
FLUX LoRAは、特に自分のデータセットでAIモデルを微調整したい人々の間でAIコミュニティで非常に人気を集めています。このアプローチにより、既存のFLUXモデルをユニークなデータセットに合わせて簡単に適応させることができ、幅広いクリエイティブな取り組みに対して高いカスタマイズ性と効率性を提供します。ComfyUIに既に精通している場合、ComfyUI FLUX LoRA トレーニングワークフローを使用してFLUX LoRAモデルをトレーニングするのは簡単です。ワークフローと関連ノードはKijaiによって作成されたものであり、彼の貢献に大きな感謝を捧げます!詳細についてはKijai's GitHubをご覧ください。
ComfyUI FLUX LoRA トレーニングチュートリアル
ComfyUI FLUX LoRA トレーニングワークフローは、FLUX LoRAモデルをトレーニングするために設計された強力なプロセスです。ComfyUIでのトレーニングは、そのインターフェースに既に精通しているユーザーにとって、いくつかの利点を提供します。FLUX LoRA トレーニングを使用すると、推論に使用されるのと同じモデルを使用でき、同じPython環境内で互換性の問題が発生しません。さらに、異なる設定を比較するためのワークフローを構築し、トレーニングプロセスを強化できます。このチュートリアルでは、ComfyUIでFLUX LoRA トレーニングを設定し、使用する手順を説明します。
以下をカバーします:
- FLUX LoRA トレーニング用データセットの準備
- FLUX LoRA トレーニングプロセス
- FLUX LoRA トレーニングの実行
- FLUXおよびFLUX LoRAモデルの使用方法と場所
1. FLUX LoRA トレーニング用データセットの準備
FLUX LoRA トレーニング用のトレーニングデータを準備する際には、ターゲット被写体の高品質な画像を用意することが重要です。
