LayerDiffuse | テキストから透明な画像へ
LayerDiffuseモデルは、透明な画像を直接作成できるようにする斬新な画像操作手法を導入しています。このComfyUI LayerDiffuseワークフローでは、透明な画像の作成、前景からの背景生成、既存の背景に基づく前景の作成という3つの特殊なサブワークフローが統合されています。ComfyUI LayerDiffuse ワークフロー

- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI LayerDiffuse 例

ComfyUI LayerDiffuse 説明
1. ComfyUI LayerDiffuseワークフローの概要
ComfyUI LayerDiffuseワークフローは、透明な画像の作成、前景からの背景生成、既存の背景に基づく前景の生成という3つの特殊なサブワークフローを統合しています。これらのLayerDiffuseサブワークフローはそれぞれ独立して機能し、創造的なニーズに合った特定のLayerDiffuse機能を選択して有効にする柔軟性を提供します。
1.1. LayerDiffuseを使用した透明な画像の作成:
このワークフローでは、透明な画像を直接作成できます。アルファチャネルマスクを指定するかどうかにかかわらず、画像を生成する柔軟性があります。
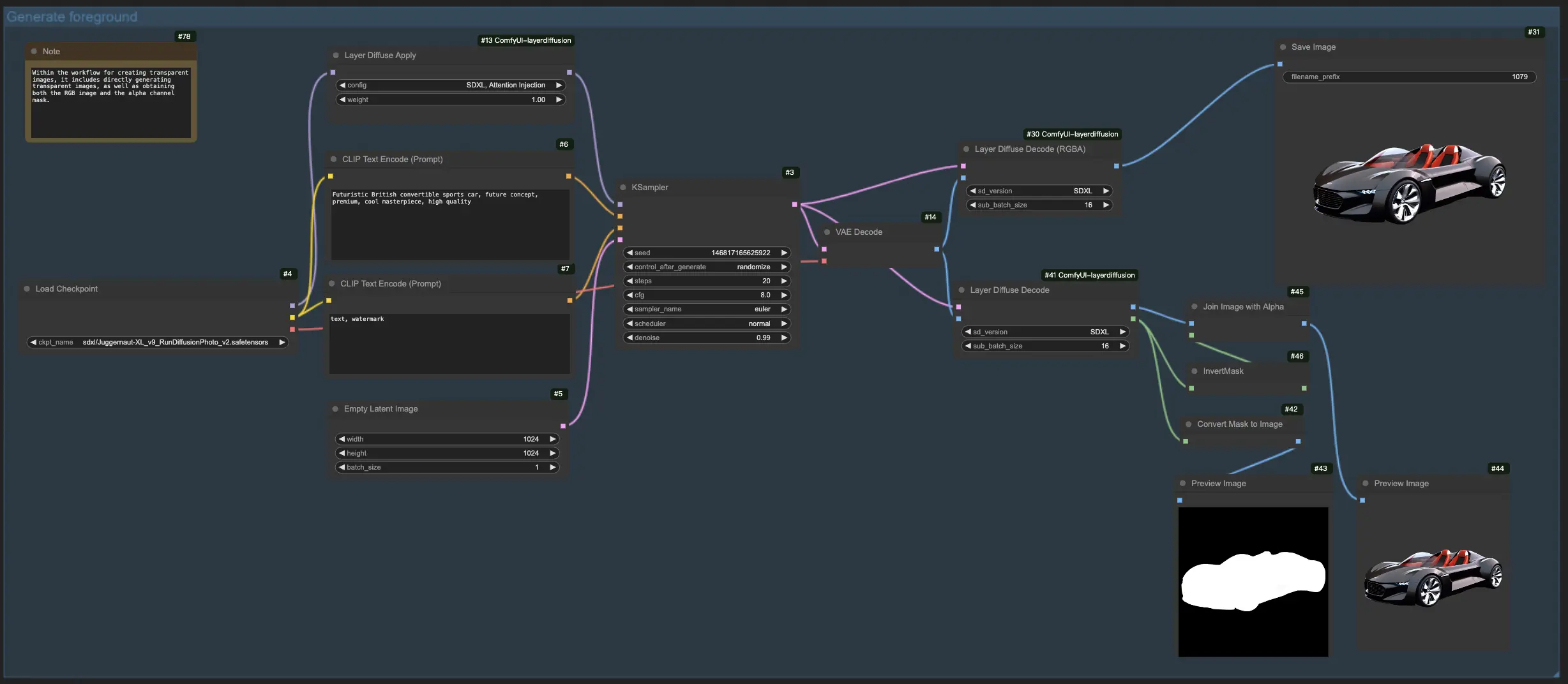
