
ComfyUI ControlNet 진화: Depth, OpenPose, Canny, Lineart, Softedge, Scribble, Seg... 포함
Updated: 5/16/2024
안녕하세요! 이 가이드에서는 ComfyUI에서 ControlNet의 흡미로운 세계로 빠져들어 가보려 합니다. 함께 살펴보면서 ControlNet이 어떤 가능성을 제공하는지, 그리고 여러분의 프로젝트에 도움이 될 수 있는지 알아봅시다!
다룰 내용은 다음과 같습니다:
1. ControlNet이란 무엇인가요?
2. ControlNet의 기술적 원리
3. ComfyUI ControlNet의 기본 사용법
- 3.1. ComfyUI에서 "Apply ControlNet" 노드 불러오기
- 3.2. "Apply ControlNet" 노드의 입력
- 3.3. "Apply ControlNet" 노드의 출력
- 3.4. "Apply ControlNet" 세부 조정 매개변수들
4. ComfyUI ControlNet의 고급 기능 사용법 - Timestep Keyframes
5. 다양한 ControlNet/T2IAdaptor 모델들: 상세 설명
- 5.1. ControlNet Openpose
- 5.2. ControlNet Tile
- 5.3. ControlNet Canny
- 5.4. ControlNet Depth
- 5.5. ControlNet Lineart
- 5.6. ControlNet Scribbles
- 5.7. ControlNet Segmentation
- 5.8. ControlNet Shuffle
- 5.9. ControlNet Inpainting
- 5.10. ControlNet MLSD
- 5.11. ControlNet Normalmaps
- 5.12. ControlNet Soft Edge
- 5.13. ControlNet IP2P (Instruct Pix2Pix)
- 5.14. T2I Adapter
- 5.15. 기타 인기 ControlNet: QRCode Monster와 IP-Adapter
6. 여러 개의 ControlNet을 동시에 사용하는 방법
7. 지금 바로 ComfyUI ControlNet 체험하기!
🌟🌟🌟 ComfyUI Online - ControlNet 워크플로우를 지금 바로 경험하세요 🌟🌟🌟
ControlNet 워크플로우를 탐색해 보고 싶다면 아래 ComfyUI 웹을 사용해보세요. 핵심이 되는 모든 고객 노드와 모델이 이미 포함되어 있으므로 복잡한 설정 없이도 쉽게 참신성을 발휘할 수 있어요. 바로 ControlNet의 기능을 테스트해보거나, 이 튜토리얼을 계속 따라가면서 ControlNet을 효과적으로 사용하는 법도 배울 수 있습니다.
더 고급 기능의 프리미엄 워크플로우가 궁금하다면 이곳 🌟ComfyUI 워크플로우 목록🌟을 참고하세요.
1. ControlNet이란 무엇인가요?
ControlNet은 텍스트-투-이미지 생성 모델의 기능을 크게 높여 주는 혁신적인 기술로, 이미지 생성 과정에 공간적 조건을 추가할 수 있습니다. ControlNet은 Stable Diffusion과 같은 대형 사전 학습 모델과 잘 통합되는 신경망 아키텍처입니다. 이 모델은 여러 조건들을 활용하는데, 예를 들어 이미지 가장자리, 사람 동작, 깊이 및 분할 지도 등의 정보를 포함하여 사용자가 오직 텍스트 프롬프트만으로는 불가능했던 방식으로 이미지 생성을 안내할 수 있게 합니다.
2. ControlNet의 기술적 원리
ControlNet의 강력한 점은 특이한 방식에 있습니다. 초기에는 기존 모델의 파라미터를 고정시켜 원래의 학습 내용이 변경되지 않도록 합니다. 그 다음 ControlNet은 모델의 인코딩 레이어를 복제하며 이를 "영 반도체"로 학습시킵니다. 이 특수 설계된 레이어는 가중치가 0으로 시작하며 새로운 공간 조건들을 주의 깊게 통합합니다. 이러한 방식은 어떤 이상한 잔음도 간섭하지 않으며 모델의 원래 능력은 유지하면서 새로운 학습 경로를 열어줍니다.
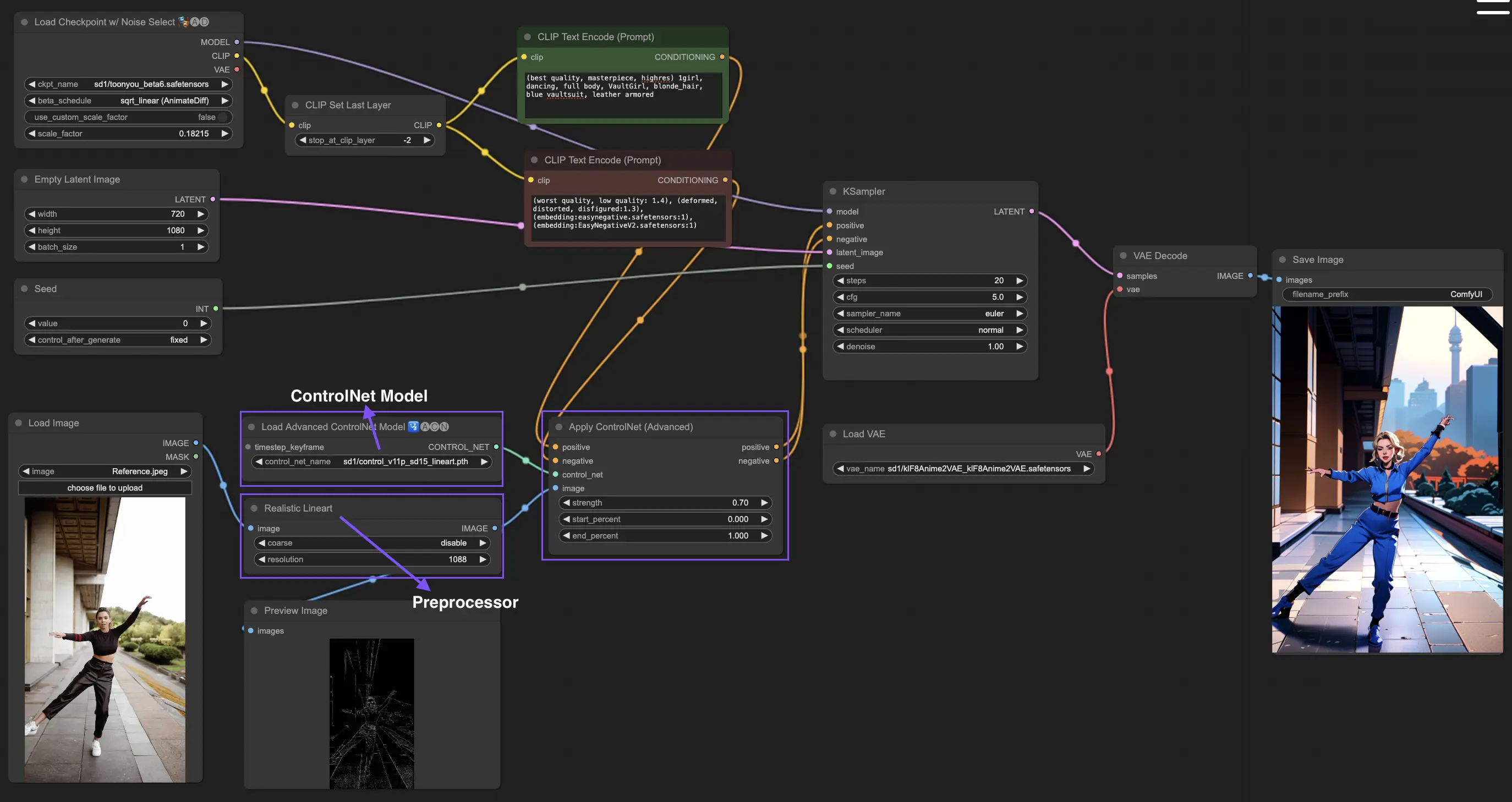
3. ComfyUI ControlNet의 기본 사용법
일반적으로 stable diffusion 모델은 텍스트 프롬프트를 사용하여 생성된 이미지가 프롬프트의 내용과 일치하도록 조정합니다. ControlNet은 여기에 추가로 이미지 생성을 더욱 정밀하게 조종하는 방법을 제공합니다.
3.1. ComfyUI에서 "Apply ControlNet" 노드 불러오기
이 단계에서는 ComfyUI 워크플로우에 ControlNet을 통합하여 이미지 생성에 추가 조건을 적용할 수 있습니다. 이는 텍스트 프롬프트와 함께 시각적 안내를 통합하는 기반을 만듭니다.
3.2. "Apply ControlNet" 노드의 입력
Positive 와 Negative Conditioning: 이들 입력은 원하는 결과와 피해야 할 부분을 정의하는데 필수적입니다. 각각 "Positive prompt"와 "Negative prompt"에 연결되어 텍스트 조건 부분과 동기화됩니다.
ControlNet Model: "Load ControlNet Model" 노드의 출력과 연결되어야 합니다. 이 단계는 ControlNet 또는 T2IAdaptor 모델을 선택하여 워크플로우에 통합하는데 필수적입니다. 이로써 선택한 모델이 제공하는 특정 가이드라인을 따라 생성 모델이 혜택을 받게 됩니다. ControlNet이든 T2IAdaptor든 각 모델은 특정한 데이터 유형이나 스타일에 맞추어 이미지 생성에 영향을 끼치도록 첤저히 학습됩니다. 많은 T2IAdapter 모델들의 기능이 ControlNet 모델들과 명확히 관련되어 있기 때문에, 우리는 이후의 논의에서 ControlNet 모델을 주로 다루겠습니다. 다만 완전성을 위해 몇 가지 유명한 T2IAdapter도 간략히 소개하겠습니다.
Preprocessor: "image" 입력은 반드시 "ControlNet Preprocessor" 노드와 연결되어야 합니다. 이 노드는 사용하고자 하는 ControlNet 모델에 맞춰 이미지를 적절히 변환하는 핵심 역할을 합니다. 이 단계를 통해 원래 이미지는 필요에 맞게 조정되어 예를 들어 포맷, 크기, 색깔이 변경되거나 특정 필터가 적용되어 ControlNet이 이를 활용하는데 최적화됩니다. 이러한 전처리 단계를 거치면 원래의 이미지는 수정된 이미지로 대체되며 ControlNet은 이를 이용하게 됩니다. 매우 중요한 것은 선택한 ControlNet 모델에 맞는 올바른 Preprocessor를 사용하는 것입니다. 이를 통해 입력 이미지들이 ControlNet 과정에 정확히 준비될 수 있습니다.
3.3. "Apply ControlNet" 노드의 출력
"Apply ControlNet" 노드에서는 Positive 와 Negative Conditioning이라는 두 가지 중요한 출력을 생성합니다. ControlNet과 시각적 안내의 영향을 받은 이들 출력은 ComfyUI에서 생성 모델의 행동을 조종하는데 핵심적인 역할을 합니다. 이어서 두 가지 선택이 가능한데, 최종 이미지를 추가로 가꾸기 위해 바로 KSampler로 이동하여 샘플링 단계를 거칠 수 있습니다. 또는 더 높은 수준의 세부사항과 사용자 조정을 원하는 사람을 위해 추가적인 ControlNet을 적용하는 과정을 계속 진행할 수도 있습니다. 이러한 추가 ControlNet 결합은 이미지의 속성을 보다 세밀하게 조종할 수 있는 최상의 도구가 되어, 자신의 시각적 결과물에서 가장 정밀한 수준의 콘트롤을 원하는 작가들에게 강력한 옵션을 제공합니다.
