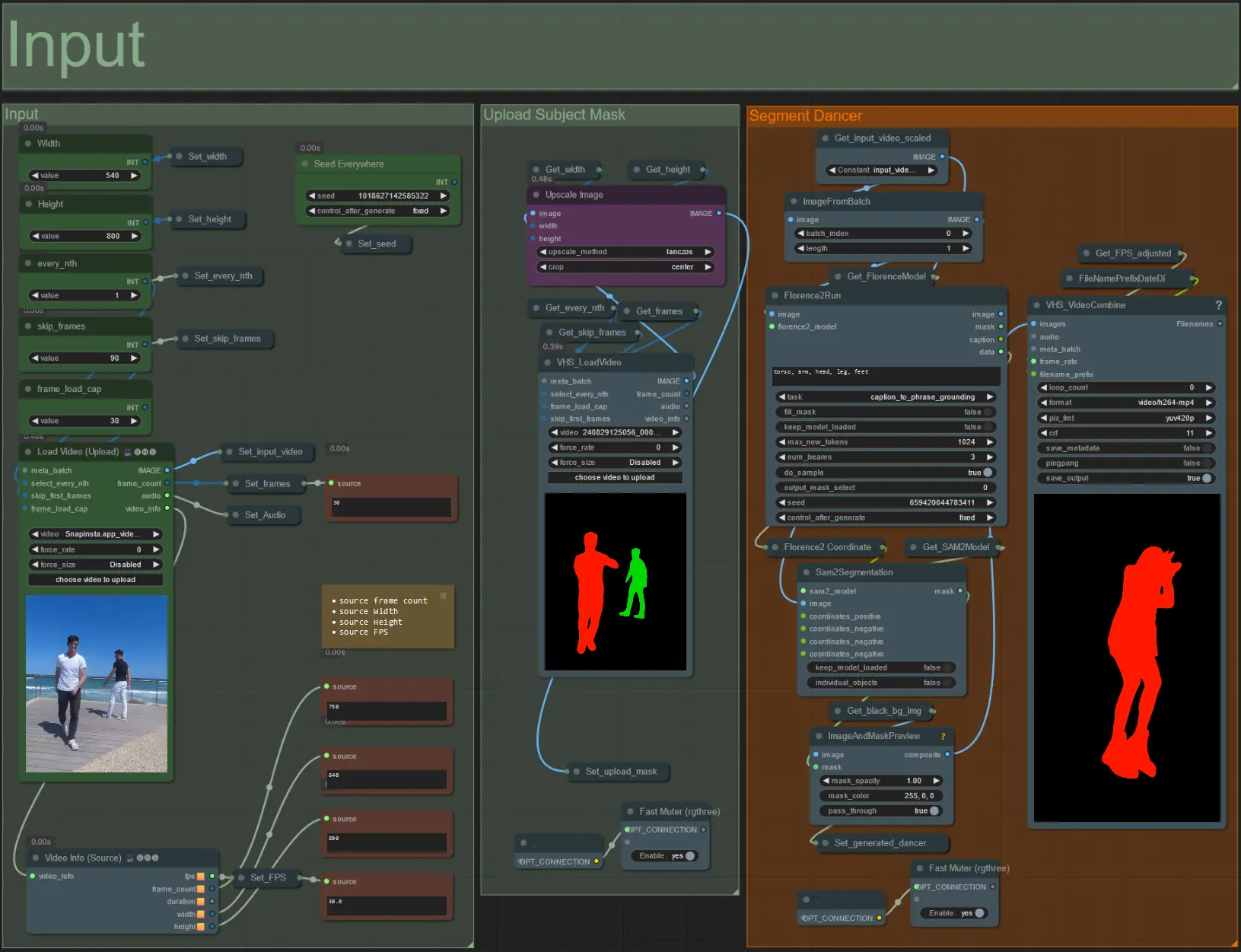
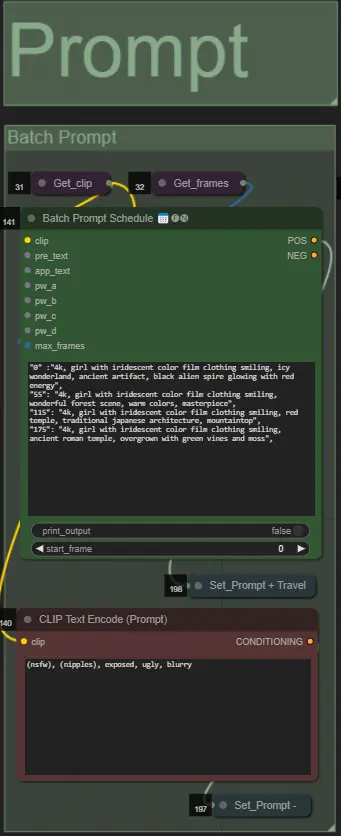
