


ComfyUIのパワーを解き放とう:実践的な初心者ガイド
Updated: 5/15/2024
こんにちは、AIアーティストの皆さん! 👋 この初心者向けチュートリアルでは、驚くほど強力で柔軟なAIアートツールであるComfyUIの基本を紹介します。 🎨 このガイドでは、ComfyUIの基本を説明し、その機能を探求し、あなたのAIアートを次のレベルに引き上げるポテンシャルを解き放つのを助けます。 🚀
以下の内容を取り上げます:
1. ComfyUIとは?
- 1.1. ComfyUI vs. AUTOMATIC1111
- 1.2. ComfyUIを始めるには?
- 1.3. 基本的な操作方法
2. ComfyUIのワークフロー:Text-to-Image
- 2.1. モデルの選択
- 2.2. ポジティブプロンプトとネガティブプロンプトの入力
- 2.3. 画像の生成
- 2.4. ComfyUIの技術的説明
- 2.4.1 チェックポイントノードの読み込み
- 2.4.2. CLIPテキストエンコード
- 2.4.3. 空のLatent画像
- 2.4.4. VAE
- 2.4.5. KSampler
3. ComfyUIのワークフロー:Image-to-Image
4. ComfyUI SDXL
5. ComfyUI Inpainting
6. ComfyUI Outpainting
7. ComfyUI Upscale
- 7.1. Upscale Pixel
- 7.1.1. アルゴリズムによるUpscale Pixel
- 7.1.2. モデルによるUpscale Pixel
- 7.2. Upscale Latent
- 7.3. Upscale Pixel vs. Upscale Latent
8. ComfyUI ControlNet
9. ComfyUI Manager
- 9.1. 不足しているカスタムノードのインストール方法
- 9.2. カスタムノードの更新方法
- 9.3. ワークフローにカスタムノードを読み込む方法
10. ComfyUI Embeddings
- 10.1. オートコンプリート機能付きのEmbedding
- 10.2. Embeddingの重み付け
11. ComfyUI LoRA
- 11.1. シンプルなLoRAワークフロー
- 11.2. 複数のLoRA
12. ComfyUIのショートカットとコツ
- 12.1. コピー&ペースト
- 12.2. 複数ノードの移動
- 12.3. ノードをバイパスする
- 12.4. ノードを最小化する
- 12.5. 画像生成
- 12.6. 埋め込みワークフロー
- 12.7. シードを固定して時間を節約
13. ComfyUIオンライン
1. ComfyUIとは? 🤔
ComfyUIは、手軽に感動的なAI生成アートワークを作成できる魔法の杖のようなものです。🪄 ComfyUIの核となるのは、テキストの説明から画像を生成する最先端のディープラーニングモデル「Stable Diffusion」の上に構築されたノードベースのグラフィカルユーザーインターフェイス(GUI)です。🌟 しかし、ComfyUIが本当に特別なのは、アーティストであるあなたの創造力を解き放ち、最も大胆なアイデアを実現できるようにすることです。
異なる機能や操作を表す各ノードを接続して、独自の画像生成ワークフローを構築できるデジタルキャンバスを想像してみてください。🧩 まるでAIが生成したマスターピースのためのビジュアルレシピを構築するようなものです!
テキストプロンプトから画像をゼロから生成したいですか?そのためのノードがあります! 特定のサンプラーを適用したり、ノイズレベルを微調整したりする必要がありますか? 対応するノードを追加するだけで、魔法が起こるのを見ることができます。✨
でも、ここが一番素晴らしい部分です。ComfyUIは、ワークフローを並べ替え可能な要素に分解し、あなたの芸術的ビジョンに合わせてカスタムワークフローを作成する自由を与えてくれます。🖼️ まるで、創作プロセスに合わせて進化するパーソナライズされたツールキットを持っているようなものです。
1.1. ComfyUI vs. AUTOMATIC1111 🆚
AUTOMATIC1111はStable Diffusionのデフォルトのインターフェースです。では、代わりにComfyUIを使うべきでしょうか?比較してみましょう。
✅ ComfyUIを使うメリット:
- 軽量:高速かつ効率的に動作します。
- 柔軟性:ニーズに合わせて高度にカスタマイズ可能。
- 透明性:データフローが可視化され、理解しやすい。
- 共有しやすい:各ファイルが再現可能なワークフローを表す。
- プロトタイピングに適している:コーディングの代わりにグラフィカルインターフェースでプロトタイプを作成できる。
❌ ComfyUIを使うデメリット:
- インターフェースの一貫性のなさ:ワークフローごとにノードレイアウトが異なる可能性がある。
- 詳細が多すぎる:一般的なユーザーは根底にある接続を知る必要がないかもしれない。
1.2. ComfyUIを始めるには? 🏁
私たちは、ComfyUIを学ぶための最良の方法は、実例に飛び込み、直接体験することだと考えています。🙌 そのため、他のチュートリアルとは一線を画すこのユニークなチュートリアルを作成しました。このチュートリアルでは、順を追って学べる詳細なガイドを用意しています。
そして、ここが最も素晴らしい部分です。🌟 このウェブページにComfyUIを直接組み込んでいます!ガイドを進めながら、リアルタイムでComfyUIの例に触れることができます。🌟 さっそく始めましょう!
2. ComfyUIのワークフロー:Text-to-Image 🖼️
最もシンプルなケースから始めましょう:テキストから画像を生成することです。Queue Promptをクリックして、ワークフローを実行してください。少し待つと、最初の生成画像が表示されるはずです!キューを確認するには、View Queueをクリックしてください。
こちらが試せるデフォルトのText-to-Imageワークフローです:
基本的な構成要素 🕹️
ComfyUIのワークフローは、ノードとエッジの2つの基本的な構成要素からなります。
- ノードは長方形のブロックで、Load Checkpoint、Clip Text Encoderなどがあります。各ノードは特定のコードを実行し、入力、出力、パラメータを必要とします。
- エッジは、ノード間の出力と入力を結ぶワイヤーです。
基本的な操作方法 🕹️
- マウスホイールまたは2本指のピンチで拡大・縮小します。
- 入力または出力の点をドラッグ&ホールドして、ノード間の接続を作成します。
- マウスの左ボタンを押しながらドラッグして、ワークスペースを移動します。
このワークフローの詳細に飛び込みましょう。
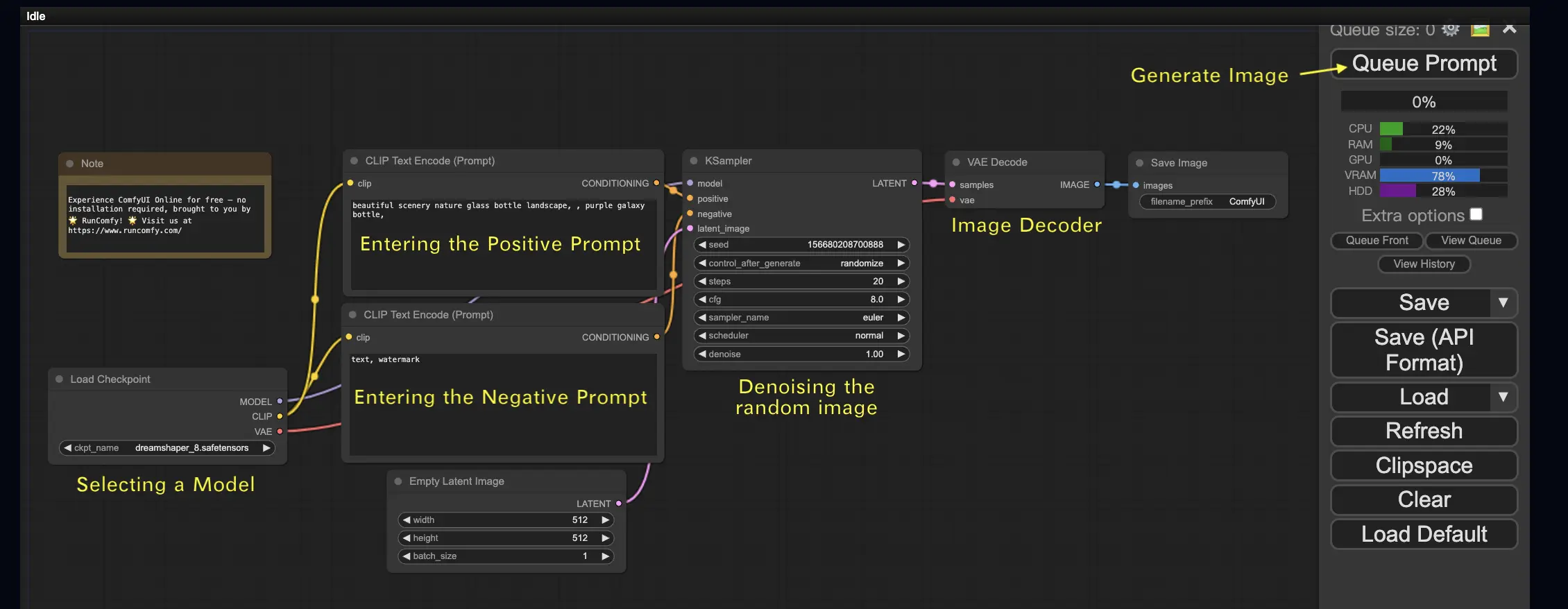
2.1. モデルの選択 🗃️
まず、Load CheckpointノードでStable Diffusionのチェックポイントモデルを選択します。モデル名をクリックすると、利用可能なモデルが表示されます。モデル名をクリックしても何も起こらない場合は、カスタムモデルをアップロードする必要があるかもしれません。
2.2. ポジティブプロンプトとネガティブプロンプトの入力 📝
CLIP Text Encode (Prompt)というラベルの付いた2つのノードが見えるでしょう。上のプロンプトはKSamplerノードのpositive入力に、下のプロンプトはnegative入力に接続されています。そのため、ポジティブプロンプトを上に、ネガティブプロンプトを下に入力します。
CLIP Text Encodeノードは、プロンプトをトークンに変換し、テキストエンコーダーを使ってそれらをエンベディングにエンコードします。
💡 ヒント:(keyword:weight)の構文を使って、キーワードの重みを制御します。例えば、(keyword:1.2)で効果を高めたり、(keyword:0.8)で効果を下げたりできます。
2.3. 画像の生成 🎨
Queue Promptをクリックして、ワークフローを実行します。少し待つと、最初の画像が生成されます!
