Stable Diffusion 3 (SD3) | テキストから画像へ
Stable Diffusion 3 (SD3) mediumは現在RunComfy Beta Versionで利用可能で、プロジェクトに簡単にアクセスできます。このワークフロー内でStable Diffusion 3 mediumを直接使用するか、既存のワークフローに統合することができます。ComfyUI Stable Diffusion 3 (SD3) Playground
ComfyUI Stable Diffusion 3 (SD3) ワークフロー
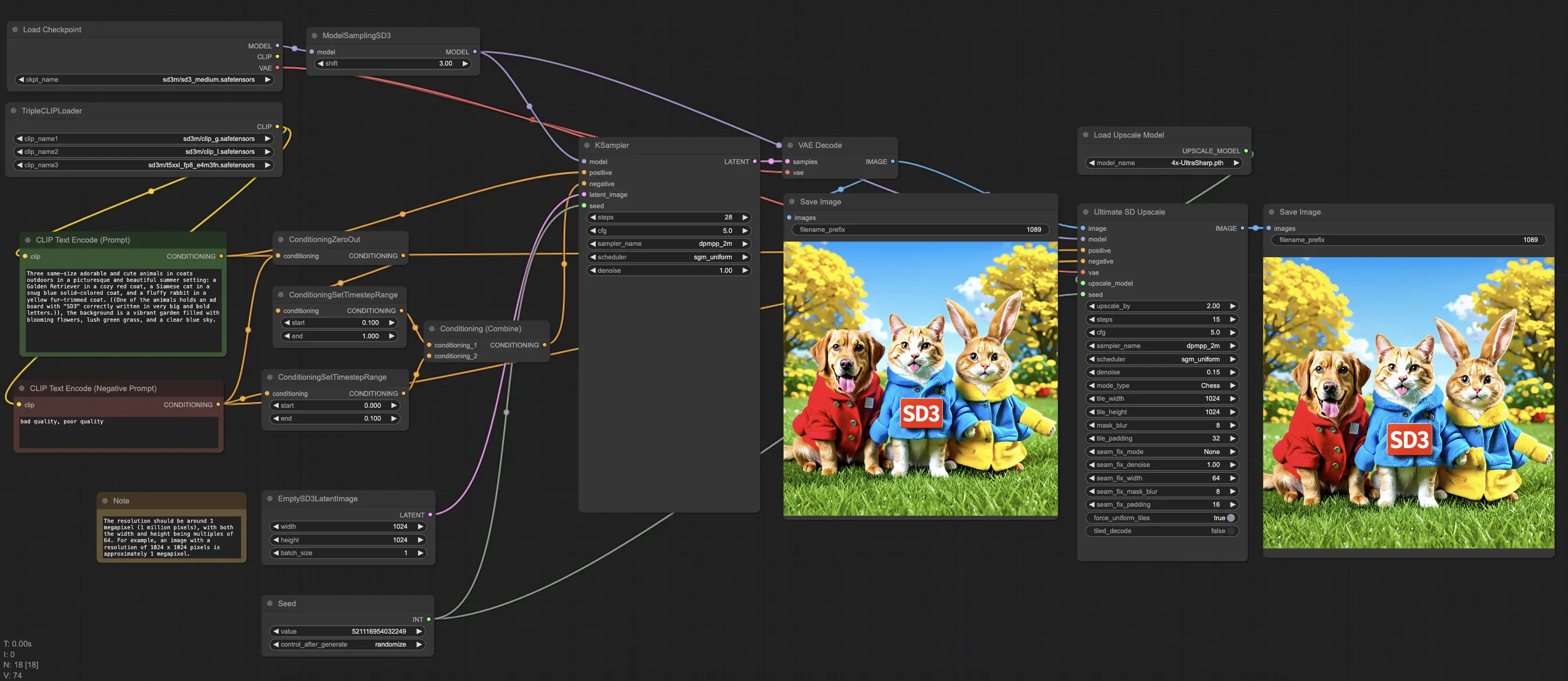
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI Stable Diffusion 3 (SD3) 例



ComfyUI Stable Diffusion 3 (SD3) 説明
1. ComfyUI Stable Diffusion 3でクリエイティブプロセスを強化する
🌟🌟🌟**Stable Diffusion 3 Mediumモデルとその関連ノードがRunComfyのComfyUI Beta Version (Version 24.06.13.0)に事前にロードされています!!!**🌟🌟🌟 このComfyUIワークフロー内でStable Diffusion 3 Mediumを直接使用するか、既存のComfyUIワークフローにシームレスに統合することができます。
ComfyUI Stable Diffusion 3ワークフローには、すべての必要なStable Diffusion 3 Mediumモデルが含まれています。異なるプロンプトやパラメータで実験して体験してみてください!
