





ComfyUI FLUX: FLUX-ControlNet, FLUX-LoRA, FLUX-IPAdapter 등의 설정, 워크플로우 및 온라인 액세스 안내
Updated: 8/26/2024
안녕하세요, AI 애호가 여러분! 👋 ComfyUI에서 FLUX를 사용하는 입문 가이드에 오신 것을 환영합니다. FLUX는 Black Forest Labs에서 개발한 최첨단 모델입니다. 🌟 이 튜토리얼에서는 ComfyUI FLUX의 기본 사항을 살펴보고, 이 강력한 모델이 창의적인 프로세스를 어떻게 향상시키고 AI 생성 예술의 경계를 넓힐 수 있는지 보여드리겠습니다. 🚀
다음 내용을 다룹니다:
1. FLUX 소개
2. FLUX의 다양한 버전
3. FLUX 하드웨어 요구 사항
- 3.1. FLUX.1 [Pro] 하드웨어 요구 사항
- 3.2. FLUX.1 [Dev] 하드웨어 요구 사항
- 3.3. FLUX.1 [Schnell] 하드웨어 요구 사항
4. ComfyUI에 FLUX 설치 방법
- 4.1. ComfyUI 설치 또는 업데이트
- 4.2. ComfyUI FLUX 텍스트 인코더 및 CLIP 모델 다운로드
- 4.3. FLUX.1 VAE 모델 다운로드
- 4.4. FLUX.1 UNET 모델 다운로드
5. ComfyUI FLUX 워크플로우 | 다운로드, 온라인 액세스 및 가이드
- 5.1. ComfyUI 워크플로우: FLUX Txt2Img
- 5.2. ComfyUI 워크플로우: FLUX Img2Img
- 5.3. ComfyUI 워크플로우: FLUX LoRA
- 5.4. ComfyUI 워크플로우: FLUX ControlNet
- 5.5. ComfyUI 워크플로우: FLUX Inpainting
- 5.6. ComfyUI 워크플로우: FLUX NF4 & Upscale
- 5.7. ComfyUI 워크플로우: FLUX IPAdapter
- 5.8. ComfyUI 워크플로우: Flux LoRA Trainer
- 5.9. ComfyUI 워크플로우: Flux Latent Upscale
1. FLUX 소개
Black Forest Labs에서 개발한 최첨단 AI 모델인 FLUX.1은 텍스트 설명에서 이미지를 생성하는 방식을 혁신하고 있습니다. 입력 프롬프트에 맞춰 놀랍도록 상세하고 복잡한 이미지를 생성하는 FLUX.1의 독보적인 능력은 경쟁사와 차별화됩니다. FLUX.1의 성공 비결은 고유의 하이브리드 아키텍처에 있으며, 이는 다양한 유형의 트랜스포머 블록을 결합하고 인상적인 120억 개의 파라미터로 구동됩니다. 이는 FLUX.1이 텍스트 설명을 정확하게 나타내는 시각적으로 매력적인 이미지를 생성할 수 있게 합니다.
FLUX.1의 가장 흥미로운 측면 중 하나는 다양한 스타일의 이미지를 생성할 수 있는 다재다능함입니다. FLUX.1은 심지어 생성된 이미지 내에 텍스트를 매끄럽게 통합하는 놀라운 능력을 가지고 있으며, 이는 다른 많은 모델들이 달성하기 어려운 성과입니다. 또한, FLUX.1은 예외적인 프롬프트 준수로 유명하여 단순한 설명부터 복잡한 설명까지 쉽게 처리할 수 있습니다. 이로 인해 FLUX.1은 종종 Stable Diffusion 및 Midjourney와 같은 다른 잘 알려진 모델들과 비교되며, 사용자 친화성과 최상급 결과로 인해 종종 선호되는 선택이 됩니다.
FLUX.1의 인상적인 기능은 놀라운 시각적 콘텐츠를 생성하고 혁신적인 디자인에 영감을 주며 과학적 시각화를 촉진하는 등 다양한 응용 분야에서 귀중한 도구가 됩니다. 텍스트 설명에서 매우 상세하고 정확한 이미지를 생성할 수 있는 FLUX.1의 능력은 창의적인 전문가, 연구원 및 애호가에게 다양한 가능성을 열어줍니다. AI 생성 이미지 분야가 계속 발전함에 따라, FLUX.1은 품질, 다재다능성 및 사용 편의성에 대한 새로운 기준을 설정하며 최전선에 서 있습니다.
혁신적인 FLUX.1을 개발한 선구적인 AI 회사인 Black Forest Labs는 이전에 Stability AI의 핵심 멤버로 활동했던 AI 업계의 저명한 인물 Robin Rombach가 설립했습니다. Black Forest Labs와 FLUX.1의 혁신적인 작업에 대해 더 알고 싶다면 공식 웹사이트 https://blackforestlabs.ai/를 방문해 보세요.

2. FLUX의 다양한 버전
FLUX.1은 특정 사용자 요구에 맞춘 세 가지 다른 버전으로 제공됩니다:
- FLUX.1 [pro]: 최고 품질과 성능을 제공하며, 전문적인 사용과 고급 프로젝트에 적합한 최상위 버전입니다.
- FLUX.1 [dev]: 비상업적 사용을 위해 최적화된 이 버전은 고품질 출력을 유지하면서도 더 효율적이며, 개발자와 애호가에게 적합합니다.
- FLUX.1 [schnell]: 이 버전은 속도와 경량성을 중시하며, 로컬 개발 및 개인 프로젝트에 적합합니다. 또한 Apache 2.0 라이선스 하에 오픈 소스로 제공되어 다양한 사용자가 접근할 수 있습니다.
| Name | HuggingFace repo | License | md5sum |
FLUX.1 [pro] | Only available in our API. | ||
FLUX.1 [dev] | https://huggingface.co/black-forest-labs/FLUX.1-dev | FLUX.1-dev Non-Commercial License | a6bd8c16dfc23db6aee2f63a2eba78c0 |
FLUX.1 [schnell] | https://huggingface.co/black-forest-labs/FLUX.1-schnell | apache-2.0 | a9e1e277b9b16add186f38e3f5a34044 |
3. FLUX 하드웨어 요구 사항
3.1. FLUX.1 [Pro] 하드웨어 요구 사항
- 권장 GPU: NVIDIA RTX 4090 또는 동급의 24 GB 이상의 VRAM을 가진 GPU. 모델은 복잡한 작업을 처리하기 위해 고급 GPU에 최적화되어 있습니다.
- RAM: 32 GB 이상의 시스템 메모리.
- 디스크 공간: 약 30 GB.
- 컴퓨팅 요구 사항: 고정밀이 필요하며, FP16 (반정밀도) 사용을 권장하여 메모리 부족 오류를 피할 수 있습니다. 최고의 결과를 위해
fp16Clip 모델 변형을 사용하는 것이 좋습니다. - 기타 요구 사항: 빠른 SSD를 사용하면 로딩 시간과 전반적인 성능이 향상됩니다.
3.2. FLUX.1 [Dev] 하드웨어 요구 사항
- 권장 GPU: NVIDIA RTX 3080/3090 또는 최소 16 GB VRAM을 가진 동급의 GPU. 이 버전은 Pro 모델에 비해 하드웨어 요구 사항이 다소 유연하지만 여전히 상당한 GPU 성능이 필요합니다.
- RAM: 16 GB 이상의 시스템 메모리.
- 디스크 공간: 약 25 GB.
- 컴퓨팅 요구 사항: Pro와 유사하게 FP16 모델을 사용하지만, 약간의 낮은 정밀도 계산을 허용합니다. GPU 기능에 따라
fp16또는fp8Clip 모델을 사용할 수 있습니다. - 기타 요구 사항: 최적의 성능을 위해 빠른 SSD를 사용하는 것이 좋습니다.
3.3. FLUX.1 [Schnell] 하드웨어 요구 사항
- 권장 GPU: NVIDIA RTX 3060/4060 또는 12 GB VRAM을 가진 동급의 GPU. 이 버전은 더 빠른 추론과 낮은 하드웨어 요구 사항에 최적화되어 있습니다.
- RAM: 8 GB 이상의 시스템 메모리.
- 디스크 공간: 약 15 GB.
- 컴퓨팅 요구 사항: 이 버전은 덜 까다로우며 메모리 부족 시
fp8계산을 허용합니다. 속도에 중점을 두고 있으며 초고품질보다는 효율성에 초점을 맞추고 있습니다. - 기타 요구 사항: SSD는 유용하지만 Pro 및 Dev 버전만큼 필수적이지는 않습니다.