この例では、特定のインフルエンサーの画像を生成するためにFLUX LoRAモデルをトレーニングしています。これには、さまざまなポーズや設定のインフルエンサーの高品質な画像セットが必要です。これらの画像を集める便利な方法は、ComfyUI Consistent Character workflowを使用することです。これにより、同じキャラクターが異なるポーズをとりながらも外観を一貫して表示する一連の画像を簡単に生成できます。トレーニングデータセットには、インフルエンサーのさまざまなポーズや設定の高品質な画像5枚を選択し、FLUX LoRA トレーニングが一貫性と正確な出力を生成するために必要な詳細を学習できるようにしています。
トレーニングデータを取得するプロセス
トレーニングデータの例

また、FLUX LoRA トレーニングは柔軟でさまざまなタイプのデータで機能するため、特定のニーズに基づいて独自のデータセットを収集することもできます。
2. FLUX LoRA トレーニングプロセス
FLUX LoRA トレーニングワークフローは、モデルをトレーニングおよび検証するために連携するいくつかの主要なノードから構成されています。ここでは、データセット、設定と初期化、トレーニングの3つの部分に分けて、主要ノードの詳細な概要を示します。
2.1. FLUX LoRA トレーニング用データセットの設定
データセットセクションには、トレーニングデータを構成およびカスタマイズするのに役立つ2つの重要なノードがあります: TrainDatasetGeneralConfig と TrainDatasetAdd。
2.1.1. TrainDatasetGeneralConfig
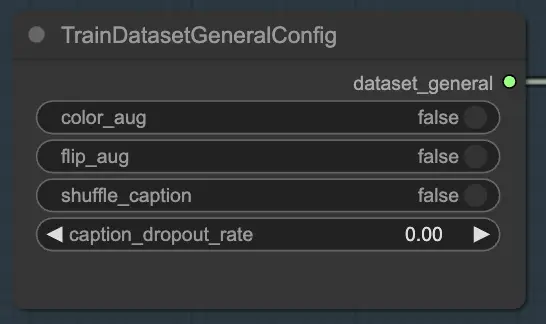
TrainDatasetGeneralConfig ノードは、FLUX LoRA トレーニングでのトレーニングデータセットの全体的な設定を定義する場所です。このノードでは、データの拡張と前処理のさまざまな側面を制御できます。たとえば、色の拡張を有効または無効にすることができ、異なる色のバリエーションにモデルが一般化できるようにすることができます。