
ComfyUI Vid2Vid ワークフローは、**YVANN**によって作成され、高品質でプロフェッショナルなアニメーションを実現するために2つの異なるワークフローを紹介します。
- 最初のComfyUIワークフロー: ComfyUI Vid2Vid パート1 | 構成とマスキング
- 二つ目のワークフロー: ComfyUI Vid2Vid パート2 | SDXL Style Transfer
ComfyUI Vid2Vid パート1 | 構成とマスキング
このワークフローは、元のビデオの構成とマスキングに焦点を当てることで創造性を高めます。
ステップ1: モデルローダー | ComfyUI Vid2Vid ワークフロー パート1
アニメーションに適したモデルを選択します。これには、チェックポイントモデル、VAE (Variational Autoencoder) モデル、およびLoRA (Low-Rank Adaptation) モデルの選択が含まれます。これらのモデルは、アニメーションの能力とスタイルを定義するために重要です。
ステップ2: ビデオローダー | ComfyUI Vid2Vid ワークフロー パート1
Input Video ノードは、アニメーションに使用されるビデオファイルをインポートする役割を担います。このノードはビデオを読み取り、個々のフレームに変換し、その後のステップで処理されます。これにより、フレームごとの詳細な編集と強化が可能になります。
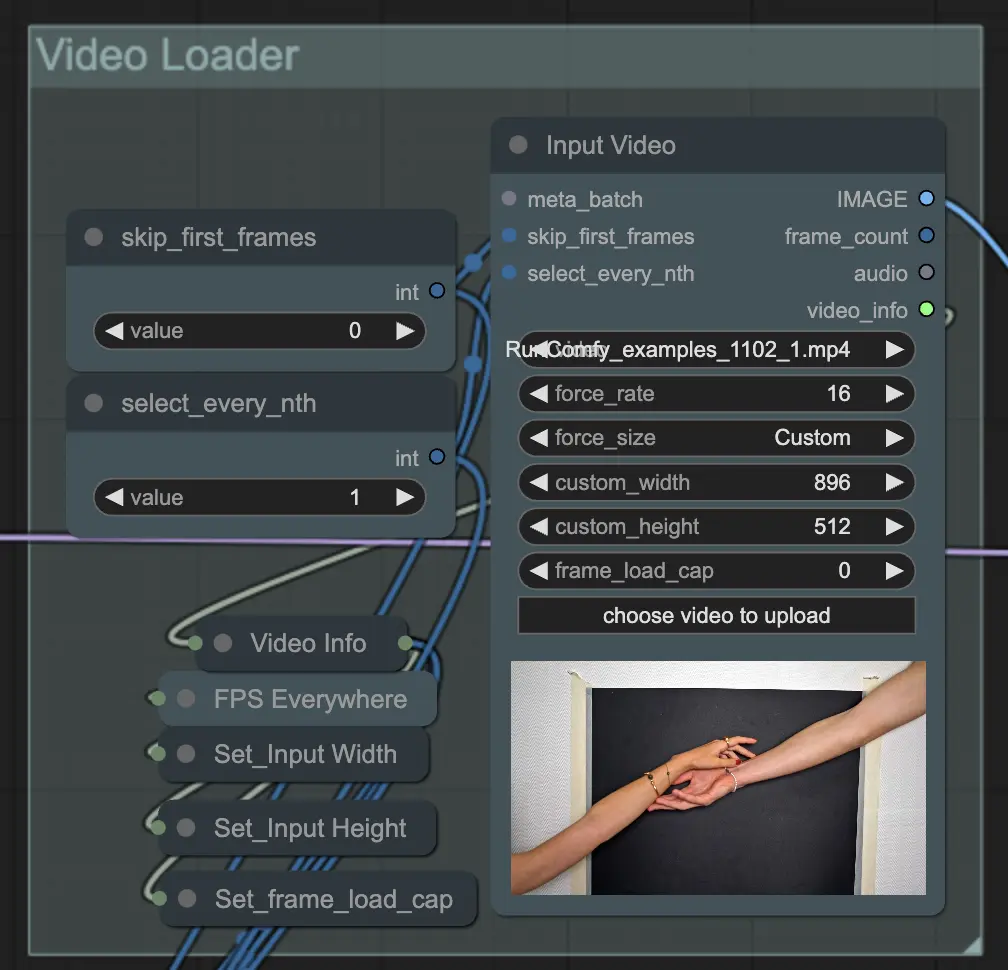
ステップ3: 背景を削除 (自動マスキング) | ComfyUI Vid2Vid ワークフロー パート1
