EchoMimic | オーディオ駆動のポートレートアニメーション
EchoMimicは、提供されたオーディオとシームレスに同期するリアルなトーキングヘッドとボディジェスチャーを作成できるツールです。高度なAI技術を活用して、EchoMimicはオーディオ入力を分析し、話された言葉と感情に完璧に一致するリアルな表情、リップムーブメント、ボディランゲージを生成します。EchoMimicを使用すると、キャラクターを生き生きとさせ、観客を魅了するアニメーションコンテンツを作成できます。ComfyUI EchoMimic ワークフロー
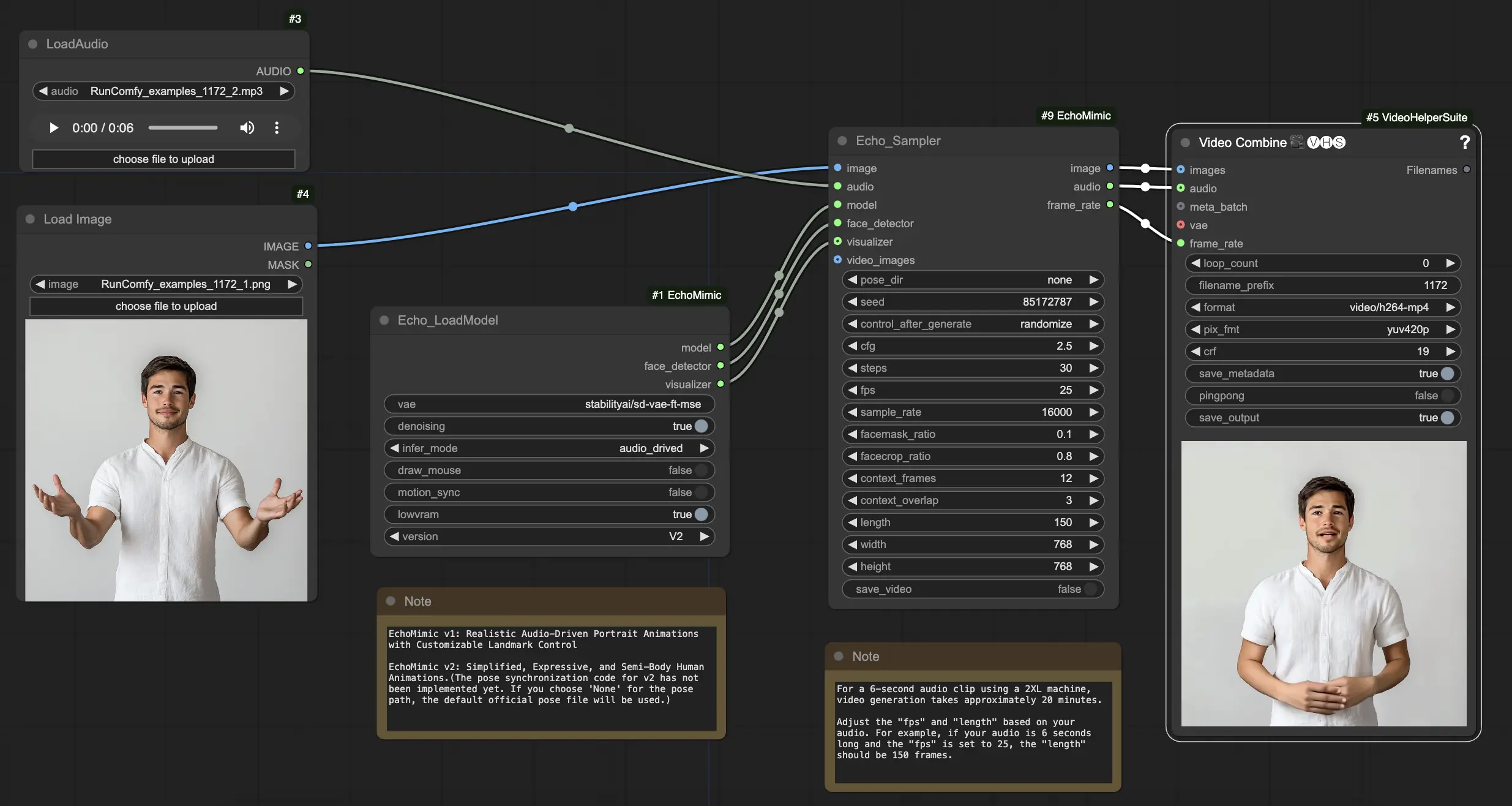
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI EchoMimic 例
ComfyUI EchoMimic 説明
EchoMimicは、リアルなオーディオ駆動のポートレートアニメーションを生成するためのツールです。入力オーディオを分析し、音声の感情や音声内容に密接に一致する表情、リップムーブメント、頭のジェスチャーを生成するためにディープラーニング技術を利用しています。
EchoMimic V2は、Alipay, Ant Groupのターミナルテクノロジー部門の研究者チーム、Rang Meng、Xingyu Zhang、Yuming Li、Chenguang Maによって開発されました。詳細情報については、/をご覧ください。ComfyUI_EchoMimicノードは/によって開発されました。すべてのクレジットは彼らの重要な貢献に帰属します。
EchoMimic V1とV2
- EchoMimic V1: カスタマイズ可能なランドマークコントロールを備えたリアルなオーディオ駆動のポートレートアニメーション
- EchoMimic V2: 簡略化され、表現力があり、半身の人間アニメーション
主な違いは、EchoMimic V2がEchoMimic V1に比べて不要なコントロール条件を簡素化しながら、印象的な半身の人間アニメーションを実現することを目指している点です。EchoMimic V2は、顔の表情と身体のジェスチャーを強化するために新しいAudio-Pose Dynamic Harmonization戦略を使用しています。
EchoMimic V2の長所と短所
長所:
- EchoMimic V2は、オーディオによって駆動される非常にリアルで表現力豊かなポートレートアニメーションを生成します
- EchoMimic V2は、アニメーションを頭部だけでなく上半身にも拡張します
- EchoMimic V2は、EchoMimic V1と比較して条件の複雑さを減少させながら、アニメーションの質を維持します
- EchoMimic V2は、顔の表情を強化するためにヘッドショットデータをシームレスに組み込みます
短所:
- EchoMimic V2は、最良の結果を得るためにポートレートに一致するオーディオソースを必要とします
- EchoMimic V2は現在、ポーズ同期コードが欠如しており、デフォルトのポーズファイルを使用しています
- EchoMimic V2で高品質なアニメーションを長時間生成することは計算負荷が高い場合があります
- EchoMimic V2は、全身ショットよりもクロップされたポートレート画像で最適に動作します
ComfyUI EchoMimicワークフローの使用方法
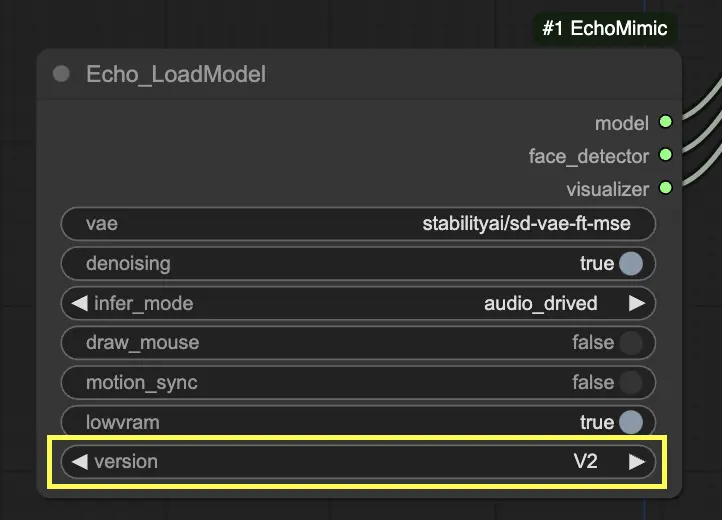
"Echo_LoadModel"ノードでは、EchoMimic v1とEchoMimic v2の選択肢があります:
- EchoMimic v1: このバージョンは、ランドマークコントロールをカスタマイズする能力を備えたリアルなオーディオ駆動のポートレートアニメーションの生成に焦点を当てています。入力オーディオに密接に一致するリアルな顔のアニメーションを作成するのに適しています。
