오디오 반응형 마스크 확장 | 놀라운 애니메이션
이 ComfyUI 오디오 반응형 마스크 확장 워크플로우는 비디오 주제를 창의적으로 변형할 수 있게 해줍니다. 이는 개인 또는 그룹 공연자에게 음악의 리듬에 완벽하게 동기화된 동적이고 반응적인 아우라로 둘러싸는 기능을 제공합니다. 이 효과는 비디오에 매혹적인 시각적 차원을 추가하여 전체적인 임팩트와 참여도를 높입니다.ComfyUI Audioreactive Mask Dilation 워크플로우

이 워크플로우를 실행하고 싶으신가요?
- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
ComfyUI Audioreactive Mask Dilation 예제
ComfyUI Audioreactive Mask Dilation 설명
주제(예: 댄서)를 리듬에 맞춰 확장되고 수축되는 동적 아우라로 변형하여 놀라운 비디오 애니메이션을 만드세요. 이 워크플로우를 단일 주제 또는 예제에서 볼 수 있는 여러 주제와 함께 사용하세요.
오디오 반응형 마스크 확장 워크플로우 사용 방법:
- 입력 섹션에서 주제 비디오 업로드
- 최종 비디오의 원하는 너비와 높이, 'every_nth'로 건너뛸 입력 비디오 프레임 수를 선택하세요. 'frame_load_cap'으로 렌더링할 총 프레임 수를 제한할 수도 있습니다.
- 긍정 및 부정 프롬프트를 작성하세요. 장면 전환이 발생할 때를 일치시키기 위해 배치 프레임 시간을 설정하세요.
- 각 기본 IP 어댑터 주제 마스크 색상에 대한 이미지를 업로드하세요:
- 빨강 = 주제(댄서)
- 검정 = 배경
- 흰색 = 흰색 오디오 반응형 확장 마스크
- '모델' 섹션에서 적절한 LCM 체크포인트를 로드하세요(저는 Machine Delusions의 ParadigmLCM을 사용합니다).
- 모델 로더 아래의 로라 스태커를 사용하여 로라를 추가하세요
- 큐 프롬프트를 클릭하세요
입력
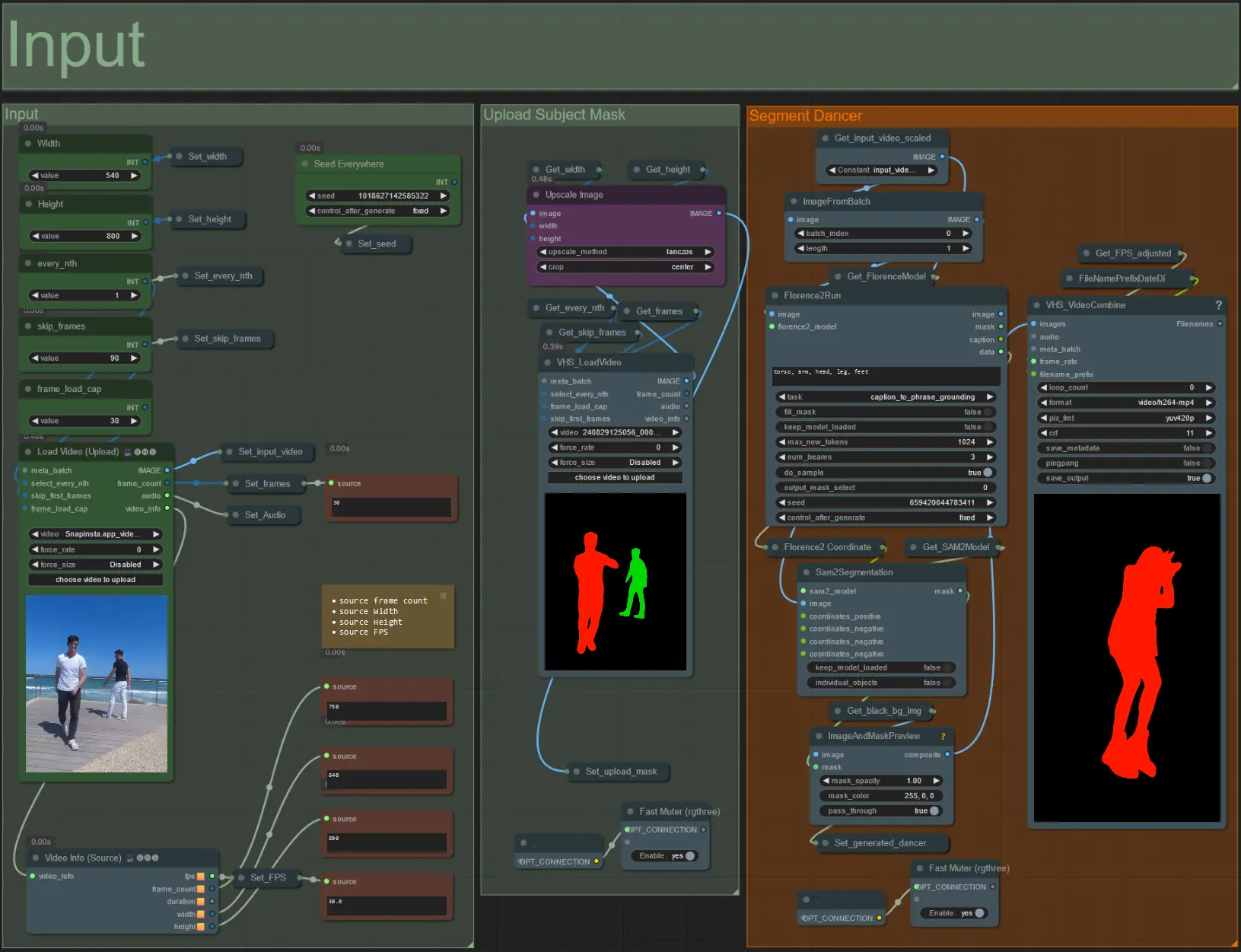
- Load Video (Upload) 노드에 원하는 주제 비디오를 업로드하세요.