3.4. "Apply ControlNet" 세부 조정 매개변수들
strength: 이 매개변수는 ComfyUI에서 생성된 이미지에 대한 ControlNet의 효과 세기를 결정합니다. 1.0으로 설정하면 ControlNet의 안내가 생성 모델의 결과에 최대한 영향을 끼치게 됩니다. 반면 0.0으로 하면 ControlNet의 효과가 전혀 없는 것으로 간주됩니다.
start_percent: 이 매개변수는 생성 프로세스의 얼마나 진행됐을 때 ControlNet이 영향을 주기 시작할지 지정합니다. 예를 들어 20%로 설정하면 생성 과정의 20% 지점부터 ControlNet의 안내가 적용되기 시작합니다.
end_percent: "Start Percent"와 동일하게 "End Percent" 매개변수는 ControlNet의 영향이 중단되는 지점을 정의합니다. 예를 들어 80%로 설정하면 생성 과정이 80% 진행된 시점에서 ControlNet의 안내 효과가 중단되어 마지막 단계는 영향을 받지 않게 됩니다.
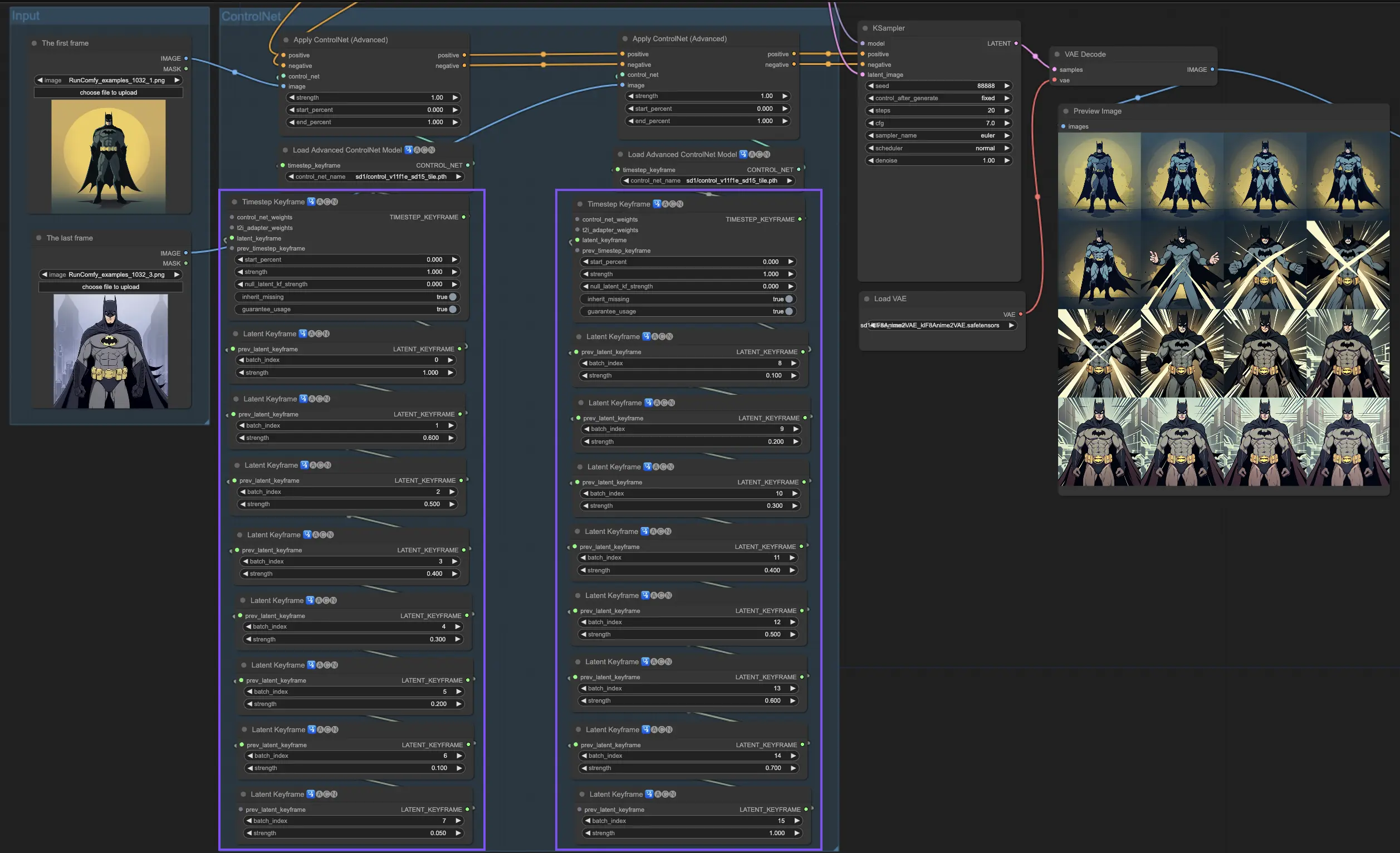
4. ComfyUI ControlNet의 고급 기능 사용법 - Timestep Keyframes
ControlNet의 Timestep Keyframes 기능은 시간과 진행 과정이 중요한 애니메이션이나 변화하는 이미지 등의 AI 생성 콘텐츠에서 미세한 조정을 가능케 합니다. 관련된 주요 매개변수에 대해 자세히 설명드려 이들을 효과적으로 활용할 수 있도록 도움을 드리겠습니다.
prev_timestep_kf: prev_timestep_kf는 순서상 이전 keyframe과 연결되는 것으로 생각하면 됩니다. keyframe을 연결함으로써 자연스러운 전환이나 스토리보드를 만들어 AI 생성 과정의 단계별 진행을 유도할 수 있게 해줄 수 있습니다. 이로써 각 단계가 논리적으로 다음으로 연결되도록 보장됩니다.
cn_weights: cn_weights는 생성 과정의 다양한 단계에서 ControlNet 내의 특정 특징들을 조정하여 최종 결과물을 세밀하게 조정하는데 유용합니다.
latent_keyframe: latent_keyframe은 생성 과정의 특정 단계에서 AI 모델의 각 부분이 최종 결과에 얼마나 강하게 영향을 끼칠지 조정할 수 있도록 해줍니다. 예를 들어 과정이 진행될수록 고화질의 세부사항이 더욱 부각되어야 하는 이미지를 생성한다면, 마지막 keyframe에서 그런 세부사항을 담당하는 모델 부분(latent)의 세기를 높일 수 있습니다. 반면 시간이 지날수록 특정 요소가 배경으로 흰듯이 에져야 한다면, 뒤에 나오는 keyframe에서 그 세기를 점점 낮춰줄 수 있죠. 이러한 미세 조려는 방식은 다이내믹한 반복적인 이미지나 정확한 시간 흐름과 진행이 중요한 프로젝트에서 매우 유용합니다.
mask_optional: 이미지에서 특정 부분에만 ControlNet의 영향을 집중시키려면 attention mask를 스폿라이트처럼 활용할 수 있습니다. 씬에서 배역을 강조하거나 배경 요소를 부각시키는 등, 이러한 mask들은 AI의 주의를 원하는 부분에 정확히 모아주도록 할 수 있는데 이는 고르게 적용될 수도 있고 박도에 따라 영향을 끼칠 수도 있습니다.
start_percent: start_percent는 전체 생성 과정 중 어느 시점에서 현재 keyframe이 등장할지 알려줍니다. 이는마치 배우가 공연에서 특정 순간에 등장하도록 하는 것와 같은 개념이에요.
strength: strength는 전반적인 수준에서 ControlNet의 영향력을 제어해주는 매개변수입니다.
null_latent_kf_strength: 이 keyframe에서 명시적으로 설정하지 않은 생성 개체(latent)에 대해서 전역적으로 적용될 기본 세기를 지정합니다. 이러한 설정을 통해 생성 과정 중 설정하지 않은 부분도 무시되지 않고 전체적인 코히런스를 유지할 수 있습니다.
inherit_missing: inherit_missing을 활성화하면 이 keyframe이 설정된 각 문단(그레이드라고 생각)에서, 앞 keyframe의 설정을 따라가는 부분(그레이드를 받는 부분이라고 생각)을 공유할 수 있습니다. 이는 동일한 조정을 반복하지 않아도 연속성과 일관성을 보장해주는 유용한 단축기능입니다.
guarantee_usage: guarantee_usage를 설정하면 어떻게든 현재 keyframe이 생성 과정 중 반드시 반영되어야 함을 의미합니다. 비록 아주 짧은 기간이라도 말이죠. 설정한 모든 keyframe이 차질없이 반영될 수 있음을 보장해 구성한 공정과 세부사항이 AI의 창작 과정에 활용될 수 있도록 합니다
Timestep Keyframes는 AI의 창작 과정을 공주하고 대본으로 설계할 때 필요한 정밀한 조종 방법을 제공합니다. 이는 시작장면부터 마지막 장면까지 이미지의 변화와 공정을 유도하는데 특히 애니메이션에서 강력한 도구로 사용될 수 있습니다. 특히 하나의 애니메이션 장면을 처음부터 끝까지 자신이 그린 아티스트의 상상대로 미캔지 소작하게 관장할 수 있게 해줍니다. 이어서 Timestep Keyframes를 어떻게 전략적으로 활용하여 애니메이션의 진행 과정을 제어할 수 있는지, 또 그 과정이 작가의 예술적 목표에 어떻게 부합할 수 있는지 좀 더 자세히 알아보겠습니다.
