AnimateDiff + ControlNet + IPAdapter V1 | 일본 애니메이션 스타일
ComfyUI가 AnimateDiff, ControlNet 및 IPAdapter의 힘을 활용하여 일반 비디오를 매력적인 일본 애니메이션 렌디션으로 변환하면서 애니메이션 변환의 스릴을 경험하세요. 이 워크플로는 Lora의 미묘한 터치와 함께 깊이 인식, 소프트 에지 디테일링 및 OpenPose 기술과 같은 고급 기술을 능숙하게 활용하여 각 비디오가 정통 애니메이션 미학으로 재구성되도록 합니다. 원활하고 스타일이 가미된 변신으로 애니메이션 세계에 몰입해보세요.ComfyUI Vid2Vid (Japanese Anime) 워크플로우
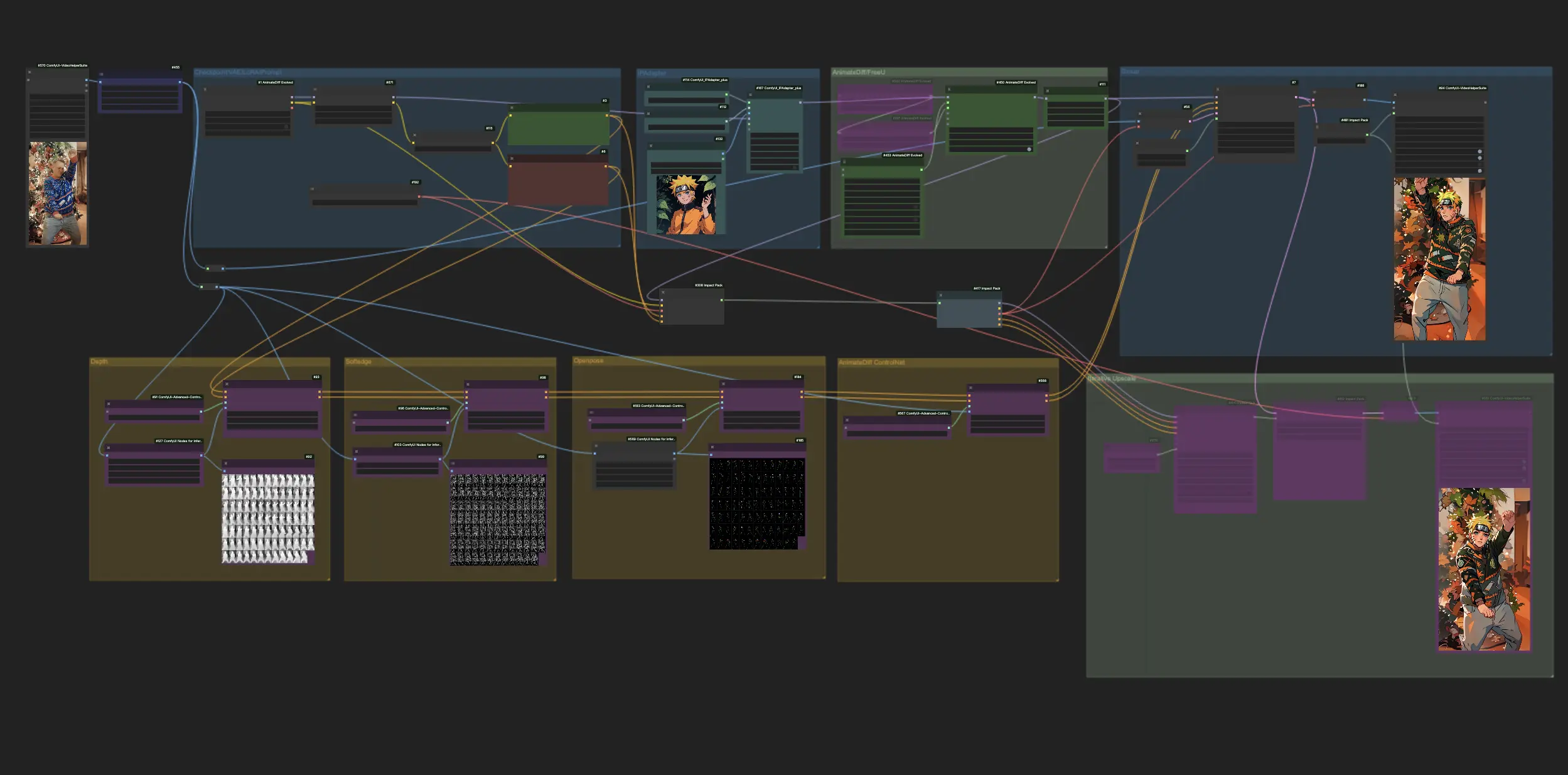
- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
ComfyUI Vid2Vid (Japanese Anime) 예제
ComfyUI Vid2Vid (Japanese Anime) 설명
이 워크플로는 의 영감을 받아 일부 수정되었습니다. 자세한 내용은 그의 YouTube 채널을 방문하세요.
1. ComfyUI 워크플로: AnimateDiff + ControlNet + IPAdapter | 일본 애니메이션 스타일
이 워크플로를 사용하면 AnimateDiff, ControlNet 및 IPAdapter를 사용하여 표준 비디오를 매력적인 일본 애니메이션 작품으로 변환할 수 있습니다. 다양한 체크포인트, LoRA 설정 및 IPAdapter에 대한 참조 이미지를 자유롭게 실험하여 고유한 스타일을 만들어보세요. 애니메이션 세계에서 비디오에 생명을 불어넣는 재미있고 창의적인 방법입니다!
2. AnimateDiff 개요
에 대한 자세한 내용을 확인하세요.
3. ControlNet 사용 방법
3.1. ControlNet 이해하기
ControlNet은 텍스트 기반 이미지 생성 확산 모델에 새로운 수준의 공간 제어를 도입하여 이미지 생성 방식을 혁신합니다. 이 최첨단 신경망 아키텍처는 Stable Diffusion과 같은 거대 모델과 아름답게 협력하여 수십억 장의 이미지에서 축적된 방대한 라이브러리를 활용하여 공간적 뉘앙스를 이미지 생성의 직물에 직접 짜넣습니다. 가장자리 스케치부터 인간 자세 매핑, 깊이 인식 또는 시각적 분할에 이르기까지 ControlNet은 단순한 텍스트 프롬프트의 범위를 넘어서는 방식으로 이미지를 조작할 수 있게 해줍니다.
3.2. ControlNet의 혁신
ControlNet의 핵심은 매우 간단합니다. 먼저 원래 모델의 매개변수 무결성을 보호하여 기본 훈련을 그대로 유지합니다. 그런 다음 ControlNet은 모델의 인코딩 레이어 세트를 복제하지만 "제로 컨볼루션"을 사용하여 훈련된다는 차이점이 있습니다. 이러한 0을 시작점으로 사용한다는 것은 레이어가 새로운 공간 조건을 부드럽게 통합하여 혼란을 일으키지 않으므로 모델이 새로운 학습 경로를 시작하더라도 원래 재능이 보존된다는 것을 의미합니다.