2.4. ComfyUIの技術的説明 🤓
ComfyUIのパワーは、その設定可能性にあります。各ノードが何をするのかを理解することで、ニーズに合わせてカスタマイズできます。でも、詳細に飛び込む前に、ComfyUIがどのように機能するのかをより理解するために、Stable Diffusionのプロセスを見てみましょう。
Stable Diffusionのプロセスは、大きく3つのステップに要約できます。
- テキストエンコーディング:ユーザー入力のプロンプトは、Text Encoderと呼ばれるコンポーネントによって個々の単語の特徴ベクトルにコンパイルされます。このステップでは、テキストをモデルが理解して扱える形式に変換します。
- 潜在空間変換:Text Encoderからの特徴ベクトルとランダムノイズ画像が、潜在空間に変換されます。この空間では、ランダム画像が特徴ベクトルに基づいてデノイジングされ、中間生成物となります。このステップでは、モデルがテキストの特徴をビジュアル表現と関連付けることを学習し、魔法が起こります。
- 画像デコーディング:最後に、潜在空間からの中間生成物が Image Decoder によってデコードされ、私たちが見て感謝できる実際の画像に変換されます。
Stable Diffusionのプロセスの大まかな理解ができたところで、ComfyUIでこのプロセスを可能にする主要なコンポーネントとノードを詳しく見ていきましょう。
2.4.1 チェックポイントノードの読み込み 🗃️
ComfyUIのLoad Checkpointノードは、Stable Diffusionモデルを選択するために重要な役割を果たします。Stable Diffusionモデルは、MODEL、CLIP、VAEの3つの主要コンポーネントで構成されています。各コンポーネントとComfyUIの対応するノードの関係を見ていきましょう。
- MODEL:MODELコンポーネントは、潜在空間で動作するノイズ予測モデルです。潜在表現から画像を生成するコアプロセスを担当します。ComfyUIでは、Load CheckpointノードのMODEL出力がKSamplerノードに接続されており、ここで逆拡散プロセスが行われます。KSamplerノードはMODELを使用して、潜在表現を反復的にデノイズし、目的のプロンプトに合致するまで徐々に画像を洗練していきます。
- CLIP:CLIP(Contrastive Language-Image Pre-training)は、ユーザーが提供するポジティブプロンプトとネガティブプロンプトを前処理する言語モデルです。テキストプロンプトをMODELが理解して使用できる形式に変換します。ComfyUIでは、Load CheckpointノードのCLIP出力がCLIP Text Encodeノードに接続されます。CLIP Text Encodeノードは、ユーザーが提供したプロンプトを受け取り、CLIP言語モデルに入力し、各単語をエンベディングに変換します。これらのエンベディングは単語の意味を捉え、MODELが与えられたプロンプトに沿った画像を生成できるようにします。
- VAE:VAE(Variational AutoEncoder)は、画像をピクセル空間と潜在空間の間で変換する役割を担います。画像を低次元の潜在表現に圧縮するエンコーダと、潜在表現から画像を再構成するデコーダで構成されています。Text-to-Imageのプロセスでは、VAEは最後のステップでのみ使用され、生成された画像を潜在空間からピクセル空間に変換します。ComfyUIのVAE Decodeノードは、KSamplerノード(潜在空間で動作)の出力を受け取り、VAEのデコーダ部分を使って潜在表現を最終的なピクセル空間の画像に変換します。
VAEはCLIP言語モデルとは別のコンポーネントであることに注意が必要です。CLIPはテキストプロンプトの処理に重点を置いているのに対し、VAEはピクセル空間と潜在空間の間の変換を扱います。
2.4.2. CLIPテキストエンコード 📝
ComfyUIのCLIP Text Encodeノードは、ユーザーが提供したプロンプトを受け取り、CLIP言語モデルに入力する役割を果たします。CLIPは、単語の意味を理解し、視覚的概念と関連付けることができる強力な言語モデルです。プロンプトがCLIP Text Encodeノードに入力されると、各単語がエンベディングに変換される変換プロセスを経ます。これらのエンベディングは、単語の意味情報を捉える高次元のベクトルです。プロンプトをエンベディングに変換することで、CLIPはMODELが与えられたプロンプトの意味と意図を正確に反映した画像を生成できるようになります。
2.4.3. 空のLatent画像 🌌
Text-to-Imageのプロセスでは、潜在空間のランダムな画像から生成がスタートします。このランダム画像は、MODELが扱う初期状態として機能します。Latent画像のサイズは、ピクセル空間での実際の画像サイズに比例します。ComfyUIでは、Latent画像の高さと幅を調整して、生成される画像のサイズを制御できます。さらに、バッチサイズを設定して、1回の実行で生成する画像の数を決めることができます。
Latent画像の最適なサイズは、使用する特定のStable Diffusionモデルによって異なります。SD v1.5モデルでは、512x512または768x768のサイズが推奨されますが、SDXLモデルでは1024x1024が最適なサイズです。ComfyUIには、1:1(正方形)、3:2(横長)、2:3(縦長)、4:3(横長)、3:4(縦長)、16:9(ワイドスクリーン)、9:16(縦長)など、一般的なアスペクト比が用意されています。モデルのアーキテクチャとの互換性を確保するために、Latent画像の幅と高さは8の倍数である必要があります。
2.4.4. VAE 🔍
VAE(Variational AutoEncoder)は、Stable Diffusionモデルにおいて、ピクセル空間と潜在空間の間で画像の変換を扱う重要なコンポーネントです。Image EncoderとImage Decoderの2つの主要な部分で構成されています。
Image Encoderは、ピクセル空間の画像を受け取り、それを低次元の潜在表現に圧縮します。この圧縮プロセスは、データサイズを大幅に削減し、より効率的な処理と保存を可能にします。例えば、512x512ピクセルの画像を64x64の潜在表現にまで圧縮できます。
一方、Image Decoder(VAE Decoderとも呼ばれる)は、潜在表現から画像をピクセル空間に再構成する役割を担います。圧縮された潜在表現を取り込み、最終的な画像を生成するために展開します。
VAEを使用することにはいくつかの利点があります。
- 効率性:画像を低次元の潜在空間に圧縮することで、VAEは高速な生成とより短いトレーニング時間を可能にします。データサイズが縮小されることで、より効率的な処理とメモリ使用が実現します。
- 潜在空間操作:潜在空間は画像のよりコンパクトで意味のある表現を提供します。これにより、画像の詳細やスタイルのより正確な制御と編集が可能になります。潜在表現を操作することで、生成された画像の特定の側面を修正することができます。
しかし、いくつかの欠点も考慮する必要があります。
- データの損失:エンコーディングとデコーディングのプロセス中に、元の画像の一部の詳細が失われる可能性があります。圧縮と再構成の手順により、元の画像と比較して最終的な画像にアーチファクトや若干のバリエーションが生じる可能性があります。
- 元のデータの限定的な捕捉:低次元の潜在空間では、元の画像の複雑な特徴や詳細のすべてを完全に捉えきれない可能性があります。圧縮プロセス中に一部の情報が失われ、元のデータのやや不正確な表現になる可能性があります。
これらの制限にもかかわらず、VAEはStable Diffusionモデルにおいて重要な役割を果たし、ピクセル空間と潜在空間の間の効率的な変換を可能にし、より高速な生成とより正確な生成画像の制御を促進します。
2.4.5. KSampler ⚙️
ComfyUIのKSamplerノードは、Stable Diffusionにおける画像生成プロセスの中心です。潜在空間のランダム画像をユーザー提供のプロンプトに一致するようにデノイズする役割を担っています。KSamplerは、逆拡散と呼ばれる手法を採用しており、CLIPエンベディングからのガイダンスに基づいて、ノイズを除去し意味のある詳細を追加することで、潜在表現を反復的に洗練します。
KSamplerノードには、ユーザーが画像生成プロセスを微調整できるいくつかのパラメータがあります。
Seed:シード値は、最終的な画像の初期ノイズと構成を制御します。特定のシードを設定することで、ユーザーは再現可能な結果を得ることができ、複数の生成にわたって一貫性を維持できます。
Control_after_generation:このパラメータは、各生成後にシード値がどのように変化するかを決定します。randomize(各実行で新しいランダムシードを生成)、increment(シード値を1ずつ増加)、decrement(シード値を1ずつ減少)、fixed(シード値を一定に保つ)に設定できます。
Step:サンプリングステップの数は、洗練プロセスの強度を決定します。値が大きいほどアーチファクトが少なくなり、より詳細な画像が生成されますが、生成時間も長くなります。
Sampler_name:このパラメータでは、KSamplerが使用する特定のサンプリングアルゴリズムを選択できます。異なるサンプリングアルゴリズムは、わずかに異なる結果を生み出し、生成速度も異なる場合があります。
Scheduler:スケジューラは、デノイジングプロセスの各ステップでノイズレベルがどのように変化するかを制御します。潜在表現からノイズが除去される速度を決定します。
Denoise:デノイズパラメータは、デノイジングプロセスによって消去されるべき初期ノイズの量を設定します。値が1の場合、すべてのノイズが除去され、クリーンで詳細な画像が生成されます。
これらのパラメータを調整することで、目的の結果を得るために画像生成プロセスを微調整できます。
さあ、ComfyUIの旅に出発する準備はできましたか?
