Hunyuan Video | Video to Video
Questo flusso di lavoro Hunyuan in ComfyUI ti consente di trasformare visuali esistenti in nuove visuali sorprendenti. Inserendo prompt di testo e un video sorgente, il modello Hunyuan genera traduzioni impressionanti che incorporano il movimento e gli elementi chiave del sorgente. Con architettura avanzata e tecniche di addestramento, Hunyuan produce contenuti di alta qualità, diversificati e stabili.ComfyUI Hunyuan Video to Video Flusso di lavoro
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Hunyuan Video to Video Esempi
ComfyUI Hunyuan Video to Video Descrizione
Il video Hunyuan, un modello AI open-source sviluppato da Tencent, ti permette di generare visuali straordinarie e dinamiche con facilità. Il modello Hunyuan sfrutta un'architettura avanzata e tecniche di addestramento per comprendere e generare contenuti di alta qualità, diversità di movimento e stabilità.
Informazioni sul flusso di lavoro Hunyuan Video to Video
Questo flusso di lavoro Hunyuan in ComfyUI utilizza il modello Hunyuan per creare nuovi contenuti visivi combinando prompt di testo di input con un video di riferimento esistente. Sfruttando le capacità del modello Hunyuan, puoi generare traduzioni video impressionanti che incorporano senza soluzione di continuità il movimento e gli elementi chiave dal video di riferimento allineando l'output con il tuo prompt di testo desiderato.