- EchoMimic v2: このバージョンは、アニメーションプロセスを簡素化しつつ、表現力豊かで半身の人間アニメーションを提供することを目的としています。顔の領域だけでなく上半身の動きにもアニメーションを拡張します。ただし、v2のポーズ同期機能は現在のComfyUIワークフローのバージョンには実装されていないことに注意してください。ポーズパスに「None」を選択すると、代わりにデフォルトの公式ポーズファイルが使用されます。
以下は、提供されたComfyUIワークフローの使用方法のステップバイステップガイドです:
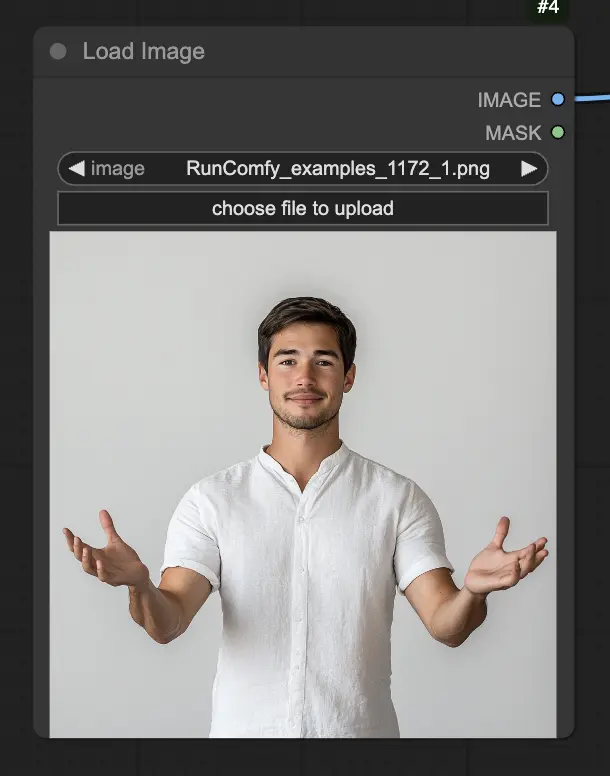
ステップ 1. LoadImageノードを使用してポートレート画像をロードします。これは被写体の頭部と肩のクローズアップショットであるべきです。
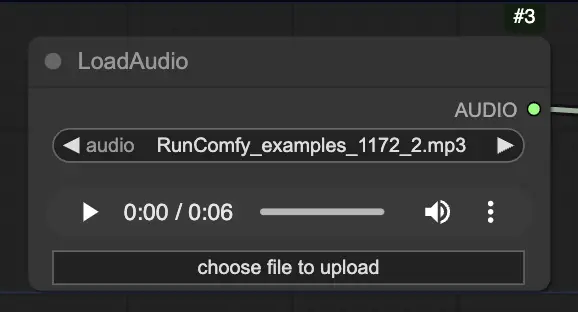
ステップ 2. LoadAudioノードを使用してオーディオファイルをロードします。オーディオ内のスピーチは、ポートレートの被写体のアイデンティティと一致する必要があります。
ステップ 3. Echo_LoadModelノードを使用してEchoMimicモデルをロードします。主要な設定:
- バージョンを選択します(V1またはV2)。
- 推論モードを選択します。例: オーディオ駆動モード。
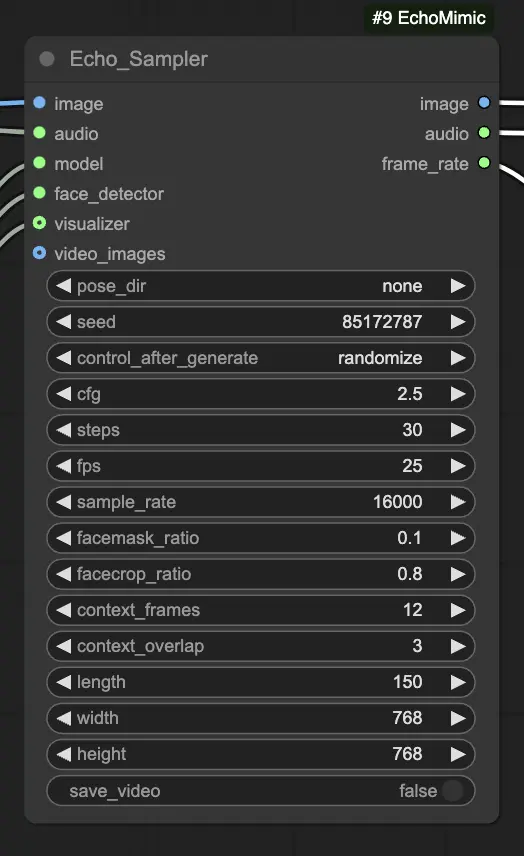
ステップ 4. 画像、オーディオ、およびロードされたモデルをEcho_Samplerノードに接続します。主要な設定:
- pose_dir: ポーズ駆動のアニメーションモードで使用されるポーズシーケンスファイルのディレクトリパス。"none"に設定すると、ポーズシーケンスは使用されません。
- seed: 実行を通じて一貫した結果を生成するためのランダムシード。0からMAX_SEEDまでの整数であるべきです。
- cfg: オーディオ条件付けの強度を制御する分類器フリーガイダンススケール。高い値はより顕著なオーディオ駆動の動きをもたらします。デフォルト値は2.5で、0.0から10.0までの範囲で設定できます。
