Vid2Vid Part 1 | 구성 및 마스킹
ComfyUI Vid2Vid는 고품질의 전문 애니메이션을 만드는 두 가지 고유한 워크플로우를 제공합니다: Vid2Vid Part 1은 원본 비디오의 구성 및 마스킹에 중점을 두어 창의성을 향상시키고, Vid2Vid Part 2는 SDXL Style Transfer를 활용하여 비디오의 스타일을 원하는 미적 감각에 맞게 변환합니다. 이 페이지는 Vid2Vid Part 1을 다룹니다.ComfyUI Vid2Vid 워크플로우

- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
ComfyUI Vid2Vid 예제
ComfyUI Vid2Vid 설명
ComfyUI Vid2Vid 워크플로우는 에 의해 만들어졌으며, 고품질의 전문 애니메이션을 달성하기 위한 두 가지 고유한 워크플로우를 도입합니다.
- 첫 번째 ComfyUI 워크플로우: ComfyUI Vid2Vid Part 1 | 구성 및 마스킹
- 두 번째 워크플로우:
ComfyUI Vid2Vid Part 1 | 구성 및 마스킹
이 워크플로우는 원본 비디오의 구성 및 마스킹에 중점을 두어 창의성을 향상시킵니다.
Step 1: Models Loader | ComfyUI Vid2Vid Workflow Part1
애니메이션에 적합한 모델을 선택하십시오. 여기에는 체크포인트 모델, VAE (Variational Autoencoder) 모델, 및 LoRA (Low-Rank Adaptation) 모델 선택이 포함됩니다. 이 모델들은 애니메이션의 능력과 스타일을 정의하는 데 중요합니다.
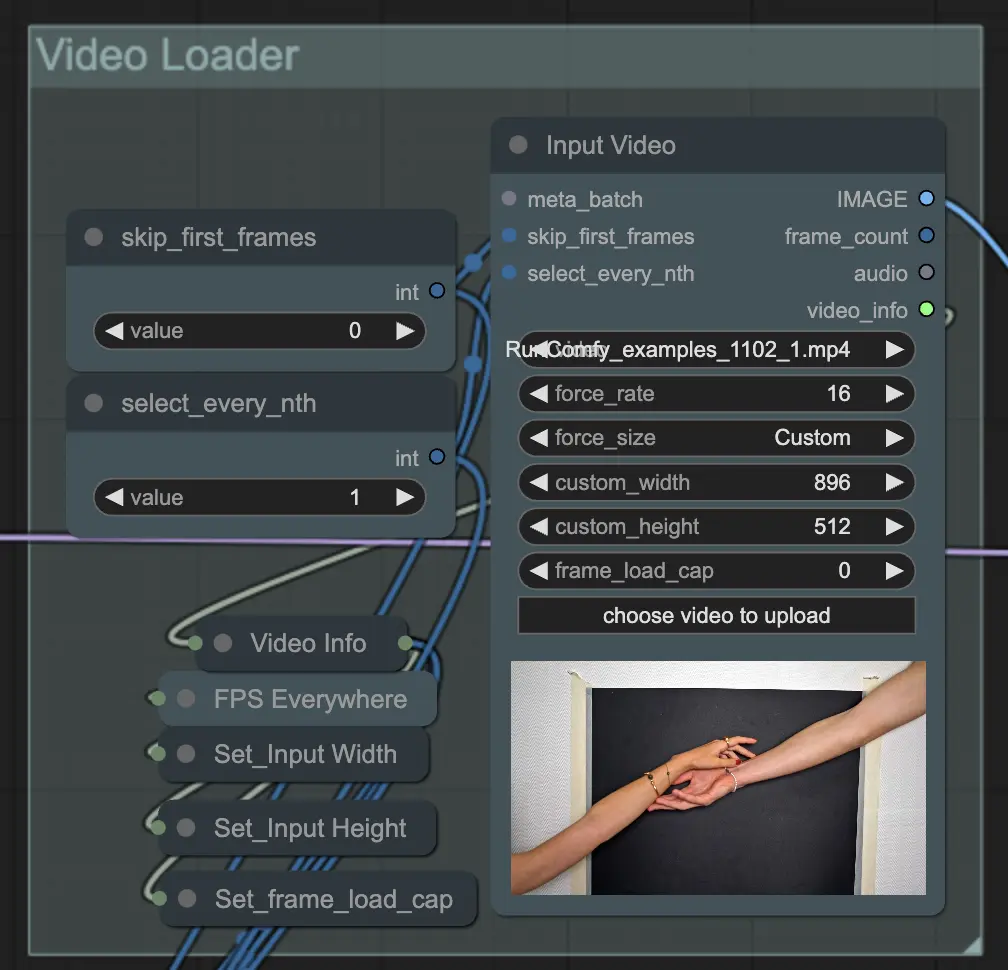
Step 2: Video Loader | ComfyUI Vid2Vid Workflow Part1
Input Video 노드는 애니메이션에 사용할 비디오 파일을 가져오는 역할을 합니다. 노드는 비디오를 읽고 개별 프레임으로 변환하여 후속 단계에서 처리할 수 있게 합니다. 이를 통해 프레임 단위의 세부 편집 및 향상이 가능합니다.
