
ComfyUI Vid2Vid Parte 1 | Composizione e Mascheratura
Questo workflow migliora la creatività concentrandosi sulla composizione e mascheratura del video originale.
Step 1: Models Loader | ComfyUI Vid2Vid Workflow Parte1
Seleziona i modelli appropriati per la tua animazione. Questo include la scelta del modello checkpoint, del modello VAE (Variational Autoencoder) e del modello LoRA (Low-Rank Adaptation). Questi modelli sono cruciali per definire le capacità e lo stile della tua animazione.
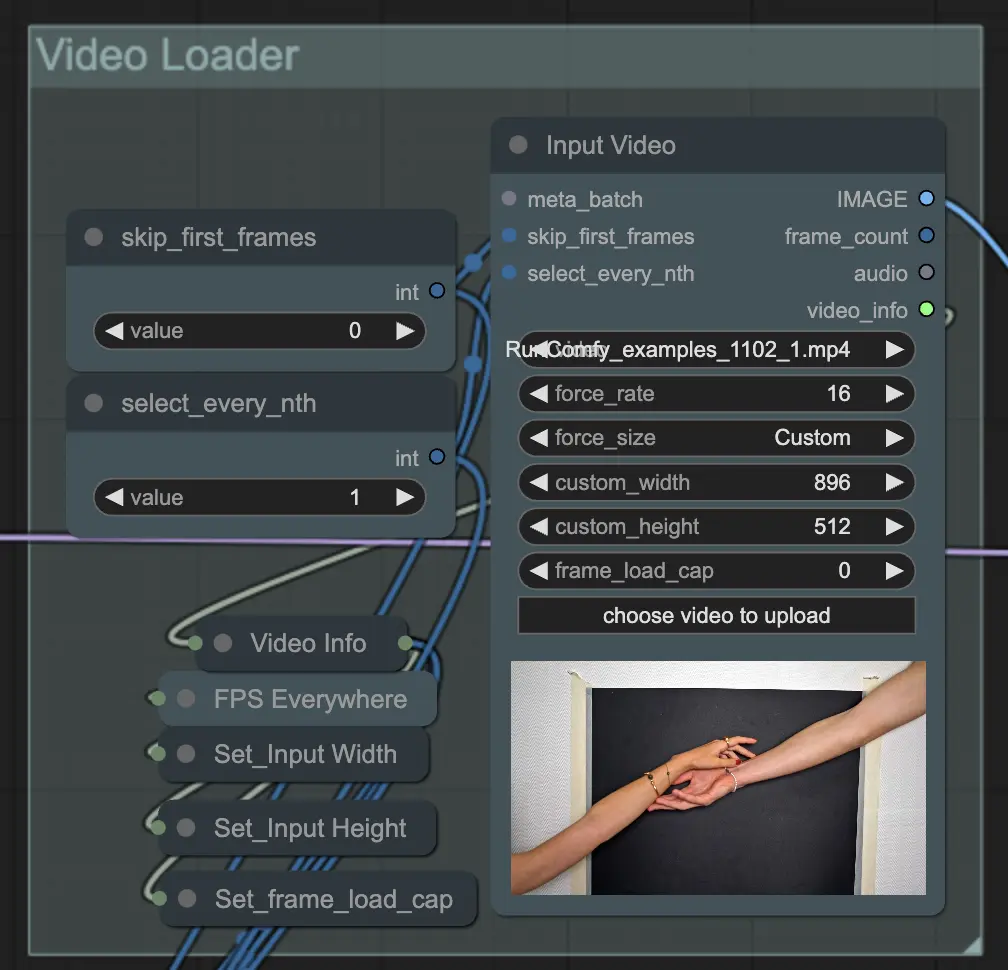
Step 2: Video Loader | ComfyUI Vid2Vid Workflow Parte1
Il nodo Input Video è responsabile dell'importazione del file video che verrà utilizzato per l'animazione. Il nodo legge il video e lo converte in singoli fotogrammi, che vengono poi elaborati nei passaggi successivi. Questo consente un'editing e un miglioramento dettagliato fotogramma per fotogramma.
