LatentSync| Lip Sync Model
LatentSync는 오디오 조건부 잠재 확산 모델로 립싱크를 재정의하며, 중간 모션 표현을 우회하여 매끄러운 오디오-비주얼 정렬을 구현합니다. Stable Diffusion을 활용하여 복잡한 상관관계를 캡처하면서 시간적 부드러움을 보장합니다. 픽셀 기반 접근 방식과 달리, LatentSync는 혁신적인 시간적 표현 정렬(TREPA) 모듈로 우수한 시간적 일관성을 보장합니다. TREPA 모듈은 뛰어난 정확도와 현실감을 제공합니다.ComfyUI LatentSync 워크플로우
- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
ComfyUI LatentSync 예제
ComfyUI LatentSync 설명
LatentSync는 오디오 조건부 잠재 확산 모델의 힘을 활용하여 현실적인 립싱크 생성을 위한 최첨단 종단 간 립싱크 프레임워크입니다. LatentSync를 차별화하는 점은 중간 모션 표현에 의존하지 않고 오디오와 시각적 요소 간의 복잡한 상관관계를 직접 모델링하여 립싱크 합성 접근 방식을 혁신한다는 것입니다.
LatentSync 파이프라인의 핵심은 고품질 이미지를 캡처하고 생성하는 뛰어난 능력으로 유명한 강력한 생성 모델인 Stable Diffusion의 통합입니다. Stable Diffusion의 기능을 활용하여 LatentSync는 말소리와 해당 입술 움직임 간의 복잡한 역학을 효과적으로 학습하고 재현할 수 있어 매우 정확하고 설득력 있는 립싱크 애니메이션을 제공합니다.
확산 기반 립싱크 방법의 주요 과제 중 하나는 생성된 프레임 전반에 걸쳐 시간적 일관성을 유지하는 것입니다. 이는 현실적인 결과를 위해 중요합니다. LatentSync는 시간적 일관성을 강화하도록 특별히 설계된 획기적인 시간적 표현 정렬(TREPA) 모듈로 이 문제를 정면으로 해결합니다. TREPA는 대규모 자가 지도 비디오 모델을 사용하여 생성된 프레임에서 시간적 표현을 추출하기 위해 첨단 기술을 사용합니다. 이러한 표현을 실제 프레임과 정렬함으로써 LatentSync의 프레임워크는 높은 수준의 시간적 일관성을 보장하여 오디오 입력과 밀접하게 일치하는 놀랍도록 부드럽고 설득력 있는 립싱크 애니메이션을 제공합니다.
1.1 LatentSync Workflow 사용 방법?