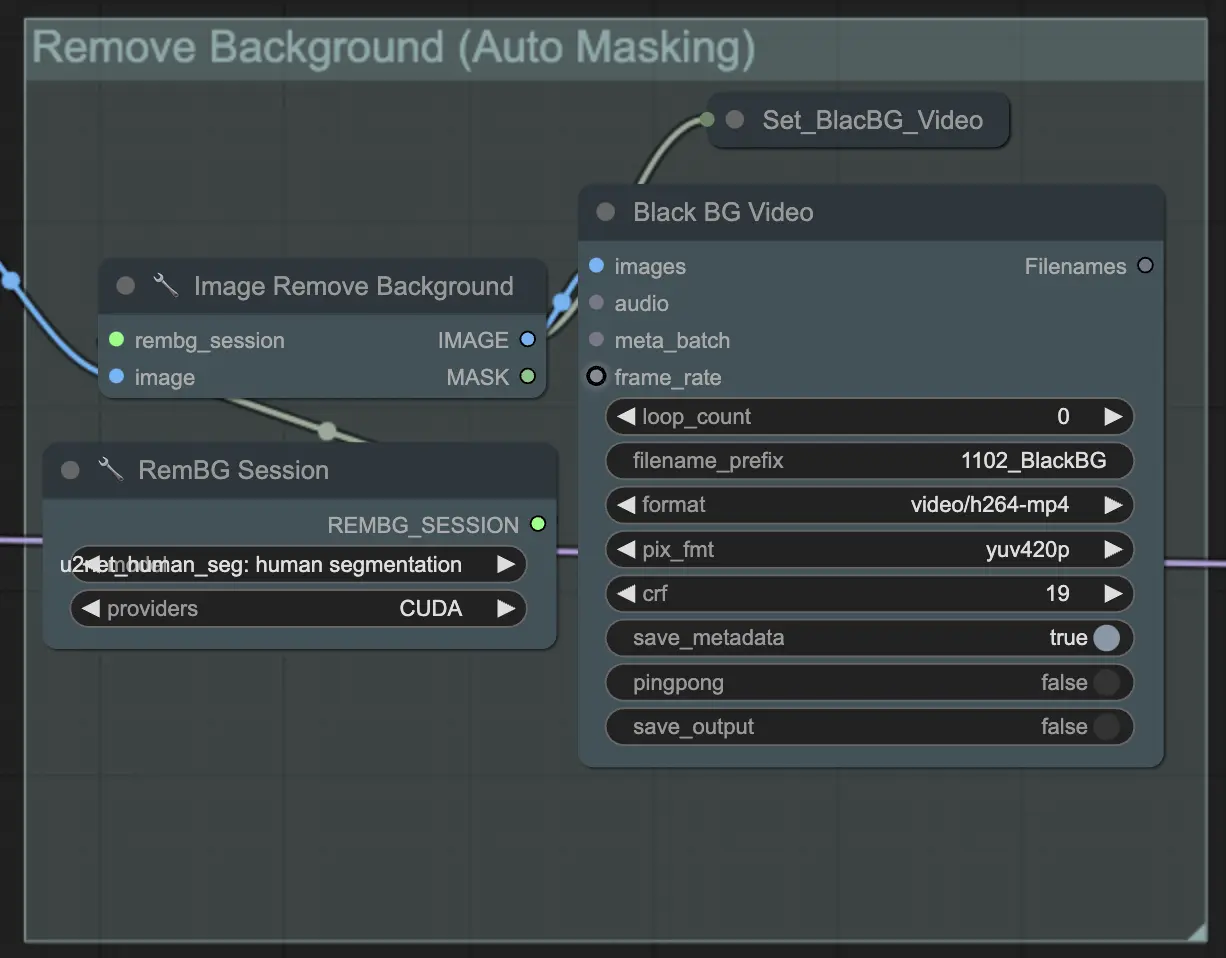
Step 3: Remove Background (Auto Masking) | ComfyUI Vid2Vid Workflow Part1
**Remove Background (Auto Masking)**은 자동 마스킹 기법을 사용하여 배경에서 주제를 분리합니다. 이는 모델이 전경 주제를 배경에서 감지하고 분리하여 이진 마스크를 생성하는 과정을 포함합니다. 이 단계는 주제를 배경과 독립적으로 조작할 수 있도록 하는 데 중요합니다.
