CogVideoX-5B | 최첨단 텍스트-비디오 모델
Zhipu AI에서 개발한 CogVideoX-5B는 텍스트 프롬프트에서 고품질 비디오를 생성하는 최첨단 텍스트-비디오 모델입니다. 3D Causal VAE와 Expert Transformer 아키텍처를 활용하여 이 모델은 시간적으로 일관되고 부드러운 비디오 시퀀스를 보장하며, 복잡한 동작과 상세한 의미 생성을 위해 이상적입니다.ComfyUI CogVideoX-5B 워크플로우
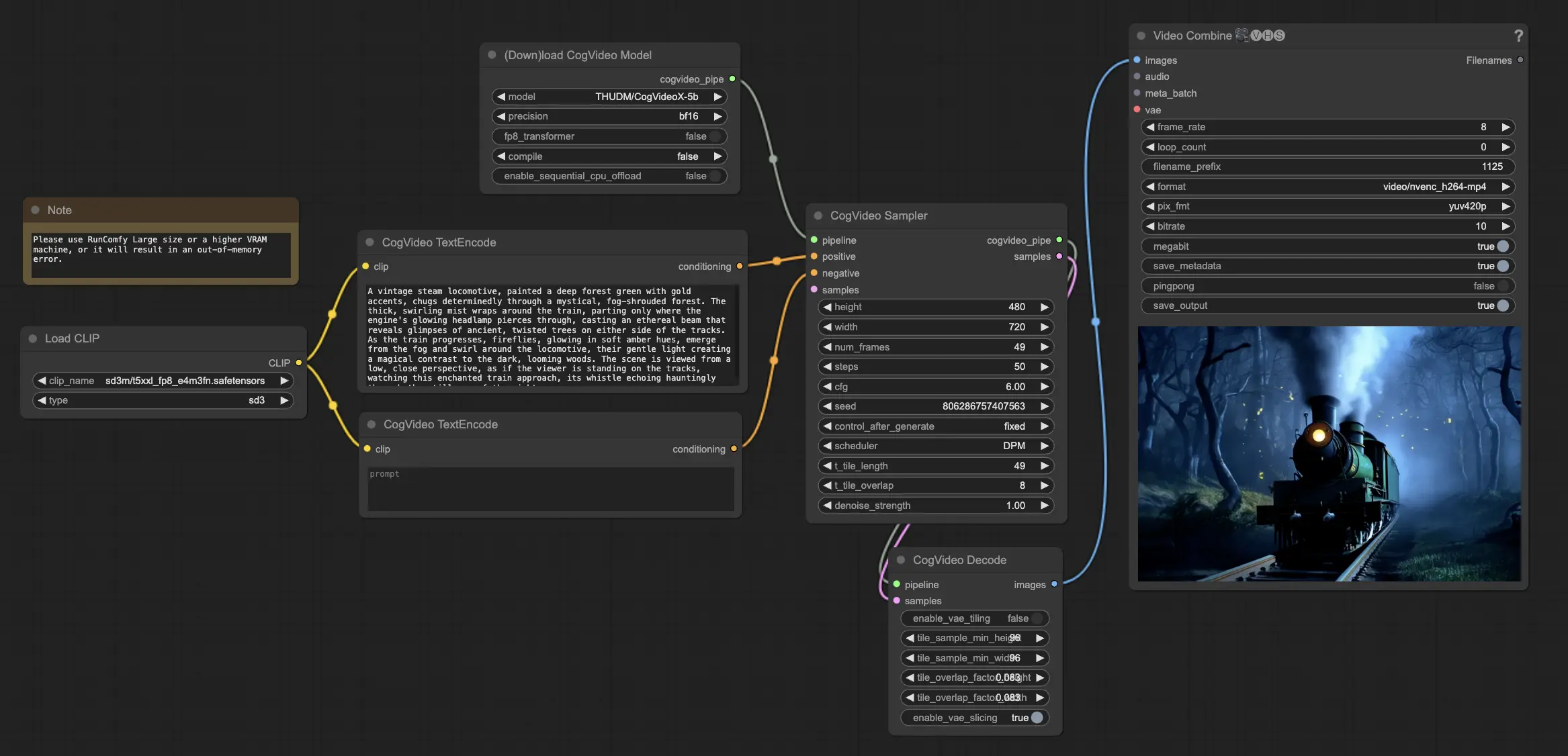
- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
ComfyUI CogVideoX-5B 예제
ComfyUI CogVideoX-5B 설명
1. CogVideoX-5B에 대하여
CogVideoX-5B는 Tsinghua University의 Zhipu AI에서 개발한 최첨단 텍스트-비디오 확산 모델입니다. CogVideoX 시리즈의 일환으로, 이 모델은 3D Variational Autoencoder (VAE)와 Expert Transformer와 같은 고급 AI 기술을 사용하여 텍스트 프롬프트에서 직접 비디오를 생성합니다. CogVideoX-5B는 복잡한 동작과 상세한 의미를 포착하는 고품질의 시간적으로 일관된 결과를 생성합니다.