4. ComfyUI에 FLUX 설치 방법
4.1. ComfyUI 설치 또는 업데이트
ComfyUI 환경 내에서 FLUX.1을 효과적으로 사용하려면 최신 버전의 ComfyUI를 설치하는 것이 중요합니다. 이 버전은 FLUX.1 모델에 필요한 기능과 통합을 지원합니다.
4.2. ComfyUI FLUX 텍스트 인코더 및 CLIP 모델 다운로드
FLUX.1을 사용하여 최적의 성능과 정확한 텍스트-이미지 생성을 위해 특정 텍스트 인코더 및 CLIP 모델을 다운로드해야 합니다. 시스템의 하드웨어에 따라 다음 모델이 필요합니다:
| Model File Name | Size | Note | Link |
t5xxl_fp16.safetensors | 9.79 GB | 더 나은 결과를 위해, 높은 VRAM 및 RAM(32GB 이상의 RAM)을 가진 경우. | Download |
t5xxl_fp8_e4m3fn.safetensors | 4.89 GB | 메모리 사용량이 적은 경우 (8-12GB) | Download |
clip_l.safetensors | 246 MB | Download |
다운로드 및 설치 단계:
clip_l.safetensors모델을 다운로드합니다.- 시스템의 VRAM 및 RAM에 따라
t5xxl_fp8_e4m3fn.safetensors(낮은 VRAM용) 또는t5xxl_fp16.safetensors(높은 VRAM 및 RAM용) 중 하나를 다운로드합니다. - 다운로드한 모델을
ComfyUI/models/clip/디렉토리에 배치합니다. 참고: 이전에 SD 3 Medium을 사용한 경우, 이미 이러한 모델을 가지고 있을 수 있습니다.
4.3. FLUX.1 VAE 모델 다운로드
FLUX.1에서 이미지 생성 품질을 향상시키기 위해 VAE (변분 오토인코더) 모델이 중요합니다. 다음 VAE 모델을 다운로드할 수 있습니다:
| File Name | Size | Link |
ae.safetensors | 335 MB | Download(opens in a new tab) |
다운로드 및 설치 단계:
ae.safetensors모델 파일을 다운로드합니다.- 다운로드한 파일을
ComfyUI/models/vae디렉토리에 배치합니다. - 파일을 쉽게 식별할 수 있도록
flux_ae.safetensors로 이름을 변경하는 것이 좋습니다.
4.4. FLUX.1 UNET 모델 다운로드
UNET 모델은 FLUX.1에서 이미지 합성의 중추 역할을 합니다. 시스템 사양에 따라 다른 변형을 선택할 수 있습니다:
| File Name | Size | Link | Note |
flux1-dev.safetensors | 23.8GB | Download | 높은 VRAM 및 RAM을 가진 경우. |
flux1-schnell.safetensors | 23.8GB | Download | 메모리 사용량이 적은 경우 |
다운로드 및 설치 단계:
- 시스템의 메모리 구성에 따라 적절한 UNET 모델을 다운로드합니다.
- 다운로드한 모델 파일을
ComfyUI/models/unet/디렉토리에 배치합니다.
5. ComfyUI FLUX 워크플로우 | 다운로드, 온라인 액세스, 및 가이드
ComfyUI FLUX 워크플로우를 지속적으로 업데이트하여 ComfyUI FLUX를 사용하여 멋진 이미지를 생성하는 데 필요한 최신 및 가장 포괄적인 워크플로우를 제공합니다.
5.1. ComfyUI 워크플로우: FLUX Txt2Img
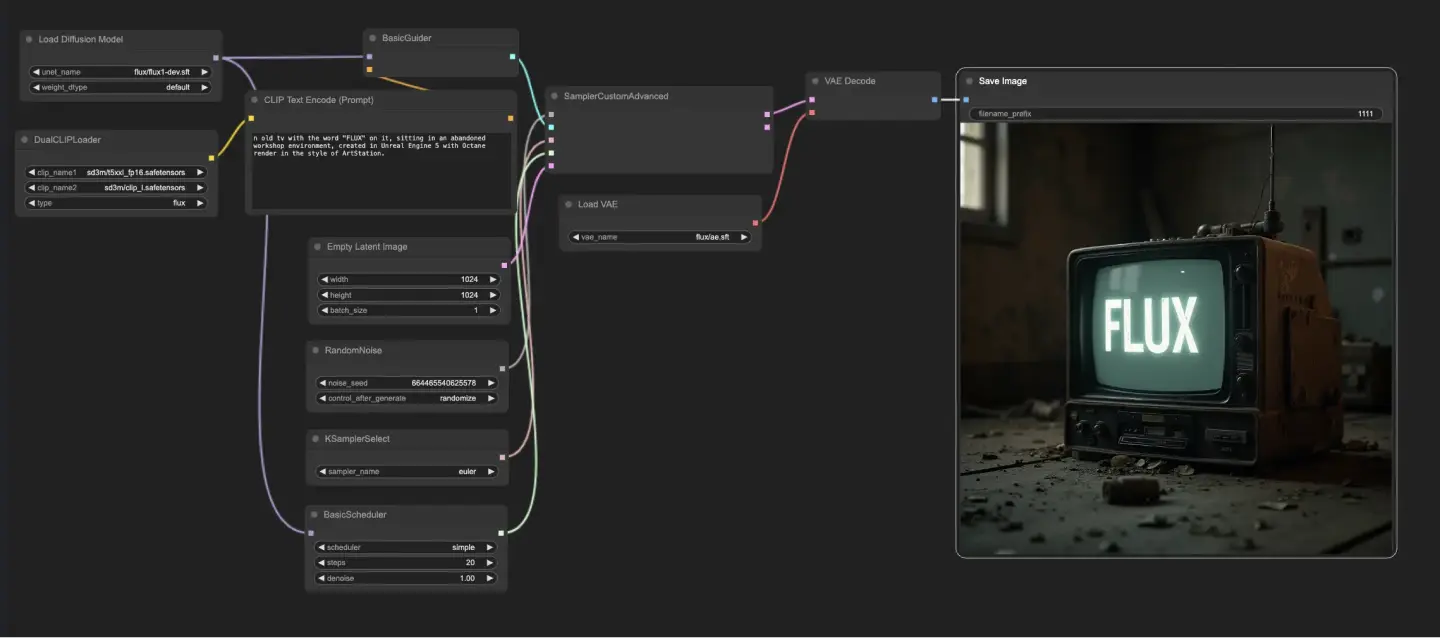
5.1.1. ComfyUI FLUX Txt2Img : Download
5.1.2. ComfyUI FLUX Txt2Img 온라인 버전: ComfyUI FLUX Txt2Img
RunComfy 플랫폼에서는 모든 필수 모드와 노드를 미리 로드합니다. 또한 고성능 GPU 머신을 제공하여 ComfyUI FLUX Txt2Img 경험을 쉽게 즐길 수 있습니다.
5.1.3. ComfyUI FLUX Txt2Img 설명:
ComfyUI FLUX Txt2Img 워크플로우는 FLUX UNET (UNETLoader), FLUX CLIP (DualCLIPLoader), FLUX VAE (VAELoader) 등의 필수 구성 요소를 로드하는 것으로 시작됩니다. 이는 ComfyUI FLUX 이미지 생성 프로세스의 기초를 형성합니다.
- UNETLoader: 이미지 생성을 위한 UNET 모델을 로드합니다.
- 체크포인트: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: 텍스트 인코딩을 위한 CLIP 모델을 로드합니다.
- 임베딩 모델 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- 임베딩 모델 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- 그룹화: CLIP 모델의 그룹화 전략은 flux입니다.
- VAELoader: 잠재 표현을 디코딩하기 위한 변분 오토인코더 (VAE) 모델을 로드합니다.
- VAE 모델: flux/ae.sft
텍스트 프롬프트는 원하는 출력을 설명하며, CLIPTextEncode를 사용하여 인코딩됩니다. 이 노드는 텍스트 프롬프트를 입력으로 받아 인코딩된 텍스트 컨디셔닝을 출력하며, 이는 ComfyUI FLUX가 생성 중에 가이드를 제공합니다.
ComfyUI FLUX 생성 프로세스를 시작하기 위해, 빈 잠재 표현이 EmptyLatentImage를 사용하여 생성됩니다. 이는 ComfyUI FLUX가 구축할 출발점으로 사용됩니다.