3.3. ControlNet과 T2I-Adapter 이해하기
ControlNet과 T2I-Adapter는 이미지 생성의 조건화에서 중요한 역할을 하며, 각각 고유한 장점을 제공합니다. T2I-Adapter는 특히 이미지 생성 속도를 높이는 측면에서 효율성으로 인정받고 있습니다. 그럼에도 불구하고 ControlNet은 생성 프로세스를 정교하게 안내하는 능력에서 타의 추종을 불허하므로 창작자에게 강력한 도구가 됩니다.
많은 T2I-Adapter 및 ControlNet 모델 간의 기능 중복을 고려할 때 우리의 논의는 주로 ControlNet에 초점을 맞출 것입니다. 그러나 RunComfy 플랫폼에는 사용 편의성을 위해 여러 T2I-Adapter 모델이 사전 로드되어 있다는 점에 유의할 필요가 있습니다. T2I-Adapter를 실험하는 데 관심이 있는 분들은 이러한 모델을 원활하게 로드하여 프로젝트에 통합할 수 있습니다.
ComfyUI에서 ControlNet과 T2I-Adapter 모델 중에서 선택하는 것은 ControlNet 노드의 사용이나 워크플로의 일관성에 영향을 미치지 않습니다. 이러한 통일성은 간소화된 프로세스를 보장하므로 프로젝트 요구 사항에 따라 각 모델 유형의 고유한 이점을 활용할 수 있습니다.
3.4. ControlNet 노드 사용
3.4.1. "Apply ControlNet" 노드 로드
시작하려면 "Apply ControlNet" 노드를 ComfyUI에 로드해야 합니다. 이것은 시각적 요소와 텍스트 프롬프트를 혼합하는 이중 조건 이미지 제작 여정의 첫 번째 단계입니다.
3.4.2. "Apply ControlNet" 노드의 입력 이해
Positive and Negative Conditioning: 최종 이미지를 형성하는 도구입니다. 포용해야 할 것과 피해야 할 것을 결정합니다. 이들을 "Positive prompt"와 "Negative prompt" 슬롯에 연결하여 텍스트 기반 창의적 방향과 동기화합니다.
ControlNet 모델 선택: 이 입력을 "Load ControlNet Model" 노드의 출력에 연결해야 합니다. 여기에서 목표로 하는 특정 특성이나 스타일에 따라 ControlNet 또는 T2IAdaptor 모델을 사용할지 결정합니다. ControlNet 모델에 초점을 맞추고 있지만, 잘 알려진 T2IAdapter를 언급하는 것도 전체적인 관점에서 가치가 있습니다.
이미지 전처리: 이미지를 "ControlNet Preprocessor" 노드에 연결하는 것이 중요합니다. 이는 이미지가 ControlNet에 맞게 준비되도록 하는 데 필수적입니다. 전처리기를 ControlNet 모델과 일치시키는 것이 중요합니다. 이 단계에서는 원본 이미지를 모델의 요구 사항에 맞게 조정합니다. 크기 조정, 색상 변경 또는 필요한 필터 적용 등을 통해 ControlNet에서 사용할 수 있도록 준비합니다.
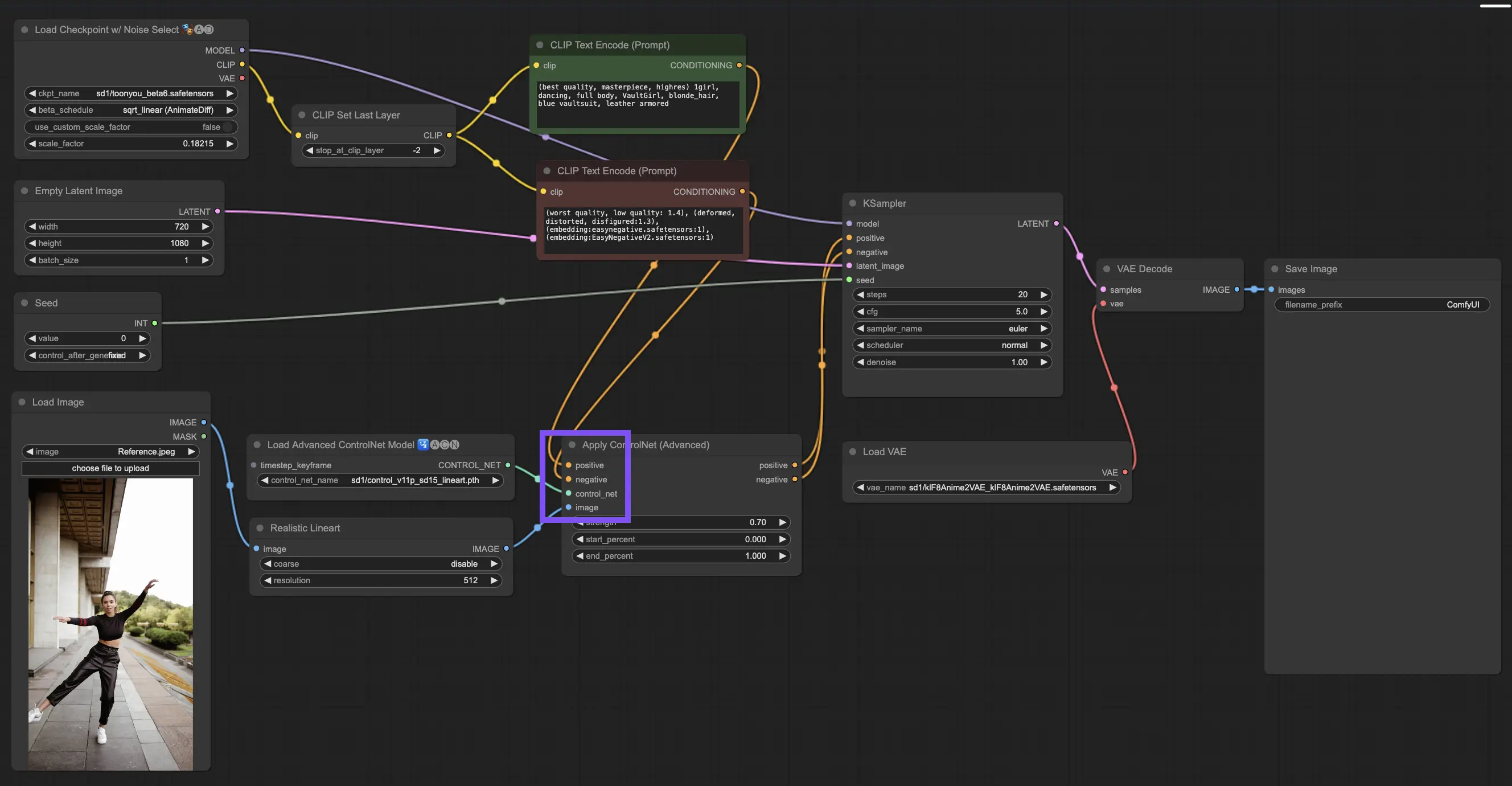
3.4.3. "Apply ControlNet" 노드의 출력 이해
처리 후 "Apply ControlNet" 노드는 ControlNet과 창의적 입력의 정교한 상호 작용을 반영하는 두 가지 출력을 제공합니다: Positive and Negative Conditioning. 이러한 출력은 ComfyUI 내의 확산 모델을 안내하여 다음 선택으로 이어집니다. KSampler를 사용하여 이미지를 정제하거나 더 많은 ControlNet을 쌓아 전례 없는 디테일과 사용자 지정을 추구하는 사람들을 위해 더 깊이 파고드십시오.
