Blender + ComfyUI | AIレンダリング3Dアニメーション
AIレンダリングで3Dアニメーションプロジェクトを変革します。まず、Blenderを使用して3Dシーンを設定し、マスク、深度、およびアウトラインシーケンスを含む画像シーケンスを生成します。その後、ComfyUIを使用してレンダリングを行います。ComfyUIでは、各オブジェクトを個別にレンダリングでき、最終的に完全なクリエイティブコントロールを持つ素晴らしいアニメーションを作成できます。ComfyUI 3D Animation Rendering ワークフロー
このワークフローを実行しますか?
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI 3D Animation Rendering 例
ComfyUI 3D Animation Rendering 説明
AIレンダリングの3Dアニメーション: Blender + ComfyUI
この革新的なワークフローは、才能あるによって開発され、BlenderとComfyUIを組み合わせてAIでレンダリングされた驚くべき3Dアニメーションを作成します。彼のYouTubeチャンネルをぜひチェックして、さらなるインスピレーションを得てください。
以下では、彼のアプローチを再現するためにさまざまな素材を使用しました。以下はその手順です:
🌟
パート1: Blenderを使用して3Dアニメーションとレンダーパスを作成する
1. Blenderで3Dシーンを設定する
- キャラクター、環境、道具など必要な3Dアセットをインポートまたはモデリングすることから始めます。これらのアセットをシーン内に配置し、カメラを配置し、必要なアニメーションを設定します。既存のマテリアル、テクスチャ、およびライトを削除します。レンダリングプロセス中にComfyUIがこれらを生成します。