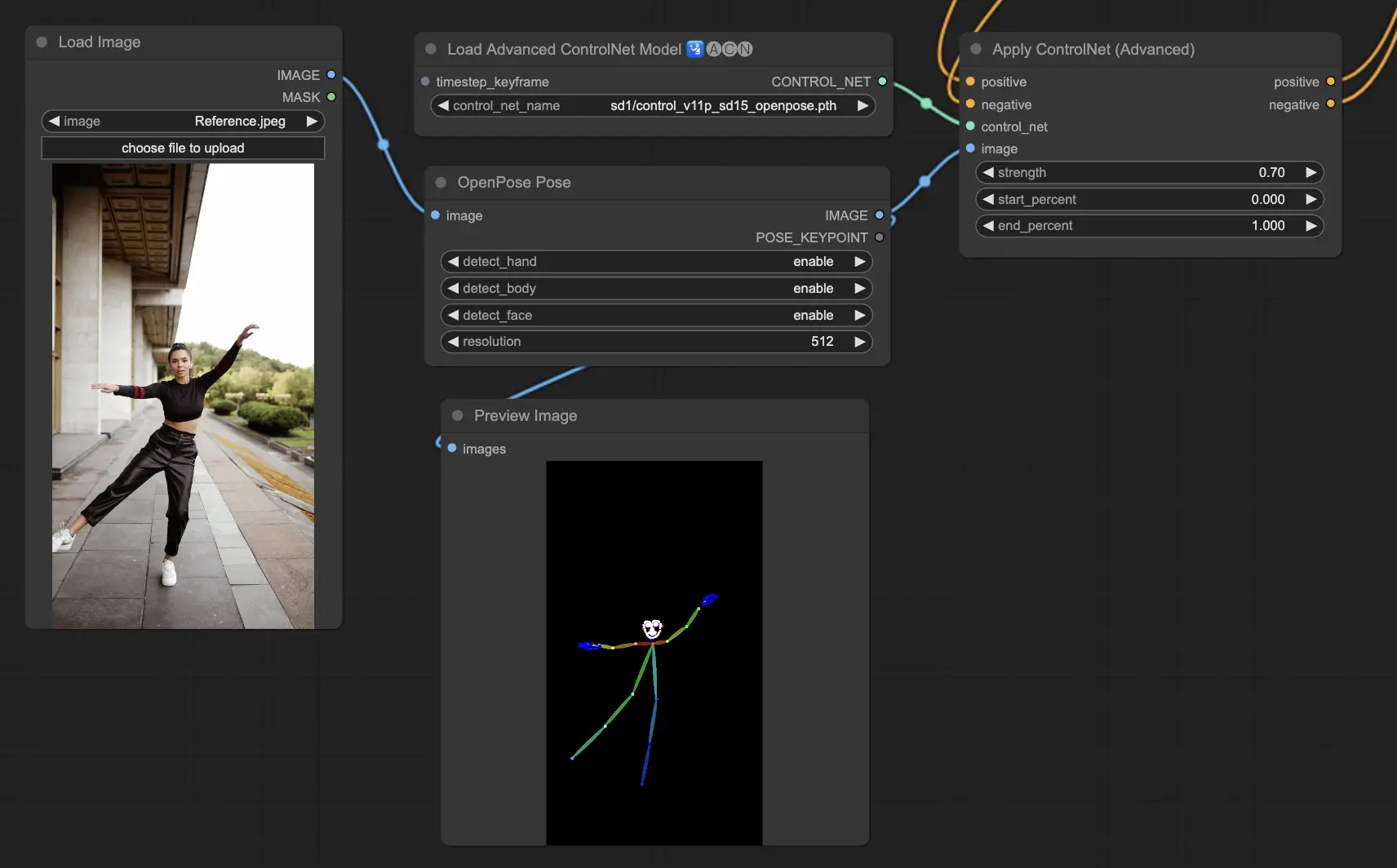
5. 다양한 ControlNet/T2IAdaptor 모델들: 상세 설명
많은 T2IAdaptor 모델들의 기능이 ControlNet 모델들과 명확히 관련되어 있기 때문에, 우리는 이후의 논의에서 ControlNet 모델을 주로 다루겠습니다. 다만 완전성을 위해 몇 가지 유명한 T2IAdaptor도 간략히 소개하겠습니"다.
5.1. ComfyUI ControlNet Openpose
- Openpose (또는 Openpose body): 이 ControlNet 내의 기본 모델은 눈, 코, 목, 어깨, 팔꼽이, 손목, 무릎 등과 같은 심플한 신체 keypoint들을 식별합니다. 기본적인 인물 자세 복사에 적합하죠.
- Openpose_face: OpenPose 모델에 얼굴 keypoint 감지를 추가하여 얼굴 표정과 방향을 보다 자세히 분석할 수 있게 해줍니다. 얼굴 표정에 주력하는 프로젝트에 필수적인 ControlNet 모델이에요.
- Openpose_hand: OpenPose 모델에 손과 손가락의 세부 부분을 포착할 수 있는 기능을 추가하여 세부적인 손 제스처와 위치를 인식할 수 있게 해줍니다. 이는 ControlNet에서 OpenPose의 활용도를 높입니다.
- Openpose_faceonly: 신체 keypoint 대신 오직 얼굴 세부사항을 위주한 전문 모델로, 얼굴 표정과 움직임을 인식하는데 중점을 둡니다. ControlNet에서 이 모델은 오직 얼굴 특징에만 집중합니다.
- Openpose_full: OpenPose, OpenPose_face, OpenPose_hand 모델의 통합판으로 신체, 얼굴, 손 전체를 구별하여 인식할 수 있는 종합적 설계입니다. ControlNet에서 완전한 사람 자세 복사를 지원합니다.
- DW_Openpose_full: OpenPose_full 모델의 극선의 강화 버전으로 더욱 세부적이고 정밀한 자세 인식이 가능해졌습니다. 이 버전은 ControlNet 프레임워크에서 자세 인식의 정밀도와 관련하여 최고처럼 도약적입니다.
Preprocessor: Openpose 또는 DWpose
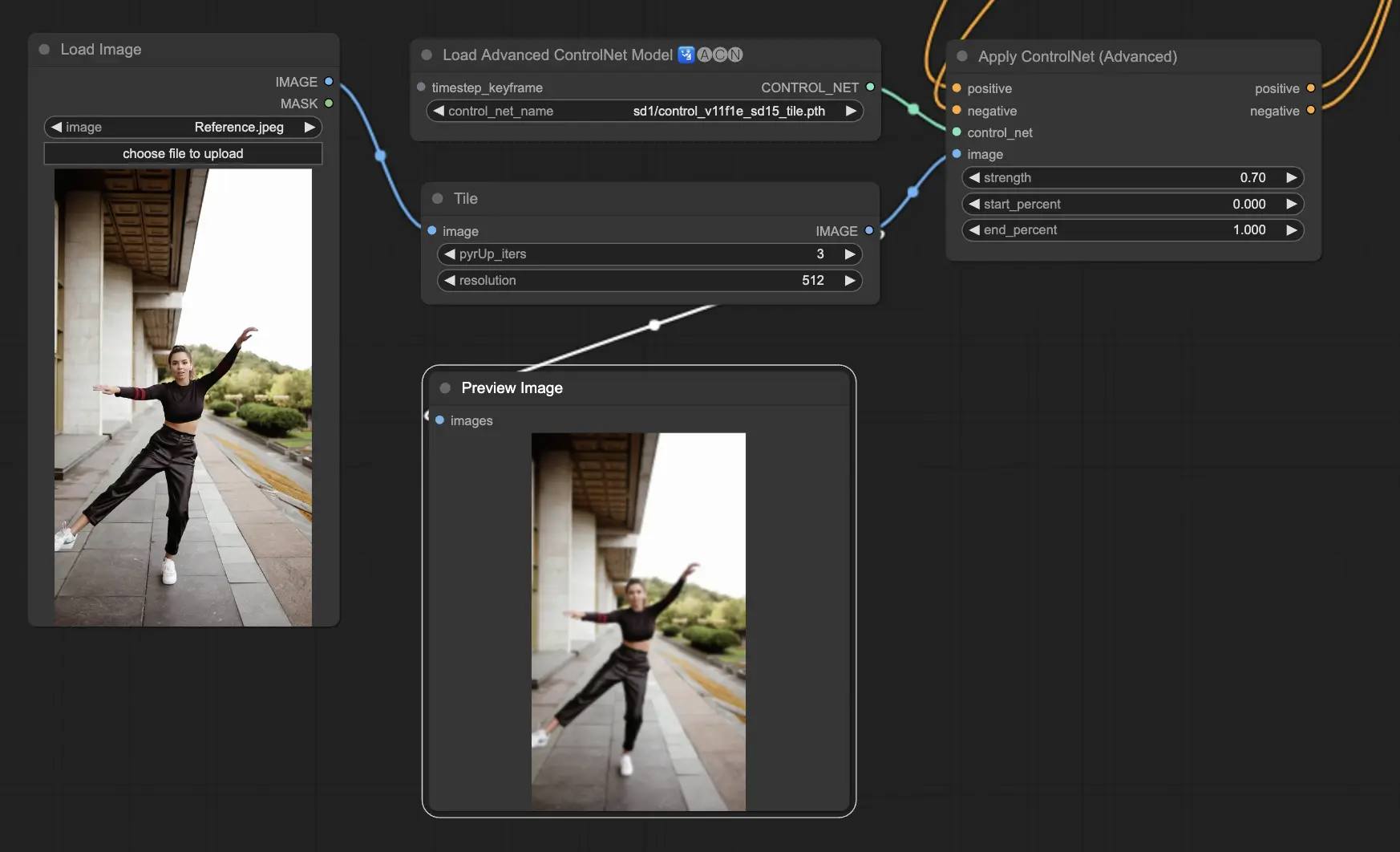
5.2. ComfyUI ControlNet Tile
Tile Resample 모델은 이미지에서 세부 내용을 강화하는 데 사용됩니다. 특히 이미지 해상도를 높이면서도 필요한 세부사항을 추가할 때 upscaler와 함께 사용하면 유용하며, 종종 이미지 내 속성과 요소를 선명하고 풍부하게 만드는 데 사용됩니다.
Preprocessor: Tile
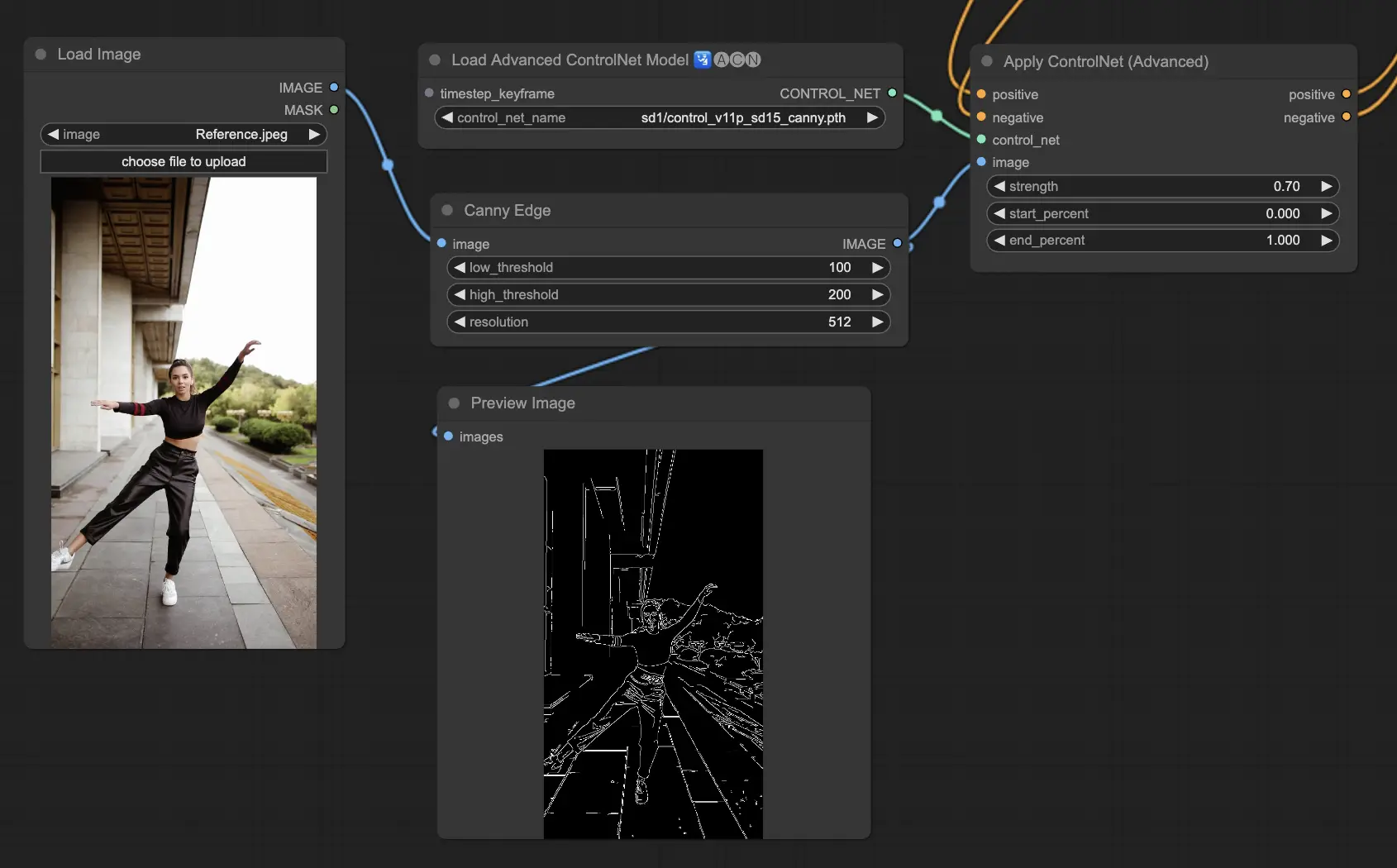
5.3. ComfyUI ControlNet Canny
Canny 모델은 이미지에서 다양한 가장자리를 식별하기 위한 다단계 과정인 Canny 가장자리 감지 알고리즘을 적용합니다. 이 모델은 이미지의 구조적 요소를 자연스럽게 보존하면서도 감각적인 구성을 단순화할 수 있어 스타일리시한 아트워크나 추가 이미지 조작 전 전처리 단계로 유용합니다.
