Linear Mask Dilation | 驚くべきアニメーション
ComfyUI Linear Mask Dilationは、驚くべきビデオアニメーションを作成するための強力なワークフローです。ダンサーなどの被写体を変換することで、マスク拡張効果を使用してシームレスに異なるシーンを移動させることができます。このワークフローは、単一の被写体ビデオに特化しています。Linear Mask Dilationを効果的に使用する方法をステップバイステップで学び、被写体ビデオのアップロードからプロンプトの設定、さまざまなパラメータの調整まで最適な結果を得るためのガイドを提供します。ComfyUI Linear Mask Dilationを使用して、クリエイティビティを発揮し、ビデオアニメーションを生き生きとさせましょう。ComfyUI Linear Mask Dilation ワークフロー
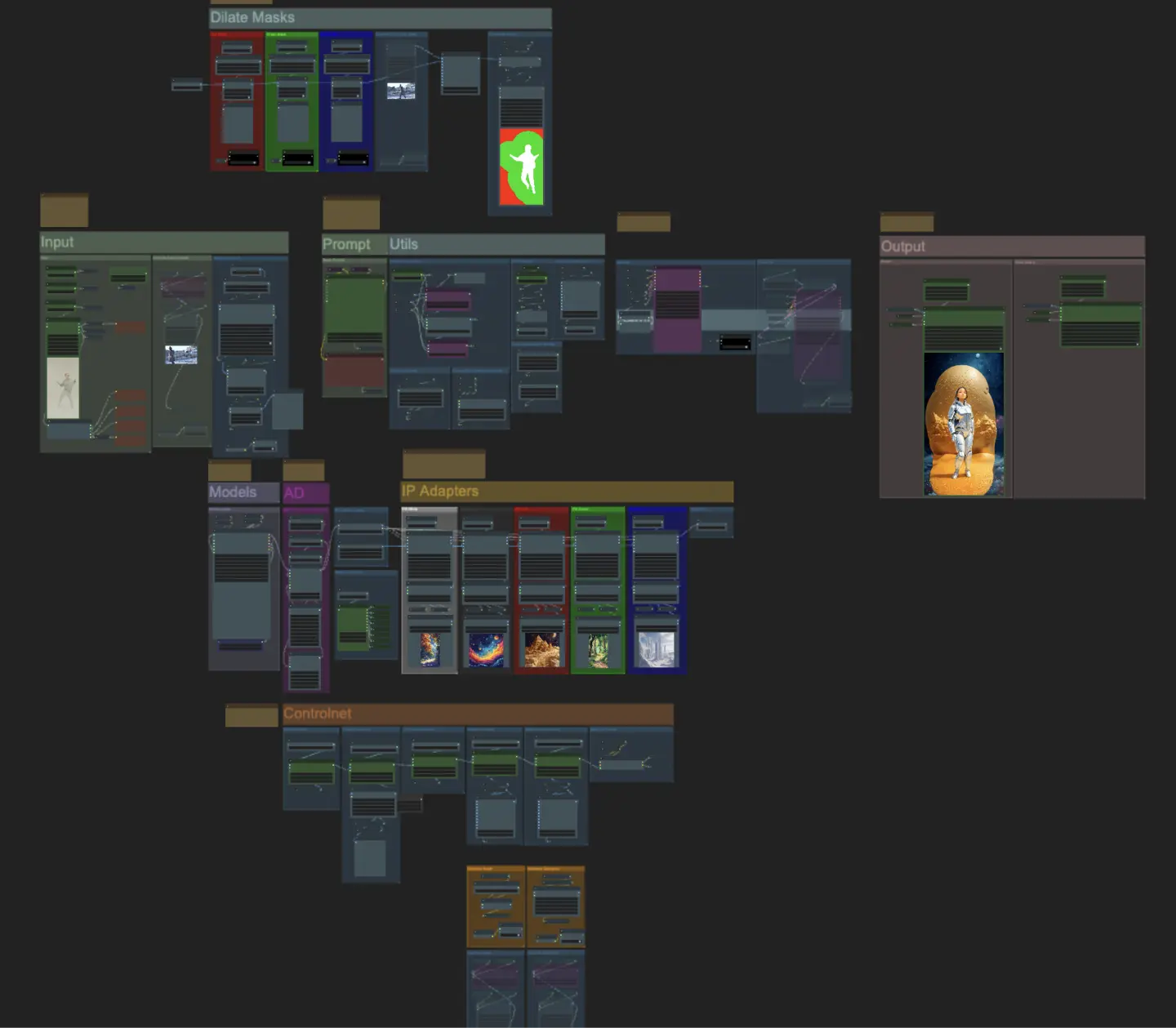
このワークフローを実行しますか?
