Omost | 画像作成を強化
OmostはLarge Language Modelsを活用して、コーディングを詳細な画像構成に変換します。構造化されたキャンバスと高度なプロンプトエンジニアリングを使用することで、Omostは正確で効率的な画像生成を実現しますComfyUI Omost ワークフロー
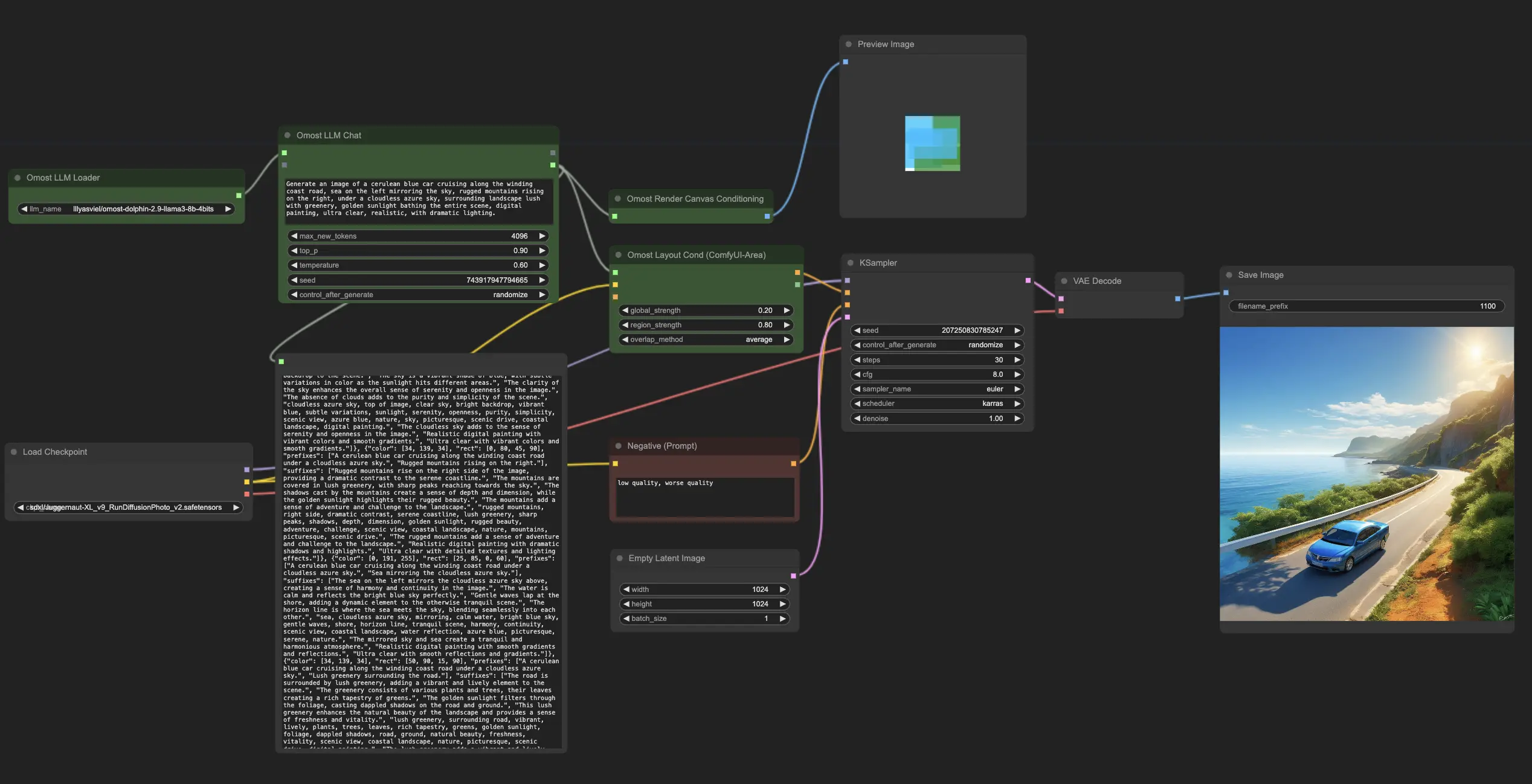
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI Omost 例