Preprocessors: Canny
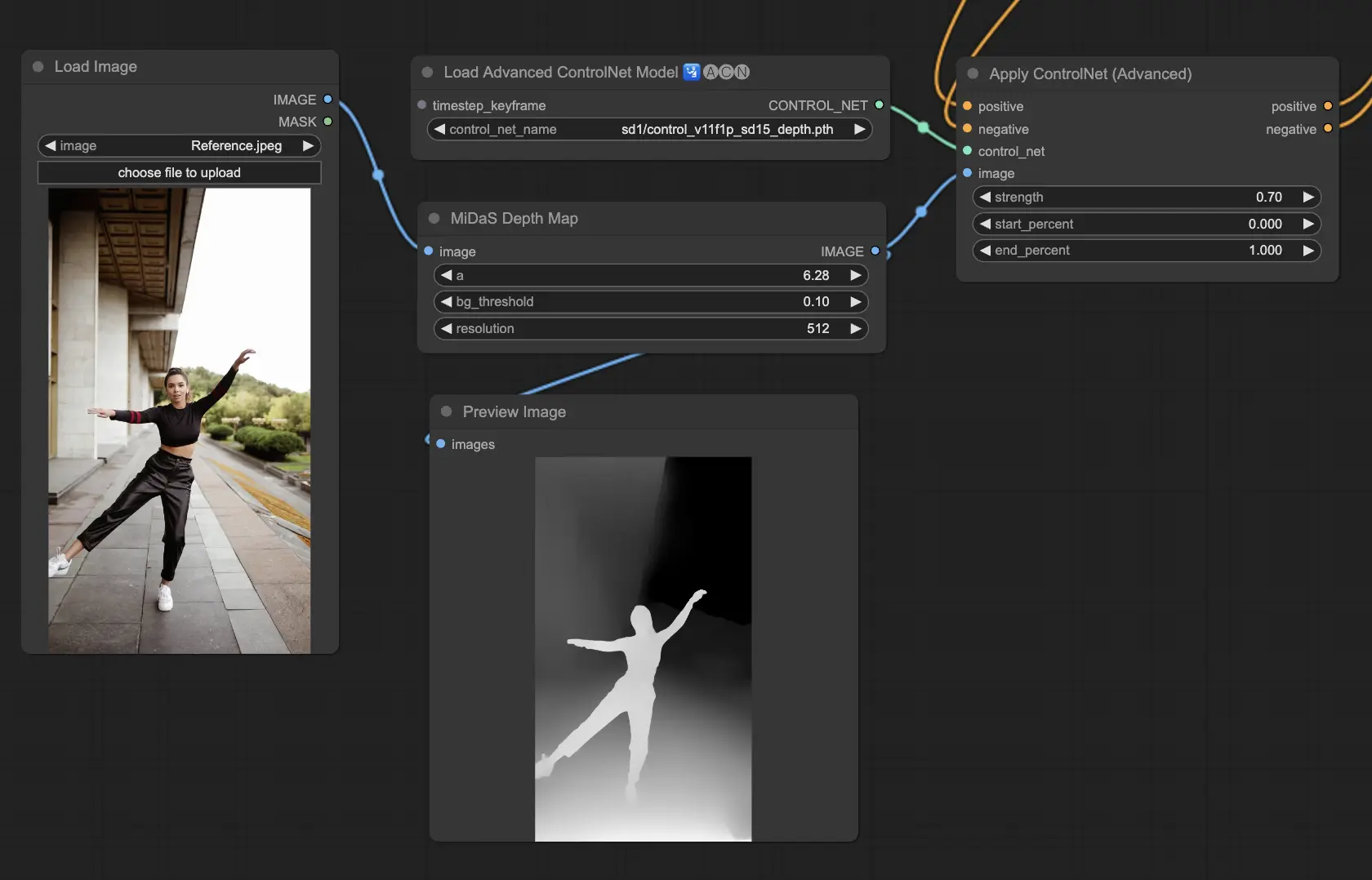
5.4. ComfyUI ControlNet Depth
Depth 모델은 2D 이미지에서 감지된 거리 정보를 그레이스케일 덱스 맵으로 변환하는 기능을 제공합니다. 각 모델마다 세부사항의 포착도와 배경의 강조 사이에서 서로 다른 밸런스를 탐색할 수 있습니다:
- Depth Midas: 세부사항과 배경을 고르게 균형을 맞추는 클래식 덱스 예측을 제공합니다.
- Depth Leres: 배경 요소들을 더 많이 반영하는 성향이 있는 필요한 세부사항을 강조하는데 중점을 둡니다.
- Depth Leres++: 좀 더 복잡한 장면에 맞게 덱스 정보의 층을 세분화하여 세밀한 표현이 가능한 고급 수준의 기능을 제공합니다.
- Zoe: Midas 모델과 Leres 모델의 세부 수준 중간 정도를 지향합니다.
- Depth Anything: 다양한 장면에 대한 덱스 예측을 위한 새롭고 개선된 모델로 가장 최근에 개발되었습니다.
- Depth Hand Refiner: 덱스 맵에서 손 세부사항을 강화하는 데 집중된 특별한 모델로 손 위치가 중요한 장면에서 유용합니다.
Preprocessors: Depth_Midas, Depth_Leres, Depth_Zoe, Depth_Anything, MeshGraphormer_Hand_Refiner 등 매우 강력한 모델들은 실제 렌더링 엔진에서 생성된 덱스 맵을 잘 처리할 수 있습니다.
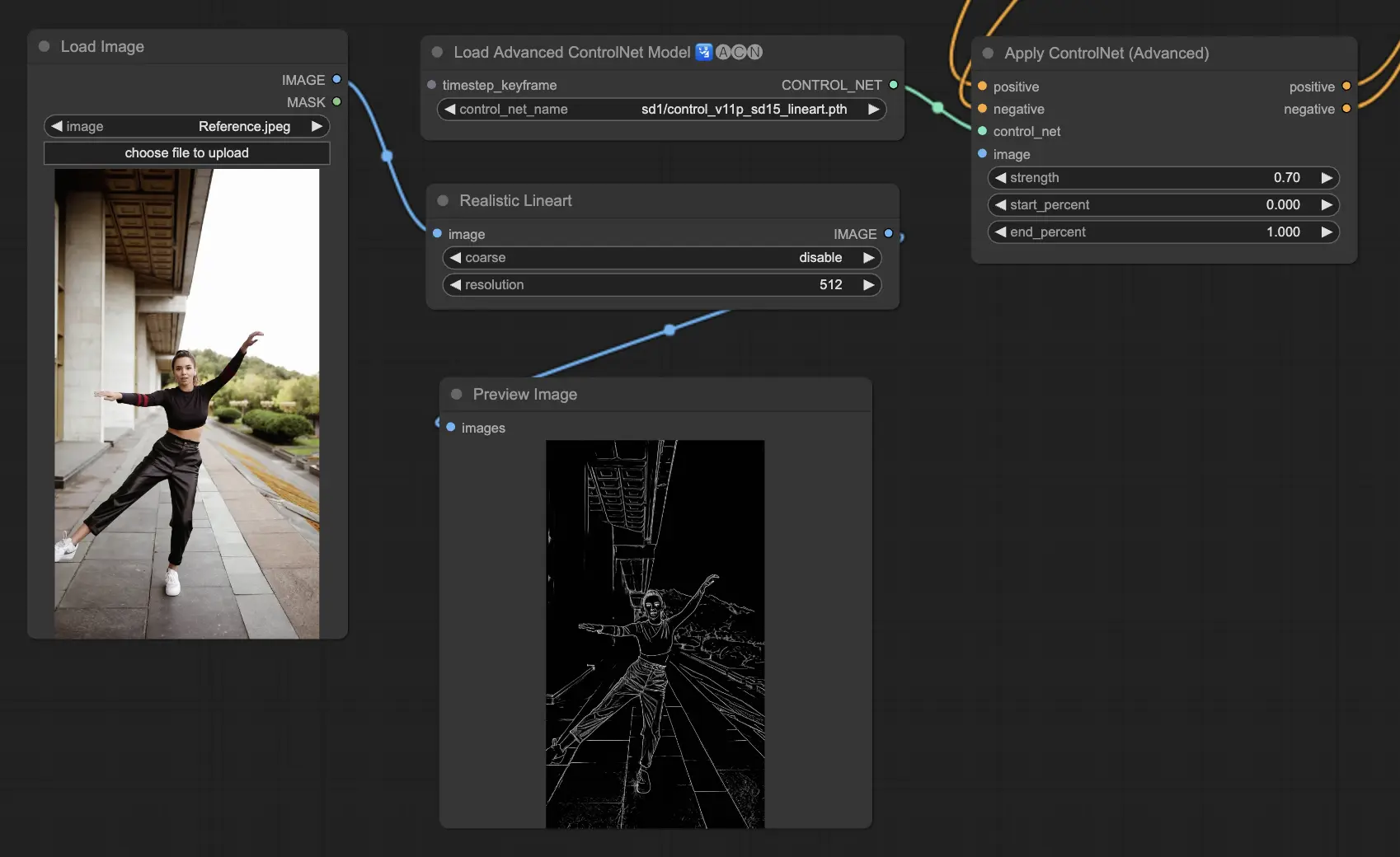
5.5. ComfyUI ControlNet Lineart
Lineart 모델은 이미지를 스타일링된 선 그림으로 변환하여 예술적 표현이나 추가 참신 작업의 기반으로 유용하게 해줍니다:
- Lineart: 이 표준 모델은 이미지를 스타일링된 선 그림으로 변환하여 다양한 예술 프로젝트나 참신 작업에 다재다능한 기반이 되도록 합니다.
- Lineart anime: 선명하고 정교한 선을 특징으로 하는 애니메이션 스타일의 선 그림을 생성하는데 주력하며, 애니 아트워크를 목표로 하는 프로젝트에 적합합니다.
- Lineart realistic: 더 많은 세부사항을 포착하면서 대상의 현실적인 분위기를 표현하는 선 그림을 생성합니다. 현실적인 표현이 필요한 프로젝트에 적합합니다.
- Lineart coarse: 더 굵고 두꺼운 선을 사용하는 독특하고 두드러진 선 그림을 제공하며, 다른 부분과 확연히 구분되어 강렬한 예술 표현에 적용하기 알맞습니다.