1.1. ComfyUIに事前ロードされたStable Diffusion 3 Mediumモデル
sd3_medium.safetensors: MMDiTおよびVAEウェイトを含みますが、テキストエンコーダは含まれていません。sd3_medium_incl_clips_t5xxlfp16.safetensors: 必要なすべてのウェイトを含み、T5XXLテキストエンコーダのfp16バージョンを含みます。sd3_medium_incl_clips_t5xxlfp8.safetensors: 必要なすべてのウェイトを含み、T5XXLテキストエンコーダのfp8バージョンを含み、品質とリソース要件のバランスを提供します。sd3_medium_incl_clips.safetensors: T5XXLテキストエンコーダを除く必要なすべてのウェイトを含みます。このバージョンは最小限のリソースを必要としますが、T5XXLテキストエンコーダがないためモデルのパフォーマンスは異なります。text_encodersフォルダには、ユーザーの利便性のために3つのテキストエンコーダとそのオリジナルのモデルカードリンクが含まれています。このフォルダ内のすべてのコンポーネント(および他のパッケージに埋め込まれたそれらの同等物)は、それぞれのオリジナルのライセンスに従います。
1.2 Stable Diffusion 3 Mediumの全体的な品質とフォトリアリズム
Stable Diffusion 3 Mediumは、AIアートコミュニティにおける画像品質の新しい基準を設定します。このモデルは、卓越したディテール、色の精度、リアルな照明を備えた画像を提供します。期待できることは次の通りです:
- ディテールと解像度: 複雑な詳細をレンダリングする能力が向上しており、クローズアップや複雑な構図に最適です。
- 色と照明: 改良されたアルゴリズムにより、色が鮮やかでリアルに見え、動的な照明効果が画像に深みとリアリズムを追加します。
- 顔と手のリアリズム: 16チャンネルのVariational Autoencoder (VAE)のような革新により、歪んだ手や顔などの一般的な問題が大幅に減少します。
1.3 Stable Diffusion 3 Mediumのプロンプト理解
SD3 Mediumの際立った特徴の一つは、その高度なプロンプト理解能力です。このモデルは、空間的推論、構成要素、アクション、スタイルを含む長く複雑なプロンプトを解釈することができます。ここにいくつかのハイライトがあります:
- テキストエンコーダ: パフォーマンスと効率のバランスを取るために3つのテキストエンコーダを使用します。これにより、詳細なプロンプトの微妙な理解と実行が可能になります。
- 構成認識: 空間関係を維持し、シーンを正確に描写する能力があり、視覚を通じたストーリーテリングに最適です。
1.4 Stable Diffusion 3 Mediumのタイポグラフィ
タイポグラフィはテキストから画像生成への挑戦の一つです。SD3 Mediumはこれを驚くほど成功させています:
- テキスト品質: スペル、カーニング、文字形成、スペーシングにおいて前例のない精度を達成します。
- Diffusion Transformerアーキテクチャ: この高度なアーキテクチャにより、画像内のテキストのより正確なレンダリングが可能になり、エラーが減少し視覚的一貫性が向上します。
1.5 Stable Diffusion 3 Mediumのリソース効率
その高度な機能にもかかわらず、SD3 Mediumはリソース効率を重視して設計されています:
- 低VRAMフットプリント: 標準の消費者用GPUでパフォーマンスの低下なしに実行でき、高品質のAIアートをより多くのユーザーに提供します。
- 効率のための最適化: 計算要求と出力品質のバランスを取り、低性能のハードウェアでもスムーズに動作します。
1.6 Stable Diffusion 3 Mediumの微調整
カスタマイズはAIアーティストにとって重要な側面であり、SD3 Mediumはこの分野で優れています:
- 微妙な詳細の吸収: 小さなデータセットでの微調整が可能で、アーティストが独自のスタイルを反映させたり、特定のプロジェクト要件に対応したりできます。
- 多用途性: 特定のテーマ、スタイル、複雑な詳細を扱う場合でも、SD3 Mediumはパーソナライズされたアートワークに必要な柔軟性を提供します。
2. Stable Diffusion 3とは何ですか