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI Linear Mask Dilation 例
ComfyUI Linear Mask Dilation 説明
ComfyUI Linear Mask Dilation
被写体(ダンサー)を変換し、マスク拡張効果を介して異なるシーンを移動させることで、驚くべきビデオアニメーションを作成します。このワークフローは、単一の被写体ビデオで使用するように設計されています。
ComfyUI Linear Mask Dilationワークフローの使用方法:
- 入力セクションに被写体ビデオをアップロードします
- 最終ビデオの希望する幅と高さを選択し、入力ビデオのフレームをスキップする数を"every_nth"で設定します。また、レンダリングする総フレーム数を"frame_load_cap"で制限できます。
- ポジティブおよびネガティブプロンプトを入力します。シーンの遷移が発生するタイミングに合わせてバッチフレーム時間を設定します。
- 各IPアダプターの被写体マスク色の画像をアップロードします:
- 白 = 被写体(ダンサー)
- 黒 = 最初の背景
- 赤 = 赤の拡張マスク背景
- 緑 = 緑の拡張マスク背景
- 青 = 青の拡張マスク背景
- 「Models」セクションで良いLCMチェックポイント(例: Machine DelusionsのParadigmLCM)を読み込みます。
- モデルローダーの下にあるLoraスタッカーを使用して、任意のloraを追加します
- キュープロンプトを押します
入力
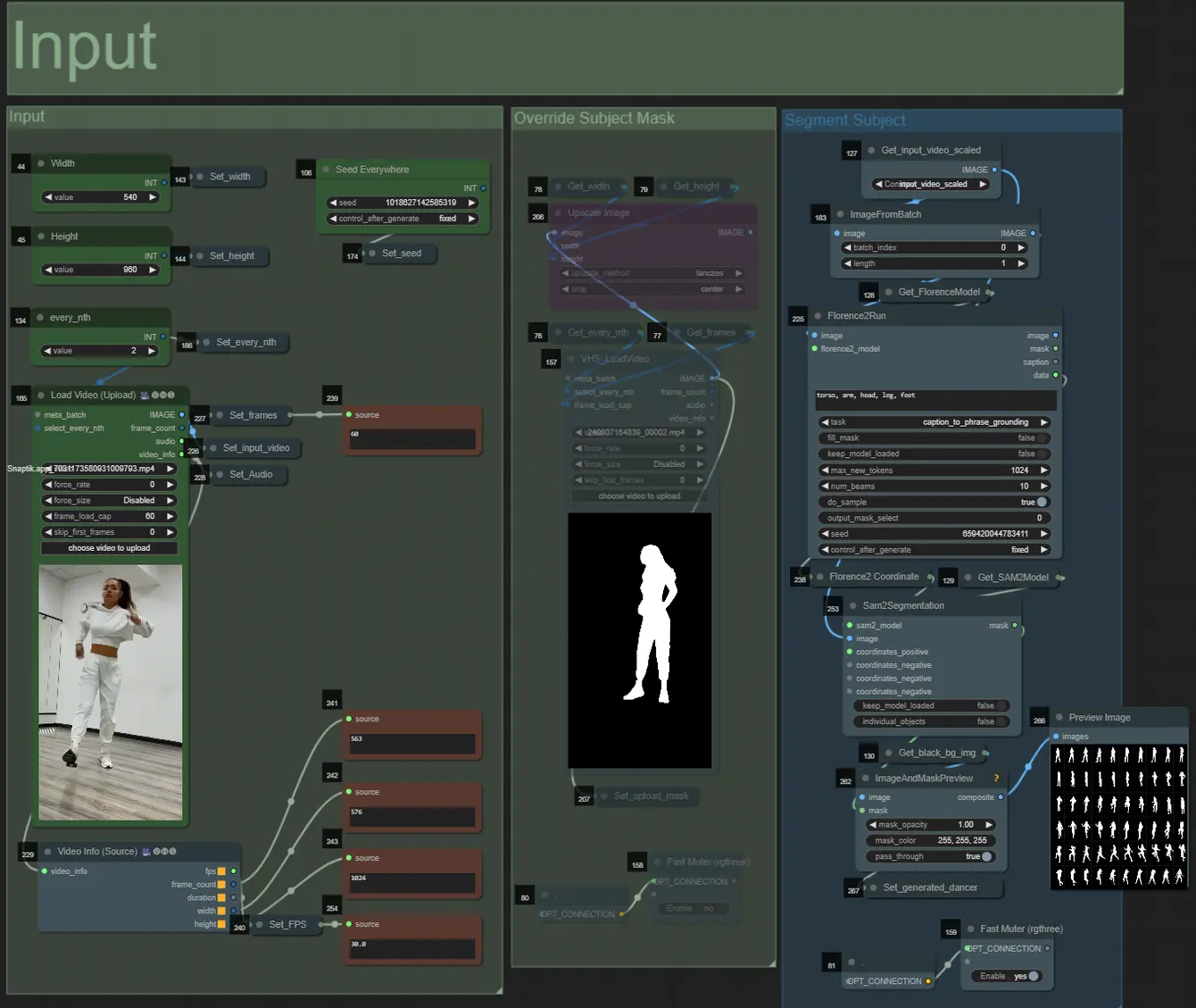
- 左上の2つの入力を使用して幅と高さを調整できます
- every_nthは入力フレームのスキップ数を設定します(例: 2 = 1フレームごとにスキップ)
- 左下の数値フィールドには、アップロードされた入力ビデオの情報(総フレーム数、幅、高さ、FPS)が表示されます
- 既に生成された被写体のマスクビデオがある場合(白い被写体が黒い背景上にある必要があります)、"Override Subject Mask"セクションをミュート解除してマスクビデオをアップロードできます。オプションで、処理時間を節約するために"Segment Subject"セクションをミュートできます。