同様に、画像をランダムに水平反転するフリップ拡張を切り替えて、より多様なトレーニングサンプルを提供することができます。さらに、各画像に関連付けられたキャプションをシャッフルするオプションがあり、ランダム性を導入し、過学習を減少させます。キャプションのドロップアウト率を設定して、トレーニング中にキャプションをランダムに省略することができ、不完全なキャプションや不足しているキャプションに対してモデルをより堅牢にすることができます。
2.1.2. TrainDatasetAdd
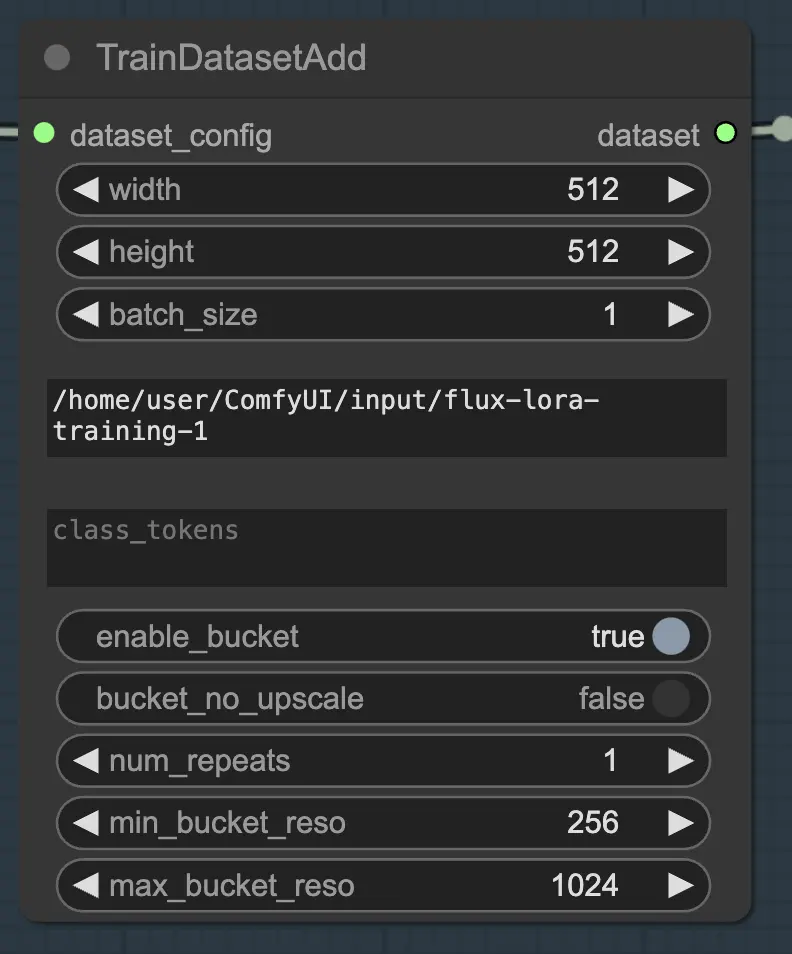
TrainDatasetAdd ノードは、FLUX LoRA トレーニングに含める各個別のデータセットの詳細を指定する場所です。
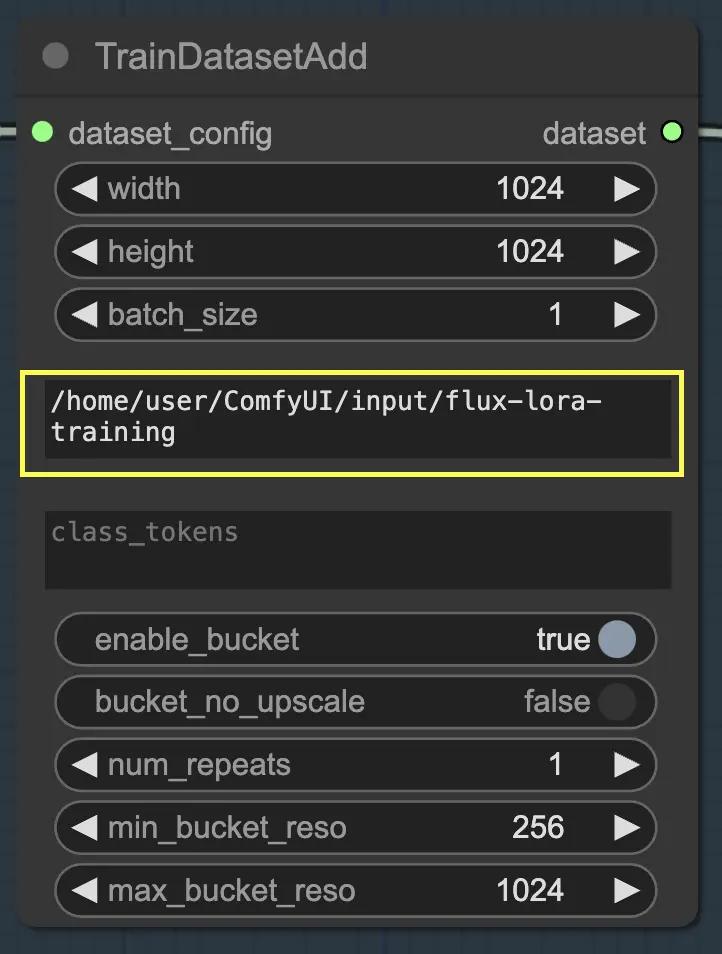
入力ディレクトリ: トレインデータセットパス
このノードを最大限に活用するためには、トレーニングデータを適切に整理することが重要です。RunComfyのファイルブラウザを使用する場合、トレーニングデータを /home/user/ComfyUI/input/{file-name} ディレクトリに配置します。ここで {file-name} はデータセットに割り当てた意味のある名前です。
トレーニングデータを適切なディレクトリに配置したら、そのディレクトリへのパスを TrainDatasetAdd ノードの image_dir パラメータに指定する必要があります。これにより、ノードがトレーニング画像を見つける場所を知ることができます。
クラストークン
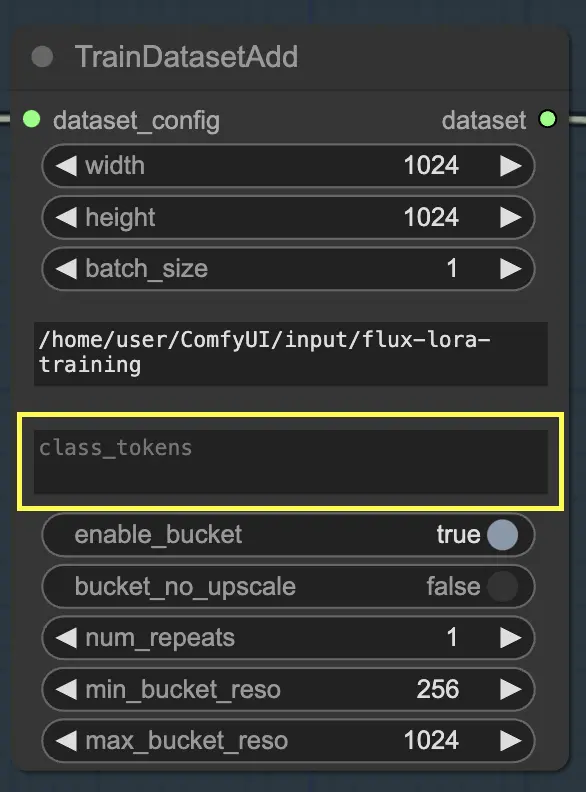
