IPAdapter V1 FaceID Plus | Personaggi coerenti
Sblocca tutto il potenziale dei tuoi design di personaggi con il modello IPAdapter Face Plus V2. Questo flusso di lavoro consente ai creatori di mantenere caratteristiche coerenti dei personaggi attraverso vari stili. Sentiti libero di utilizzare diversi checkpoint o modelli LoRA per esplorare una varietà di stiliComfyUI Consistent Characters Flusso di lavoro
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Consistent Characters Esempi

ComfyUI Consistent Characters Descrizione
1. Flusso di lavoro per personaggi coerenti
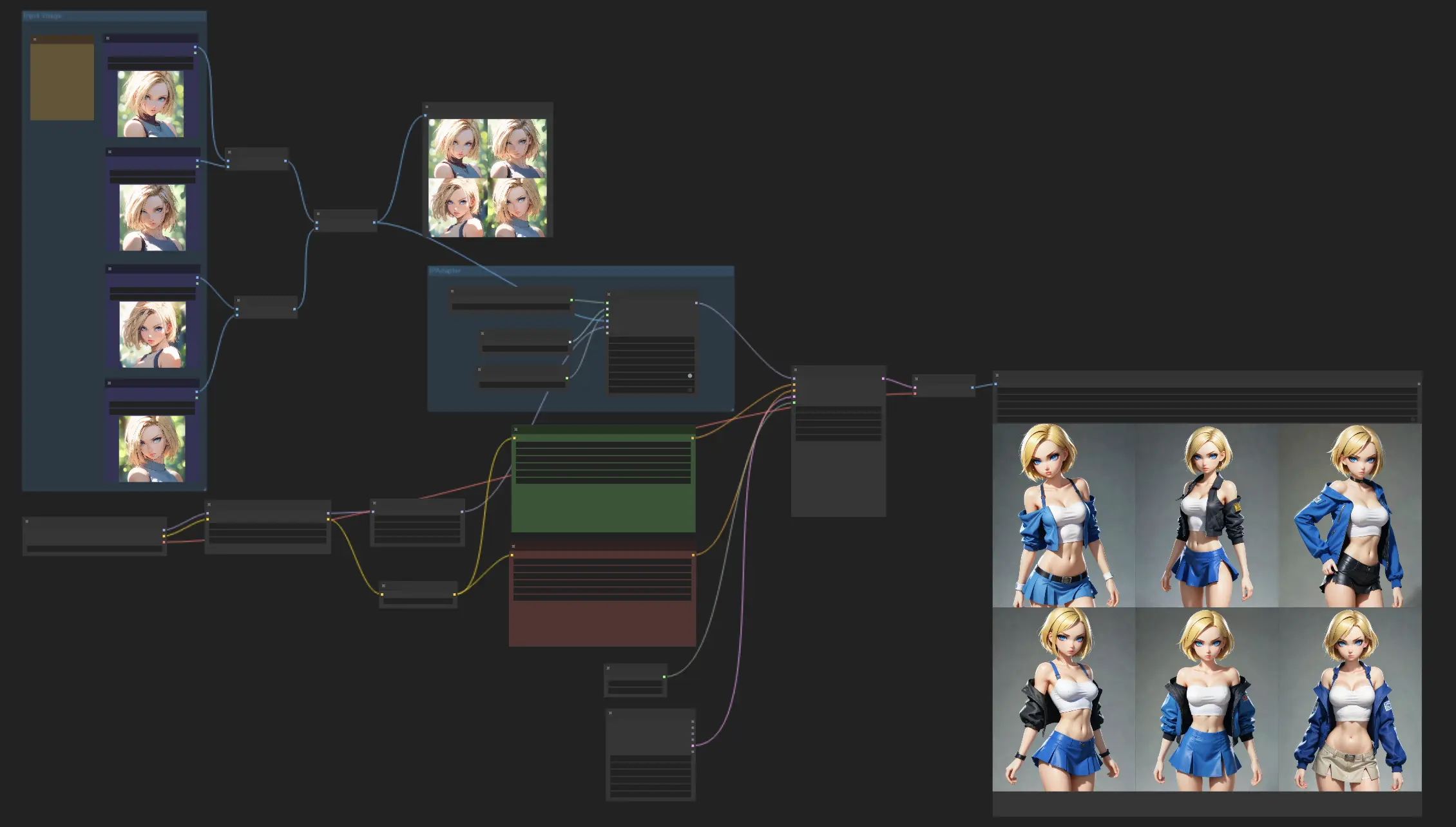
Questo flusso di lavoro riguarda la creazione di personaggi con un aspetto coerente, sfruttando il modello IPAdapter Face Plus V2. Inizia semplicemente caricando alcune immagini di riferimento, quindi lascia che il modello Face Plus V2 faccia la sua magia, creando una serie di immagini che mantengono le stesse caratteristiche facciali. Sentiti libero di mescolare le cose con diversi checkpoint o modelli LoRA per esplorare una varietà di stili, mantenendo sempre coerente l'aspetto del tuo personaggio.