- 時にはセグメント化された被写体が完全でないことがあります。その場合は、右下のプレビューウィンドウでマスクの品質を確認できます。その場合、"Florence2Run"ノードのプロンプトで"head"、"chest"、"legs"などの異なる体の部位をターゲットにして、より良い結果が得られるかどうか試してみることができます。
プロンプト
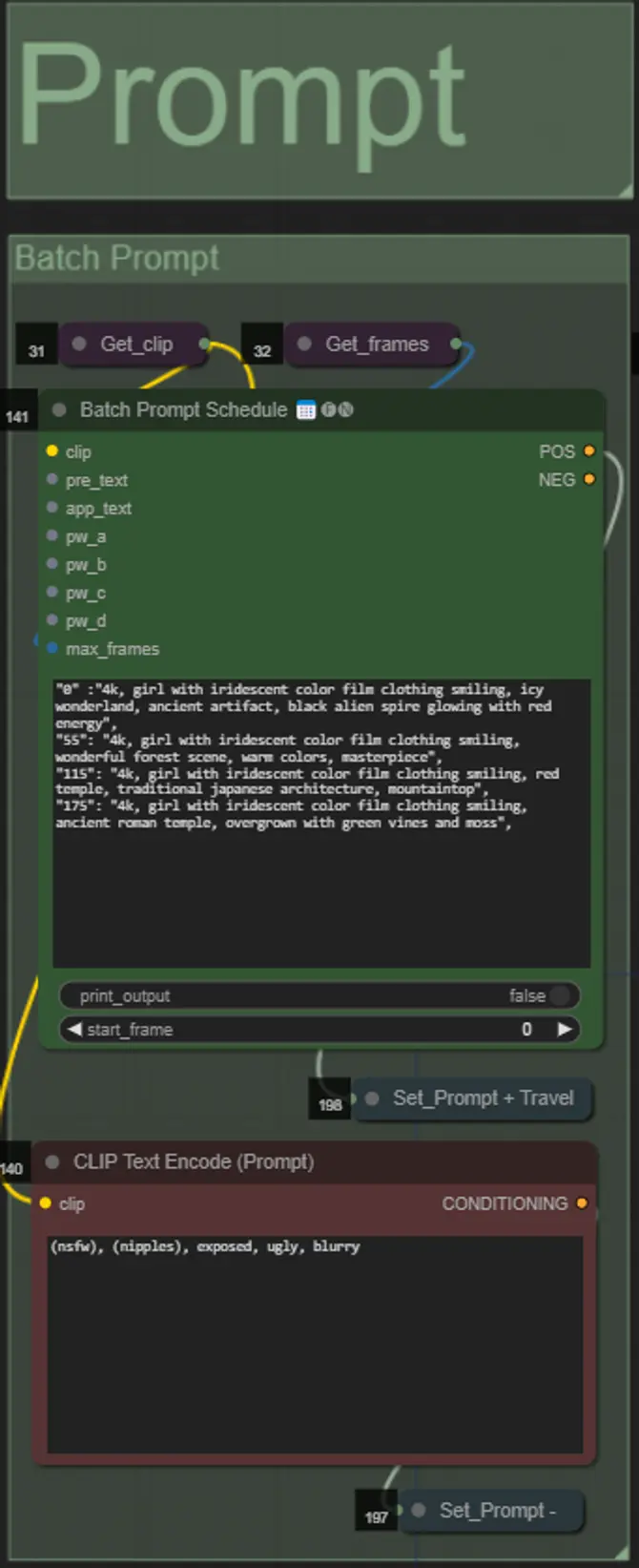
- バッチフォーマットを使用してポジティブプロンプトを設定します:
- 例: "0": "4k, masterpiece, 1girl standing on the beach, absurdres", "25": "HDR, sunset scene, 1girl with black hair and a white jacket, absurdres", …
- ネガティブプロンプトは通常のフォーマットで、必要に応じて埋め込みを追加できます。
マスク拡張
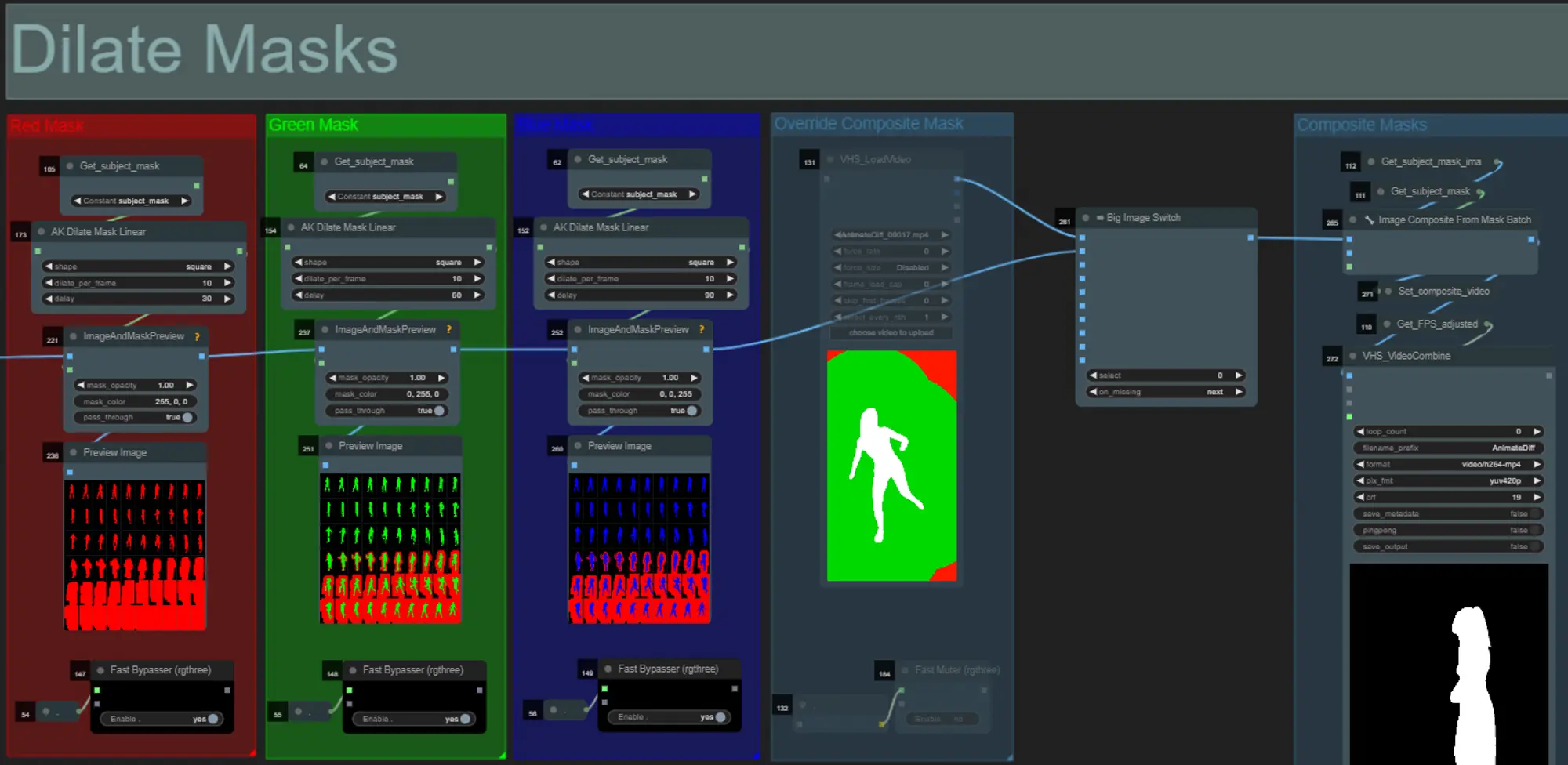
- 各色のグループは、それによって生成される拡張マスクの色に対応します。
- 以下のノードを使用して、マスクの形状、拡張速度、およびフレーム遅延を設定できます:
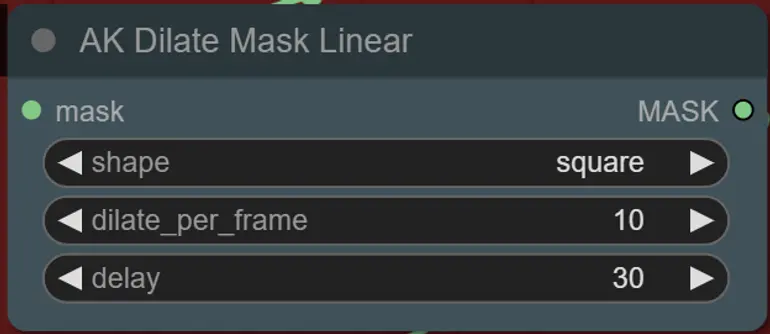