1.2. LayerDiffuseを使用した前景からの背景生成:
このLayerDiffuseワークフローでは、まず前景画像をアップロードし、説明的なプロンプトを作成します。次に、LayerDiffuseがこれらの要素をブレンドして、目的の画像を生成します。LayerDiffuse用のプロンプトを作成する際は、背景要素のみ(例:"the street")を説明するのではなく、シーン全体(例:"a car parked on the side of the street")を詳しく説明することが重要です。
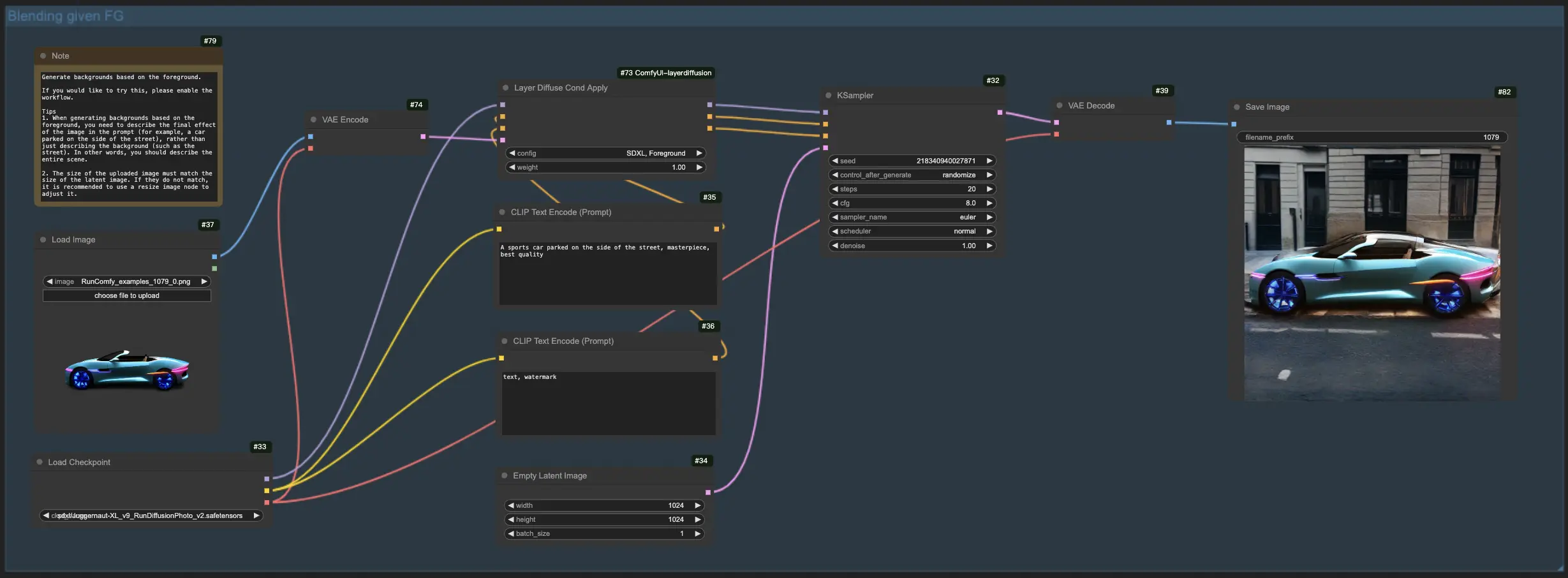
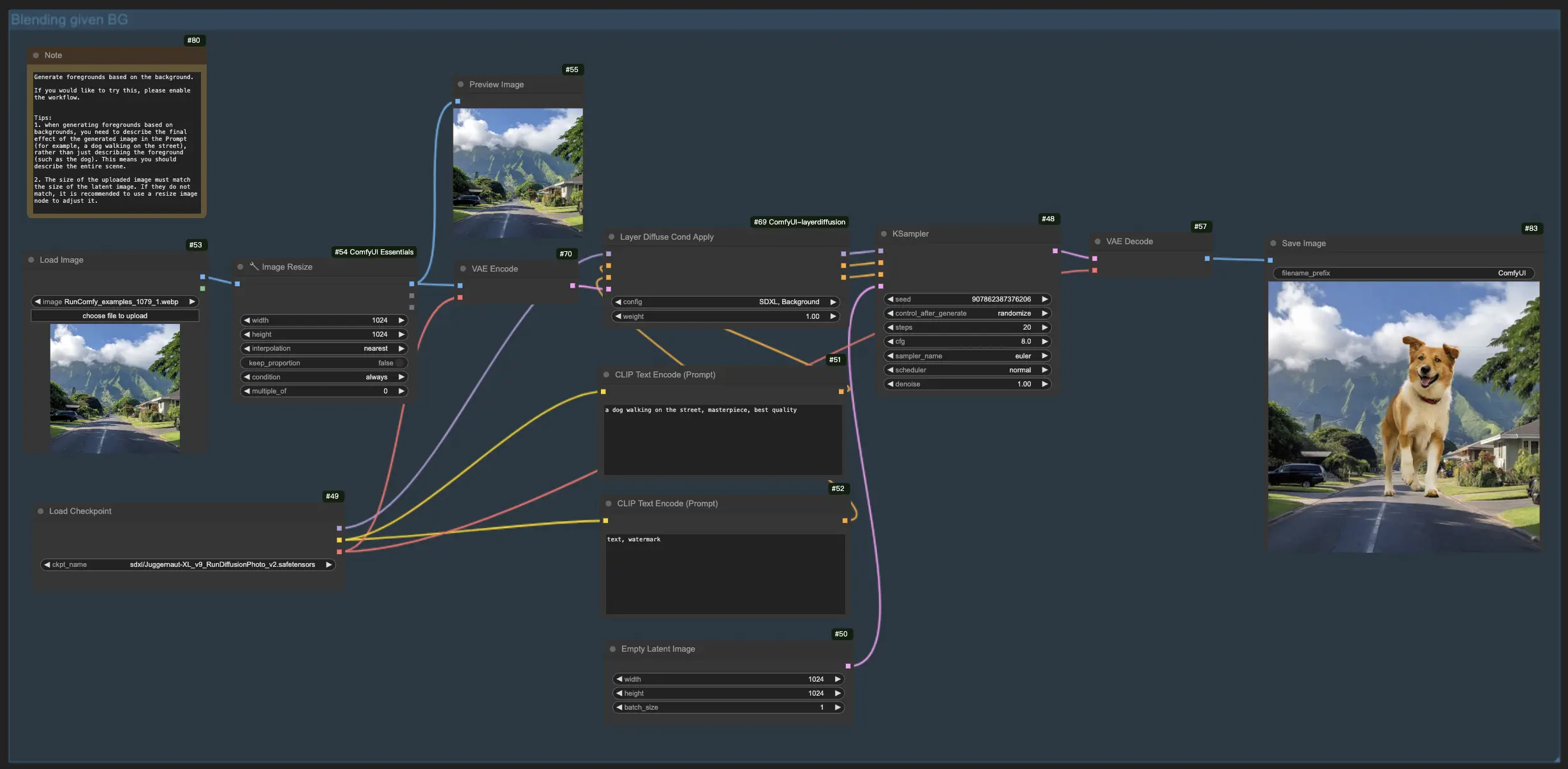
1.3. 背景に基づく前景の生成:
前のワークフローと同様に、このLayerDiffuse機能は焦点を反転させ、既存の背景に前景要素を統合することを目的としています。したがって、背景画像をアップロードし、個々の要素(例:"the dog")ではなく、想像する最終画像全体(例:"a dog walking on the street")をプロンプトで強調する必要があります。
その他のLayerDiffuseワークフローについては、でご確認ください。
2. LayerDiffuseワークフローの有効性
透明な画像を作成するプロセスは堅牢で、信頼性の高い高品質の結果を生み出しますが、背景と前景をブレンドするためのワークフローはより実験的です。この技術の革新的だが発展途上の性質を示すように、完璧なブレンドを実現できない場合があります。