BasicGuider는 ComfyUI FLUX 생성 프로세스를 안내하는 중요한 역할을 합니다. 이는 인코딩된 텍스트 컨디셔닝과 로드된 FLUX UNET을 입력으로 받아, 생성된 출력이 제공된 텍스트 설명과 일치하도록 합니다.
KSamplerSelect는 ComfyUI FLUX 생성에 사용할 샘플링 방법을 선택할 수 있게 하며, RandomNoise는 ComfyUI FLUX에 입력으로 사용할 랜덤 노이즈를 생성합니다. BasicScheduler는 생성 프로세스의 각 단계에서 노이즈 레벨 (시그마)을 스케줄링하여 최종 출력의 세부 사항과 선명도를 제어합니다.
SamplerCustomAdvanced는 ComfyUI FLUX Txt2Img 워크플로우의 모든 구성 요소를 결합합니다. 이는 랜덤 노이즈, 가이더, 선택한 샘플러, 스케줄된 시그마 및 빈 잠재 표현을 입력으로 받아, 텍스트 프롬프트를 나타내는 잠재 표현을 생성합니다.
마지막으로, VAEDecode는 로드된 FLUX VAE를 사용하여 생성된 잠재 표현을 최종 출력으로 디코딩합니다. SaveImage는 생성된 출력을 지정된 위치에 저장하여 ComfyUI FLUX Txt2Img 워크플로우로 만든 멋진 창작물을 보존할 수 있게 합니다.
5.2. ComfyUI 워크플로우: FLUX Img2Img
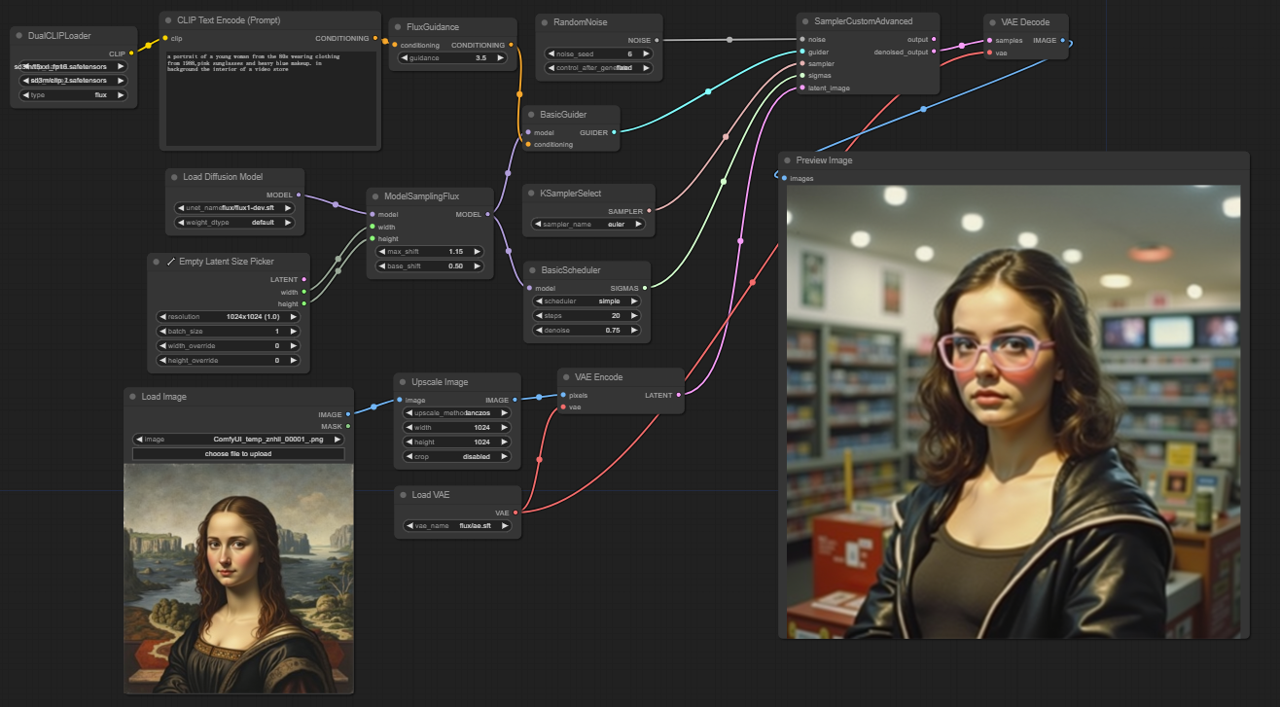
5.2.1. ComfyUI FLUX Img2Img: Download
5.2.2. ComfyUI FLUX Img2Img 온라인 버전: ComfyUI FLUX Img2Img
RunComfy 플랫폼에서는 모든 필수 모드와 노드를 미리 로드합니다. 또한 고성능 GPU 머신을 제공하여 ComfyUI FLUX Img2Img 경험을 쉽게 즐길 수 있습니다.
5.2.3. ComfyUI FLUX Img2Img 설명:
ComfyUI FLUX Img2Img 워크플로우는 텍스트 프롬프트와 입력 표현을 기반으로 출력을 생성하기 위해 ComfyUI FLUX의 힘을 활용합니다. 이 워크플로우는 CLIP 모델 (DualCLIPLoader), UNET 모델 (UNETLoader), VAE 모델 (VAELoader) 등의 필수 구성 요소를 로드하는 것으로 시작됩니다.
- UNETLoader: 이미지 생성을 위한 UNET 모델을 로드합니다.
- 체크포인트: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: 텍스트 인코딩을 위한 CLIP 모델을 로드합니다.
- 임베딩 모델 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- 임베딩 모델 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- 그룹화: CLIP 모델의 그룹화 전략은 flux입니다.
- VAELoader: 잠재 표현을 디코딩하기 위한 변분 오토인코더 (VAE) 모델을 로드합니다.
- VAE 모델: flux/ae.sft
입력 표현은 ComfyUI FLUX Img2Img 프로세스의 출발점으로 사용되며, LoadImage를 사용하여 로드됩니다. ImageScale은 입력 표현을 원하는 크기로 조정하여 ComfyUI FLUX와의 호환성을 보장합니다.
조정된 입력 표현은 VAEEncode를 사용하여 인코딩되어 잠재 표현으로 변환됩니다. 이 잠재 표현은 입력의 주요 특징과 세부 사항을 포착하여 ComfyUI FLUX가 작업할 기초를 제공합니다.
텍스트 프롬프트는 원하는 수정 또는 향상을 설명하며, CLIPTextEncode를 사용하여 인코딩됩니다. FluxGuidance는 지정된 가이드 스케일에 따라 컨디셔닝에 가이드를 적용하여 최종 출력에 텍스트 프롬프트의 영향을 강화합니다.
ModelSamplingFlux는 ComfyUI FLUX의 샘플링 매개변수를 설정하며, 여기에는 타임스텝 재스페이싱, 패딩 비율 및 출력 차원이 포함됩니다. 이러한 매개변수는 생성된 출력의 세밀도와 해상도를 제어합니다.
KSamplerSelect는 ComfyUI FLUX 생성에 사용할 샘플링 방법을 선택할 수 있게 하며, BasicGuider는 인코딩된 텍스트 컨디셔닝 및 로드된 FLUX UNET을 기반으로 생성 프로세스를 안내합니다.
랜덤 노이즈는 RandomNoise를 사용하여 생성되며, BasicScheduler는 생성 프로세스의 각 단계에서 노이즈 레벨 (시그마)을 스케줄링하여 최종 출력의 세부 사항과 선명도를 제어합니다.
SamplerCustomAdvanced는 랜덤 노이즈, 가이더, 선택한 샘플러, 스케줄된 시그마 및 입력의 잠재 표현을 결합합니다. 고급 샘플링 프로세스를 통해, 텍스트 프롬프트에 의해 지정된 수정 사항을 통합하면서 입력의 주요 특징을 보존하는 잠재 표현을 생성합니다.
마지막으로, VAEDecode는 로드된 FLUX VAE를 사용하여 디노이즈된 잠재 표현을 최종 출력으로 디코딩합니다. PreviewImage는 생성된 출력의 미리보기를 표시하여 ComfyUI FLUX Img2Img 워크플로우로 달성한 멋진 결과를 보여줍니다.