RunComfyでは、あなたのためだけに究極のComfyUIオンライン体験を用意しました。複雑なインストールにさようなら! 🎉 今すぐComfyUI Onlineを試す と、かつてないほどあなたの芸術的可能性が開花するでしょう! 🎉
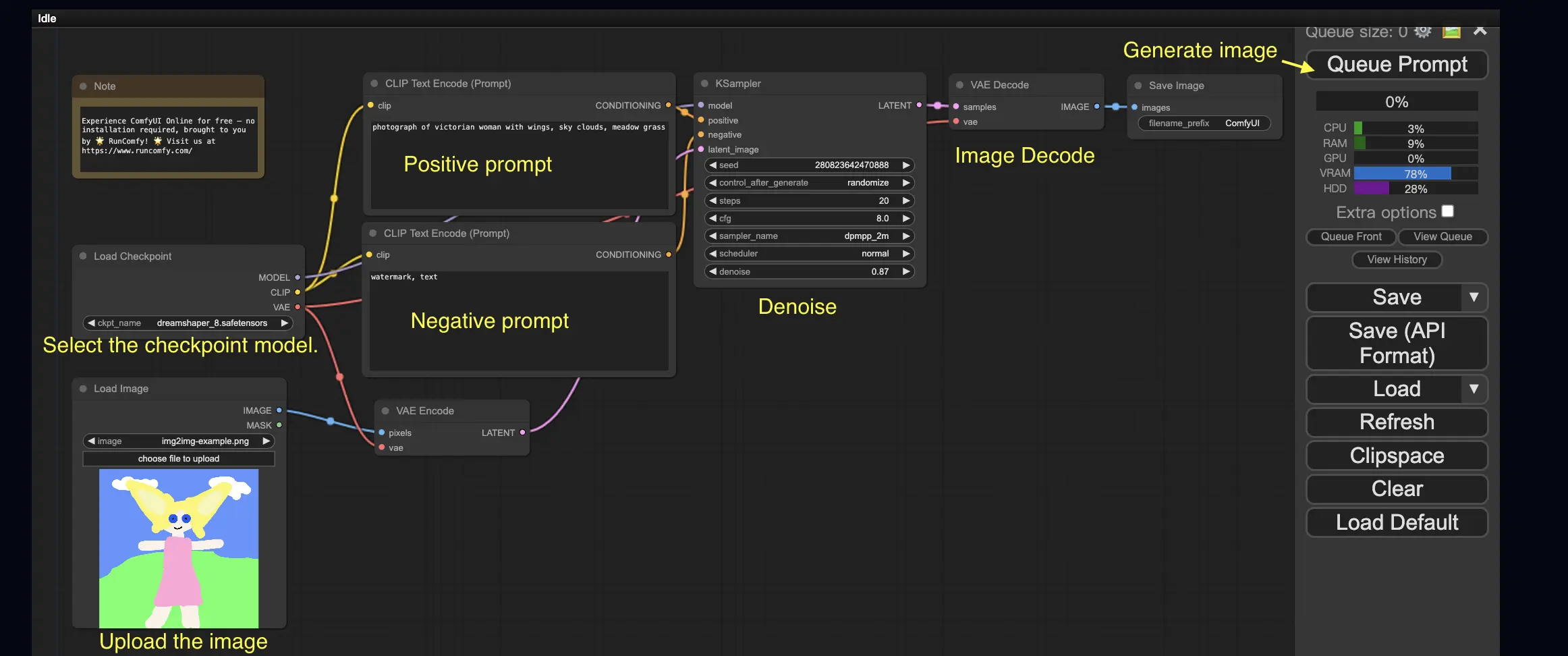
3. ComfyUIのワークフロー:Image-to-Image 🖼️
Image-to-Imageワークフローは、プロンプトと入力画像に基づいて画像を生成します。自分で試してみましょう!
Image-to-Imageワークフローを使用するには:
- チェックポイントモデルを選択します。
- 画像をイメージプロンプトとしてアップロードします。
- ポジティブプロンプトとネガティブプロンプトを修正します。
- 必要に応じて、KSamplerノードのデノイズ(デノイズ強度)を調整します。
- Queue Promptを押して生成を開始します。
より高品質なComfyUIワークフローについては、🌟ComfyUIワークフローリスト🌟をご覧ください。
4. ComfyUI SDXL 🚀
極端な設定可能性のおかげで、ComfyUIはStable Diffusion XLモデルをサポートする最初のGUIの1つとなっています。試してみましょう!