背景を削除 (自動マスキング) は、自動マスキング技術を使用して背景から被写体を分離します。これには、前景の被写体を背景から検出して分離するモデルが含まれ、バイナリマスクを作成します。このステップは、被写体を背景とは独立して操作できるようにするために重要です。
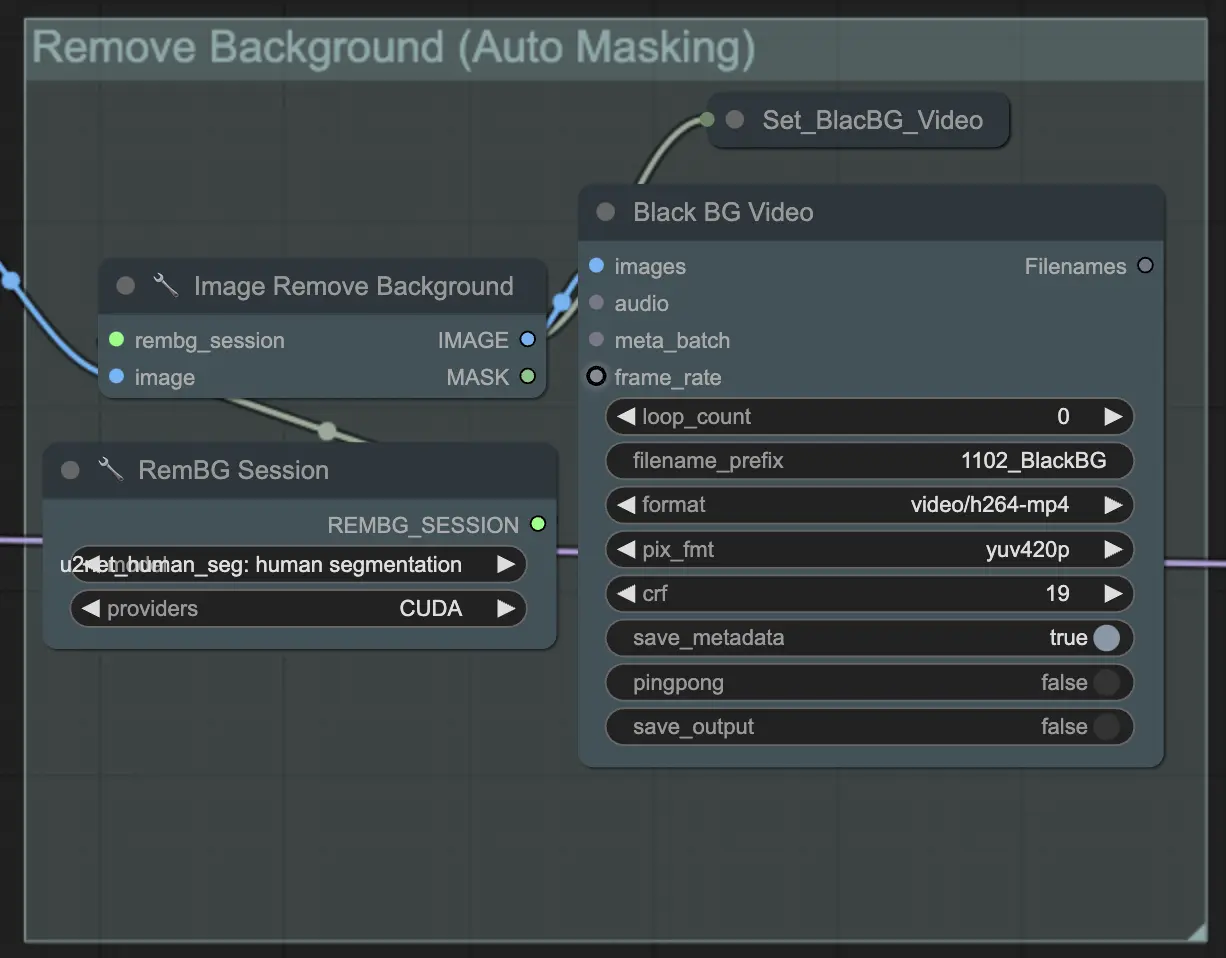
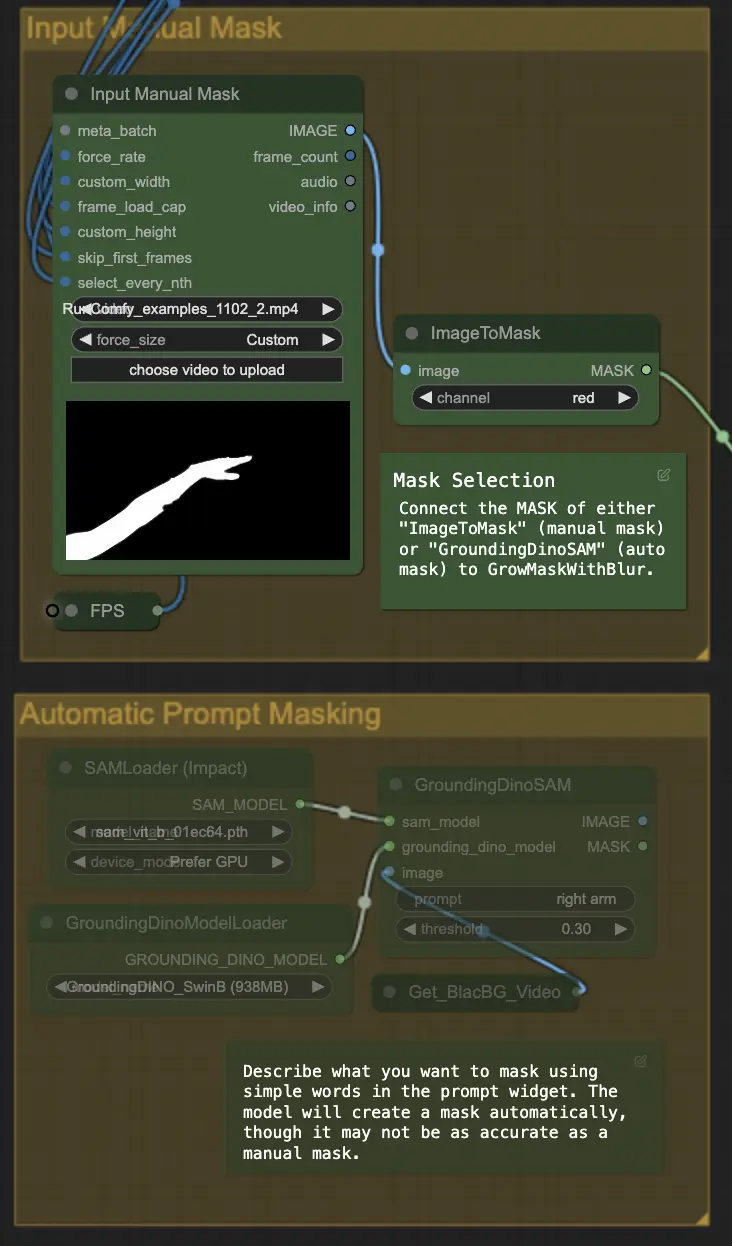
ステップ4: 特定のエリアをマスキング (手動マスクまたは自動マスク) | ComfyUI Vid2Vid ワークフロー パート1
このステップでは、前のステップで作成されたマスクの精度を高めることができます。別のソフトウェアを使用して手動で特定のエリアをマスクするか、ComfyUIの 'Segment Anything' 自動マスク機能を利用することができます。
