


ComfyUI의 힘을 활용하세요: 실습으로 배우는 초보자 가이드
Updated: 5/16/2024
안녕하세요, AI 아티스트 여러분! 👋 놀라운 AI 생성 아트워크를 만들기 위한 강력하고 유연한 도구인 ComfyUI에 대한 초보자 친화적인 튜토리얼에 오신 것을 환영합니다. 🎨 이 가이드에서는 ComfyUI의 기본 사항을 살펴보고, 기능을 탐색하며, AI 아트를 한 단계 높은 수준으로 끌어올리는 잠재력을 발휘할 수 있도록 도와드리겠습니다. 🚀
다음 내용을 다룰 예정입니다:
1. ComfyUI란 무엇인가요?
- 1.1. ComfyUI vs. AUTOMATIC1111
- 1.2. ComfyUI 시작 지점
- 1.3. 기본 컨트롤
2. ComfyUI 워크플로우: Text-to-Image
- 2.1. 모델 선택
- 2.2. Positive Prompt와 Negative Prompt 입력
- 2.3. 이미지 생성
- 2.4. ComfyUI 기술 설명
- 2.4.1 Load Checkpoint Node
- 2.4.2. CLIP Text Encode
- 2.4.3. Empty Latent Image
- 2.4.4. VAE
- 2.4.5. KSampler
3. ComfyUI 워크플로우: Image-to-Image
4. ComfyUI SDXL
5. ComfyUI Inpainting
6. ComfyUI Outpainting
7. ComfyUI Upscale
- 7.1. Upscale Pixel
- 7.1.1. 알고리즘으로 Upscale Pixel
- 7.1.2. 모델로 Upscale Pixel
- 7.2. Upscale Latent
- 7.3. Upscale Pixel vs. Upscale Latent
8. ComfyUI ControlNet
9. ComfyUI Manager
- 9.1. 누락된 Custom Node 설치 방법
- 9.2. Custom Node 업데이트 방법
- 9.3. 워크플로우에서 Custom Node 로드 방법
10. ComfyUI Embeddings
- 10.1. 자동 완성으로 Embedding
- 10.2. Embedding Weight
11. ComfyUI LoRA
- 11.1. 간단한 LoRA 워크플로우
- 11.2. 여러 LoRA
12. ComfyUI 단축키와 팁
- 12.1. 복사 및 붙여넣기
- 12.2. 여러 노드 이동
- 12.3. 노드 우회
- 12.4. 노드 최소화
- 12.5. 이미지 생성
- 12.6. 임베디드 워크플로우
- 12.7. 시간 절약을 위해 시드 고정
13. ComfyUI 온라인
1. ComfyUI란 무엇인가요? 🤔
ComfyUI는 마법의 지팡이 🪄처럼 손쉽게 멋진 AI 생성 아트워크를 만들어냅니다. ComfyUI의 핵심은 텍스트 설명에서 이미지를 생성하는 최첨단 딥러닝 모델인 Stable Diffusion 위에 구축된 노드 기반의 그래픽 사용자 인터페이스(GUI)입니다. 🌟 하지만 ComfyUI가 정말 특별한 이유는 아티스트인 여러분에게 창의성을 마음껏 발휘하고 가장 엉뚱한 아이디어를 현실로 만들 수 있는 힘을 준다는 점입니다.
디지털 캔버스에서 각각 특정 기능이나 작업을 나타내는 다양한 노드를 연결하여 자신만의 독특한 이미지 생성 워크플로우를 구축할 수 있다고 상상해 보세요. 🧩 마치 AI로 만든 걸작을 위한 시각적인 레시피를 만드는 것과 같죠!
텍스트 프롬프트를 사용하여 처음부터 이미지를 생성하고 싶으신가요? 이를 위한 노드가 있습니다! 특정 샘플러를 적용하거나 노이즈 레벨을 미세 조정해야 하나요? 해당 노드를 추가하기만 하면 마법이 펼쳐집니다. ✨
하지만 가장 좋은 점은 ComfyUI가 워크플로우를 재배열 가능한 요소로 분해하여 여러분의 예술적 비전에 맞춘 맞춤형 워크플로우를 만들 수 있는 자유를 준다는 것입니다. 🖼️ 마치 창작 과정에 맞춰 조정되는 개인화된 도구 모음을 갖는 것과 같죠.
1.1. ComfyUI vs. AUTOMATIC1111 🆚
AUTOMATIC1111은 Stable Diffusion의 기본 GUI입니다. 그렇다면 대신 ComfyUI를 사용해야 할까요? 비교해 보겠습니다:
✅ ComfyUI 사용의 이점:
- 가벼움: 빠르고 효율적으로 실행됩니다.
- 유연성: 필요에 따라 높은 구성 가능.
- 투명성: 데이터 흐름이 보이고 이해하기 쉽습니다.
- 공유 용이: 각 파일은 재현 가능한 워크플로우를 나타냅니다.
- 프로토타이핑에 적합: 코딩 대신 그래픽 인터페이스로 프로토타입을 만들 수 있습니다.
❌ ComfyUI 사용의 단점:
- 일관성 없는 인터페이스: 각 워크플로우는 서로 다른 노드 레이아웃을 가질 수 있습니다.
- 지나친 세부 사항: 일반 사용자는 기본 연결을 알 필요가 없을 수 있습니다.
1.2. ComfyUI 시작 지점 🏁
ComfyUI를 배우는 가장 좋은 방법은 예제를 살펴보고 직접 경험하는 것이라고 생각합니다. 🙌 그래서 우리는 다른 튜토리얼과 차별화되는 이 독특한 튜토리얼을 만들었습니다. 이 튜토리얼에서는 따라 할 수 있는 자세한 단계별 가이드를 찾을 수 있습니다.
하지만 가장 좋은 점은 🌟 이 웹페이지에 ComfyUI를 직접 통합했다는 것입니다! 가이드를 진행하면서 실시간으로 ComfyUI 예제와 상호 작용할 수 있습니다.🌟 그럼 시작해 볼까요!
2. ComfyUI 워크플로우: Text-to-Image 🖼️
가장 간단한 경우인 텍스트에서 이미지를 생성하는 것부터 시작해 보겠습니다. 워크플로우를 실행하려면 Queue Prompt를 클릭하세요. 잠시 기다리면 첫 번째 생성된 이미지를 볼 수 있습니다! 큐를 확인하려면 View Queue를 클릭하면 됩니다.
여기 시도해 볼 수 있는 기본 text-to-image 워크플로우가 있습니다:
기본 구성 요소 🕹️
ComfyUI 워크플로우는 두 가지 기본 구성 요소로 이루어집니다: 노드와 엣지.
- 노드는 직사각형 블록으로, Load Checkpoint, Clip Text Encoder 등이 있습니다. 각 노드는 특정 코드를 실행하며 입력, 출력 및 매개변수가 필요합니다.
- 엣지는 노드 간의 출력과 입력을 연결하는 선입니다.
기본 컨트롤 🕹️
- 마우스 휠이나 두 손가락 집기로 확대/축소합니다.
- 입력 또는 출력 점을 드래그하여 노드 간 연결을 만듭니다.
- 마우스 왼쪽 버튼을 누른 채로 드래그하여 작업 영역을 이동합니다.
이 워크플로우의 세부 사항을 살펴보겠습니다.
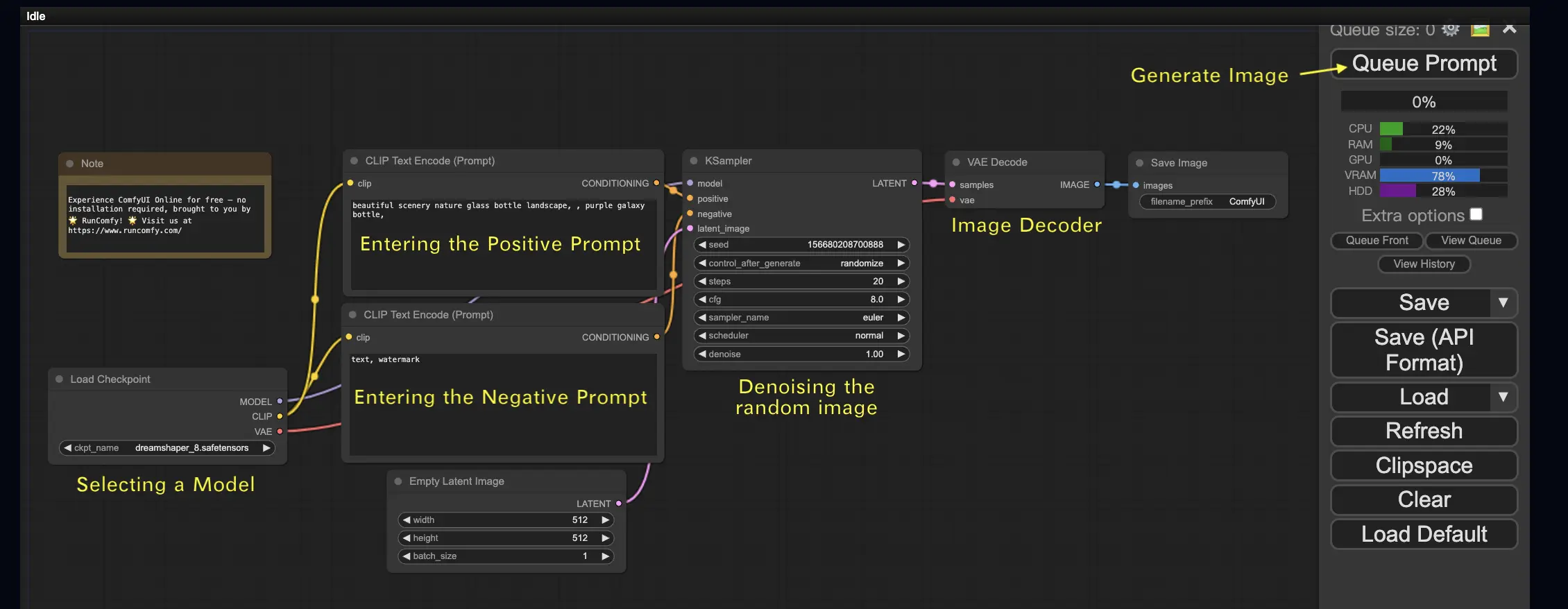
2.1. 모델 선택 🗃️
먼저 Load Checkpoint 노드에서 Stable Diffusion Checkpoint 모델을 선택합니다. 사용 가능한 모델을 보려면 모델 이름을 클릭하세요. 모델 이름을 클릭해도 아무 일도 일어나지 않는다면 사용자 정의 모델을 업로드해야 할 수 있습니다.