データセットが特定のクラストークンやトリガーワードを使用することで利益を得る場合、それらを class_tokens パラメータに入力することができます。クラストークンは、各キャプションの先頭に付加され、モデルの生成プロセスをガイドする特別な単語やフレーズです。たとえば、さまざまな動物種のデータセットでトレーニングしている場合、生成された画像に望む動物を示すために、「dog」、「cat」、「bird」などのクラストークンを使用できます。これらのクラストークンをプロンプトで使用することで、モデルに生成させたい特定の側面を制御できます。
解像度(幅と高さ)、バッチサイズの設定
image_dir および class_tokens パラメータに加えて、TrainDatasetAdd ノードはデータセットを微調整するためのいくつかのオプションを提供します。画像の解像度(幅と高さ)を設定し、トレーニングのバッチサイズを指定し、データセットをエポックごとに何回繰り返すかを決定できます。
複数のデータセット
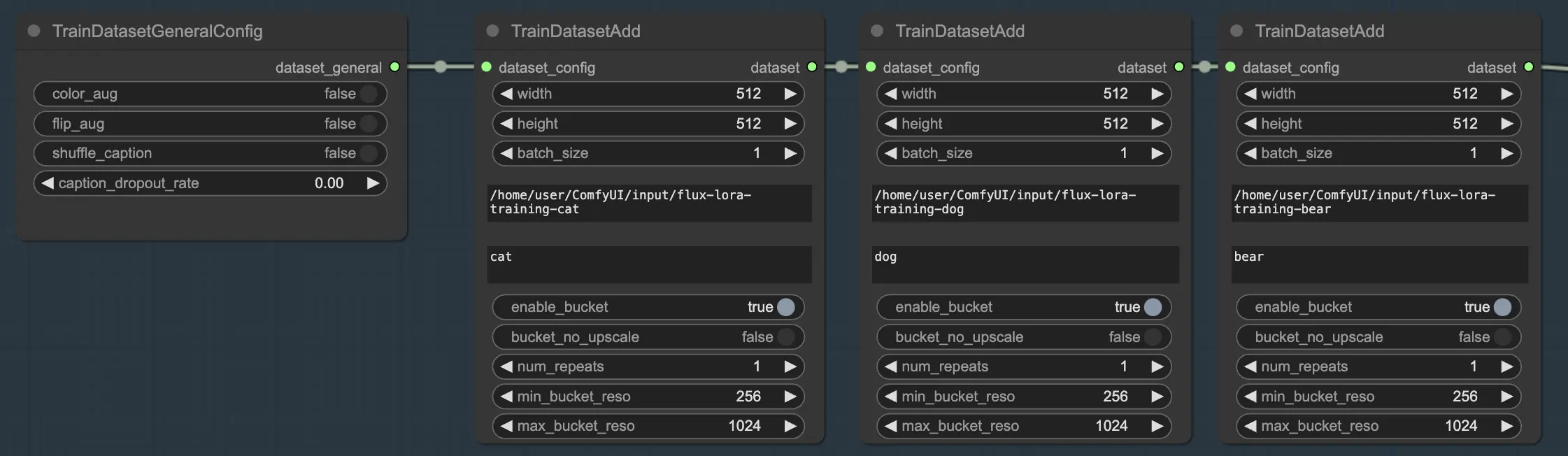
FLUX LoRA トレーニングの強力な機能の1つは、複数のデータセットをシームレスに組み合わせる能力です。FLUX LoRA トレーニングワークフローでは、3つの TrainDatasetAdd ノードが順番に接続されています。各ノードは、それぞれ独自の設定を持つ個別のデータセットを表します。これらのノードをリンクすることで、さまざまなソースからの画像とキャプションを統合した豊かで多様なトレーニングセットを作成できます。
これを説明するために、3つの別々のデータセットがあるシナリオを考えてみましょう: 1つは猫用、1つは犬用、もう1つは熊用です。これらのデータセットのそれぞれに専用の3つの TrainDatasetAdd ノードを設定できます。最初のノードでは、image_dir パラメータに「cats」データセットへのパスを指定し、class token を「cat」に設定し、解像度やバッチサイズなどの他のパラメータをニーズに合わせて調整します。同様に、2番目と3番目のノードを「dogs」および「bears」データセットに設定します。
このアプローチにより、FLUX LoRA トレーニングプロセスは、さまざまなカテゴリにわたってモデルの一般化能力を向上させるために、多様な画像を活用できます。