ComfyUI SDXLワークフローを使用するには:
- ポジティブプロンプトとネガティブプロンプトを修正します。
- Queue Promptを押して生成を開始します。
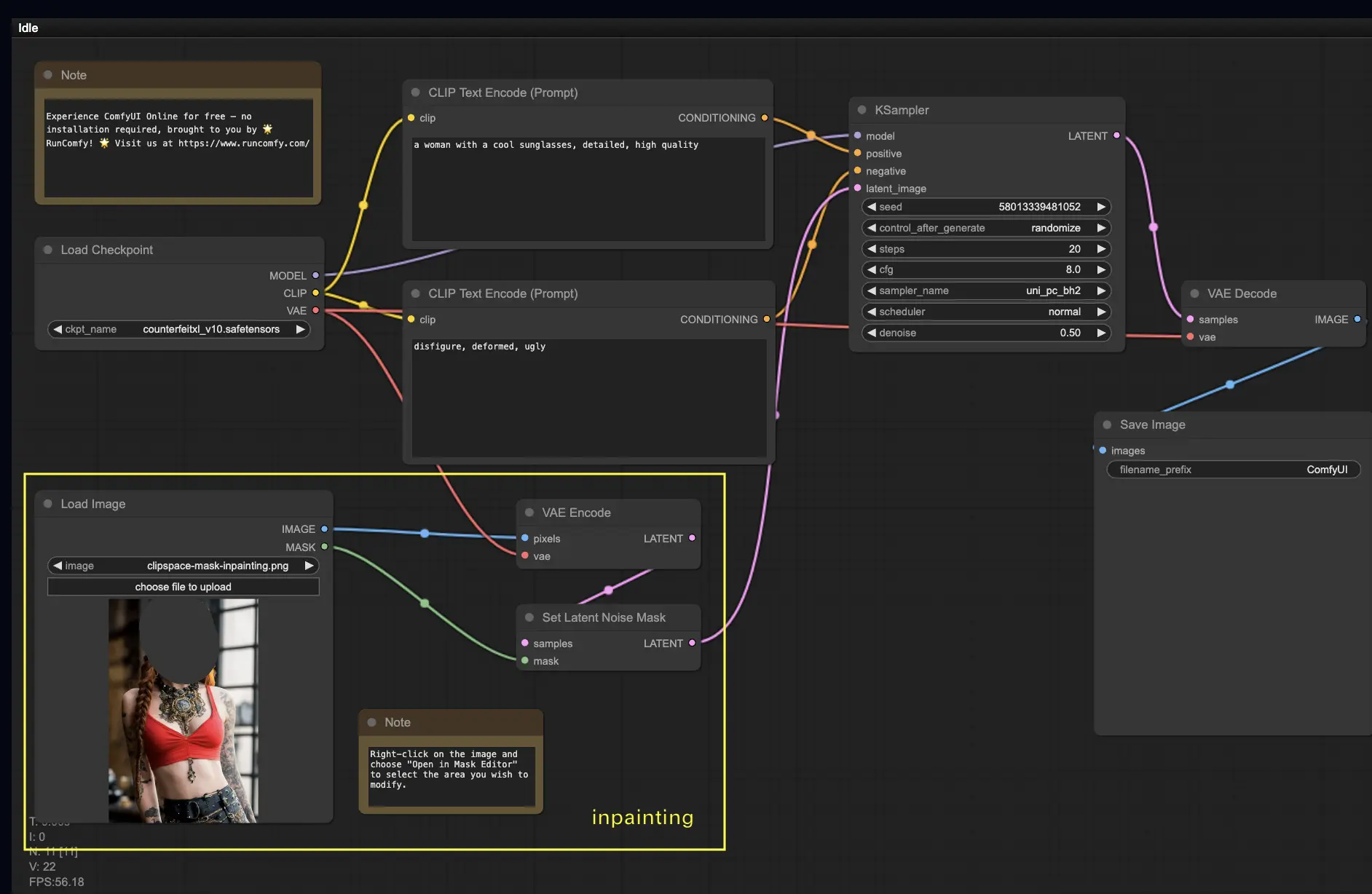
5. ComfyUI Inpainting 🎨
もっと複雑なことに飛び込んでみましょう:インペインティング!素晴らしい画像があるけれど特定の部分を修正したいときは、インペインティングが最良の方法です。ここで試してみてください!
インペインティングワークフローを使用するには:
- インペインティングしたい画像をアップロードします。
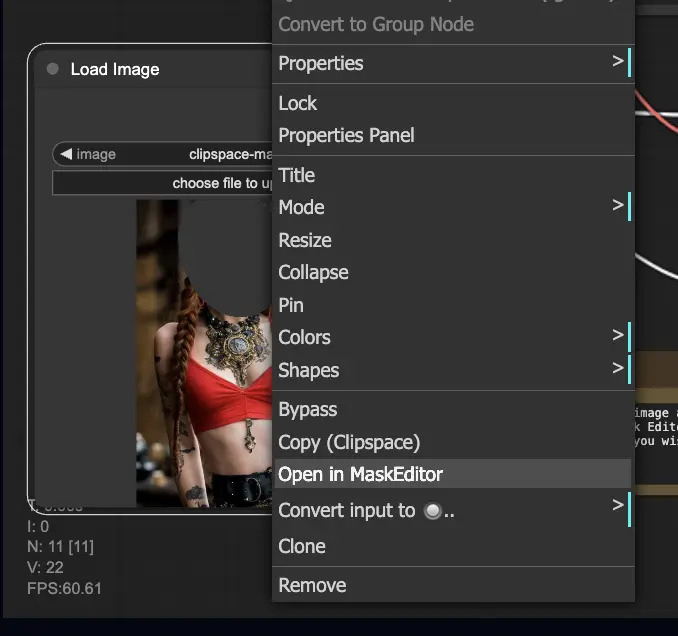
- 画像を右クリックして「MaskEditorで開く」を選択します。再生成したい領域をマスクし、「Save to node」をクリックします。
- チェックポイントモデルを選択します:
- このワークフローは、標準のStable Diffusionモデルでのみ動作し、インペインティングモデルでは動作しません。
- インペインティングモデルを利用したい場合は、"VAE Encode" と "Set Noise Latent Mask" ノードを、インペインティングモデル専用の "VAE Encode (Inpaint)" ノードに切り替えてください。
- インペインティング プロセスをカスタマイズします:
- CLIP Text Encode (Prompt) ノードで、インペインティングのガイドとなる追加情報を入力できます。例えば、インペインティング領域に含めたいスタイル、テーマ、要素を指定できます。
- 元のデノイジング強度(デノイズ)を設定します(例:0.6)。
- Queue Promptを押してインペインティングを実行します。
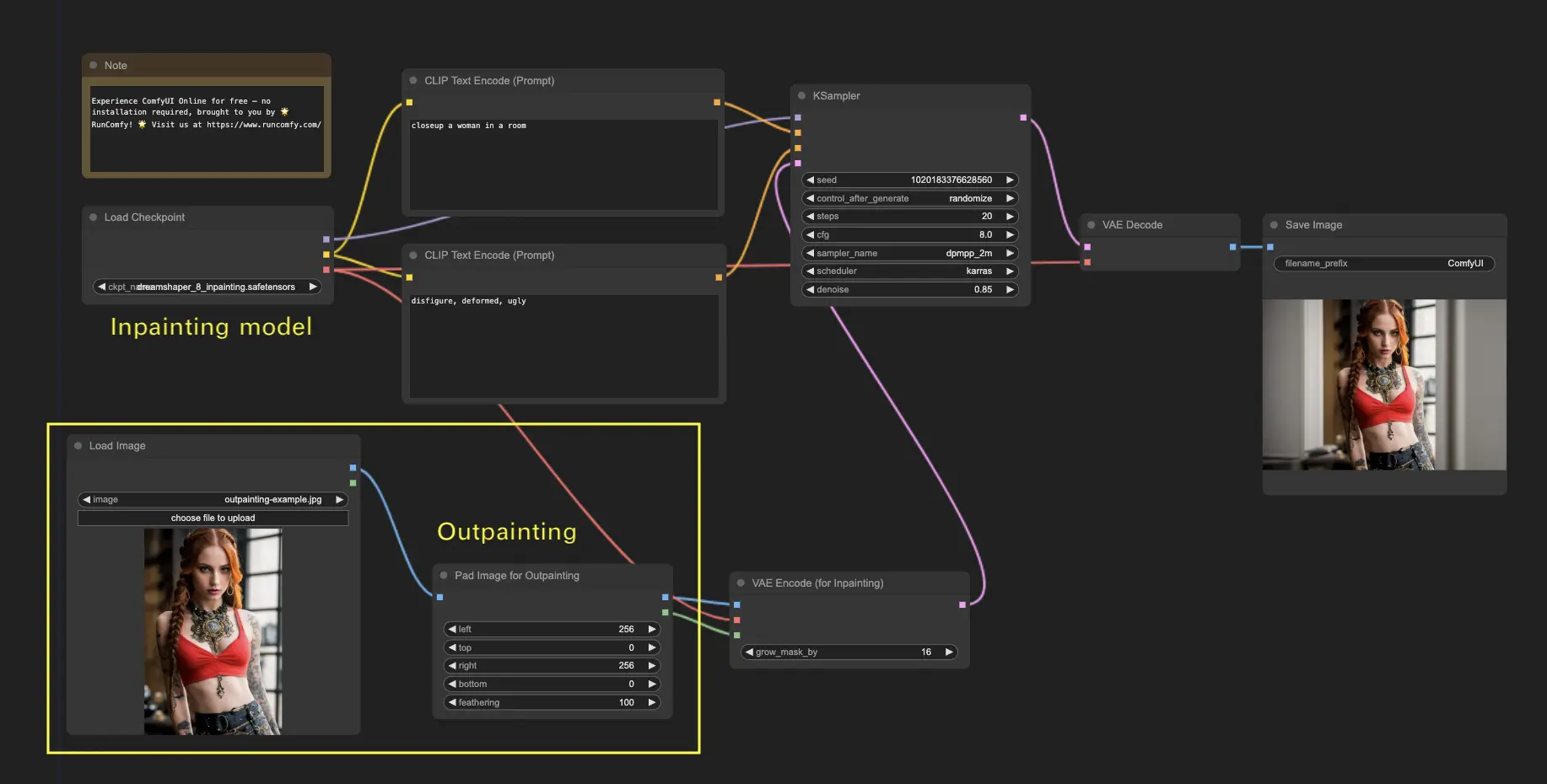
6. ComfyUI Outpainting 🖌️
アウトペインティングは、画像を元の境界を越えて拡張できるもう一つのエキサイティングな手法です。🌆 まるで無限のキャンバスで作業しているようなものです!