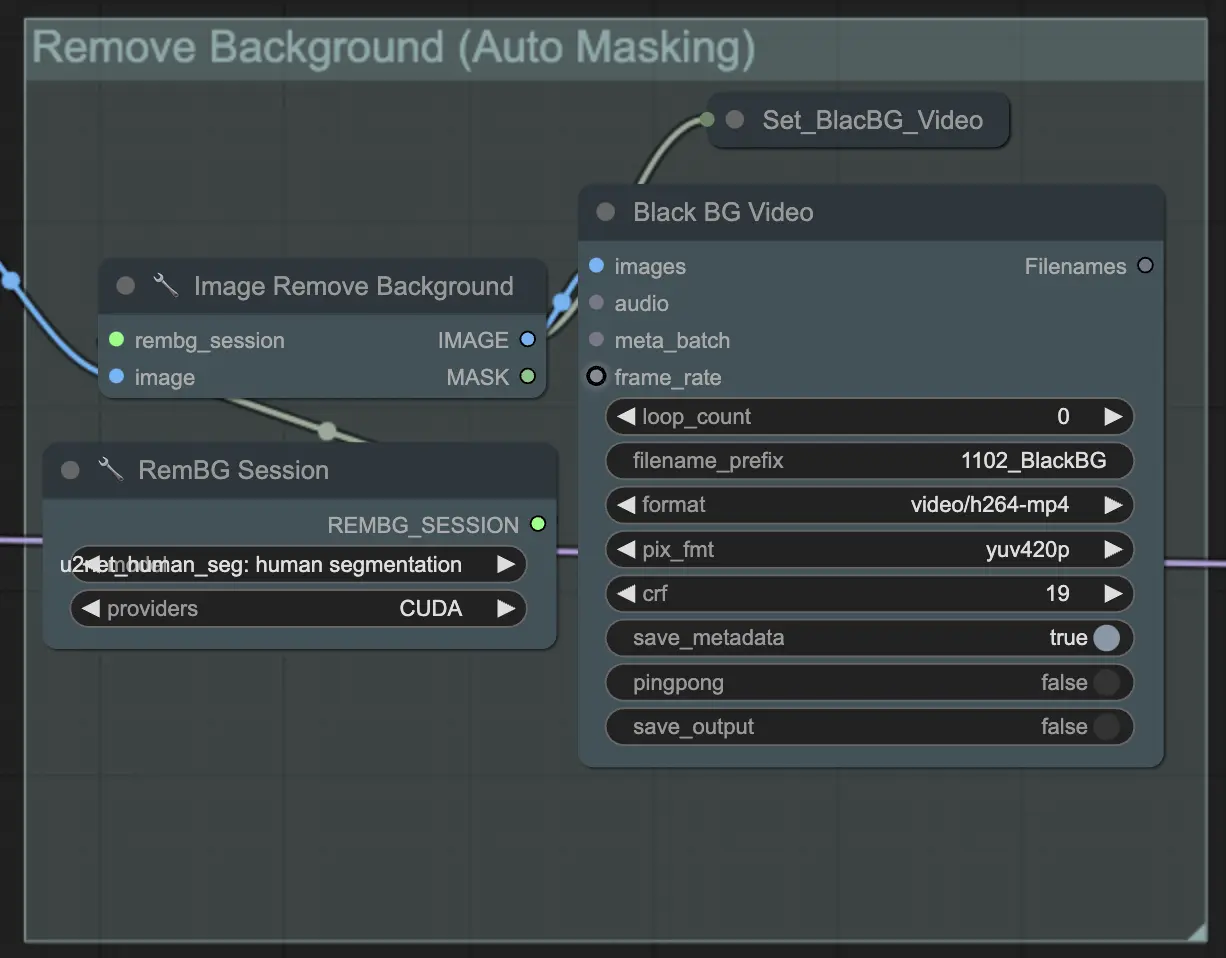
Step 3: Remove Background (Auto Masking) | ComfyUI Vid2Vid Workflow Parte1
Remove Background (Auto Masking) isola il soggetto dallo sfondo utilizzando una tecnica di mascheratura automatizzata. Questo coinvolge modelli che rilevano e separano il soggetto in primo piano dallo sfondo, creando una maschera binaria. Questo passaggio è cruciale per garantire che il soggetto possa essere manipolato indipendentemente dallo sfondo.