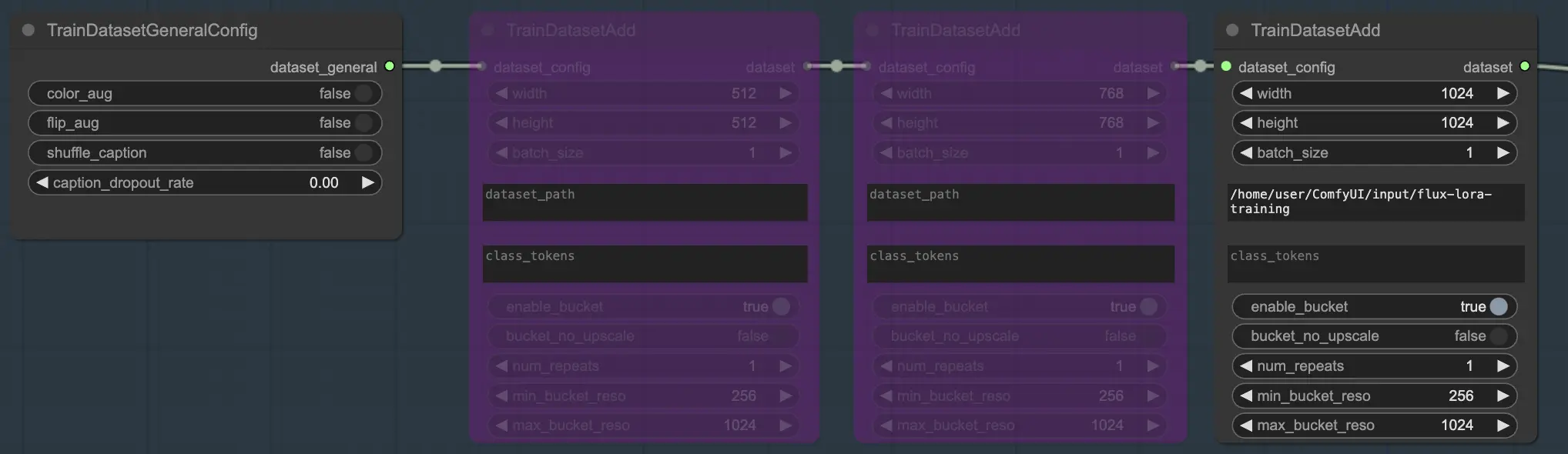
例
例では、モデルをトレーニングするために1つのデータセットのみを使用しているため、1つの TrainDatasetAdd ノードを有効にし、他の2つをバイパスしています。設定方法は以下のとおりです:
2.2. 設定と初期化
設定と初期化セクションでは、FLUX LoRA トレーニングの主要なコンポーネントとパラメータを構成します。このセクションには、トレーニング環境を設定するために連携するいくつかの重要なノードが含まれています。
2.2.1. FluxTrainModelSelect
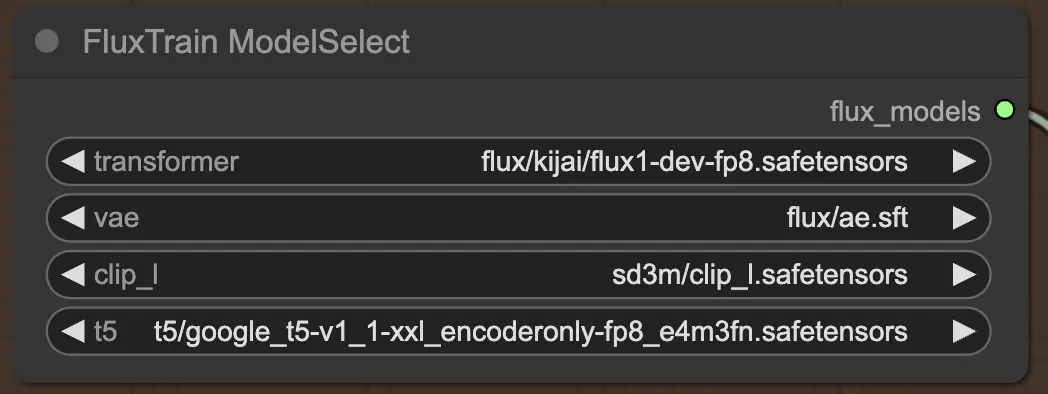
まず、FluxTrainModelSelect ノードがあります。これは、FLUX LoRA トレーニング中に使用されるFLUXモデルを選択する役割を担います。このノードでは、トランスフォーマー、VAE(変分オートエンコーダー)、CLIP_L(Contrastive Language-Image Pre-training)、およびT5(Text-to-Text Transfer Transformer)の4つの重要なモデルのパスを指定できます。これらのモデルはFLUXトレーニングプロセスのバックボーンを形成し、すべてRunComfyプラットフォーム上にセットアップされています。
2.2.2. OptimizerConfig
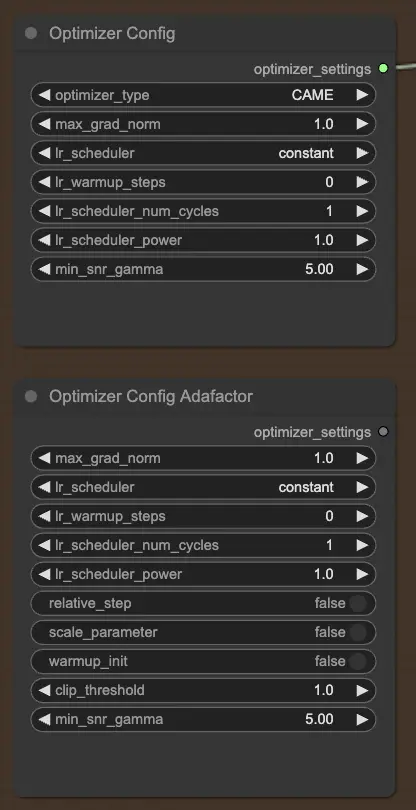
OptimizerConfig ノードは、FLUX LoRA トレーニング内でのオプティマイザーの設定に不可欠であり、トレーニング中にモデルのパラメータがどのように更新されるかを決定します。オプティマイザーのタイプ(例: AdamW, CAME)を選択し、勾配クリッピングのための最大勾配ノルムを設定し、学習率スケジューラ(例: constant, cosine annealing)を選択できます。さらに、ウォームアップステップやスケジューラパワーなどのオプティマイザー固有のパラメータを微調整し、さらなるカスタマイズのために追加の引数を提供できます。