5.3. ComfyUI 워크플로우: FLUX LoRA
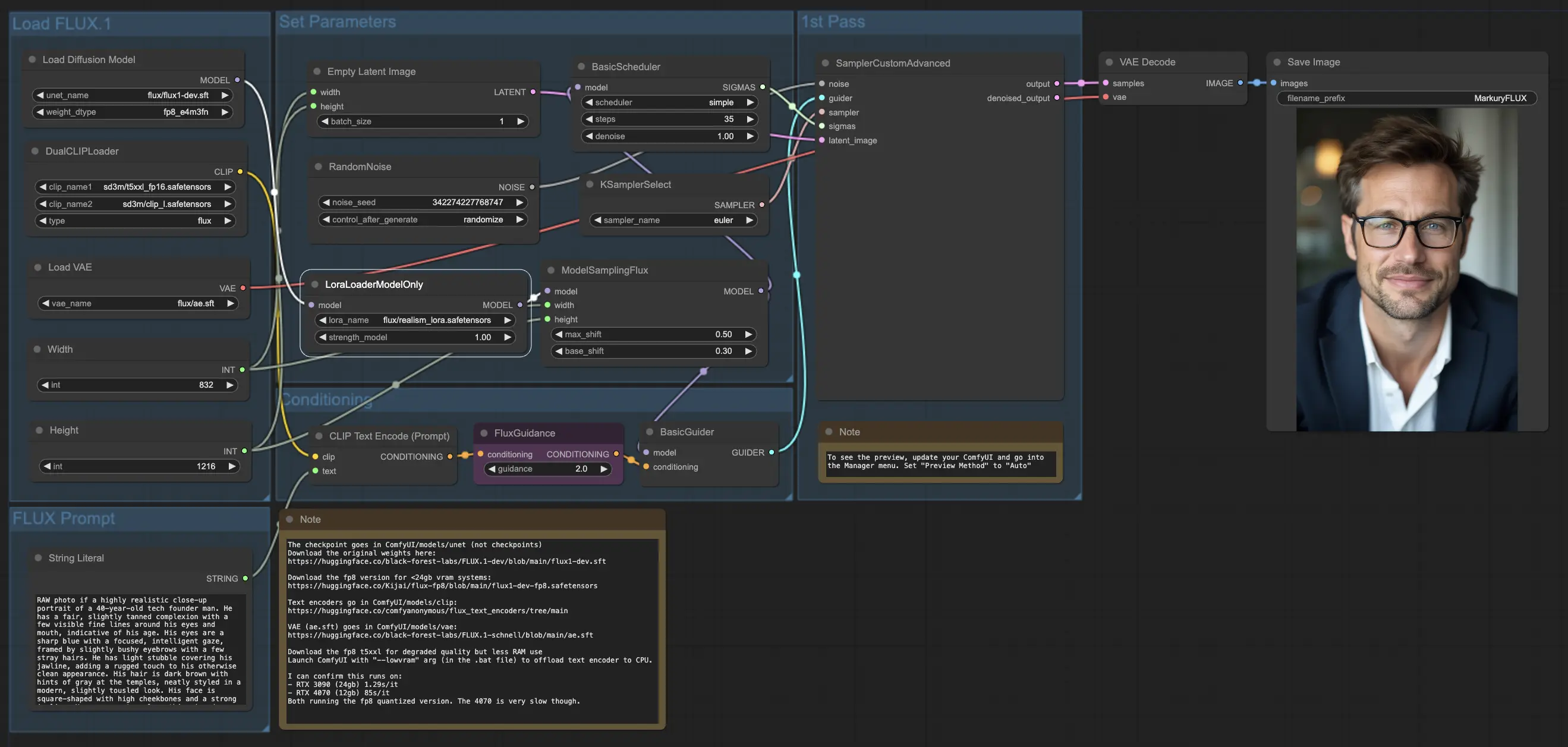
5.3.1. ComfyUI FLUX LoRA: Download
5.3.2. ComfyUI FLUX LoRA 온라인 버전: ComfyUI FLUX LoRA
RunComfy 플랫폼에서는 모든 필수 모드와 노드를 미리 로드합니다. 또한 고성능 GPU 머신을 제공하여 ComfyUI FLUX LoRA 경험을 쉽게 즐길 수 있습니다.
5.3.3. ComfyUI FLUX LoRA 설명:
ComfyUI FLUX LoRA 워크플로우는 Low-Rank Adaptation (LoRA)의 힘을 활용하여 ComfyUI FLUX의 성능을 향상시킵니다. 이 워크플로우는 UNET 모델 (UNETLoader), CLIP 모델 (DualCLIPLoader), VAE 모델 (VAELoader), 및 LoRA 모델 (LoraLoaderModelOnly) 등의 필수 구성 요소를 로드하는 것으로 시작됩니다.
- UNETLoader: 이미지 생성을 위한 UNET 모델을 로드합니다.
- 체크포인트: flux/flux1-dev.sft
- DualCLIPLoader: 텍스트 인코딩을 위한 CLIP 모델을 로드합니다.
- 임베딩 모델 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- 임베딩 모델 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- 그룹화: CLIP 모델의 그룹화 전략은 flux입니다.
- VAELoader: 잠재 표현을 디코딩하기 위한 변분 오토인코더 (VAE) 모델을 로드합니다.
- VAE 모델: flux/ae.sft
- LoraLoaderModelOnly: UNET 모델을 향상시키기 위한 LoRA (Low-Rank Adaptation) 모델을 로드합니다.
- LoaderModel: flux/realism_lora.safetensors
텍스트 프롬프트는 원하는 출력을 설명하며, String Literal을 사용하여 지정됩니다. CLIPTextEncode는 텍스트 프롬프트를 인코딩하여 ComfyUI FLUX 생성 프로세스를 안내하는 인코딩된 텍스트 컨디셔닝을 생성합니다.
FluxGuidance는 인코딩된 텍스트 컨디셔닝에 가이드를 적용하여 ComfyUI FLUX의 텍스트 프롬프트 준수 강도를 강화합니다.
빈 잠재 표현은 EmptyLatentImage를 사용하여 생성되며, 이는 생성의 출발점으로 사용됩니다. 생성된 출력의 원하는 크기를 보장하기 위해 Int Literal을 사용하여 너비와 높이가 지정됩니다.
ModelSamplingFlux는 ComfyUI FLUX의 샘플링 매개변수를 설정하며, 여기에는 패딩 비율 및 타임스텝 재스페이싱이 포함됩니다. 이러한 매개변수는 생성된 출력의 해상도와 세밀도를 제어합니다.
KSamplerSelect는 ComfyUI FLUX 생성에 사용할 샘플링 방법을 선택할 수 있게 하며, BasicGuider는 인코딩된 텍스트 컨디셔닝과 FLUX LoRA로 향상된 로드된 FLUX UNET을 기반으로 생성 프로세스를 안내합니다.
랜덤 노이즈는 RandomNoise를 사용하여 생성되며, BasicScheduler는 생성 프로세스의 각 단계에서 노이즈 레벨 (시그마)을 스케줄링하여 최종 출력의 세부 사항과 선명도를 제어합니다.
SamplerCustomAdvanced는 랜덤 노이즈, 가이더, 선택한 샘플러, 스케줄된 시그마 및 빈 잠재 표현을 결합합니다. 고급 샘플링 프로세스를 통해 텍스트 프롬프트를 나타내는 잠재 표현을 생성하며, 이는 FLUX 및 FLUX LoRA 향상의 힘을 활용합니다.
마지막으로, VAEDecode는 로드된 FLUX VAE를 사용하여 생성된 잠재 표현을 최종 출력으로 디코딩합니다. SaveImage는 생성된 출력을 지정된 위치에 저장하여 ComfyUI FLUX LoRA 워크플로우로 만든 멋진 창작물을 보존할 수 있게 합니다.