2.2. Positive Prompt와 Negative Prompt 입력 📝
**CLIP Text Encode (Prompt)**라는 레이블이 붙은 두 개의 노드가 보일 것입니다. 상단 프롬프트는 KSampler 노드의 positive 입력에 연결되고, 하단 프롬프트는 negative 입력에 연결됩니다. 따라서 상단에는 positive prompt를, 하단에는 negative prompt를 입력하세요.
CLIP Text Encode 노드는 프롬프트를 토큰으로 변환하고 텍스트 인코더를 사용하여 임베딩으로 인코딩합니다.
💡 팁: (keyword:weight) 구문을 사용하여 키워드의 가중치를 제어할 수 있습니다. 예를 들어 (keyword:1.2)로 효과를 높이거나 (keyword:0.8)로 낮출 수 있습니다.
2.3. 이미지 생성 🎨
Queue Prompt를 클릭하여 워크플로우를 실행합니다. 잠시 기다리면 첫 번째 이미지가 생성됩니다!
2.4. ComfyUI 기술 설명 🤓
ComfyUI의 힘은 구성 가능성에서 비롯됩니다. 각 노드의 역할을 이해하면 필요에 맞게 조정할 수 있습니다. 하지만 세부 사항을 살펴보기 전에 ComfyUI가 어떻게 작동하는지 더 잘 이해하기 위해 Stable Diffusion 프로세스를 살펴보겠습니다.
Stable Diffusion 프로세스는 크게 세 가지 주요 단계로 요약할 수 있습니다:
- 텍스트 인코딩: 사용자가 입력한 프롬프트는 텍스트 인코더라는 구성 요소에 의해 개별 단어 특징 벡터로 컴파일됩니다. 이 단계에서는 텍스트를 모델이 이해하고 사용할 수 있는 형식으로 변환합니다.
- 잠재 공간 변환: 텍스트 인코더의 특징 벡터와 랜덤 노이즈 이미지가 잠재 공간으로 변환됩니다. 이 공간에서 랜덤 이미지는 특징 벡터를 기반으로 디노이징 프로세스를 거쳐 중간 산물을 생성합니다. 이 단계에서 모델은 텍스트 특징을 시각적 표현과 연결하는 방법을 학습합니다.
- 이미지 디코딩: 마지막으로, 잠재 공간의 중간 산물은 이미지 디코더에 의해 디코딩되어 우리가 볼 수 있고 감상할 수 있는 실제 이미지로 변환됩니다.
Stable Diffusion 프로세스에 대한 개략적인 이해를 바탕으로 이제 ComfyUI에서 이 프로세스를 가능하게 하는 핵심 구성 요소와 노드를 살펴보겠습니다.
2.4.1 Load Checkpoint Node 🗃️
ComfyUI의 Load Checkpoint 노드는 Stable Diffusion 모델을 선택하는 데 중요한 역할을 합니다. Stable Diffusion 모델은 MODEL, CLIP, VAE라는 세 가지 주요 구성 요소로 이루어집니다. 각 구성 요소와 ComfyUI의 해당 노드와의 관계를 살펴보겠습니다.
- MODEL: MODEL 구성 요소는 잠재 공간에서 작동하는 노이즈 예측 모델입니다. 잠재 표현에서 이미지를 생성하는 핵심 프로세스를 담당합니다. ComfyUI에서 Load Checkpoint 노드의 MODEL 출력은 KSampler 노드에 연결되며, 여기서 역방향 확산 프로세스가 이루어집니다. KSampler 노드는 MODEL을 사용하여 잠재 표현을 반복적으로 디노이징하고 원하는 프롬프트와 일치할 때까지 이미지를 점진적으로 개선합니다.
- CLIP: CLIP(Contrastive Language-Image Pre-training)은 사용자가 제공한 positive 및 negative 프롬프트를 전처리하는 언어 모델입니다. 텍스트 프롬프트를 MODEL이 이해하고 이미지 생성 프로세스를 안내하는 데 사용할 수 있는 형식으로 변환합니다. ComfyUI에서 Load Checkpoint 노드의 CLIP 출력은 CLIP Text Encode 노드에 연결됩니다. CLIP Text Encode 노드는 사용자가 제공한 프롬프트를 가져와 CLIP 언어 모델에 입력하여 각 단어를 임베딩으로 변환합니다. 이러한 임베딩은 단어의 의미론적 의미를 포착하고 MODEL이 주어진 프롬프트와 일치하는 이미지를 생성할 수 있게 합니다.
- VAE: VAE(Variational AutoEncoder)는 이미지를 픽셀 공간과 잠재 공간 사이에서 변환하는 역할을 합니다. 이미지를 저차원 잠재 표현으로 압축하는 인코더와 잠재 표현에서 이미지를 재구성하는 디코더로 구성됩니다. text-to-image 프로세스에서 VAE는 잠재 공간에서 생성된 이미지를 픽셀 공간으로 다시 변환하는 최종 단계에서만 사용됩니다. ComfyUI의 VAE Decode 노드는 KSampler 노드(잠재 공간에서 작동)의 출력을 받아 VAE의 디코더 부분을 사용하여 잠재 표현을 픽셀 공간의 최종 이미지로 변환합니다.
VAE는 CLIP 언어 모델과 별개의 구성 요소라는 점에 유의하는 것이 중요합니다. CLIP은 텍스트 프롬프트 처리에 중점을 두는 반면, VAE는 픽셀 공간과 잠재 공간 간의 변환을 다룹니다.
2.4.2. CLIP Text Encode 📝
ComfyUI의 CLIP Text Encode 노드는 사용자가 제공한 프롬프트를 CLIP 언어 모델에 입력하는 역할을 합니다. CLIP은 단어의 의미론적 의미를 이해하고 이를 시각적 개념과 연결할 수 있는 강력한 언어 모델입니다. 프롬프트가 CLIP Text Encode 노드에 입력되면 각 단어가 임베딩으로 변환되는 변환 프로세스를 거칩니다. 이러한 임베딩은 단어의 의미론적 정보를 포착하는 고차원 벡터입니다. 프롬프트를 임베딩으로 변환함으로써 CLIP은 MODEL이 주어진 프롬프트의 의미와 의도를 정확하게 반영하는 이미지를 생성할 수 있도록 합니다.
2.4.3. Empty Latent Image 🌌
text-to-image 프로세스에서 생성은 잠재 공간의 랜덤 이미지로 시작합니다. 이 랜덤 이미지는 MODEL이 작업할 초기 상태 역할을 합니다. 잠재 이미지의 크기는 픽셀 공간의 실제 이미지 크기에 비례합니다. ComfyUI에서는 잠재 이미지의 높이와 너비를 조정하여 생성되는 이미지의 크기를 제어할 수 있습니다. 또한 배치 크기를 설정하여 각 실행에서 생성되는 이미지 수를 결정할 수 있습니다.
잠재 이미지의 최적 크기는 사용 중인 특정 Stable Diffusion 모델에 따라 다릅니다. SD v1.5 모델의 경우 권장 크기는 512x512 또는 768x768이며, SDXL 모델의 경우 최적 크기는 1024x1024입니다. ComfyUI는 1:1(정사각형), 3:2(가로), 2:3(세로), 4:3(가로), 3:4(세로), 16:9(와이드스크린), 9:16(수직) 등 다양한 일반적인 가로 세로 비율을 제공합니다. 잠재 이미지의 너비와 높이는 모델의 아키텍처와 호환되도록 8로 나누어 떨어져야 한다는 점에 유의하는 것이 중요합니다.
2.4.4. VAE 🔍
VAE(Variational AutoEncoder)는 픽셀 공간과 잠재 공간 사이에서 이미지 변환을 처리하는 Stable Diffusion 모델의 중요한 구성 요소입니다. 이미지 인코더와 이미지 디코더라는 두 가지 주요 부분으로 구성됩니다.
이미지 인코더는 픽셀 공간의 이미지를 가져와 저차원 잠재 표현으로 압축합니다. 이 압축 프로세스는 데이터 크기를 크게 줄여 더 효율적인 처리와 저장을 가능하게 합니다. 예를 들어, 512x512 픽셀 크기의 이미지는 64x64 크기의 잠재 표현으로 압축될 수 있습니다.
반면에 VAE 디코더라고도 하는 이미지 디코더는 잠재 표현에서 이미지를 픽셀 공간으로 재구성하는 역할을 담당합니다. 압축된 잠재 표현을 가져와 최종 이미지를 생성하기 위해 확장합니다.