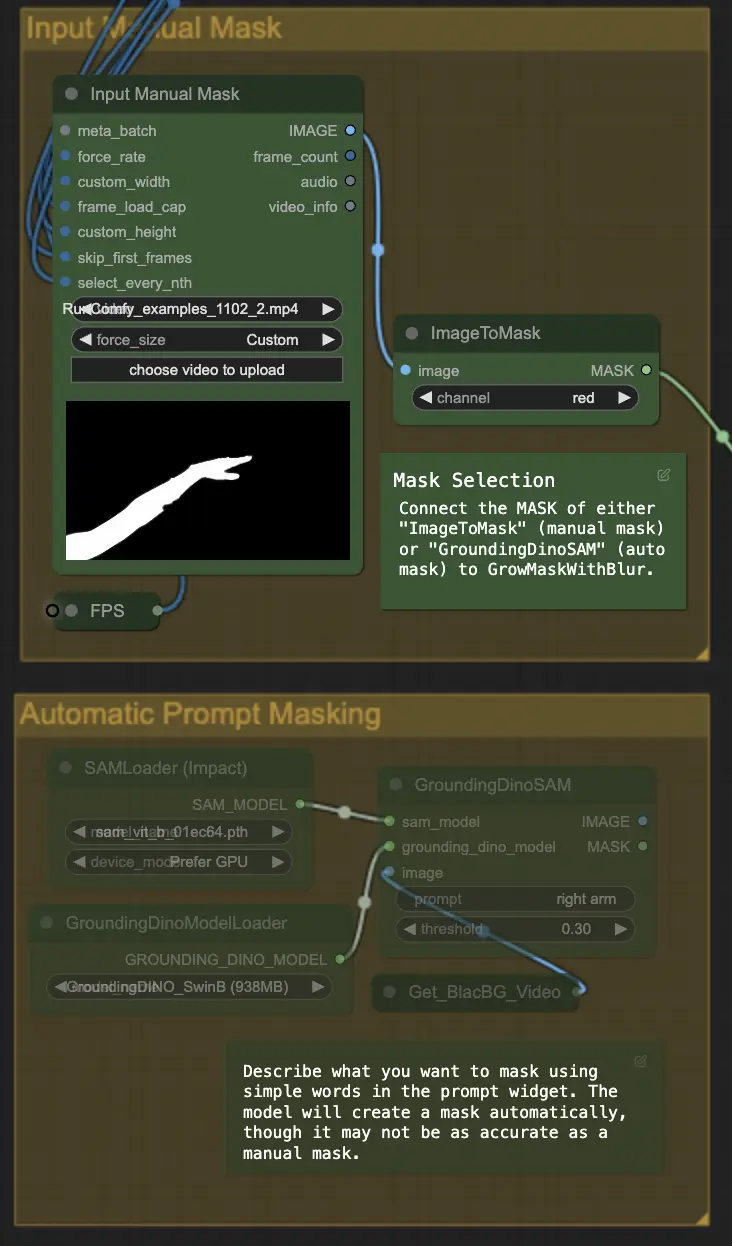
Step 4: Masking Specific Area (Manual Mask or Auto Mask) | ComfyUI Vid2Vid Workflow Part1
이 단계에서는 이전 단계에서 생성된 마스크를 정교화할 수 있습니다. 다른 소프트웨어를 사용하여 특정 영역을 수동으로 마스킹하거나 ComfyUI의 'Segment Anything' 자동 마스크 기능을 사용할 수 있습니다.
