Hunyuan 비디오 | 비디오에서 비디오로
ComfyUI의 이 Hunyuan 워크플로우를 통해 기존 비주얼을 놀라운 새로운 비주얼로 변환할 수 있습니다. 텍스트 프롬프트와 소스 비디오를 입력하면, Hunyuan 모델이 소스의 움직임과 주요 요소를 통합한 인상적인 번역을 생성합니다. 고급 아키텍처와 훈련 기법을 통해 Hunyuan은 고품질, 다양하고 안정적인 콘텐츠를 제작합니다.ComfyUI Hunyuan Video to Video 워크플로우
이 워크플로우를 실행하고 싶으신가요?
- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
ComfyUI Hunyuan Video to Video 예제
ComfyUI Hunyuan Video to Video 설명
Hunyuan 비디오는 Tencent에서 개발한 오픈 소스 AI 모델로, 놀랍고 역동적인 비주얼을 쉽게 생성할 수 있습니다. Hunyuan 모델은 고급 아키텍처와 훈련 기법을 활용하여 높은 품질의 콘텐츠, 움직임의 다양성, 안정성을 이해하고 생성합니다.
Hunyuan 비디오에서 비디오로 워크플로우 소개
ComfyUI의 이 Hunyuan 워크플로우는 Hunyuan 모델을 활용하여 입력 텍스트 프롬프트와 기존 드라이빙 비디오를 결합하여 새로운 비주얼 콘텐츠를 생성합니다. Hunyuan 모델의 기능을 활용하여, 드라이빙 비디오의 움직임과 주요 요소를 매끄럽게 통합하면서 원하는 텍스트 프롬프트와 일치하는 인상적인 비디오 번역을 생성할 수 있습니다.