Preprocessor: Lineart 와 Lineart_Coarse는 이미지로부터 세부적이거나 대략적인 선 그림을 생성할 수 있습니다.
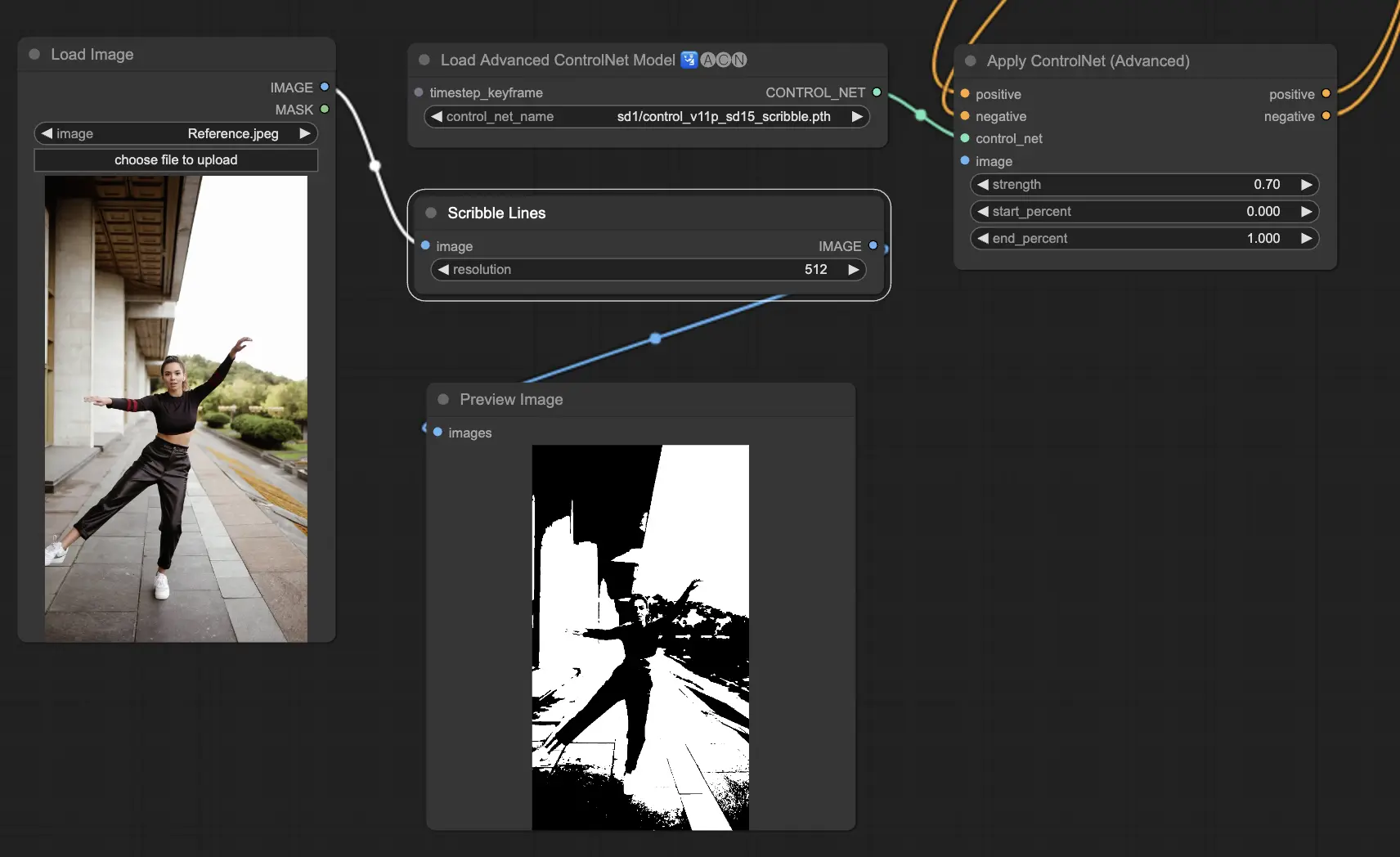
5.6. ComfyUI ControlNet Scribbles
Scribble 모델은 이미지를 그림이나 스케치처럼 보이도록 수정하는 것을 목표로 합니다. 예술 재스타일링이나 더 큰 디자인 워크플로우에서 예비 단계로 유용합니다:
- Scribble: 이미지를 수작으로 그려진 그림이나 스케치를 있는 그대로 표현한 아트워크로 변환하는 것을 위해 제작되었습니다.
- Scribble HED: Holistically-Nested Edge Detection (HED) 기법을 사용하여 수작을 연상하는 아웃라인을 생성합니다. 이미지 재색상이나 재스타일링에 특히 유용하며, 아트워크에 특유한 예술적 느낌을 더합니다.
- Scribble Pidinet: 픽셀 차이를 감지하는데 주력하여 세부사항을 줄이고 더 맑맑한 선을 생성하는데 중점을 두어 더 확실하고 간결한 표현에 알맞습니다. Scribble Pidinet은 세부사항을 유지하면서도 매끄럽고 멋진 곡선과 직선을 만들어내는데 완벽한 옵션으로, 당신의 예술적 창작에 활용하기 완벽한 선택입니다.
- Scribble xdog: Extended Difference of Gaussian (xDoG) 알고리즘을 활용한 가장자리 감지를 수행합니다. 이는 임계치 설정을 조정하여 스케치 효과의 세부수준을 콘트롤할 수 있게 해줍니다. xDoG는 다재다능해서 아트워크에서 필요한 세부수준을 조정하는데 유연하게 활용할 수 있습니다.
Preprocessors: Scribble, Scribble_HED, Scribble_PIDI, Scribble_XDOG
5.7. ComfyUI ControlNet Segmentation
Segmentation 모델은 이미지의 픽셀들을 각각 특정 색상으로 표현되는 개별 오브젝트 클래스로 분류합니다. 이는 이미지 내에서 각 요소들을 식별하여 평면의 배경과 오브젝트를 구분하거나 상세 편집을 위해 오브젝트를 구분하는 데 필수적입니다.
- Seg: 이미지 내 개별 오브젝트를 색상으로 구분하여 이를 생성된 이미지에서 또래한 요소들로 변환하는 것을 목적으로 합니다. 예를 들어 실내 레이아웃에서 가구들을 구분할 수 있어서 이미지 구성과 편집에 대한 정밀한 조종이 필요한 프로젝트에 특히 유용합니다.
- ufade20k: ADE20K 데이터셋으로 학습된 UniFormer 분할 모델을 활용하여 다양한 종류의 오브젝트를 높은 정확도로 구분할 수 있습니다.
- ofade20k: ADE20K 데이터로 학습된 OneFormer 모델을 사용하며 다양한 오브젝트 구분을 위한 대체적인 방법을 제공합니다.
- ofcoco: COCO 데이터셋 범위 내에서 정의된 객체를 가진 이미지에 최적화된 COCO 데이터로 학습된 OneFormer 분할 방법을 활용하여 정확한 객체 식별과 조작을 가능하게 합니다.
Preprocessor로 Sam, Seg_OFADE20K (Oneformer ADE20K), Seg_UFADE20K (Uniformer ADE20K), Seg_OFCOCO (Oneformer COCO), 또는 직접 생성한 마스크를 사용할 수 있습니다.
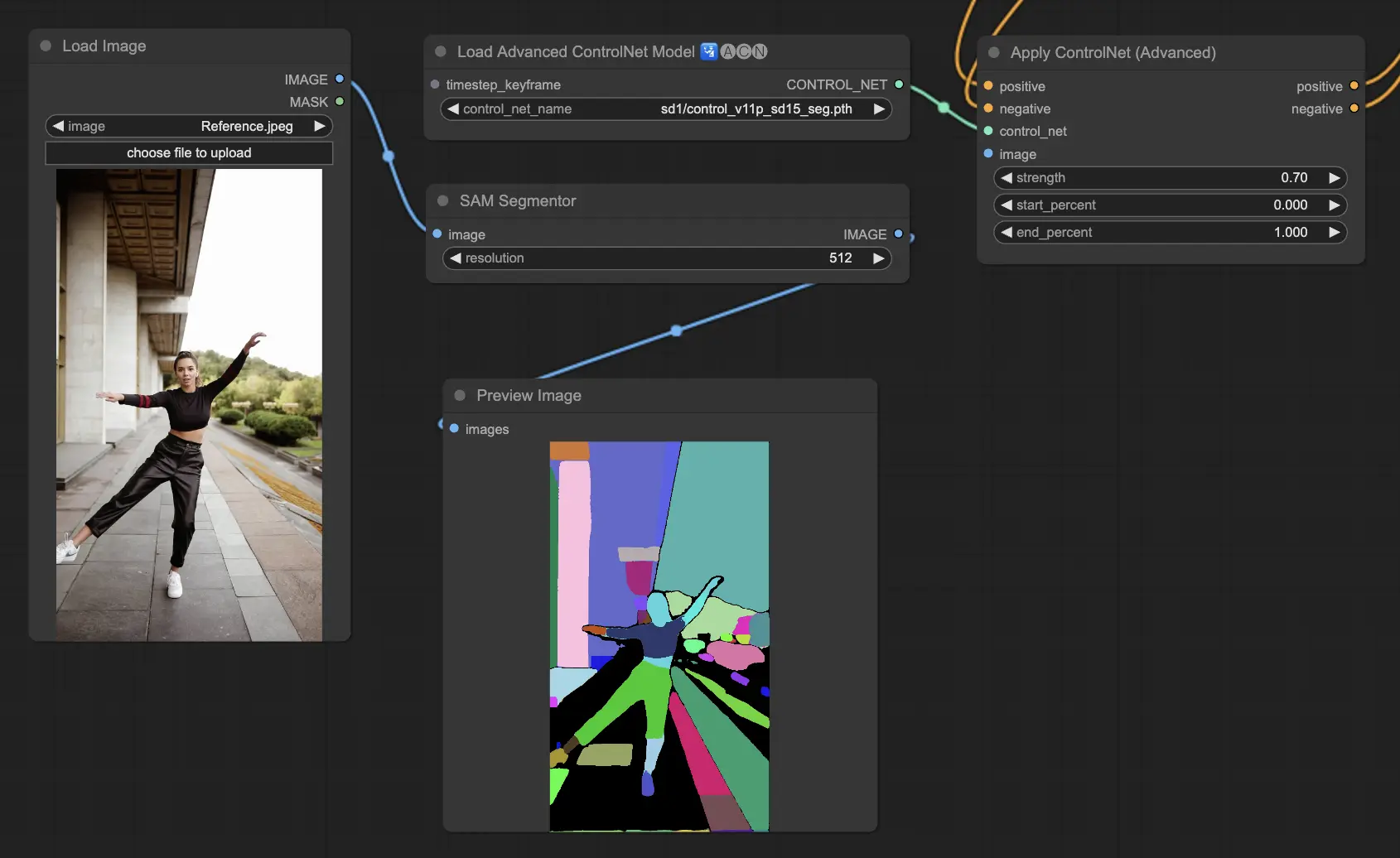
5.8. ComfyUI ControlNet Shuffle
Shuffle 모델은 이미지의 구성을 유지하면서 색상 구성이나 텍스처 등의 속성을 무작위로 변화시키는 특이한 방식을 도입합니다. 이 모델은 창의적인 탐색이나 이미지의 무작위 변형을 생성하는데 특히 효과적이며, 구조적 완결성은 유지하면서도 시각적 아름다움이 변화된 다양한 결과물을 출력합니다. 이 모델의 무작위성으로 인해 매 출력마다 유일한 결과물이 생성되며, 이는 생성 과정에 사용된 시드 값의 영향을 받습니다.