- 手動マスク: これは、正確な制御のためにComfyUI以外の他のソフトウェアで処理する必要があります。
- 自動マスク: 自動マスク機能を使用すると、プロンプトウィジェットで単純な言葉を使用してマスクしたい部分を記述できます。モデルは自動的にマスクを作成しますが、手動マスクほど正確ではない場合があります。
デフォルトでは手動マスクを使用します。自動マスクを試したい場合は、手動マスクグループをバイパスして自動マスクグループを有効にしてください。さらに、'GroundingDinoSAM' (自動マスク) のMASKを 'GrowMaskWithBlur' に接続し、'ImageToMask' (手動マスク) を 'GrowMaskWithBlur' に接続しないでください。
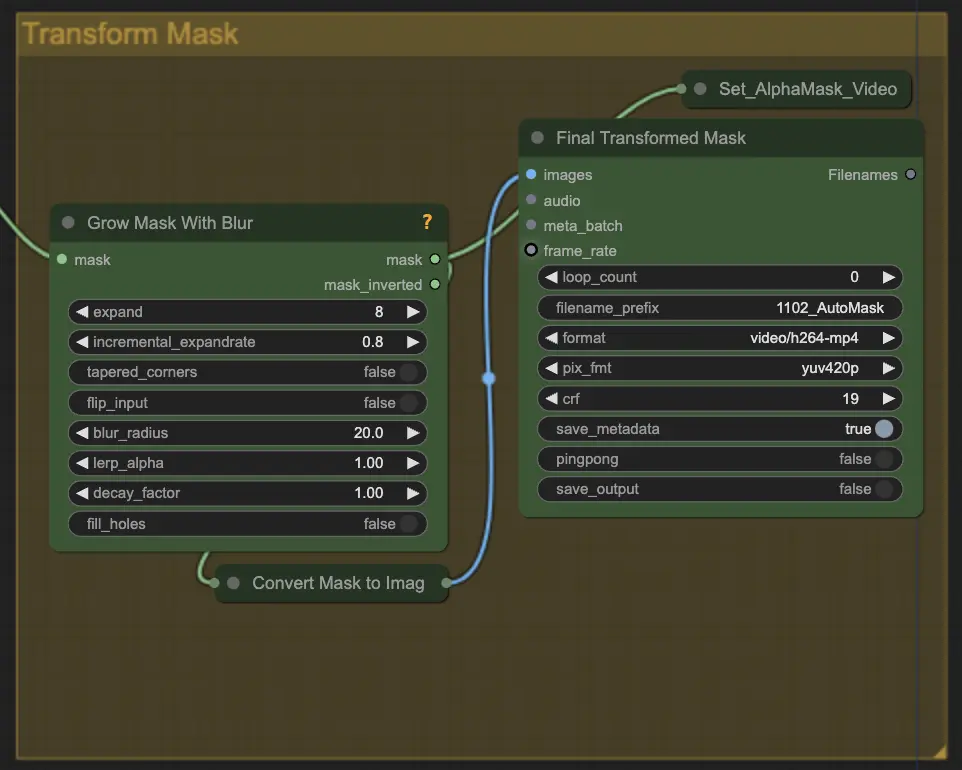
ステップ5: マスクを変換 | ComfyUI Vid2Vid ワークフロー パート1
マスクを変換 は、マスクを画像に変換し、元のマスクにぼかしを追加するなどの追加調整を可能にします。これにより、エッジを柔らかくし、マスクが画像の他の部分と自然にブレンドされるようになります。
ステップ6: 入力プロンプト | ComfyUI Vid2Vid ワークフロー パート1
アニメーションプロセスをガイドするためのテキストプロンプトを入力します。プロンプトは、被写体の望ましいスタイル、外観、または動作を記述できます。これはアニメーションの創造的な方向性を定義するために重要であり、最終的な出力が想像された芸術的スタイルに一致することを保証します。
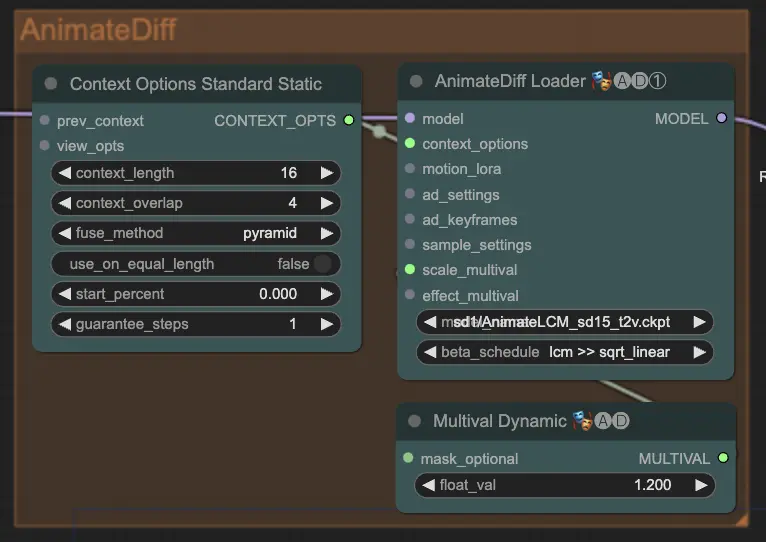