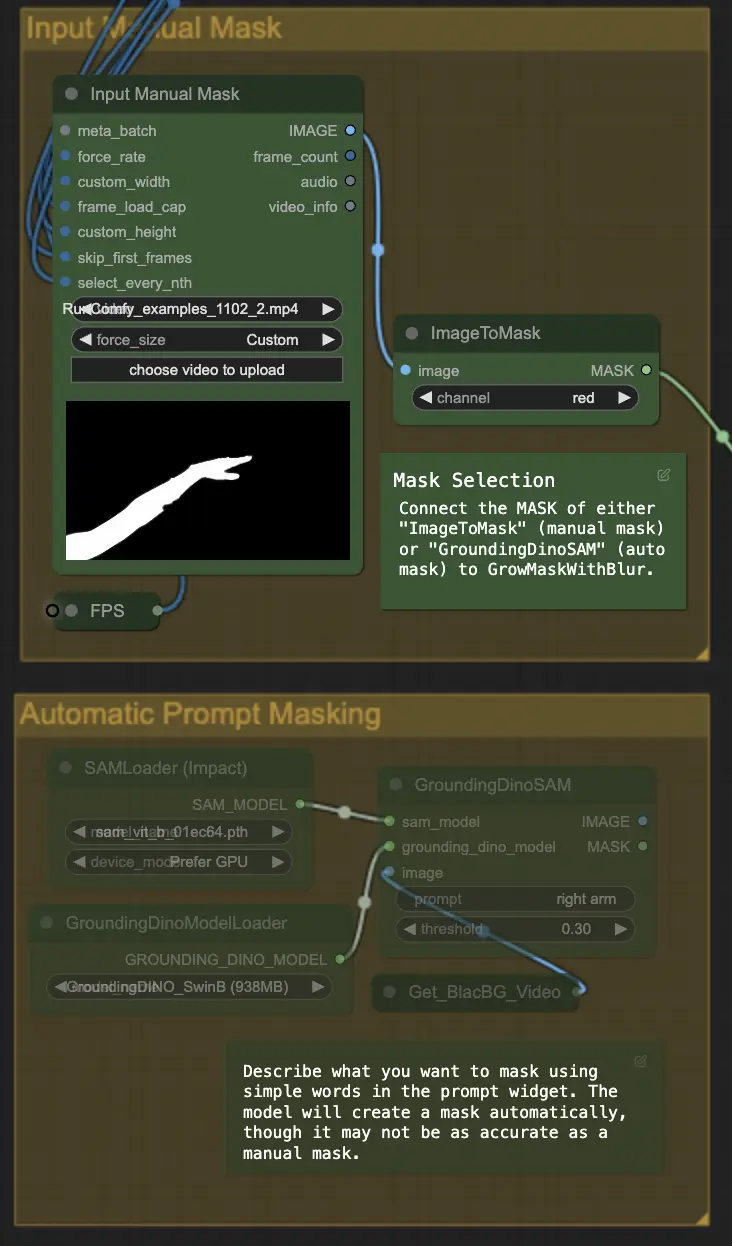
Step 4: Masking Specific Area (Manual Mask or Auto Mask) | ComfyUI Vid2Vid Workflow Parte1
Questo passaggio consente di perfezionare la maschera creata nel passaggio precedente. Puoi mascherare manualmente aree specifiche utilizzando altri software o affidarti alla funzione di maschera automatizzata 'Segment Anything' di ComfyUI.