5.4. ComfyUI 워크플로우: FLUX ControlNet
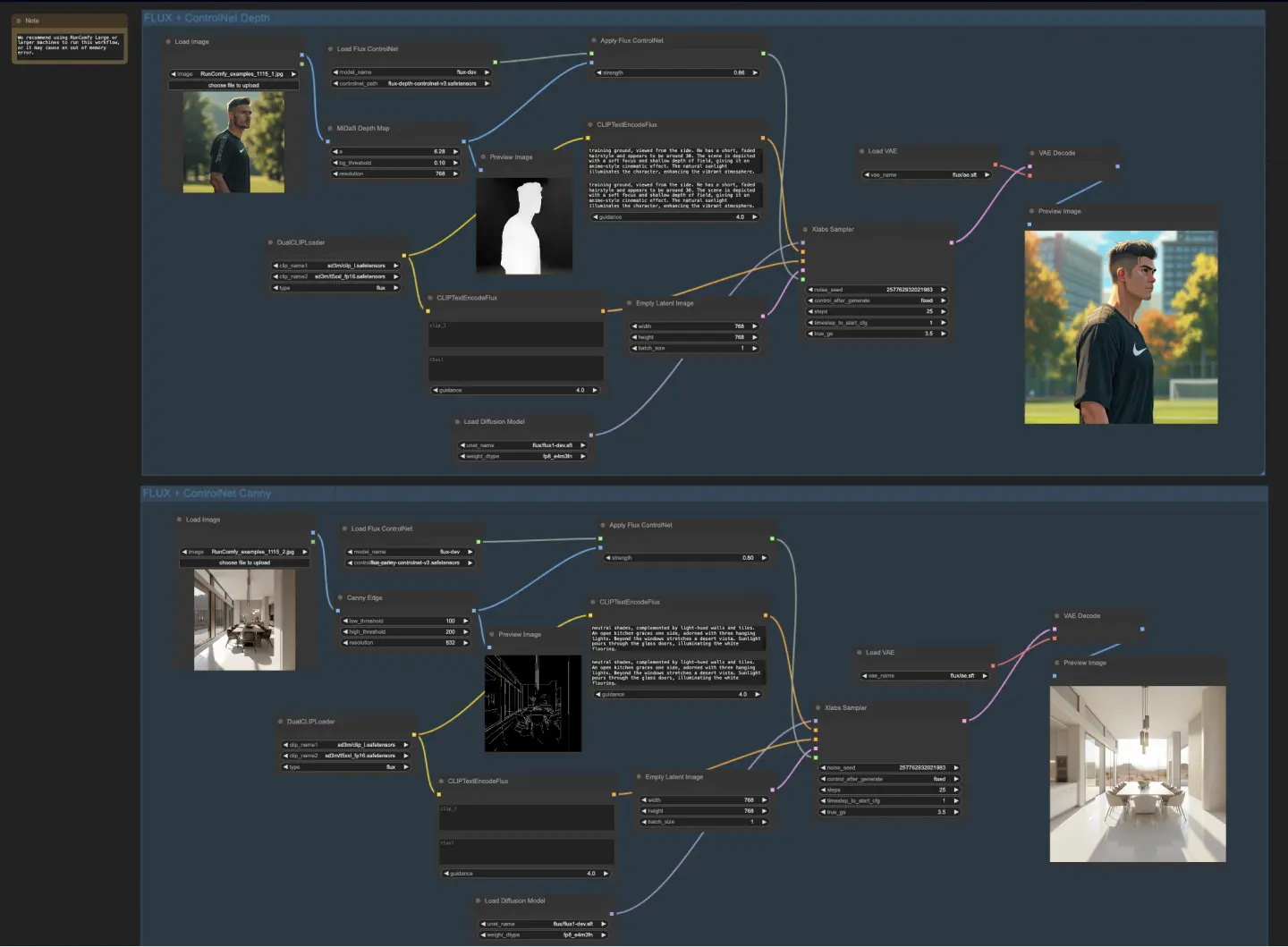
5.4.1. ComfyUI FLUX ControlNet: Download
5.4.2. ComfyUI FLUX ControlNet 온라인 버전: ComfyUI FLUX ControlNet
RunComfy 플랫폼에서는 모든 필수 모드와 노드를 미리 로드합니다. 또한 고성능 GPU 머신을 제공하여 ComfyUI FLUX ControlNet 경험을 쉽게 즐길 수 있습니다.
5.4.3. ComfyUI FLUX ControlNet 설명:
ComfyUI FLUX ControlNet 워크플로우는 ControlNet을 ComfyUI FLUX와 통합하여 출력 생성을 향상시키는 방법을 보여줍니다. 이 워크플로우는 깊이 기반 컨디셔닝과 Canny 에지 기반 컨디셔닝의 두 가지 예제를 보여줍니다.
- UNETLoader: 이미지 생성을 위한 UNET 모델을 로드합니다.
- 체크포인트: flux/flux1-dev.sft
- DualCLIPLoader: 텍스트 인코딩을 위한 CLIP 모델을 로드합니다.
- 임베딩 모델 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- 임베딩 모델 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- 그룹화: CLIP 모델의 그룹화 전략은 flux입니다.
- VAELoader: 잠재 표현을 디코딩하기 위한 변분 오토인코더 (VAE) 모델을 로드합니다.
- VAE 모델: flux/ae.sft
깊이 기반 워크플로우에서는 입력 표현이 MiDaS-DepthMapPreprocessor를 사용하여 전처리되어 깊이 맵을 생성합니다. 깊이 맵은 로드된 FLUX ControlNet과 함께 ApplyFluxControlNet (Depth)을 통해 깊이 컨디셔닝을 위해 전달됩니다. 결과 FLUX ControlNet 조건은 XlabsSampler (Depth)의 입력으로 사용되며, 여기에는 로드된 FLUX UNET, 인코딩된 텍스트 컨디셔닝, 네거티브 텍스트 컨디셔닝 및 빈 잠재 표현이 포함됩니다. XlabsSampler는 이러한 입력을 기반으로 잠재 표현을 생성하며, 이는 VAEDecode를 사용하여 최종 출력으로 디코딩됩니다.
- MiDaS-DepthMapPreprocessor (Depth): MiDaS를 사용하여 입력 이미지를 깊이 추정용으로 전처리합니다.
- LoadFluxControlNet: ControlNet 모델을 로드합니다.
- 경로: flux-depth-controlnet.safetensors
유사하게, Canny 에지 기반 워크플로우에서는 입력 표현이 CannyEdgePreprocessor를 사용하여 전처리되어 Canny 에지를 생성합니다. Canny 에지 표현은 로드된 FLUX ControlNet과 함께 ApplyFluxControlNet (Canny)을 통해 Canny 에지 컨디셔닝을 위해 전달됩니다. 결과 FLUX ControlNet 조건은 XlabsSampler (Canny)의 입력으로 사용되며, 여기에는 로드된 FLUX UNET, 인코딩된 텍스트 컨디셔닝, 네거티브 텍스트 컨디셔닝 및 빈 잠재 표현이 포함됩니다. XlabsSampler는 이러한 입력을 기반으로 잠재 표현을 생성하며, 이는 VAEDecode를 사용하여 최종 출력으로 디코딩됩니다.
- CannyEdgePreprocessor (Canny): 입력 이미지를 Canny 에지 검출용으로 전처리합니다.
- LoadFluxControlNet: ControlNet 모델을 로드합니다.
- 경로: flux-canny-controlnet.safetensors
ComfyUI FLUX ControlNet 워크플로우는 필수 구성 요소 (DualCLIPLoader, UNETLoader, VAELoader, LoadFluxControlNet)를 로드하고, 텍스트 프롬프트를 인코딩하며 (CLIPTextEncodeFlux), 빈 잠재 표현을 생성하고 (EmptyLatentImage), 생성된 출력 및 전처리된 출력의 미리보기를 표시하는 (PreviewImage) 노드를 포함합니다.
FLUX ControlNet의 힘을 활용함으로써, ComfyUI FLUX ControlNet 워크플로우는 깊이 맵이나 Canny 에지와 같은 특정 컨디셔닝과 일치하는 출력을 생성할 수 있습니다. 이 추가적인 제어 및 가이드 수준은 생성 프로세스의 유연성과 정밀성을 향상시켜, ComfyUI FLUX를 사용하여 멋지고 맥락적으로 관련 있는 출력을 생성할 수 있게 합니다.
5.5. ComfyUI 워크플로우: FLUX Inpainting
5.5.1. ComfyUI FLUX Inpainting: Download
5.5.2. ComfyUI FLUX Inpainting 온라인 버전: ComfyUI FLUX Inpainting
RunComfy 플랫폼에서는 모든 필수 모드와 노드를 미리 로드합니다. 또한 고성능 GPU 머신을 제공하여 ComfyUI FLUX Inpainting 경험을 쉽게 즐길 수 있습니다.