- 수동 마스크: 정확한 제어를 위해 ComfyUI 외부의 다른 소프트웨어로 처리해야 합니다.
- 자동 마스크: 자동 마스크 기능을 사용하면 프롬프트 위젯에서 간단한 단어로 마스킹하려는 내용을 설명할 수 있습니다. 모델은 자동으로 마스크를 생성하지만, 수동 마스크만큼 정확하지 않을 수 있습니다.
기본 버전은 수동 마스크를 사용합니다. 자동 마스크를 시도하려면 수동 마스크 그룹을 우회하고 자동 마스크 그룹을 활성화하십시오. 또한 'GroundingDinoSAM' (자동 마스크)의 MASK를 'GrowMaskWithBlur'에 연결하고, 'ImageToMask' (수동 마스크)를 'GrowMaskWithBlur'에 연결하지 마십시오.
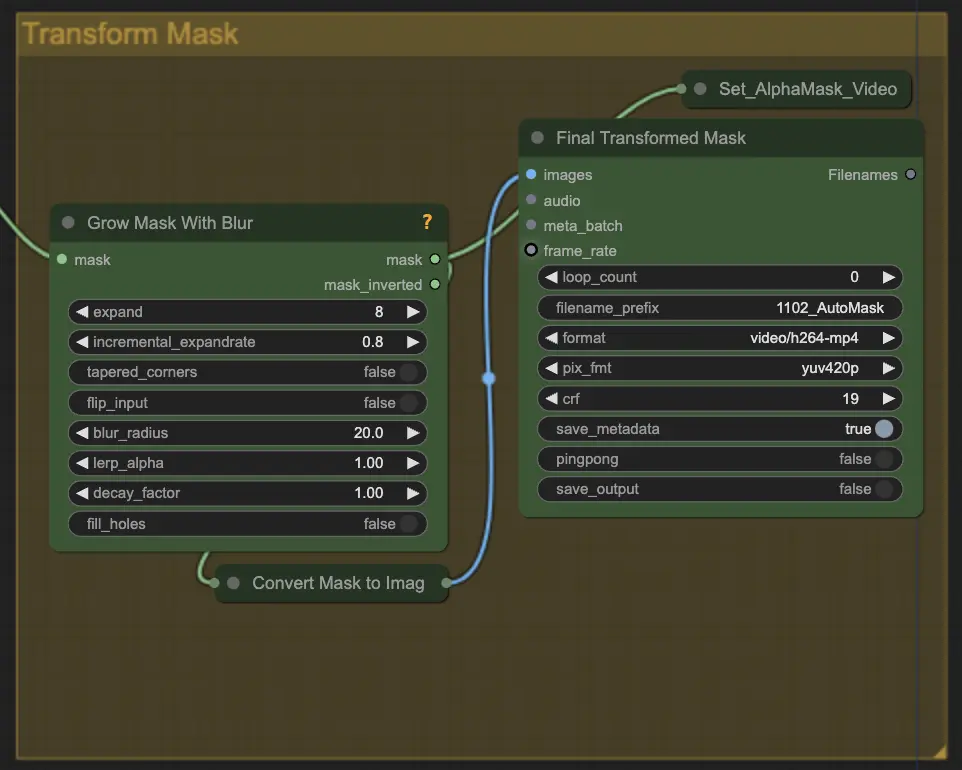
Step 5: Transform Mask | ComfyUI Vid2Vid Workflow Part1
Transform Mask는 마스크를 이미지로 변환하고 원본 마스크에 블러를 추가하는 등의 추가 조정을 허용합니다. 이는 가장자리를 부드럽게 하여 마스크가 이미지의 나머지 부분과 자연스럽게 어우러지도록 도와줍니다.