- 왼쪽 상단의 두 입력을 사용하여 출력 너비와 높이를 조정하세요.
- every_nth는 매 프레임, 매 두 번째 프레임 등을 사용할지 설정합니다(2 = 매 두 번째 프레임). 기본값은 1로 설정되어 있습니다.
- skip_frames는 비디오 시작 시 프레임을 건너뛰는 데 사용됩니다. (100 = 입력 비디오에서 처음 100 프레임 건너뛰기). 기본값은 0입니다.
- frame_load_cap는 입력 비디오에서 로드할 총 프레임 수를 지정하는 데 사용됩니다. 설정을 테스트할 때는 낮게 유지하는 것이 좋습니다(예: 30 - 60) 그런 다음 최종 비디오를 렌더링할 때는 증가시키거나 0(프레임 제한 없음)으로 설정하세요.
- 오른쪽 하단의 숫자 필드는 업로드된 입력 비디오에 대한 정보를 표시합니다: 총 프레임 수, 너비, 높이, FPS(위에서부터 아래로).
- 이미 생성된 주제 마스크 비디오가 있는 경우 'Upload Subject Mask' 섹션을 음소거 해제하고 마스크 비디오를 업로드하세요. 'Segment Dancer' 섹션을 음소거하여 처리 시간을 절약할 수 있습니다.
- 때때로 세그먼트된 주제가 완벽하지 않을 수 있으므로 위의 오른쪽 하단에 표시된 미리보기 상자를 사용하여 마스크 품질을 확인하세요. 그런 경우 'Florence2Run' 노드의 프롬프트를 사용하여 'head', 'chest', 'legs' 등 다른 신체 부위를 타겟팅하여 더 나은 결과를 얻을 수 있는지 확인하세요.
프롬프트
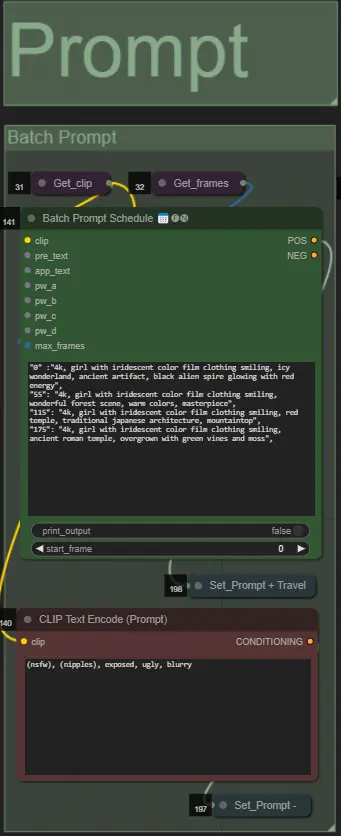
- 배치 형식을 사용하여 긍정 프롬프트를 설정하세요:
- 예: '0': '4k, 걸작, 해변에 서 있는 1 소녀, absurdres', '25': 'HDR, 일몰 장면, 검은 머리와 흰 재킷을 입은 1 소녀, absurdres', …
- 부정 프롬프트는 일반 형식으로, 원하는 경우 임베딩을 추가하세요.