- steps: 各フレームを生成するための拡散ステップの数。高い値はよりスムーズなアニメーションを生成しますが、生成に時間がかかります。デフォルトは30で、1から100までの範囲で設定できます。
- fps: 出力ビデオのフレーム毎秒のフレームレート。デフォルトは25で、5から100までの範囲で設定できます。
- sample_rate: 入力オーディオのサンプルレート(Hz)。デフォルトは16000で、8000から48000まで1000単位で設定できます。
- facemask_ratio: 顔マスク領域の全画像領域に対する比率。顔の周囲のアニメーション領域のサイズを制御します。デフォルトは0.1で、0.0から1.0までの範囲で設定できます。
- facecrop_ratio: 顔のクロップ領域の全画像領域に対する比率。画像のどれだけが顔領域に割り当てられるかを決定します。デフォルトは0.8で、0.0から1.0までの範囲で設定できます。
- context_frames: 各フレームを生成するために使用される過去と未来のフレームの数。デフォルトは12で、0から50までの範囲で設定できます。
- context_overlap: 隣接するコンテキストウィンドウ間の重なりフレームの数。デフォルトは3で、0から10までの範囲で設定できます。
- length: 出力ビデオのフレーム数。入力オーディオの長さとfps設定に基づいているべきです。例えば、オーディオが6秒長く、fpsが25に設定されている場合、長さは150フレームであるべきです。長さは50から5000フレームまでの範囲で設定できます。
- width: 出力ビデオフレームのピクセル単位の幅。デフォルトは512で、128から1024まで64単位で設定できます。
- height: 出力ビデオフレームのピクセル単位の高さ。デフォルトは512で、128から1024まで64単位で設定できます。
ビデオの生成には時間がかかる場合があります。例えば、RunComfyの2XLマシンを使用して6秒のオーディオクリップからビデオを作成するのには約20分かかります。