ステップ7: AnimateDiff | ComfyUI Vid2Vid ワークフロー パート1
AnimateDiff ノードは、連続するフレーム間の違いを識別し、これらの変更を段階的に適用することでスムーズなアニメーションを作成します。これにより、動きの一貫性を保ち、アニメーションの急激な変化を減少させ、より流動的で自然な外観を実現します。
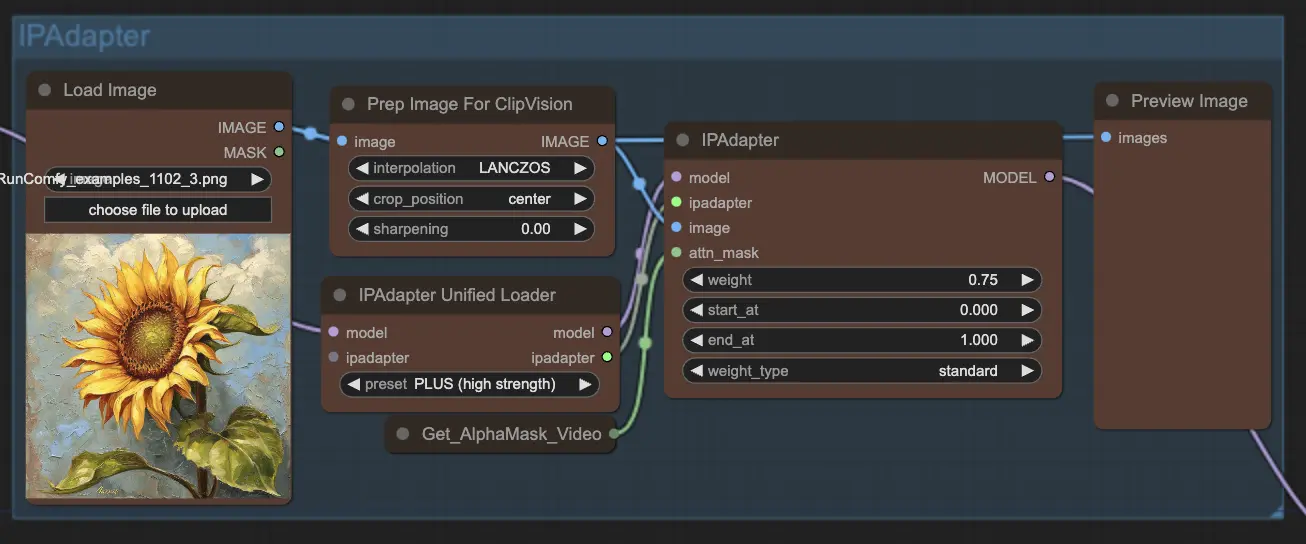
ステップ8: IPAdapter | ComfyUI Vid2Vid ワークフロー パート1
IPAdapter ノードは、入力画像を希望する出力スタイルや特徴に合わせて調整します。これには、カラー化やスタイル転送などのタスクが含まれ、アニメーションの各フレームが一貫した外観と感触を維持することを保証します。