오디오 처리
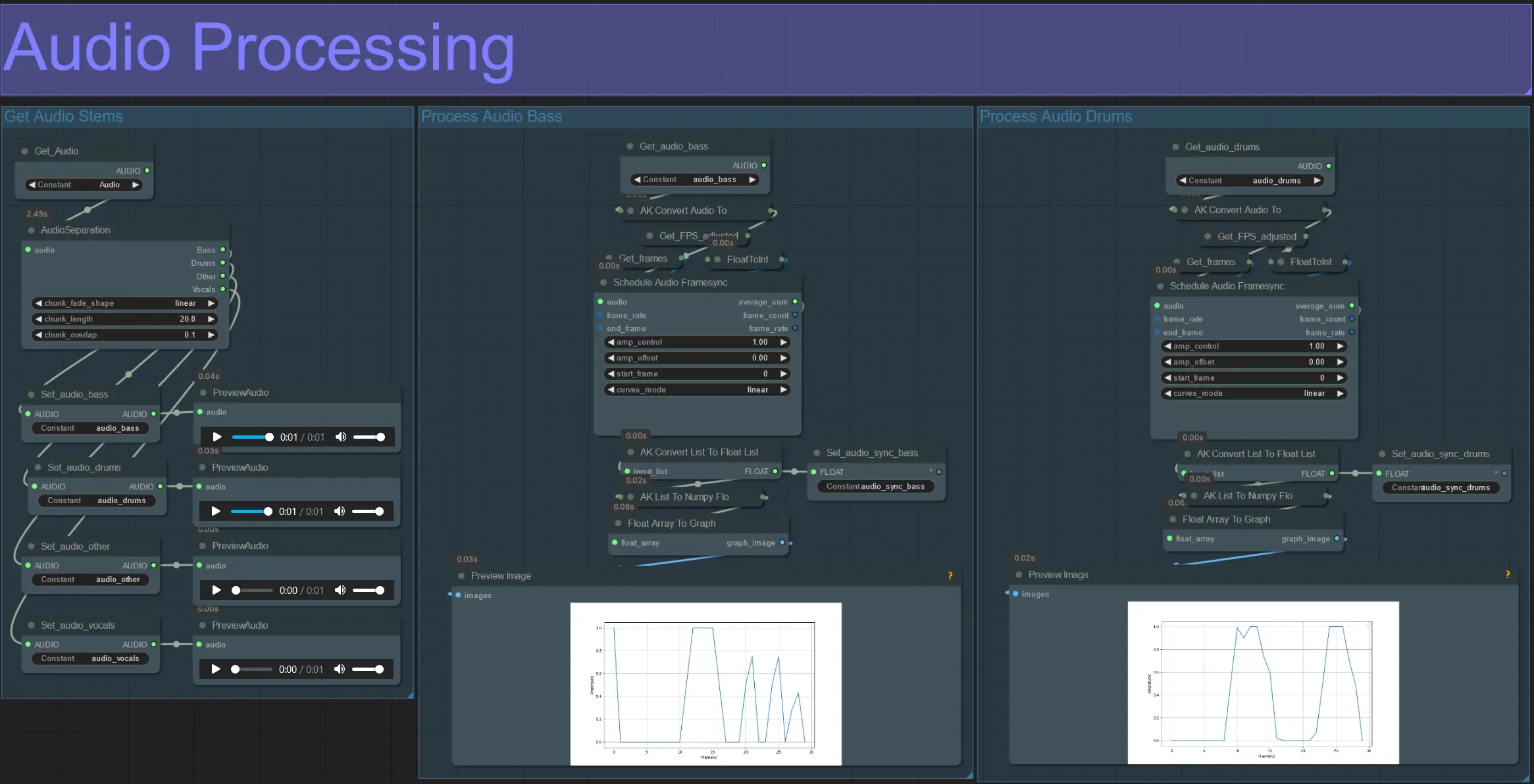
- 이 섹션은 입력 비디오에서 오디오를 가져와 스템(베이스, 드럼, 보컬 등)을 추출한 다음 입력 비디오 프레임과 동기화된 정규화된 진폭으로 변환합니다.
- amp_control = 진폭이 이동할 수 있는 전체 범위.
- amp_offset = 진폭이 가질 수 있는 최소 값.
- 예: amp_control = 0.8 및 amp_offset = 0.2는 신호가 0.2에서 1.0 사이에서 이동함을 의미합니다.
- 때때로 드럼 스템에는 노래의 실제 베이스 음이 포함될 수 있으므로 각 스템을 미리 보고 마스크에 가장 적합한 것을 결정하세요.
- 그래프를 사용하여 비디오의 전체 지속 시간 동안 해당 스템의 신호가 어떻게 변하는지 명확하게 이해하세요.