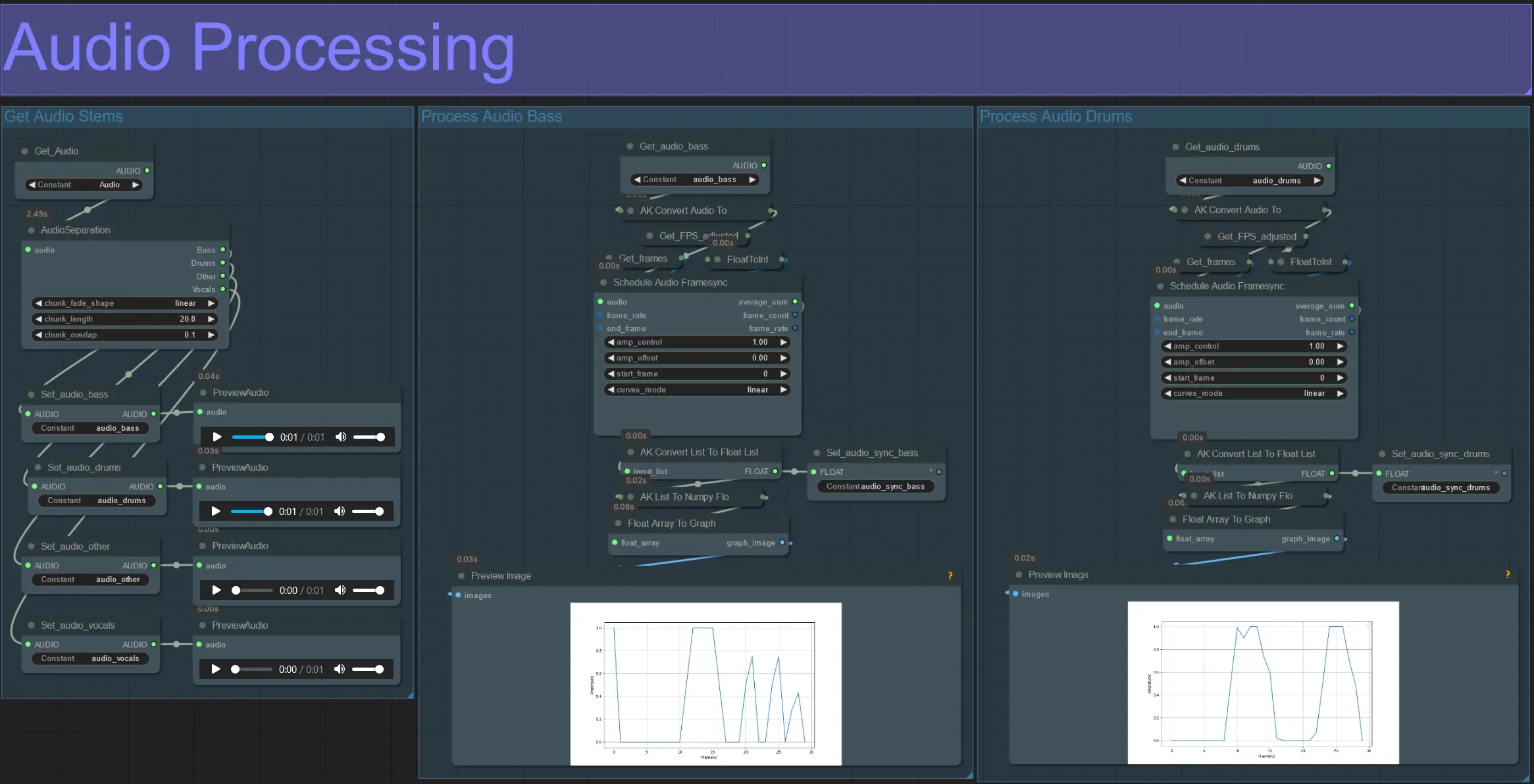
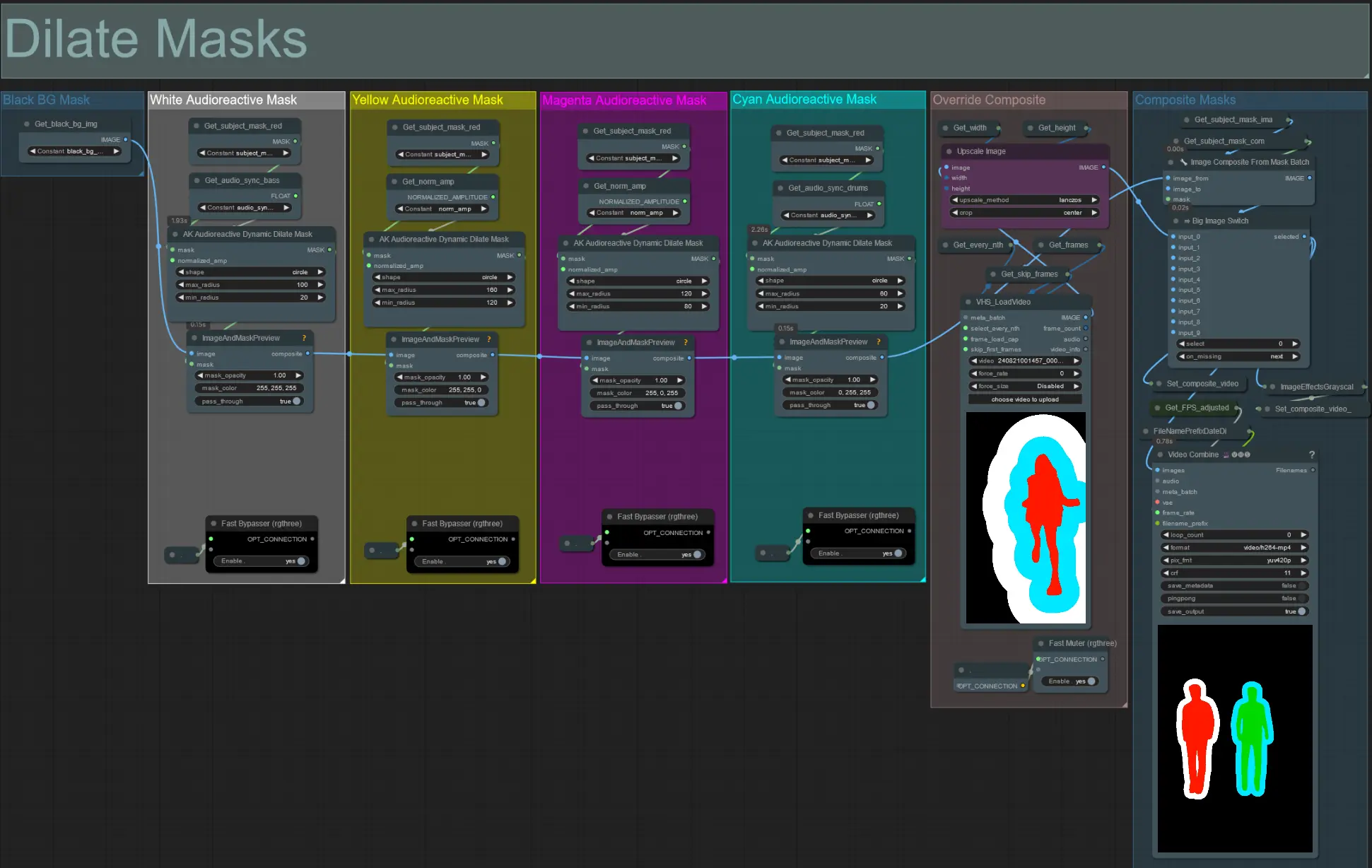