Hunyuan 비디오에서 비디오로 워크플로우 사용법
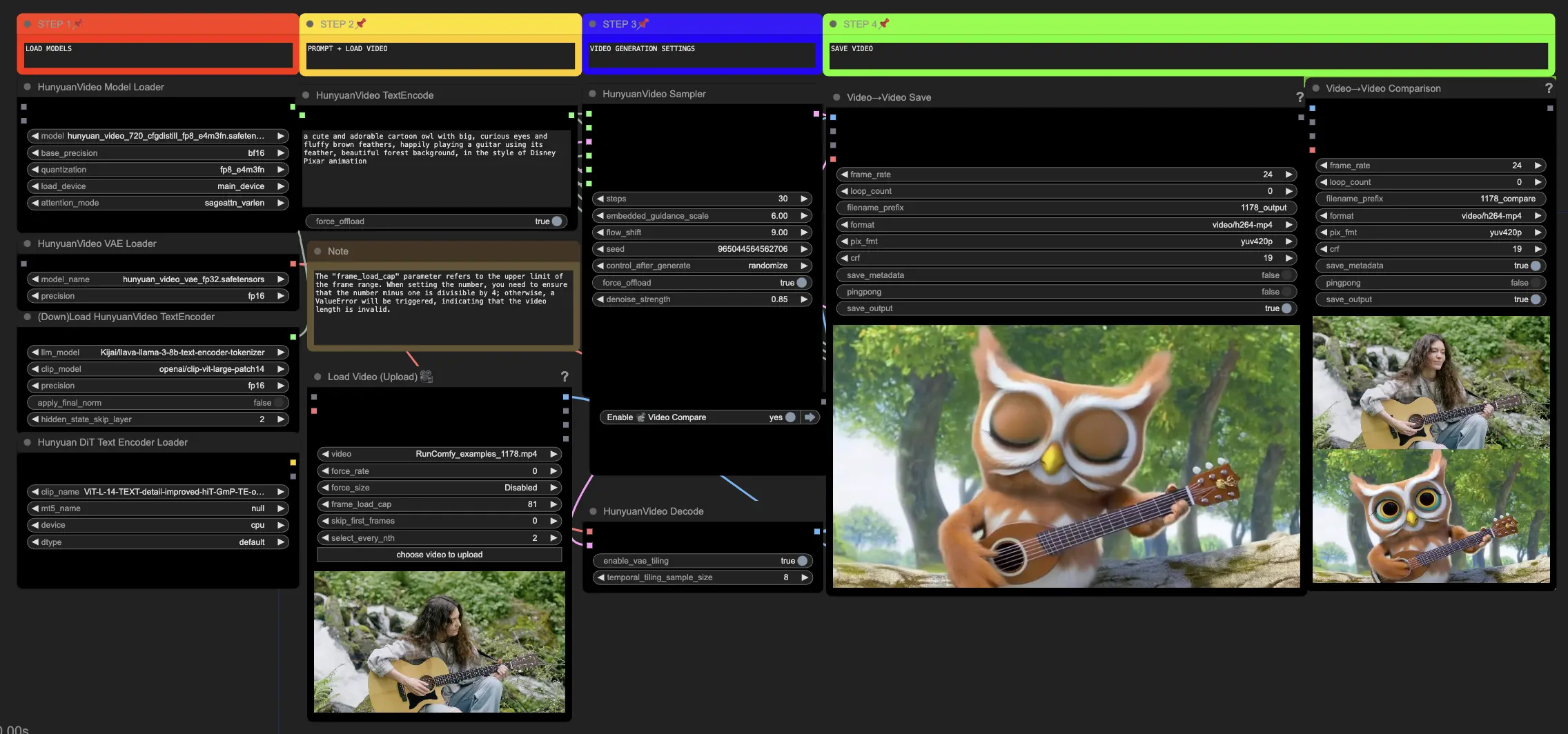
🟥 1단계: Hunyuan 모델 로드
- HyVideoModelLoader 노드에서 "hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors" 파일을 선택하여 Hunyuan 모델을 로드합니다. 이 모델은 주요 변환 모델입니다.
- HunyuanVideo VAE 모델은 HunyuanVideoVAELoader 노드에서 자동으로 다운로드됩니다. 이는 비디오 프레임을 인코딩/디코딩하는 데 사용됩니다.
- DownloadAndLoadHyVideoTextEncoder 노드에서 텍스트 인코더를 로드합니다. 워크플로우는 기본적으로 "Kijai/llava-llama-3-8b-text-encoder-tokenizer" LLM 인코더와 "openai/clip-vit-large-patch14" CLIP 인코더를 사용하며, 자동으로 다운로드됩니다. 이전 모델과 함께 작동했던 다른 CLIP 또는 T5 인코더도 사용할 수 있습니다.
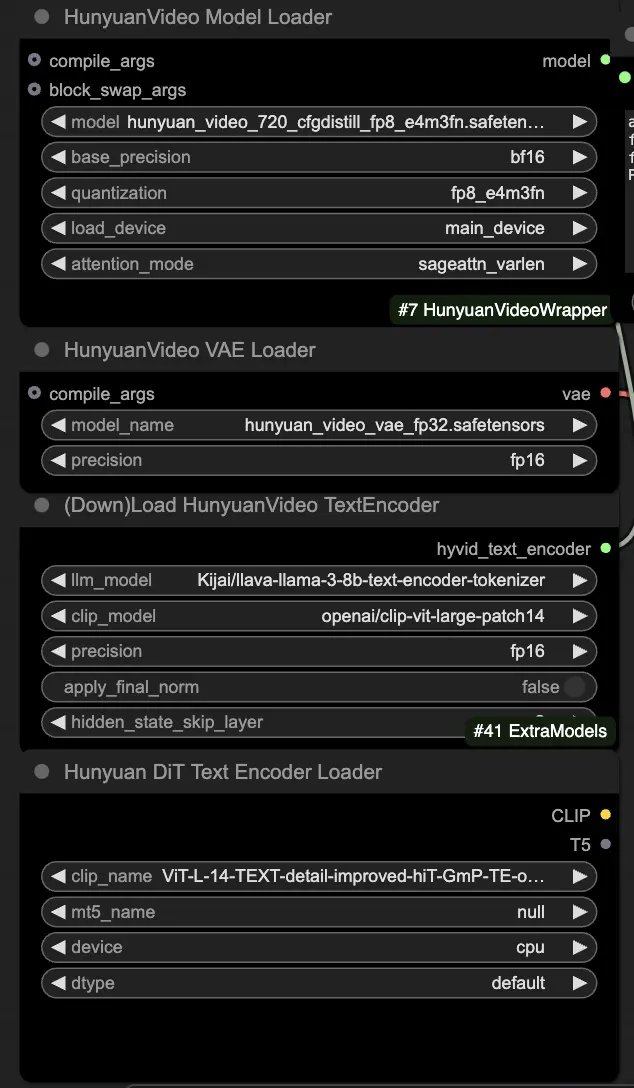
🟨 2단계: 프롬프트 입력 및 드라이빙 비디오 로드
- HyVideoTextEncode 노드에서 생성하고자 하는 비주얼을 설명하는 텍스트 프롬프트를 입력하세요.
