Segment Anything V2 (SAM2) | 비디오 세그먼테이션
Meta AI에서 개발한 Segment Anything V2 (SAM2)는 이미지와 비디오에서 객체 세그먼테이션을 간소화하는 혁신적인 AI 모델입니다. 다양한 입력 방법과 결합된 지능형 세그먼테이션 기능으로 AI 아티스트의 워크플로우를 최적화합니다. SAM2의 향상된 비디오 세그먼테이션, 감소된 상호작용 시간, 빠른 추론 속도는 AI 기반 예술 창작의 한계를 넓히는 강력한 도구입니다. ComfyUI-LivePortraitKJ 노드는 Kijai에 의해 만들어졌으며, 이 워크플로우는 그에 의해 완전히 개발되었습니다.ComfyUI Segment Anything V2 (SAM2) 워크플로우
- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
ComfyUI Segment Anything V2 (SAM2) 예제
ComfyUI Segment Anything V2 (SAM2) 설명
Segment Anything V2, SAM2로도 알려진 이 모델은 Meta AI에서 개발한 혁신적인 AI 모델로, 이미지와 비디오의 객체 세그먼테이션을 혁신적으로 변모시킵니다.
Segment Anything V2 (SAM2)란 무엇인가요?
Segment Anything V2는 이미지와 비디오 전반에 걸쳐 객체를 원활하게 세그먼트할 수 있는 최첨단 AI 모델입니다. 이 모델은 이미지와 비디오 세그먼테이션 작업 모두를 뛰어난 정확도와 효율성으로 처리할 수 있는 최초의 통합 모델입니다. Segment Anything V2 (SAM2)는 전임자인 Segment Anything Model (SAM)의 성공을 바탕으로 비디오 도메인으로 프롬프트 가능한 기능을 확장합니다.
Segment Anything V2 (SAM2)를 사용하면 클릭, 바운딩 박스, 마스크와 같은 다양한 입력 방법을 사용하여 이미지나 비디오 프레임에서 객체를 선택할 수 있습니다. 모델은 선택된 객체를 지능적으로 세그먼트하여 시각적 콘텐츠 내에서 특정 요소를 정밀하게 추출하고 조작할 수 있게 합니다.
Segment Anything V2 (SAM2)의 주요 특징
- 최첨단 성능: SAM2는 이미지와 비디오의 객체 세그먼테이션 분야에서 기존 모델을 능가하는 성능을 제공합니다. 이미지 세그먼테이션 작업에서 SAM의 성능을 뛰어넘어 새로운 정확도와 정밀도의 기준을 설정합니다.
- 이미지와 비디오를 위한 통합 모델: SAM2는 이미지와 비디오 전반에 걸쳐 객체를 세그먼트할 수 있는 통합 솔루션을 최초로 제공합니다. 이는 AI 아티스트가 다양한 세그먼테이션 작업에 단일 모델을 사용할 수 있도록 워크플로우를 단순화합니다.
- 향상된 비디오 세그먼테이션 기능: SAM2는 객체 부분 추적에서 특히 뛰어난 비디오 객체 세그먼테이션 성능을 자랑합니다. 프레임 전반에 걸쳐 객체를 세그먼트하는 데 있어 기존 비디오 세그먼테이션 모델보다 향상된 정확도와 일관성을 제공합니다.
- 상호작용 시간 감소: 기존의 상호작용 비디오 세그먼테이션 방법과 비교하여 SAM2는 사용자로부터 더 적은 상호작용 시간을 요구합니다. 이 효율성 덕분에 AI 아티스트는 수동 세그먼테이션 작업에 소요되는 시간을 줄이고 창의적인 비전에 더 집중할 수 있습니다.
- 간단한 디자인과 빠른 추론: 고급 기능에도 불구하고 SAM2는 간단한 아키텍처 디자인을 유지하고 빠른 추론 속도를 제공합니다. 이를 통해 AI 아티스트는 성능이나 효율성을 저해하지 않고 SAM2를 워크플로우에 원활하게 통합할 수 있습니다.
Segment Anything V2 (SAM2)의 작동 방식
SAM2는 세션당 메모리 모듈을 도입하여 프레임 전반에 걸쳐 객체 정보를 캡처함으로써 SAM의 프롬프트 가능한 기능을 비디오로 확장합니다. 이 스트리밍 아키텍처는 비디오 프레임을 하나씩 처리하며, 메모리 모듈이 비어 있을 때 이미지를 위한 SAM처럼 작동합니다. 이를 통해 실시간 비디오 처리가 가능하며, SAM의 기능이 자연스럽게 일반화됩니다. SAM2는 또한 사용자 프롬프트에 기반한 상호작용 마스크 예측 수정을 지원합니다. 이 모델은 스트리밍 메모리를 갖춘 트랜스포머 아키텍처를 사용하며, 사용자 상호작용을 통해 모델과 데이터를 개선하는 모델 인-더-루프 데이터 엔진을 사용하여 수집된 최대 비디오 세그먼테이션 데이터셋인 SA-V 데이터셋에서 훈련되었습니다.