- Manual Mask: Questo deve essere gestito da altri software al di fuori di ComfyUI per un controllo preciso.
- Auto Mask: Utilizzando la funzione di maschera automatica, puoi descrivere cosa vuoi mascherare utilizzando semplici parole nel widget del prompt. Il modello creerà una maschera automaticamente, anche se potrebbe non essere accurata come una maschera manuale.
La versione predefinita utilizza una maschera manuale. Se desideri provare quella automatica, bypassa il gruppo di maschera manuale e abilita il gruppo di maschera automatica. Inoltre, collega il MASK di 'GroundingDinoSAM' (maschera automatica) a 'GrowMaskWithBlur' invece di collegare 'ImageToMask' (maschera manuale) a 'GrowMaskWithBlur'.
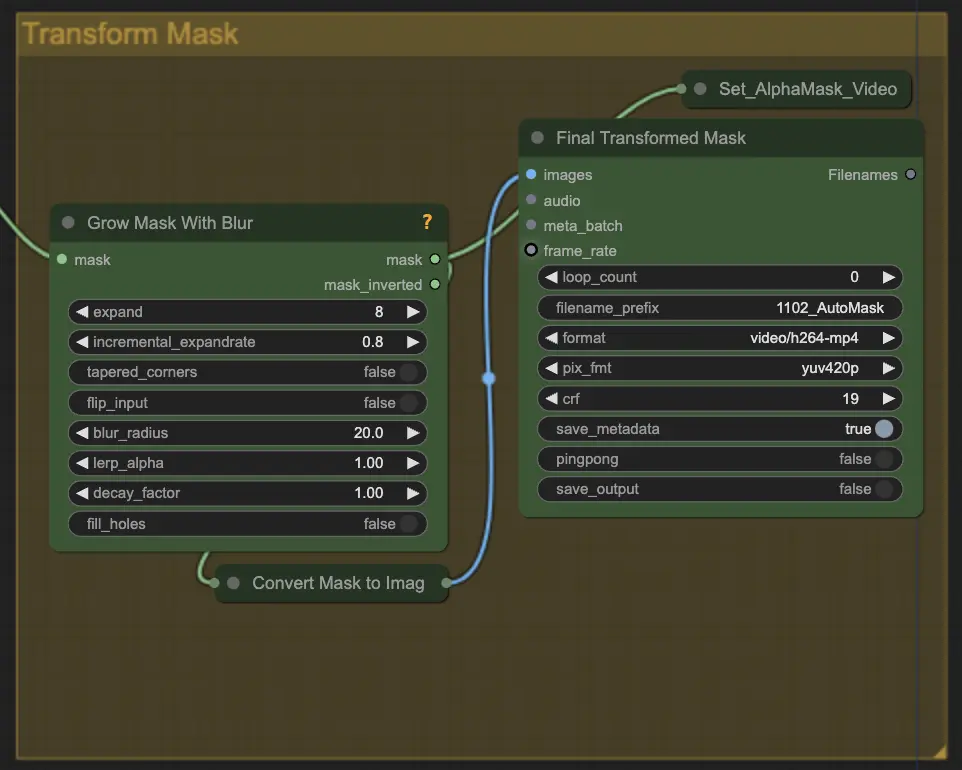
Step 5: Transform Mask | ComfyUI Vid2Vid Workflow Parte1
Transform Mask converte la maschera in un'immagine e consente regolazioni aggiuntive come l'aggiunta di sfocatura alla maschera originale. Questo aiuta ad ammorbidire i bordi e a far fondere la maschera in modo più naturale con il resto dell'immagine.
Step 6: Input Prompt | ComfyUI Vid2Vid Workflow Parte1
Inserisci prompt testuali per guidare il processo di animazione. Il prompt può descrivere lo stile desiderato, l'aspetto o le azioni del soggetto. È cruciale per definire la direzione creativa dell'animazione, assicurando che il risultato finale corrisponda allo stile artistico immaginato.