마스크 확장
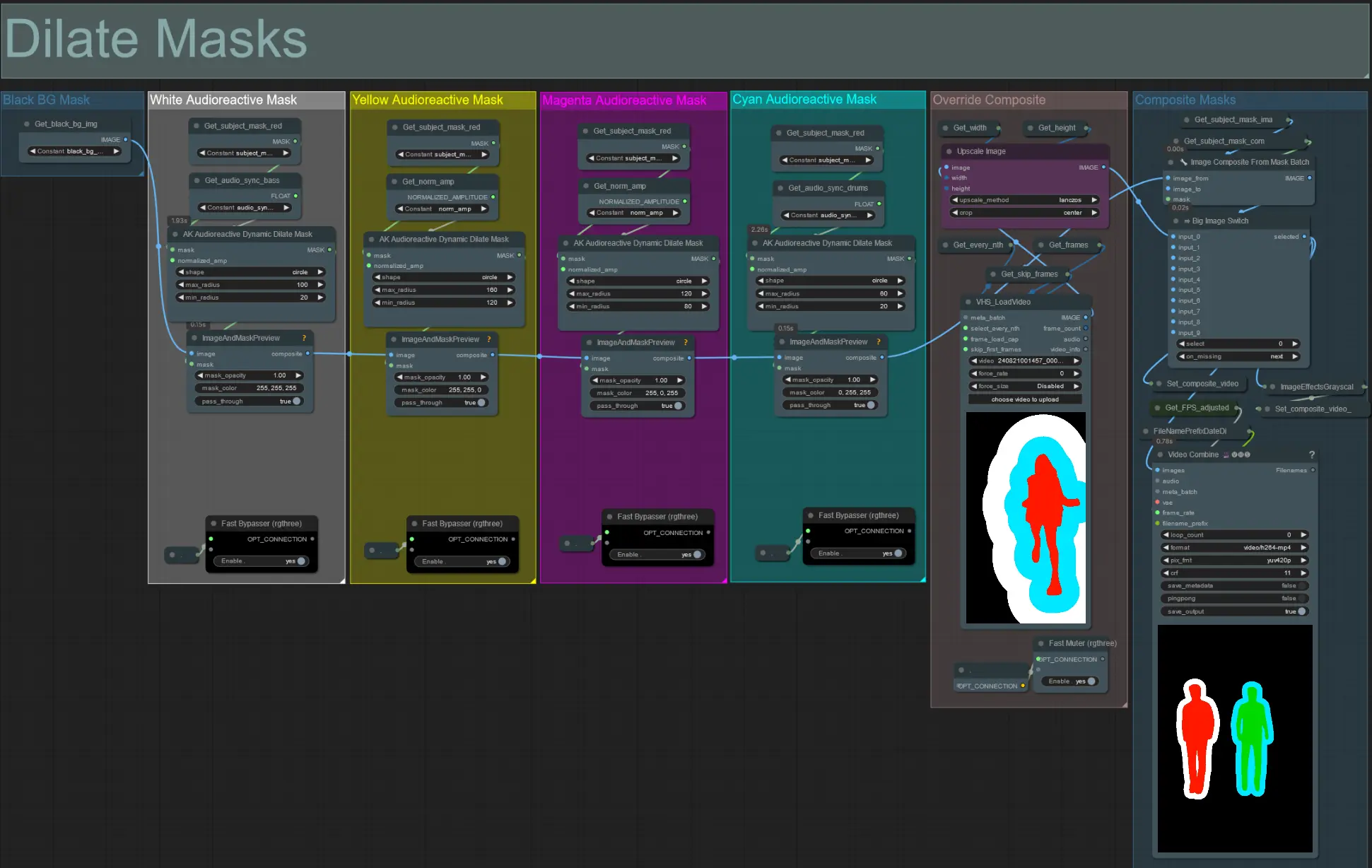
- 각 색상 그룹은 생성될 확장 마스크의 색상에 해당합니다.
- 다음 노드를 사용하여 확장 마스크의 최소 및 최대 반경과 모양을 설정하세요:
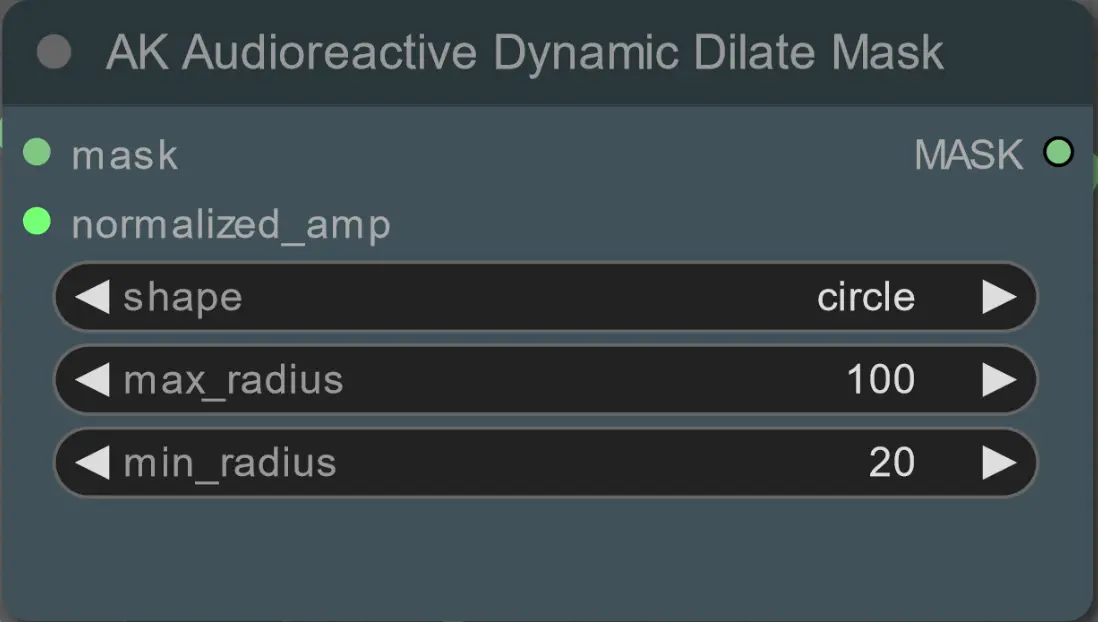
- shape: 'circle'은 가장 정확하지만 생성 시간이 더 오래 걸립니다. 최종 렌더링을 수행할 준비가 되었을 때 설정하세요. 'square'는 계산이 빠르지만 덜 정확하여 워크플로우를 테스트하고 IP 어댑터 이미지를 결정하는 데 가장 적합합니다.