- 形状: "circle"は最も正確ですが、生成に時間がかかります。最終レンダリングの準備ができたらこれを設定します。"square"は計算が速く、精度は低いですが、ワークフローをテストし、IPアダプター画像を決定するのに最適です。
- dilate_per_frame: マスクがどれだけ速く拡張するかを設定します。大きな数値 = 速い拡張速度
- delay: マスクが拡張を開始するまでのフレーム数を設定します。
- 既に生成された複合マスクビデオがある場合は、"Override Composite Mask"グループをミュート解除してアップロードできます。上書きする場合は、処理時間を節約するために拡張マスクグループをバイパスすることをお勧めします。
モデル
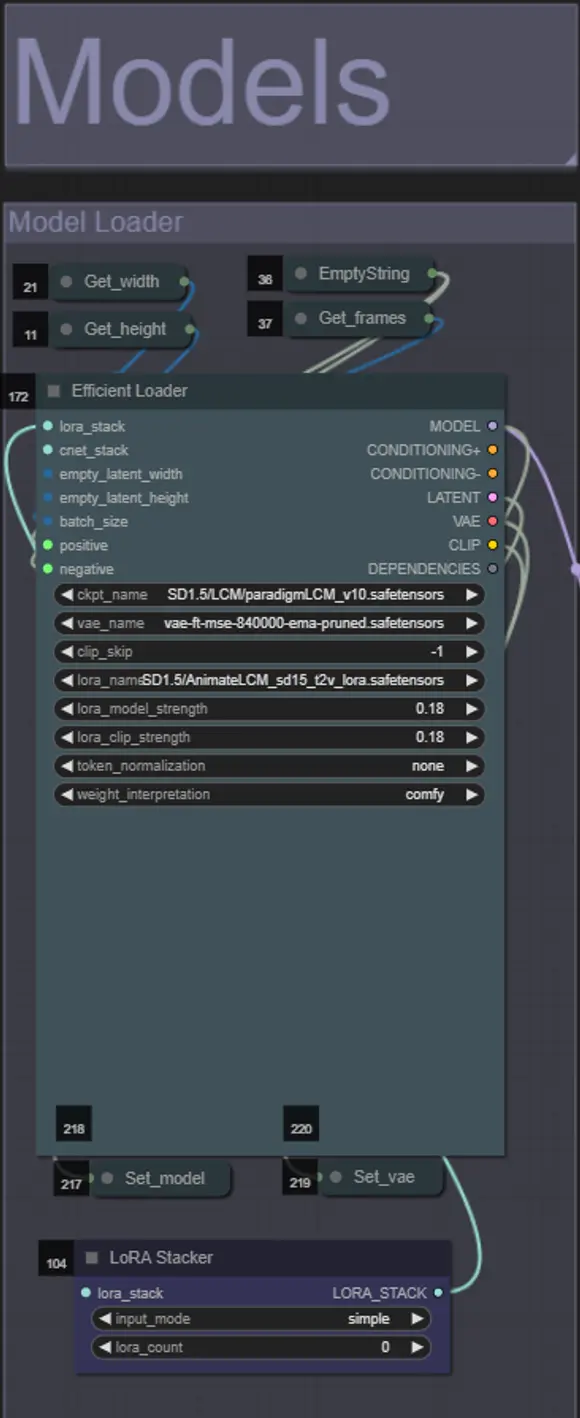
- チェックポイントには良いLCMモデルを使用します。Machine DelusionsのParadigmLCMをお勧めします。
- 最終結果をさらに強化するために、低い重み0.18でAnimateLCM_sd15_t2v_lora.safetensorsを指定することもできます。
- モデルローダーの下にある青いLoraスタッカーを使用して、追加のLoraをモデルに追加します。