VAE를 사용하면 몇 가지 이점이 있습니다:
- 효율성: 이미지를 저차원 잠재 공간으로 압축함으로써 VAE는 더 빠른 생성과 더 짧은 학습 시간을 가능하게 합니다. 줄어든 데이터 크기로 인해 더 효율적인 처리와 메모리 사용이 가능합니다.
- 잠재 공간 조작: 잠재 공간은 이미지의 더 컴팩트하고 의미 있는 표현을 제공합니다. 이를 통해 이미지 세부 사항과 스타일을 더 정확하게 제어하고 편집할 수 있습니다. 잠재 표현을 조작함으로써 생성된 이미지의 특정 측면을 수정할 수 있습니다.
하지만 몇 가지 단점도 고려해야 합니다:
- 데이터 손실: 인코딩 및 디코딩 과정에서 원본 이미지의 일부 세부 사항이 손실될 수 있습니다. 압축 및 재구성 단계에서 원본과 비교하여 최종 이미지에 아티팩트나 약간의 변형이 발생할 수 있습니다.
- 원본 데이터 캡처 제한: 저차원 잠재 공간은 원본 이미지의 모든 복잡한 특징과 세부 사항을 완전히 캡처하지 못할 수 있습니다. 압축 과정에서 일부 정보가 손실되어 원본 데이터의 약간 덜 정확한 표현이 될 수 있습니다.
이러한 제한 사항에도 불구하고 VAE는 픽셀 공간과 잠재 공간 사이의 효율적인 변환을 가능하게 하여 더 빠른 생성과 생성된 이미지에 대한 더 정확한 제어를 촉진함으로써 Stable Diffusion 모델에서 중요한 역할을 합니다.
2.4.5. KSampler ⚙️
ComfyUI의 KSampler 노드는 Stable Diffusion의 이미지 생성 프로세스의 핵심입니다. 사용자가 제공한 프롬프트와 일치하도록 잠재 공간의 랜덤 이미지를 디노이징하는 역할을 합니다. KSampler는 역방향 확산이라는 기술을 사용하여 CLIP 임베딩의 안내에 따라 노이즈를 제거하고 의미 있는 세부 사항을 추가하여 잠재 표현을 반복적으로 개선합니다.
KSampler 노드는 사용자가 이미지 생성 프로세스를 미세 조정할 수 있는 몇 가지 매개변수를 제공합니다:
Seed: 시드 값은 최종 이미지의 초기 노이즈와 구성을 제어합니다. 특정 시드를 설정하면 재현 가능한 결과를 얻고 여러 생성에 걸쳐 일관성을 유지할 수 있습니다.
Control_after_generation: 이 매개변수는 각 생성 후 시드 값이 어떻게 변경되는지 결정합니다. randomize(각 실행에 대해 새로운 무작위 시드 생성), increment(시드 값을 1 증가), decrement(시드 값을 1 감소) 또는 fixed(시드 값을 일정하게 유지)로 설정할 수 있습니다.
Step: 샘플링 단계 수는 개선 프로세스의 강도를 결정합니다. 값이 높을수록 아티팩트가 줄어들고 더 세밀한 이미지가 생성되지만 생성 시간도 늘어납니다.
Sampler_name: 이 매개변수를 사용하면 KSampler에서 사용하는 특정 샘플링 알고리즘을 선택할 수 있습니다. 서로 다른 샘플링 알고리즘은 약간 다른 결과를 산출하고 다양한 생성 속도를 가질 수 있습니다.
Scheduler: 스케줄러는 디노이징 프로세스의 각 단계에서 노이즈 레벨이 어떻게 변하는지 제어합니다. 잠재 표현에서 노이즈가 제거되는 속도를 결정합니다.
Denoise: 디노이즈 매개변수는 디노이징 프로세스에 의해 지워져야 하는 초기 노이즈의 양을 설정합니다. 1의 값은 모든 노이즈가 제거되어 깨끗하고 세밀한 이미지가 생성됨을 의미합니다.
이러한 매개변수를 조정하여 원하는 결과를 얻기 위해 이미지 생성 프로세스를 미세 조정할 수 있습니다.
이제 ComfyUI 여정을 시작할 준비가 되셨나요?
RunComfy에서는 여러분만을 위한 궁극의 ComfyUI 온라인 경험을 만들었습니다. 복잡한 설치는 이제 안녕!
🎉 지금 ComfyUI 온라인 사용해보기 그리고 전에 없이 예술적 잠재력을 발휘하세요! 🎉
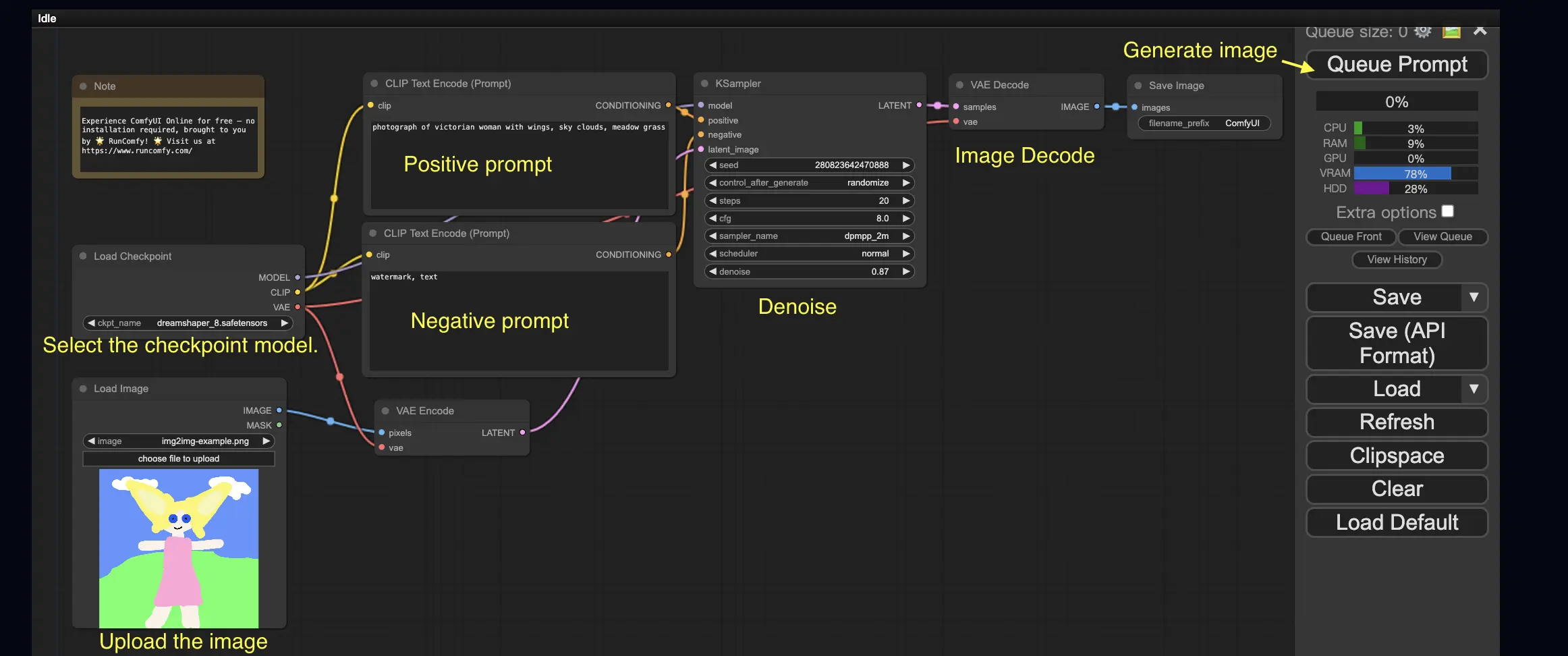
3. ComfyUI 워크플로우: Image-to-Image 🖼️
Image-to-Image 워크플로우는 프롬프트와 입력 이미지를 기반으로 이미지를 생성합니다. 직접 시도해 보세요!
Image-to-Image 워크플로우를 사용하려면:
- 체크포인트 모델을 선택합니다.
- 이미지를 이미지 프롬프트로 업로드합니다.
- positive 프롬프트와 negative 프롬프트를 수정합니다.
- 필요에 따라 KSampler 노드에서 denoise(디노이징 강도)를 조정합니다.
- Queue Prompt를 눌러 생성을 시작합니다.
더 많은 프리미엄 ComfyUI 워크플로우는 🌟ComfyUI 워크플로우 목록🌟을 참조하세요.
4. ComfyUI SDXL 🚀
극도로 구성 가능하다는 점 덕분에 ComfyUI는 Stable Diffusion XL 모델을 지원하는 첫 번째 GUI 중 하나입니다. 한번 시도해 보겠습니다!
ComfyUI SDXL 워크플로우를 사용하려면:
- positive 프롬프트와 negative 프롬프트를 수정합니다.
- Queue Prompt를 눌러 생성을 시작합니다.