ComfyUI Omost 説明
1. Omostとは?
Omostは"Your image is almost there!"の略で、Large Language Models(LLM)のコーディング能力を画像生成、より正確には画像構成能力に変換する革新的なプロジェクトです。"Omost"という名前には二重の意味があります:Omostを使用するたびに画像がほぼ完成していることを示し、また"omni"(多モーダル)と"most"(最大限に活用する)を意味します。
Omostは、Omostの仮想キャンバスエージェントを使用して画像の視覚コンテンツを構成するコードを生成する事前訓練されたLLMモデルを提供します。このキャンバスは、画像生成器の特定の実装によってレンダリングされ、最終的な画像が作成されます。Omostは、AIアーティストにとって画像生成プロセスを簡素化し、効率化するよう設計されています。
2. Omostの仕組み
2.1. キャンバスと説明
Omostは画像の要素が記述され、配置される仮想キャンバスを使用します。キャンバスは9x9=81の位置に分割され、要素の正確な配置を可能にします。これらの位置はさらにバウンディングボックスに細分化され、それぞれの要素に729の異なる位置を提供します。この構造化されたアプローチにより、要素が正確かつ一貫して配置されます。
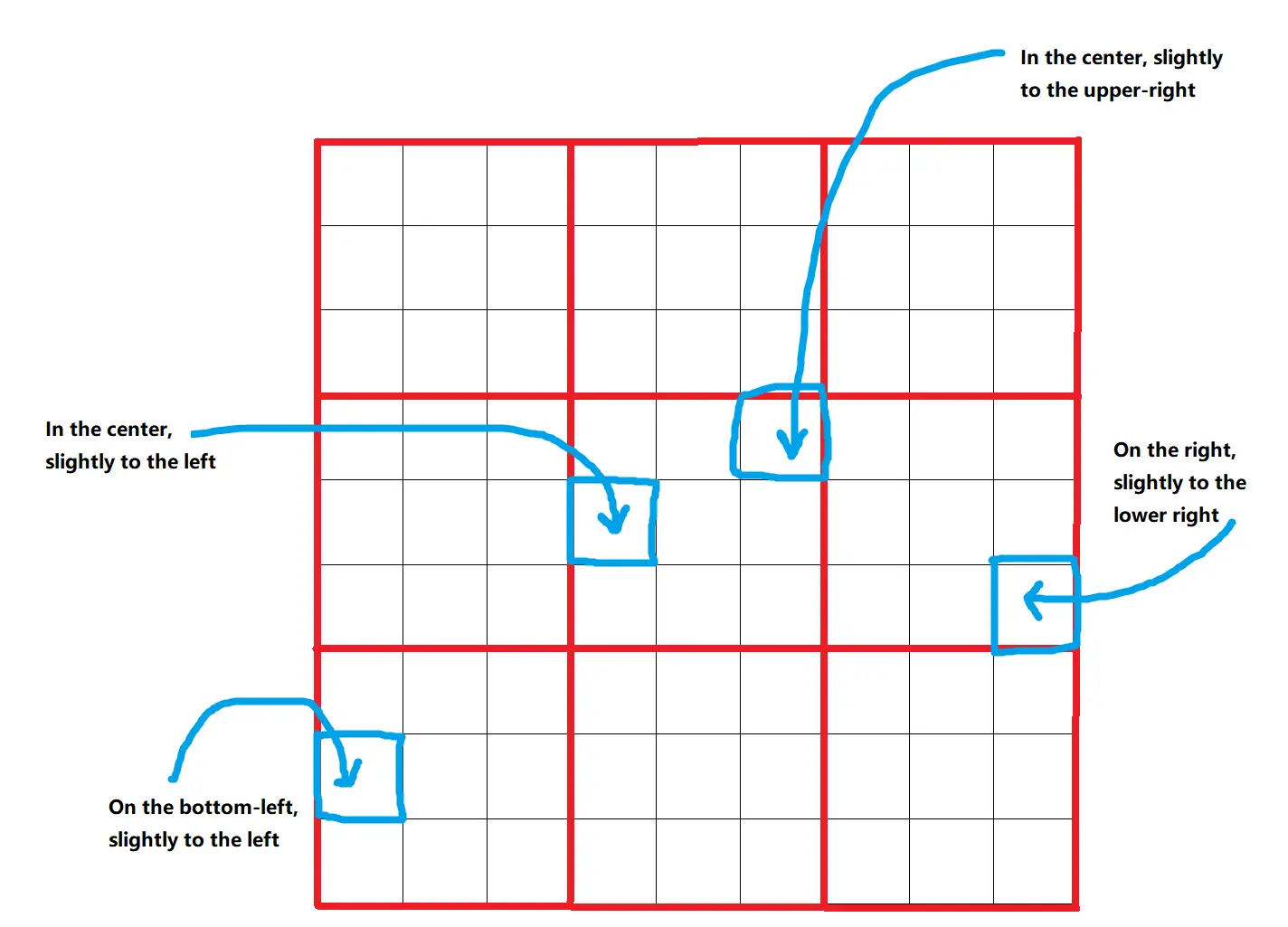
2.2. 深度と色
キャンバス上の要素にはdistance_to_viewerパラメータが割り当てられ、これにより背景から前景へのレイヤーにソートされます。このパラメータは相対的な深度指標として機能し、近い要素が遠い要素の前に表示されることを保証します。さらに、HTML_web_color_nameパラメータは初期レンダリングのための粗い色表現を提供し、拡散モデルを使用して洗練されることができます。この初期の色は、微調整前の構成を視覚化するのに役立ちます。

2.3. プロンプトエンジニアリング
Omostは要素の詳細で一貫した画像構成を生成するために、短く独立した説明であるサブプロンプトを使用します。各サブプロンプトは75トークン未満であり、要素を独立して説明します。これらのサブプロンプトはLLMが処理する完全なプロンプトに統合され、生成された画像が正確で意味的に豊かであることを保証します。この方法により、テキストエンコードが効率的であり、意味の切り捨てエラーを回避します。
2.4. リージョナルプロンプター