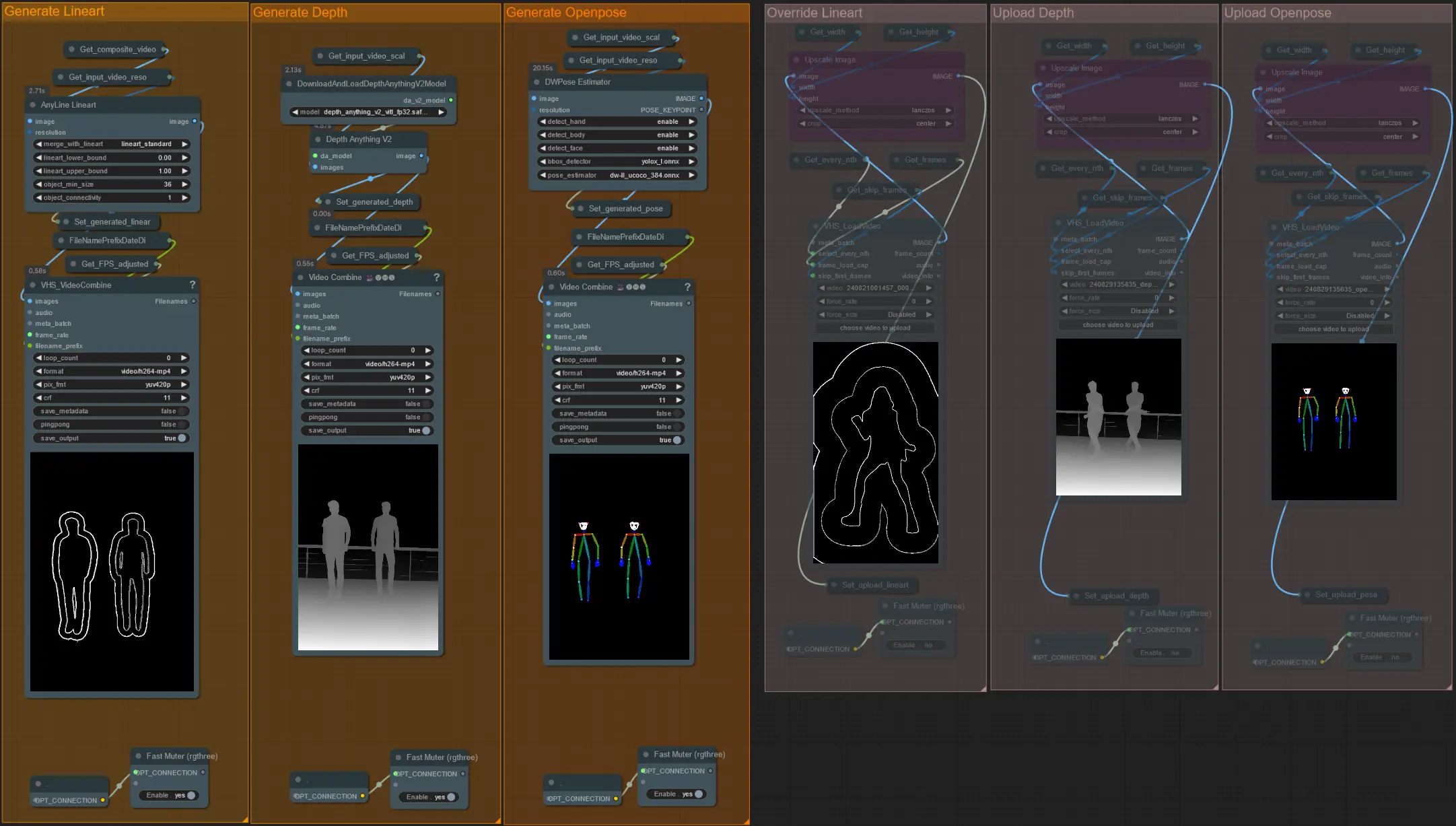
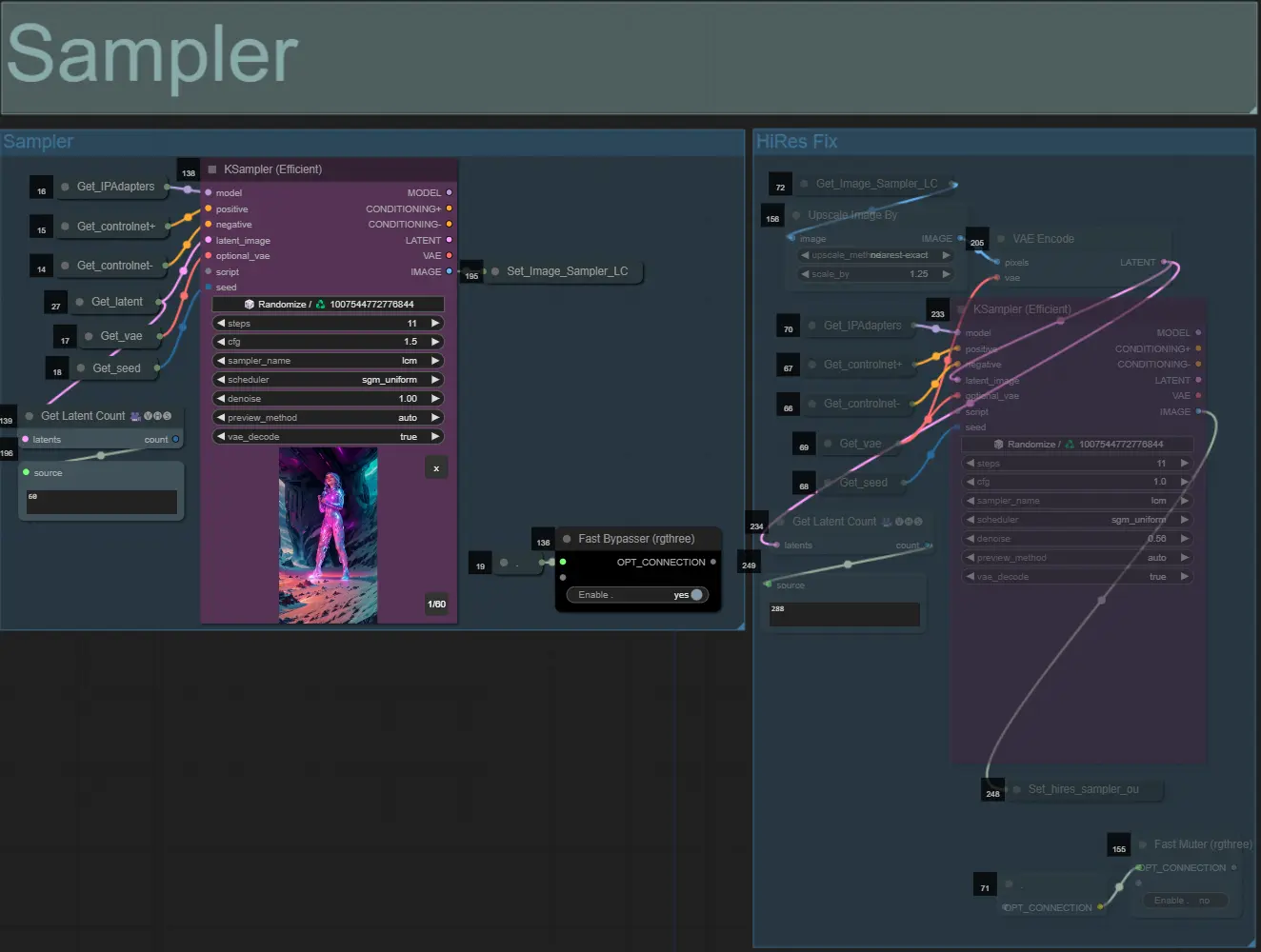
ダンサーなどの被写体を動的なオーラでリズムに合わせて拡大および収縮させることで、驚異的なビデオアニメーションを作成します。このワークフローを使用して、単一の被写体または複数の被写体を処理することができます。
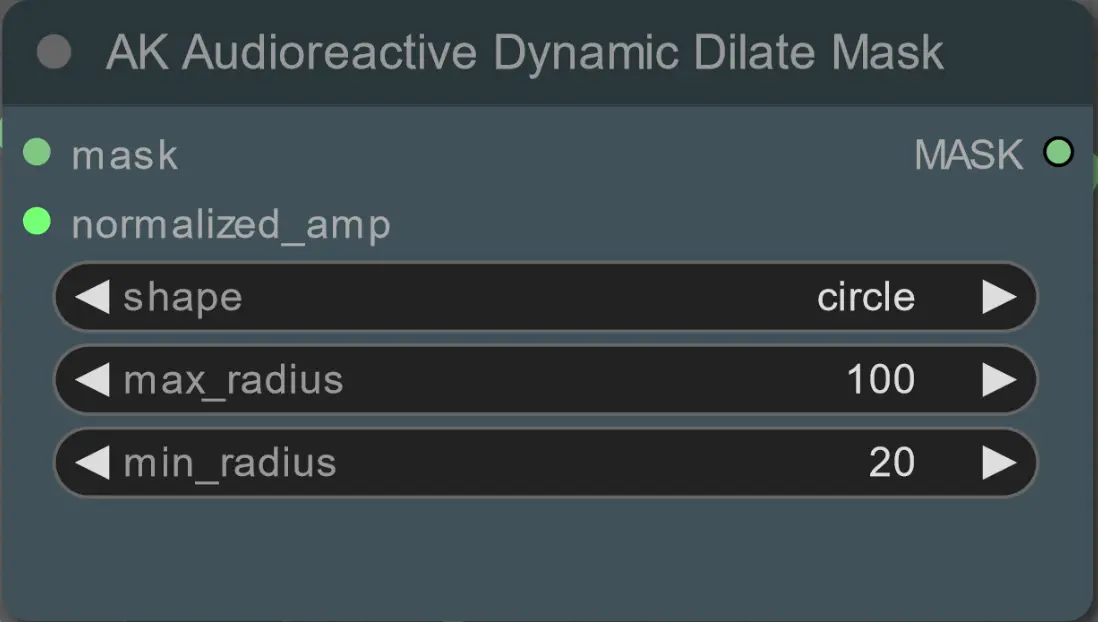
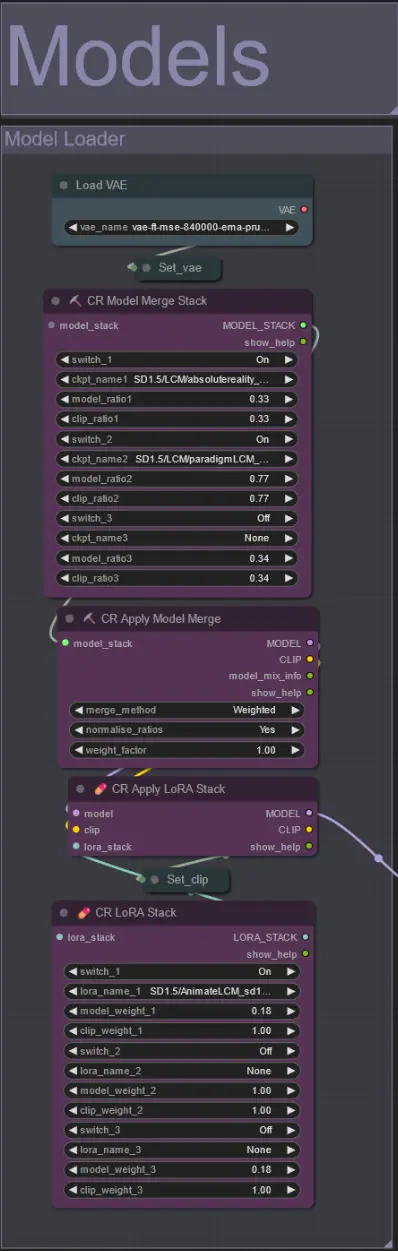