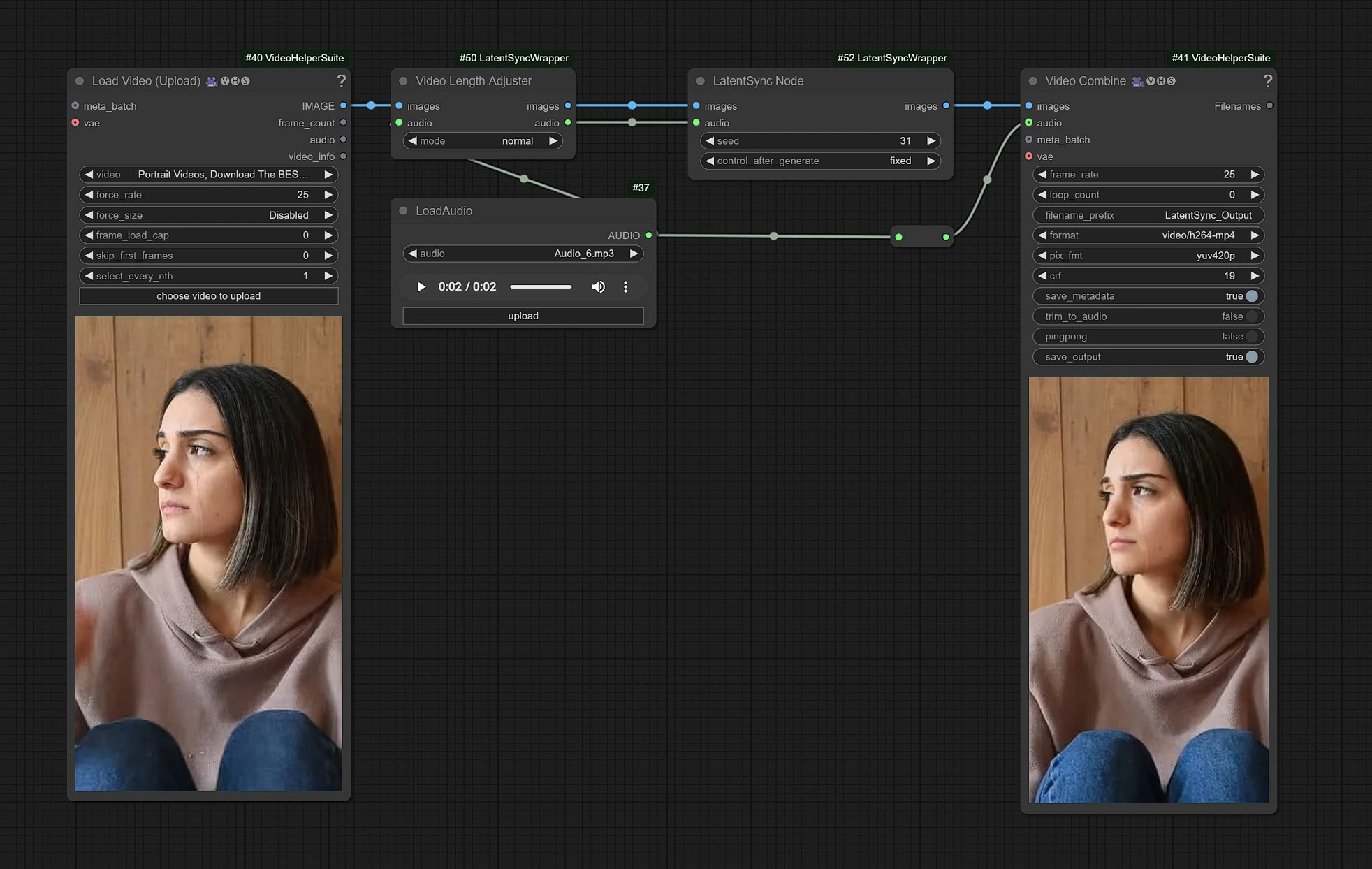
이것이 LatentSync 워크플로우입니다. 왼쪽 노드는 비디오 업로드를 위한 입력이며, 중간은 LatentSync 노드를 처리하고, 오른쪽은 출력 노드입니다.
- 입력 노드에 비디오를 업로드하세요.
- 대화 오디오 입력을 업로드하세요.
- 렌더를 클릭하세요!!!
1.2 비디오 입력
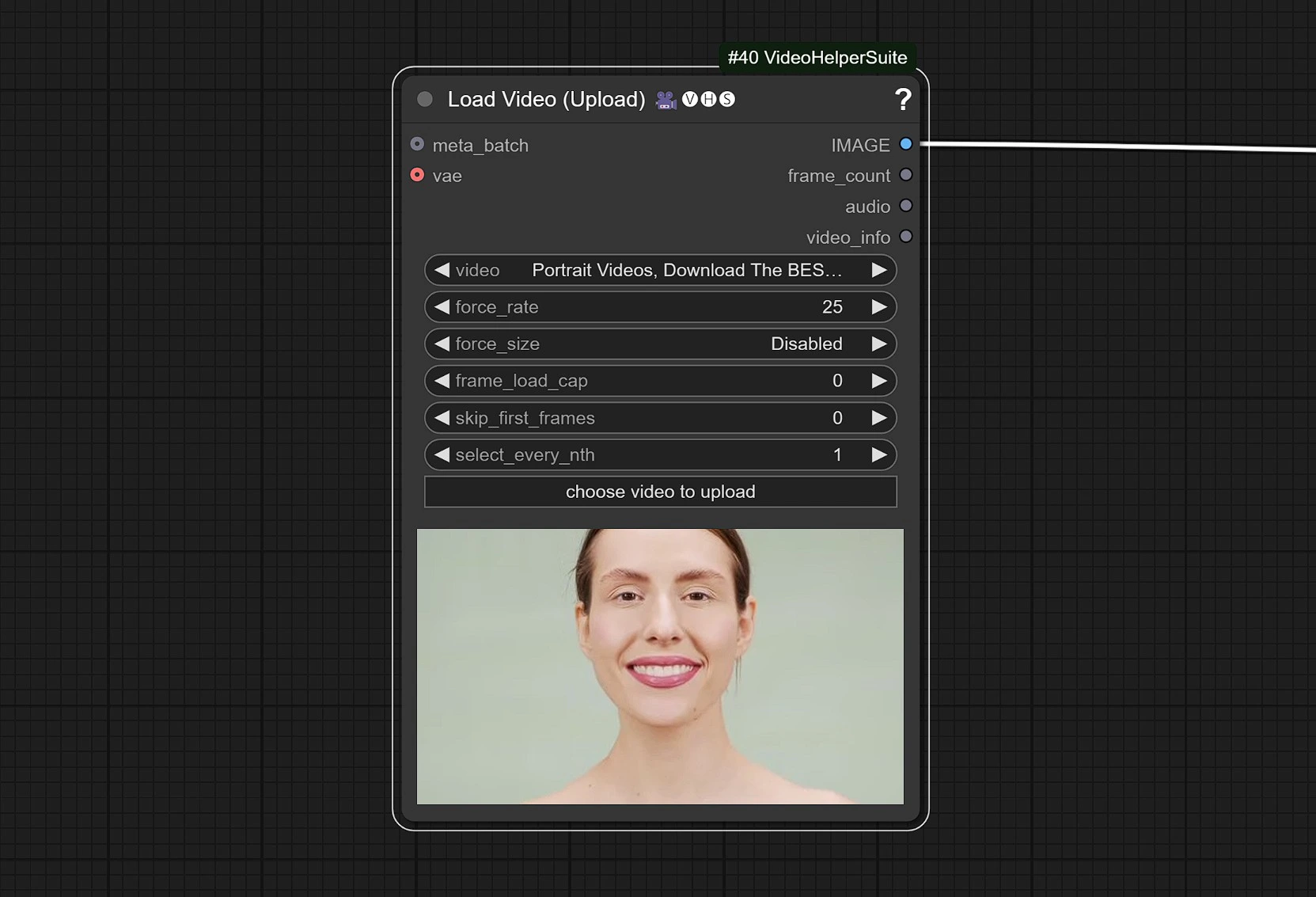
- 얼굴이 있는 참조 비디오를 클릭하고 업로드하세요.
비디오는 오디오 모델과 제대로 동기화되기 위해 25 FPS로 조정됩니다.
1.3 오디오 입력
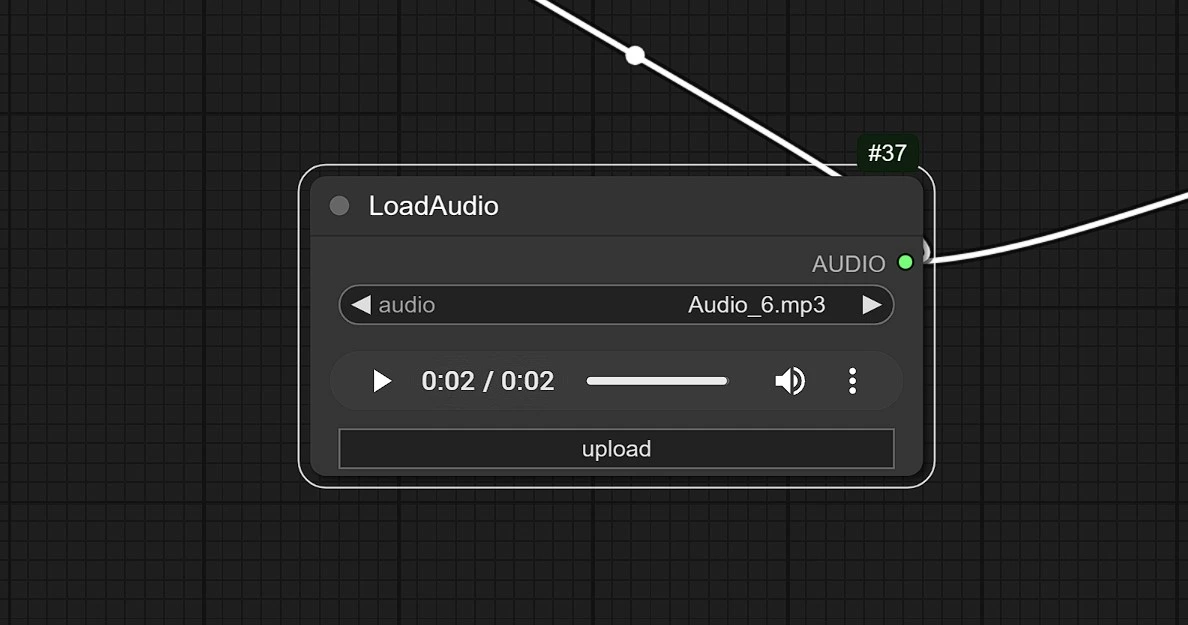
- 여기에 오디오를 클릭하고 업로드하세요.
LatentSync는 혁신적인 오디오-비주얼 생성 접근 방식으로 립싱크의 새로운 기준을 설정합니다. 정밀도, 시간적 일관성, Stable Diffusion의 힘을 결합하여 LatentSync는 동기화된 콘텐츠를 생성하는 방식을 변화시킵니다. LatentSync로 립싱크의 가능성을 재정의하십시오.