5.5.3. ComfyUI FLUX Inpainting 설명:
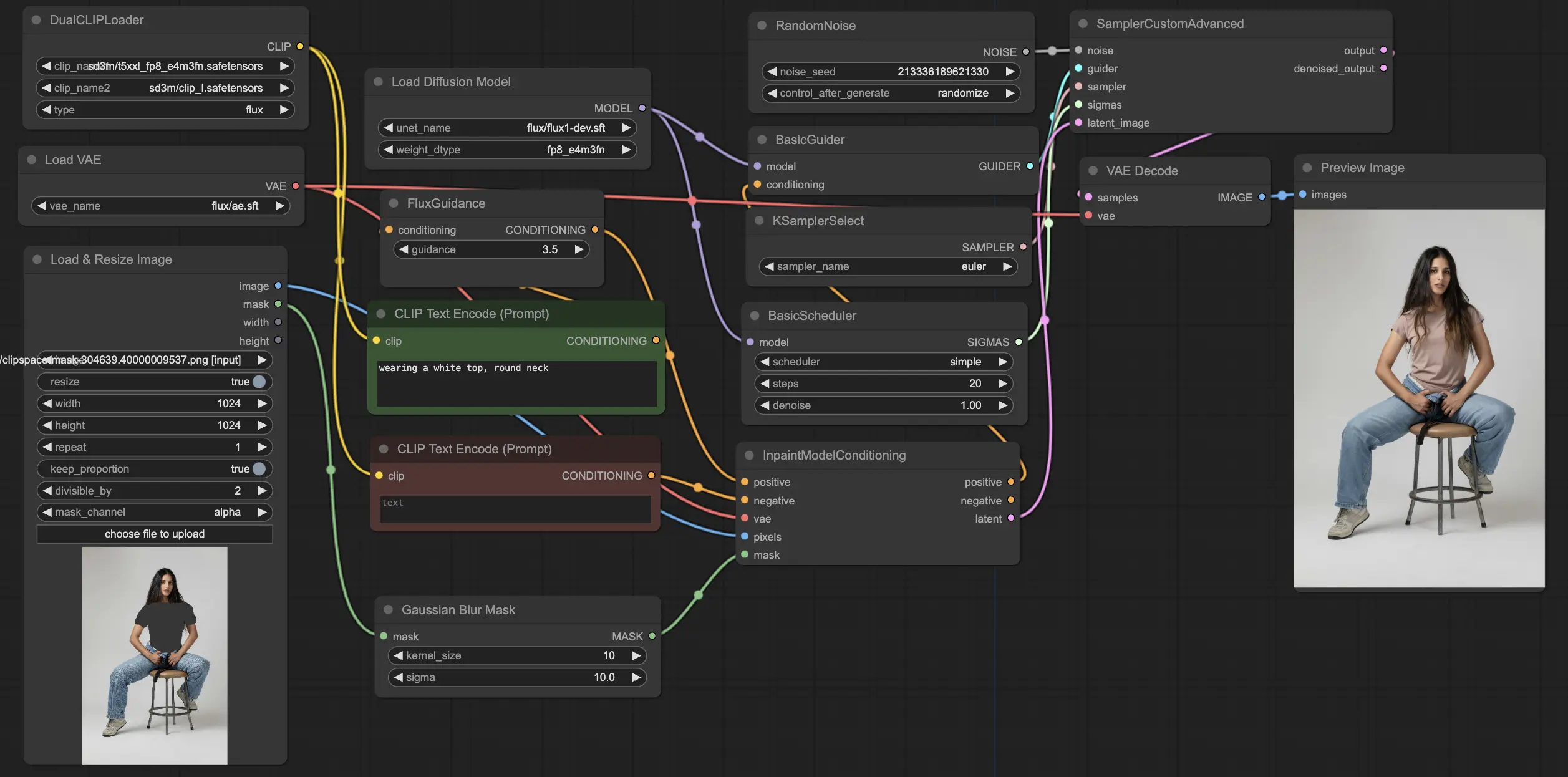
ComfyUI FLUX Inpainting 워크플로우는 주어진 텍스트 프롬프트와 주변 맥락을 기반으로 출력의 누락되거나 마스킹된 영역을 채우는 능력을 보여줍니다. 워크플로우는 UNET 모델 (UNETLoader), VAE 모델 (VAELoader), 및 CLIP 모델 (DualCLIPLoader) 등의 필수 구성 요소를 로드하는 것으로 시작됩니다.
- UNETLoader: 이미지 생성을 위한 UNET 모델을 로드합니다.
- 체크포인트: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: 텍스트 인코딩을 위한 CLIP 모델을 로드합니다.
- 임베딩 모델 1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- 임베딩 모델 2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- 그룹화: CLIP 모델의 그룹화 전략은 flux입니다.
- VAELoader: 잠재 표현을 디코딩하기 위한 변분 오토인코더 (VAE) 모델을 로드합니다.
- VAE 모델: flux/ae.sft
긍정적 및 부정적 텍스트 프롬프트는 원하는 인페인팅 영역의 내용과 스타일을 설명하며, CLIPTextEncodes를 사용하여 인코딩됩니다. 긍정적 텍스트 컨디셔닝은 ComfyUI FLUX 인페인팅 프로세스에 영향을 주기 위해 FluxGuidance를 사용하여 추가로 안내됩니다.
입력 표현과 마스크는 LoadAndResizeImage를 사용하여 로드 및 크기 조정되며, 이는 ComfyUI FLUX의 요구 사항과 호환성을 보장합니다. ImpactGaussianBlurMask는 마스크에 가우시안 블러를 적용하여 인페인팅 영역과 원본 표현 간의 부드러운 전환을 만듭니다.
InpaintModelConditioning은 가이드된 긍정적 텍스트 컨디셔닝, 인코딩된 부정적 텍스트 컨디셔닝, 로드된 FLUX VAE, 로드 및 크기 조정된 입력 표현, 및 블러된 마스크를 결합하여 FLUX 인페인팅을 위한 컨디셔닝을 준비합니다. 이 컨디셔닝은 ComfyUI FLUX 인페인팅 프로세스의 기초로 사용됩니다.
랜덤 노이즈는 RandomNoise를 사용하여 생성되며, 샘플링 방법은 KSamplerSelect를 사용하여 선택됩니다. BasicScheduler는 ComfyUI FLUX 인페인팅 프로세스의 각 단계에서 노이즈 레벨 (시그마)을 스케줄링하여 인페인팅 영역의 세부 사항과 선명도를 제어합니다.
BasicGuider는 준비된 컨디셔닝과 로드된 FLUX UNET을 기반으로 ComfyUI FLUX 인페인팅 프로세스를 안내합니다. SamplerCustomAdvanced는 고급 샘플링 프로세스를 수행하며, 생성된 랜덤 노이즈, 가이더, 선택한 샘플러, 스케줄된 시그마, 및 입력의 잠재 표현을 입력으로 받아 인페인팅된 잠재 표현을 출력합니다.
마지막으로, VAEDecode는 인페인팅된 잠재 표현을 최종 출력으로 디코딩하여 원본 표현과 매끄럽게 혼합합니다. PreviewImage는 최종 출력을 표시하여 FLUX의 인페인팅 기능을 보여줍니다.
FLUX의 힘과 신중하게 설계된 인페인팅 워크플로우를 활용함으로써, FLUX Inpainting은 시각적으로 일관되고 맥락적으로 관련 있는 인페인팅된 출력을 생성할 수 있습니다. 누락된 부분을 복원하거나, 원치 않는 객체를 제거하거나, 특정 영역을 수정하는 등, ComfyUI FLUX 인페인팅 워크플로우는 편집 및 조작을 위한 강력한 도구를 제공합니다.
5.6. ComfyUI 워크플로우: FLUX NF4
5.6.1. ComfyUI FLUX NF4: Download
5.6.2. ComfyUI FLUX NF4 온라인 버전: ComfyUI FLUX NF4
RunComfy 플랫폼에서는 모든 필수 모드와 노드를 미리 로드합니다. 또한 고성능 GPU 머신을 제공하여 ComfyUI FLUX NF4 경험을 쉽게 즐길 수 있습니다.