Step 6: Input Prompt | ComfyUI Vid2Vid Workflow Part1
애니메이션 프로세스를 안내하기 위해 텍스트 프롬프트를 입력하십시오. 프롬프트는 주제의 원하는 스타일, 외관 또는 동작을 설명할 수 있습니다. 이는 애니메이션의 창의적 방향을 정의하는 데 중요하며, 최종 출력이 구상된 예술적 스타일과 일치하도록 보장합니다.
Step 7: AnimateDiff | ComfyUI Vid2Vid Workflow Part1
AnimateDiff 노드는 연속 프레임 간의 차이를 식별하고 이러한 변화를 점진적으로 적용하여 부드러운 애니메이션을 생성합니다. 이는 애니메이션의 운동 일관성을 유지하고 급격한 변화를 줄여 더 유동적이고 자연스러운 외관을 제공합니다.
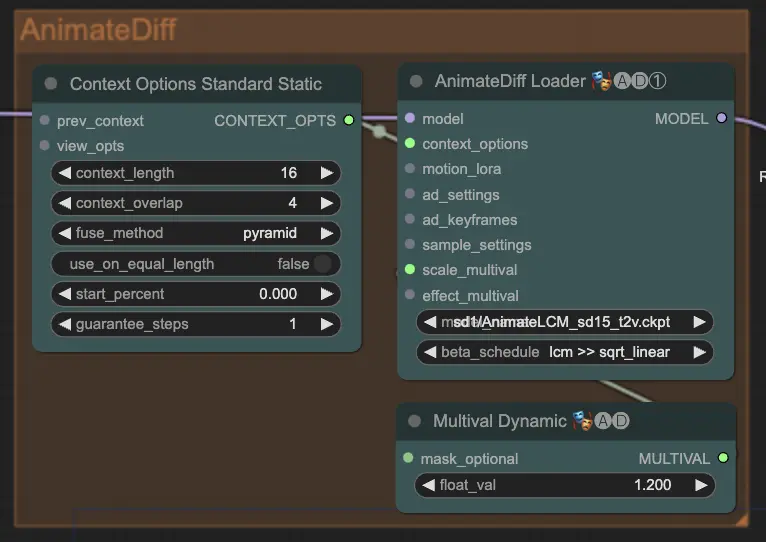
Step 8: IPAdapter | ComfyUI Vid2Vid Workflow Part1