メモリ効率が高く大規模なモデルを扱う能力を持つAdafactorオプティマイザーを好む場合は、OptimizerConfigAdafactor ノードを代わりに使用できます。
2.2.3. InitFluxLoRATraining
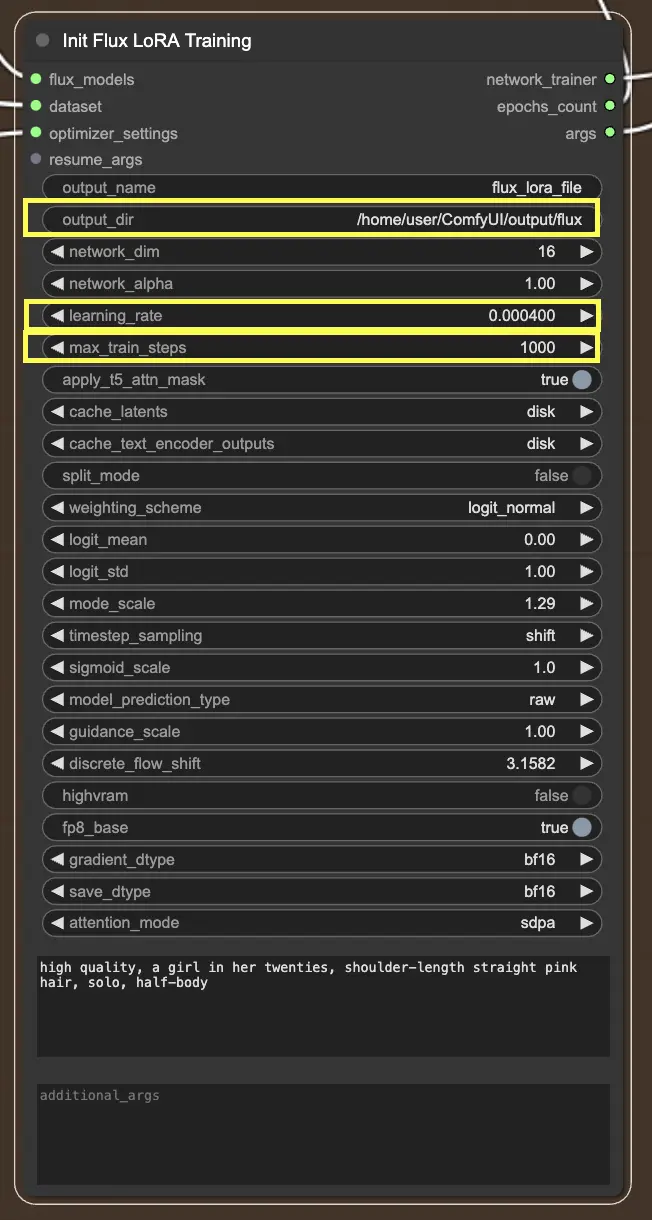
InitFluxLoRATraining ノードは、FLUX LoRA トレーニングプロセスを開始するためにすべての重要なコンポーネントが集まる中心的なハブです。
出力ディレクトリ: FLUX LoRA パス
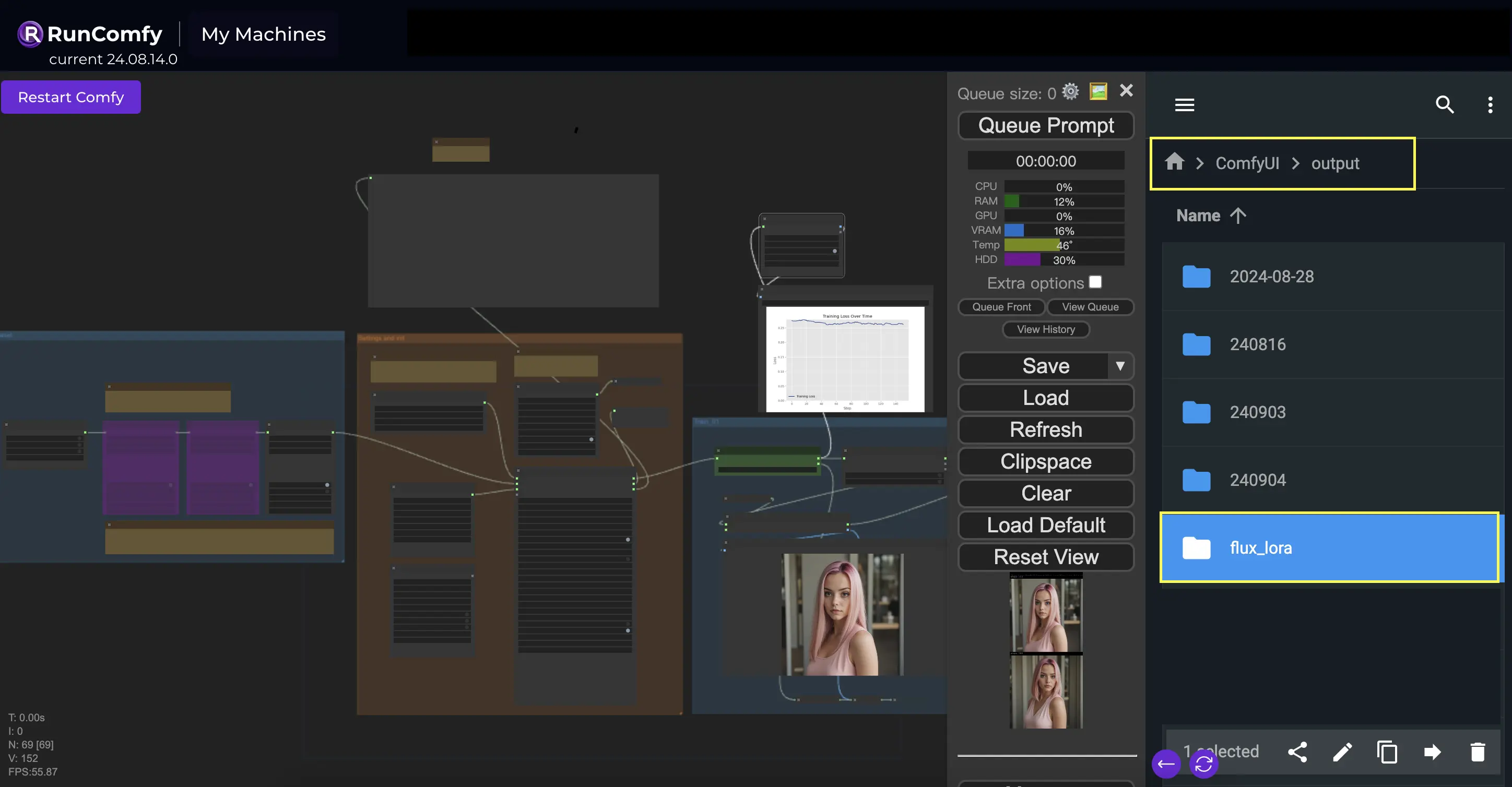
InitFluxLoRATraining ノードで指定する必要がある重要な点の1つは、トレーニング済みモデルが保存される出力ディレクトリです。RunComfyプラットフォーム上では、/home/user/ComfyUI/output/{file_name} を出力の場所として選択できます。トレーニングが完了すると、ファイルブラウザで確認できます。
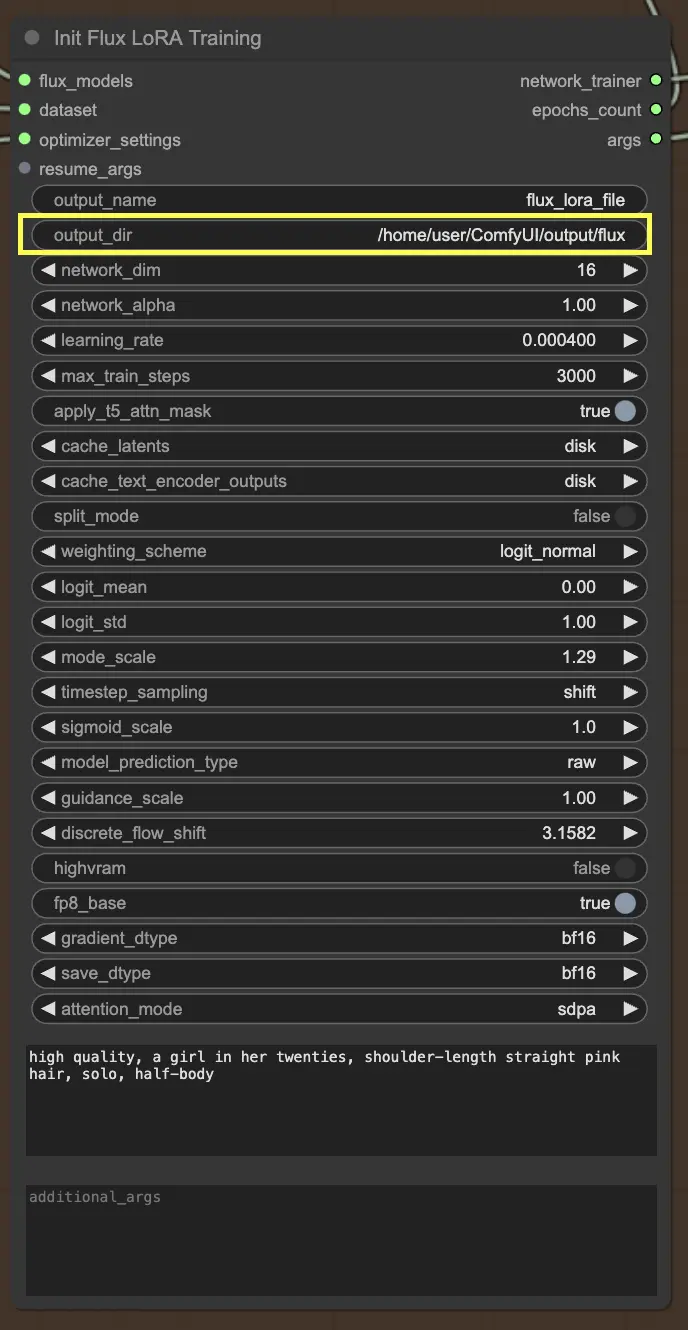
ネットワーク寸法と学習率
次に、ネットワーク寸法と学習率を設定します。ネットワーク寸法はLoRAネットワークのサイズと複雑さを決定し、学習率はモデルがどの程度迅速json さく学習し適応するかを制御します。
最大トレインステップ
もう1つ考慮すべき重要なパラメータは max_train_steps です。これは、トレーニングプロセスがどれだけ長く実行されるか、つまり、モデルが完全に焼き上がるまでに必要なステップ数を決定します。この値を特定のニーズやデータセットのサイズに基づいて調整できます。モデルが十分に学習し、魅力的な出力を生成できるスイートスポットを見つけることが重要です!