- max_radius: 진폭 값이 최대(1.0)일 때 마스크 반경(픽셀 단위).
- min_radius: 진폭 값이 최소(0.0)일 때 마스크 반경(픽셀 단위).
- 이미 생성된 복합 마스크 비디오가 있는 경우 'Override Composite Mask' 그룹을 음소거 해제하고 업로드하세요. 처리 시간을 절약하기 위해 확장 마스크 그룹을 우회하는 것이 좋습니다.
모델
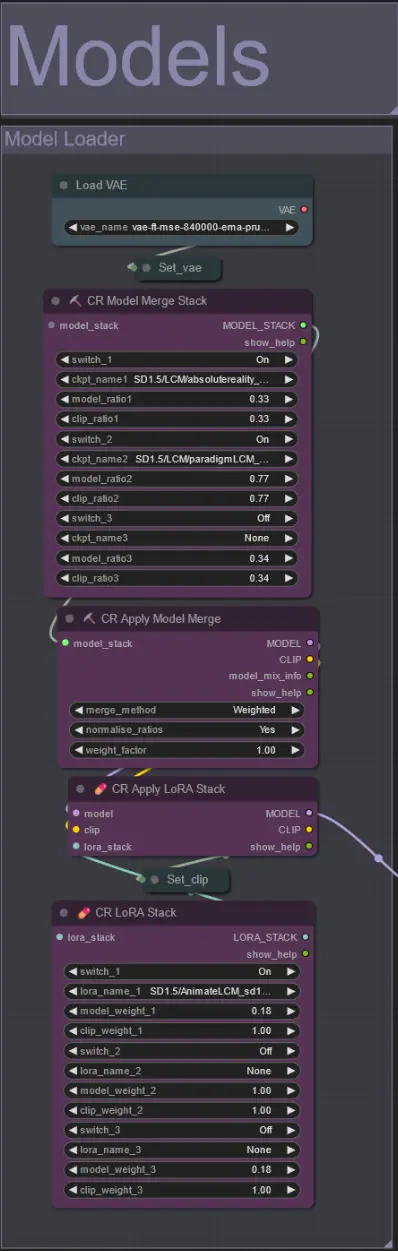
- 체크포인트에 좋은 LCM 모델을 사용하세요. Machine Delusions의 ParadigmLCM을 추천합니다.
- Model Merge Stack을 사용하여 여러 모델을 병합하여 다양한 흥미로운 효과를 얻으세요. 활성화된 모델의 가중치가 1.0이 되도록 하세요.
- 최종 결과를 더욱 향상시키기 위해 낮은 가중치(0.18)로 AnimateLCM_sd15_t2v_lora.safetensors를 지정할 수 있습니다.
- 모델 로더 아래의 로라 스태커를 사용하여 추가 로라를 모델에 추가하세요.