5. ComfyUI Inpainting 🎨
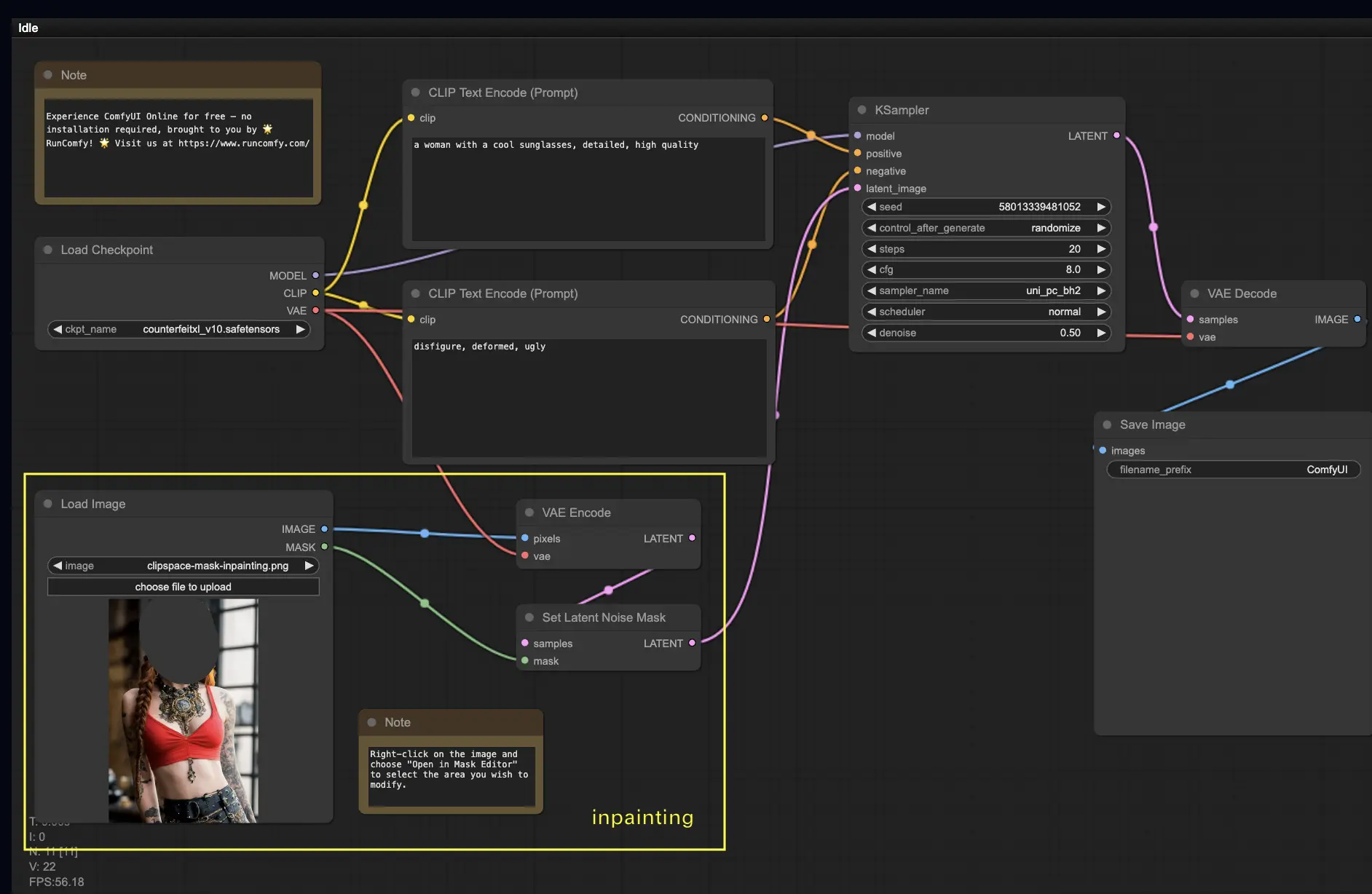
더 복잡한 것을 살펴보겠습니다: 인페인팅! 훌륭한 이미지가 있지만 특정 부분을 수정하려면 인페인팅이 가장 좋은 방법입니다. 여기에서 시도해 보세요!
인페인팅 워크플로우를 사용하려면:
- 인페인팅하려는 이미지를 업로드합니다.
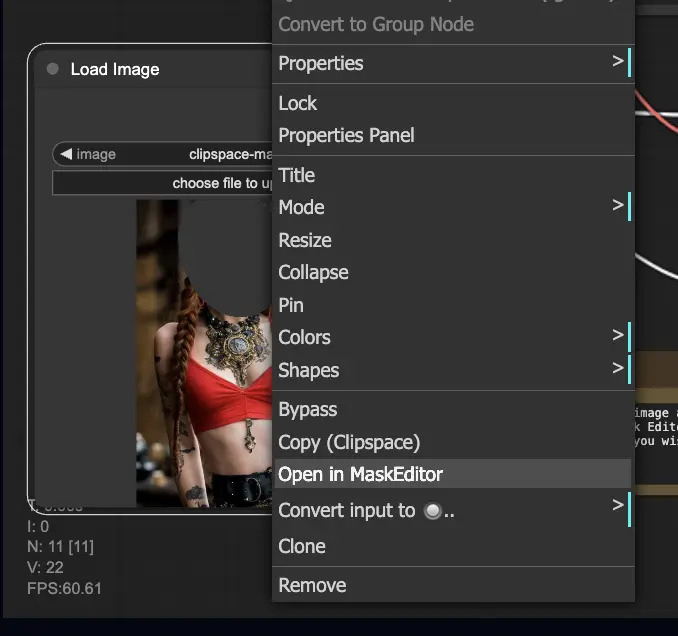
- 이미지를 마우스 오른쪽 버튼으로 클릭하고 "MaskEditor에서 열기"를 선택합니다. 재생성할 영역을 마스킹한 다음 "노드에 저장"을 클릭합니다.
- 체크포인트 모델을 선택합니다:
- 이 워크플로우는 인페인팅 모델이 아닌 표준 Stable Diffusion 모델에서만 작동합니다.
- 인페인팅 모델을 활용하려면 "VAE Encode" 및 "Set Noise Latent Mask" 노드를 인페인팅 모델 전용 "VAE Encode (Inpaint)" 노드로 전환하세요.
- 인페인팅 프로세스를 사용자 지정합니다:
- CLIP Text Encode (Prompt) 노드에서 인페인팅을 안내하기 위한 추가 정보를 입력할 수 있습니다. 예를 들어, 인페인팅 영역에 포함하려는 스타일, 테마 또는 요소를 지정할 수 있습니다.
- 원래의 디노이징 강도(denoise)를 설정합니다(예: 0.6).
- Queue Prompt를 눌러 인페인팅을 수행합니다.
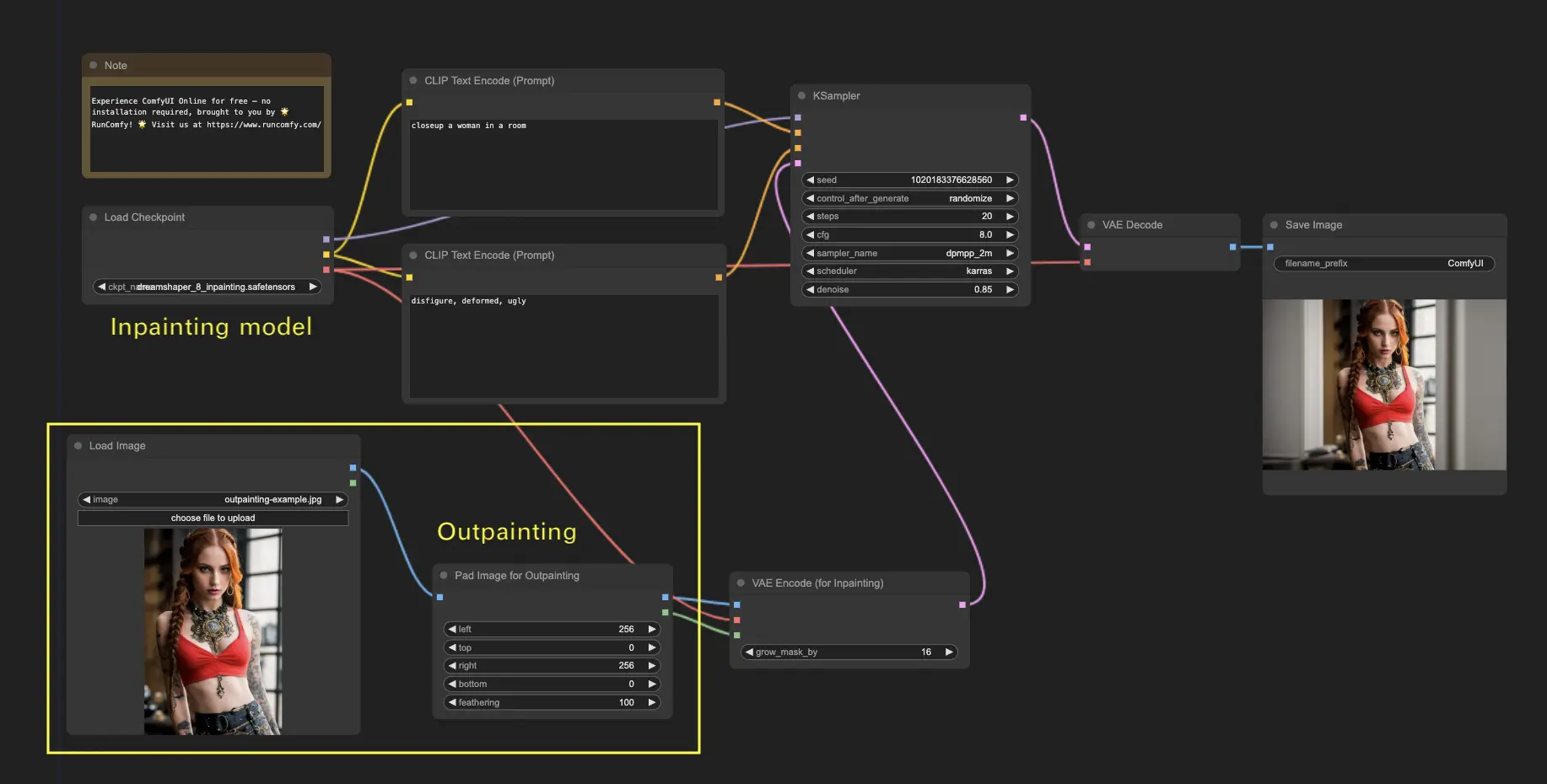
6. ComfyUI Outpainting 🖌️
아웃페인팅은 이미지를 원래 경계를 넘어 확장할 수 있게 해주는 또 다른 흥미로운 기술입니다. 🌆 무한한 캔버스로 작업하는 것과 같습니다!