2.3.4. FluxTrainValidationSettings
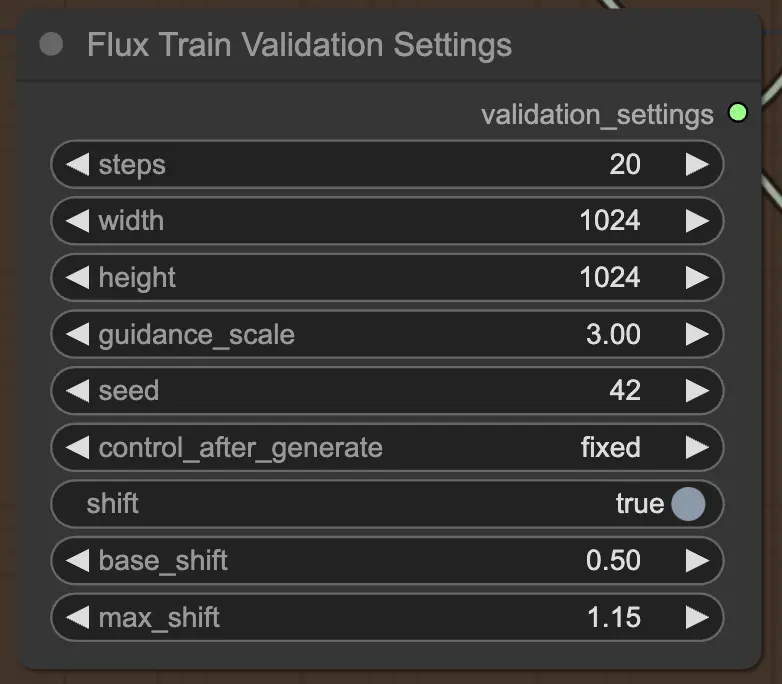
最後に、FluxTrainValidationSettings ノードを使用して、FLUX LoRA トレーニングプロセス中にモデルのパフォーマンスを評価するための検証設定を構成できます。検証ステップ数、画像サイズ、ガイダンススケール、再現性のためのシードを設定できます。さらに、タイムステップサンプリング方法を選択し、シグモイドスケールとシフトパラメータを調整して、タイムステップスケジューリングを制御し、生成された画像の品質を向上させることができます。
3. トレイン
FLUX LoRA トレーニングのトレインセクションは、魔法が起こる場所です。これは、Train_01、Train_02、Train_03、および Train_04 の4つの部分に分かれており、FLUX LoRA トレーニングプロセスの異なる段階を表し、モデルを段階的に洗練し改善することができます。
3.1. Train_01
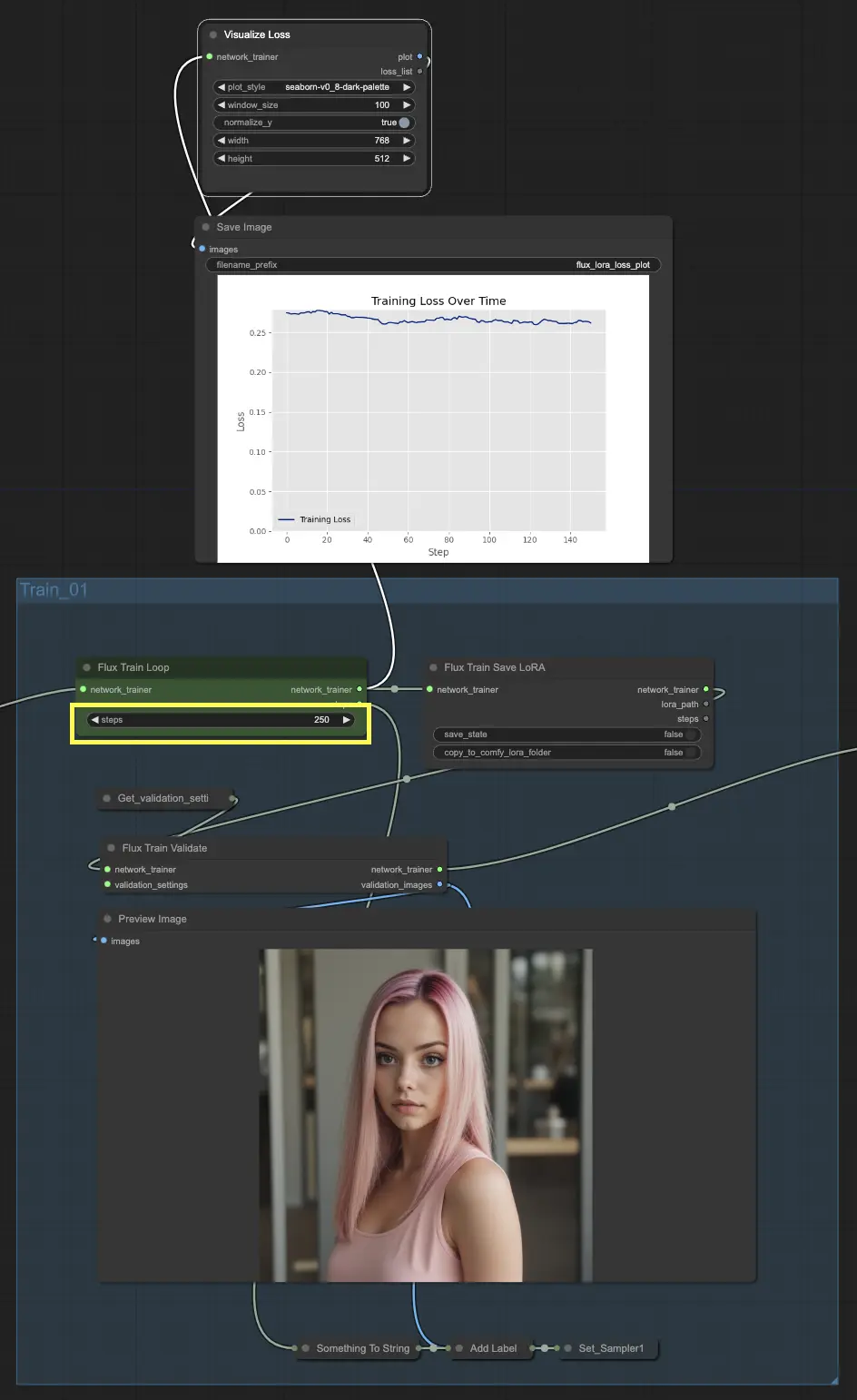
まず Train_01 から始めましょう。ここでは、最初のトレーニングループが行われます。このセクションの主役は FluxTrainLoop ノードであり、指定されたステップ数でトレーニングループを実行する役割を担います。この例では250ステップに設定していますが、ニーズに応じて調整できます。トレーニングループが完了すると、トレーニング済みモデルは FluxTrainSave ノードに渡され、定期的にモデルを保存します。これにより、トレーニングの進捗を追跡し、予期しない中断から回復するために、トレーニングの異なる段階でモデルのチェックポイントを確保できます。
しかし、トレーニングはモデルの保存だけではありません。そのパフォーマンスを検証して、どれだけうまく機能しているかを確認する必要があります。それが FluxTrainValidate ノードの役割です。このノードは、トレーニング済みモデルを検証データセットを使用してテストします。このデータセットはトレーニングデータとは別であり、モデルが未見の例にどれだけ一般化できるかを評価するのに役立ちます。FluxTrainValidate ノードは、検証データに基づいてサンプル画像を生成し、この段階でのモデルの出力を視覚的に示します。