IPAdapter 노드는 입력 이미지를 원하는 출력 스타일이나 기능에 맞게 조정합니다. 여기에는 색상화 및 스타일 전환과 같은 작업이 포함되어 애니메이션의 각 프레임이 일관된 외관을 유지하도록 보장합니다.
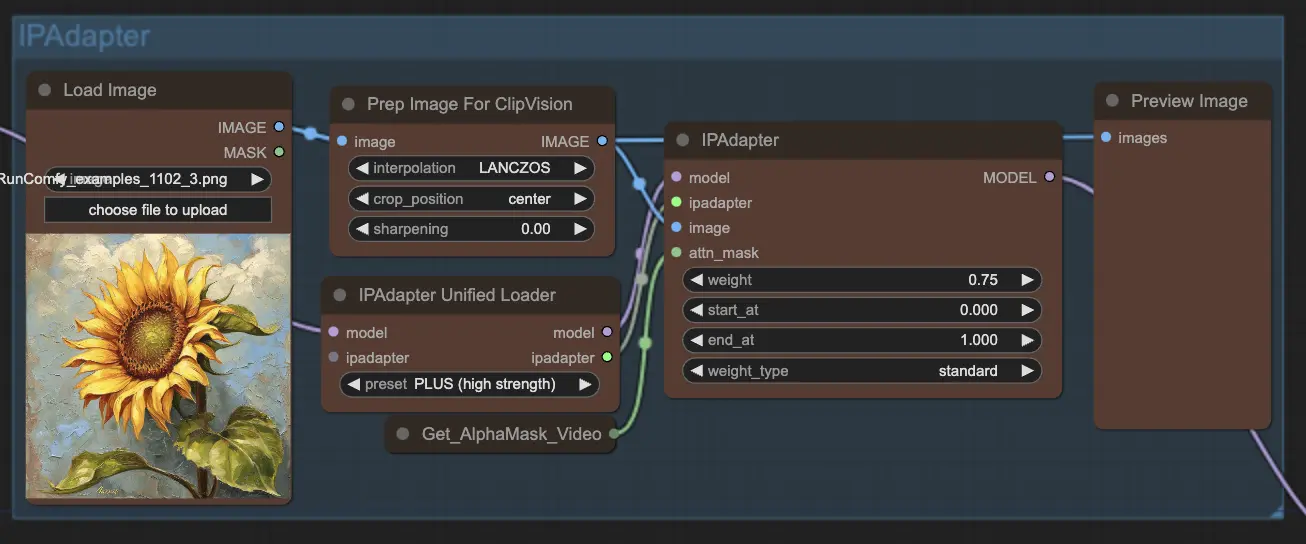
Step 9: ControlNet | ComfyUI Vid2Vid Workflow Part1
ControlNet - v1.1 - Instruct Pix2Pix Version 모델을 사용하여 확산 모델이 추가 입력 조건(예: 에지 맵, 세그멘테이션 맵)을 처리할 수 있도록 향상시킵니다. 이는 텍스트-이미지 생성에서 사전 학습된 모델을 태스크-특정 조건으로 제어하여 소규모 데이터셋으로도 강력한 학습을 가능하게 합니다.
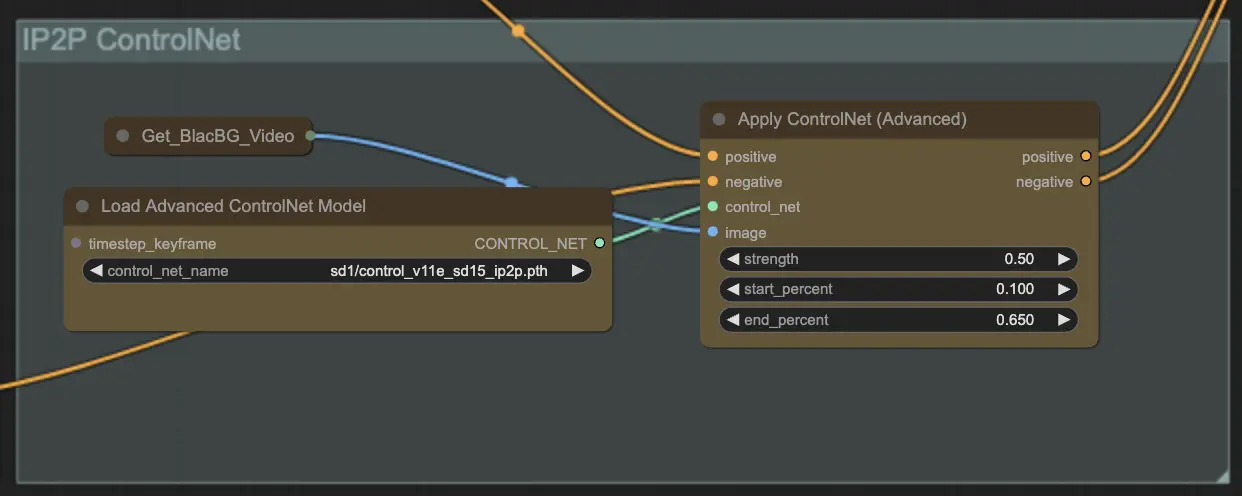
Step 10: Render | ComfyUI Vid2Vid Workflow Part1
Render 단계에서는 처리된 프레임을 최종 비디오 출력으로 컴파일합니다. 이 단계는 개별 프레임을 일관된 애니메이션으로 무결하게 결합하여 내보내기 및 추가 사용을 준비합니다.