AnimateDiff
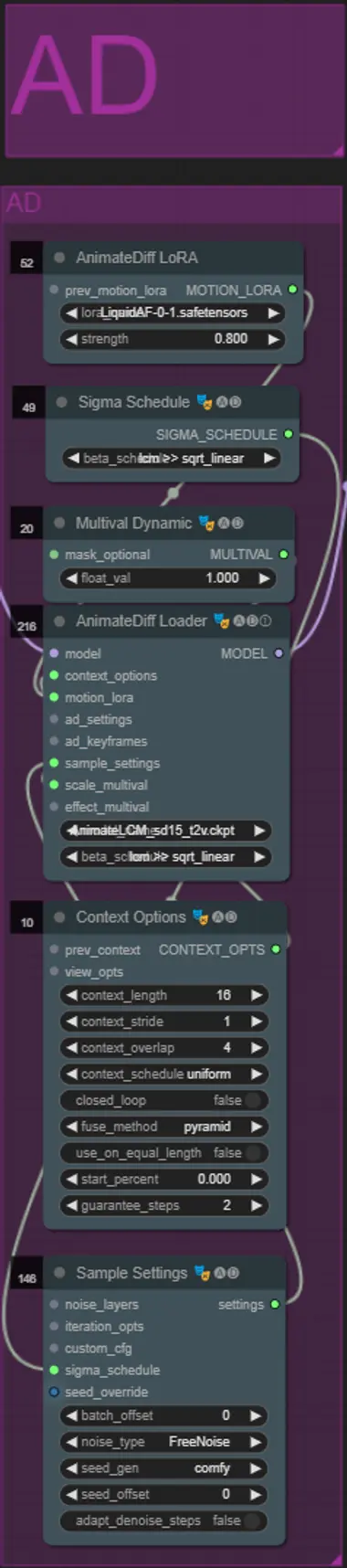
- 私が使用したMotion Lora(LiquidAF-0-1.safetensors)の代わりに異なるMotion Loraを設定できます。
- 結果により多くの動きを持たせたい場合は、Multival Dynamicのfloat値を上げるか、動きを少なくしたい場合は値を下げます。
IPアダプター
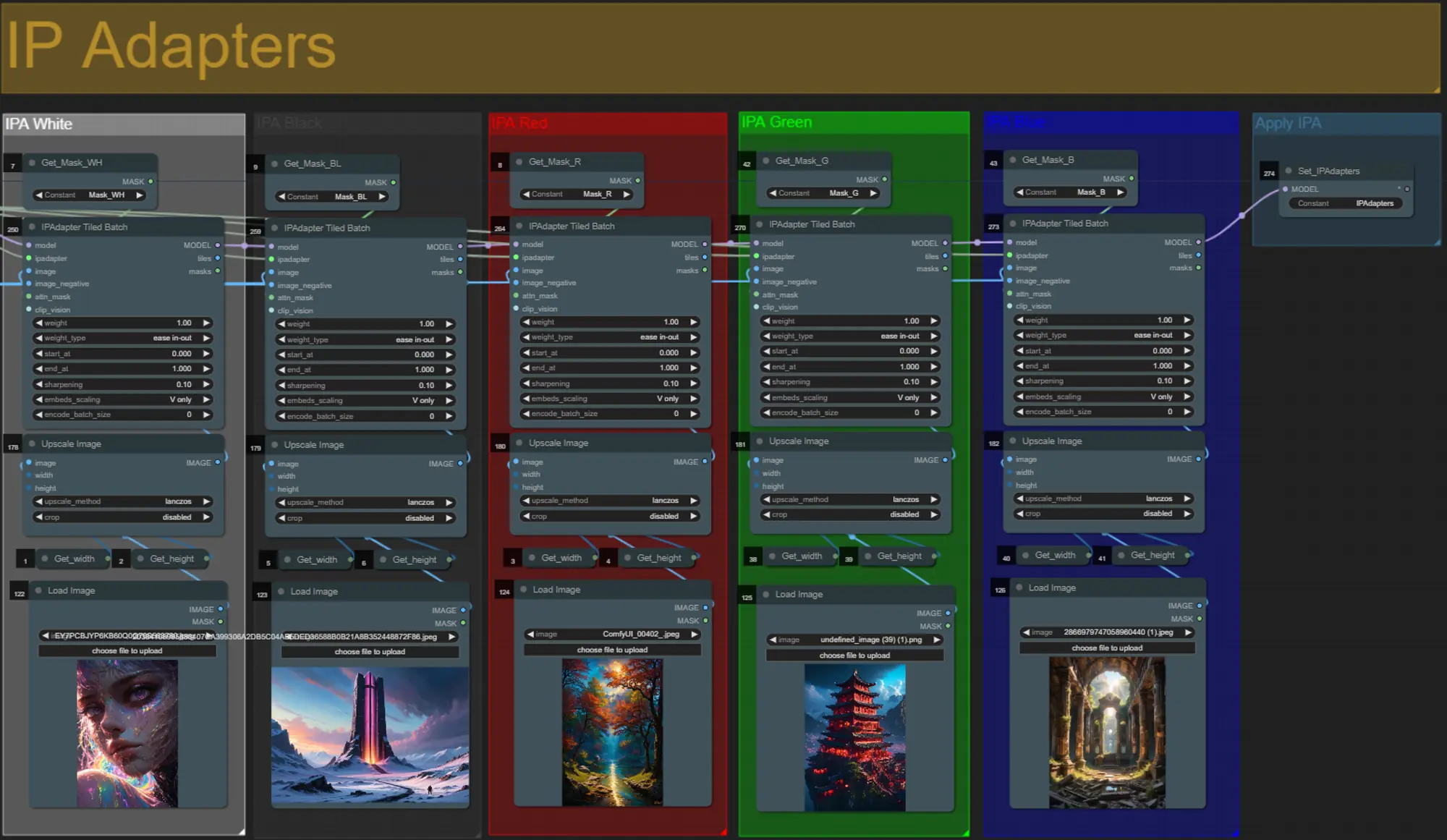
- ここでは各拡張マスクの背景およびビデオ被写体をレンダリングするために使用される参照被写体を指定できます。
- 各グループの色はターゲットとするマスクを表します:
- 白 = 被写体(ダンサー)
- 黒 = 最初の背景
- 赤 = 赤の拡張マスク背景
- 緑 = 緑の拡張マスク背景
- 青 = 青の拡張マスク背景
- 最終レンダリングが入力IPアダプター画像により忠実に従うようにしたい場合は、IPA Unified LoaderグループでIPAdapterプリセットをVIT-GからPLUSに変更できます。
ControlNet
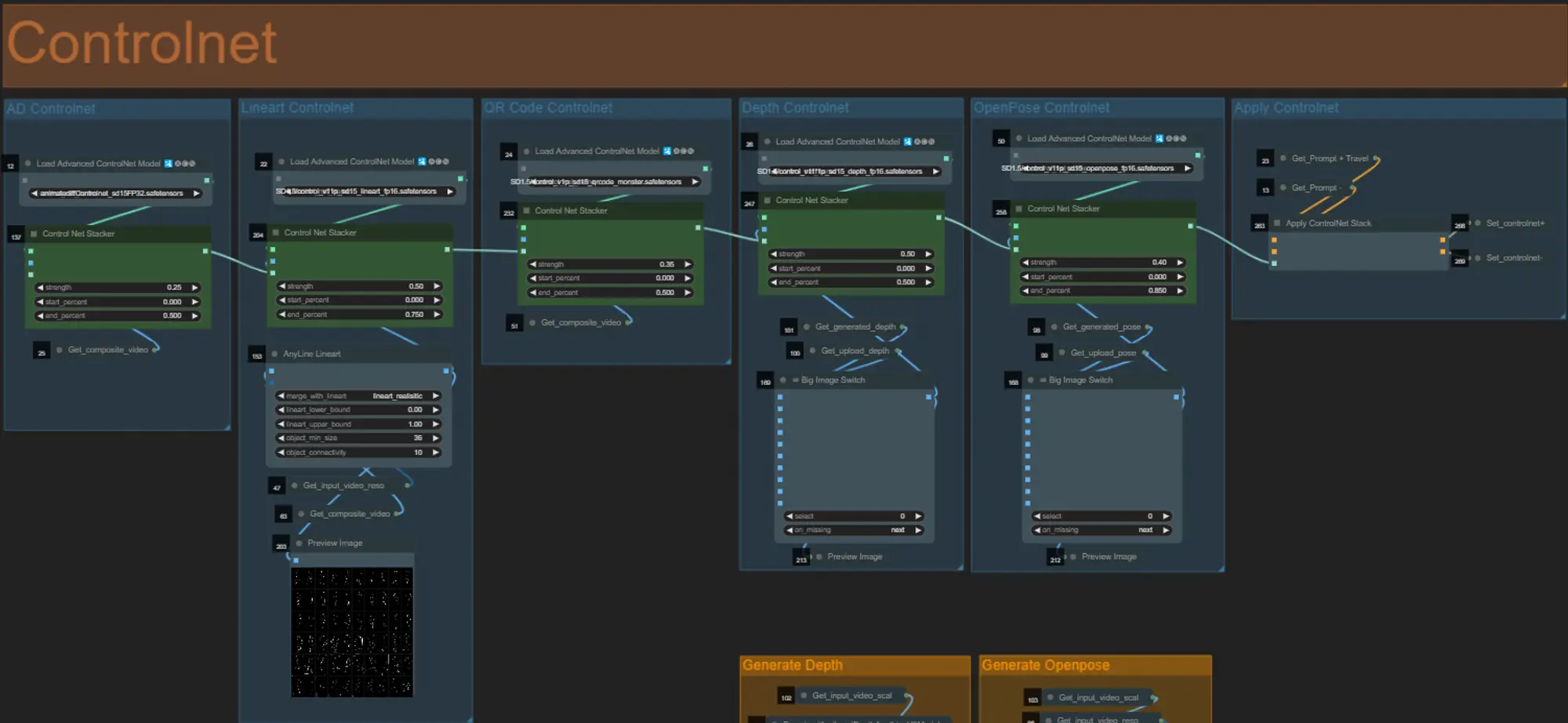