3. LayerDiffuseの技術的紹介
LayerDiffuseは、大規模な事前学習済みの潜在拡散モデルが透明性を持つ画像を生成できるようにすることを目的とした革新的なアプローチです。この手法では、アルファチャネルの透明性を既存のモデルの潜在マニフォールドに直接エンコードする「潜在透明性」の概念を導入しています。これにより、事前学習済みモデルの元の潜在分布を大幅に変更することなく、透明な画像や複数の透明なレイヤーを作成できます。目標は、これらのモデルの高品質な出力を維持しながら、透明性を持つ画像を生成する機能を追加することです。
これを実現するために、LayerDiffuseは事前学習済みの潜在拡散モデルを微調整し、透明性を潜在オフセットとして含めるようにモデルの潜在空間を調整します。このプロセスでは、モデルへの変更を最小限に抑え、元の特性とパフォーマンスを維持します。LayerDiffuseの学習では、人間を介したスキームを通じて収集された100万枚の透明画像レイヤーのペアのデータセットを使用し、さまざまな透明効果を確保しています。
この手法は、さまざまなオープンソースの画像生成器に適応可能であり、異なる条件制御システムに統合できることが示されています。この汎用性により、前景/背景固有の透明性を持つ画像の生成、共同生成機能を持つレイヤーの作成、レイヤーの構造コンテンツの制御など、さまざまなアプリケーションが可能になります。