ComfyUI 아웃페인팅 워크플로우를 사용하려면:
- 확장하려는 이미지로 시작합니다.
- Pad Image for Outpainting 노드를 워크플로우에 사용합니다.
- 아웃페인팅 설정을 구성합니다:
- left, top, right, bottom: 각 방향으로 확장할 픽셀 수를 지정합니다.
- feathering: 원본 이미지와 아웃페인팅된 영역 사이의 전환 부드러움을 조정합니다. 값이 높을수록 더 점진적인 혼합이 생성되지만 번짐 효과가 발생할 수 있습니다.
- 아웃페인팅 프로세스를 사용자 지정합니다:
- CLIP Text Encode (Prompt) 노드에서 아웃페인팅을 안내하기 위한 추가 정보를 입력할 수 있습니다. 예를 들어, 확장된 영역에 포함하려는 스타일, 테마 또는 요소를 지정할 수 있습니다.
- 원하는 결과를 얻기 위해 다양한 프롬프트를 실험해 보세요.
- VAE Encode (for Inpainting) 노드를 미세 조정합니다:
- grow_mask_by 매개변수를 조정하여 아웃페인팅 마스크의 크기를 제어합니다. 최적의 결과를 얻으려면 10보다 큰 값이 권장됩니다.
- Queue Prompt를 눌러 아웃페인팅 프로세스를 시작합니다.
더 많은 프리미엄 인페인팅/아웃페인팅 워크플로우는 🌟ComfyUI 워크플로우 목록🌟을 참조하세요.
7. ComfyUI Upscale ⬆️
다음으로 ComfyUI 업스케일에 대해 알아보겠습니다. 효율적으로 업스케일하는 데 도움이 되는 세 가지 기본 워크플로우를 소개하겠습니다.
업스케일에는 두 가지 주요 방법이 있습니다:
- Upscale pixel: 보이는 이미지를 직접 업스케일합니다.
- 입력: 이미지, 출력: 업스케일된 이미지2. Upscale latent: 보이지 않는 잠재 공간 이미지를 업스케일합니다.
- 입력: latent, 출력: 업스케일된 latent(보이는 이미지가 되려면 디코딩이 필요함)
7.1. Upscale Pixel 🖼️
이를 달성하는 두 가지 방법:
- 알고리즘 사용: 가장 빠른 생성 속도이지만 모델에 비해 결과가 다소 열등합니다.
- 모델 사용: 더 나은 결과이지만 생성 시간이 느립니다.
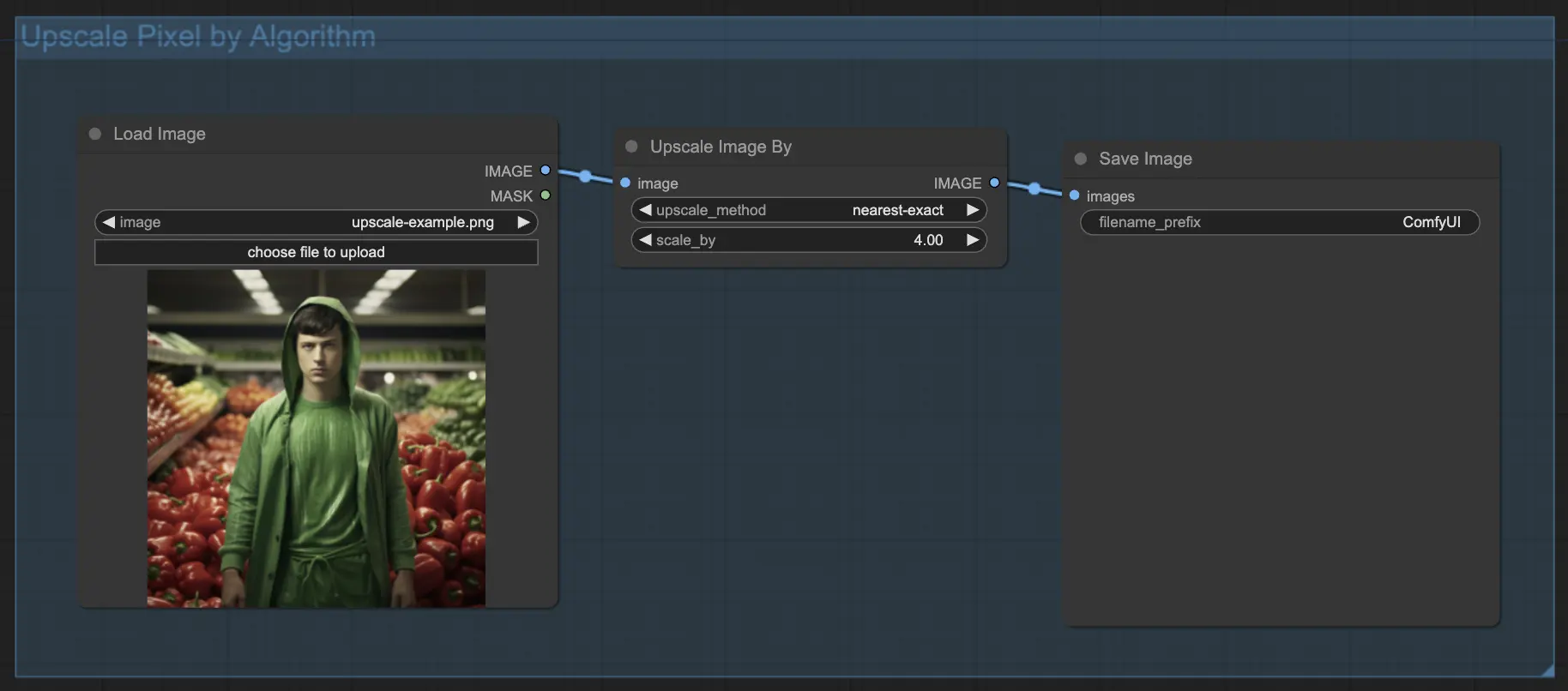
7.1.1. 알고리즘으로 Upscale Pixel 🧮
- Upscale Image by 노드 추가.
- method 매개변수: 업스케일 알고리즘 선택(bicubic, bilinear, nearest-exact).
- Scale 매개변수: 업스케일 계수 지정(예: 2배는 2).
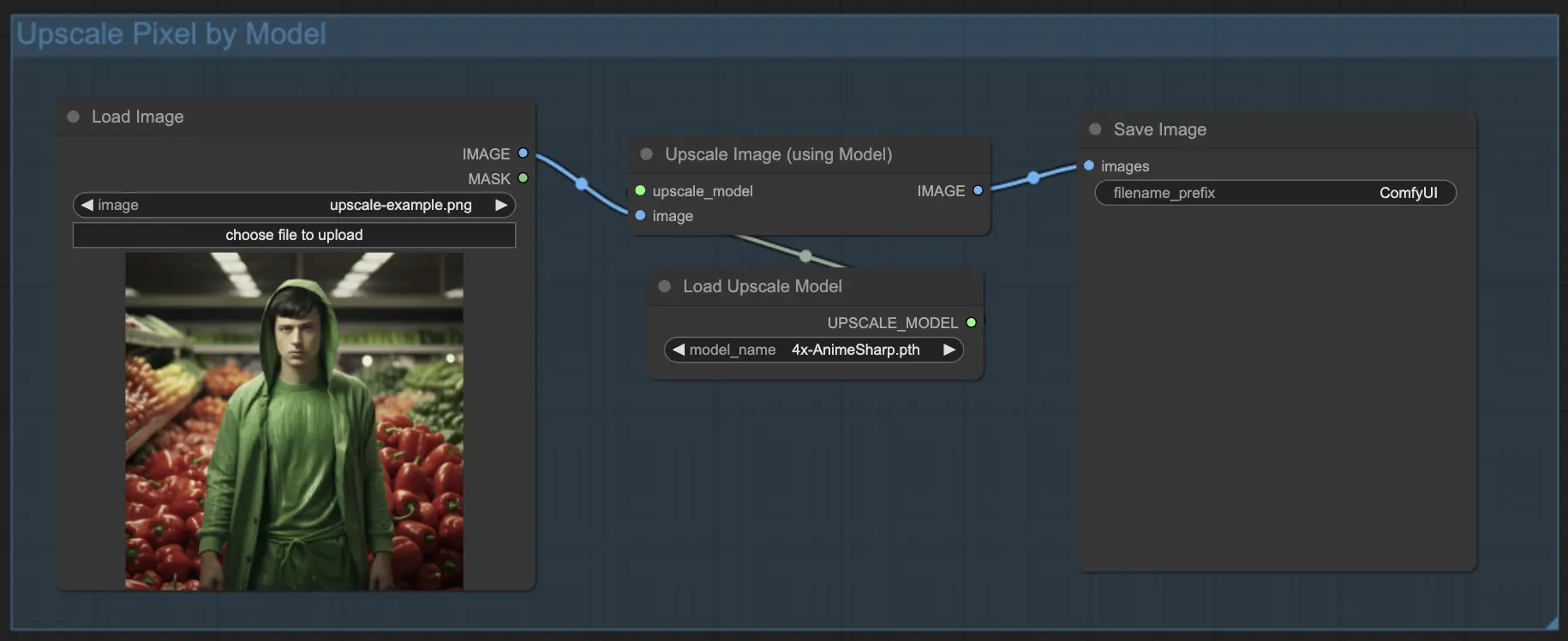
7.1.2. 모델로 Upscale Pixel 🤖
- Upscale Image (using Model) 노드 추가.