5.6.3. ComfyUI FLUX NF4 설명:
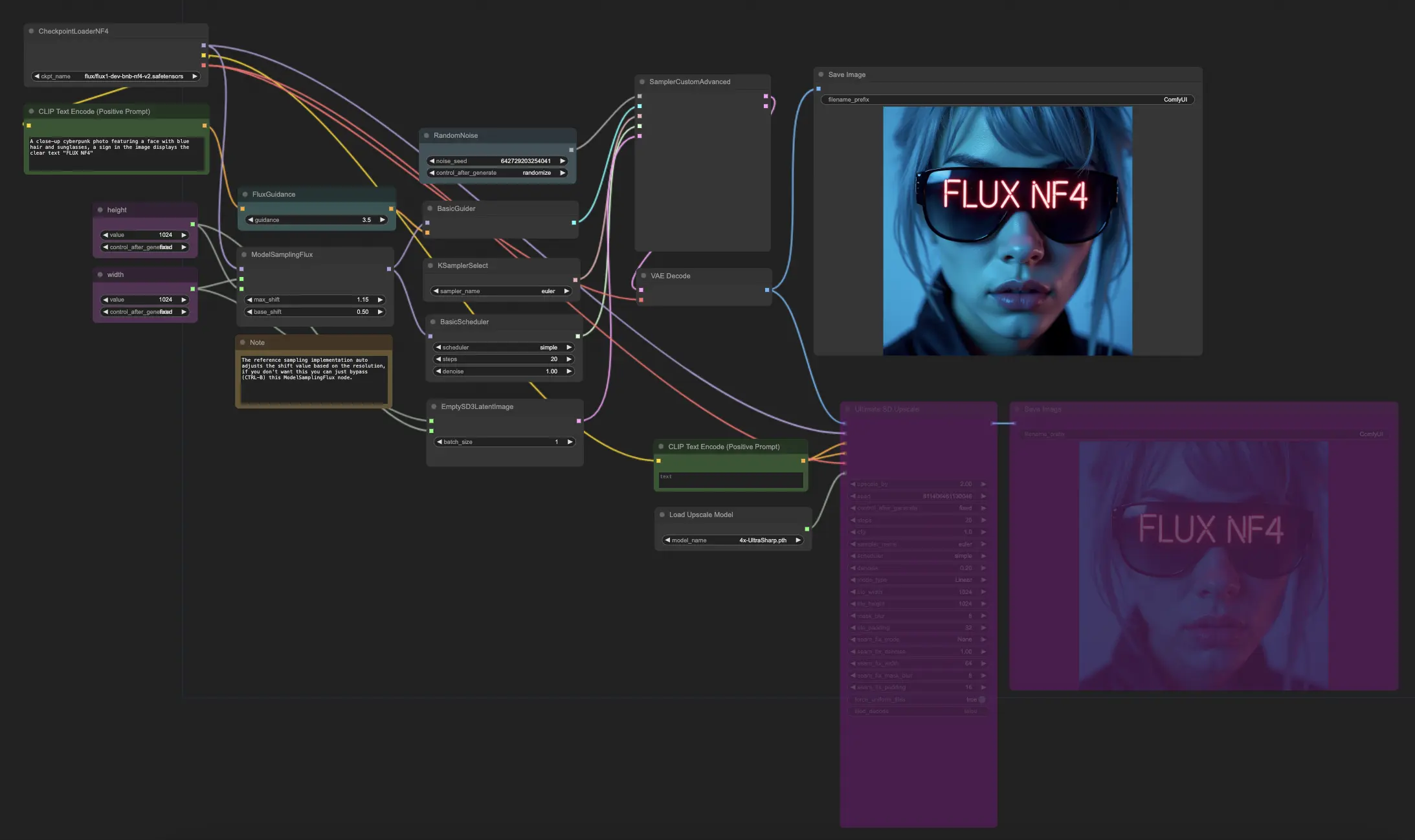
ComfyUI FLUX NF4 워크플로우는 고품질 출력 생성을 위해 ComfyUI FLUX와 NF4 (Normalizing Flow 4) 아키텍처를 통합하는 방법을 보여줍니다. 워크플로우는 CheckpointLoaderNF4를 사용하여 필요한 구성 요소를 로드하는 것으로 시작되며, 여기에는 FLUX UNET, FLUX CLIP, 및 FLUX VAE가 포함됩니다.
- UNETLoader: 이미지 생성을 위한 UNET 모델을 로드합니다.
- 체크포인트: TBD
PrimitiveNode (height) 및 PrimitiveNode (width) 노드는 생성된 출력의 원하는 높이와 너비를 지정합니다. ModelSamplingFlux 노드는 로드된 FLUX UNET 및 지정된 높이와 너비를 기반으로 ComfyUI FLUX의 샘플링 매개변수를 설정합니다.
EmptySD3LatentImage 노드는 생성의 출발점으로 사용되는 빈 잠재 표현을 생성합니다. BasicScheduler 노드는 ComfyUI FLUX 생성 프로세스의 노이즈 레벨 (시그마)을 스케줄링합니다.
RandomNoise 노드는 ComfyUI FLUX 생성 프로세스를 위한 랜덤 노이즈를 생성합니다. BasicGuider 노드는 컨디셔닝된 ComfyUI FLUX를 기반으로 생성 프로세스를 안내합니다.
KSamplerSelect 노드는 ComfyUI FLUX 생성에 사용할 샘플링 방법을 선택합니다. SamplerCustomAdvanced 노드는 고급 샘플링 프로세스를 수행하며, 생성된 랜덤 노이즈, 가이더, 선택한 샘플러, 스케줄된 시그마, 및 빈 잠재 표현을 입력으로 받아 생성된 잠재 표현을 출력합니다.
VAEDecode 노드는 로드된 FLUX VAE를 사용하여 생성된 잠재 표현을 최종 출력으로 디코딩합니다. SaveImage 노드는 생성된 출력을 지정된 위치에 저장합니다.
업스케일링을 위해 UltimateSDUpscale 노드를 사용합니다. 이는 생성된 출력, 로드된 FLUX, 업스케일링을 위한 긍정적 및 부정적 컨디셔닝, 로드된 FLUX VAE 및 로드된 FLUX 업스케일링을 입력으로 받습니다. CLIPTextEncode (Upscale Positive Prompt) 노드는 업스케일링을 위한 긍정적 텍스트 프롬프트를 인코딩합니다. UpscaleModelLoader 노드는 FLUX 업스케일링을 로드합니다. UltimateSDUpscale 노드는 업스케일링 프로세스를 수행하여 업스케일된 표현을 출력합니다. 마지막으로, SaveImage (Upscaled) 노드는 업스케일된 출력을 지정된 위치에 저장합니다.
ComfyUI FLUX와 NF4 아키텍처의 힘을 활용함으로써, ComfyUI FLUX NF4 워크플로우는 향상된 충실도와 현실감을 가진 고품질 출력을 생성할 수 있습니다. ComfyUI FLUX와 NF4 아키텍처의 원활한 통합은 멋지고 매혹적인 출력을 생성할 수 있는 강력한 도구를 제공합니다.
5.7. ComfyUI 워크플로우: FLUX IPAdapter
5.7.1. ComfyUI FLUX IPAdapter: Download
5.7.2. ComfyUI FLUX IPAdapter 온라인 버전: ComfyUI FLUX IPAdapter
RunComfy 플랫폼에서는 모든 필수 모드와 노드를 미리 로드합니다. 또한 고성능 GPU 머신을 제공하여 ComfyUI FLUX IPAdapter 경험을 쉽게 즐길 수 있습니다.
5.7.3. ComfyUI FLUX IPAdapter 설명:
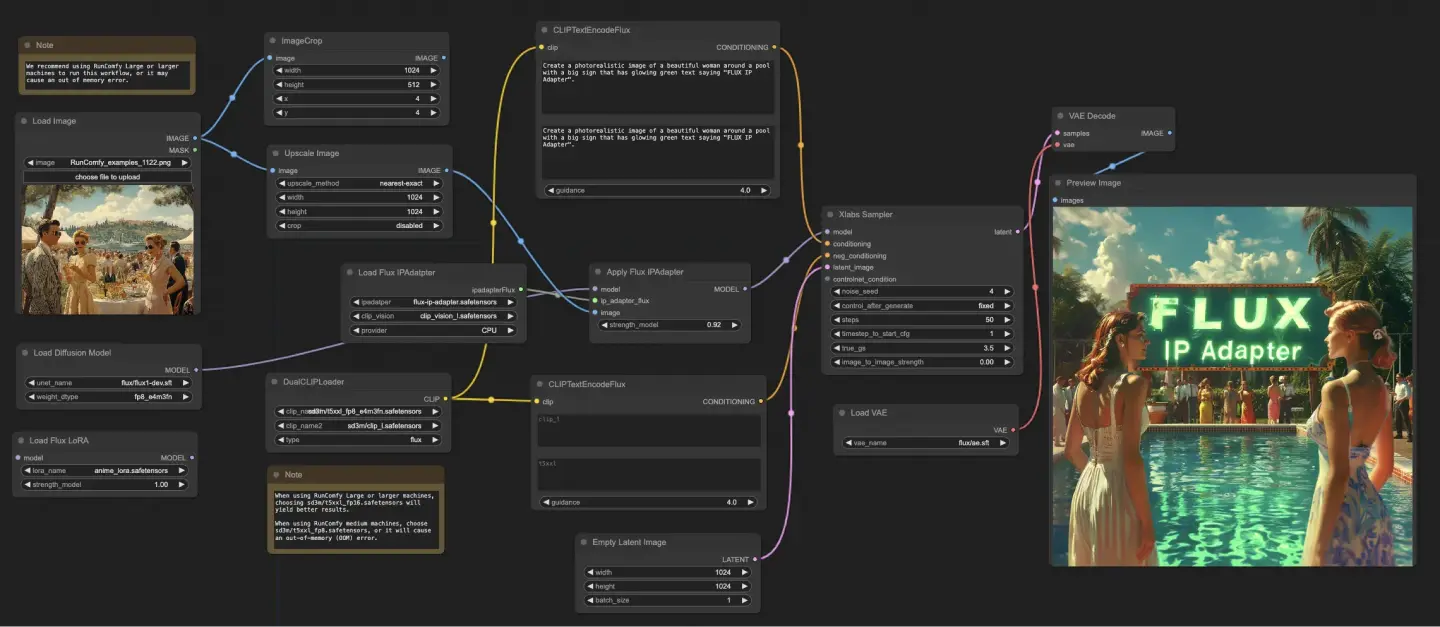
ComfyUI FLUX IPAdapter 워크플로우는 UNET 모델 (UNETLoader), CLIP 모델 (DualCLIPLoader), 및 VAE 모델 (VAELoader) 등의 필요한 모델을 로드하는 것으로 시작됩니다.