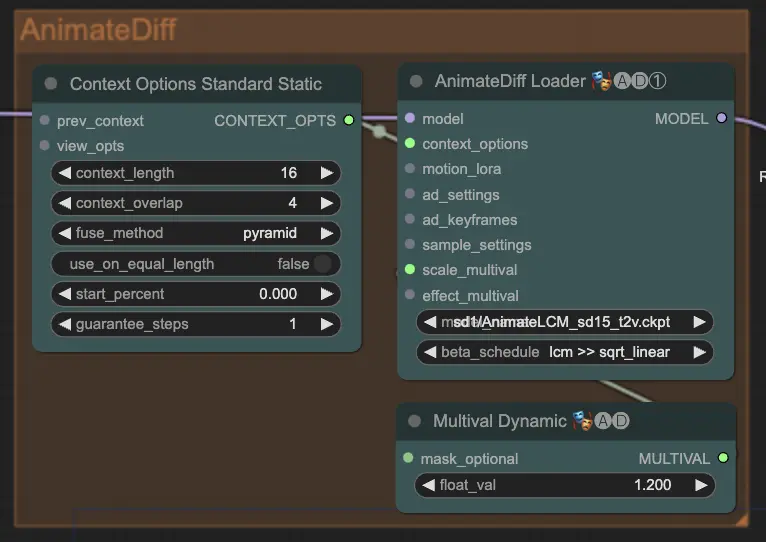
Step 7: AnimateDiff | ComfyUI Vid2Vid Workflow Parte1
Il nodo AnimateDiff crea animazioni fluide identificando le differenze tra fotogrammi consecutivi e applicando questi cambiamenti in modo incrementale. Questo aiuta a preservare la coerenza del movimento e a ridurre i cambiamenti improvvisi nell'animazione, portando a un aspetto più fluido e naturale.
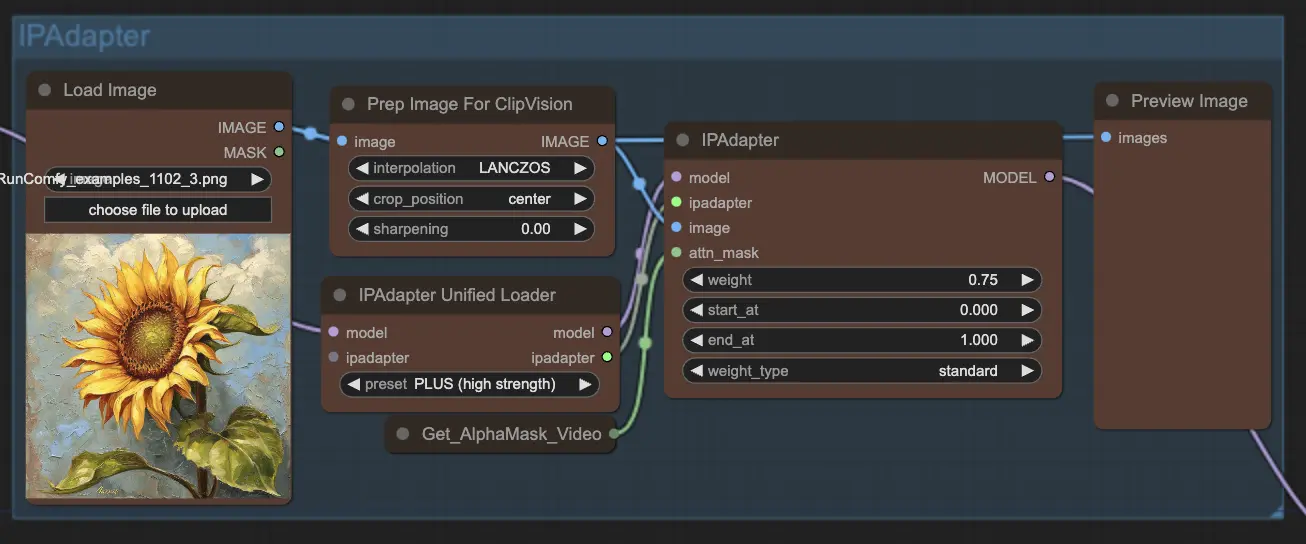
Step 8: IPAdapter | ComfyUI Vid2Vid Workflow Parte1
Il nodo IPAdapter adatta le immagini di input per allinearle con gli stili o le caratteristiche desiderate dell'output. Questo include compiti come la colorazione e il trasferimento di stile, assicurando che ogni fotogramma dell'animazione mantenga un aspetto coerente.