AnimateDiff

- 제가 사용한 것 대신 다른 Motion Lora를 설정하세요(LiquidAF-0-1.safetensors)
- 출력의 움직임 양을 증가/감소시키기 위해 Scale 및 Effect 플로트를 증가/감소시키세요.
IP 어댑터
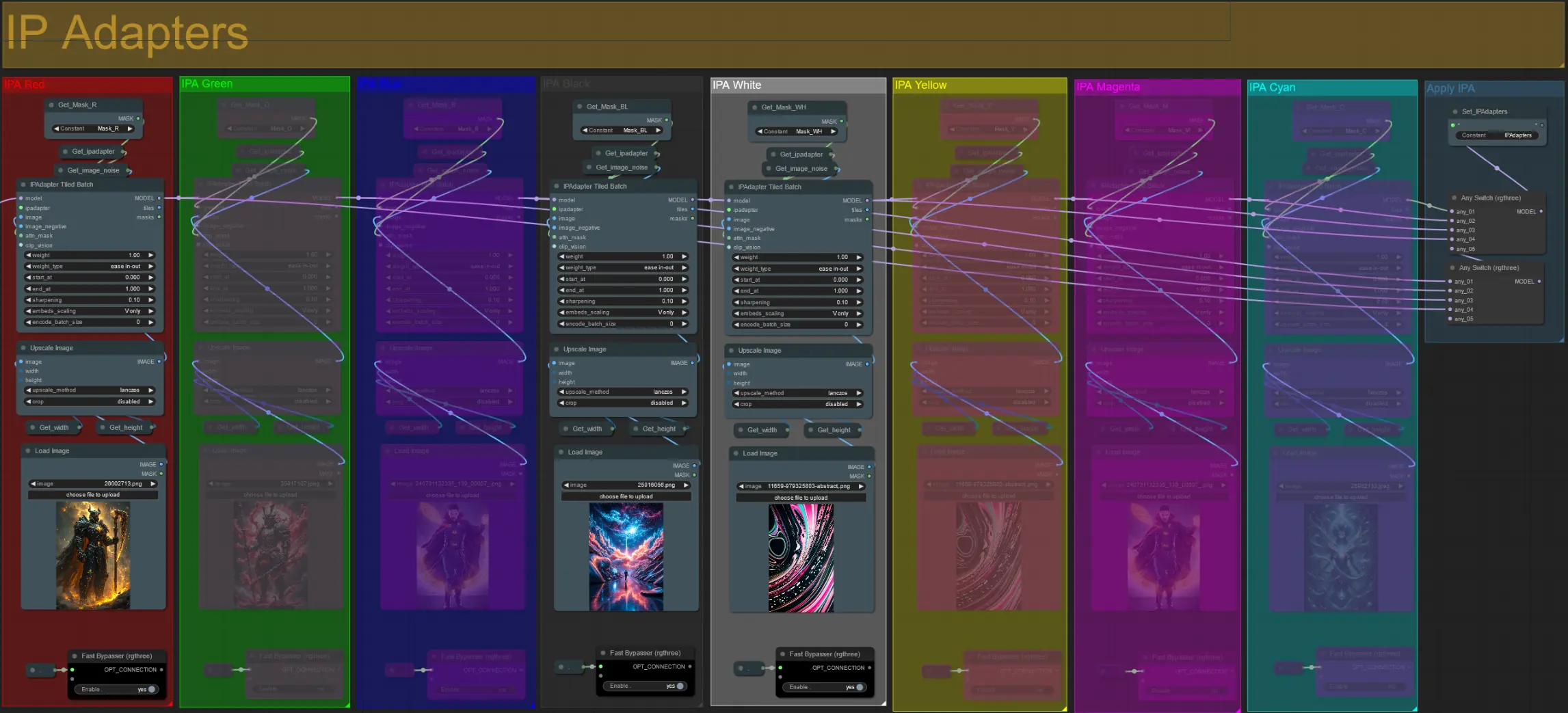
- 여기에서 각 확장 마스크와 비디오 주제를 렌더링하는 데 사용될 참조 이미지를 지정할 수 있습니다.
- 각 그룹의 색상은 대상 마스크를 나타냅니다:
빨강, 초록, 파랑:
- 주제 마스크 참조 이미지.
검정:
- 배경 마스크 이미지, 배경 참조 이미지를 업로드하세요.
흰색, 노랑, 마젠타, 시안:
- 확장 마스크 참조 이미지, 사용 중인 각 색상 확장 마스크에 대한 참조 이미지를 업로드하세요.
ControlNet
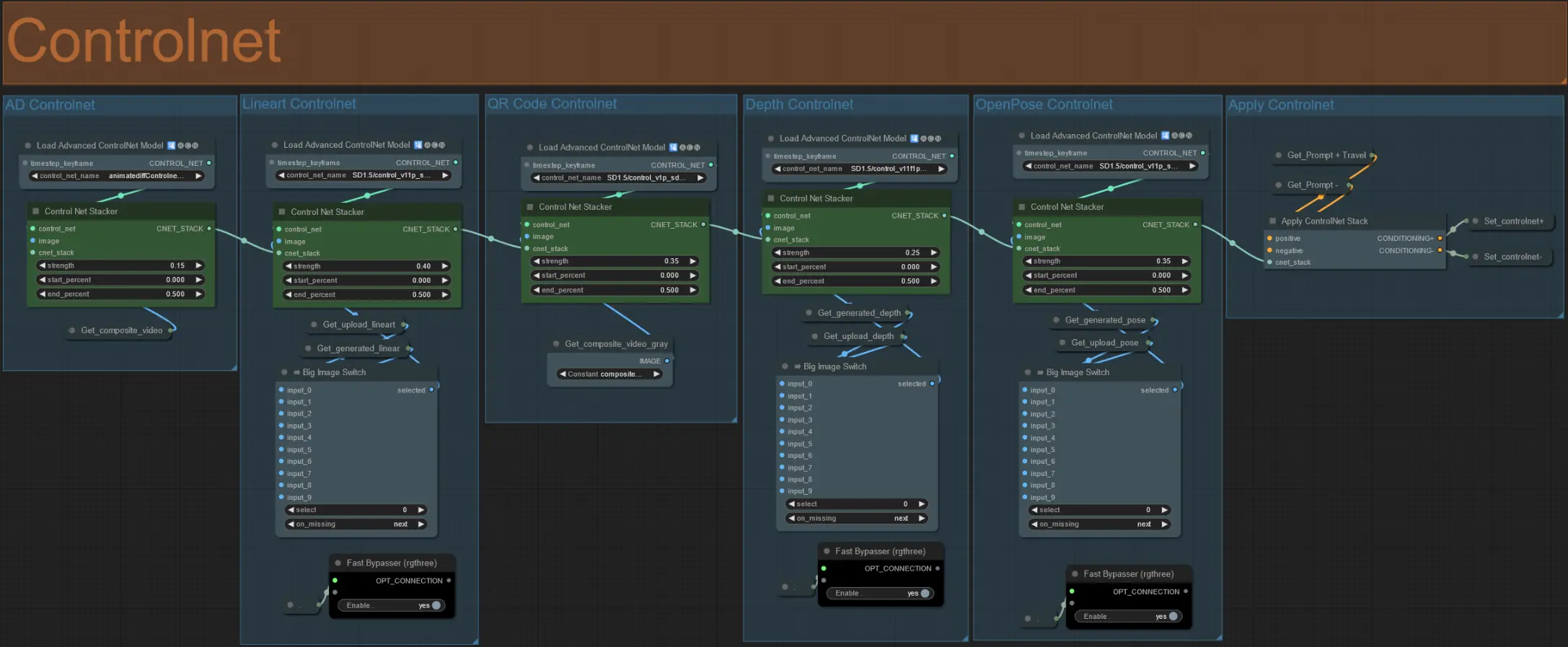
- 이 워크플로우는 AD, Lineart, QR Code, Depth, OpenPose를 포함한 5가지 다른 ControlNet을 사용합니다.