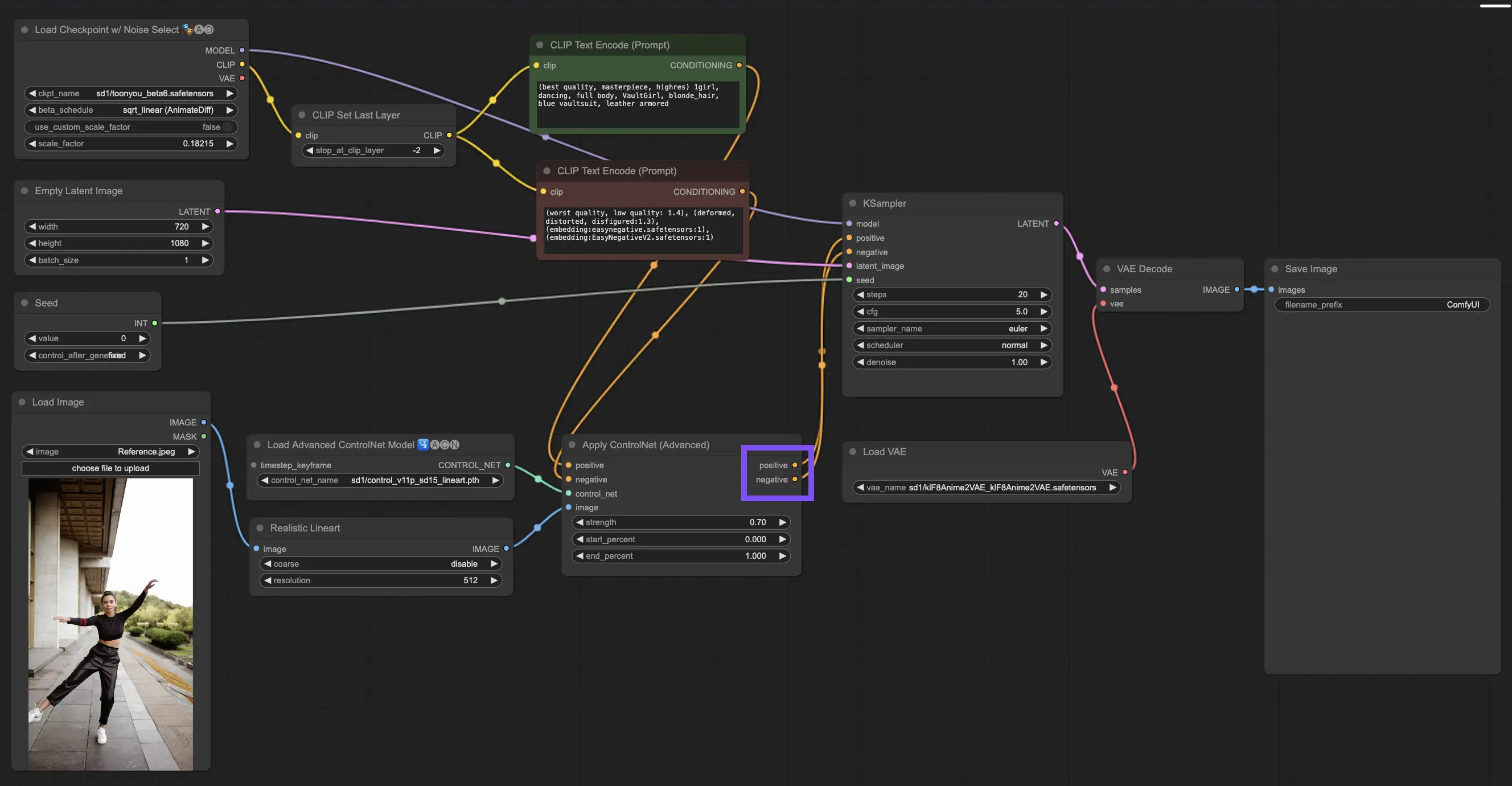
3.4.4. 최상의 결과를 위해 "Apply ControlNet" 조정
Strength 결정: 이 설정은 ControlNet이 결과 이미지에 미치는 영향을 제어합니다. 1.0은 ControlNet의 입력이 완전히 주도권을 잡는 것을 의미하는 반면, 0.0으로 낮추면 ControlNet의 영향 없이 모델이 실행되도록 합니다.
Start Percent 조정: 이것은 확산 프로세스 중 ControlNet이 언제 개입하기 시작하는지를 알려줍니다. 예를 들어 20%의 시작은 5분의 1 지점부터 ControlNet이 자신의 영향력을 발휘하기 시작한다는 것을 의미합니다.
End Percent 설정: Start Percent의 반대편에 위치하며 ControlNet이 언제 물러나는지를 표시합니다. 80%로 설정하면 이미지가 마지막 단계에 근접할 때 ControlNet의 영향력이 사라지며, 마지막 구간에서는 ControlNet의 영향을 받지 않습니다.
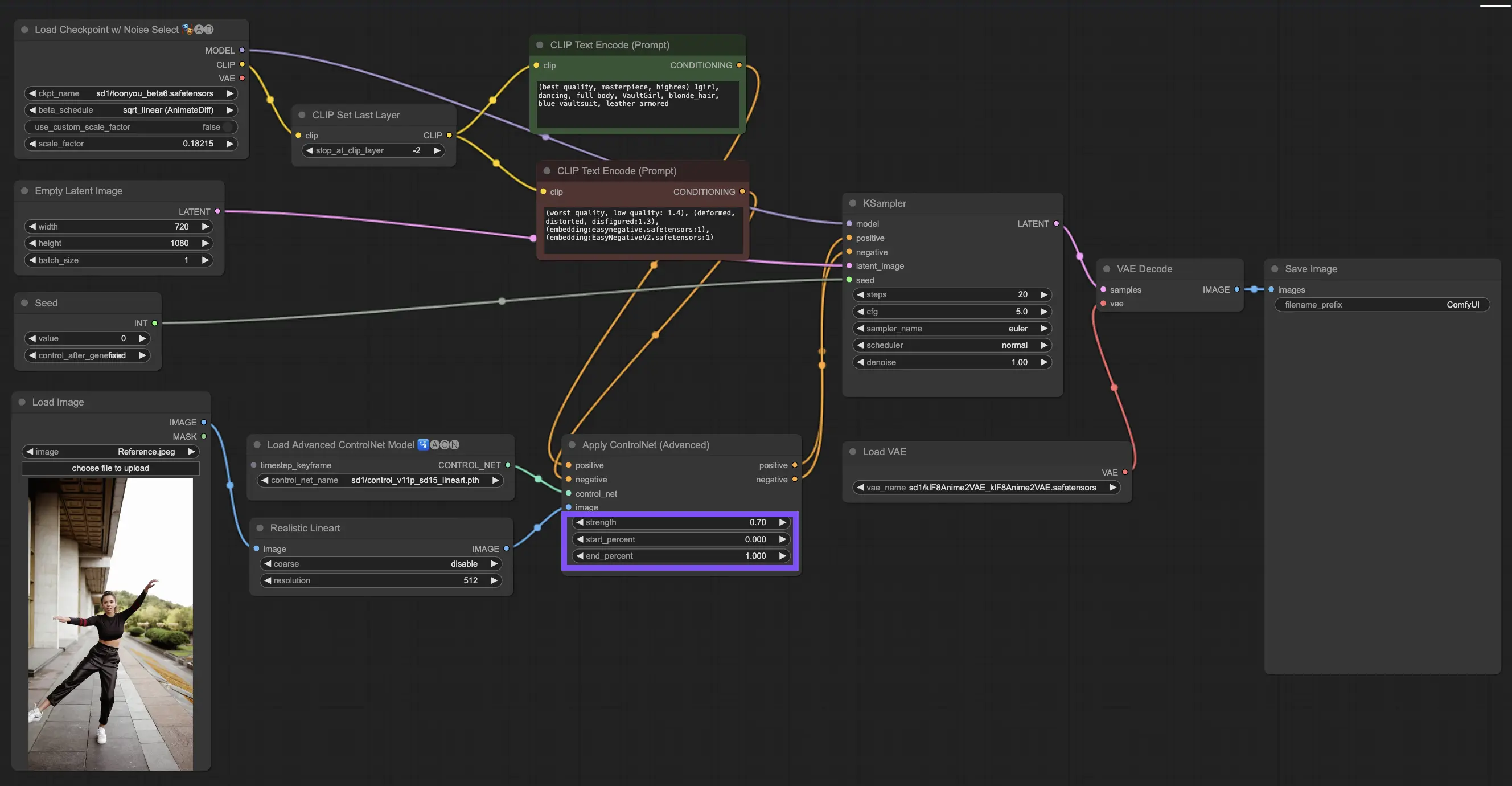
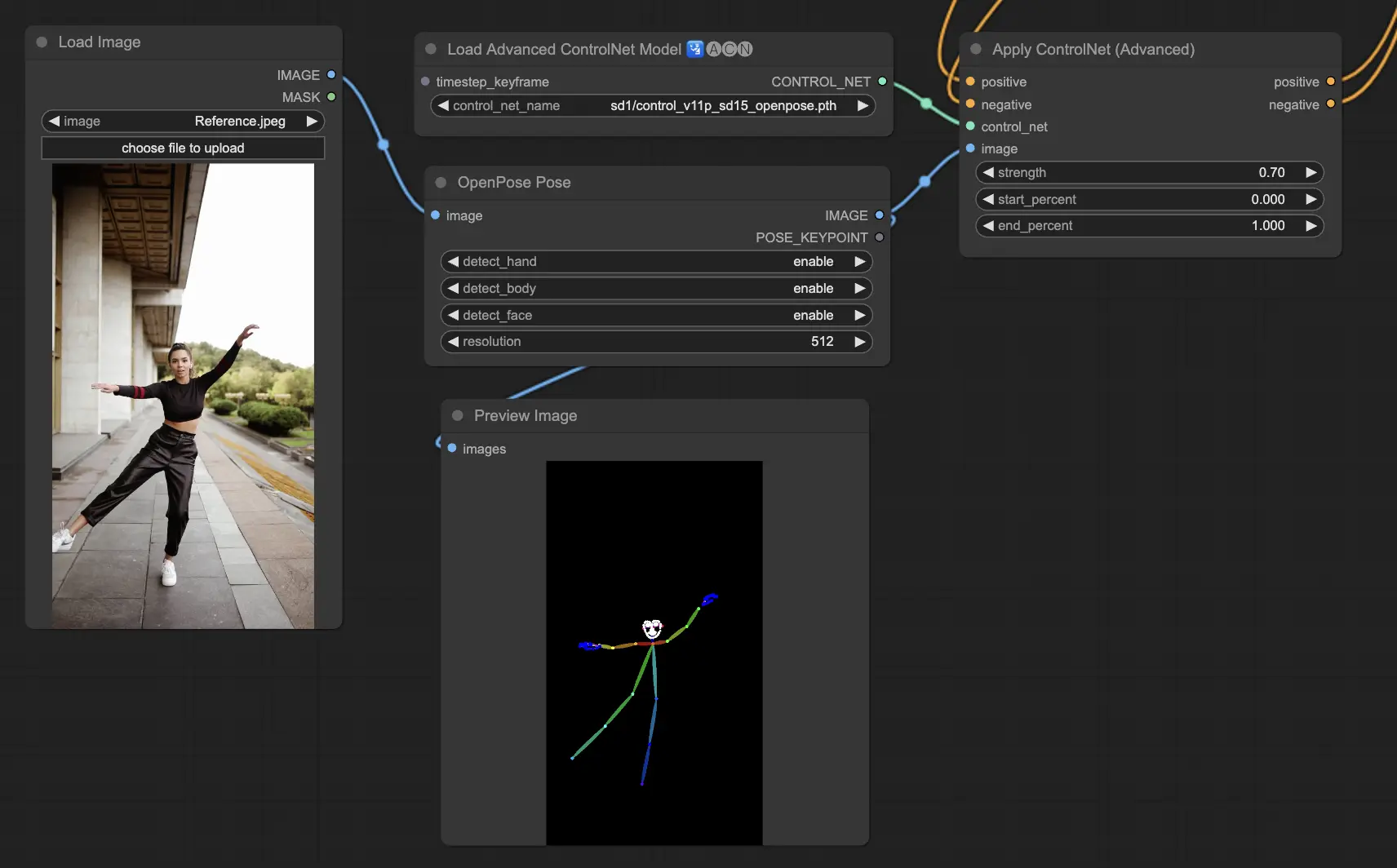
3.5. ControlNet 모델 가이드: Openpose, Depth, SoftEdge, Canny, Lineart, Tile
3.5.1. ControlNet 모델: Openpose