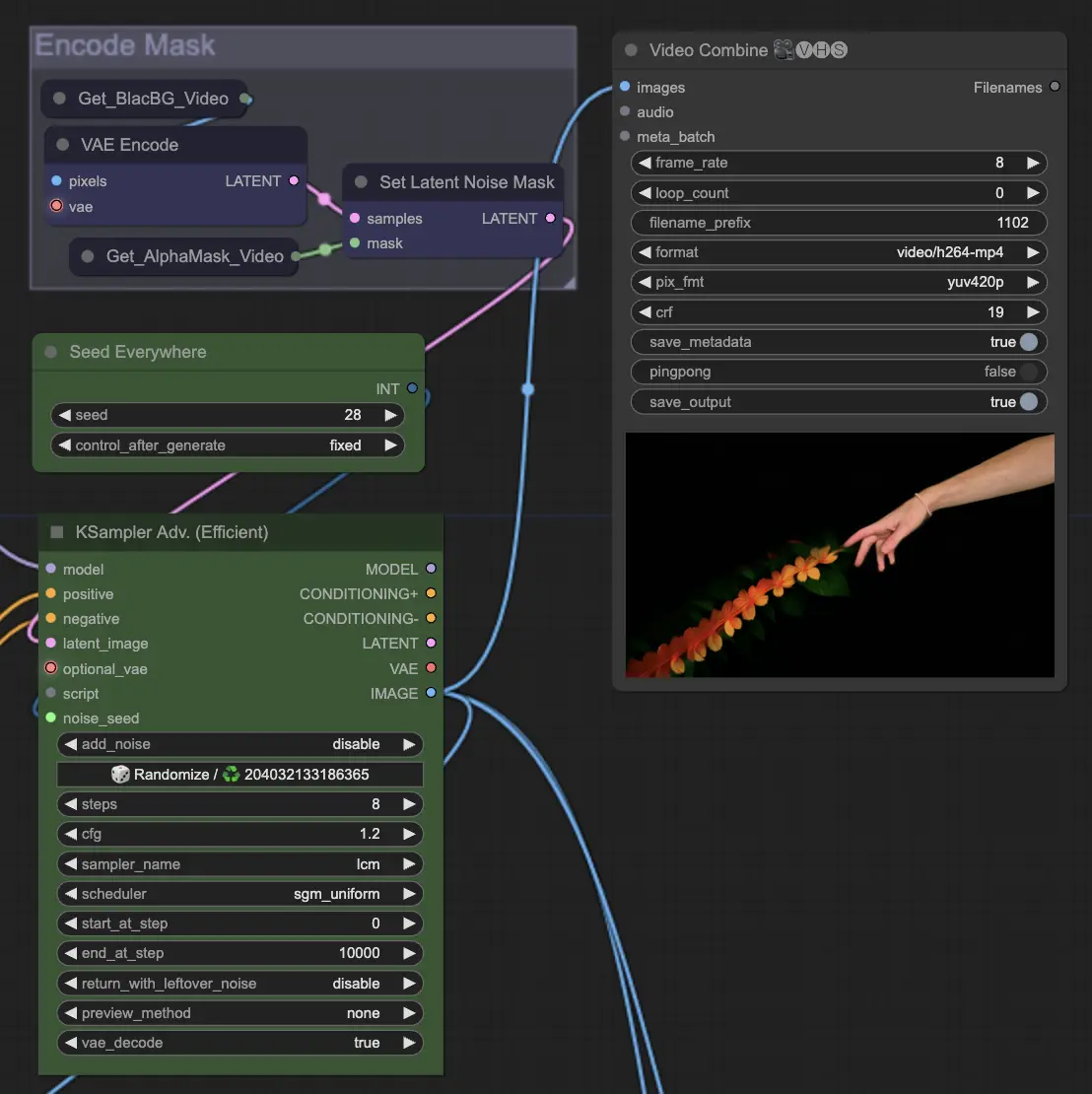
Step 11: Compose Background | ComfyUI Vid2Vid Workflow Part1
이는 애니메이션 주제와 배경을 합성하는 과정입니다. 애니메이션에 정적 또는 동적 배경을 추가하여 주제가 새로운 배경과 원활하게 통합되어 시각적으로 매력적인 최종 제품을 만듭니다.