Come utilizzare il flusso di lavoro Hunyuan Video to Video
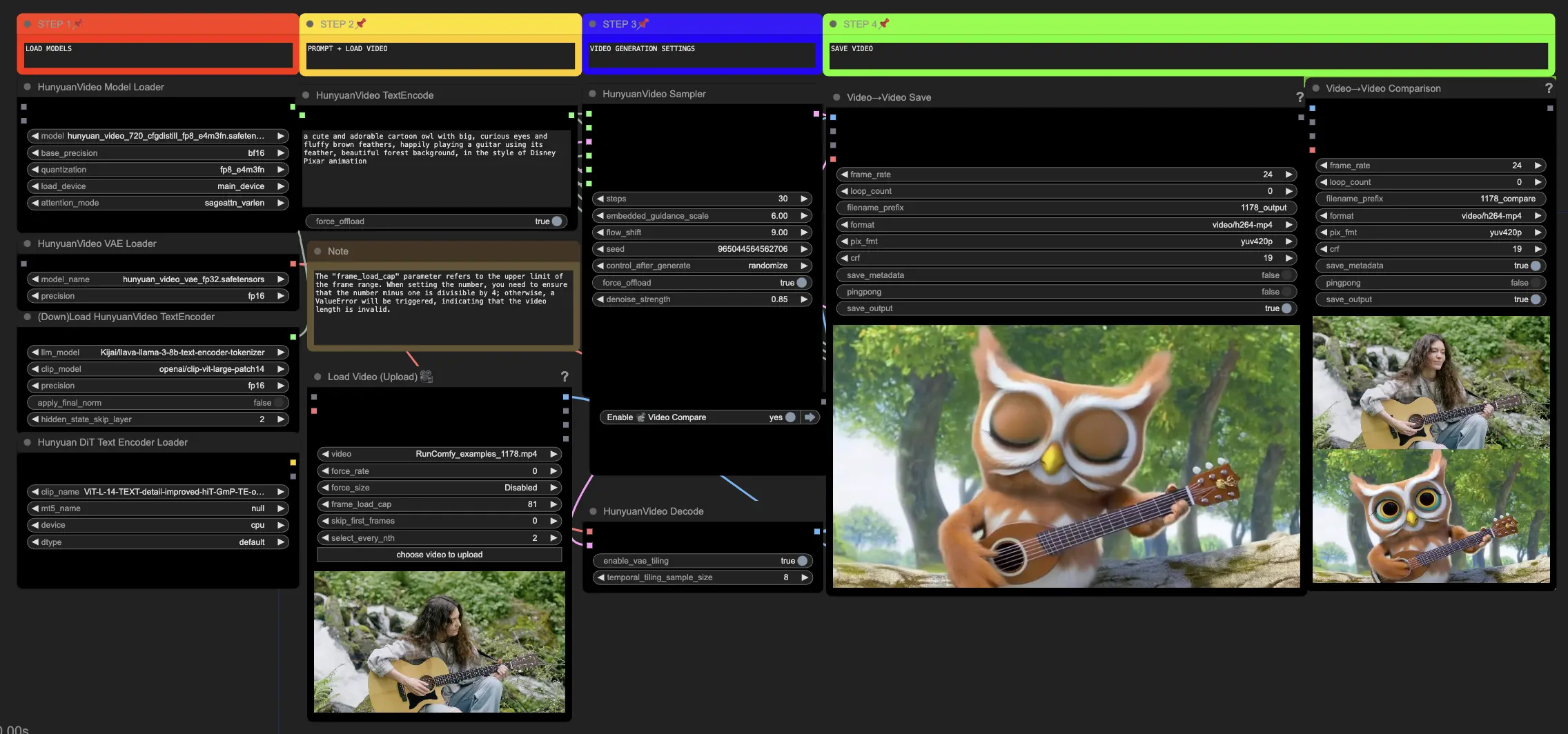
🟥 Passo 1: Carica i modelli Hunyuan
- Carica il modello Hunyuan selezionando il file "hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors" nel nodo HyVideoModelLoader. Questo è il modello principale del transformer.
- Il modello HunyuanVideo VAE verrà scaricato automaticamente nel nodo HunyuanVideoVAELoader. Viene utilizzato per la codifica/decodifica dei fotogrammi video.
- Carica un codificatore di testo nel nodo DownloadAndLoadHyVideoTextEncoder. Il flusso di lavoro predefinito utilizza il codificatore LLM "Kijai/llava-llama-3-8b-text-encoder-tokenizer" e il codificatore CLIP "openai/clip-vit-large-patch14", che verranno scaricati automaticamente. Puoi utilizzare altri codificatori CLIP o T5 che hanno funzionato con modelli precedenti.
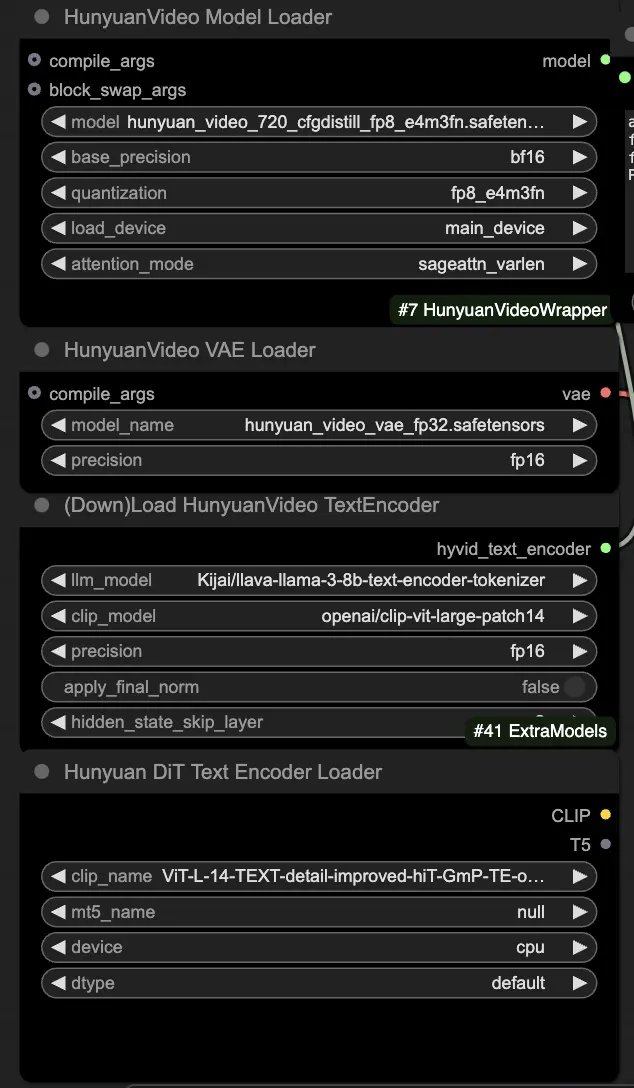
🟨 Passo 2: Inserisci il prompt e carica il video di riferimento
- Inserisci il tuo prompt di testo descrivendo il visuale che desideri generare nel nodo HyVideoTextEncode.