- Openpose (Openpose body라고도 함): 이 모델은 눈, 코, 목, 어깨, 팔꿈치, 손목, 무릎, 발목과 같은 인체의 주요 포인트를 식별하는 ControlNet의 기반이 됩니다. 단순한 인간 포즈를 복제하는 데 완벽합니다.
- Openpose_face: Openpose의 이 버전은 얼굴 표정과 얼굴이 가리키는 방향에 대한 세부적인 분석을 가능하게 하는 얼굴 핵심 포인트 감지 기능을 추가로 제공합니다. 프로젝트가 얼굴 표정을 중심으로 하는 경우 이 모델이 필수적입니다.
- Openpose_hand: Openpose 모델의 이 개선 사항은 손과 손가락 움직임의 세부 사항에 초점을 맞추어 손 제스처와 위치를 자세히 파악하는 데 핵심적입니다. ControlNet 내에서 Openpose가 할 수 있는 범위를 넓힙니다.
- Openpose_faceonly: 얼굴 디테일 분석을 위해 맞춤 설계된 이 모델은 신체 핵심 포인트를 건너뛰고 오직 얼굴 표정과 방향에만 초점을 맞춥니다. 얼굴 특징이 전부인 경우 선택할 모델입니다.
- Openpose_full: 전신, 얼굴 및 손 핵심 포인트 감지를 위해 Openpose, Openpose_face 및 Openpose_hand의 기능을 통합하는 이 올인원 모델은 ControlNet 내에서 포괄적인 인간 포즈 분석을 위한 최고의 선택입니다.