ComfyUI Outpaintingワークフローを使用するには:
- 拡張したい画像から始めます。
- Pad Image for Outpaintingノードをワークフローに追加します。
- アウトペインティングの設定を行います:
- left、top、right、bottom:各方向に拡張するピクセル数を指定します。
- feathering:元の画像とアウトペインティングされた領域の間の移行のスムーズさを調整します。値が高いほどよりグラデーションがかかった境界になりますが、ぼかし効果が生じる可能性があります。
- アウトペインティングプロセスをカスタマイズします:
- CLIP Text Encode (Prompt) ノードで、アウトペインティングのガイドとなる追加情報を入力できます。例えば、拡張領域に含めたいスタイル、テーマ、要素を指定できます。
- 異なるプロンプトを試して、目的の結果を得てください。
- VAE Encode (for Inpainting) ノードを微調整します:
- grow_mask_byパラメータを調整して、アウトペインティングマスクのサイズを制御します。最適な結果を得るには、10より大きい値をお勧めします。
- Queue Promptを押してアウトペインティングプロセスを開始します。
より高品質なインペインティング/アウトペインティングワークフローについては、🌟ComfyUIワークフローリスト🌟をご覧ください。
7. ComfyUI Upscale ⬆️
次に、ComfyUIアップスケールを探求しましょう。効率的にアップスケールするための3つの基本的なワークフローを紹介します。
アップスケールには2つの主な方法があります:
- Upscale pixel:可視画像を直接アップスケールする。
- 入力:画像、出力:アップスケールされた画像
- Upscale latent:非可視の潜在空間の画像をアップスケールする。
- 入力:潜在表現、出力:アップスケールされた潜在表現(可視画像になるにはデコードが必要)
7.1. Upscale Pixel 🖼️
これを実現するには2つの方法があります:
- アルゴリズムを使用:生成速度は最も速いが、モデルを使用した結果と比べてやや劣る。
- モデルを使用:より良い結果が得られるが、生成時間が長くなる。
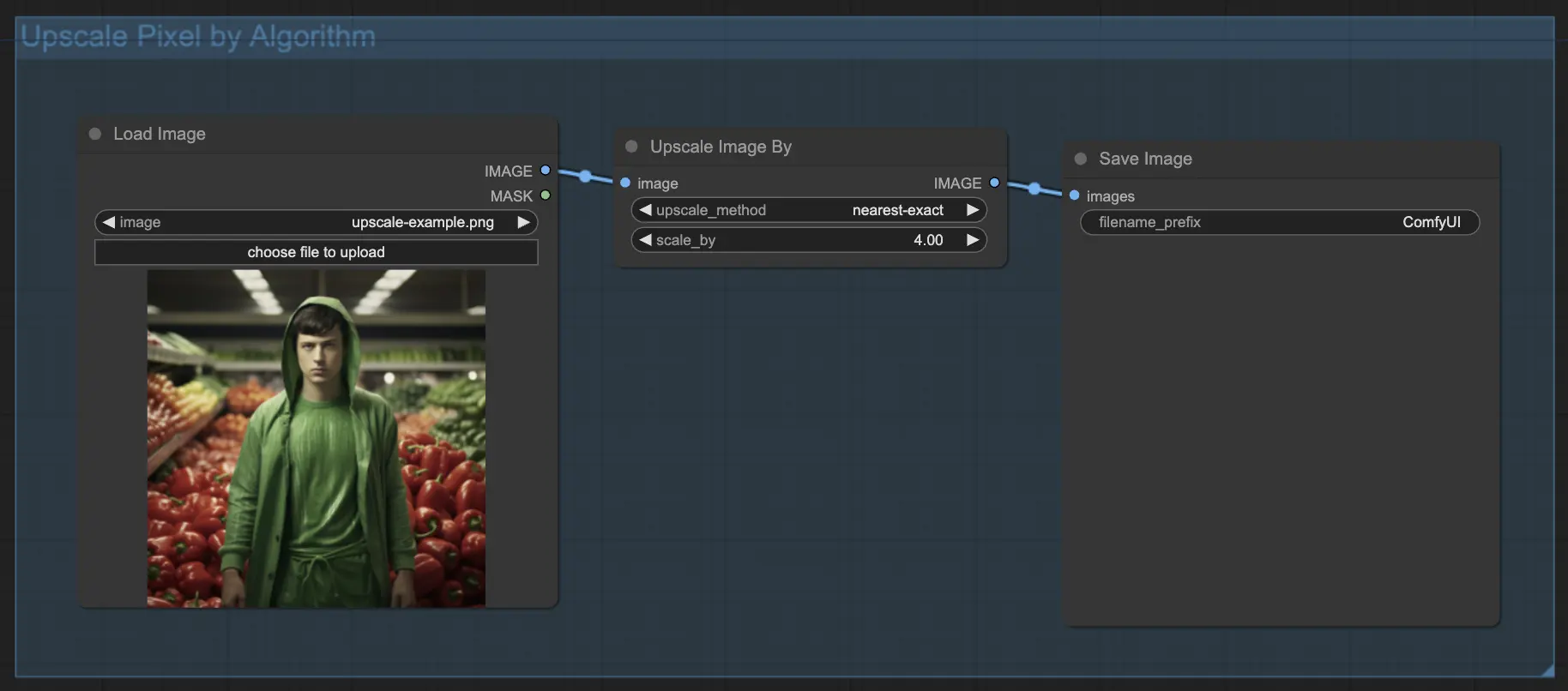
7.1.1. アルゴリズムによるUpscale Pixel 🧮
- Upscale Image byノードを追加。
- methodパラメータ:アップスケールアルゴリズムを選択(bicubic、bilinear、nearest-exact)。
- Scaleパラメータ:アップスケール率を指定(例:2xの場合は2)。