ComfyUI에서 Segment Anything V2 (SAM2)를 사용하는 방법
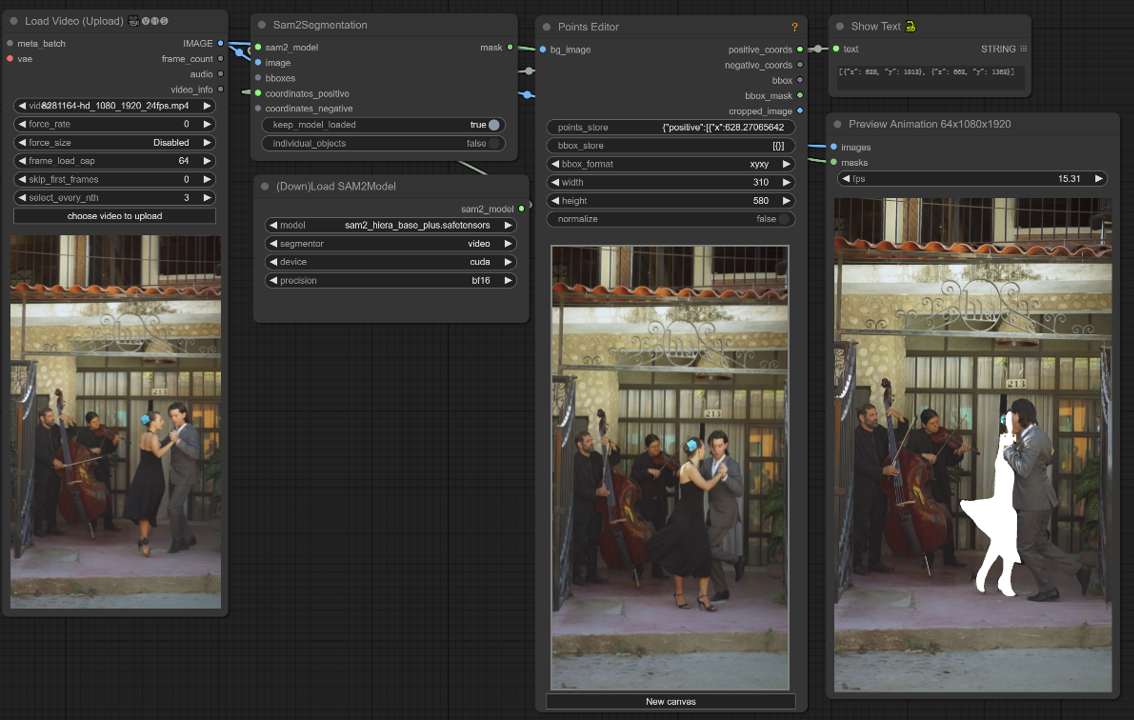
이 ComfyUI 워크플로우는 클릭/포인트를 사용하여 비디오 프레임에서 객체를 선택하는 것을 지원합니다.
1. 비디오 로드(업로드)
비디오 로딩: 처리할 비디오를 선택하고 업로드하세요.

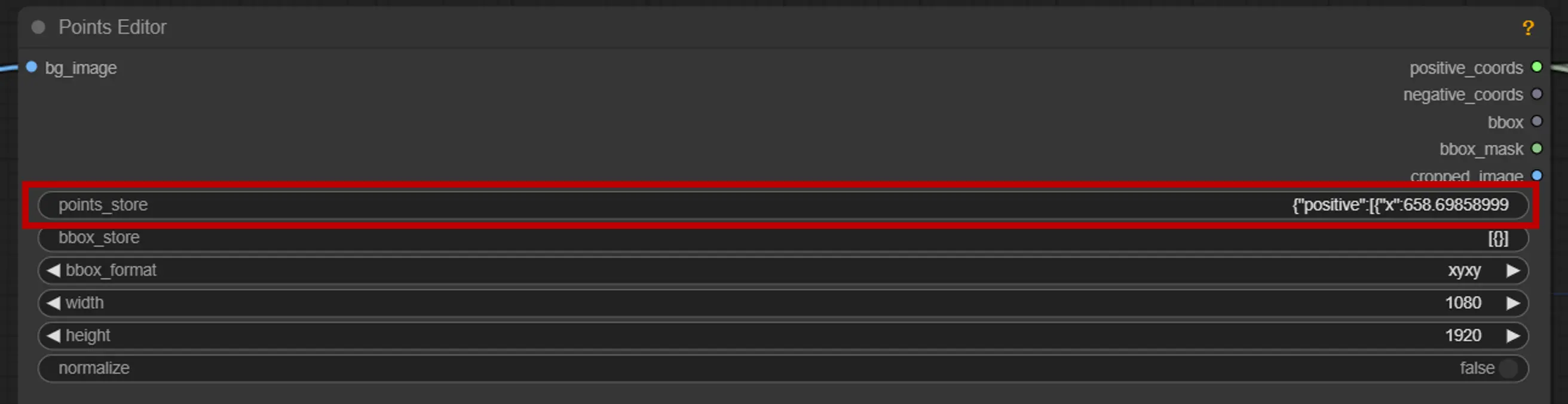
2. 포인트 편집기
핵심 포인트: 캔버스에 세 개의 핵심 포인트—positive0, positive1, negative0을 배치하세요:
positive0와 positive1은 세그먼트하려는 영역이나 객체를 표시합니다.
negative0은 불필요한 영역이나 방해 요소를 제외하는 데 도움을 줍니다.

points_store: 세그먼테이션 과정을 정밀하게 조정하기 위해 필요에 따라 포인트를 추가하거나 제거할 수 있습니다.
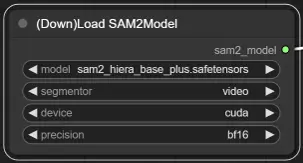
3. SAM2 모델 선택
모델 옵션: 사용 가능한 SAM2 모델 중에서 선택하세요: tiny, small, large, 또는 base_plus. 더 큰 모델은 더 나은 결과를 제공하지만 로딩 시간이 더 오래 걸립니다.
자세한 내용은 를 방문하세요.