- DW_Openpose_full: Openpose_full을 기반으로 하는 이 모델은 포즈 감지 디테일과 정확도를 향상시키기 위해 추가 개선 사항을 도입합니다. ControlNet 제품군에서 사용할 수 있는 가장발전된 버전입니다.
Preprocessor options include: Openpose or DWpose
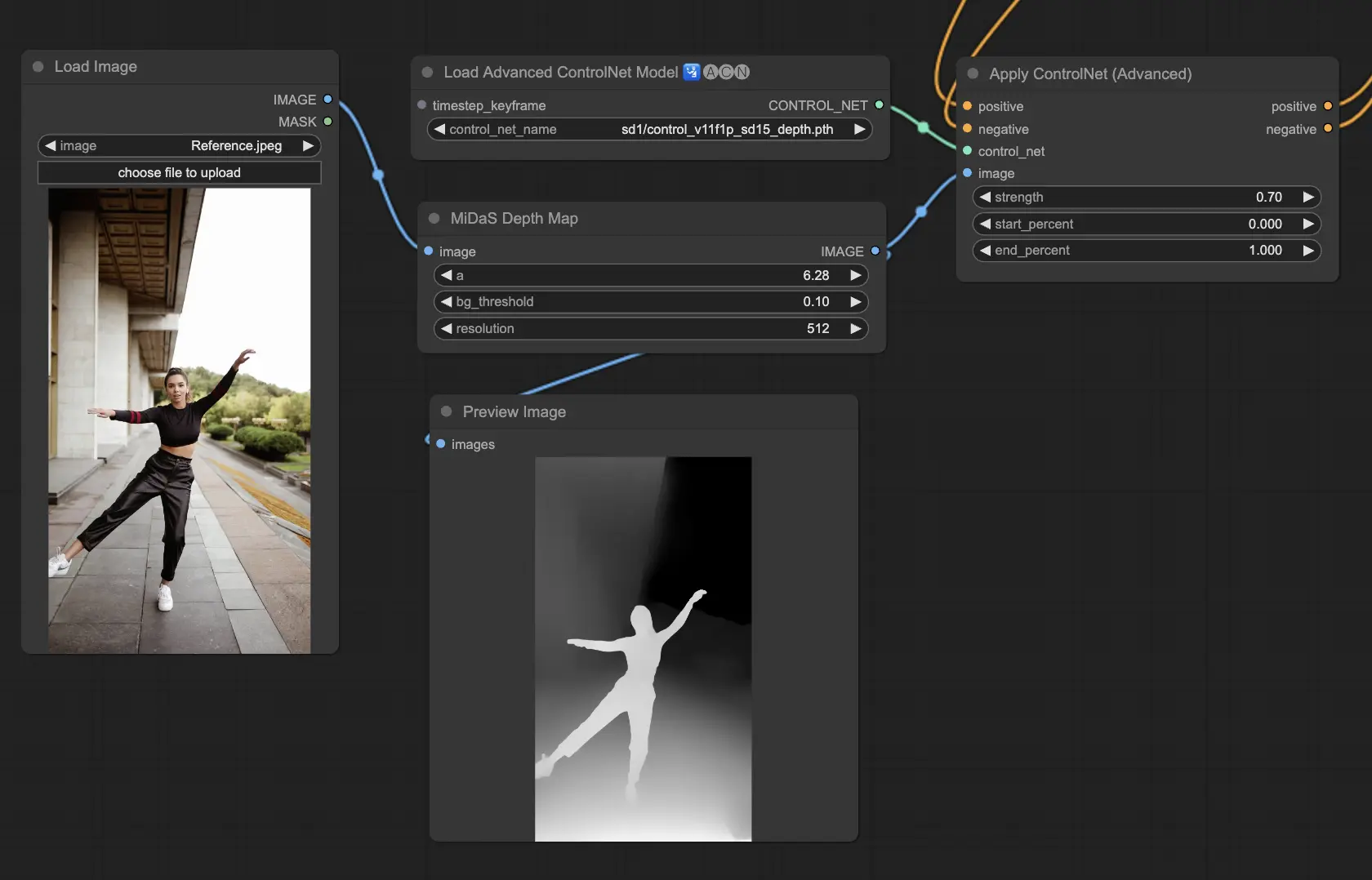
3.5.2. ControlNet 모델: Depth
Depth 모델은 2D 이미지를 사용하여 깊이를 추론하고 이를 그레이스케일 맵으로 표현합니다. 각각은 디테일이나 배경 초점 면에서 장점이 있습니다:
- Depth Midas: 깊이 추정에 대한 균형 잡힌 접근 방식인 Depth Midas는 디테일과 배경 묘사에서 중간 지점을 제공합니다.
- Depth Leres: 배경 요소를 더 두드러지게 포착하면서도 디테일에 중점을 둡니다.
- Depth Leres++: 복잡한 장면에 특히 유용한 깊이 정보의 디테일을 위해 한계를 뚫습니다.
- Zoe: Midas와 Leres 모델의 디테일 수준 사이에서 균형을 찾습니다.
- Depth Anything: 다양한 장면에 대한 다재다능한 깊이 추정을 위한 개선된 모델입니다.
- Depth Hand Refiner: 깊이 맵에서 손의 디테일을 구체적으로 미세 조정하므로 정확한 손 배치가 중요한 장면에 매우 유용합니다.
Preprocessors to consider: Depth_Midas, Depth_Leres, Depth_Zoe, Depth_Anything, MeshGraphormer_Hand_Refiner. 이 모델은 렌더링 엔진의 실제 깊이 맵과의 호환성 및 견고성 면에서 뛰어납니다.