Stable Diffusion 3は、プロンプトから画像を生成するために特別に設計された最先端のAIモデルです。Stable Diffusionシリーズの第3世代を表し、以前のバージョンやDALL·E 3、Midjourney v6、Ideogram v1などの他のモデルに比べて、精度の向上、プロンプトのニュアンスへの対応の向上、優れた視覚美学を提供することを目指しています。
3. Stable Diffusion 3モデル
Stable Diffusion 3は、異なるニーズと計算能力に対応する3つの異なるモデルを提供します:
3.1. Stable Diffusion 3 Medium
🌟🌟🌟 このワークフローに直接統合されています 🌟🌟🌟
- パラメータ: 20億
- 主な特徴:
- 高品質なフォトリアリスティックな画像
- 複雑なプロンプトの高度な理解
- 優れたタイポグラフィ機能
- リソース効率が良く、消費者向けGPUに適しています
- 小さなデータセットでの微調整に最適
3.2. Stable Diffusion 3 Large
で利用可能
- パラメータ: 80億
- 主な特徴:
- 画像品質とディテールの向上
- 複雑なプロンプトやスタイルの処理能力が向上
- 高解像度と忠実度が求められるプロフェッショナルなプロジェクトに最適
3.3. Stable Diffusion 3 Large Turbo
で利用可能
- パラメータ: 80億(推論時間を最適化)
- 主な特徴:
- SD3 Largeと同じ高性能
- 推論が速く、リアルタイムアプリケーションや迅速なプロトタイピングに適しています
4. Stable Diffusion 3の技術アーキテクチャ
Stable Diffusion 3の核心には、Multimodal Diffusion Transformer (MMDiT)アーキテクチャがあります。この革新的なフレームワークは、モデルがテキストと視覚情報を処理し統合する方法を強化します。以前のバージョンでは、画像とテキストの処理に単一のニューラルネットワークウェイトセットが使用されていましたが、Stable Diffusion 3では各モダリティに対して別々のウェイトセットを使用します。この分離により、テキストと画像データのより専門的な処理が可能になり、生成された画像のテキスト理解とスペルの精度が向上します。
4.1. MMDiTアーキテクチャのコンポーネント
- テキストエンベッダー: Stable Diffusion 3は、CLIPモデル2つとT5を含む3つのテキスト埋め込みモデルを組み合わせて、テキストをAIが理解し処理できる形式に変換します。
- 画像エンコーダ: 画像をAIが操作し新しい視覚コンテンツを生成するのに適した形式に変換するための強化されたオートエンコーディングモデル。
- デュアルトランスフォーマーアプローチ: アーキテクチャはテキストと画像のための2つの異なるトランスフォーマーを特徴とし、それぞれ独立して動作しますが、注意操作のために相互に接続されています。この設定により、両方のモダリティが直接影響し合い、テキスト入力と画像出力の間の一貫性が向上します。
5. Stable Diffusion 3の新機能と改善点
- プロンプトへの遵守: SD3は、特に複雑なシーンや複数の被写体を含むユーザープロンプトの特定に従うことに優れています。この詳細なプロンプトの理解とレンダリングの精度により、DALL·E 3、Midjourney v6、Ideogram v1などの他の主要モデルよりも優れたパフォーマンスを発揮し、与えられた指示に厳密に従う必要があるプロジェクトに高い信頼性を持ちます。
- 画像内のテキスト: 高度なMultimodal Diffusion Transformer (MMDiT)アーキテクチャにより、SD3は画像内のテキストの明瞭さと読みやすさを大幅に向上させます。画像データと言語データの処理に別々のウェイトセットを使用することで、モデルは優れたテキスト理解とスペルの精度を達成します。これは、テキストから画像へのAIアプリケーションにおける一般的な課題に対する大きな改善です。
- 視覚品質: SD3は、競合他社が生成する画像の視覚品質に匹敵するだけでなく、多くの場合それを上回ります。生成された画像は美的に優れているだけでなく、プロンプトに対する高い忠実度を維持しており、モデルの精緻なテキスト記述の解釈と視覚化能力のおかげです。これにより、生成された画像に優れた視覚美学を求めるユーザーにとって、SD3は最適な選択肢となります。

モデルの詳細な洞察については、をご覧ください。