- Load Upscale Model 노드 추가.
- 이미지 유형에 적합한 모델 선택(예: 애니메이션 또는 실사).
- 업스케일 계수 선택(X2 또는 X4).
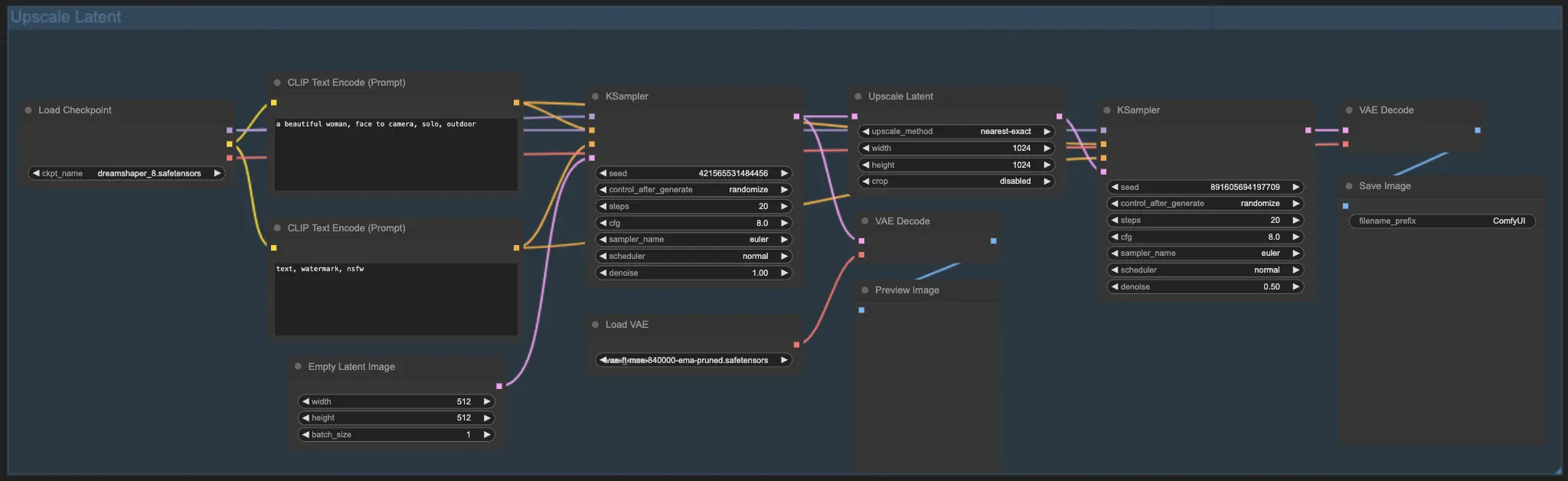
7.2. Upscale Latent ⚙️
또 다른 업스케일 방법은 Hi-res Latent Fix Upscale이라고도 하는 Upscale Latent로, 잠재 공간에서 직접 업스케일합니다.
7.3. Upscale Pixel vs. Upscale Latent 🆚
- Upscale Pixel: 새로운 정보를 추가하지 않고 이미지만 확대합니다. 더 빠른 생성이지만 번짐 효과가 있을 수 있고 세부 사항이 부족할 수 있습니다.
- Upscale Latent: 확대 외에도 원본 이미지 정보의 일부를 변경하여 세부 사항을 풍부하게 합니다. 원본 이미지에서 벗어날 수 있고 생성 속도가 느립니다.
더 많은 프리미엄 복원/업스케일 워크플로우는 🌟ComfyUI 워크플로우 목록🌟을 참조하세요.
8. ComfyUI ControlNet 🎮
ControlNet과 함께 AI 아트를 한 단계 높은 수준으로 끌어올릴 준비를 하세요. ControlNet은 이미지 생성을 혁신하는 획기적인 기술입니다!
ControlNet은 전례 없는 AI 생성 이미지 제어 권한을 부여하는 마법의 지팡이 🪄와 같습니다. Stable Diffusion과 같은 강력한 모델과 손잡고 작동하며, 그 기능을 향상시키고 이전에는 볼 수 없었던 방식으로 이미지 생성 프로세스를 안내할 수 있게 해줍니다!
원하는 이미지의 가장자리, 사람 포즈, 깊이 또는 심지어 분할 맵을 지정할 수 있다고 상상해 보세요. 🌠 ControlNet을 사용하면 그렇게 할 수 있습니다!
ControlNet의 세계에 더 깊이 뛰어들고 그 잠재력을 최대한 발휘하고 싶다면 저희가 도와드리겠습니다. ComfyUI에서 ControlNet 마스터하기에 대한 자세한 튜토리얼을 확인해 보세요! 📚 단계별 가이드와 영감을 주는 예제로 가득 차 있어 ControlNet 전문가가 될 수 있습니다. 🏆
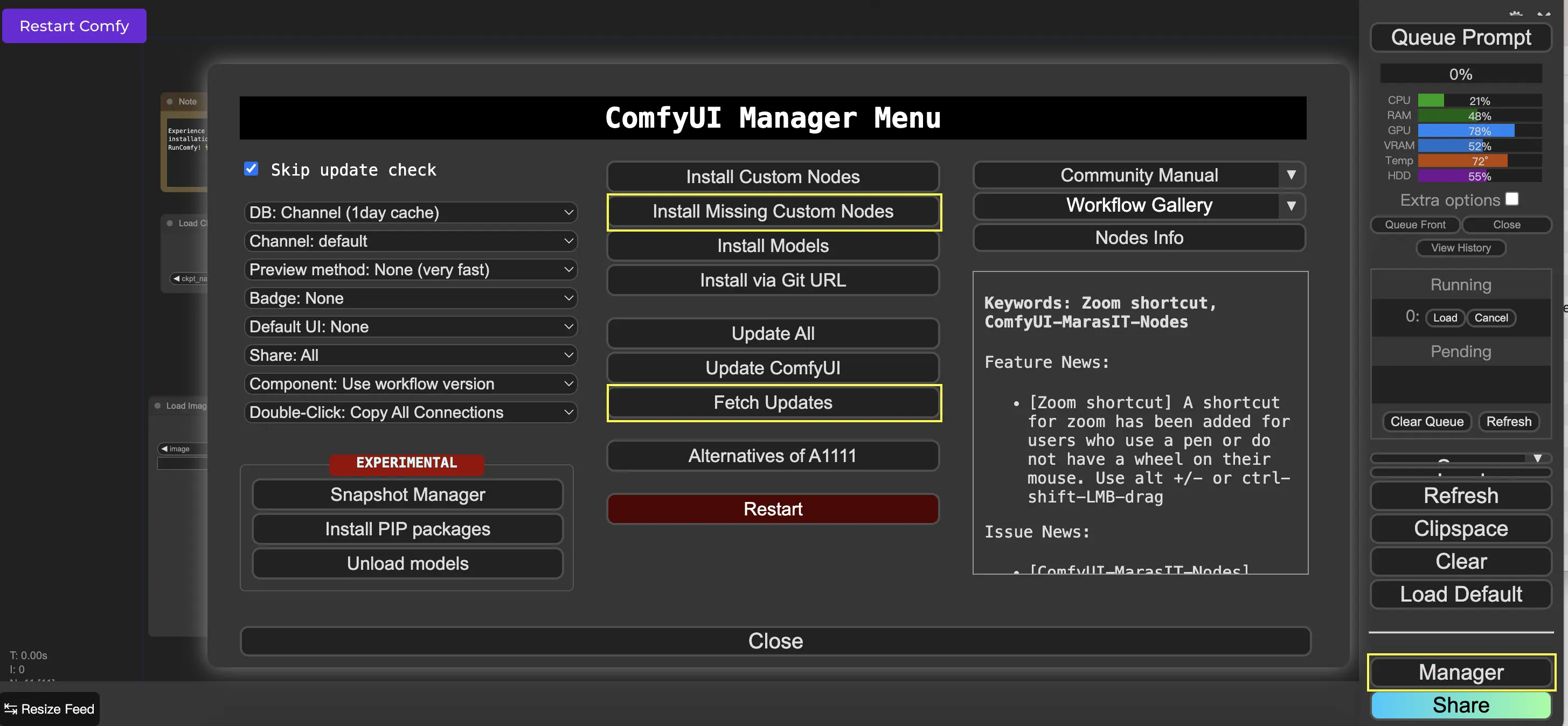
9. ComfyUI Manager 🛠️
ComfyUI Manager는 ComfyUI 인터페이스를 통해 다른 사용자 지정 노드를 설치하고 업데이트할 수 있는 사용자 지정 노드입니다. Queue Prompt 메뉴에서 Manager 버튼을 찾을 수 있습니다.