Preprocessors: Shuffle
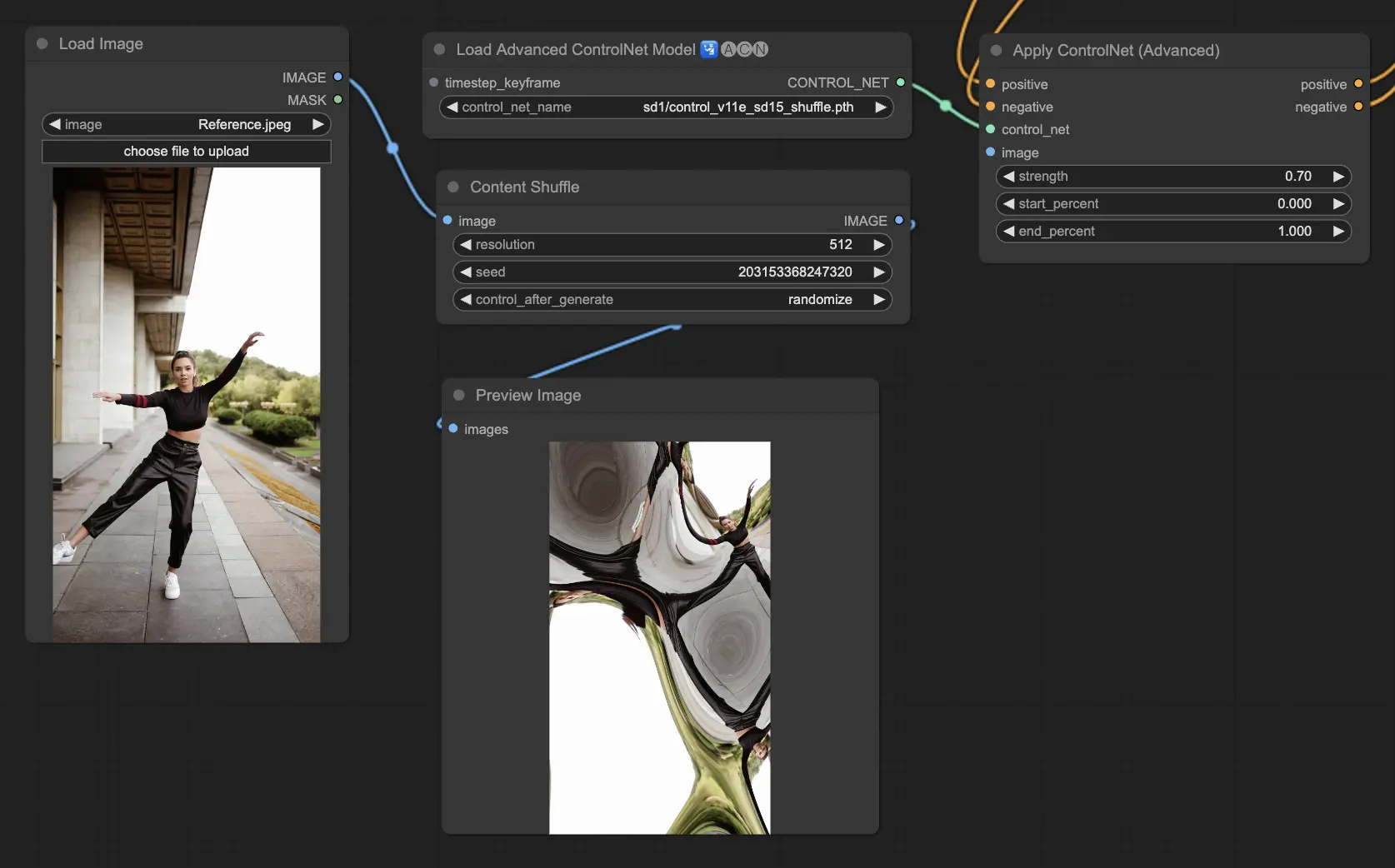
5.9. ComfyUI ControlNet Inpainting
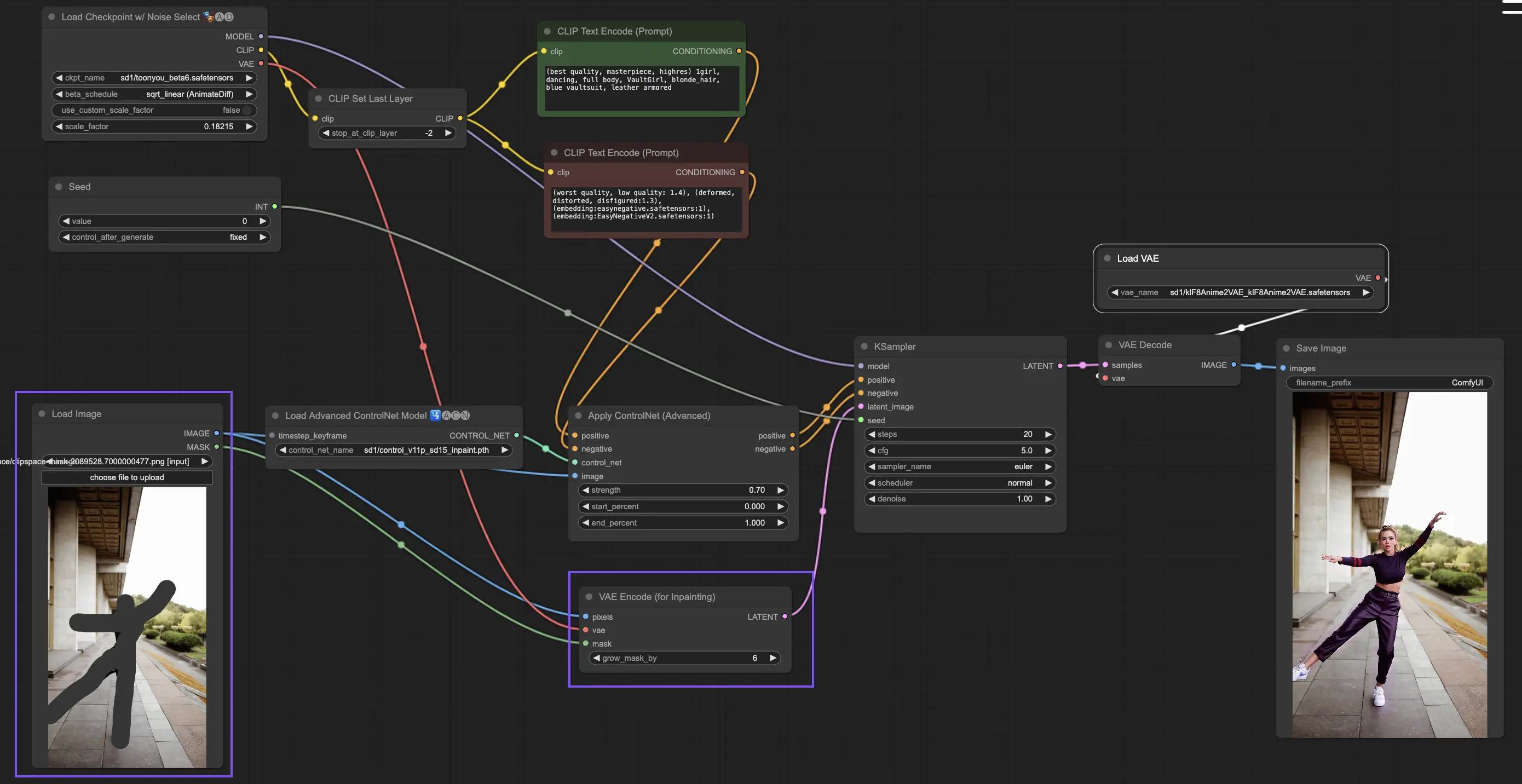
ControlNet 내의 Inpainting 모델은 이미지의 특정 영역만 선택적으로 편집할 수 있도록 하며, 전체적인 일관성은 유지하면서도 특정 부분에 크게 변화를 주거나 수정이 가능하게 합니다.
ControlNet Inpainting을 사용하기 위해서는 먼저 재생성하고자 하는 영역을 마스킹을 통해 선택합니다. 이는 원하는 이미지를 마우스 오른쪽 클릭 - "MaskEditor에서 열기" 메뉴를 통해 수정할 수 있습니다.
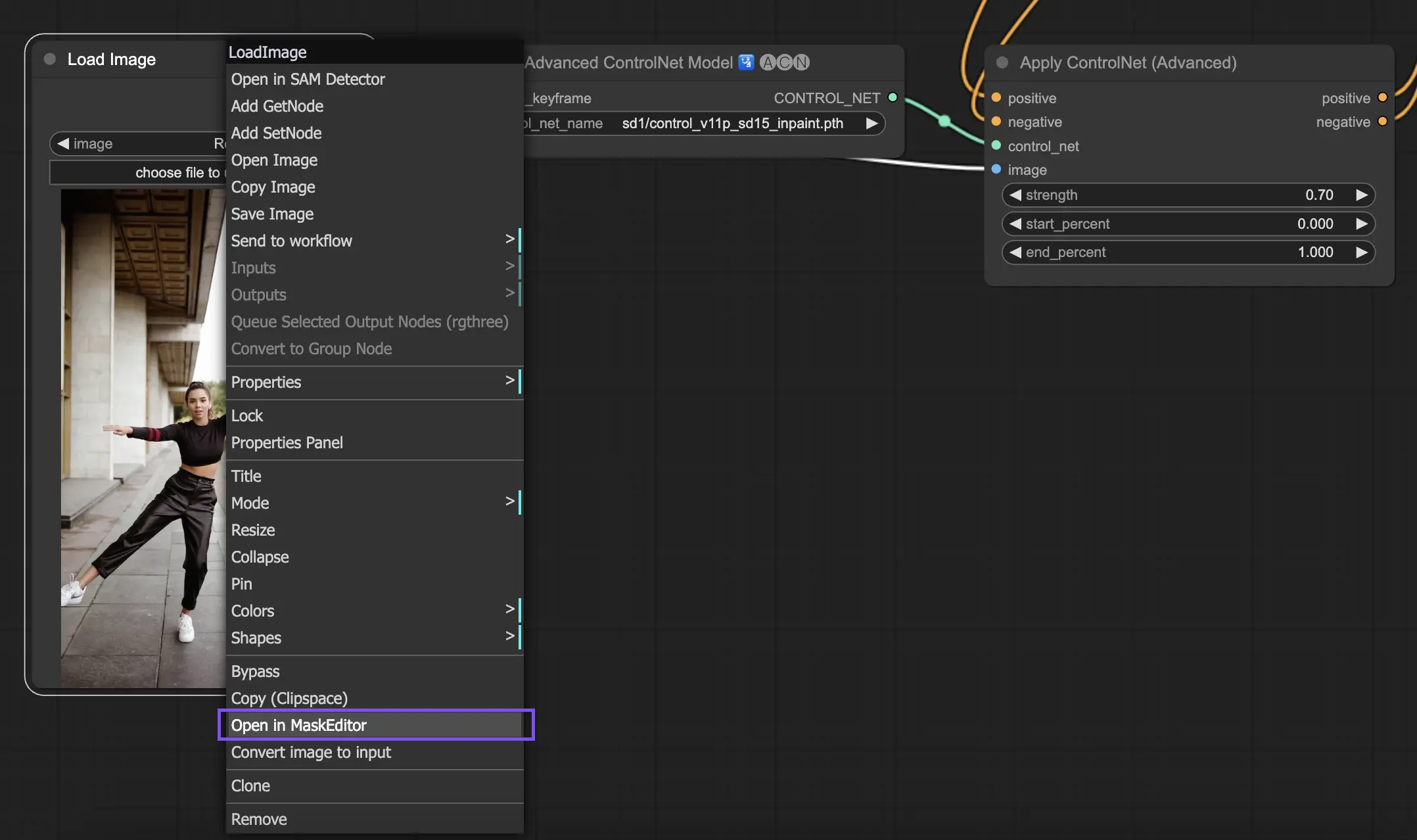
ControlNet 내 다른 모델과는 달리, Inpainting 모델은 이미지를 직접 수정하므로 preprocessor를 통과할 필요가 없습니다. 하지만 수정된 이미지를 latent 공간으로 전달하기 위해서는 KSampler를 통해야 합니다. 이는 생성 모델이 마스킹 영역에만 집중하여 이 부분을 재생성하고, 나머지 영역은 바꾸지 않고 유지할 수 있게 합니다.