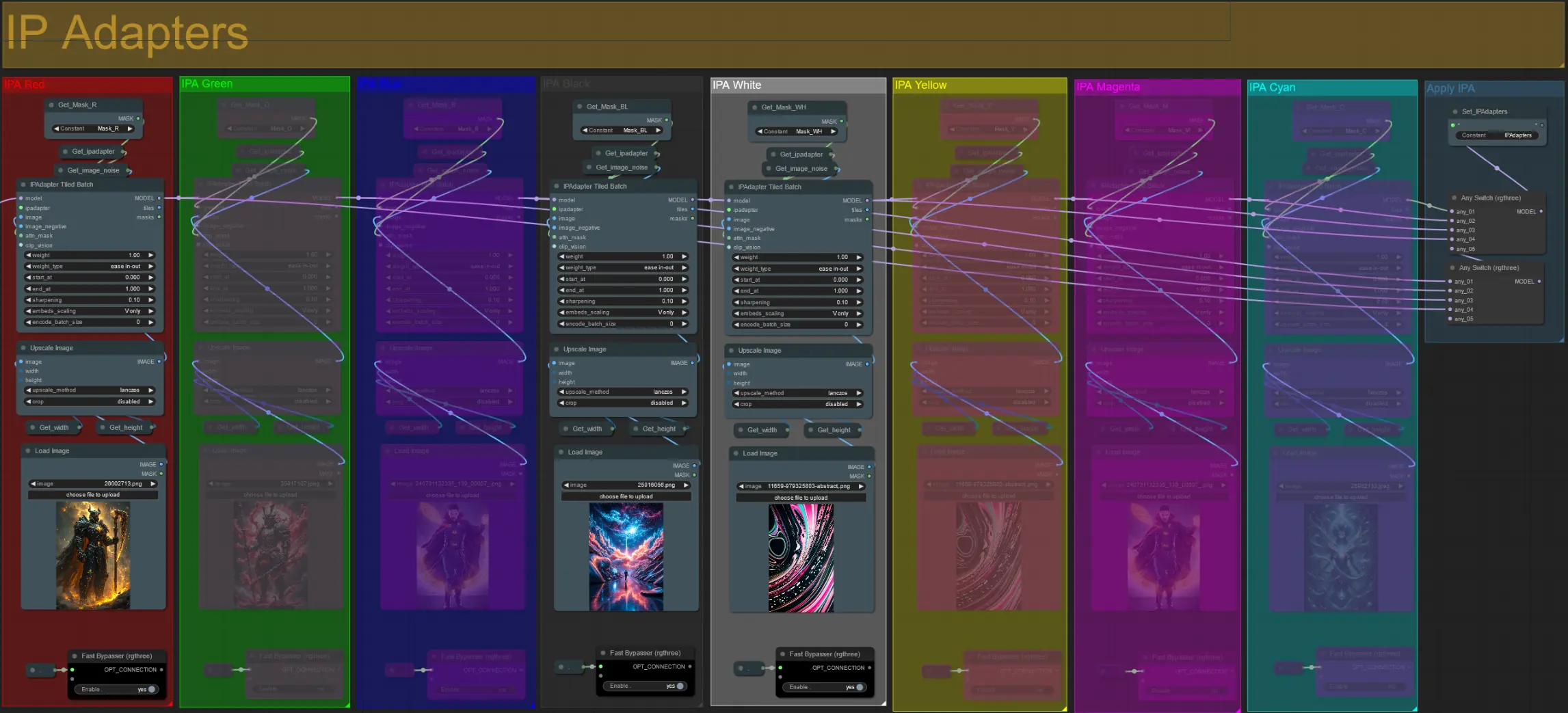
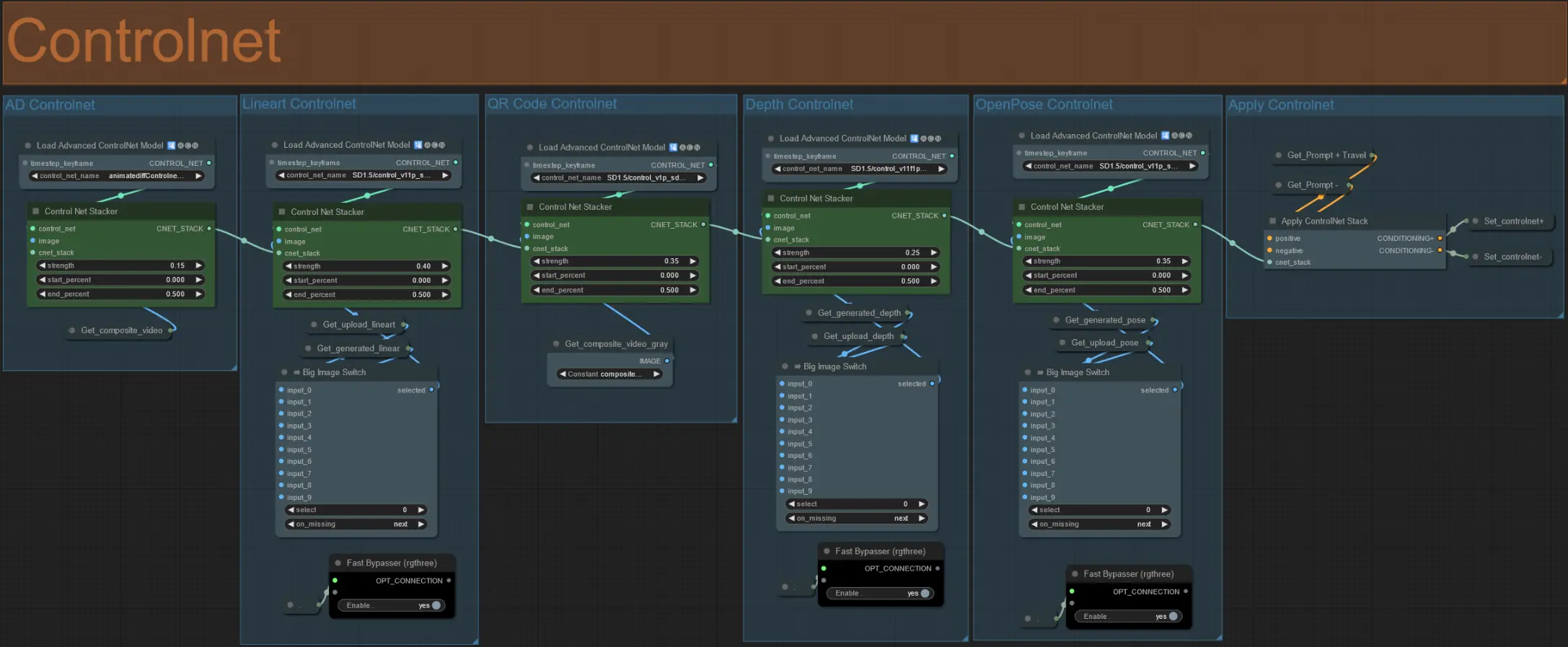
ヒント:

Akatz AI:
連絡先:
RunComfyは最高の ComfyUI プラットフォームです。次のものを提供しています: ComfyUIオンライン 環境とサービス、および ComfyUIワークフロー 魅力的なビジュアルが特徴です。 RunComfyはまた提供します AI Playground, アーティストが最新のAIツールを活用して素晴らしいアートを作成できるようにする。
