Hallo2 | リップシンクポートレートアニメーション
Hallo2は、オーディオ入力によって駆動される高品質のリップシンクポートレートアニメーションを生成する高度なAIモデルです。拡散モデル、オーディオエンコーディング、顔検出などの技術を使用して、Hallo2は正確に同期された口の動きと表情を持つ4Kアニメーションを作成します。ComfyUIフレームワークにシームレスに統合されており、ユーザーはリアルなリップシンクポートレートアニメーションを作成できます。ComfyUI Hallo2 Lip-Sync ワークフロー
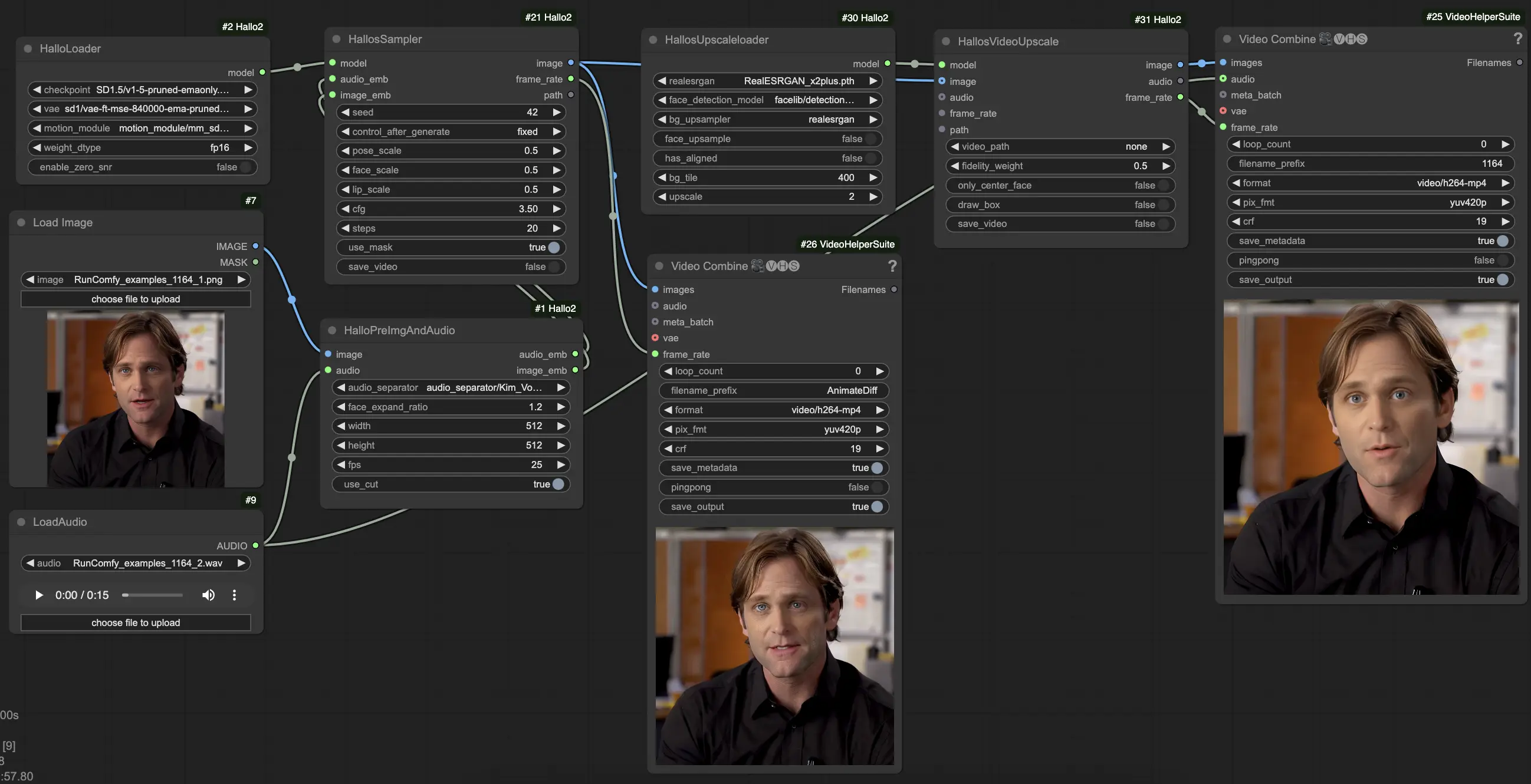
このワークフローを実行しますか?