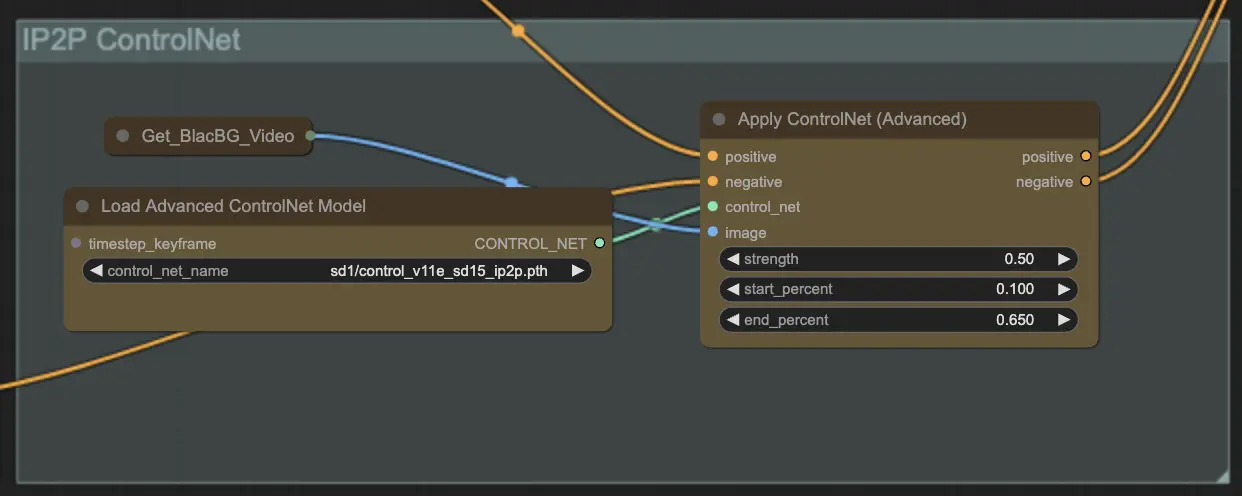
Step 9: ControlNet | ComfyUI Vid2Vid Workflow Parte1
L'utilizzo del modello ControlNet - v1.1 - Instruct Pix2Pix Version migliora i modelli di diffusione consentendo loro di elaborare condizioni di input aggiuntive (ad esempio, mappe dei bordi, mappe di segmentazione). Facilita la generazione di immagini da testo controllando questi modelli pre-addestrati con condizioni specifiche del compito in un modo end-to-end, consentendo un apprendimento robusto anche con dataset più piccoli.