- ControlNet의 모든 입력은 자동으로 생성됩니다
- 원할 경우 Lineart, Depth, Openpose ControlNet의 입력 비디오를 무시하도록 선택할 수 있으며 아래와 같이 'Override ' 그룹을 음소거 해제하세요:
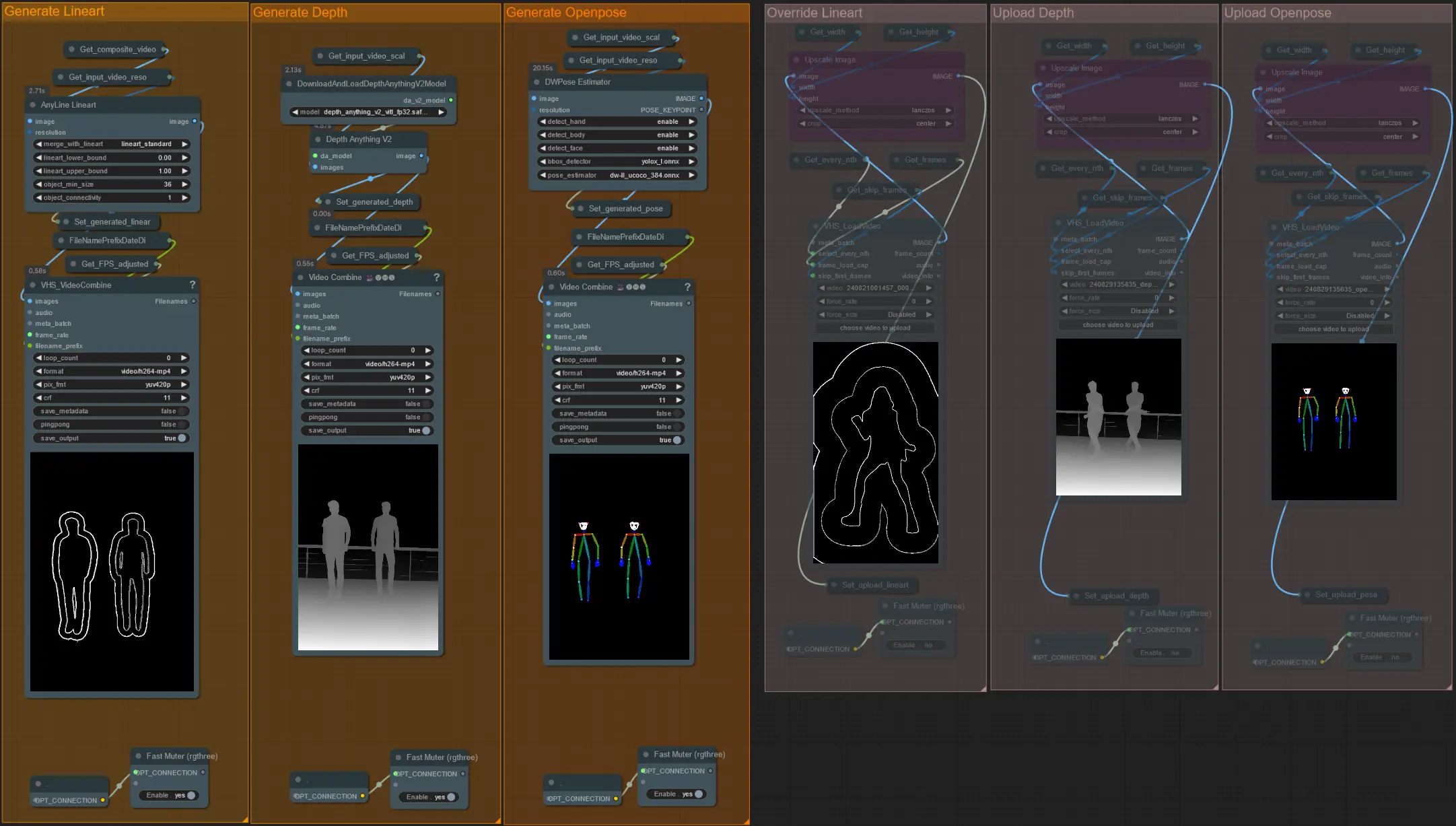
- 무시할 경우 처리 시간을 절약하기 위해 'Generate' 그룹도 음소거하는 것이 좋습니다.