2. 深度パスをレンダリングする
- 深度パスは、深度知覚を強化するための重要な距離情報を提供し、ComfyUIで使用されます。
- Blenderで、
View Layer Propertiesに移動し、Zパスを有効にして画像をレンダリングします。Compositingタブで、ビューワーノードを深度出力に接続します。Map Rangeノードを使用して深度値を正規化し、シーンの深度を表す白黒のグラデーションを作成します。
3. アウトラインパスをレンダリングする
- アウトラインパスは、ComfyUIで使用するためのオブジェクトの形状とシルエットを定義するラインアートエッジを生成します。
- Blenderで、Freestyleツールを使用して3Dジオメトリに基づくアウトラインを作成します。色を白に設定し、線の太さを調整します。画像をレンダリングし、
Compositingタブで処理します。
4. マスクパスをレンダリングする
- マスクパスは、異なるオブジェクトに固有の色を割り当てます。これらの色のHexコードをメモしておいてください。これらはComfyUIで特定のAIプロンプトに使用されます。
- Blenderで、各オブジェクトに異なる色のシンプルなエミッションシェーダーを割り当てます。画像をレンダリングして保存します。
これらの手順の詳細については、Blenderに不慣れな場合はのYouTubeチュートリアルを参照してください。
パート1を完了すると、マスク画像、深度画像、およびアウトライン画像の3種類の画像シーケンスが作成されます。これらは次のステップでComfyUIと共に使用されます。
パート2: ComfyUIを使用してAIアニメーションをレンダリングする
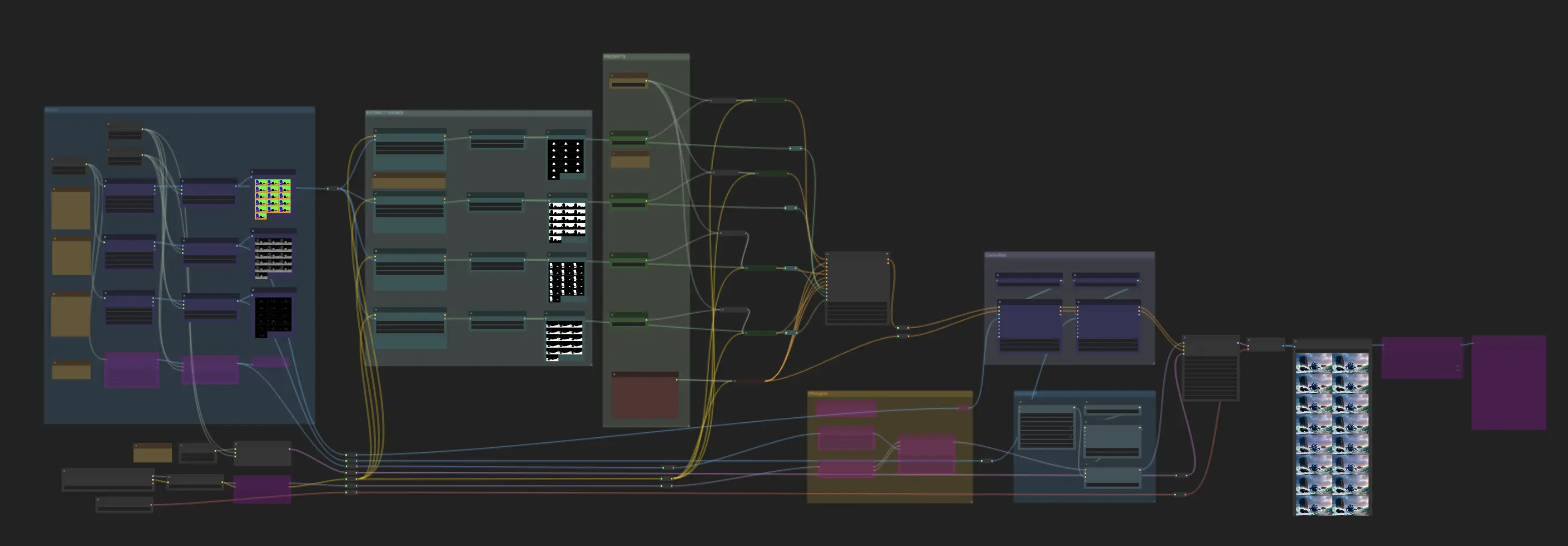
MickmumpitzのComfyUIワークフローは、いくつかの主要なコンポーネントで構成されています:
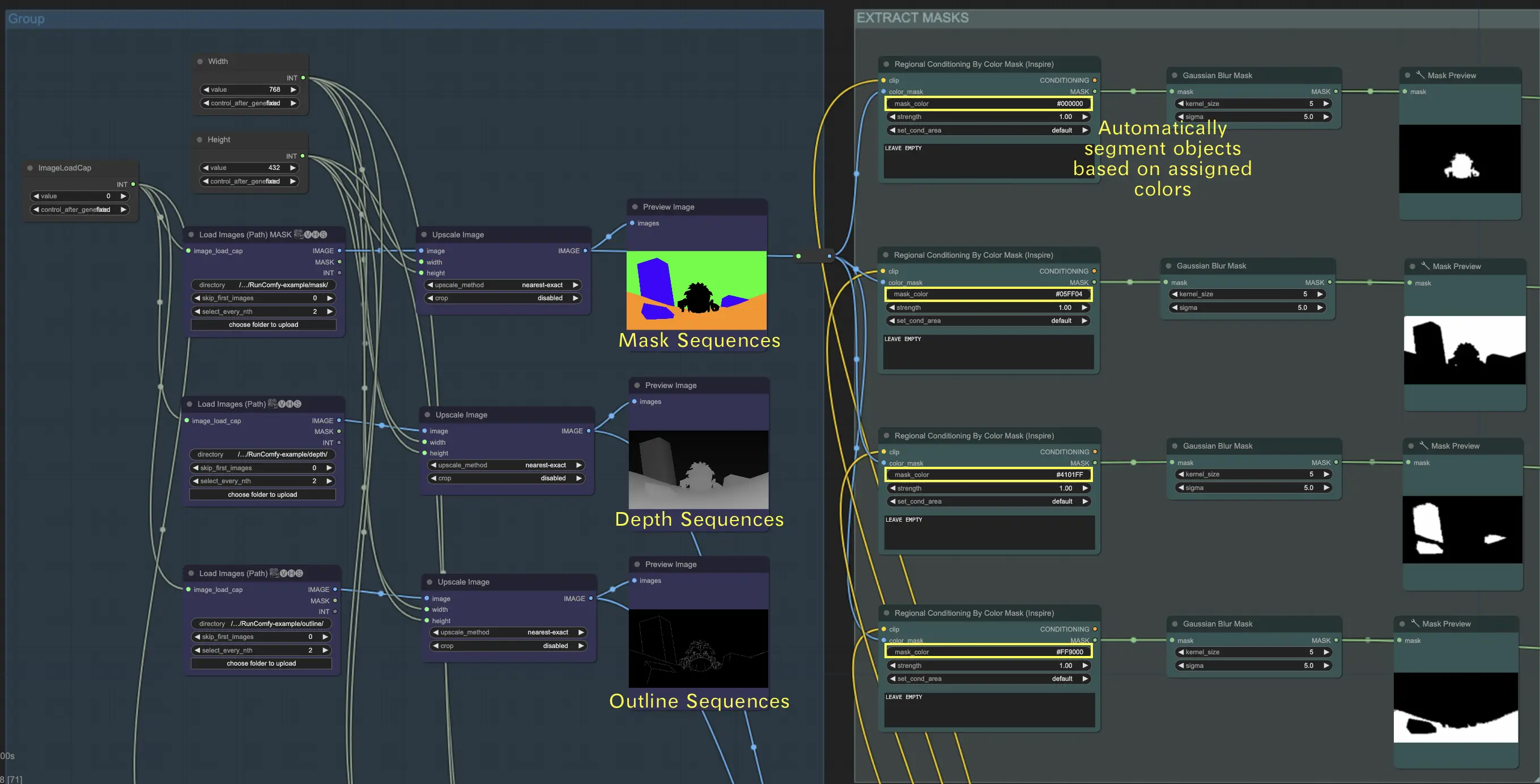
1. 画像シーケンスを読み込む
- マスクシーケンスを読み込む: マスクシーケンスを読み込み、次に"regional conditioning by color mask"ノードを使用してマスク画像内のオブジェクトを分離します。ステップ1で取得したHexコードを"mask_color"フィールドに入力します。このノードは割り当てられた色に基づいて自動的にオブジェクトをセグメント化します。 🌟 注意: このワークフローでは特定のHexコードを使用しています。別のマスク画像を使用する場合は、対応するHexコードを"mask_color"フィールドに入力してください。これにより、"regional conditioning by color mask"ノードがオブジェクトを正しくセグメント化します。
- 深度シーケンスを読み込む: 深度シーケンスを読み込んで、シーン内のオブジェクトの距離情報を提供します。
- アウトラインシーケンスを読み込む: アウトラインシーケンスを読み込んで、シーン内のオブジェクトの形状とエッジを定義します。
🌟 パスによる画像シーケンスの読み込み方法
シーケンスを整理する
- マスクシーケンスをフォルダに配置します。例えば、
{mask}です。 - 深度シーケンスを別のフォルダに配置します。例えば、
{depth}です。 - アウトラインシーケンスを別のフォルダに配置します。例えば、
{outline}です。
フォルダをアップロードする
- 私たちのファイルブラウザを使用して、これらのフォルダを
ComfyUI/inputディレクトリにアップロードします。
ディレクトリパス
- フルディレクトリパスは次のようになります:
/home/user/ComfyUI/input/{folder_name}。 - 例えば:
/home/user/ComfyUI/input/{mask}。
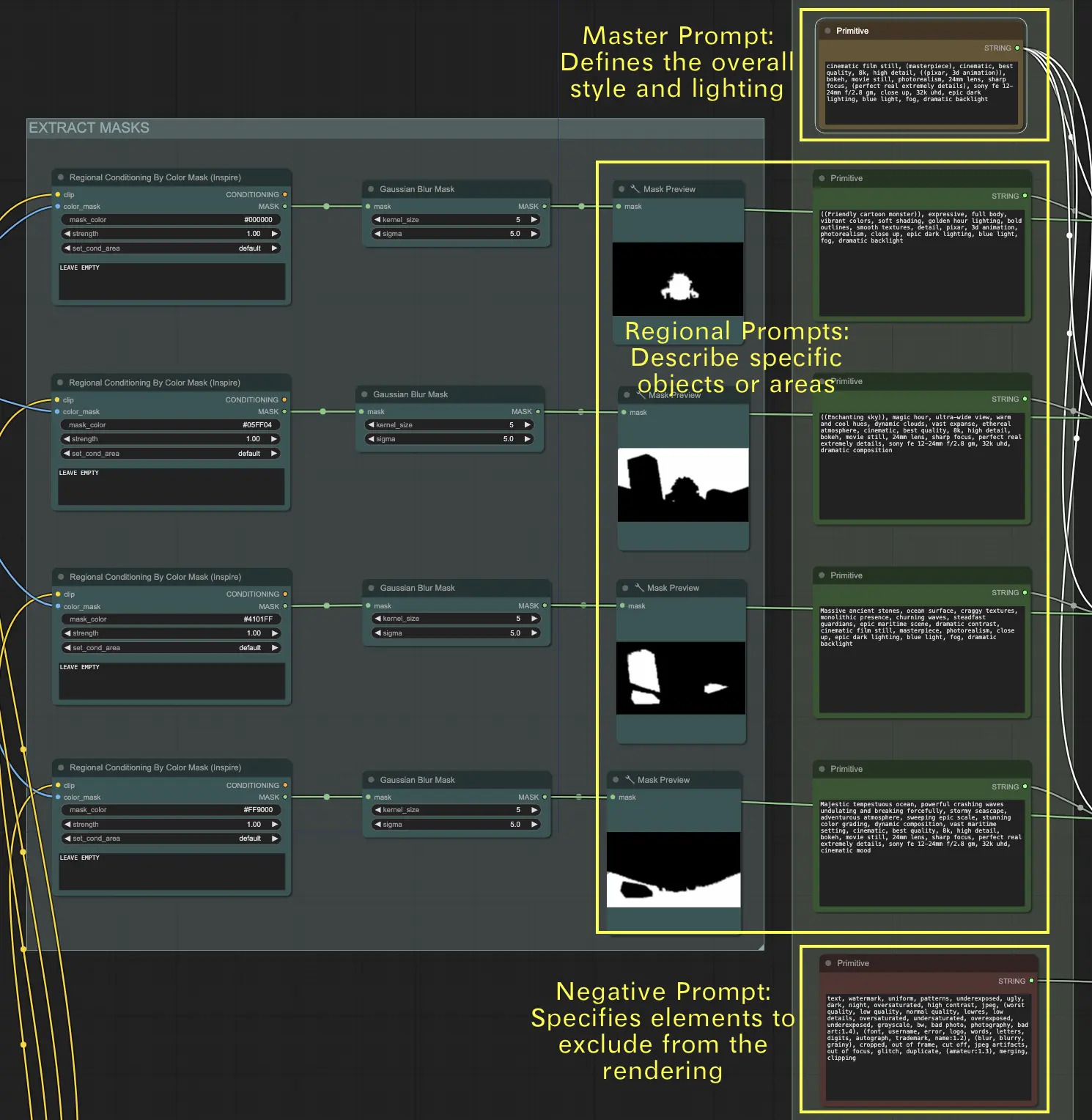
2. テキストプロンプトを使用して視覚効果を定義する
マスクシーケンスの場合、テキストプロンプトを使用してシーン内の各オブジェクトの視覚効果を指定します。
- マスタープロンプト: このプロンプトは、シーン全体のスタイルとライティングを設定します。最終的なレンダリングが達成するべき全体的なムード、雰囲気、および視覚的トーンを決定します。
- リージョナルプロンプト: これらのプロンプトは、シーン内の特定のオブジェクトまたは領域に対する詳細な説明を提供します。各プロンプトは、異なるオブジェクトまたは領域に対応し、すべての要素が意図した通りに正確に表現されるようにします。
- ネガティブプロンプト: このプロンプトは、レンダリングから除外すべき要素をリストアップします。これにより、最終的な出力から特定の特徴やオブジェクトが現れないようにし、シーンが集中し、不要な詳細がない状態に保ちます。
3. ControlNetモジュール
- 深度シーケンスをControlNet Depthモデルに入力します。
- アウトラインシーケンスをControlNet Cannyモデルに入力します。
4. AnimateDiffモジュール
- このモジュールを使用して、処理されたシーケンスからスムーズなアニメーションをレンダリングします。
5. オプションのIPAdapterの使用
- 追加のコンディショニングガイダンスのためにIPAdapterを使用して、生成された画像の一貫性と品質を向上させます。
Blenderの精密な3DデータとStable Diffusionを介したComfyUIの強力な画像生成機能を組み合わせることで、完全なクリエイティブコントロールを持つ非常にフォトリアリスティックまたはスタイライズされた3Dアニメーションを生成できます。