긍정적 및 부정적 텍스트 프롬프트는 CLIPTextEncodeFlux를 사용하여 인코딩됩니다. 긍정적 텍스트 컨디셔닝은 ComfyUI FLUX 생성 프로세스를 안내하는 데 사용됩니다.
입력 이미지는 LoadImage를 사용하여 로드됩니다. LoadFluxIPAdapter는 FLUX 모델을 위한 IP-Adapter를 로드하며, 이는 ApplyFluxIPAdapter를 사용하여 로드된 UNET 모델에 적용됩니다. ImageScale은 입력 이미지를 원하는 크기로 조정한 후 IP-Adapter를 적용합니다.
- LoadFluxIPAdapter: FLUX 모델을 위한 IP-Adapter를 로드합니다.
- IP Adapter 모델: flux-ip-adapter.safetensors
- CLIP Vision 인코더: clip_vision_l.safetensors
EmptyLatentImage는 ComfyUI FLUX 생성을 위한 출발점으로 사용되는 빈 잠재 표현을 생성합니다.
XlabsSampler는 샘플링 프로세스를 수행하며, 여기에는 IP-Adapter가 적용된 FLUX UNET, 인코딩된 긍정적 및 부정적 텍스트 컨디셔닝, 및 빈 잠재 표현이 포함됩니다. 이는 잠재 표현을 생성합니다.
VAEDecode는 로드된 FLUX VAE를 사용하여 생성된 잠재 표현을 최종 출력으로 디코딩합니다. PreviewImage 노드는 최종 출력의 미리보기를 표시합니다.
ComfyUI FLUX IPAdapter 워크플로우는 ComfyUI FLUX와 IP-Adapter의 힘을 활용하여 제공된 텍스트 프롬프트와 일치하는 고품질 출력을 생성합니다. IP-Adapter를 FLUX UNET에 적용함으로써, 워크플로우는 텍스트 컨디셔닝에서 지정된 특성과 스타일을 캡처한 출력을 생성할 수 있게 합니다.
5.8. ComfyUI 워크플로우: Flux LoRA Trainer

5.8.1. ComfyUI FLUX LoRA Trainer: Download
5.8.2. ComfyUI Flux LoRA Trainer 설명:
ComfyUI FLUX LoRA Trainer 워크플로우는 ComfyUI에서 FLUX 아키텍처를 사용하여 LoRA를 훈련시키는 여러 단계를 포함합니다.
ComfyUI FLUX 선택 및 구성: FluxTrainModelSelect 노드는 UNET, VAE, CLIP, 및 CLIP 텍스트 인코더를 포함한 훈련용 구성 요소를 선택하는 데 사용됩니다. OptimizerConfig 노드는 ComfyUI FLUX 훈련을 위한 옵티마이저 설정을 구성하며, 여기에는 옵티마이저 유형, 학습률 및 가중치 감소가 포함됩니다. TrainDatasetGeneralConfig 및 TrainDatasetAdd 노드는 해상도, 증강 설정 및 배치 크기를 포함한 훈련 데이터셋을 구성하는 데 사용됩니다.
ComfyUI FLUX 훈련 초기화: InitFluxLoRATraining 노드는 선택된 구성 요소, 데이터셋 구성 및 옵티마이저 설정을 사용하여 LoRA 훈련 프로세스를 초기화합니다. FluxTrainValidationSettings 노드는 검증 샘플 수, 해상도 및 배치 크기와 같은 훈련을 위한 검증 설정을 구성합니다.
ComfyUI FLUX 훈련 루프: FluxTrainLoop 노드는 지정된 단계 수 동안 LoRA에 대한 훈련 루프를 수행합니다. 각 훈련 루프 후, FluxTrainValidate 노드는 검증 설정을 사용하여 훈련된 LoRA를 검증하고 검증 출력을 생성합니다. PreviewImage 노드는 검증 결과의 미리보기를 표시합니다. FluxTrainSave 노드는 지정된 간격으로 훈련된 LoRA를 저장합니다.
ComfyUI FLUX 손실 시각화: VisualizeLoss 노드는 훈련 과정에서 손실을 시각화합니다. SaveImage 노드는 추가 분석을 위해 손실 플롯을 저장합니다.
ComfyUI FLUX 검증 출력 처리: AddLabel 및 SomethingToString 노드는 검증 출력에 훈련 단계를 나타내는 레이블을 추가하는 데 사용됩니다. ImageBatchMulti 및 ImageConcatFromBatch 노드는 검증 출력을 결합하고 단일 결과로 연결하여 더 쉽게 시각화할 수 있게 합니다.
ComfyUI FLUX 훈련 완료: FluxTrainEnd 노드는 LoRA 훈련 프로세스를 완료하고 훈련된 LoRA를 저장합니다. UploadToHuggingFace 노드는 훈련된 LoRA를 Hugging Face에 업로드하여 ComfyUI FLUX와 함께 공유하고 사용할 수 있도록 합니다.
5.9. ComfyUI 워크플로우: Flux Latent Upscaler
5.9.1. ComfyUI Flux Latent Upscaler: Download
5.9.2. ComfyUI Flux Latent Upscaler 설명:
ComfyUI Flux Latent Upscale 워크플로우는 CLIP (DualCLIPLoader), UNET (UNETLoader), 및 VAE (VAELoader) 등의 필수 구성 요소를 로드하는 것으로 시작됩니다. 텍스트 프롬프트는 CLIPTextEncode 노드를 사용하여 인코딩되며, FluxGuidance 노드를 사용하여 가이드를 적용합니다.
SDXLEmptyLatentSizePicker+ 노드는 FLUX에서 업스케일링 프로세스의 출발점으로 사용되는 빈 잠재 표현의 크기를 지정합니다. 잠재 표현은 LatentUpscale 및 LatentCrop 노드를 사용하여 일련의 업스케일링 및 크롭핑 단계를 거칩니다.
업스케일링 프로세스는 인코딩된 텍스트 컨디셔닝에 의해 안내되며, 선택된 샘플링 방법 (KSamplerSelect) 및 스케줄된 노이즈 레벨 (BasicScheduler)을 사용하여 SamplerCustomAdvanced 노드를 사용합니다. ModelSamplingFlux 노드는 샘플링 매개변수를 설정합니다.
업스케일된 잠재 표현은 SolidMask 및 FeatherMask 노드에 의해 생성된 마스크를 사용하여 LatentCompositeMasked 노드와 함께 원본 잠재 표현과 합성됩니다. 업스케일된 잠재 표현에 노이즈가 InjectLatentNoise+ 노드를 사용하여 주입됩니다.
마지막으로, VAEDecode 노드는 생성된 잠재 표현을 최종 출력으로 디코딩하며, ImageSmartSharpen+ 노드를 사용하여 스마트 샤프닝을 적용합니다. PreviewImage 노드는 ComfyUI FLUX에 의해 생성된 최종 출력의 미리보기를 표시합니다.
ComfyUI FLUX Latent Upscaler 워크플로우는 업스케일링 프로세스를 위한 차원, 비율 및 기타 매개변수를 계산하기 위해 SimpleMath+, SimpleMathFloat+, SimpleMathInt+, 및 SimpleMathPercent+ 노드를 사용한 다양한 수학적 작업을 포함합니다.