- VHS_LoadVideo 노드에서 움직임 참조로 사용할 드라이빙 비디오를 로드하세요.
- frame_load_cap: 생성할 프레임 수입니다. 숫자를 설정할 때 숫자에서 1을 뺀 값이 4로 나누어 떨어지도록 해야 합니다. 그렇지 않으면 ValueError가 발생하여 비디오 길이가 유효하지 않음을 나타냅니다.
- skip_first_frames: 비디오의 어느 부분을 사용할지 제어하기 위해 이 매개변수를 조정하세요.
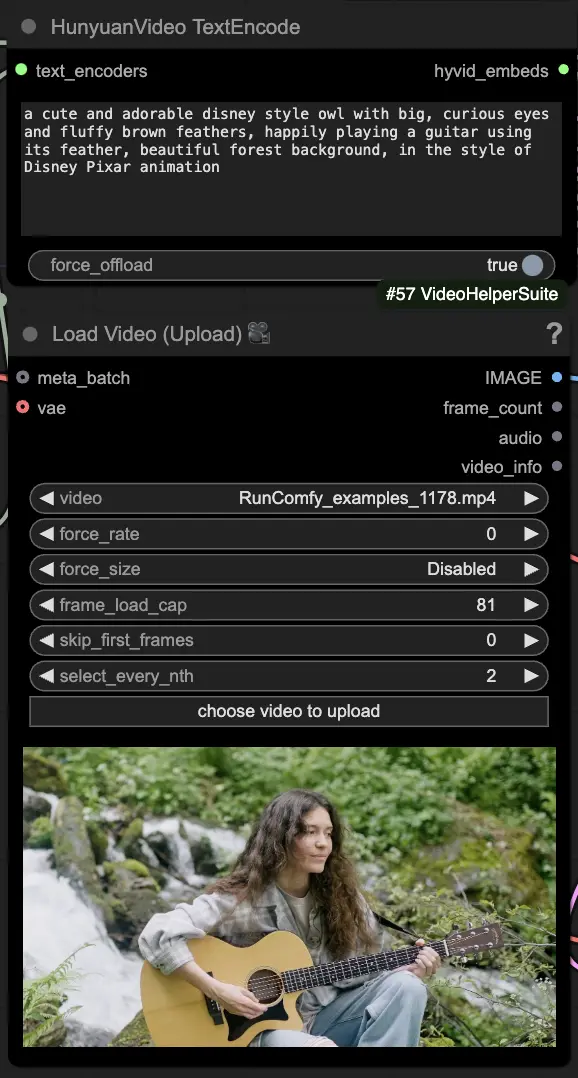
🟦 3단계: Hunyuan 생성 설정
- HyVideoSampler 노드에서 비디오 생성 하이퍼파라미터를 구성하세요:
- Steps: 프레임당 확산 단계 수, 높을수록 품질이 좋지만 생성 속도가 느려집니다. 기본값은 30입니다.
- Embedded_guidance_scale: 프롬프트에 얼마나 충실할지를 결정합니다. 값이 높을수록 프롬프트에 더 가까워집니다.
- Denoise_strength: 초기 드라이빙 비디오의 사용 강도를 조절합니다. 낮은 값(예: 0.6)은 출력이 초기 비디오와 더 비슷하게 보이도록 만듭니다.