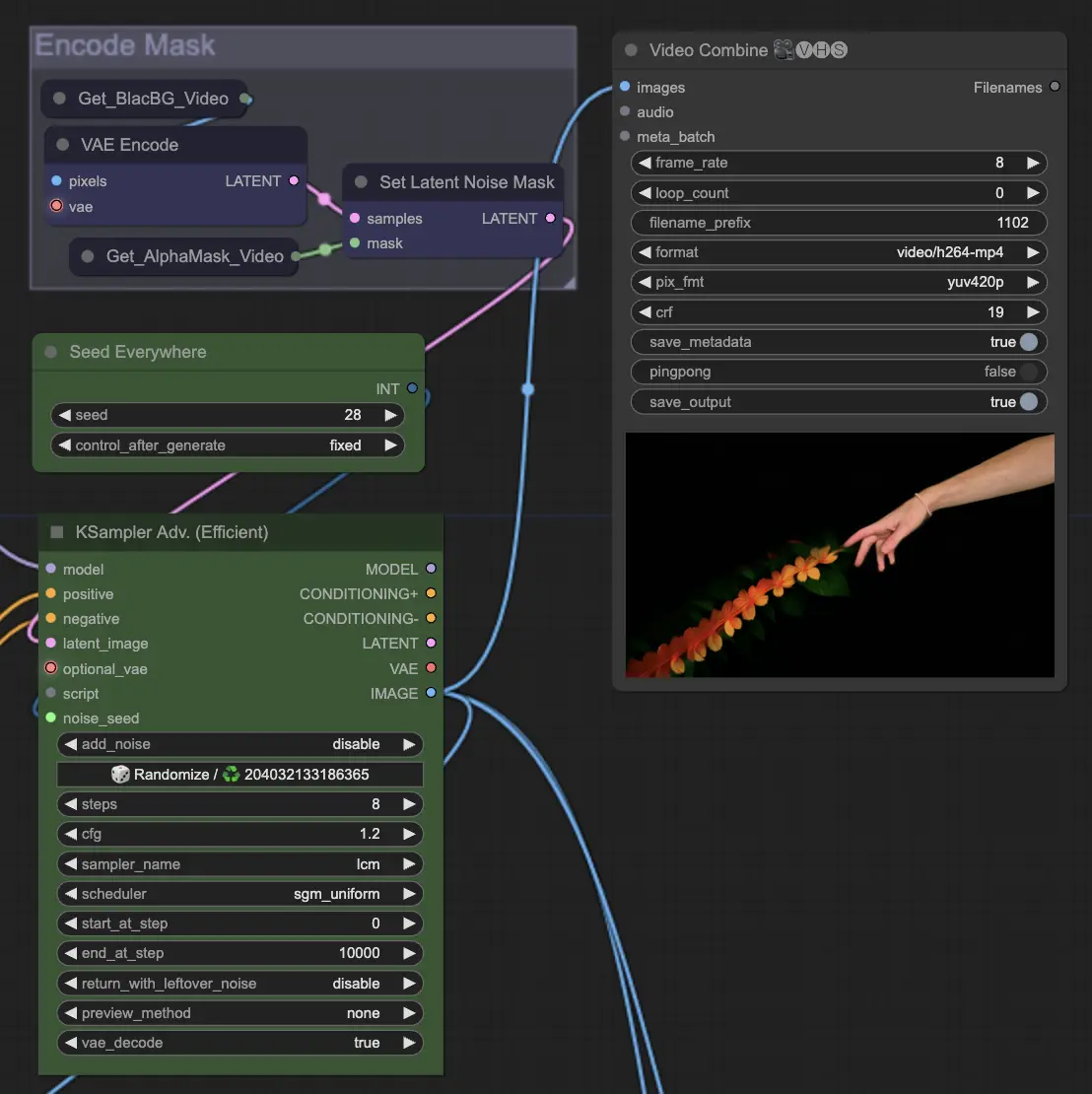
Step 10: Render | ComfyUI Vid2Vid Workflow Parte1
Nel passaggio Render, i fotogrammi elaborati vengono compilati in un output video finale. Questo passaggio assicura che tutti i singoli fotogrammi siano combinati senza soluzione di continuità in un'animazione coerente, pronta per l'esportazione e l'uso successivo.