Omostはリージョナルプロンプトを処理するために高度な注意操作技術を実装し、各部分の画像が与えられた説明に基づいて正確に生成されることを保証します。注意スコアの操作などの技術により、マスクされた領域内の活性化が促進され、外部のものが抑制されます。この正確な注意制御により、高品質でリージョン固有の画像生成が実現します。
3. ComfyUI Omostノードの詳細説明
3.1. Omost LLMローダーノード
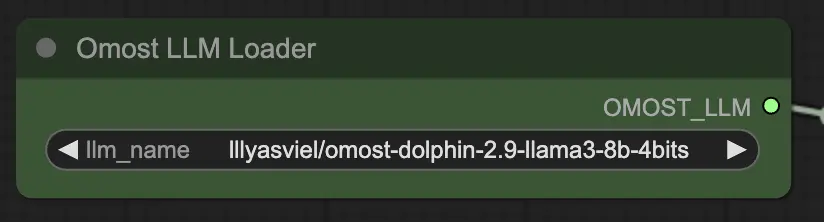
Omost LLMローダーノードの入力パラメータ
llm_name: ロードする事前訓練済みLLMモデルの名前。利用可能なオプションには以下が含まれます:lllyasviel/omost-phi-3-mini-128k-8bitslllyasviel/omost-llama-3-8b-4bitslllyasviel/omost-dolphin-2.9-llama3-8b-4bits
このパラメータは、ロードするモデルを指定し、それぞれが異なる機能と最適化を提供します。
Omost LLMローダーノードの出力パラメータ
OMOST_LLM: ロードされたLLMモデル。
この出力は、画像の説明と構成を生成する準備が整ったLLMを提供します。
3.2. Omost LLMチャットノード
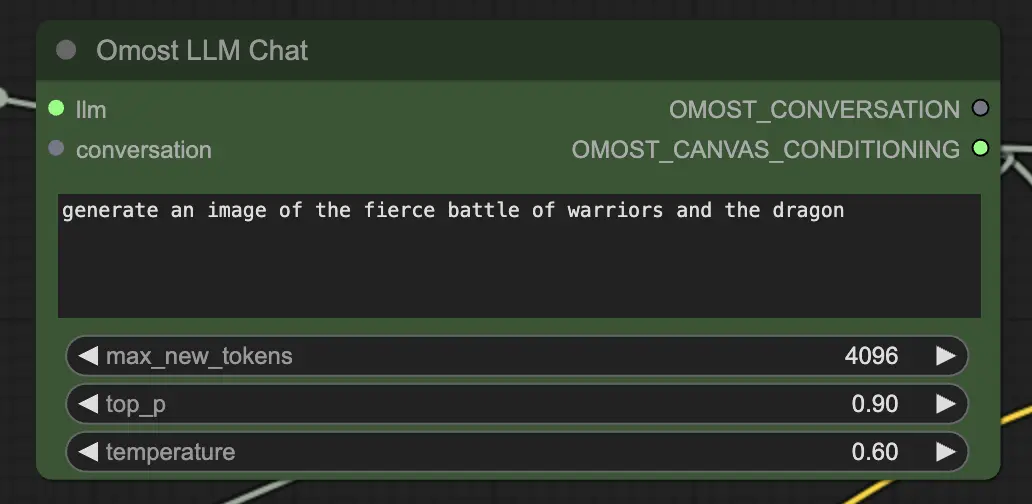
Omost LLMチャットノードの入力パラメータ
llm:OmostLLMLoaderによってロードされたLLMモデル。text: 画像を生成するためのテキストプロンプト。これは、生成したいシーンや要素を説明する主要な入力です。max_new_tokens: 生成する新しいトークンの最大数。これにより生成されるテキストの長さが制御され、詳細な説明が可能になります。top_p: 生成された出力の多様性を制御します。1.0に近い値は多様な可能性を含み、低い値は最も可能性の高い結果に焦点を当てます。temperature: 生成された出力のランダム性を制御します。高い値はよりランダムな出力を生み出し、低い値は出力をより決定論的にします。conversation(オプション): 以前の会話のコンテキスト。これにより、モデルが以前のやり取りから続けて、コンテキストと一貫性を維持することができます。
Omost LLMチャットノードの出力パラメータ
OMOST_CONVERSATION: 新しい応答を含む会話履歴。これにより、対話を追跡し、複数のやり取りにわたってコンテキストを維持できます。OMOST_CANVAS_CONDITIONING: レンダリングのための生成されたキャンバス調整パラメータ。これらのパラメータは、キャンバス上の要素の配置と説明を定義します。