팁:
- Ksampler를 우회하고 전체 입력 비디오로 렌더링을 시작하세요. 모든 전처리기 비디오가 생성되면 저장하고 해당 무시 항목에 업로드하세요. 이제 워크플로우 테스트 시 각 전처리기 비디오를 개별적으로 생성할 필요가 없습니다.
샘플러
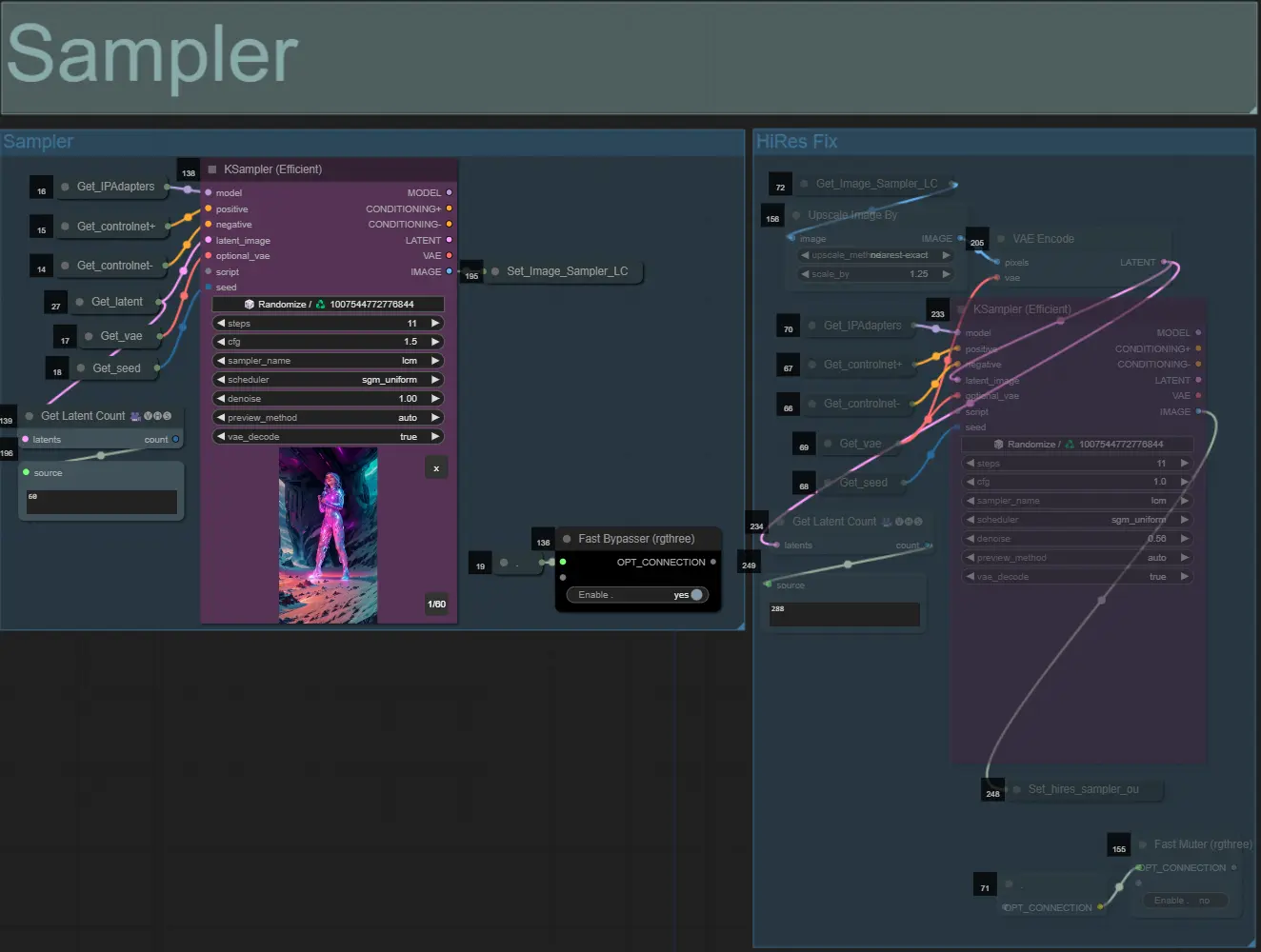
- 기본적으로 HiRes Fix 샘플러 그룹은 테스트 시 처리 시간을 절약하기 위해 음소거됩니다
- 확장 마스크 설정을 실험할 때 시간을 절약하기 위해 샘플러 그룹도 우회하는 것이 좋습니다.
- 최종 렌더링 시 HiRes Fix 그룹의 음소거를 해제하여 최종 결과를 업스케일하고 세부 사항을 추가할 수 있습니다.
출력

- 두 개의 출력 그룹이 있습니다: 왼쪽은 표준 샘플러 출력용, 오른쪽은 HiRes Fix 샘플러 출력용.
저자 소개
Akatz AI:
- 웹사이트:
- http://patreon.com/Akatz
- https://civitai.com/user/akatz
- https://www.youtube.com/@akatz_ai
- https://www.instagram.com/akatz.ai/
- https://www.tiktok.com/@akatz_ai
- https://x.com/akatz_ai
- https://github.com/akatz-ai
연락처:
- 이메일: akatz.hello@gmail.com