CogVideoX-5B를 사용하면 뛰어난 명확성과 유동성을 얻을 수 있습니다. 이 모델은 복잡한 세부 사항과 역동적인 요소를 매우 정확하게 포착하여 원활한 흐름을 보장합니다. CogVideoX-5B를 활용하면 불일치와 인공물을 줄여 매끄럽고 매력적인 프레젠테이션을 제공합니다. CogVideoX-5B의 고충실도 출력은 텍스트 프롬프트에서 풍부하게 세부화된 일관된 장면을 생성하는 데 도움을 주어 최상급 품질과 시각적 충격을 위한 필수 도구가 됩니다.
2. CogVideoX-5B의 기술
2.1 CogVideoX-5B의 3D Causal Variational Autoencoder (VAE)
3D Causal VAE는 CogVideoX-5B의 핵심 구성 요소로, 비디오 데이터를 공간적 및 시간적으로 압축하여 효율적인 비디오 생성을 가능하게 합니다. 전통적인 모델이 각 프레임을 개별적으로 처리하는 2D VAE를 사용하여 프레임 간 깜박임이 발생하는 것과 달리, CogVideoX-5B는 3D 컨볼루션을 사용하여 공간적 및 시간적 정보를 한 번에 캡처합니다. 이 접근 방식은 프레임 간의 부드럽고 일관된 전환을 보장합니다.
3D Causal VAE의 아키텍처는 인코더, 디코더 및 잠재 공간 정규화를 포함합니다. 인코더는 비디오 데이터를 잠재 표현으로 압축하고, 디코더는 이를 사용하여 비디오를 재구성합니다. Kullback-Leibler (KL) 정규화는 잠재 공간을 제약하여 인코딩된 비디오가 Gaussian 분포 내에 유지되도록 합니다. 이는 재구성 중에 높은 비디오 품질을 유지하는 데 도움이 됩니다.
3D Causal VAE의 주요 특징
- 공간적 및 시간적 압축: VAE는 시간적 차원에서 4배, 공간적 차원에서 8x8의 비율로 비디오 데이터를 압축하여 총 압축 비율이 4x8x8이 됩니다. 이는 계산 요구 사항을 줄여 모델이 적은 리소스로 더 긴 비디오를 처리할 수 있게 합니다.
- Causal Convolution: 비디오의 프레임 순서를 유지하기 위해 모델은 시간적으로 인과적인 컨볼루션을 사용합니다. 이는 미래의 프레임이 현재 또는 과거의 프레임 예측에 영향을 미치지 않도록 하여 생성 중 시퀀스의 무결성을 유지합니다.
- Context Parallelism: 긴 비디오를 처리하는 높은 계산 부하를 관리하기 위해 모델은 시간적 차원에서 컨텍스트 병렬 처리를 사용하여 작업 부하를 여러 장치에 분산시킵니다. 이는 훈련 과정을 최적화하고 메모리 사용량을 줄입니다.