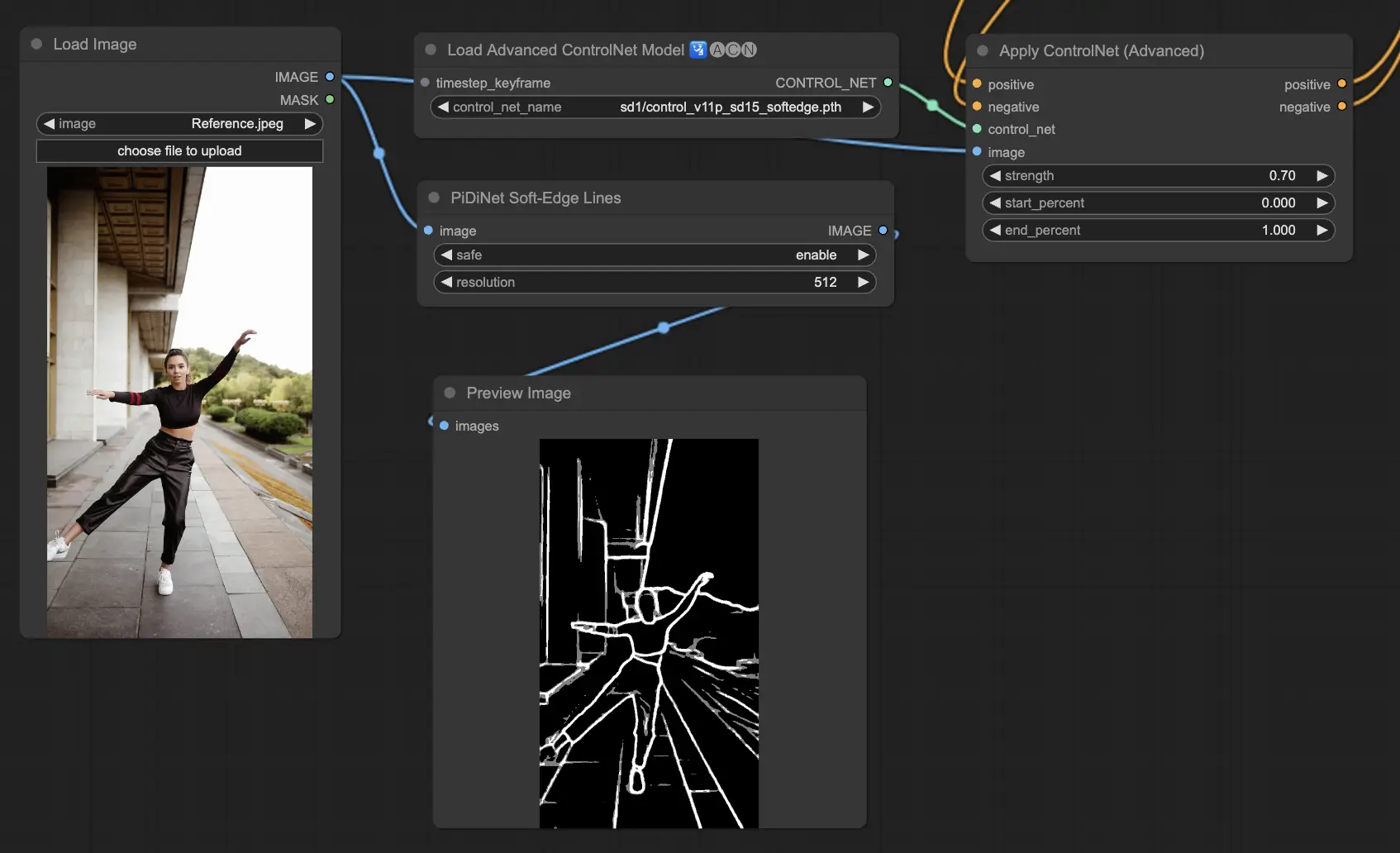
3.5.3. ControlNet 모델: SoftEdge
ControlNet Soft Edge는 자연스러운 모습을 유지하면서 디테일을 향상시키는 더 부드러운 가장자리가 있는 이미지를 생성하도록 제작되었습니다. 정교한 이미지 조작을 위해 최첨단 신경망을 활용하여 광범위한 창의적 제어와 완벽한 통합을 제공합니다.
견고성 면에서: SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED
최고 품질의 결과를 위해: SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
일반적인 권장 사항으로, SoftEdge_PIDI는 일반적으로 우수한 결과를 제공하므로 최선의 선택입니다.
Preprocessors include: SoftEdge_PIDI, SoftEdge_PIDI_safe, SoftEdge_HED, SoftEdge_HED_safe.
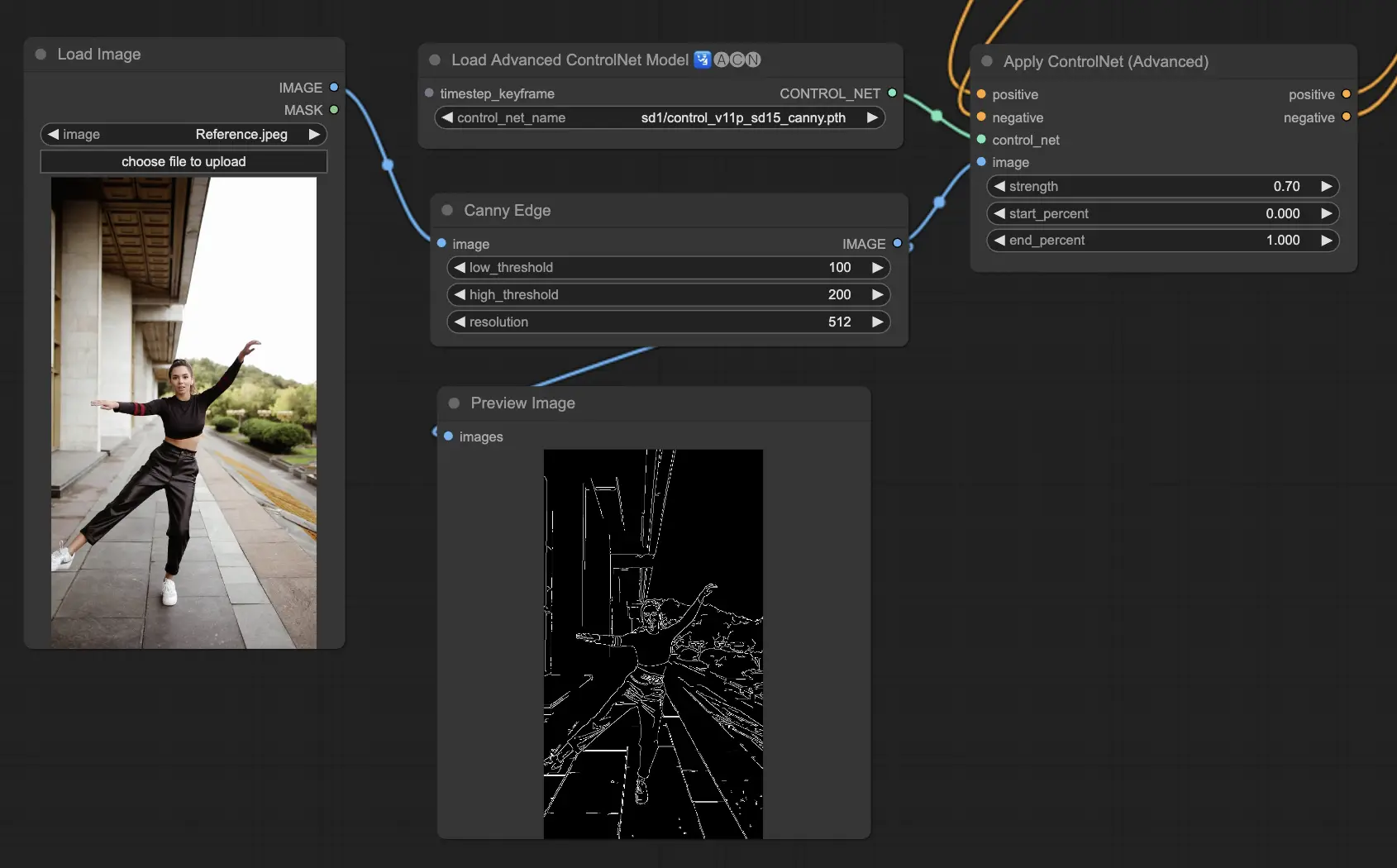
3.5.4. ControlNet 모델: Canny
Canny 모델은 Canny 가장자리 감지를 구현하여 이미지 내의 다양한 가장자리를 강조 표시합니다. 이 모델은 이미지의 전체적인 모습을 단순화하면서 구조적 요소의 무결성을 유지하는 데 탁월하여 스타일화된 예술 작품 제작이나 추가 조작을 위한 이미지 준비에 도움이 됩니다.