5.10. ComfyUI ControlNet MLSD
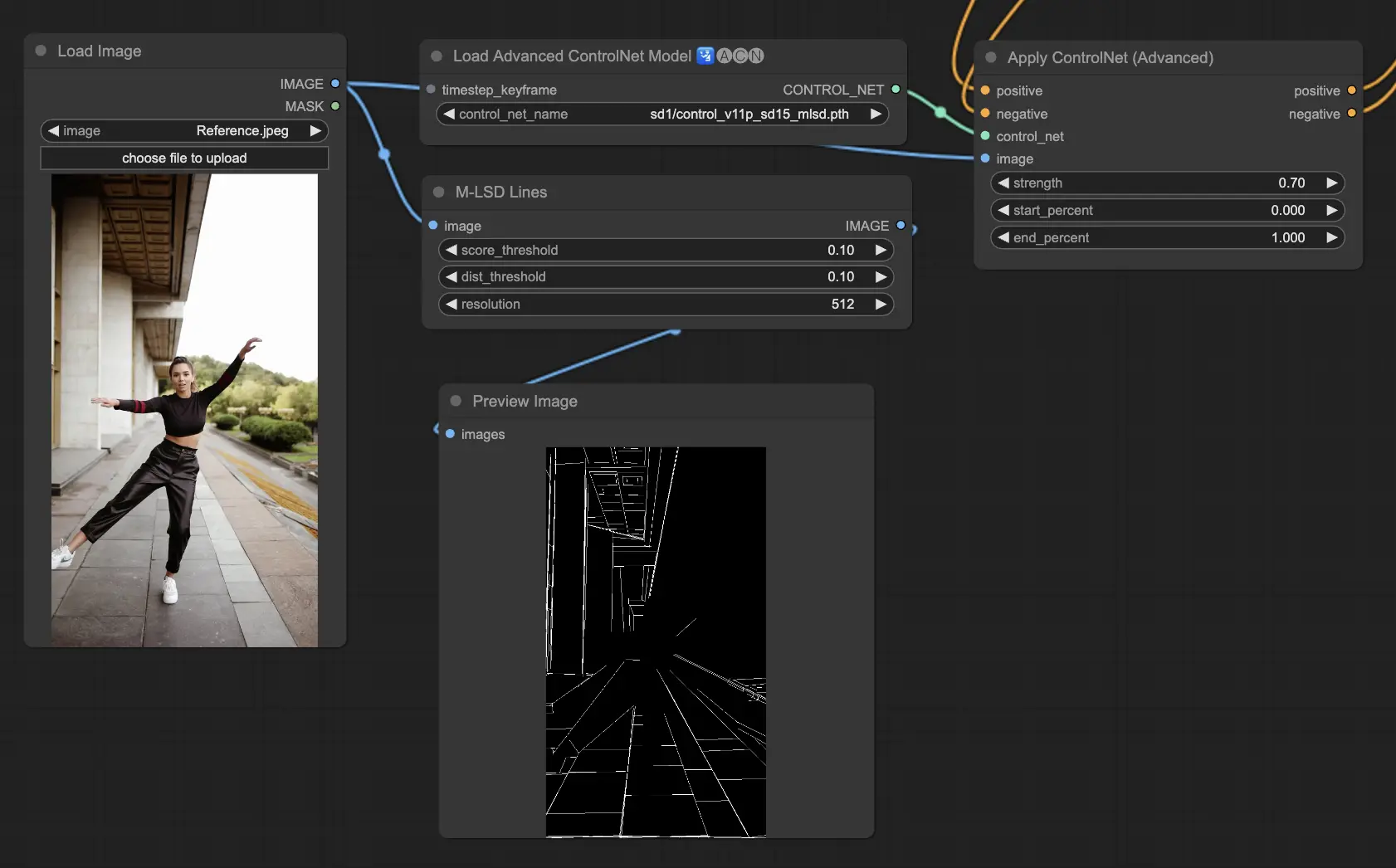
M-LSD (Mobile Line Segment Detection)는 직선 감지에 주력하며, 건축물, 내부 공간, 기하학적 요소가 많은 이미지에 적합합니다. 장면을 구조적인 특징으로 간소화하여 인공물 환경에 관한 창의적 프로젝트에 유용합니다.
Preprocessors: MLSD
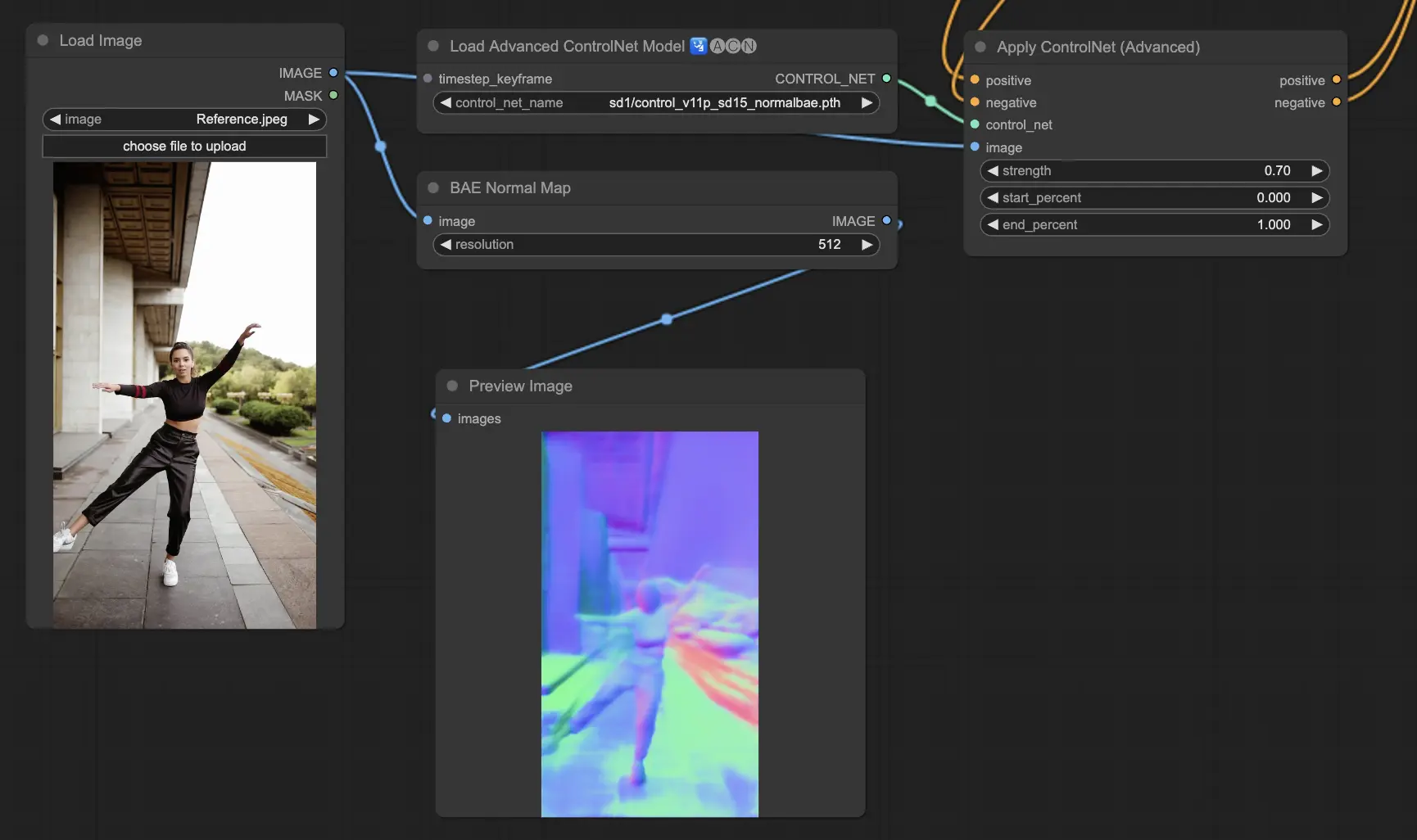
5.11. ComfyUI ControlNet Normalmaps
Normalmaps는 공간에서 표면의 방향을 모델링함으로써 단순히 색상 정보만 사용하는 것 대신에 복잡한 조명과 텍스처 효과를 시뮤레이션 할 수 있게 해줍니다. 이는 3D 모델링이나 시뮤레이션 작업에 필수적입니다.
- Normal Bae: 이 방법은 normal 불확실성 근사법을 활용하여 normal map을 생성합니다. 이는 모델링된 장면의 물리적 지형에 기반해 조명 효과를 시뮤레이션 할 때 표면의 방향을 표현하는 새로운 방식을 제공하며, 전통적인 색상 기반의 방식을 대체합니다.
- Normal Midas: Midas 모델로 생성된 덱스 맵을 활용하여 normal map을 정확하게 추정합니다. 이 방식은 장면의 깊이 정보를 기반으로 표면 재질과 조명의 세부적인 시뮤레이션을 가능하게 하여 3D 모델의 시각적 복잡도를 업그레이드 합니다.