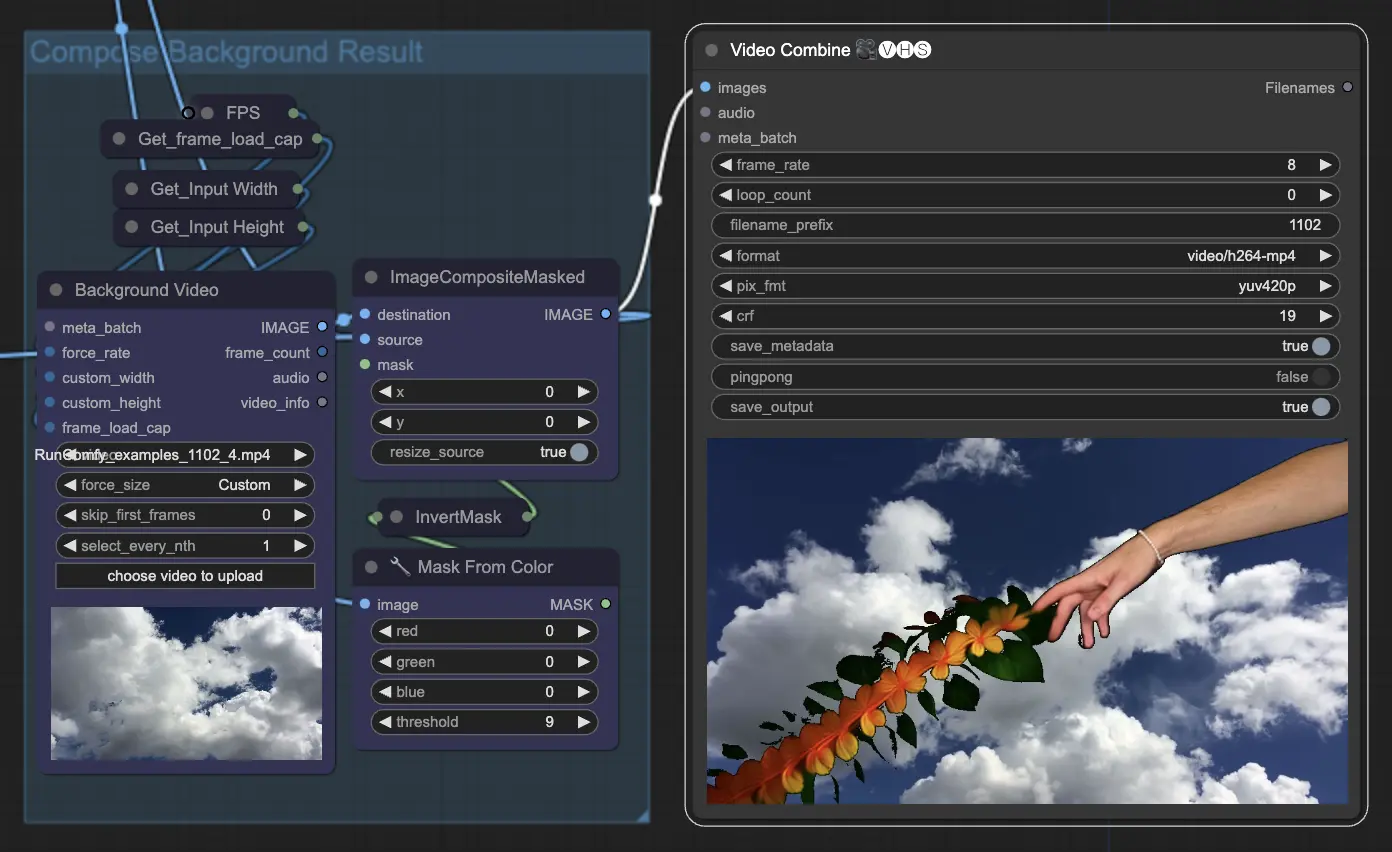
ComfyUI Vid2Vid 워크플로우 Part1을 활용하여 구성 및 마스킹부터 최종 렌더링까지 프로세스의 모든 측면을 정밀하게 제어할 수 있는 정교한 애니메이션을 만들 수 있습니다.