Preprocessors available: Canny
3.5.5. ControlNet 모델: Lineart
Lineart 모델은 이미지를 다양한 예술적 응용 분야에 적합한 스타일화된 선 그림으로 변환하는 도구입니다:
- Lineart: 이미지를 선 그림으로 변환하기 위한 표준 선택으로, 다양한 예술적 또는 창의적 노력을 위한 다재다능한 출발점을 제공합니다.
- Lineart anime: 깨끗하고 정확한 애니메이션 스타일의 선 그림을 만들기 위해 맞춤 제작되었으며, 애니메이션 영감을 받은 모습을 목표로 하는 프로젝트에 완벽합니다.
- Lineart realistic: 선 그림에서 더 사실적인 표현을 포착하는 것을 목표로 하며, 사실성을 필요로 하는 프로젝트를 위해 더 많은 디테일을 제공합니다.
- Lineart coarse: 시각적 충격을 위해 더 대담하고 두드러진 선을 강조하며, 대담한 그래픽 진술을 위해 이상적입니다.
Preprocessors available can produce either detailed or more pronounced lineart (Lineart and Lineart_Coarse).
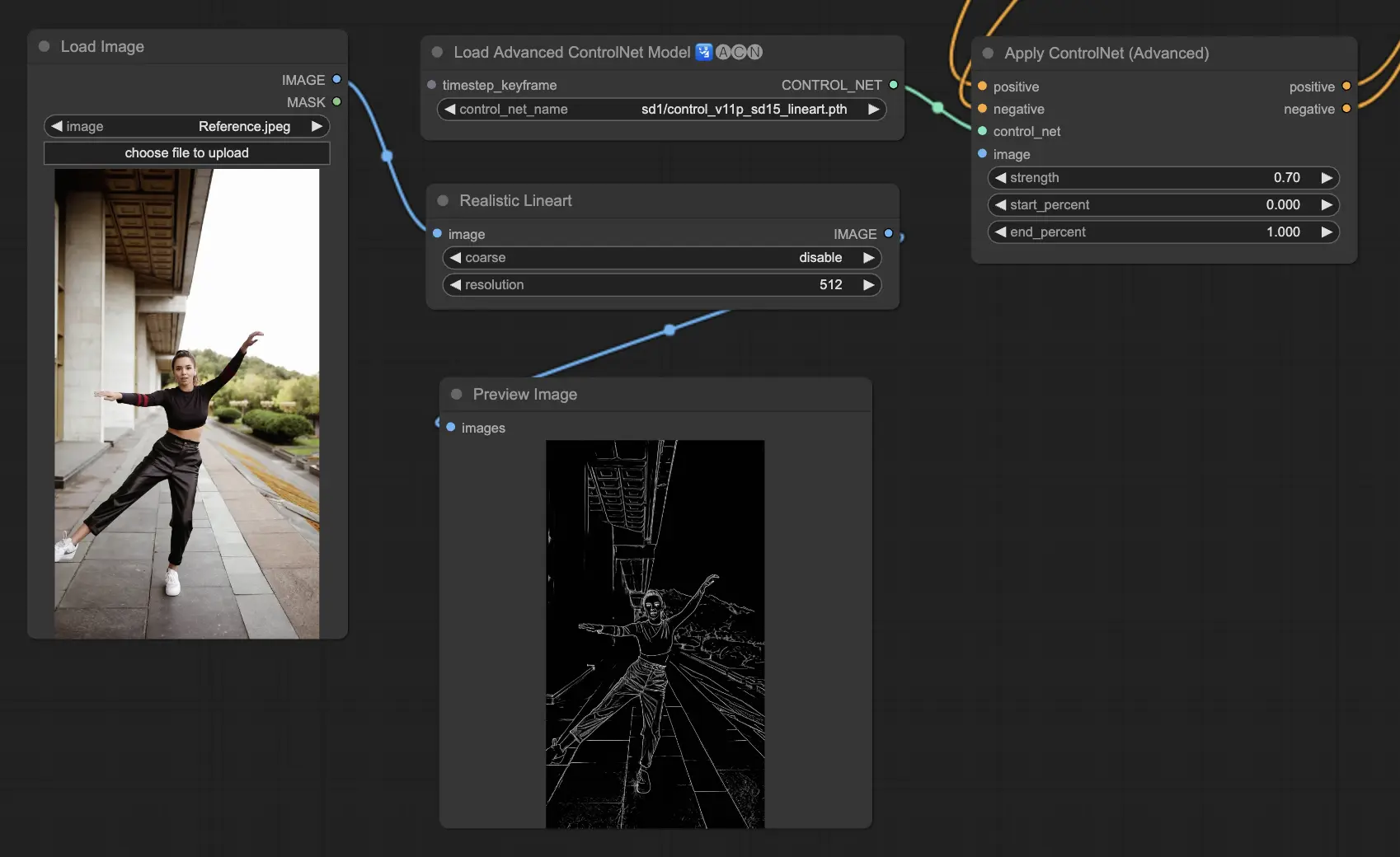
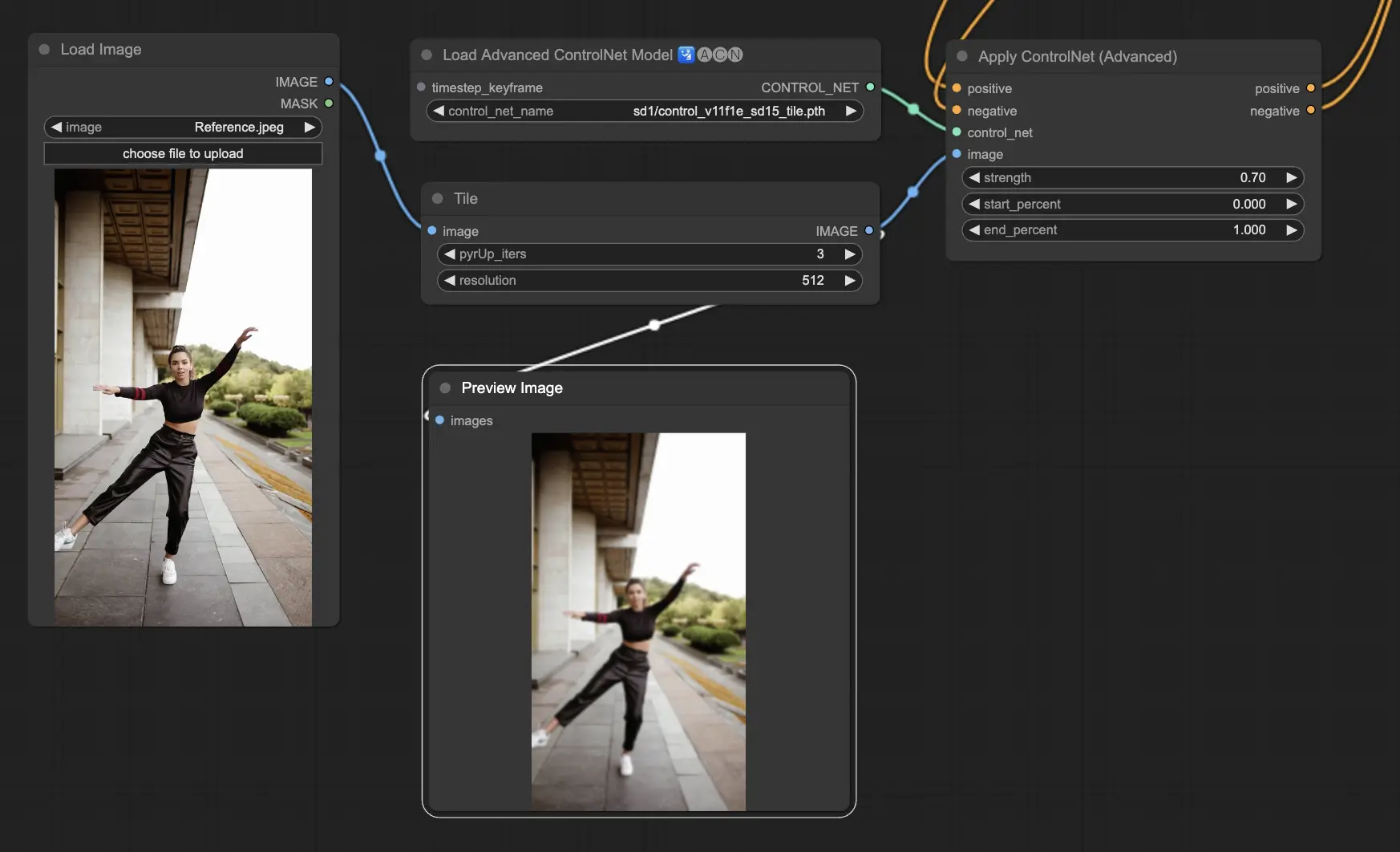
3.5.6. ControlNet 모델: Tile
Tile Resample 모델은 이미지의 디테일을 부각시키는 데 탁월합니다. 특히 업스케일러와 함께 사용하여 이미지 해상도와 디테일을 향상시키는 데 효과적이며, 종종 이미지 텍스처와 요소를 선명하게 하고 풍부하게 하는 데 적용됩니다.