Preprocessors: Normal BAE, Normal Midas
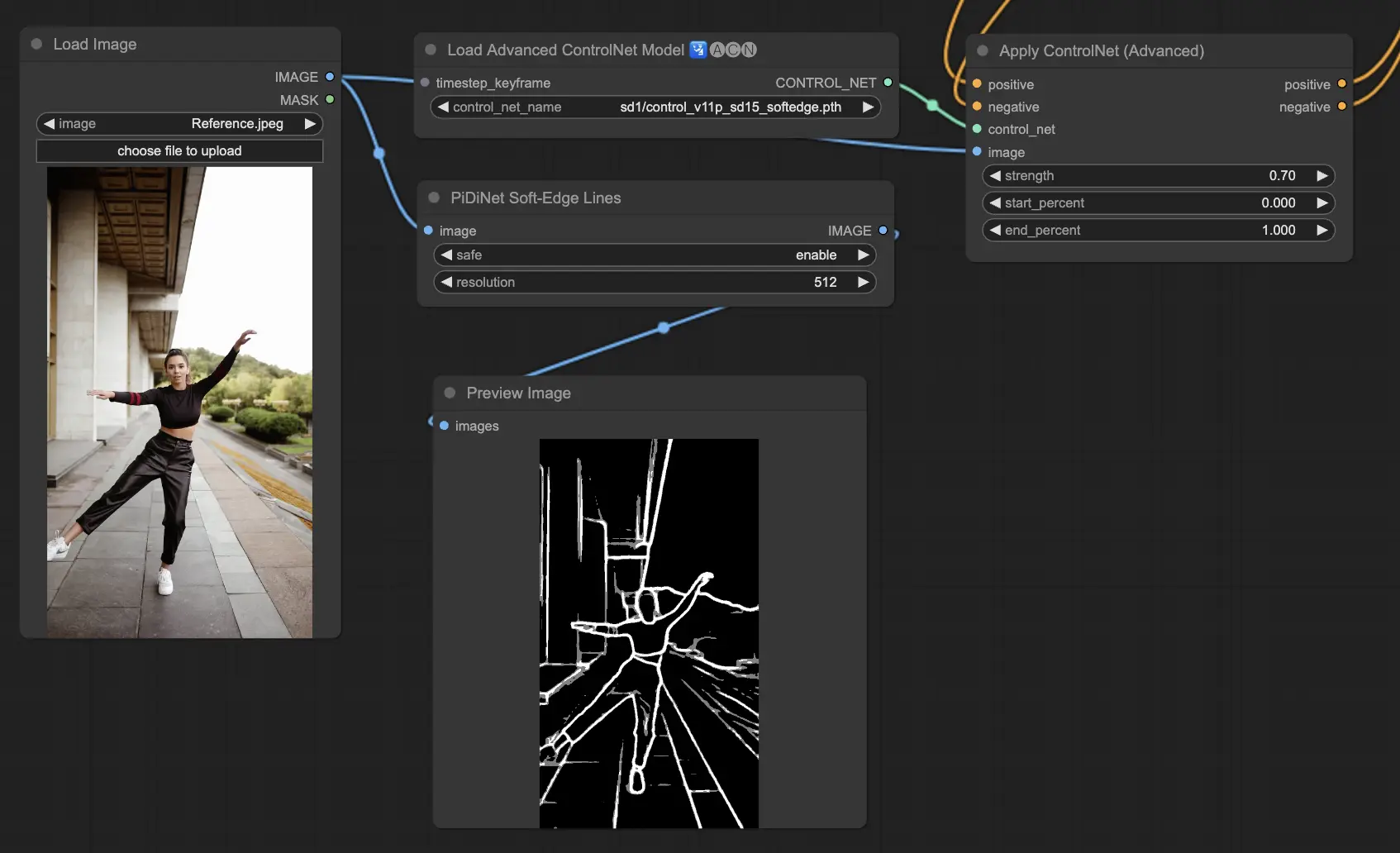
5.12. ComfyUI ControlNet Soft Edge
ControlNet Soft Edge는 가장자리를 부드럽게 하여 세부적인 가장자리 제어와 자연스러운 이미지 생성에 중점을 둡니다. 정밀한 이미지 조작을 위해 고급 신경망 기술을 사용하여 더욱 많은 창의성을 발휘할 수 있으며 자연스러운 이미지 혼합을 제공합니다.
Preprocessor로는 강한순으로 SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED 가 있으며, 최종 결과 품질 측면에서는 SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe 순입니다.
일반적으로는 SoftEdge_PIDI를 사용하기를 추천하며 대부분의 경우에 매우 잘 작동합니다.
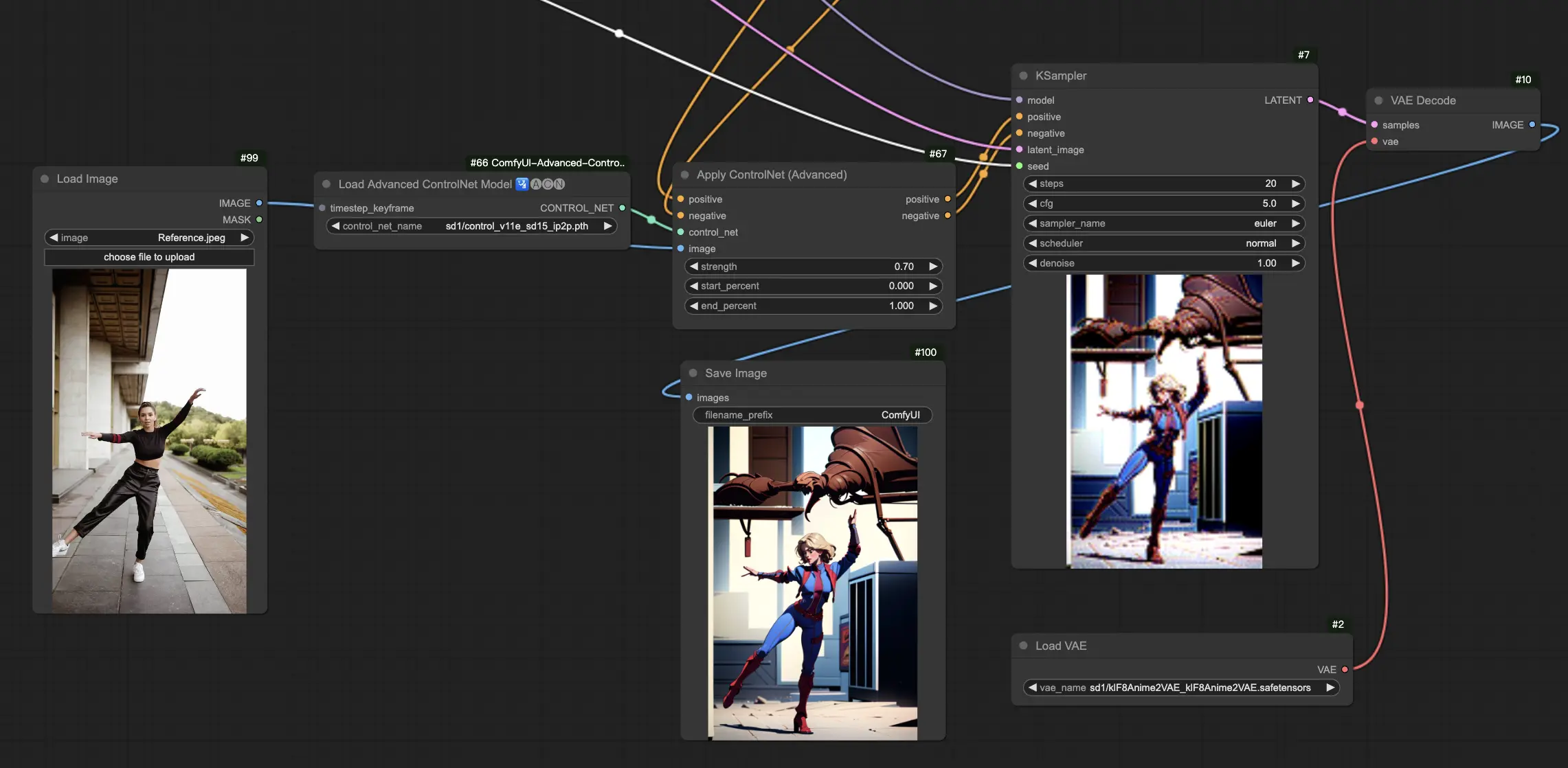
5.13. ComfyUI ControlNet IP2P (Instruct Pix2Pix)
ControlNet IP2P (Instruct Pix2Pix) 모델은 Instruct Pix2Pix 데이터셋을 활용하여 이미지 변형을 위해 ControlNet 프레임워크 내에서 특별히 개작된 버전입니다. 이 ControlNet 변종은 학습 단계에서 명령 프롬프트와 설명 프롬프트 사이의 균형을 맞추는데 중점을 둡니다. 공식 Instruct Pix2Pix 접근법과는 달리 ControlNet IP2P는 이러한 프롬프트 유형을 50/50 비율로 조합하여 결과를 내는데 더욱 다양하고 효과적인 스타일로 만들어냅니다.
5.14. ComfyUI T2I Adapter
t2iadapter color: t2iadapter_color 모델은 텍스트-투-이미지 생성 모델을 사용할 때 생성된 이미지의 색상 표현과 정확도를 높이는 데 주력합니다. 색상 적응에 초점을 맞춰 텍스트 프롬프트에 설명된 색감과 더욱 일치하고 생동감 있는 색이 구현됩니다. 이는 색상의 풍부함과 세부사항이 중요한 프로젝트에 특히 유용하며 생성된 이미지에 더욱 사실감과 세부사항이 추가됩니다.
t2iadapter style: t2iadapter_style 모델은 생성된 이미지의 예술적 스타일을 조절하고 제어할 수 있도록 하는 데 더욱 많은 역할을 합니다. 이 어댑터를 통해 텍스트 프롬프트에 설명된 예술적 스타일이나 아름다움에 맞는 이미지를 생성할 수 있도록 텍스트-투-이미지 모델을 관장할 수 있습니다. 이는 이미지 스타일이 핵심적인 역할을 하는 창의적 프로젝트에서 전통적 예술 스타일과 현대 AI 기술의 조화를 쉽게 해주는 무결한 도구가 됩니다.
5.15. 기타 인기 ComfyUI ControlNet: QRCode Monster와 IP-Adapter
이 부분들에 대해서는, 주제에 대해 알려드리고 싶은 많은 내용을 고려하여 추후 별도의 기사를 통해 상세히 이야기하겠습니다.
6. 여러 개의 ComfyUI ControlNet을 동시에 사용하는 방법
ComfyUI에서 여러 ControlNet을 혼합적으로 사용하는 것은 자세, 형태, 스타일, 색상 등 다양한 측면에서 이미지 생성을 보다 정밀하게 제어하기 위해 ControlNet 모델들을 레이어로 첨가하거나 연결하는 과정이 됩니다.
이를 위해서는 먼저 하나의 ControlNet(예: OpenPose)을 적용한 후, 그 출력을 다른 ControlNet(예: Canny)의 입력으로 전달하면서 워크플로우를 구성할 수 있습니다. 이러한 계층적 접근은 각 ControlNet이 각각의 특정 변환이나 컨트롤을 적용하며 이미지를 세부적으로 조작할 수 있도록 합니다. 이 과정은 최종 결과물을 정밀하게 조종함으로써 여러 측면에서 ControlNet의 가이드를 통합할 수 있게 해줍니다.
🌟🌟🌟 ComfyUI Online - ControlNet 워크플로우를 지금 바로 경험하세요 🌟🌟🌟
ControlNet 워크플로우를 탐색해 보고 싶다면 아래 ComfyUI 웹을 사용해보세요. 핵심이 되는 모든 고객 노드와 모델이 이미 포함되어 있으므로 복잡한 설정 없이도 쉽게 참신성을 발휘할 수 있어요. 지금 바로 ControlNet의 기능을 체험해 보고 익숙해지세요!
더 고급 기능의 프리미엄 ComfyUI 워크플로우가 궁금하다면 이곳 🌟ComfyUI 워크플로우 목록🌟을 참고하세요
RunComfy는 최고의 ComfyUI 플랫폼으로서 ComfyUI 온라인 환경과 서비스를 제공하며 ComfyUI 워크플로우 멋진 비주얼을 제공합니다. RunComfy는 또한 제공합니다 AI Playground, 예술가들이 최신 AI 도구를 활용하여 놀라운 예술을 창조할 수 있도록 지원합니다.