- Carica il video di riferimento che vuoi utilizzare come riferimento del movimento nel nodo VHS_LoadVideo.
- frame_load_cap: Numero di fotogrammi da generare. Quando imposti il numero, devi assicurarti che il numero meno uno sia divisibile per 4; altrimenti, verrà generato un ValueError, indicando che la lunghezza del video non è valida.
- skip_first_frames: Regola questo parametro per controllare quale parte del video viene utilizzata.
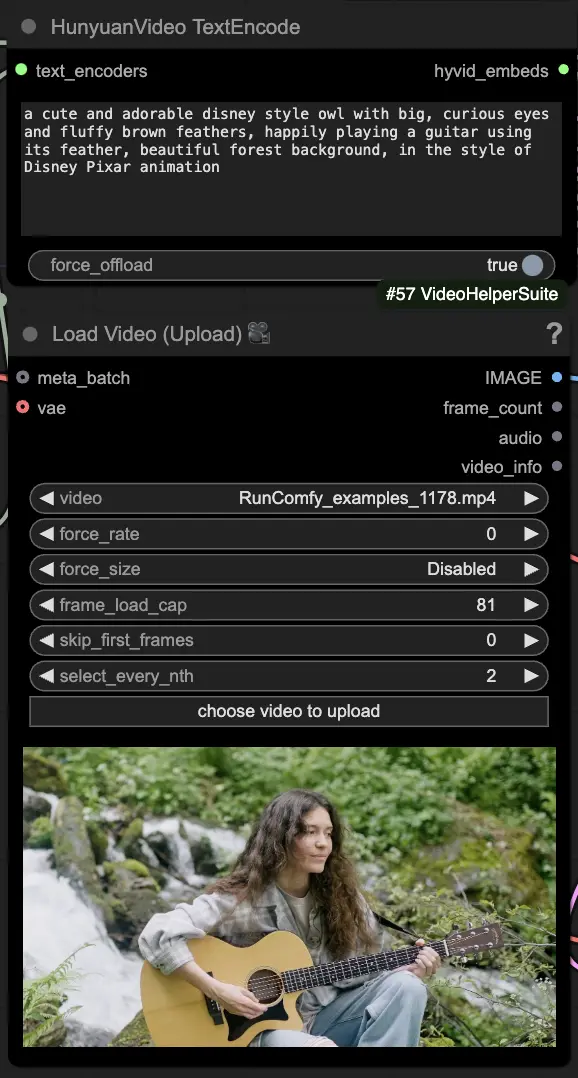
🟦 Passo 3: Impostazioni di generazione Hunyuan
- Nel nodo HyVideoSampler, configura gli iperparametri di generazione video:
- Steps: Numero di passaggi di diffusione per fotogramma, maggiore significa qualità migliore ma generazione più lenta. Predefinito 30.
- Embedded_guidance_scale: Quanto aderire al prompt, valori più alti si attengono più al prompt.
- Denoise_strength: Controlla la forza dell'utilizzo del video di riferimento iniziale. Valori più bassi (es. 0.6) fanno sembrare l'output più simile all'inizio.