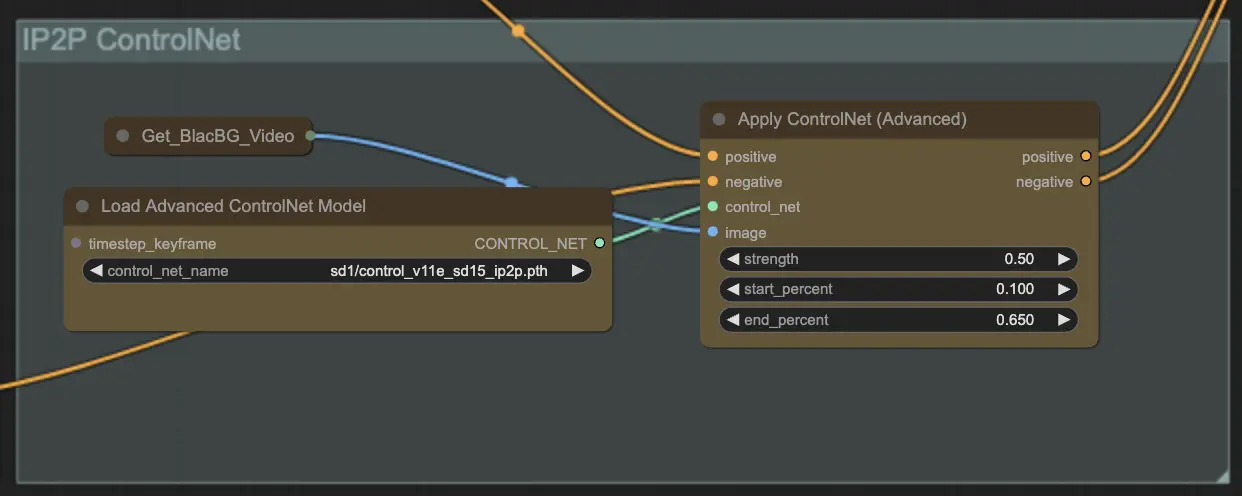
ステップ9: ControlNet | ComfyUI Vid2Vid ワークフロー パート1
ControlNet - v1.1 - Instruct Pix2Pix Version model を使用すると、追加の入力条件 (エッジマップ、セグメンテーションマップなど) を処理することにより、拡散モデルを強化します。これにより、これらの事前訓練されたモデルをタスク固有の条件で制御し、少ないデータセットでも強力な学習が可能になります。
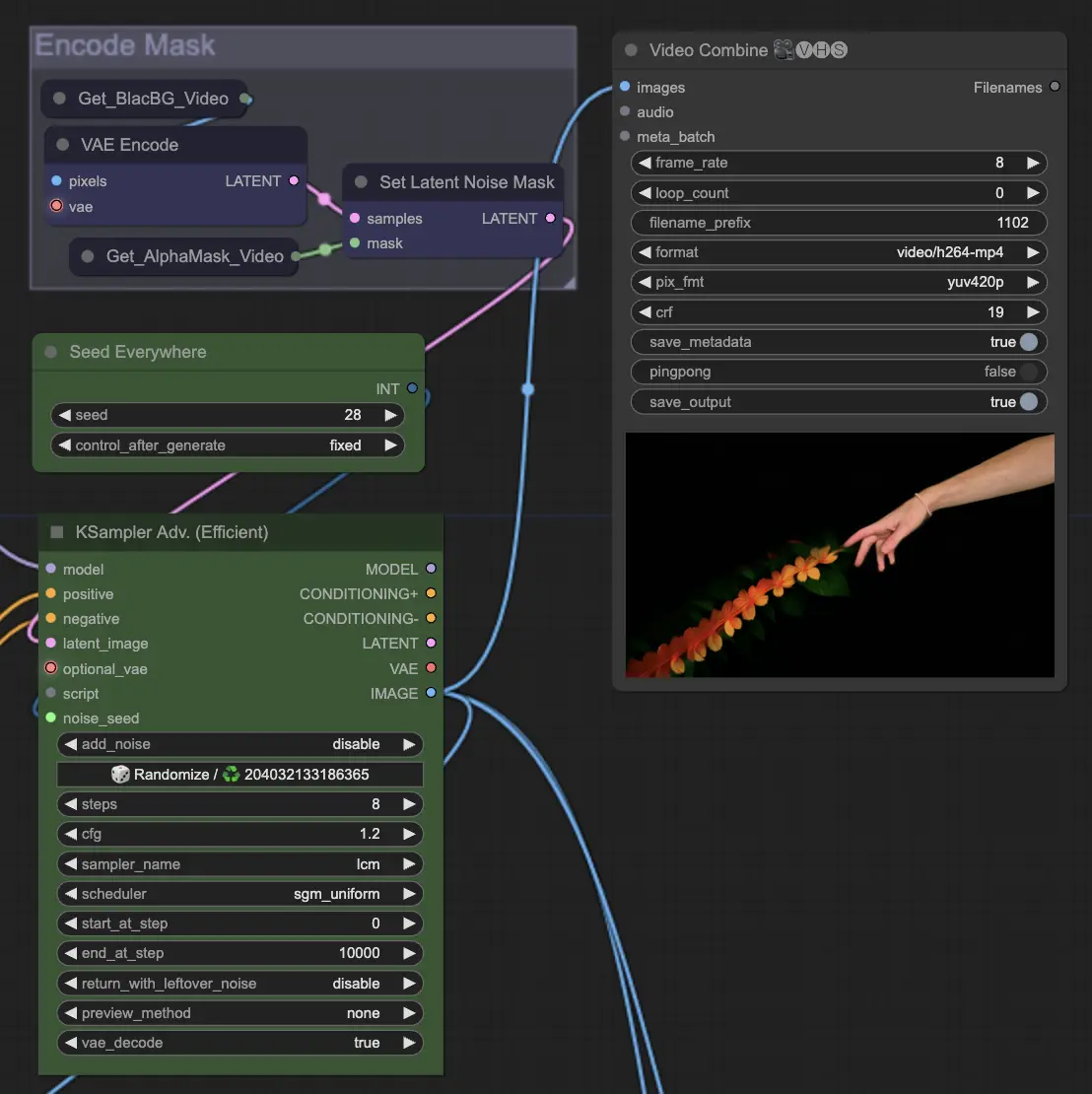
ステップ10: レンダリング | ComfyUI Vid2Vid ワークフロー パート1