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI Hallo2 Lip-Sync 例
ComfyUI Hallo2 Lip-Sync 説明
Hallo2技術は、Fudan UniversityとBaidu Inc.のJiahao Cui、Hui Li、Yao Yao、Hao Zhu、Hanlin Shang、Kaihui Cheng、Hang Zhou、Siyu Zhu、Jingdong Wangによって開発されました。詳細はを訪問してください。ComfyUI_Hallo2ノードとワークフローはsmthemexによって開発されました。詳細はを訪問してください。すべての貢献に感謝します。
1. Hallo2について
Hallo2は、高品質で長時間の4K解像度のオーディオ駆動ポートレートアニメーションビデオを生成する最先端モデルです。元のHalloモデルにいくつかの重要な改善を加えています:
- 数十分から数時間にわたる非常に長いビデオの生成をサポート
- 4K解像度でビデオを生成
- オーディオに加えてテキストプロンプトを使用して表情とポーズを制御可能
Hallo2は、データ拡張のような高度な技術を使用して長時間にわたる一貫性を維持し、4K解像度の潜在コードのベクトル量子化、およびオーディオとテキストの両方に導かれた改良されたノイズ除去プロセスを使用してこれを達成しています。
2. Hallo2の技術的特徴
Hallo2は、いくつかの高度なAIモデルと技術を組み合わせて高品質のポートレートビデオを作成します:
- 拡散モデル: これはビデオフレームを生成する「エンジン」です。ランダムノイズから始まり、オーディオとテキストプロンプトに導かれて目的の出力に合うように徐々に洗練されます。
- 3D U-Net: これは拡散プロセスの「彫刻家」として機能するタイプのニューラルネットワークです。現在のノイズのあるフレーム、オーディオ、テキスト指示を見て、最終ポートレートに見えるようにノイズを変更する方法を提案します。
- オーディオエンコーダー: Hallo2は、Wav2Vec2と呼ばれるモデルを「耳」として使用してオーディオを理解し、生の波形をトーン、速度、音声内容を捉えるコンパクトな表現に変換します。
- 顔検出器: 顔のアニメーションに集中するために、Hallo2は顔検出モデルを使用して参照画像のポートレートの顔を自動的に見つけます。これにより、リップと表情の動きを適用する場所がわかります。
- 画像圧縮器: 高解像度4K画像を効率的に処理するために、Hallo2は特定のタイプのオートエンコーダーモデル(VQ-VAE)を使用してそれらをより小さな「潜在」表現に圧縮し、最後に4Kにデコードします。これはJPEGが画像ファイルサイズを縮小しながら品質を保持する方法に似ています。
- 拡張トリック: 長時間ビデオの品質を維持するために、Hallo2は生成された以前のフレームにいくつかの賢い「データ拡張」を適用し、それらを次のフレームに影響を与えるために使用します。これにはランダムなパッチを消去したり、微妙なノイズを追加したりすることが含まれます。これにより、時間の経過とともに一貫性を損なう可能性のある累積エラーの防止に役立ちます。
要するに、Hallo2はオーディオとポートレート画像を取り込み、それらを一致させるためにビデオフレームを彫刻するAI「エージェント」を持ち、長時間のビデオでもすべてを同期させて一貫性を保つための追加のトリックを採用しています。これらのすべての部分が多段階のパイプラインで連携して、あなたが見る印象的な結果を生み出します。
3. ComfyUI Hallo2ワークフローの使用方法
Hallo2は、いくつかの専門的なノードを備えたカスタムワークフローを通じてComfyUIに統合されています。使用方法は次のとおりです:
LoadImageノードを使用して参照ポートレート画像をロードします。これは明確な正面のポートレートであるべきです。(ヒント:参照ポートレートがより良くフレーム化され、照明されているほど、結果は良くなります。側面のプロファイル、遮蔽、忙しい背景などを避けてください。)LoadAudioノードを使用して駆動オーディオをロードします。それはポートレートに感情を与えたいムードに合致するべきです。HalloPreImgAndAudioノードに画像とオーディオを接続します。これにより、画像とオーディオが埋め込みに前処理されます。主要なパラメータ:audio_separator: 背景ノイズから音声を分離するモデル。通常はデフォルトのままにします。face_expand_ratio: 検出された顔領域をどの程度拡張するか。より高い値はより多くの髪/背景を含みます。width/height: 生成解像度。より高い値は遅いが詳細。512-1024四角は良いバランスです。fps: 目標ビデオFPS。25は良いデフォルトです。
HalloLoaderノードを使用してコアHallo2モデルをロードします。あなたのHallo2チェックポイント、VAE、およびモーションモジュールファイルを指します。- 前処理された画像とオーディオの埋め込みとロードされたモデルを
HalloSamplerノードに接続します。これが実際のビデオ生成を行います。主要なパラメータ:seed: マイナーな詳細を決定するランダムシード。最初の結果が気に入らない場合は変更します。pose_scale/face_scale/lip_scale: ポーズ、顔の表情、リップの動きの強度をどの程度スケールするか。1.0 = 完全な強度、0.0 = 固定。cfg: クラスフィアフリーガイダンススケール。高いほど条件に従いますが多様性が少なくなります。steps: ノイズ除去ステップの数。ステップが多いほど品質が良くなりますが遅くなります。
- この時点で、生成されたビデオを表示できます。超解像で品質をさらに向上させるには、チェーンの最後に
HallosUpscaleloaderとHallosVideoUpscaleノードを追加します。アップスケールローダーは事前にトレーニングされたアップスケーリングモデルを読み込み、アップスケーラーノードは実際に4Kにアップスケーリングを行います。