- このワークフローでは、AD、Lineart、QR Code、Depth、OpenPoseを含む5つの異なるcontrolnetを使用します。
- controlnetへのすべての入力は自動的に生成されます
- 希望する場合は、"Override Depth"および"Override Openpose"グループをミュート解除して、DepthおよびOpenpose controlnetの入力ビデオを上書きすることができます。
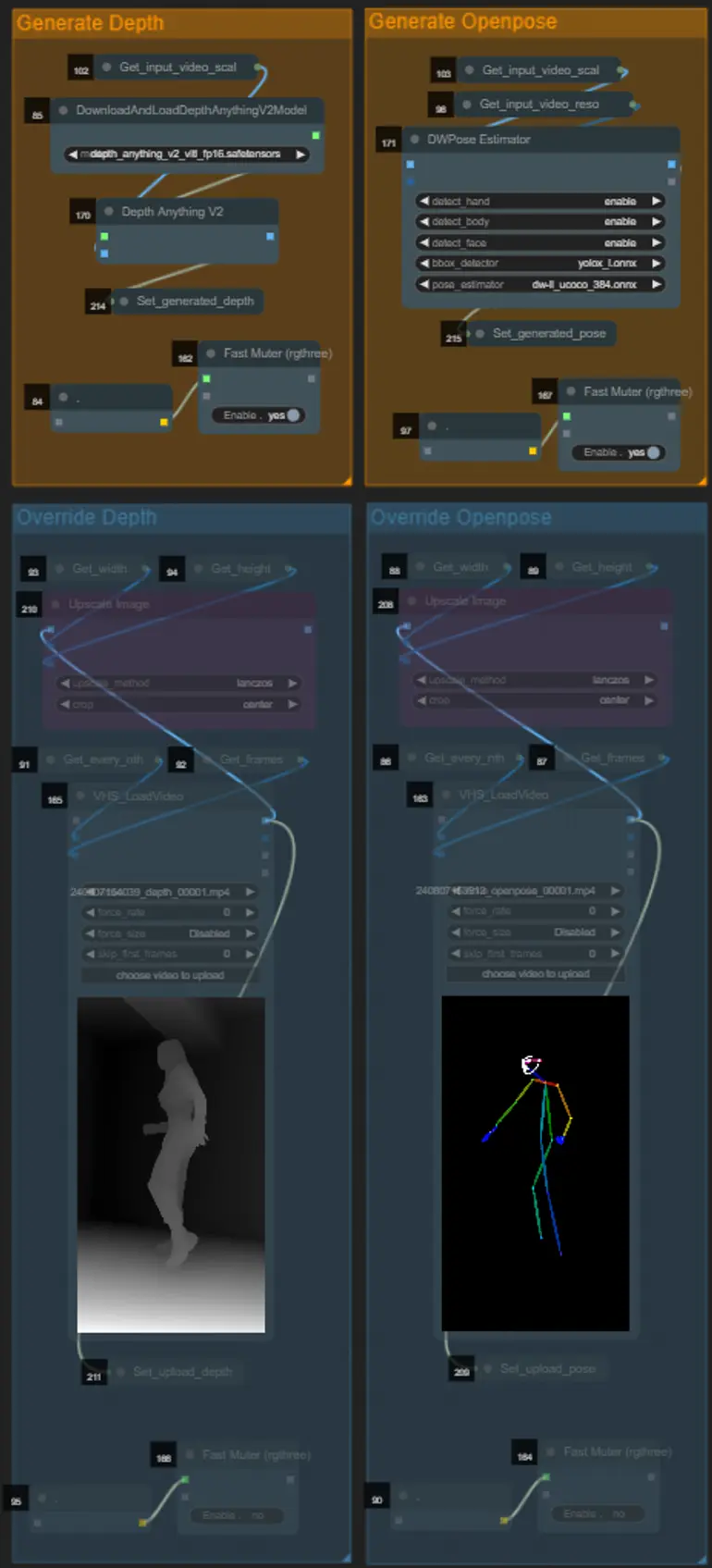
- 上書きする場合は、処理時間を節約するために"Generate Depth"および"Generate Openpose"グループをミュートすることをお勧めします。
サンプラー
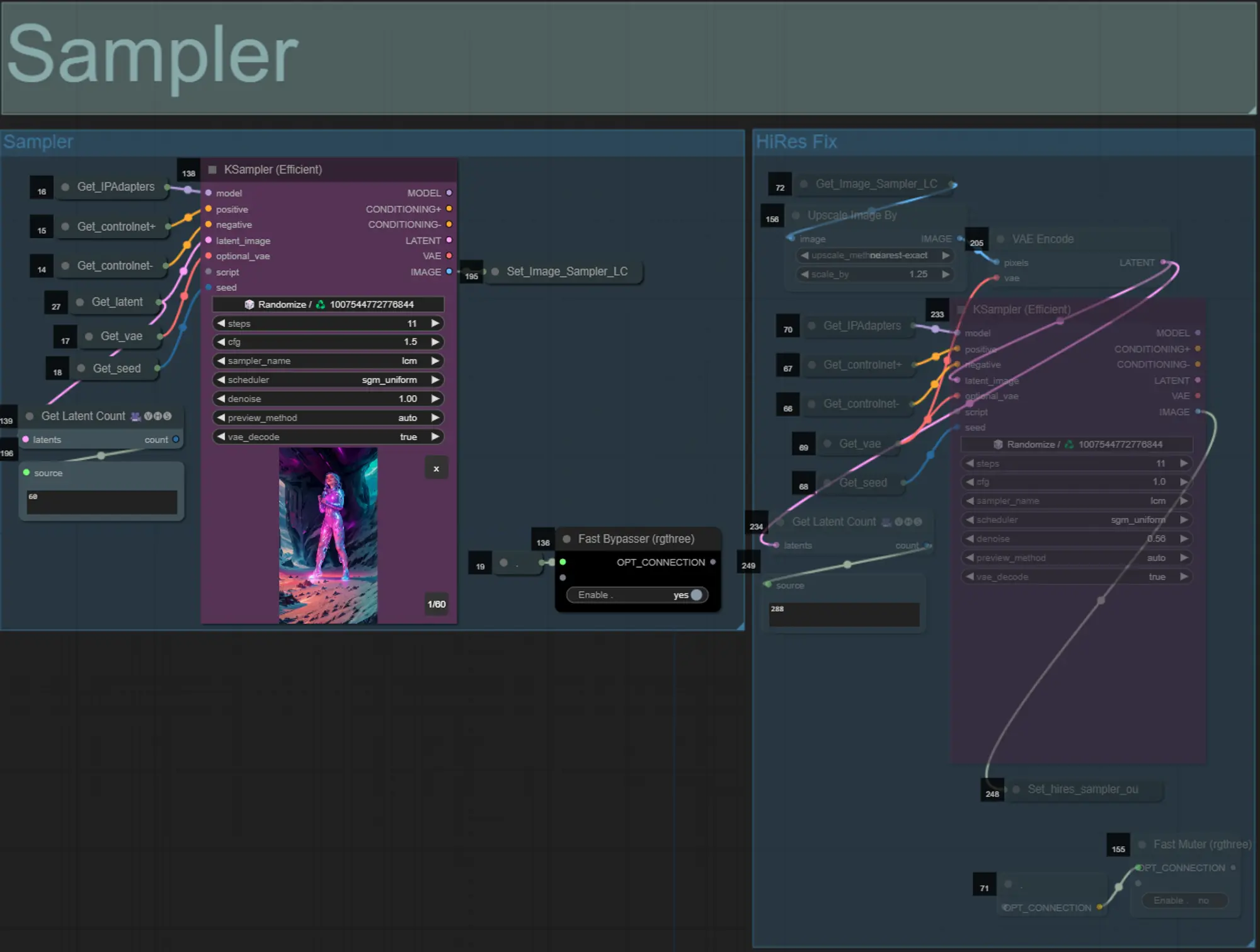
- テスト時には処理時間を節約するために、デフォルトでHiRes Fixサンプラーグループはミュートされます
- 拡張マスク設定を試してみるときには、時間を節約するためにサンプラーグループもバイパスすることをお勧めします。
- 最終レンダリングでは、HiRes Fixグループをミュート解除して、最終結果をアップスケールし、詳細を追加することができます。
出力

- 出力グループは2つあり、左側は標準サンプラー出力用、右側はHiRes Fixサンプラー出力用です。
- "FileNamePrefixDateDirFirst"ノードの"custom_directory"文字列を変更して、ファイルの保存場所を変更できます。デフォルトでは、このノードはComfyUIの"output"ディレクトリ内のタイムスタンプディレクトリに出力ビデオを保存します
- 例: …/ComfyUI/output/240812/
<custom_directory>/<my_video>.mp4
- 例: …/ComfyUI/output/240812/
著者について
Akatz AI:
- ウェブサイト:
- https://www.youtube.com/@akatz_ai
- https://www.instagram.com/akatz.ai/
- https://www.tiktok.com/@akatz_ai
- https://x.com/akatz_ai
- https://github.com/akatz-ai
連絡先:
- Email: akatzfey@sendysoftware.com