9.1. 누락된 Custom Node 설치 방법 📥
워크플로우에 설치하지 않은 사용자 지정 노드가 필요한 경우 다음 단계를 따르세요:
- 메뉴에서 Manager를 클릭합니다.
- Install Missing Custom Nodes를 클릭합니다.
- ComfyUI를 완전히 다시 시작합니다.
- 브라우저를 새로 고칩니다.
9.2. Custom Node 업데이트 방법 🔄
- 메뉴에서 Manager를 클릭합니다.
- Fetch Updates를 클릭합니다(시간이 걸릴 수 있음).
- Install Custom Nodes를 클릭합니다.
- 업데이트가 있는 경우 설치된 사용자 지정 노드 옆에 Update 버튼이 나타납니다.
- Update를 클릭하여 노드를 업데이트합니다.
- ComfyUI를 다시 시작합니다.
- 브라우저를 새로 고칩니다.
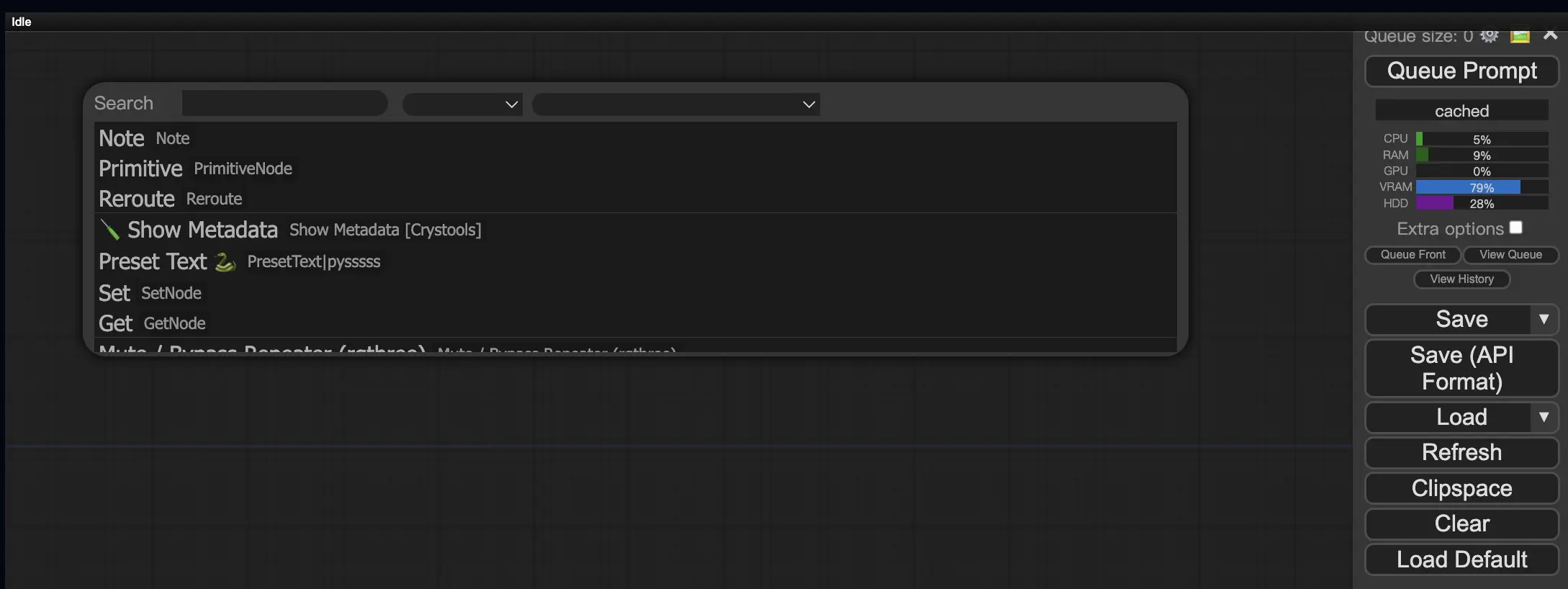
9.3. 워크플로우에서 Custom Node 로드 방법 🔍
빈 영역을 더블 클릭하여 노드를 검색할 수 있는 메뉴를 표시합니다.
10. ComfyUI Embeddings 📝
임베딩(텍스트 인버전이라고도 함)은 사용자 정의 개념이나 스타일을 AI 생성 이미지에 주입할 수 있는 ComfyUI의 강력한 기능입니다. 💡 AI에 새로운 단어나 구문을 가르치고 이를 특정 시각적 특성과 연결하는 것과 같습니다.
ComfyUI에서 임베딩을 사용하려면 positive 또는 negative 프롬프트 상자에 "embedding:" 다음에 임베딩 이름을 입력하기만 하면 됩니다. 예를 들면:
embedding: BadDream
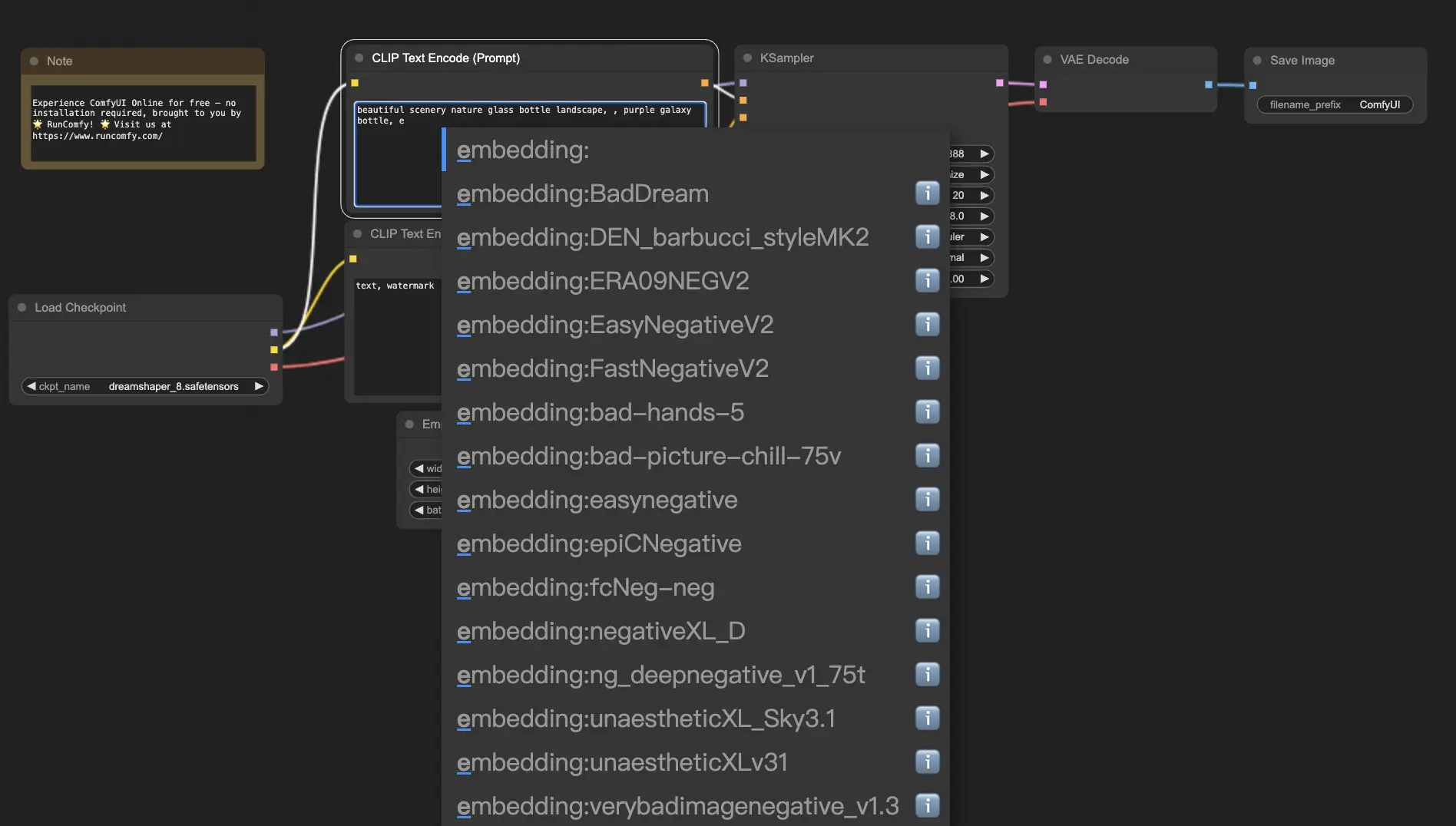
이 프롬프트를 사용하면 ComfyUI는 ComfyUI > models > embeddings 폴더에서 "BadDream"이라는 임베딩 파일을 검색합니다. 📂 일치하는 항목이 있으면 해당 시각적 특성을 생성된 이미지에 적용합니다.
임베딩은 AI 아트를 개인화하고 특정 스타일이나 미학을 달성하는 좋은 방법입니다. 🎨 원하는 개념이나 스타일을 나타내는 일련의 이미지에서 학습하여 자신만의 임베딩을 만들 수 있습니다.
10.1. 자동 완성으로 Embedding 🔠
임베딩의 정확한 이름을 기억하는 것은 특히 대규모 컬렉션이 있는 경우 번거로울 수 있습니다. 😅 이때 ComfyUI-Custom-Scripts 사용자 지정 노드가 문제를 해결해 줍니다!