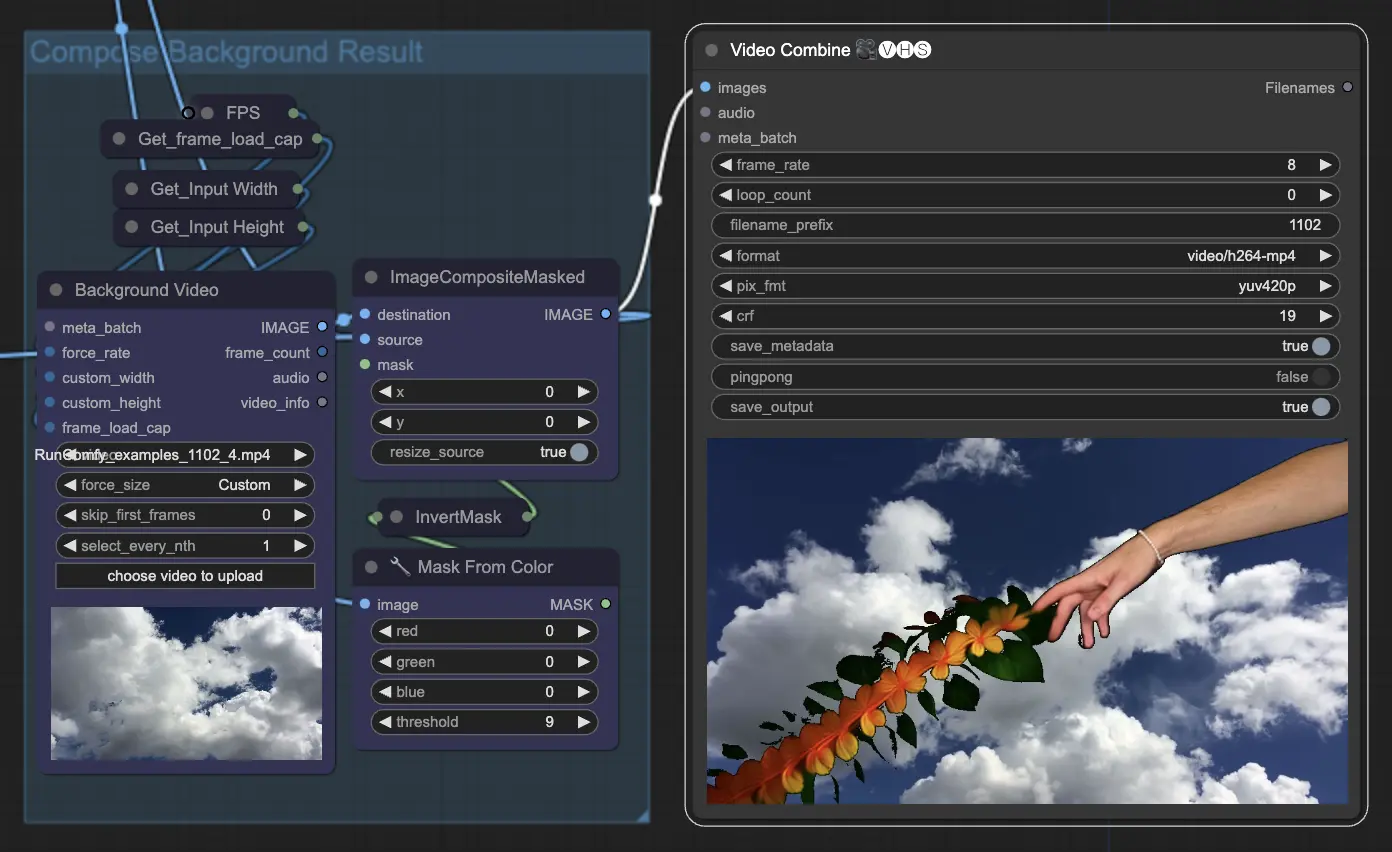
Step 11: Compose Background | ComfyUI Vid2Vid Workflow Parte1
Questo implica la composizione del soggetto animato con lo sfondo. Puoi aggiungere uno sfondo statico o dinamico all'animazione, assicurando che il soggetto si integri perfettamente con il nuovo sfondo per creare un prodotto finale visivamente attraente.
Utilizzando il workflow ComfyUI Vid2Vid Parte1, puoi creare animazioni intricate con un controllo preciso su ogni aspetto del processo, dalla composizione e mascheratura fino al rendering finale.