- "Fast Groups Bypasser" 노드에서 비교 비디오와 같은 추가 기능을 활성화/비활성화하기 위해 애드온과 토글을 선택하세요.
🟩 4단계: Hunyuan 비디오 생성
- VideoCombine 노드는 기본적으로 두 개의 출력을 생성하고 저장합니다:
- 번역된 비디오 결과
- 드라이빙 비디오와 생성된 결과를 보여주는 비교 비디오
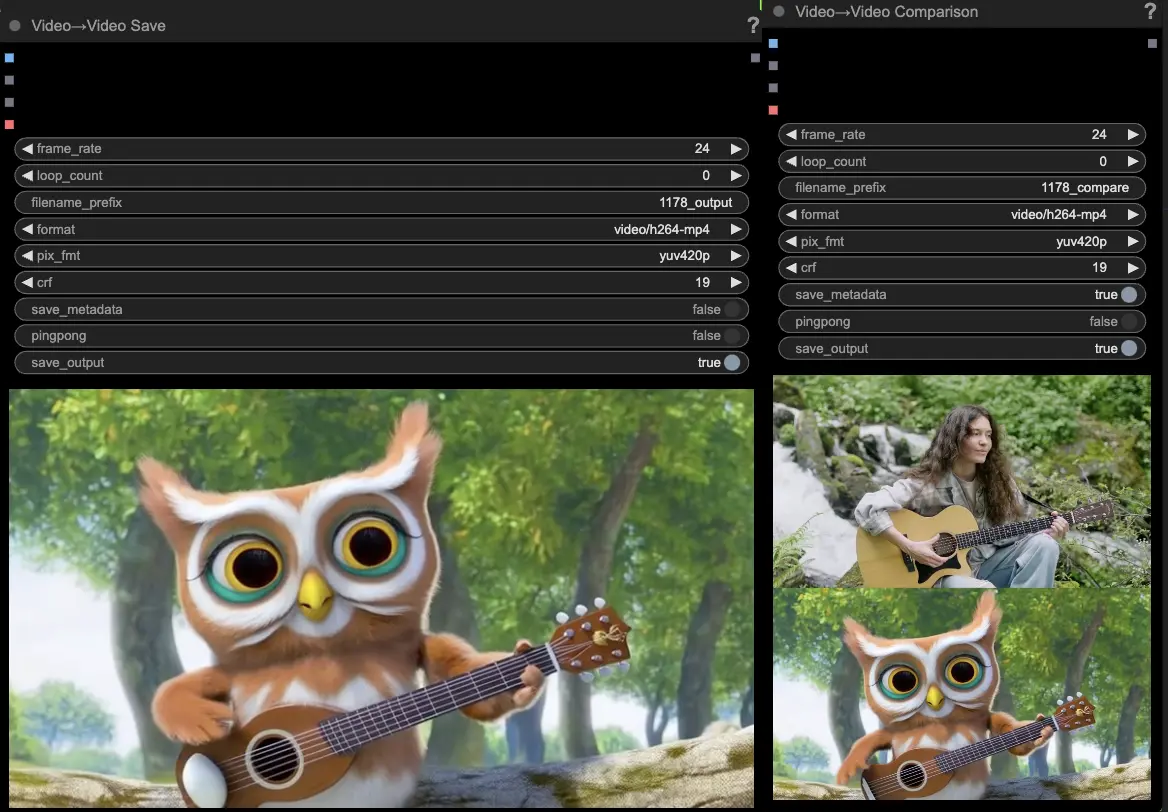
프롬프트와 생성 설정을 조정하면 Hunyuan 모델을 사용하여 기존 비디오의 움직임에 의해 주도되는 새로운 비디오를 생성하는데 인상적인 유연성을 제공합니다. 이 Hunyuan 워크플로우의 창의적인 가능성을 탐험하세요!
이 Hunyuan 워크플로우는 Black Mixture에 의해 설계되었습니다. 자세한 내용은 을 방문하세요. 또한 노드 및 워크플로우 예제에 특별히 감사드립니다.