임베딩 이름 자동 완성을 활성화하려면:
- 상단 메뉴에서 "Manager"를 클릭하여 ComfyUI Manager를 엽니다.
- "Install Custom nodes"로 이동하여 "ComfyUI-Custom-Scripts"를 검색합니다.
- "Install"을 클릭하여 사용자 지정 노드를 ComfyUI 설정에 추가합니다.
- ComfyUI를 다시 시작하여 변경 사항을 적용합니다.
ComfyUI-Custom-Scripts 노드가 설치되면 임베딩을 더 사용자 친화적인 방식으로 사용할 수 있습니다. 😊 프롬프트 상자에 "embedding:"을 입력하기 시작하면 사용 가능한 임베딩 목록이 나타납니다. 그러면 목록에서 원하는 임베딩을 선택하여 시간과 노력을 절약할 수 있습니다!
10.2. Embedding Weight ⚖️
임베딩의 강도를 제어할 수 있다는 사실을 알고 계셨나요? 💪 임베딩은 본질적으로 키워드이므로 프롬프트의 일반 키워드와 마찬가지로 가중치를 적용할 수 있습니다.
임베딩의 가중치를 조정하려면 다음 구문을 사용하세요:
(embedding: BadDream:1.2)
이 예에서 "BadDream" 임베딩의 가중치는 20% 증가합니다. 따라서 더 높은 가중치(예: 1.2)는 임베딩을 더 두드러지게 만들고 더 낮은 가중치(예: 0.8)는 영향을 줄입니다. 🎚️ 이를 통해 최종 결과를 더욱 세밀하게 제어할 수 있습니다!
11. ComfyUI LoRA 🧩
LoRA(Low-rank Adaptation의 약자)는 체크포인트 모델을 수정하고 미세 조정할 수 있는 ComfyUI의 또 다른 흥미로운 기능입니다. 🎨 기본 모델 위에 작고 특수화된 모델을 추가하여 특정 스타일을 달성하거나 사용자 지정 요소를 통합하는 것과 같습니다.
LoRA 모델은 컴팩트하고 효율적이어서 사용과 공유가 쉽습니다. 이미지의 예술적 스타일을 수정하거나 특정 사람이나 개체를 생성된 결과에 주입하는 것과 같은 작업에 일반적으로 사용됩니다.
LoRA 모델을 체크포인트 모델에 적용하면 VAE(Variational Autoencoder)는 그대로 두고 MODEL과 CLIP 구성요소를 수정합니다. 즉, LoRA는 이미지의 전체 구조를 변경하지 않고 내용과 스타일을 조정하는 데 중점을 둡니다.
11.1. LoRA 사용 방법 🔧
ComfyUI에서 LoRA를 사용하는 것은 간단합니다. 가장 간단한 방법을 살펴보겠습니다:
- 이미지 생성의 기반이 되는 체크포인트 모델을 선택합니다.
- 스타일을 수정하거나 특정 요소를 주입하는 데 적용하려는 LoRA 모델을 선택합니다.
- 이미지 생성 프로세스를 안내하기 위해 positive 및 negative 프롬프트를 수정합니다.
- "Queue Prompt"를 클릭하여 적용된 LoRA로 이미지 생성을시작합니다. ▶
ComfyUI는 체크포인트 모델과 LoRA 모델을 결합하여 지정된 프롬프트를 반영하고 LoRA에 의해 도입된 수정 사항을 통합하는 이미지를 만듭니다.
11.2. 여러 LoRA 🧩🧩
하지만 하나의 이미지에 여러 LoRA를 적용하고 싶다면 어떻게 해야 할까요? 문제 없습니다! ComfyUI를 사용하면 동일한 text-to-image 워크플로우에서 두 개 이상의 LoRA를 사용할 수 있습니다.
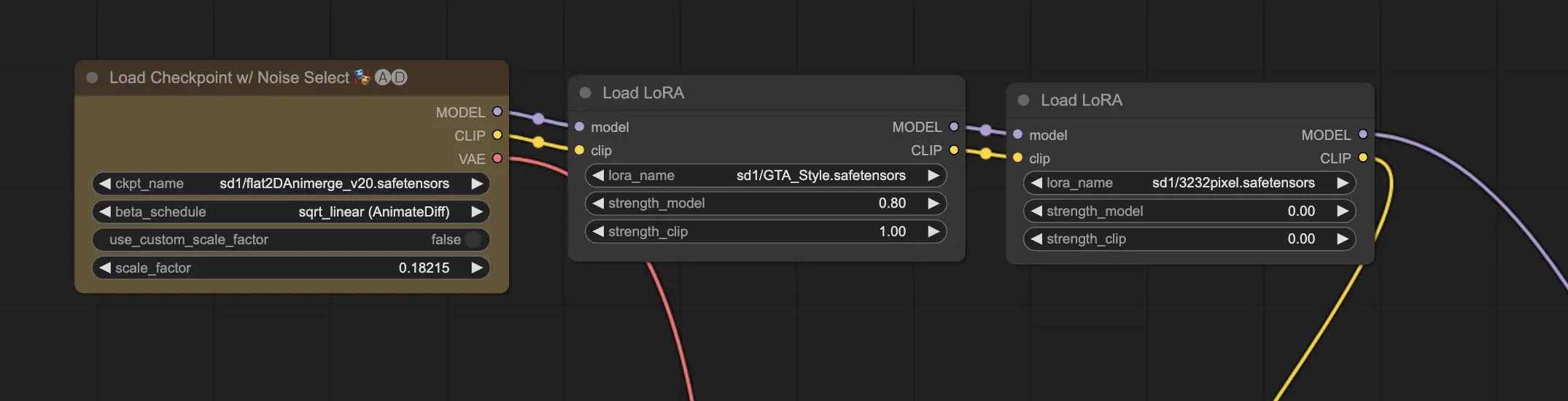
프로세스는 단일 LoRA를 사용하는 것과 유사하지만 하나가 아닌 여러 LoRA 모델을 선택해야 합니다. ComfyUI는 LoRA를 순차적으로 적용하므로 각 LoRA는 이전 LoRA에 의해 도입된 수정 사항을 기반으로 합니다.
이는 AI 생성 이미지에서 다양한 스타일, 요소 및 수정 사항을 조합할 수 있는 무한한 가능성을 열어줍니다. 🌍💡 독특하고 창의적인 결과를 얻기 위해 다양한 LoRA 조합을 실험해 보세요!
12. ComfyUI 단축키와 팁 ⌨️🖱️
12.1. 복사 및 붙여넣기 📋
- 노드를 선택하고 Ctrl+C를 눌러 복사합니다.
- Ctrl+V를 눌러 붙여넣습니다.
- Ctrl+Shift+V를 눌러 입력 연결을 그대로 유지하면서 붙여넣습니다.
12.2. 여러 노드 이동 🖱️
- 노드 세트를 함께 이동하려면 그룹을 만듭니다.
- 또는 Ctrl 키를 누른 상태에서 드래그하여 여러 노드를 선택하는 상자를 만들거나 Ctrl 키를 누른 상태에서 개별적으로 여러 노드를 선택합니다.
- 선택한 노드를 이동하려면 Shift 키를 누른 상태에서 마우스를 움직입니다.
12.3. 노드 우회 🔇
- 노드를 음소거하여 일시적으로 비활성화합니다. 노드를 선택하고 Ctrl+M을 누릅니다.
- 그룹을 음소거하는 키보드 단축키는 없습니다. 마우스 오른쪽 버튼 메뉴에서 Bypass Group Node를 선택하거나 그룹의 첫 번째 노드를 음소거하여 비활성화합니다.
12.4. 노드 최소화 🔍
- 노드 왼쪽 상단 모서리에 있는 점을 클릭하여 최소화합니다.
12.5. 이미지 생성 ▶️
- Ctrl+Enter를 눌러 워크플로우를 대기열에 넣고 이미지를 생성합니다.
12.6. 임베디드 워크플로우 🖼️
- ComfyUI는 생성하는 PNG 파일의 메타데이터에 전체 워크플로우를 저장합니다. 워크플로우를 로드하려면 이미지를 ComfyUI로 드래그 앤 드롭하세요.
12.7. 시간 절약을 위해 시드 고정 ⏰
- ComfyUI는 입력이 변경된 경우에만 노드를 다시 실행합니다. 긴 노드 체인에서 작업할 때 시드를 고정하여 업스트림 결과를 다시 생성하는 것을 방지함으로써 시간을 절약하세요.
13. ComfyUI 온라인 🚀
ComfyUI 초보자 가이드를 완료하신 것을 축하드립니다! 🙌 이제 AI 아트 제작의 흥미진진한 세계로 뛰어들 준비가 되셨습니다. 하지만 설치로 골치 아플 때 왜 바로 제작을 시작하지 않으시나요? 🤔
RunComfy에서는 설정 없이 온라인에서 ComfyUI를 사용할 수 있도록 간단하게 만들었습니다. ComfyUI 온라인 서비스에는 200개 이상의 인기 노드와 모델이 사전 로드되어 있으며, 창작물에 영감을 줄 50개 이상의 멋진 워크플로우도 포함되어 있습니다.
🌟 RunComfy는 초보자든 숙련된 AI 아티스트든 상관없이 예술적 비전을 실현하는 데 필요한 모든 것을 제공합니다. 💡 더 이상 기다리지 마세요 – 지금 ComfyUI 온라인 사용해보기를 통해 손끝으로 AI 아트 제작의 힘을 경험하세요! 🚀