2.2 CogVideoX-5B의 Expert Transformer 아키텍처
CogVideoX-5B의 Expert Transformer 아키텍처는 텍스트와 비디오 데이터 간의 복잡한 상호작용을 효과적으로 처리하도록 설계되었습니다. 이는 텍스트와 비디오의 서로 다른 특징 공간을 처리하기 위해 적응형 LayerNorm 기술을 사용합니다.
Expert Transformer의 주요 특징
- Patchification: 3D Causal VAE가 비디오 데이터를 인코딩한 후, 이는 공간적 차원에서 더 작은 패치로 나누어집니다. 이 과정은 패치화라고 하며, 비디오를 더 작은 세그먼트의 시퀀스로 변환하여 트랜스포머가 처리하고 해당 텍스트 데이터와 정렬하기 쉽게 만듭니다.
- 3D Rotary Positional Embedding (RoPE): CogVideoX-5B는 비디오 내의 공간적 및 시간적 관계를 포착하기 위해 전통적인 2D RoPE를 3D로 확장합니다. 이 임베딩 기술은 비디오의 x, y 및 t 차원에 위치 인코딩을 적용하여 트랜스포머가 긴 비디오 시퀀스를 효과적으로 모델링하고 프레임 간의 일관성을 유지하도록 돕습니다.
- Expert Adaptive LayerNorm (AdaLN): 트랜스포머는 텍스트와 비디오 임베딩을 별도로 처리하기 위해 전문가 적응형 LayerNorm을 사용합니다. 이는 모델이 텍스트와 비디오의 서로 다른 특징 공간을 정렬할 수 있게 하여 이 두 가지 모달리티의 원활한 융합을 가능하게 합니다.
2.3 CogVideoX-5B의 점진적 훈련 기술
CogVideoX-5B는 비디오 생성 중 성능과 안정성을 향상시키기 위해 여러 점진적 훈련 기술을 사용합니다.
주요 점진적 훈련 전략
- 혼합 지속 시간 훈련: 모델은 동일한 배치 내에서 다양한 길이의 비디오로 훈련됩니다. 이 기술은 모델의 일반화 능력을 향상시켜, 모델이 일관된 품질을 유지하면서 다양한 길이의 비디오를 생성할 수 있게 합니다.
- 해상도 점진적 훈련: 모델은 먼저 낮은 해상도의 비디오로 훈련된 후 점차적으로 높은 해상도의 비디오로 미세 조정됩니다. 이 접근 방식은 모델이 비디오의 기본 구조와 내용을 학습한 후 높은 해상도에서 이를 정제할 수 있게 합니다.
- 명시적 균일 샘플링: 훈련 과정을 안정화하기 위해 CogVideoX-5B는 명시적 균일 샘플링을 사용하여 각 데이터 병렬 랭크에 대해 다른 시간 단계 샘플링 간격을 설정합니다. 이 방법은 수렴을 가속화하고 모델이 전체 비디오 시퀀스에서 효과적으로 학습할 수 있도록 보장합니다.
3. ComfyUI CogVideoX-5B 워크플로우 사용 방법
Step 1: CogVideoX-5B 모델 로드
CogVideoX-5B 모델을 ComfyUI 워크플로우에 로드하는 것으로 시작합니다. CogVideoX-5B 모델은 RunComfy의 플랫폼에 사전 로드되어 있습니다.
Step 2: 텍스트 프롬프트 입력
지정된 노드에 원하는 텍스트 프롬프트를 입력하여 CogVideoX-5B 비디오 생성 과정을 안내합니다. CogVideoX-5B는 텍스트 프롬프트를 해석하고 이를 동적인 비디오 콘텐츠로 변환하는 데 뛰어납니다.
4. 라이선스 계약
CogVideoX 모델의 코드는 하에 공개되었습니다.
CogVideoX-2B 모델(해당 Transformer 모듈 및 VAE 모듈 포함)은 하에 공개되었습니다.
CogVideoX-5B 모델(Transformer 모듈)은 하에 공개되었습니다.