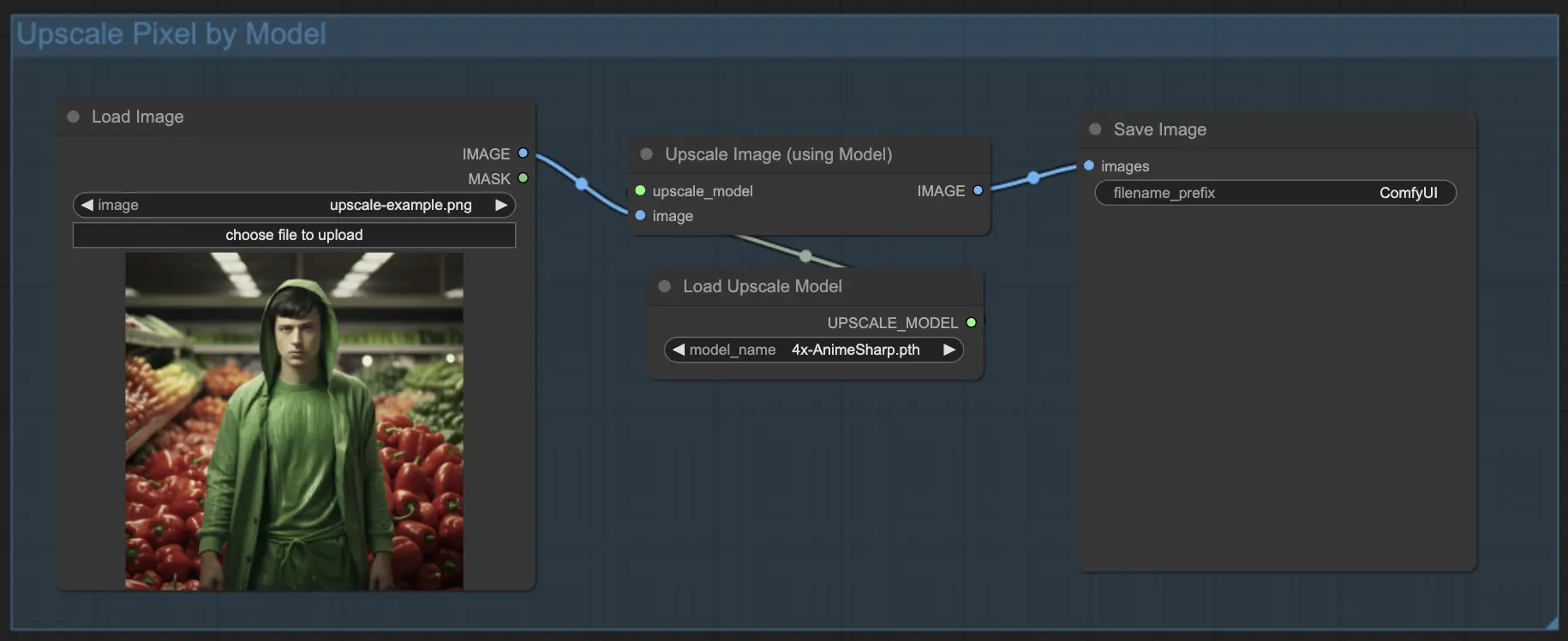
7.1.2. モデルによるUpscale Pixel 🤖
- Upscale Image (using Model) ノードを追加。
- Load Upscale Modelノードを追加。
- 画像の種類(アニメや実写など)に適したモデルを選択。
- アップスケール率(X2またはX4)を選択。
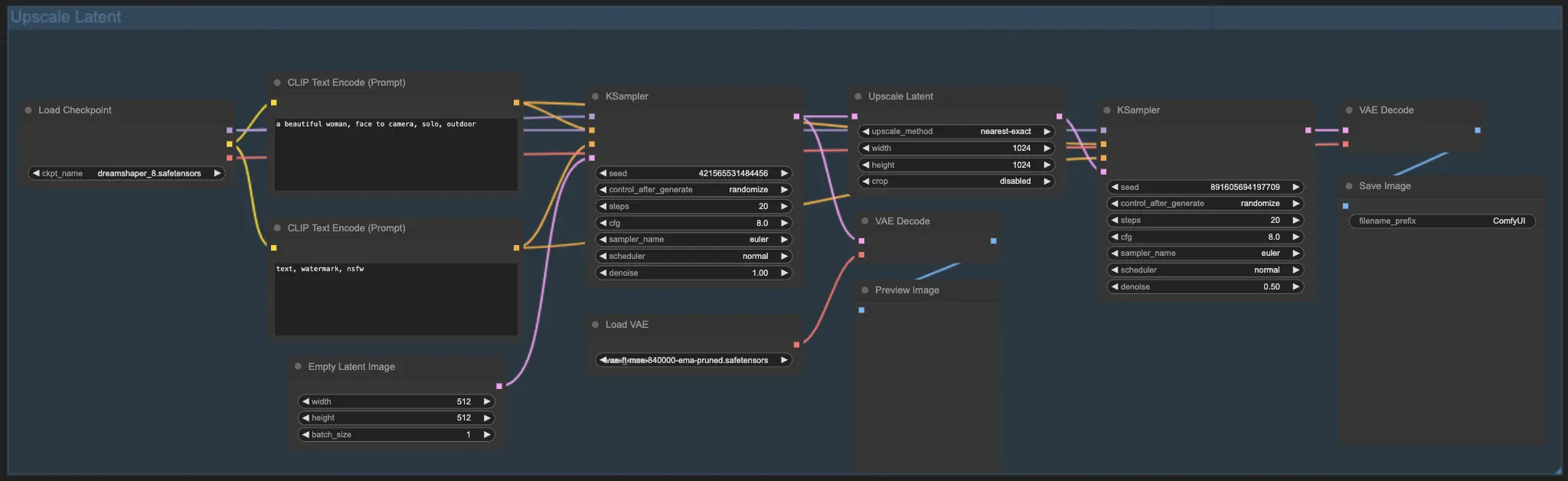
7.2. Upscale Latent ⚙️
もう一つのアップスケール方法は、Upscale Latent(Hi-res Latent Fix Upscaleとも呼ばれる)で、潜在空間で直接アップスケールを行います。
7.3. Upscale Pixel vs. Upscale Latent 🆚
- Upscale Pixel:新しい情報を追加せずに画像を拡大するだけ。生成は速いが、ぼかし効果が出て詳細が不足する可能性がある。
- Upscale Latent:拡大に加えて、元の画像情報の一部を変更し、詳細を豊かにする。元の画像から逸脱する可能性があり、生成速度が遅い。
より高品質なリストア/アップスケールワークフローについては、🌟ComfyUIワークフローリスト🌟をご覧ください。
8. ComfyUI ControlNet 🎮
ControlNetで、AIアートを次のレベルに引き上げる準備をしましょう。ControlNetは、画像生成に革命をもたらすゲームチェンジャー的テクノロジーです!
ControlNetは、AI生成画像を前例のないレベルで制御できる魔法の杖のようなものです。🪄 Stable Diffusionのような強力なモデルと連携して、その能力を強化し、これまでにないほど画像作成プロセスをガイドできるようになります!
目的の画像のエッジ、人物のポーズ、深度、さらにはセグメンテーションマップまで指定できることを想像してみてください。🌠 ControlNetを使えば、それが可能なのです!
ControlNetの世界に深く飛び込み、その可能性を最大限に引き出したい方のために、詳細なチュートリアル「ComfyUIでControlNetをマスターする!」📚を用意しました。ステップバイステップのガイドと刺激的な例が満載で、ControlNetのプロになるためのヒントが詰まっています。🏆
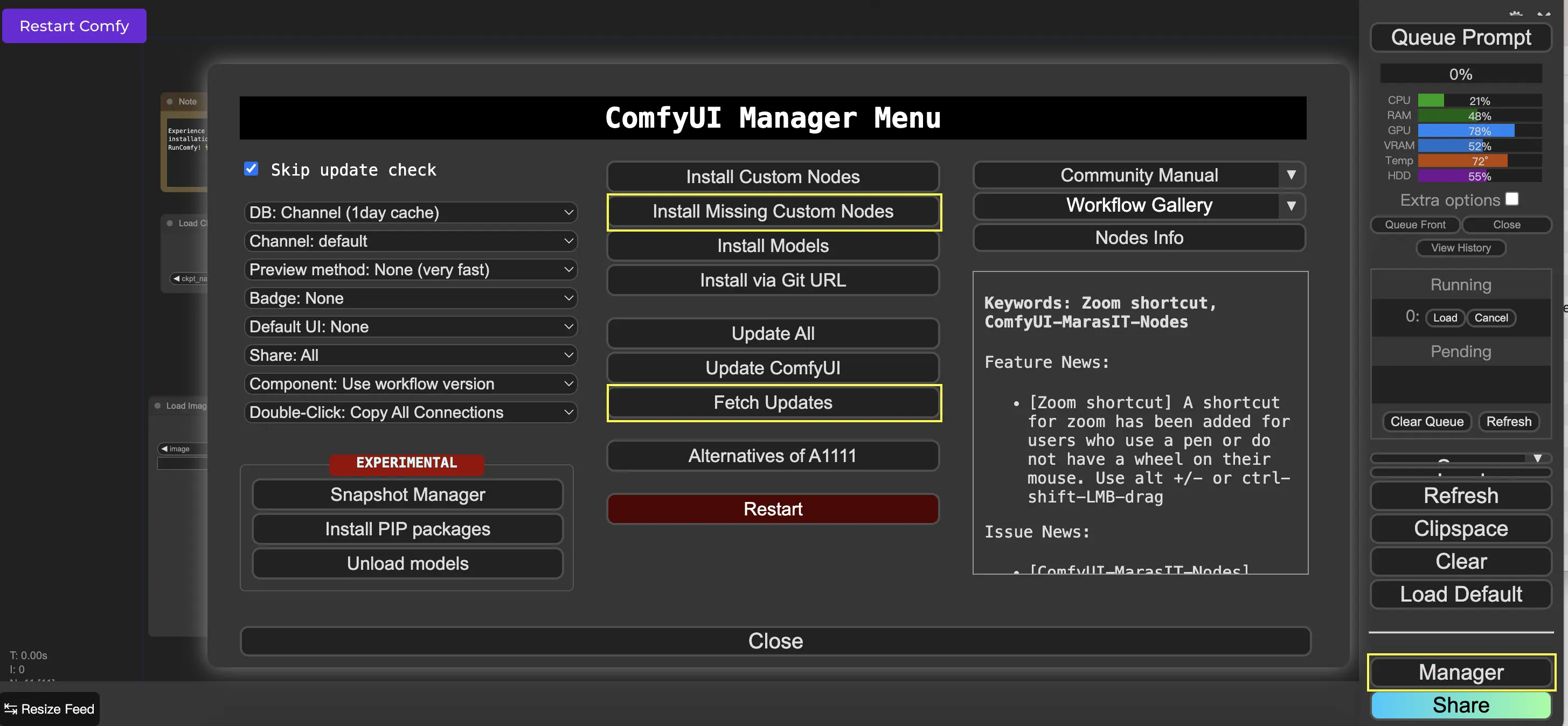
9. ComfyUI Manager 🛠️
ComfyUI Managerは、ComfyUIのインターフェースを通じて他のカスタムノードのインストールや更新を可能にするカスタムノードです。Queue Promptメニューに、Managerボタンがあります。