3.3. Omostキャンバス調整レンダーノード
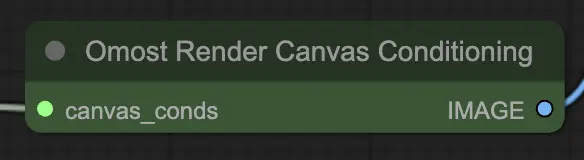
Omostキャンバス調整レンダーノードの入力パラメータ
canvas_conds: キャンバス調整パラメータ。これらのパラメータには、キャンバス上の要素の詳細な説明と位置が含まれます。
Omostキャンバス調整レンダーノードの出力パラメータ
IMAGE: キャンバス調整に基づいてレンダリングされた画像。この出力は、調整パラメータから生成されたシーンの視覚的表現です。
3.4. OmostレイアウトCondノード
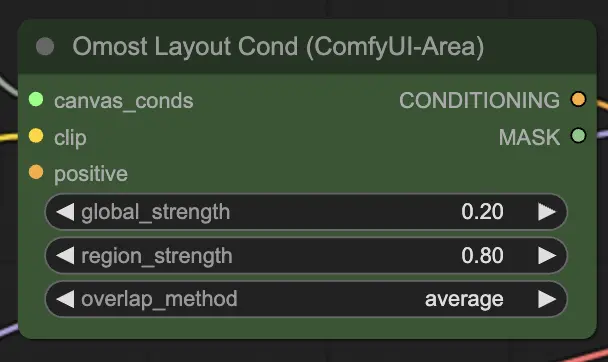
OmostレイアウトCondノードの入力パラメータ
canvas_conds: キャンバス調整パラメータ。clip: テキストエンコードのためのCLIPモデル。このモデルはテキストの説明を画像生成器が使用できるベクトルにエンコードします。global_strength: グローバル調整の強度。これにより、全体的な説明が画像にどれほど強く影響するかが制御されます。region_strength: リージョナル調整の強度。これにより、特定のリージョンの説明がそれぞれの領域にどれほど強く影響するかが制御されます。overlap_method: 重なり合う領域を処理する方法(例:overlay、average)。これにより、画像内の重なり合う領域をどのようにブレンドするかが定義されます。positive(オプション): 追加のポジティブ調整。これには、画像の特定の側面を強化するための追加のプロンプトや条件が含まれます。
OmostレイアウトCondノードの出力パラメータ
CONDITIONING: 画像生成のための調整パラメータ。これらのパラメータは、出力が説明されたシーンに一致するように画像生成プロセスをガイドします。MASK: 調整に使用されるマスク。これにより、特定の領域に追加の条件を適用したり、デバッグしたりするのに役立ちます。
3.5. Omostキャンバス調整ロードノード
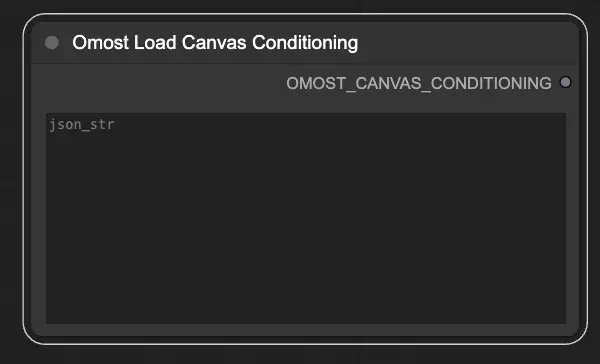
Omostキャンバス調整ロードノードの入力パラメータ
json_str: キャンバス調整パラメータを表すJSON文字列。これにより、JSONファイルから事前定義された条件をロードできます。
Omostキャンバス調整ロードノードの出力パラメータ
OMOST_CANVAS_CONDITIONING: ロードされたキャンバス調整パラメータ。これらのパラメータは、特定の条件でキャンバスを初期化し、画像生成の準備を整えます。