2. Panoramica di IPAdapter FaceID/FaceID Plus
v1.5 FaceID
Questo modello è la versione base per l'identificazione del viso, consentendo variazioni aumentate da prompt di testo, control net e maschere. È noto per la sua forza media nel condizionamento, rendendolo adatto per attività generali di condizionamento del viso. Il modello base FaceID non utilizza un encoder di visione CLIP, il che implica una configurazione più semplice senza la necessità di configurazioni di encoder complesse.
v1.5 FaceID Plus
Il modello FaceID Plus è una variante più potente, progettata per effetti di condizionamento da immagine a immagine più forti. Richiede l'uso dell'encoder di immagini ViT-H, indicando la necessità di capacità di elaborazione più elevate per la modellazione dettagliata del viso.
v1.5 FaceID Plus v2
Un'iterazione su FaceID Plus, questo modello introduce miglioramenti per un condizionamento del viso ancora più dettagliato. Simile a FaceID Plus, utilizza l'encoder di immagini ViT-H. Questo modello mira a fornire una maggiore qualità nella modellazione del viso, rispondendo a requisiti più sfumati.
v1.5 FaceID Portrait
Progettato specificamente per i ritratti, questo modello non utilizza un encoder di visione CLIP. Si concentra sulla generazione di immagini facciali di alta qualità all'interno di contesti di ritratto, offrendo potenzialmente un approccio specializzato per la generazione di immagini di ritratto.
SDXL FaceID
La variante SDXL di FaceID è adattata per l'uso con l'architettura SDXL, non utilizzando un encoder di visione CLIP. Rappresenta un modello base all'interno della suite SDXL, progettato per architetture di apprendimento profondo scalabili, concentrandosi su attività di identificazione del viso.
SDXL FaceID Plus v2
Questa è una versione più potente del modello FaceID per l'architettura SDXL, che utilizza l'encoder di immagini ViT-H. È progettato per offrire effetti di condizionamento del viso migliorati all'interno del framework SDXL, mirando a attività di generazione di immagini di alta qualità.