9.1. 不足しているカスタムノードのインストール方法 📥
ワークフローが必要とするカスタムノードがインストールされていない場合は、次の手順に従います:
- メニューのManagerをクリックします。
- Install Missing Custom Nodesをクリックします。
- ComfyUIを完全に再起動します。
- ブラウザをリフレッシュします。
9.2. カスタムノードの更新方法 🔄
- メニューのManagerをクリックします。
- Fetch Updates(しばらく時間がかかる場合があります)をクリックします。
- Install Custom Nodesをクリックします。
- 更新が利用可能な場合、インストール済みのカスタムノードの横にUpdateボタンが表示されます。
- Updateをクリックしてノードを更新します。
- ComfyUIを再起動します。
- ブラウザをリフレッシュします。
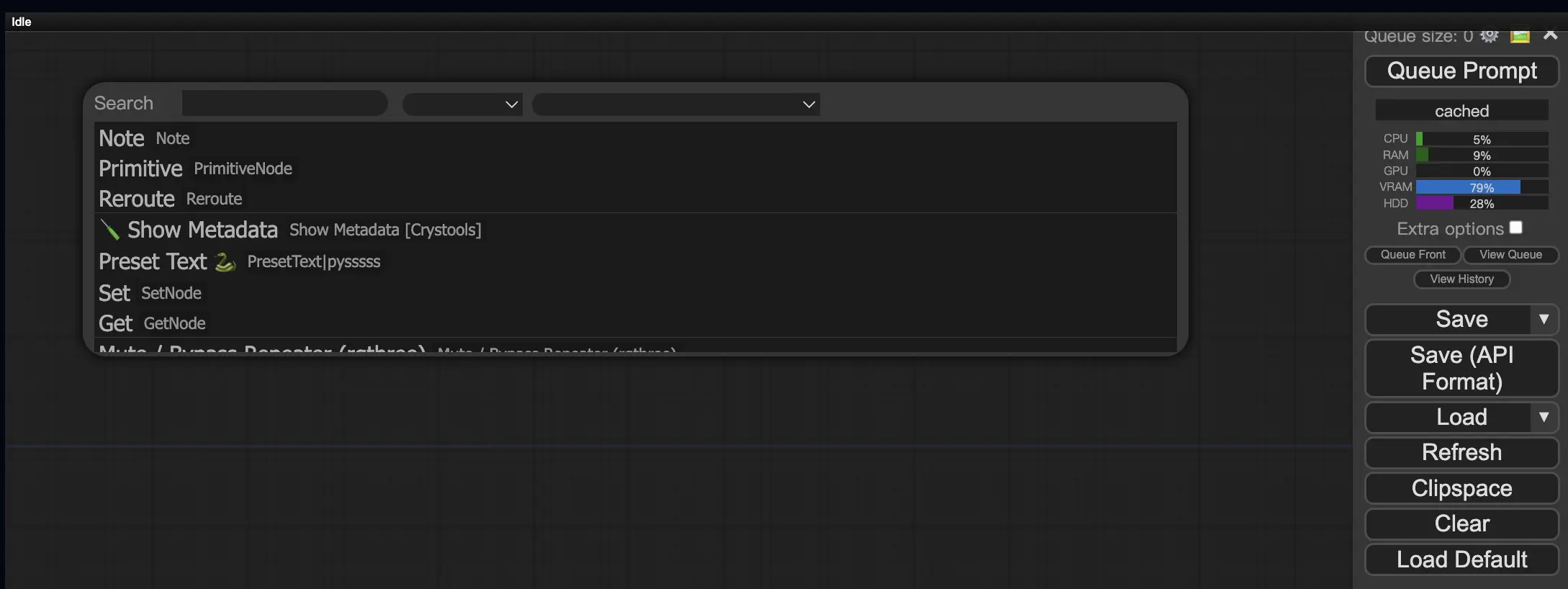
9.3. ワークフローにカスタムノードを読み込む方法 🔍
任意の空のエリアをダブルクリックすると、ノードを検索するメニューが表示されます。
10. ComfyUI Embeddings 📝
Embeddings(テキスト反転とも呼ばれる)は、ComfyUIの強力な機能で、カスタムの概念やスタイルをAI生成画像に注入できます。💡 まるでAIに新しい単語やフレーズを教え、それを特定のビジュアル特性と関連付けるようなものです。
ComfyUIでEmbeddingsを使用するには、ポジティブまたはネガティブのプロンプトボックスに"embedding:"に続いてEmbeddingの名前を入力するだけです。例えば:
embedding: BadDream
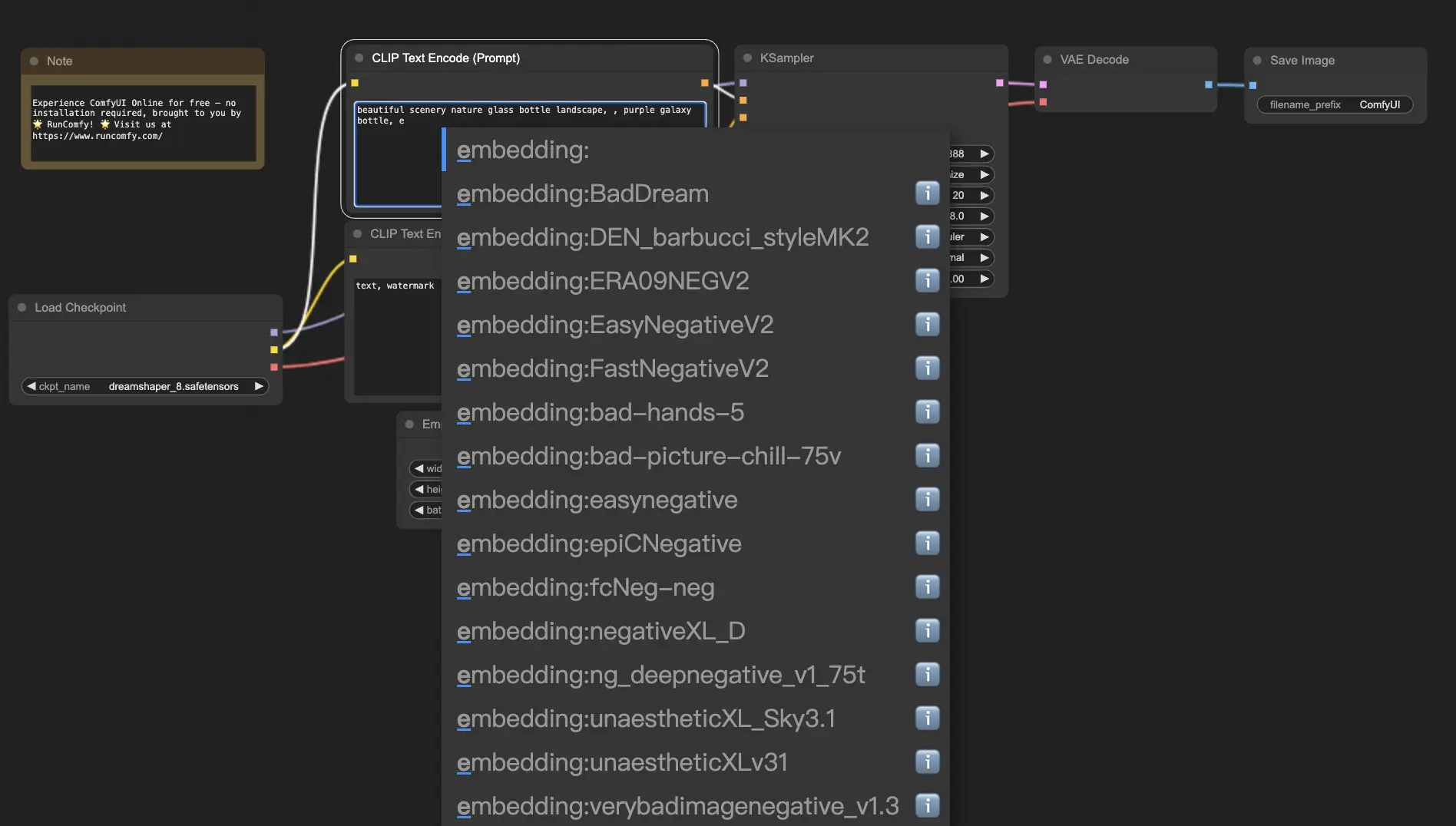
このプロンプトを使用すると、ComfyUIはComfyUI > models > embeddingsフォルダで"BadDream"という名前のEmbeddingファイルを検索します。📂 一致するものが見つかった場合、対応するビジュアル特性を生成された画像に適用します。
Embeddingsは、AIアートをパーソナライズし、特定のスタイルや美的感覚を実現するのに最適な方法です。🎨 目的の概念やスタイルを表す一連の画像でトレーニングすることで、独自のEmbeddingsを作成できます。
10.1. オートコンプリート機能付きのEmbedding 🔠
Embeddingsの正確な名前を覚えているのは面倒です。特に、たくさんのコレクションを持っている場合は大変です。😅 そこで、ComfyUI-Custom-Scriptsカスタムノードが救世主となります!