- Scegli addon e toggle nel nodo "Fast Groups Bypasser" per abilitare/disabilitare funzionalità extra come il video di confronto.
🟩 Passo 4: Genera Video Huanyuan
- I nodi VideoCombine genereranno e salveranno due output per impostazione predefinita:
- Il risultato video tradotto
- Un video di confronto che mostra il video di riferimento e il risultato generato
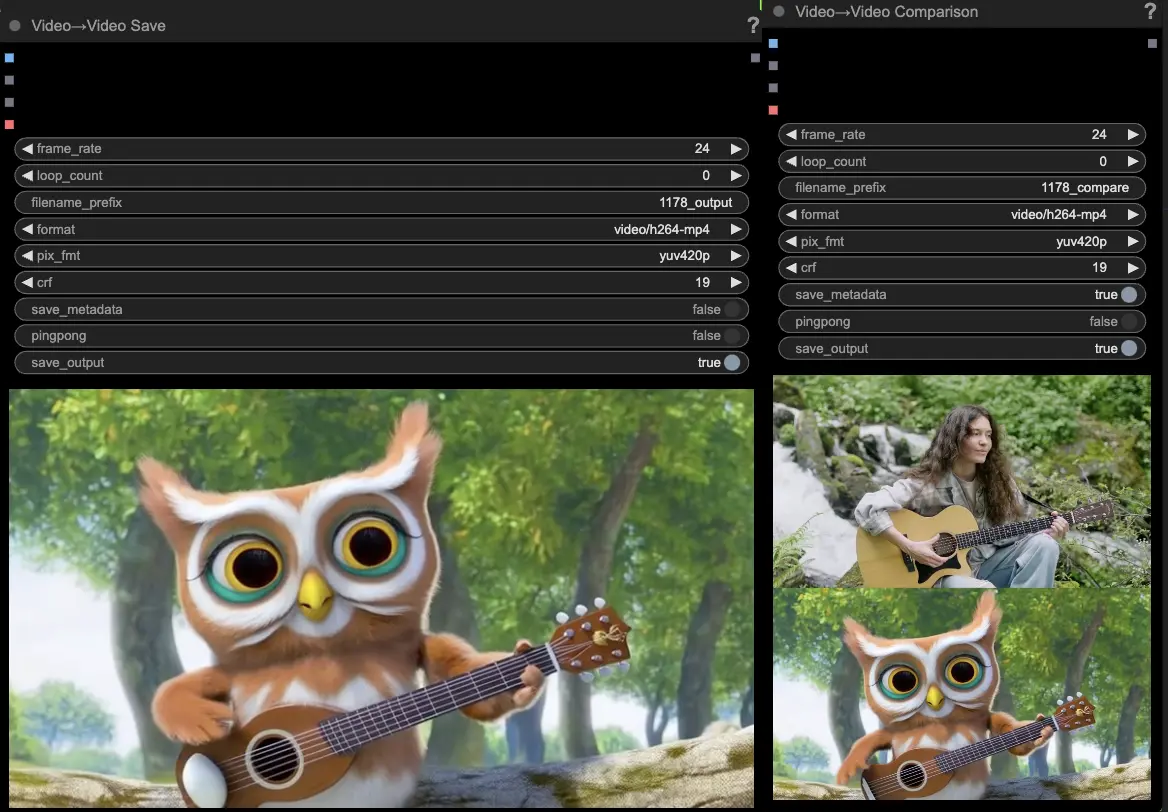
Modificare il prompt e le impostazioni di generazione consente una flessibilità impressionante nella creazione di nuovi video guidati dal movimento di un video esistente utilizzando il modello Hunyuan. Divertiti a esplorare le possibilità creative di questo flusso di lavoro Hunyuan!
Questo flusso di lavoro Hunyuan è stato progettato da Black Mixture. Visita il per ulteriori informazioni. Un ringraziamento speciale a nodi ed esempi di flusso di lavoro.