3. Come utilizzare IPAdapter FaceID/FaceID Plus
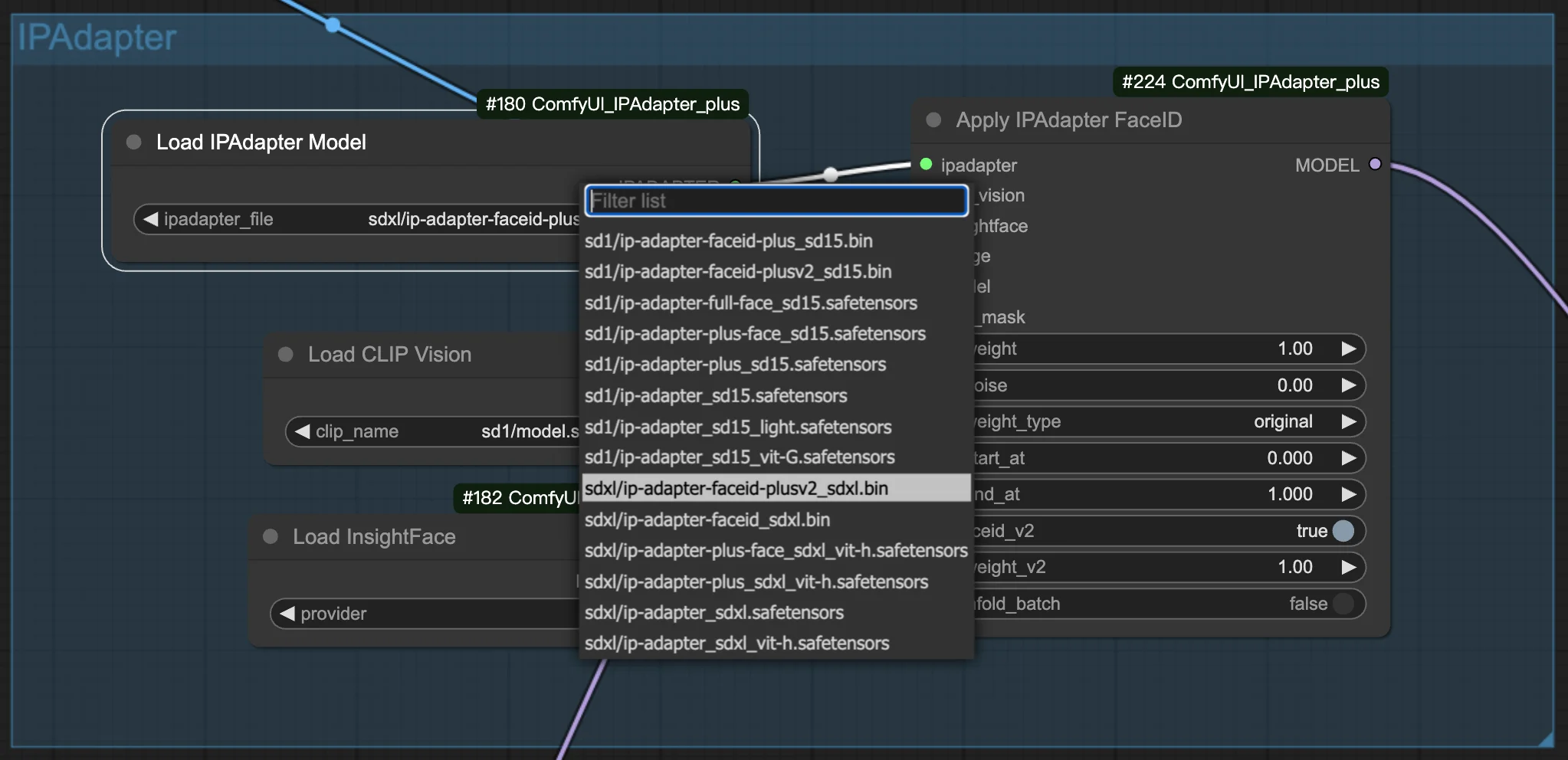
3.1. Scegli il modello FaceID/FaceID Plus
Seleziona il tuo modello FaceID o FaceID Plus preferito per iniziare a creare le tue immagini. All'interno delle impostazioni, troverai opzioni per regolare sia i pesi che il rumore. Queste regolazioni sono fondamentali per mettere a punto l'aspetto delle immagini generate, consentendoti di ottenere l'aspetto preciso a cui miri.
3.2. Preparazione dell'immagine di riferimento
Quando si utilizzano i nodi IPAdapter FaceID, il modello di visione CLIP elabora l'immagine di riferimento ridimensionandola e centrandola su una dimensione di 224x224 pixel. Questa regolazione automatica si concentra sul centro dell'immagine, rendendo cruciale che il soggetto principale dell'immagine, come il viso di un personaggio, sia posizionato centralmente. Se il soggetto è decentrato, specialmente nelle immagini di ritratto o di paesaggio, i risultati potrebbero non soddisfare le tue aspettative. Per risultati ottimali, si consiglia vivamente di utilizzare immagini quadrate con il soggetto centrato.