Embedding名のオートコンプリートを有効にするには:
- トップメニューの「Manager」をクリックして、ComfyUI Managerを開きます。
- 「Install Custom nodes」に進み、「ComfyUI-Custom-Scripts」を検索します。
- 「Install」をクリックして、カスタムノードをComfyUIセットアップに追加します。
- 変更を適用するためにComfyUIを再起動します。
ComfyUI-Custom-Scriptsノードをインストールすると、Embeddingsをより使いやすくなります。😊 プロンプトボックスで"embedding:"と入力し始めるだけで、利用可能なEmbeddingsのリストが表示されます。リストから目的のEmbeddingを選択できるので、時間と手間が省けます!
10.2. Embeddingの重み付け ⚖️
Embeddingsの強さを制御できることをご存知でしたか?💪 Embeddingsは本質的にキーワードなので、プロンプト内の通常のキーワードと同じように重みを適用できます。
Embeddingの重みを調整するには、次の構文を使用します:
(embedding: BadDream:1.2)
この例では、"BadDream" Embeddingの重みが20%増加しています。つまり、重みが高いほど(例:1.2)Embeddingがより目立つようになり、重みが低いほど(例:0.8)その影響が減少します。🎚️ これにより、最終的な結果をさらに細かく制御できます!
11. ComfyUI LoRA 🧩
LoRA(Low-rank Adaptation)は、ComfyUIのもう一つのエキサイティングな機能で、チェックポイントモデルの変更と微調整を可能にします。🎨 ベースモデルの上に小さな専門モデルを追加して、特定のスタイルを実現したり、カスタム要素を組み込んだりするようなものです。
LoRAモデルはコンパクトで効率的なので、使いやすく共有しやすいです。画像の芸術的スタイルを変更したり、特定の人物やオブジェクトを生成結果に注入したりするのによく使われます。
LoRAモデルをチェックポイントモデルに適用すると、VAE(Variational Autoencoder)はそのままに、MODELとCLIPコンポーネントが変更されます。つまり、LoRAは画像の全体的な構造を変えずに、内容とスタイルの調整に重点を置いているのです。
11.1. LoRAの使い方 🔧
ComfyUIでLoRAを使うのは簡単です。最もシンプルな方法を見てみましょう:
- 画像生成のベースとなるチェックポイントモデルを選択します。
- スタイルを変更したり、特定の要素を注入したりするために適用したいLoRAモデルを選びます。
- 画像生成プロセスを導くために、ポジティブプロンプトとネガティブプロンプトを修正します。
- 「Queue Prompt」をクリックして、適用されたLoRAで画像の生成を開始します。▶
すると、ComfyUIはチェックポイントモデルとLoRAモデルを組み合わせて、指定されたプロンプトを反映し、LoRAが導入した変更を組み込んだ画像を作成します。
11.2. 複数のLoRA 🧩🧩
では、1つの画像に複数のLoRAを適用したい場合はどうでしょうか?問題ありません!ComfyUIでは、同じText-to-Imageワークフローで2つ以上のLoRAを使用できます。
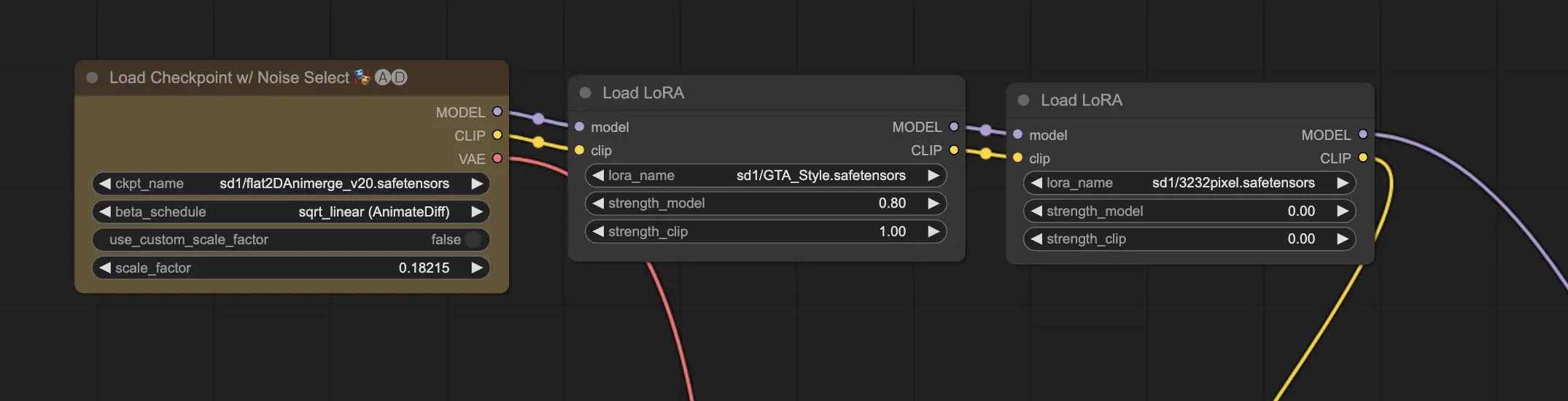
プロセスは単一のLoRAを使用する場合と似ていますが、1つではなく複数のLoRAモデルを選択する必要があります。ComfyUIは、LoRAを順番に適用します。つまり、各LoRAは前のLoRAが導入した変更に基づいて構築されていきます。
これにより、AIで生成された画像に異なるスタイル、要素、変更を組み合わせる無限の可能性が開けます。🌍💡 さまざまなLoRAの組み合わせを試して、ユニークでクリエイティブな結果を生み出しましょう!
12. ComfyUIのショートカットとコツ ⌨️🖱️
12.1. コピー&ペースト 📋
- ノードを選択してCtrl+Cを押すとコピーされます。
- Ctrl+Vを押すと貼り付けられます。
- Ctrl+Shift+Vを押すと、入力接続を保持したまま貼り付けられます。
12.2. 複数ノードの移動 🖱️
- グループを作成すると、ノードのセットをまとめて移動できます。
- または、Ctrlキーを押しながらドラッグしてボックスを作成し、複数のノードを選択するか、Ctrlキーを押しながら個別に複数のノードを選択します。
- 選択したノードを移動するには、Shiftキーを押しながらマウスを移動します。
12.3. ノードをバイパスする 🔇
- ノードをミュートすることで一時的に無効にできます。ノードを選択してCtrl+Mを押します。
- グループをミュートするためのキーボードショートカットはありません。右クリックメニューでBypass Group Nodeを選択するか、グループの最初のノードをミュートして無効にします。
12.4. ノードを最小化する 🔍
- ノードの左上隅にある点をクリックすると最小化されます。
12.5. 画像生成 ▶️
- Ctrl+Enterを押すと、ワークフローがキューに入り、画像が生成されます。
12.6. 埋め込みワークフロー 🖼️
- ComfyUIは、生成したPNGファイルのメタデータに完全なワークフローを保存します。ワークフローを読み込むには、画像をComfyUIにドラッグ&ドロップします。
12.7. シードを固定して時間を節約 ⏰
- ComfyUIは、入力が変更された場合にのみノードを再実行します。長いノードチェーンを扱う際は、シードを固定して上流の結果を再生成しないようにすることで時間を節約できます。
13. ComfyUIオンライン 🚀
ComfyUI初心者向けガイドを完了おめでとうございます!🙌 これで、AIアート制作の刺激的な世界に飛び込む準備が整いました。でも、インストールに手間取るくらいなら、すぐに制作を始めたいですよね?🤔
RunComfyなら、セットアップなしでComfyUIをオンラインで使えるようにしました。ComfyUI Onlineサービスには、200以上の人気ノードとモデルがプリロードされており、制作のインスピレーションを得られる50以上の素晴らしいワークフローも用意されています。
🌟 初心者からベテランのAIアーティストまで、RunComfyにはあなたの芸術的ビジョンを実現するために必要なものがすべて揃っています。💡 もう待たないでください。今すぐComfyUI Onlineを試す と、AIアート制作のパワーをその指先で体験できます!🚀