レンダリング ステップでは、処理されたフレームが最終的なビデオ出力にコンパイルされます。このステップは、個々のフレームがシームレスに結合され、一貫したアニメーションとしてエクスポートされ、さらに使用される準備が整います。
ステップ11: 背景を合成 | ComfyUI Vid2Vid ワークフロー パート1
これは、アニメーション化された被写体と背景を合成することを含みます。静的または動的な背景をアニメーションに追加し、被写体が新しい背景とスムーズに統合され、視覚的に魅力的な最終製品を作成します。
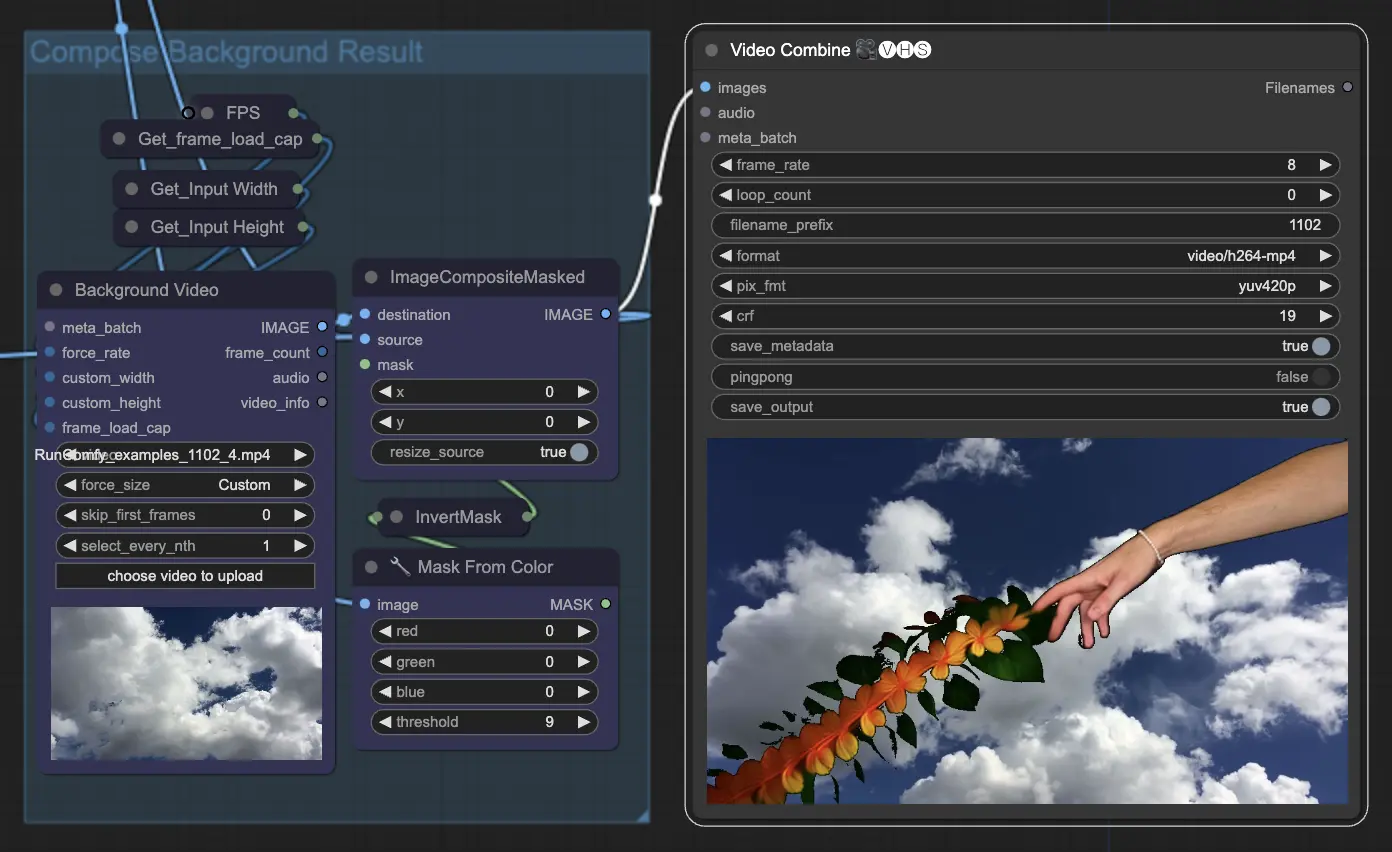
ComfyUI Vid2Vid ワークフロー パート1を利用することで、構成とマスキングから最終レンダリングまで、プロセスのすべての側面を正確に制御して複雑なアニメーションを作成できます。