Preprocessor recommended: Tile
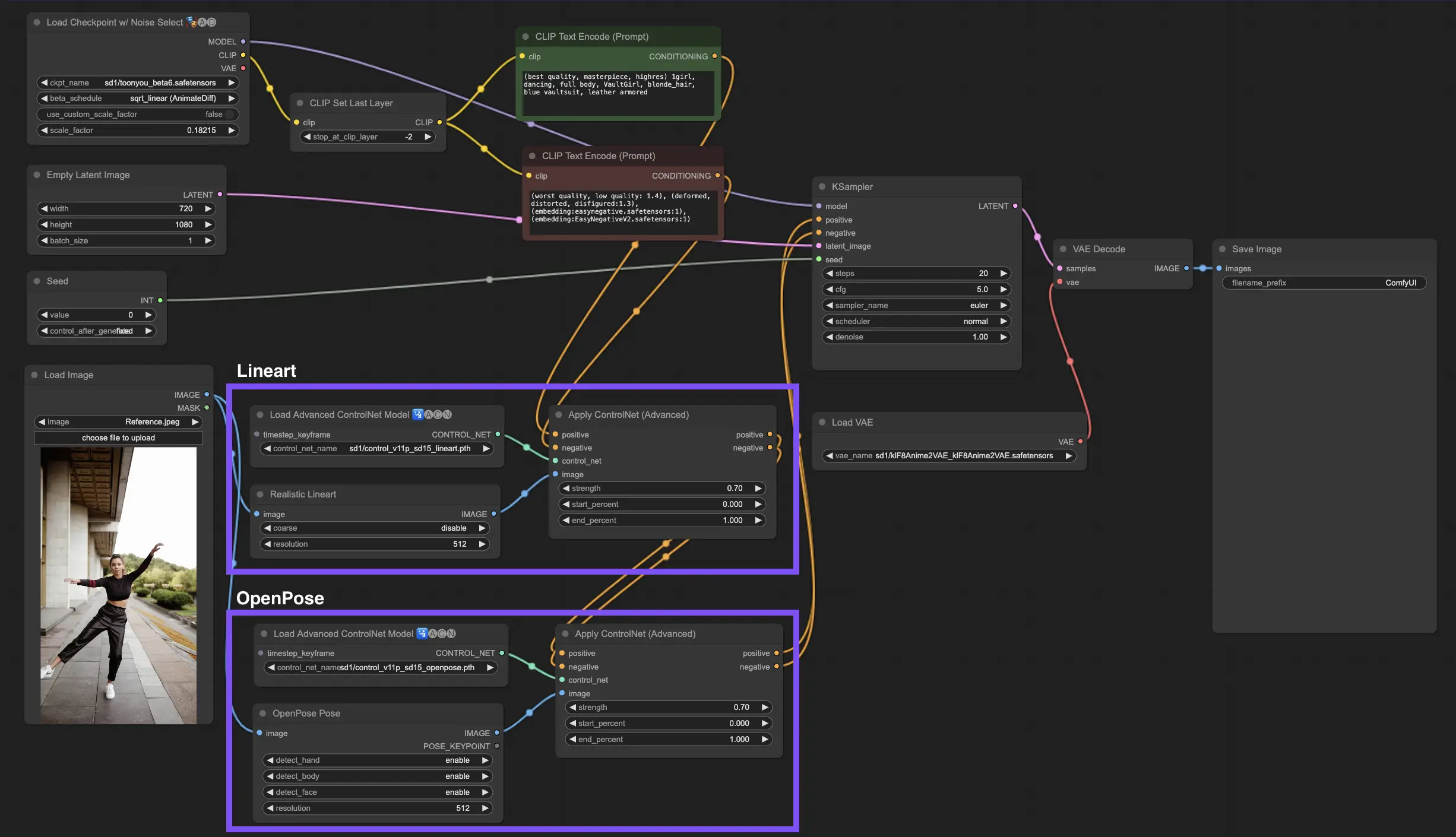
3.6. 다중 ControlNet 사용 가이드
여러 ControlNet 또는 T2I-Adapter를 통합하면 이미지 생성 프로세스에 다양한 조건 유형을 순차적으로 적용할 수 있습니다. 예를 들어, Lineart와 OpenPose ControlNet을 결합하여 디테일을 강화할 수 있습니다.
객체 모양을 위한 Lineart: Lineart ControlNet을 통합하여 이미지의 객체나 요소에 깊이와 디테일을 추가하는 것으로 시작합니다. 이 프로세스에는 포함하려는 객체에 대한 라인아트 또는 캐니 맵을 준비하는 작업이 포함됩니다.
포즈 제어를 위한 OpenPose: 라인아트 디테일링에 이어 OpenPose ControlNet을 활용하여 이미지 내 개인의 포즈를 지시합니다. 원하는 포즈를 포착하는 OpenPose 맵을 생성하거나 획득해야 합니다.
순차적 적용: 이러한 효과를 효과적으로 결합하려면 Lineart ControlNet의 출력을 OpenPose ControlNet에 연결하세요. 이 방법은 피사체의 포즈와 객체의 모양이 생성 프로세스 동안 동시에 안내되어 모든 입력 사양과 조화롭게 일치하는 결과를 만들어냅니다.
4. IPAdapter 개요
에 대한 자세한 내용을 확인하세요.