トレーニングの進捗を監視するために、VisualizeLoss ノードがあります。この便利なノードは、トレーニング中の損失を視覚化し、モデルがどれだけうまく学習しているか、良い解決策に収束しているかを確認できます。まるで個人トレーナーが進捗を追跡し、目標を達成する手助けをしてくれるようなものです。
3.2. Train_02, Train_03, Train_04
FLUX LoRA トレーニングの Train_01 から続く Train_02 では、指定された追加のステップ数(例: 250ステップ)で出力がさらにトレーニングされます。Train_03 および Train_04 も同様のパターンに従い、スムーズな進行のために更新された接続でトレーニングを拡張します。各ステージはFLUX LoRAモデルを出力し、パフォーマンスをテストおよび比較できます。
例
例では、Train_01 および Train_02 のみを選択し、それぞれ250ステップで実行しています。Train_03 および Train_04 は今のところバイパスしています。しかし、特定のニーズやリソースに基づいて、トレーニングセクションとステップ数を実験し調整してください。
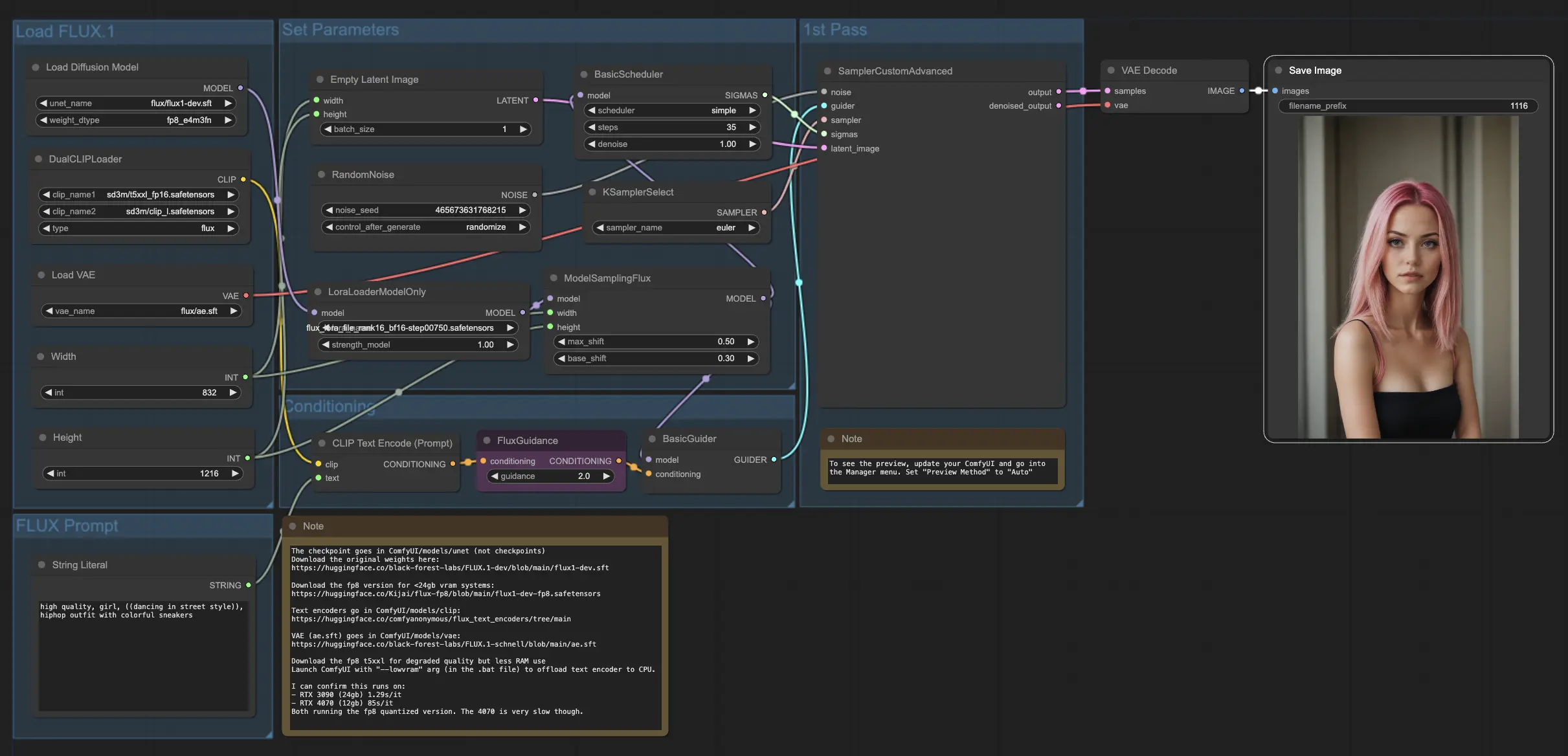
4. FLUXおよびFLUX LoRAモデルの使用方法と場所
FLUX LoRAモデルを取得したら、それを FLUX LoRA ワークフロー に組み込むことができます。既存のLoRAモデルをトレーニング済みモデルに置き換え、結果をテストしてそのパフォーマンスを評価します。
例
例では、FLUX LoRAワークフローを使用して、FLUX LoRAモデルを適用し、そのパフォーマンスを観察することにより、より多くのインフルエンサー画像を生成しています。
ライセンス
ライセンスファイルを表示:
flux/model_licenses/LICENSE-FLUX1-dev
flux/model_licenses/LICENSE-FLUX1-schnell
FLUX.1 [dev] モデルは、Black Forest Labs. Inc. によって FLUX.1 [dev] 非商用ライセンスの下でライセンスされています。著作権 Black Forest Labs. Inc.
いかなる場合においても、Black Forest Labs, Inc. は、本モデルの使用に起因する、契約、過失、またはその他の理由に基づく請求、損害、またはその他の責任に対して責任を負いません。






